使用半监督学习从研究到产品化的3个教训
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Varun Nair
编译:ronghuaiyang
导读
作者总结了自己在使用半监督学习进行研究和产品化的过程中踩过的一些坑,非常的有实际意义。

如今,大多数深度学习算法的成功,在很大程度上是几十年研究、GPU和可用数据不断增长的的结果。但不是任何类型的数据 —— 而是那些丰富的、干净的、带有标签的数据。
像ImageNet, CIFAR10, SVHN等数据集,已经帮助研究人员在计算机视觉任务上取得显著进展,并且对我们自己的实验非常有用。然而,对于许多寻求从这一进步中获益的应用(如医学)来说,棘手的问题恰恰是数据必须是“丰富的、干净的、有标签的”这一事实。
半监督学习(SSL),一个结合了监督和非监督学习的子领域,在过去几年中在深度学习研究社区中越来越受欢迎。很有可能,至少在短期内,SSL方法可能成为标签密集型监督学习和未来数据高效建模之间的桥梁。
在这篇文章中,我们将讨论在生产环境中什么时候应该考虑使用SSL方法,以及在Uizard上使用它们来改进物体检测模型所获得的经验教训。
我们希望通过展示SSL是如何工作的,以及什么时候不工作,通过分享我们从研究到生产的过程中学到的技巧,我们可以激励你在工作冒险用SSL试试,释放你的未标记数据的潜力。
简而言之,我们强调以下几点教训:
简单为王。在SSL中,从研究到生产的最成功的方法是那些最容易复制的方法。具体来说,我们将详细阐述“Self-Training with Noisy Student”对我们的作用。
使用启发式的伪标签优化可以是非常有效的。伪标记是SSL方法中一个流行的组成部分 —— 我们发现,使用简单的启发式方法来优化未标记数据中的伪标记可以提高不同大小的未标记数据集的性能。
半监督图像分类的提升很难转化为目标检测的提升。我们在SSL方面的大部分进展都是在图像分类性能方面进行的,并在目标检测方面进行类似的改进,但我们发现很难在实践中对它们进行适应。因此,在半监督目标检测领域需要进行更多的工作和研究。
什么是半监督学习(SSL)?

顾名思义,半监督学习(SSL)指的是一类介于监督学习和非监督学习之间的算法 —— 旨在同时使用标记数据和非标记数据对分布进行建模。
SSL的目标通常是比单独使用有标签的数据做得更好,能够建模目标分布,就好像我们也可以访问所有未标记数据的标签一样。
这样的算法并不是一个新想法,尽管在过去的18个月中,在深度半监督学习方面已经有了相当多的兴趣、进展和应用,我们将在下面讨论。
什么时候在产品中使用SSL是正确的?
如果你正在考虑使用SSL解决一个问题,那一定是因为你的数据集很大,并且有许多未标记的数据。你的数据集的一部分可能被标记,当然标记越多的数据越好 —— 但希望至少有和标记数据一样多的未标记数据,或者可能更多。
如果你可用的大多数数据都是带标签的,或者不带标签的数据集的分布与带标签的数据集明显不同,那么SSL现在可能并不适合你的应用。对于后一种情况,请查看域适应。
考虑到这一点,在实际应用中有两个主要设置适合去研究SSL方法:
你正在处理一个高价值的问题,对于这个问题,仅使用标记数据不足以产生足够的性能,并且还有很多倍的(10-100x +)的未标记数据可用和/或容易获得。
在这种情况下,我们要强调的是,得到具有生产价值的性能的可能性较低 —— 但是对于没有标记数据的任务,如果有一个数量级或更多的未标记数据,并且有足够的激励、时间和资源,那么尝试使用SSL是有意义的。
你正在处理的问题是,仅使用已标记的数据就足以产生足够的性能,但是你有一个未标记的样本集合,希望进一步提高性能。
在这种情况下,你可能已经有了一个做得很好的模型,或者几乎和你要求的一样好 —— 但是你想继续推动性能的提高,而不需要花费太多精力去标注新的数据。因此,可以将SSL视为改进建模的众多工具之一,例如获得标记更清晰的数据集、训练更大的模型,等等。对于性能关键型的应用,错误率相对降低5-10%以上是非常重要的,并且有未标记数据可用,SSL尤其重要。
SSL方法的研究
