垃圾邮件分类(trec06c数据集)特征分词、特征向量化、模型训练
目录
得到全量数据集
得到采样数据集
模型训练
全部代码:
结果
已完结
接上: 垃圾邮件分类(trec06c数据集)数据处理-特征提取 https://blog.csdn.net/qq_39321513/article/details/111997173
我是将分词前的文本数据存文件了,这样就得取数据,分词,向量化,输入模型;当然也可以将分词之后的存成文件,一封邮件样本存成一行,然后取数据,向量化,输入模型进行训练。
接下来就对 mailcorous.txt 文件进行操作就可以啦
得到全量数据集
(这个一般不用,内存容易爆满,但我也贴上来了)
def get_train_data(train_path):
"""获取数据集----全量数据集"""
train_file = open(train_path, encoding='utf8')
# 加载训练数据
corpus = train_file.readlines() # 列表中的每个元素为一行文本 也就是一封邮件(包含4个特征)
split_corpus = []
#分词
for c in corpus:
split_corpus.append(" ".join(jieba.lcut(c)))
train_file.close()
cv = CountVectorizer(token_pattern=r'(?u)\b\w\w+\b')# 保留两个及以上的特征词
X = cv.fit_transform(split_corpus).toarray() # 特征向量
# 垃圾邮件是1 正常邮件是0
# 垃圾邮件42854封 正常邮件21766封
y = [0] * 21766 + [1] * 42854 #构造分类标签
return X, y得到采样数据集
def Sample(train_path, k=3000, random_state=10):
# 从原始数据集中各抽取3000个样本 # 垃圾邮件42854封 正常邮件21766封
# 设置随机种子
random.seed(random_state)
# 正常邮件的
ham_range = range(0, 21766)
ham_rdnum = random.sample(ham_range, k)
# 垃圾邮件的
spam_range = range(21766, 42854)
spam_rdnum = random.sample(spam_range, k)
train_file = open(train_path, encoding='utf8')
# 加载训练数据
corpus = train_file.readlines() # 列表中的每个元素为一行文本 也就是一封邮件(包含4个特征)
split_corpus = []
# 分词
for i, c in enumerate(corpus):
if i in ham_rdnum:
split_corpus.append(" ".join(jieba.lcut(c))) # 前k个--正常邮件
for i, c in enumerate(corpus):
if i in spam_rdnum:
split_corpus.append(" ".join(jieba.lcut(c))) # 后k个--垃圾邮件
train_file.close()
cv = CountVectorizer(token_pattern=r'(?u)\b\w\w+\b')
X = cv.fit_transform(split_corpus).toarray() # 特征向量
# 垃圾邮件是1 正常邮件是0
y = [0] * k + [1] * k # [0 0 0 0 1 1 1 1 ]
return X, y模型训练
这里我使用SVM训练分类模型
def Model_train_test(X, y):
"""模型的训练及验证"""
# 切分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 使用SVM训练分类模型
SVM_model = svm.SVC(C=1.0,kernel='sigmoid',gamma='auto',verbose=True)
SVM_model.fit(x_train, y_train)
# 测试分类性能
y_test_predict = SVM_model.predict(x_test)
print("准确率: ", SVM_model.score(x_test, y_test))
print("分类报告: ", metrics.classification_report(y_test,y_test_predict))
print("混淆矩阵: ", metrics.confusion_matrix( y_test, y_test_predict))主函数
if __name__ == '__main__':
train_path = 'trec06c/data/mailcorous.txt'
X, y = Sample(train_path, k=3000, random_state=10)
Model_train_test(X, y)
全部代码:
import pandas as pd
import jieba
