【Task Special】Pandas之综合练习
前言
本次打卡用于巩固知识,在一些细节上进行了一定程度的展开和说明,温故而知新。
Mission01 企业收入的多样性
题目:一个企业的产业收入多样性可以仿照信息熵的概念来定义收入熵指标:

其中pi是企业该年某产业收入额占该年所有产业总收入的比重。在Company.csv中存有需要计算的企业和年份,在Company_data.csv中存有企业、各类收入额和收入年份的信息。现请利用后一张表中的数据,在前一张表中增加一列表示该公司该年份的收入熵指标 I。
步骤一 观察数据
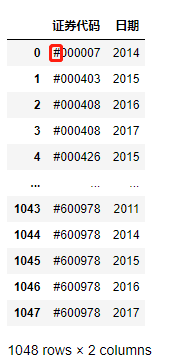
df1 = pd.read_csv('./data/mission01/Company.csv')
df1
df2 = pd.read_csv('./data/mission01/Company_data.csv')
df2

这里发现了表1和表2中股票代码和日期格式的不同,在之后的操作中要进行处理。
步骤二 细节处理
#这里考虑到收入占比需要保证为大于0,否则会对log运算产生影响
df2 = df2[df2['收入额'] > 0]
df2['日期'] = df2['日期'].apply(lambda x:x[:4])
df2.set_index(['证券代码','日期'],inplace=True)
df2=df2['收入额']
df2
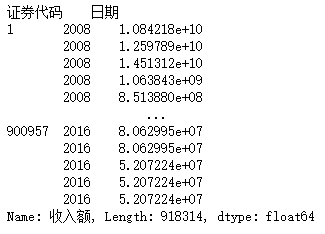
我们将日期修改为只保留年份,并将表2的索引设置为证券代码和日期,最后在列展示方面只保留收入额这一列。最后得到的df2为收入额不为0的拥有多级行索引的待处理Series型数据,值为不同企业不同年份的收入。
步骤三 构造自定义方法
#用于求收入熵的方法
def getEntropy(x):
p = x/x.sum()
res = -(p*np.log2(p)).sum()
return res
#用于求一家公司某一年份的收入熵
def getTotalEntropy(x):
#拿到每一行的公司代码和年份数据
companyCode = int(x[0][1:])
year = str(x[1])
if (companyCode,year) in df2.index:
return df2.loc[(companyCode,year)].agg(getEntropy)
else:
return 0
#df1中的数据df2不一定存在 所以要提前判断
df1['收入熵指标']=df1.apply(getTotalEntropy,axis=1)
df1
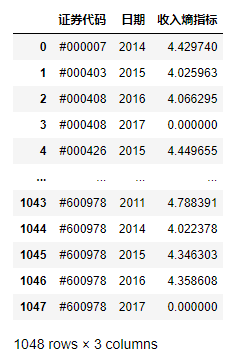
思路:利用apply方法对表1行进行遍历,对每一行通过表2的对应信息计算收入熵指数后返回。
注意,表1中的部分行不在表2中,所以在自定义方法中计算收入熵之前需要做一个包含关系判断。
另外,对于熵的计算,将负收入和零收入直接去掉,这样丢弃数据可能会损失一部分信息。
完整代码
#用于求收入熵的方法
def getEntropy(x):
p = x/x.sum()
return -(p*np.log2(p)).sum()
#用于求一家公司某一年份的收入熵
