第三章 索引
第三章 索引
文章目录
- 第三章 索引
-
- Ex1:公司员工数据集
- Ex2:巧克力数据集
学习参考:https://github.com/datawhalechina/joyful-pandas
import numpy as np
import pandas as pd
Ex1:公司员工数据集
现有一份公司员工数据集:
df = pd.read_csv('../data/company.csv')
df.head(3)

- 分别只使用
query和loc选出年龄不超过四十岁且工作部门为Dairy或Bakery的男性。 - 选出员工
ID号 为奇数所在行的第1、第3和倒数第2列。 - 按照以下步骤进行索引操作:
- 把后三列设为索引后交换内外两层
- 恢复中间一层
- 修改外层索引名为
Gender - 用下划线合并两层行索引
- 把行索引拆分为原状态
- 修改索引名为原表名称
- 恢复默认索引并将列保持为原表的相对位置
#1.分别只使用query和loc选出年龄不超过四十岁且工作部门为Dairy或Bakery的男性。
df.query('(age<40) and (department == ["Dairy","Bakery"]) and (gender=="M")').shape
![]()
con1 = df.age<40
con2 = (df.department == "Dairy") | (df.department =="Bakery")
con3 = df.gender == "M"
df.loc[con1&con2&con3].shape
![]()
#2.选出员工ID号 为奇数所在行的第1、第3和倒数第2列。
df.iloc[(df.EmployeeID%2 == 1).values,[0,2,-2]]

#按照以下步骤进行索引操作:
#3.把后三列设为索引后交换内外两层
df1 = df.set_index(df.columns.values.tolist()[-3:])
df1

df2 = df1.swaplevel(0,2,axis=0)
df2.head()
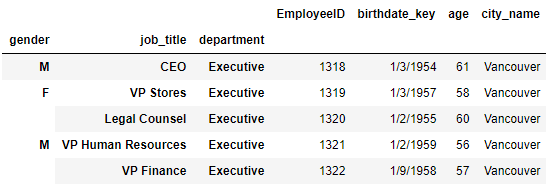
#4.恢复中间一层
df3 = df2.reset_index(level=1)
df3.head()
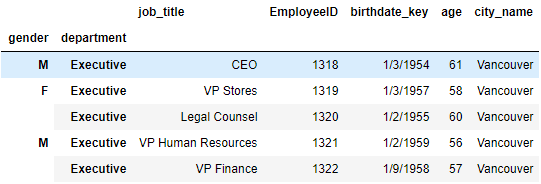
#5.修改外层索引名为Gender
df4 = df3.rename_axis(index={
'gender':'Gender'})
df4.head()

#6.用下划线合并两层行索引
df5 = df4.copy()
df5.index = df5.index.map(lambda x: (x[0]+'_'+x[1]))
df5.head()

#7.把行索引拆分为原状态
df6 = df5.copy()
df6.index = df6.index.map(lambda x:tuple(x.split('_')))
df6.head()

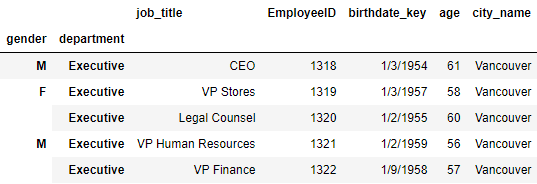
#8.修改索引名为原表名称
df7 = df6.rename_axis(index=['gender','department'])
df7.head()
#9.恢复默认索引并将列保持为原表的相对位置
df8 = df7.reset_index().reindex(df.columns,axis=1)
print(df8.equals(df)) # 判断两个数据框是否一致
df8.head()
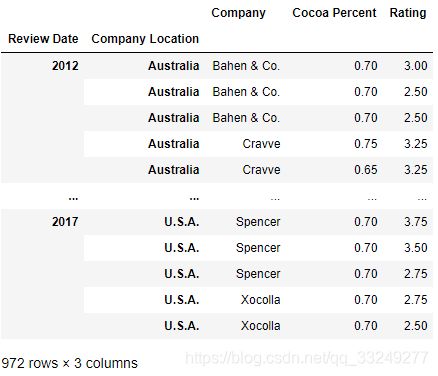
Ex2:巧克力数据集
现有一份关于巧克力评价的数据集:
df = pd.read_csv('../data/chocolate.csv')
df.head(3)

- 把列索引名中的
\n替换为空格。 - 巧克力
Rating评分为1至5,每0.25分一档,请选出2.75分及以下且可可含量Cocoa Percent高于中位数的样本。 - 将
Review Date和Company Location设为索引后,选出Review Date在2012年之后且Company Location不属于France, Canada, Amsterdam, Belgium的样本。
#1.把列索引名中的\n替换为空格
df.columns = [' '.join(i.split("\n")) for i in df.columns]
df.head()

#2.巧克力Rating评分为1至5,每0.25分一档,请选出2.75分及以下且可可含量Cocoa Percent高于中位数的样本。
df['Cocoa Percent']= df['Cocoa Percent'].str.strip("%").astype(float)/100
df.query('(Rating < 2.75) and (`Cocoa Percent`>`Cocoa Percent`.median())').shape
![]()
第三问没想出解决方法,答案的做法是:
#3.将Review Date和Company Location设为索引后,选出Review Date在2012年之后且Company Location不属于France, Canada, Amsterdam, Belgium的样本。
df1 = df.copy()
df1.head()

res = ["France","Canada","Amsterdam", "Belgium"]
df2 = df1.loc[idx[2012:,~df1.index.get_level_values(1).isin(res)],:]
df2