from sklearn.feature_extraction.text import CountVectorizer
import random
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn import metrics
def get_train_data(train_path):
"""获取数据集----全量数据集"""
train_file = open(train_path, encoding='utf8')
# 加载训练数据
corpus = train_file.readlines() # 列表中的每个元素为一行文本 也就是一封邮件(包含4个特征)
split_corpus = []
#分词
for c in corpus:
split_corpus.append(" ".join(jieba.lcut(c)))
train_file.close()
cv = CountVectorizer(token_pattern=r'(?u)\b\w\w+\b')
X = cv.fit_transform(split_corpus).toarray() # 特征向量
# 垃圾邮件是1 正常邮件是0
# 垃圾邮件42854封 正常邮件21766封
y = [0] * 21766 + [1] * 42854
return X, y
def Sample(train_path, k=3000, random_state=10):
# 从原始数据集中各抽取3000个样本 # 垃圾邮件42854封 正常邮件21766封
# 设置随机种子
random.seed(random_state)
# 正常邮件的
ham_range = range(0, 21766)
ham_rdnum = random.sample(ham_range, k)
# 垃圾邮件的
spam_range = range(21766, 42854)
spam_rdnum = random.sample(spam_range, k)
train_file = open(train_path, encoding='utf8')
# 加载训练数据
corpus = train_file.readlines() # 列表中的每个元素为一行文本 也就是一封邮件(包含4个特征)
split_corpus = []
# 分词
for i, c in enumerate(corpus):
if i in ham_rdnum:
split_corpus.append(" ".join(jieba.lcut(c))) # 前k个--正常邮件
for i, c in enumerate(corpus):
if i in spam_rdnum:
split_corpus.append(" ".join(jieba.lcut(c))) # 后k个--垃圾邮件
train_file.close()
cv = CountVectorizer(token_pattern=r'(?u)\b\w\w+\b')
X = cv.fit_transform(split_corpus).toarray() # 特征向量
# 垃圾邮件是1 正常邮件是0
y = [0] * k + [1] * k # [0 0 0 0 1 1 1 1 ]
return X, y
def Model_train_test(X, y):
"""模型的训练及验证"""
# 切分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 使用SVM训练分类模型
SVM_model = svm.SVC(C=1.0,kernel='sigmoid',gamma='auto',verbose=True)
SVM_model.fit(x_train, y_train)
# 测试分类性能
y_test_predict = SVM_model.predict(x_test)
print("准确率: ", SVM_model.score(x_test, y_test))
print("分类报告: ", metrics.classification_report(y_test,y_test_predict))
print("混淆矩阵: ", metrics.confusion_matrix( y_test, y_test_predict))
if __name__ == '__main__':
train_path = 'trec06c/data/mailcorous.txt'
X, y = Sample(train_path, k=3000, random_state=10)
Model_train_test(X, y)结果
咦 ~~~ 准确率太低了,哈哈效果不好~ 只邮件正文的特征准确率都能达到90%以上,我费了劲儿还让准确率降低了 呵呵o(* ̄︶ ̄*)o
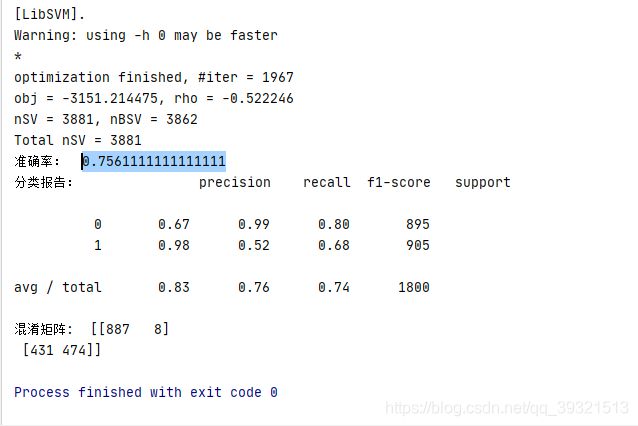
这是我的一个课程小作业,就这样吧,啊哈哈哈~ 不看效果,反正整个流程走下来还是学习到很多东西的,感觉挺充实的~
整个过程可调整可优化的地方其实还有很多,但不想再弄了 哈哈~
已完结
欢迎转发~ 评论讨论~ 点赞~
转载请注明出处~
谢谢大家的支持!~ O(∩_∩)O~