def getTotalEntropy(x):
#拿到每一行的公司代码和年份数据
companyCode = int(x[0][1:])
year = str(x[1])
#df1中的数据df2不一定存在 所以要提前判断
if (companyCode,year) in df2.index:
return df2.loc[(companyCode,year)].agg(getEntropy)
else:
return 0
df1 = pd.read_csv('./data/mission01/Company.csv')
df2 = pd.read_csv('./data/mission01/Company_data.csv')
#处理表2数据
df2 = df2[df2['收入额'] > 0]
df2['日期'] = df2['日期'].apply(lambda x:x[:4])
df2.set_index(['证券代码','日期'],inplace=True)
df2=df2['收入额']
#遍历表1的行 求每行的收入熵指标
# df1['收入熵指标']=df1.apply(getTotalEntropy,axis=1)
df1.insert(2,'收入熵指标',df1.apply(getTotalEntropy,axis=1))
df1
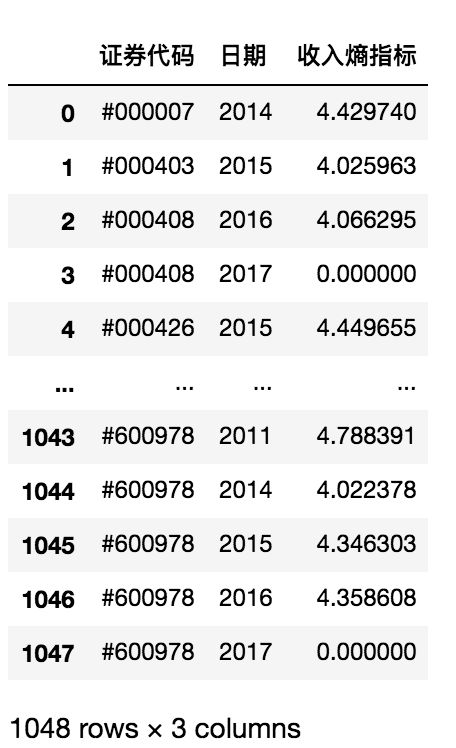
注:这里最终在插入行时使用了insert方法,通过的是绝对位置插入的,此处不能像python索引一样使用负数,如果想要动态插入,需要提前获取整个列索引的长度。
Mission02 组队学习信息表的变换
题目:请把组队学习的队伍信息表变换为如下形态,其中“是否队长”一列取1表示队长,否则为0
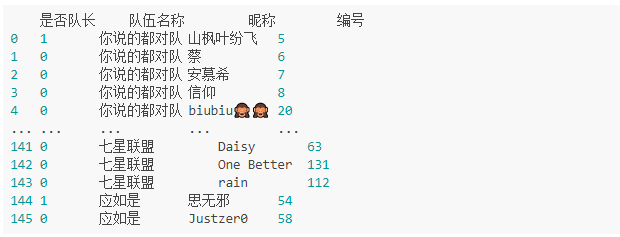
步骤一 读取数据并获取有效信息
#步骤一 读取数据并获取有效信息
df = pd.read_excel('./data/mission02/pandas_team.xlsx')
#储存队伍名和最多人数
teams = df['队伍名称']
#截取表格
df = df[df.columns[2:]]
max_num = df.shape[1]//2
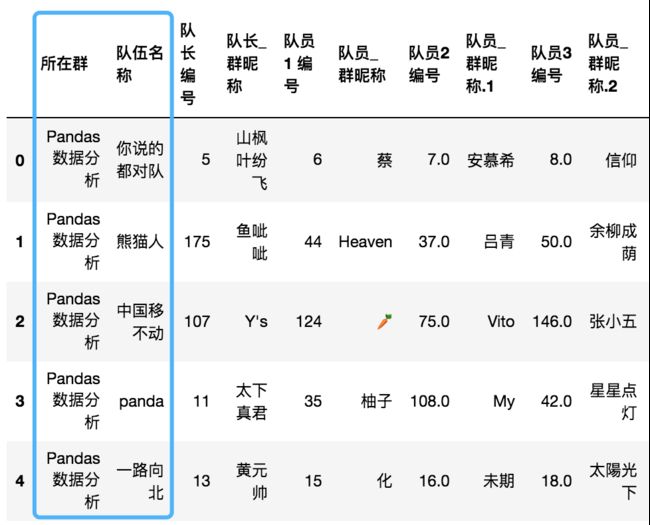
思路:读取数据,用teams变量储存队伍信息,用max_num变量储存每队最多人数,去掉数据表的前两列。
步骤二 新建列索引并改变
#第二步
max_num = df.shape[1]//2
team_num = df.shape[0]
#构建列索引
a = [x for x in range(max_num)]
cols = pd.MultiIndex.from_product([a,['编号','昵称']])
df.columns = cols
df.head()
思路:利用多级索引中from_product(笛卡尔积的创建方式)创建新的索引,对列索引进行重构,利用第一层列索引映射到每只队伍的信息,以便后续操作。
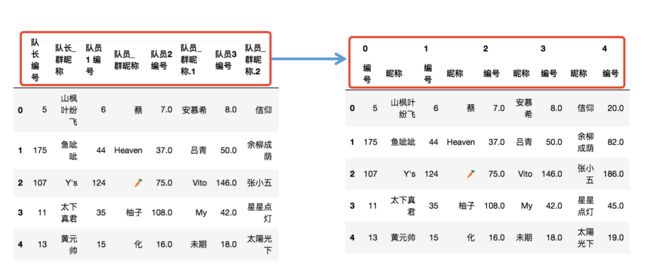
步骤三 变形
df = df.stack()
df.head()

