Day10 PythonWeb全栈课程课堂内容
Day10 PythonWeb全栈课程课堂内容
- 1. 进程和程序
- 2. python 实现多进程
- 3. 进程join方法
- 4. 队列
- 5. 进程间全局变量的共享
- 6. 队列的简单通信
1. 进程和程序
- 区别:没有执行的代码叫做程序,如pycharm.exe,而当代码运行起来以后就是进程。
- 一个程序可以对应多个进程。
进程的调度
- 先来先服务调度算法:对长作业有利,对短作业无益。
- 短作业优先调度算法。
- 时间片轮转 + 多级反馈列队。
进程状态介绍
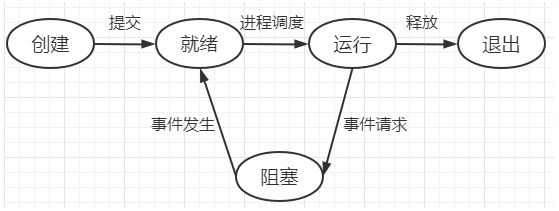
# 进入就绪状态
import time
# 程序开始运行
print("start")
# 阻塞状态
name = input("input:")
# 用户输入,解除阻塞状态。
# 就绪
# 程序开始运行
print(name)
# 阻塞
time.sleep(1)
# 就绪
print('end')
# 结束
同步和异步
- 同步:任务提交之后,原地等待任务的返回结果,等待的过程中不做任何事情。
- 异步:任务提交之后,不原地等待任务的返回结果,直接做其他的事情。
阻塞和非阻塞
- 阻塞:程序停滞,不会继续往下走。
- 非阻塞:程序不停滞,继续往下走。 就绪态、运行态。
2. python 实现多进程
通过 multiprocessing.Process模块
- group:参数未使用,默认值为None。
- target:表示调用对象,即子进程要执行的任务。
- args:表示调用的位置参数元祖。
- kwargs:表示调用对象的字典。
- name:子进程名称
import multiprocessing
import time
def task1():
while True:
print('--1--')
time.sleep(1)
def task2():
while True:
print('--1--')
time.sleep(2)
def main():
p1 = multiprocessing.Process(target=task1)
p2 = multiprocessing.Process(target=task2)
p1.start()
p2.start()
if __name__ == '__main__':
main()

注意:多个进程同时执行的顺序是随机的。
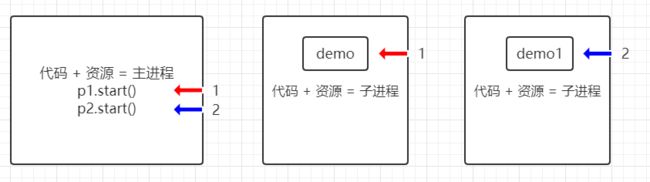
通过继承Process类创建进程
import multiprocessing
import time
class MyProcess(multiprocessing.Process):
def run(self):
print('---')
time.sleep(1)
c = MyProcess()
c.run()
进程与线程区别
-
根本区别
进程:操作系统资源分配的基本单位
线程:任务调度和执行的基本单位
-
开销
进程:通过复制代码+资源创建子进程 每个进程都有独立的代码和数据空间,程序之间的切换会有较大的开销
线程:在同一份代码里 创建线程 共享内存 开销较小
-
分配内存
进程:系统在运行的时候为每个进程分配不同的内存空间
线程:线程所使用的资源是它所属的进程的资源
-
包含关系
进程:一个进程可以拥有多个线程
线程:线程是进程的一部分


3. 进程join方法
from multiprocessing import Process
import time
def task(n):
print("hello", n)
time.sleep(n)
print('Python', n)
if __name__ == '__main__':
p1 = Process(target=task, args=(1,))
p2 = Process(target=task, args=(2,))
p3 = Process(target=task, args=(3,))
start_time = time.time()
p1.start()
p2.start()
p3.start()
print(time.time() - start_time) # 主进程的时间
- 如果我们要等到子进程结束之后打印时间。
from multiprocessing import Process
import time
def task(n):
print("hello", n)
time.sleep(n)
print('Python', n)
if __name__ == '__main__':
p1 = Process(target=task, args=(1,))
p2 = Process(target=task, args=(2,))