这里有一些方法我们在下面的图像分类和目标检测中尝试过,但SSL还可以适用于其他领域如NLP以及音频/语音处理。
图像分类
MixMatch (Berthelot et al., 2019)
Unsupervised Data Augmentation (UDA) (Xie et al., 2019)
FixMatch (Sohn et al., 2020-A)
物体检测
CSD (Jeong et al., 2020)
STAC (Sohn et al., 2020-B)
任务无关
Noisy Student (Xie et al., 2019)
Lesson #1: 简单为王
在我们于2019年6月对半监督学习方法进行的最初文献综述中,关于MixMatch和UDA在SSL领域取得显著进展的报告非常吸引人,尤其是在标签数据极其有限的情况下。我们能够相对轻松地重现他们在CIFAR10和SVHN上的结果,这让我们相信他们有能力将这些性能上的收获在我们的数据集上进行迁移。
然而,经验上我们这样做并不是最优的,主要是因为 ——hyper-parameter调优。许多在论文中用于数据集的超参数的用在我们数据集上变得对性能很敏感。我们也注意到,我们的标签数据集在无标签数据上分布稍微有点不同,这个问题通常会导致SSL技术性能下降,这是在现实中使用SSL需要克服的一个挑战。截至2019年9月,对于我们来说,现有的最先进的SSL技术似乎还不够简单或灵活。
快进到2020年6月,两项新的SSL工作已经发布,它们专注于简单的实现 —— FixMatch和Self-Training with Noisy Student。
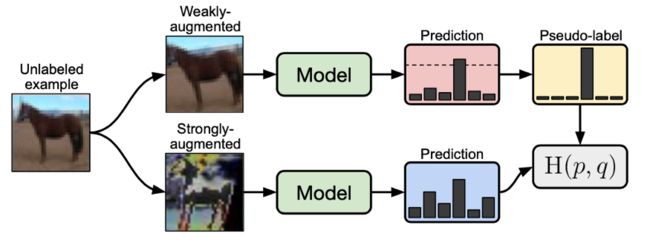
FixMatch是其前身MixMatch的一个更简单但更有效的版本,我们成功地将他们的结果在CIFAR10, SVHN上复现了。这一次,我们在自己的图像分类数据集上也看到了很好的结果,性能对超参数的选择不那么敏感,而且可以调优的超参数也很少。
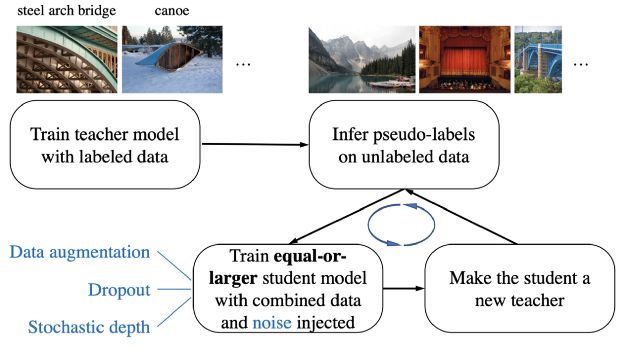
Noisy Student 训练包括一个迭代过程,在这个过程中,我们训练一个教师模型(可以访问标记数据的模型),使用这个模型推断未标记数据的输出,然后在标记数据和伪标记数据上重新训练一个称为学生的新模型。然后我们可以重复这个循环,即所谓的self-training,通过这个学生模型在未标记集上推断新的伪标签。论文中展示了使用这个框架在300M未标记图像中进行了训练,并强调了添加各种类型的噪声(增强,dropout等)是成功的关键。
需要注意的是,Noisy Student方法是一个任务无关的框架,可以被广泛应用:图像分类,目标检测,情感分析,等等。**对我们来说,Noisy Student方法是我们尝试的所有技术中用于目标检测最成功的。**我们在后面会讨论为什么FixMatch的物体检测版本(STAC)和其他方法可能对我们无效,但是我们坚信,与其他方法相比,Noisy Student的简单性和灵活性是我们在产品模型中看到改进的原因。
为什么这么简单?现有的训练超参数和设置几乎没有改变。以下是整个管道所需要做的:
把我们现有的生产模型当作教师模型。
编写一些脚本,与教师模型一起推断和改进未标记数据上的伪标签(关于伪标签改进的更多信息,请参阅lesson #2)。
训练“学生”模型,增加噪音(增强等)。
按照图中显示的框架重复这个过程。
其他的一些想法和要点:
我们惊讶地发现,在使用Noisy Student方法时,未标记数据比标记数据少的情况下,我们的一些模型得到了改进。更多关于这个的内容,请参见lesson #2。一般来说,未标记数据越多越好。
我们发现,在没有进行增强,比如dropout、随机深度或软伪标签的情况下,使用普通的自我训练,我们的学生模型的表现得到了改善。一旦增加了这些,就有可能进一步提高我们的性能,就像在ImageNet上那样。、
使用较大的学生模型的结果是有好有差的,对我们来说,这意味着在我们的检测模型中使用从ResNet-50到ResNet-101的主干。