思路:利用stack将列索引的最后一层移动到行索引的最后一层,这里用到了stack的斜移特性,效果如下。需要注意的是经过变形后编号的dtype型均变为int型。
df = df.T
df.head()

思路:然后将数据表进行转置,得到右图,第一层列索引即指向每一队的信息,红框中代表第一队信息,此时轮廓已经初现。
步骤四 堆叠
res = []
[res.append(df[i]) for i in range(len(teams)]
res = pd.concat(res)
res
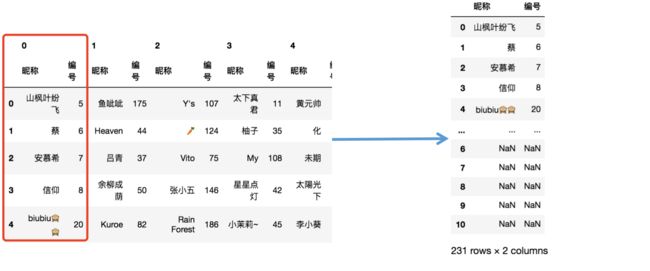
思路:按第一层列索引利用concat方法将每只队伍的信息进行堆叠,得到右图所示数据图。
步骤五 构造额外信息列
captain_col = np.array([[1]+[0]*(max_num-1)]*len(teams)).flatten()
teamname_col=[[x]*max_num for x in teams.values]
teamname_col = np.array(teamname_col).flatten()
print(captain_col.shape)
(231,)
print(teamname_col.shape)
(231,)
res.insert(0,'是否队长',captain_col)
res.insert(1,'队伍名称',teamname_col)
res