p3 = Process(target=task, args=(3,))
start_time = time.time()
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
print(time.time() - start_time)

加上join()之后会发现时间变为越3s,相当于本程序中等,p3.jion()子进程结束之后计算p3子进程的时间。
同样的将print(time.time() - start_time)放置在p2.join()之后你会得到约2s的时间,表示在计算p2子进程的时间。放置在p1之后也是同一个道理。
from multiprocessing import Process
import time
def task(n):
print("hello", n)
time.sleep(n)
print('Python', n)
if __name__ == '__main__':
start_time = time.time()
for i in range(1, 4):
p = Process(target=task, args=(i, ))
p.start()
p.join()
print(time.time() - start_time)
为什么时间边长?:因为前面的程序是p1.start(),p2.start(),p3.start()是同时运行的,而现在循环内部先p1.start()结束之后,再p2.start(),最后p3.start(),所以时间就比较长了。
- 解决此问题
# 创建一个列表
from multiprocessing import Process
import time
def task(n):
print("hello", n)
time.sleep(n)
print('Python', n)
if __name__ == '__main__':
start_time = time.time()
p_list = []
for i in range(1, 4):
p = Process(target=task, args=(i, ))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print(time.time() - start_time)
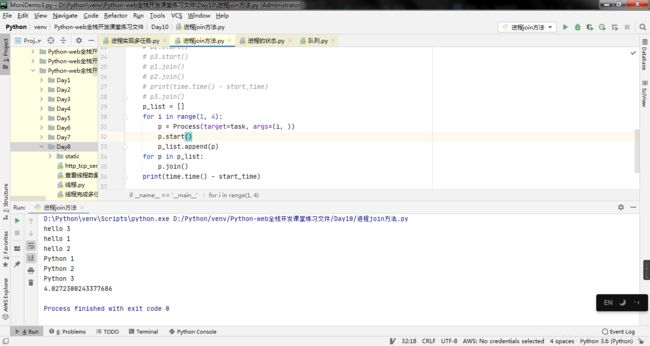
4. 队列
from multiprocessing import Queue
# 创建对象 队列
q = Queue(3)
# 存数据
q.put(3)
q.put("hello")
q.put([1,2])
# 取数据
print(q.get())
print(q.get())
print(q.get())
注意:
存数据的类型并没有限制。
Queue内的数值表示能存储多少数据。当Queue(3)时只能保存q.put(3),q.put("hello"),q.put([1,2])当存储数据大于创建对象的队列,就会使得程序发生停滞。
取数据里面当取数据的数量大于存储数据的数量时,同样最后程序也会发生停滞。
full()方法,用于判断队列内是否为满。
empty()方法,用于判断队列内是否为空。
put_nowait()方法,本质上和put()一样,只不过如果队列满了就会报异常。
get_nowait()方法,本质上和get()一样,只不过如果队列空了就会报异常。
- 队列作用
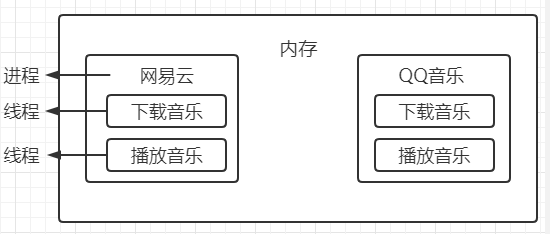
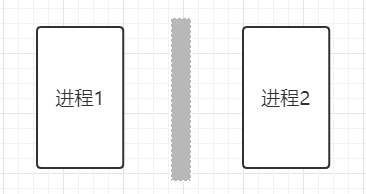
进程1和进程2之间完全不限解耦,只要经过中间灰色的队列,进程1将文件放在队列中,进程2从队列中获得。
5. 进程间全局变量的共享
import multiprocessing
a = 100
def task():
global a
a += 100
def task1():
print(a)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task)
p2 = multiprocessing.Process(target=task1)
p1.start()
p2.start()
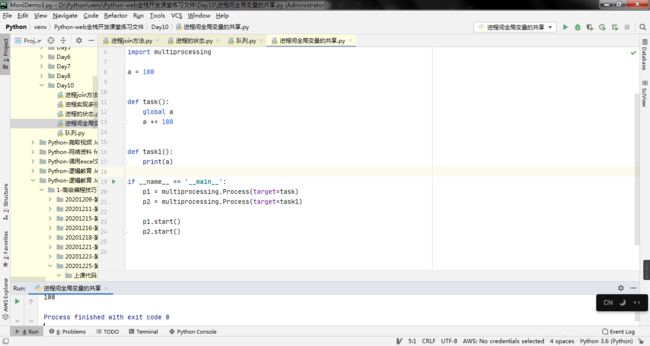
证明多进程之间的全局变量是不受影响的,且为相互独立的。
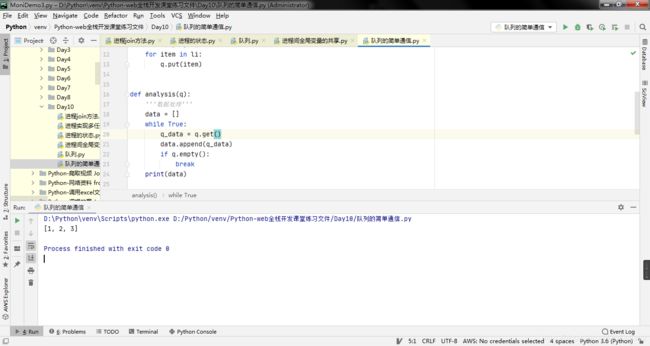
6. 队列的简单通信
# @Time : 2021/1/3 2:10
# @Author : Sam
# @File : 队列的简单通信.py
# @Software: PyCharm
import multiprocessing