总的来说,在图像分类或目标检测方面,简单性是第一位的。FixMatch明显比MixMatch更容易适应我们的自定义图像分类数据集,而Noisy Student只需要对我们现有的物体检测管道进行很少的改变就可以看到改进的性能。
Lesson #2: 启发式伪标签优化可以非常有效果
伪标签,也被称为 self-training,是在SSL中出现的一个范式,早在20世纪60年代和70年代,因为它的简单而被坚持了下来。引入伪标签的深度SSL展示了使用有标签数据的时候,这个想法是如此的简单而强大。使用该模型在未标记数据上推断标签(现在叫伪标签),然后用标签数据和伪标签数据再进行训练。许多现在的SSL技术都在使用某种形式的伪标签,包括FixMatch和使用Noisy Student的Self-Training。
然而,这些伪标签常常是有噪声的,需要某种形式的提纯才能使用。在FixMatch和Noisy Student中,这意味着对推断出的伪标签应用一个临界值(比如0.7或0.9),只取那些softmax confidence得分高于临界值的预测。我们发现这对于获得高质量的伪标签是一个有用的启发式方法,也发现对伪标签应用与其他领域特定的启发式方法在Noisy Student中有显著的效果。
我们在讨论什么样的启发式?例如,你正在为一家房地产公司构建一个物体检测分类器,该模型需要为home中的不同物体提供边框。你注意到(教师)模型的预测通常是好的,然而,分类器倾向于对未标记的集合产生几个不正确的、高可信度的预测,其中一些梳妆台实际上是厨房岛。

这里有一些启发式的例子,我们可以选择优化这个标签:
如果厨房岛和床的预测出现在同一图像中,将厨房岛标签转换为梳妆台。
如果梳妆台和厨房岛的预测出现在同一幅图像中,把厨房岛标签转换为梳妆台。
如果厨房岛,床,和梳妆台的预测出现在同一图像,将厨房岛标签转换为梳妆台。
以上哪一种启发式最有意义?这将取决于你的数据集以及最常见的错误类型。如果模型在检测床方面做得很好,也许像第一个或第三个那样的启发式可能会有用,因为我们不希望床和厨房岛出现在同一幅图像中。
特别是在物体检测中,当物体的位置和大小在你的应用领域中遵循某些规则时,你可以定义类似这样的启发式方法来优化嘈杂的伪标签,并帮助你的学生模型学习到教师模型不能学到的更好的表示。
使用启发式伪标签改进,我们能够在Noisy Student模型中取得更好的表现,在某些情况下,未标记数据比标记数据少个数量级。我们还发现,这个结论听起来与Rosenberg等人,2005年发表的一篇论文的观察结果惊人地相似。
一个独立于检测器的训练数据选择度量方法大大优于基于检测器生成的检测置信度的选择度量方法。
这是所有数据和建模问题的解决方案吗?当然不是 —— 但它说明了启发式在深度(半监督)学习管道中仍然是一个有用的部分。同样,这里应用的启发式是特定于领域的,只有仔细研究你的数据和模型的偏差才能得到有用的伪标签改进。
Lesson #3: 使用半监督在图像分类上的进步很难迁移到物体检测中
我们在SSL研究中取得的大部分进展都是基于对图像分类性能的测量,希望能够轻松地对其他任务(如物体检测)进行类似的改进。然而,在我们尝试采用图像分类方法进行目标检测时,我们遇到了几个挑战 —— 这导致我们坚持使用Lesson #1中提到的最简单的半监督目标检测方法。
以下是其中的一些挑战:
Online vs. Offline 伪标签生成
在许多用于图像分类的SSL技术(FixMatch, UDA等)中,未标记数据的伪标签目标在训练期间或online更新/计算。在offline学习训练分为多个阶段。首先用标记样本训练模型,然后生成伪标签。然后用标记样本和伪标记样本训练一个新的模型。
FixMatch和UDA是SSL技术的例子,它们利用在线学习来达到一个阈值,只允许预测超过某个阈值的未标记样本来帮助训练 —— 在Noisy Student和STAC (FixMatch的一个对物体测变体)中,然而,伪标签是离线生成的。