思路:利用在步骤一拿到的队伍信息和人数信息,构建两列新的信息列,然后使用insert方法将其插入到数据表中。
步骤六 剔除无用信息
res = res[~res['编号'].isna()]
res.reset_index(drop=True,inplace=True)
res
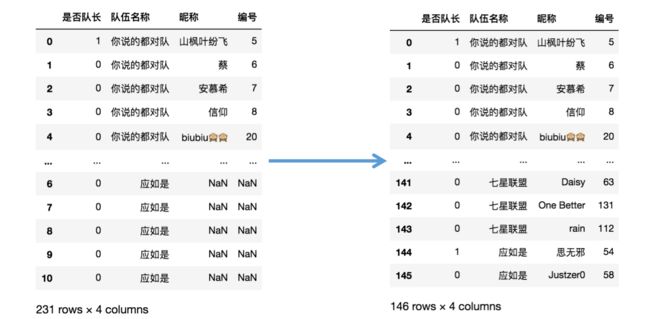
思路:利用df行的访问方式去掉编号为NaN的行,同时将行索引重置为默认索引。
完整代码
#步骤一 获取数据
df = pd.read_excel('./data/mission02/pandas_team.xlsx')
teams = df['队伍名称']
df = df[df.columns[2:]]
max_num = df.shape[1]//2
#步骤二 改变列索引
cols = pd.MultiIndex.from_product([[x for x in range(max_num)],['编号','昵称']])
df.columns = cols
#步骤三 变形
df = df.stack().T
#步骤四 堆叠
res = []
[res.append(df[i]) for i in range(len(teams))]
res = pd.concat(res)
#步骤五 插入新列
res.insert(0,'是否队长',np.array([[1]+[0]*(max_num-1)]*len(teams)).flatten())
res.insert(1,'队伍名称',np.array([[x]*max_num for x in teams.values]).flatten())
#步骤六 去掉无用数据
res = res[~res['编号'].isna()]
res.reset_index(drop=True,inplace=True)
res
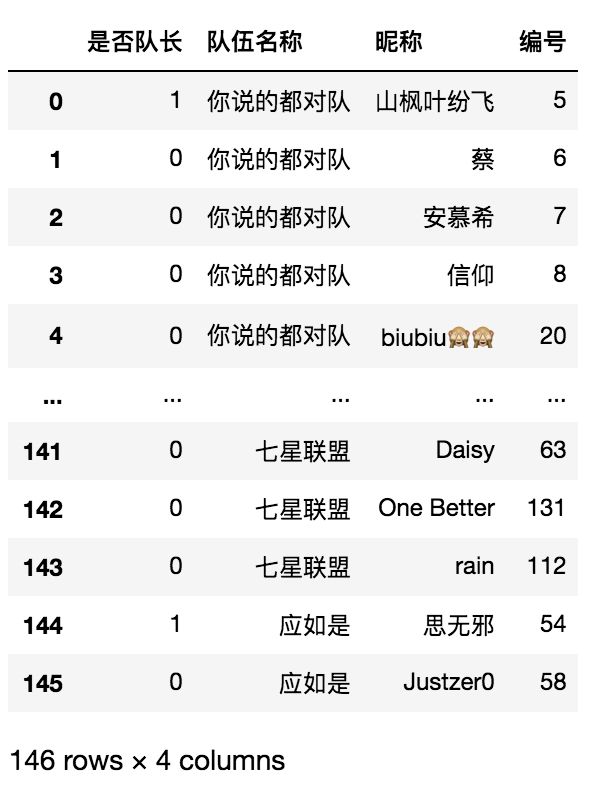
Mission03 复仇者联盟2020大战
数据展示:
#人口数各县
df1 = pd.read_csv('./data/mission03/county_population.csv')
#大选投票情况
df2 = pd.read_csv('./data/mission03/president_county_candidate.csv')

我们可以看到表1和表2中对于county列的表示是不同的,提前进行修改:
df1['US County'] = df1['US County'].apply(lambda x:x.split(',')[0][1:])
df1
这里避免每个州的县有重名的情况,特意查看了一下:
df1['US County'].sort_values()

并未出现重名的情况。
问题1 统计有效县
步骤一 分组统计
#统计每个县的有效投票数
county_votes = df2.groupby('county')['total_votes'].sum()
county_votes
思路:统计每个县的有效投票数,并存入county_votes变量中,类型为Series。
步骤二 自定义方法
def myfunc(x):
if x[0] in county_votes:
if county_votes[x[0]]>=x[1]//2:
return True
return None
return None
res = df1.apply(myfunc,axis=1)
print(res.count())
2292
思路:数据主体为表1,遍历单位为表1的每行数据,注意需要判断该县是否存在于投票的县中,然后进行数值比较,最后通过返回非缺省值和缺省值的数据类型方便使用count方法进行统计。
完整代码
def myfunc(x):
if x[0] in county_votes:
if county_votes[x[0]]>=x[1]//2:
return True
return None
return None
#统计每个县的有效投票数
county_votes = df2.groupby('county')['total_votes'].sum()
res = df1.apply(myfunc,axis=1)
print(res.count())
2292
问题2 复仇者排名
步骤一 获得排名列表
去除无意义的数据:
#根据候选人进行分组,求得每位候选人的得票综述
ranklist = df2.groupby('candidate')['total_votes'].sum()
#筛掉前面两个无意义的“候选人”,并对其余有效候选人按票数高低进行排序
ranklist = ranklist.iloc[2:].sort_values(ascending=False).index