def download(q):
'''下载数据'''
li = [1, 2, 3]
for item in li:
q.put(item)
def analysis(q):
'''数据处理'''
data = []
while True:
q_data = q.get()
data.append(q_data)
if q.empty():
break
print(data)
def main():
# 创建一个队列
q = multiprocessing.Queue()
p1 = multiprocessing.Process(target=download, args=(q,))
p2 = multiprocessing.Process(target=analysis, args=(q,))
p1.start()
p2.start()
if __name__ == '__main__':
main()
- 模拟下载延时
import multiprocessing
import time
import random
def download(q):
'''下载数据'''
li = [1, 2, 3]
for item in li:
q.put(item)
time.sleep(random.randint(1, 3))
def analysis(q):
'''数据处理'''
data = []
while True:
q_data = q.get()
data.append(q_data)
if q.empty():
break
print(data)
def main():
# 创建一个队列
q = multiprocessing.Queue()
p1 = multiprocessing.Process(target=download, args=(q,))
p2 = multiprocessing.Process(target=analysis, args=(q,))
p1.start()
p1.join()
p2.start()
if __name__ == '__main__':
main()
start() 与 run() 区别
- start() 方法来启动进程,真正实现了多进程运行,这时无需等待 run 方法体代码执行完毕而直接继续执行下面的代码:调用 Process 类的 start() 方法来启动一个进程,这时此进程处于就绪(可运行)状态,并没有运行,一旦得到 cpu 时间片,就开始执行 run() 方法,这里方法 run() 称为进程体,当进程结束后,不可以重新启动。
- run() 方法只是类的一个普通方法,如果直接调用 run 方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待 run 方法体执行完毕后才可继续执行下面的代码,这样就没有达到写线程的目的。
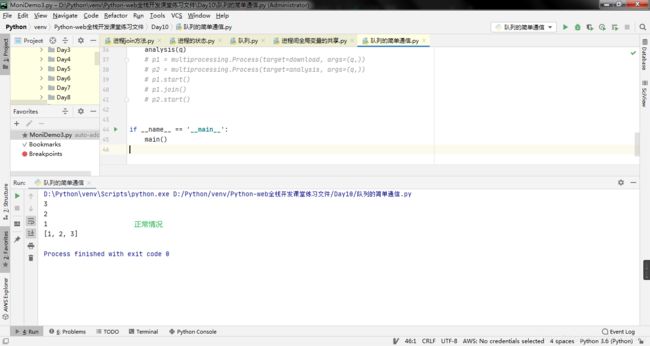
# 特殊情况 持续运行
import multiprocessing
def download(q):
'''下载数据'''
li = [1, 2, 3]
for item in li:
q.put(item)
def analysis(q):
'''数据处理'''
data = []
while True:
print(q.qsize())
q_data = q.get()
data.append(q_data)
if q.empty():
break
print(data)
def main():
# 创建一个队列
q = multiprocessing.Queue()
download(q)
analysis(q)
if __name__ == '__main__':
main()

-
为什么会只出现两个值原因是队列中恰巧放进去值时,也恰好取出,造成了队列中为空值,循环结束!
-
解决方法:将队列变成全局变量就可以。
import multiprocessing
def download(q):
global li
li = [1, 2, 3]
for item in li:
q.put(item)
def analysis(q):
'''数据处理'''
data = []
while True:
print(q.qsize())
q_data = q.get()
data.append(q_data)
if len(data) == len(li):
break
print(data)
def main():
# 创建一个队列
q = multiprocessing.Queue()
download(q)
analysis(q)
if __name__ == '__main__':
main()