虽然在线学习似乎是有利的 —— 允许在训练早期差的伪标签在以后的训练步骤中得到纠正 —— 它使得训练的计算成本更高,对于训练物体检测模型更是如此。为什么?两件事:数据增强和批处理大小。关于数据增强,让我们回顾一下在 lesson #1关于FixMatch的的图。
我们可以看到,每个未标记的样本在训练时都是“弱增强”和“强增强”,需要将两张增强的图像通过网络前向传播,计算损失。这样的数据增强是许多SSL方法的基础,虽然对于图像分类来说是可行的,但对于大图像(512x512+)上的目标检测任务,训练时的处理时间的增加显著降低了训练速度。
在batch size方面,许多文章(MixMatch, UDA, FixMatch, Noisy Student)和我们自己的实验也强调了没有标记的数据的batch size是标记的数据的几倍对SSL方法的成功是至关重要的。这种对目标检测任务的要求,加上内存中的大图像,以及对未标记batch size中的所有样本的必要扩充,造成了极大的计算负担。这两个挑战,数据增加和未标记数据的batch size,使得我们不能将比如FixMatch一对一的迁移到物体检测中。
在与STAC的作者的讨论中,他们还注意到,在半监督物体检测领域,在线学习带来的巨大资源开销。我们希望未来的工作能更深入地研究这个问题,并且希望在未来几年的成果能让研究人员更容易地了解这个问题。
管理长尾与类别均衡
SSL研究中的许多基准数据集,如CIFAR10、CIFAR100和STL-10使用类别平衡的标记的训练集。我们的数据集,像许多真实的数据集,是非常长尾的。类别平衡被认为是许多SSL方法的关键组成部分,在图像分类中,上采样和下采样技术是常见的做法。然而,在物体检测设置中,有效的类平衡技术并不是那么简单。
如果类平衡对SSL在实践中的成功至关重要,那么我们如何在半监督的物体检测中实现类平衡呢?未来解决这一问题的研究肯定会受到欢迎。
其他的一些Tips
迁移学习和自训练叠加
正如在Zoph et al., 2020中对COCO训练发现的那样,从COCO到我们的数据集执行转移学习,然后在Noisy Student中进行自训练,取得的结果比单独执行两个步骤中的任何一个都要好。应用于生产模型的任何迁移知识很可能也可以应用于SSL模型,带来同等或更多的好处。
适当的数据增强很重要
由于数据增强是现代SSL方法的主要组成部分,所以要确保这些增强对你的领域有意义。例如,如果可用的扩展集包括水平翻转,那么训练用于区分左箭头和右箭头的边框的分类器显然会受到影响。
此外,在STAC和Noisy Student中,他们观察到,在自训练中,对教师模型使用数据增强会导致较差的下游学生模型。
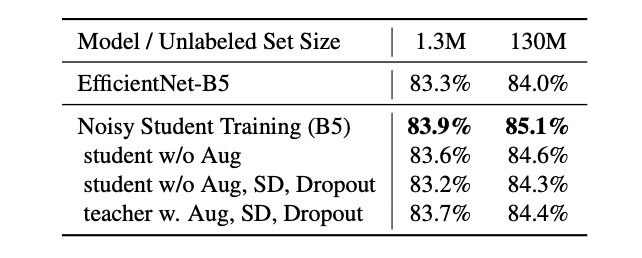
然而,我们发现,在我们的数据集上,使用数据增强的教师模型的Noisy Student和STAC的性能与不使用增强的教师模型相当或略好。虽然我们的结果可能是我们自己的数据集的一个特例,但我们相信这显示了广泛实验的重要性,并对你在论文中读到的观点的所谓成功和失败保持好奇。论文中显示的实证结果是一个很好的开始,但成功肯定是不能保证的,在SSL中仍有许多从理论角度尚不清楚的理解。
临别赠言
在过去的一年里,半监督学习(SSL)是我们工作的一个令人兴奋的领域,它在我们的生产模型中的最终结果向我们(也希望你们所有人)表明,在某些情况下可以而且应该考虑SSL。
特别是在Noisy Student中进行自训练,对于改进我们的目标检测模型是有效的。以下是我们在研究和生产深层SSL技术时所学到的3个主要教训:
简单为王
使用启发式的伪标签优化是非常有效的
半监督图像分类的进展很难转化为目标检测
所以今天的深度学习工程仍然是通过对潜在应用的了解来尝试和纠错 —— 我们希望你在半监督学习的工作中能够获得更多的经验。

—END—
英文原文:https://medium.com/@nairvarun18/from-research-to-production-with-deep-semi-supervised-learning-7caaedc39093

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!