思路:利用groupby对候选人列进行分组,求得每位候选人总的得票数,并剔除掉非候选人,使用sort_values方法获取候选人列表(按得票数从高到低)。
步骤二 获得各洲投票情况
此步用来获得每位候选人在每个州的得票情况:
df2_demo = df2.groupby(['state','candidate'])['total_votes'].sum()
df2_demo
思路:利用groupby方法按洲和候选人进行分组,对得票数进行汇总,存入df2_demo变量中,类型为Series,行索引为两层。
res = df2_demo.to_frame().unstack()
res.head()

思路:利用unstack()方法将已经转变为df的数据进行行索引移动,得到res为有效候选人在每个洲的选票情况。
步骤三 排序
直接利用第一步求出的候选人排名ranklist进行访问,注意在访问前要删除列索引的第一层索引:
#直接访问index
res.droplevel(0,axis=1)[ranklist]

完整代码
#根据候选人进行分组,求得每位候选人的得票综述
ranklist = df2.groupby('candidate')['total_votes'].sum()
#筛掉前面两个无意义的“候选人”,并对其余有效候选人按票数高低进行排序
ranklist = ranklist.iloc[2:].sort_values(ascending=False).index
#获得每位候选人在每个州的得票情况
df2_demo = df2.groupby(['state','candidate'])['total_votes'].sum()
res = df2_demo.to_frame().unstack()
#去掉第一层列索引后直接访问index
res.droplevel(0,axis=1)[ranklist]

整体思路:分三步走,前两步可以并行。首先求出每位候选人的总票数排名,存入Index数据中,这里需要注意去掉无用的前两个值。然后利用groupby和unstack方法获得每位候选人在不同州的得票情况,最后利用Index进行索引访问得到需要的数据。
问题3 求驴驴洲
步骤一 数据预处理
#只保留有用的列
use_cols = ['state','county','candidate','total_votes']
df2 = df2[use_cols]
df2

思路:只取4列,为下一步变形操作做准备。
步骤二 长宽表转换
#长表转宽表
res = df2[use_cols].pivot(index=['state','county'],columns='candidate',values='total_votes')
res

思路:步骤一得到的数据表是关于候选人的长表,根据题意用pivot方法将其转换宽表。注意,此处由于计算的是两者的得票率之差,所以要算入蓝色框中的两列。
步骤三 计算比率之差
#统计每个县所有人的投票和,并计算J和D的得票率之差,存到BT列
res = res.apply(lambda x:x/x.sum(),axis=1)[['Joe Biden','Donald Trump']]
res.insert(0,'BT',res['Joe Biden']-res['Donald Trump'])
res

思路:利用apply方法逐行进行处理,并将得到的结果列利用insert方法插入数据表中。
步骤四 分组聚合
res = res.groupby('state')['BT'].median()>0
list(res[res].index)
['California',
'Connecticut',
'Delaware',
'District of Columbia',
'Hawaii',
'Massachusetts',
'New Jersey',
'Rhode Island',
'Vermont']
思路:对state进行分组,然后使用官方API自带的median()方法求中位数,利用Series的布尔类型的索引访问求得结果。
完整代码
#数据裁剪
use_cols = ['state','county','candidate','total_votes']
df2 = df2[use_cols]
#长表转宽表
res = df2[use_cols].pivot(index=['state','county'],columns='candidate',values='total_votes')
#统计每个县所有人的投票和,并计算J和D的得票率之差,存到BT列
res = res.apply(lambda x:x/x.sum(),axis=1)[['Joe Biden','Donald Trump']]
res.insert(0,'BT',res['Joe Biden']-res['Donald Trump'])
#求出驴驴洲
res = res.groupby('state')['BT'].median()>0
list(res[res].index)
['California',
'Connecticut',
'Delaware',
'District of Columbia',
'Hawaii',
'Massachusetts',
'New Jersey',
'Rhode Island',
'Vermont']
思路:利用长宽表转换方法统计每位候选人在每个县的得票情况,然后利用apply方法逐行进行操作,求出BT指数并插入到数据表中。最后利用groupby对每个州进行分组,对州内的所有县的BT指数进行聚合操作,判断其中位数是否大于0,最后返回所谓的“驴驴洲”。
完结撒花