Collection集合
Collection集合框架、List、泛型、数据结构、 Set、Map
——前言
第一次写博客,给大家详细介绍一下 Collection集合框架, Collection集合框架是javase中入门级别的内容,也是面试时经常问道的内容,学习Collection集合框架就必须学习数据结构和各个集合的底层结构,内容有点多我打算分为7章给大家详细讲解
第一章 Collection集合
- 集合:集合是java中提供的一种容器,可以用来存储多个引用数据类型的数据。
集合和数组既然都是容器,它们有什么区别呢?
- 数组的长度是固定的。集合的长度是可变的。
- 集合存储的都是引用数据类型。如果想存储基本类型数据需要存储对应的包装类类型。
知识点-- 单列集合常用类的继承体系
Collection:是单列集合类的根接口,用于存储一系列符合某种规则的元素,它有两个重要的子接口,分别是
java.util.List:List的特点是元素存取有序、元素可重复 ;List接口的主要实现类有java.util.ArrayList和java.util.LinkedList,
java.util.Set:Set的特点是元素不可重复。Set接口的主要实现类有java.util.HashSet和java.util.LinkedHashSet,java.util.TreeSet。
为了便于初学者进行系统地学习,接下来通过一张图来描述集合常用类的继承体系

Collection集合: 是所有单列集合的父接口,所以定义了所有单列集合共有的方法
List集合:是Collection集合的子接口,所以也表示单列集合(特点:元素存取有序,元素可重复)
List集合的实现类: ArrayList类,LinkedList类
Set集合: 是Collection集合的子接口,所以也表示单列集合(特点:元素不可重复)
Set集合的实现类: HashSet类,LinkedHashSet类,TreeSet类
Collection 常用功能
- Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法可用于操作所有的单列集合。
- Collection集合 常用功能
Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法可用于操作所有的单列集合。方法如下:
public boolean add(E e): 把给定的对象添加到当前集合中 。public void clear():清空集合中所有的元素。public boolean remove(E e): 把给定的对象在当前集合中删除。public boolean contains(Object obj): 判断当前集合中是否包含给定的对象。public boolean isEmpty(): 判断当前集合是否为空。public int size(): 返回集合中元素的个数。public Object[] toArray(): 把集合中的元素,存储到数组中
tips: 有关Collection中的方法可不止上面这些,其他方法可以自行查看API学习。
public class Test {
public static void main(String[] args) {
// 创建Collection集合,限制集合中元素的类型为String类型
Collection<String> col = new ArrayList<>();
// public boolean add(E e): 把给定的对象添加到当前集合中 。
col.add("张三丰");
col.add("张无忌");
col.add("张翠山");
col.add("曾阿牛");
System.out.println("col:" + col);// [张三丰, 张无忌, 张翠山, 曾阿牛]
// public void clear() :清空集合中所有的元素。
//col.clear();
//System.out.println("col:"+col);// []
// public boolean remove(E e): 把给定的对象在当前集合中删除。
col.remove("曾阿牛");
System.out.println("col:" + col);// [张三丰, 张无忌, 张翠山]
// public boolean contains(Object obj): 判断当前集合中是否包含给定的对象。
boolean res1 = col.contains("曾阿牛");
boolean res2 = col.contains("张无忌");
System.out.println("res1:" + res1);// false
System.out.println("res2:" + res2);// true
// public boolean isEmpty(): 判断当前集合是否为空。
boolean res3 = col.isEmpty();
System.out.println("res3:" + res3);// false
// public int size(): 返回集合中元素的个数。
int size = col.size();
System.out.println("size:" + size);// 3
// public Object[] toArray(): 把集合中的元素,存储到数组中
Object[] arr = col.toArray();
System.out.println(Arrays.toString(arr));// [张三丰, 张无忌, 张翠山]
}
}
第二章 Iterator迭代器
-
在程序开发中,经常需要遍历单列集合中的所有元素。针对这种需求,JDK专门提供了一个接口
java.util.Iterator。 -
迭代的概念
-
获取迭代器对象
-
Iterator接口的常用方法
迭代的概念
迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续再判断,如果还有就再取出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
获取迭代器对象
Collection集合提供了一个获取迭代器的方法:
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。
Iterator接口的常用方法
public E next():返回迭代的下一个元素。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
案例演示
public class Test {
public static void main(String[] args) {
/*
迭代:即Collection集合元素的通用获取方式。
在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续再判断,如果还有就再取出来。
一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
获取迭代器对象: 使用Collection集合的方法
public Iterator iterator(); 获取该集合对应的迭代器
Iterator迭代器的方法:
public boolean hasNext();判断是否有元素可以迭代
public E next();获取可以迭代的元素
*/
// 创建Collection集合,限制集合中元素的类型为String
Collection<String> col = new ArrayList<>();
// 添加元素到集合中
col.add("张三丰");
col.add("张翠山");
col.add("张无忌");
col.add("曾阿牛");
// 获取col集合的迭代器对象
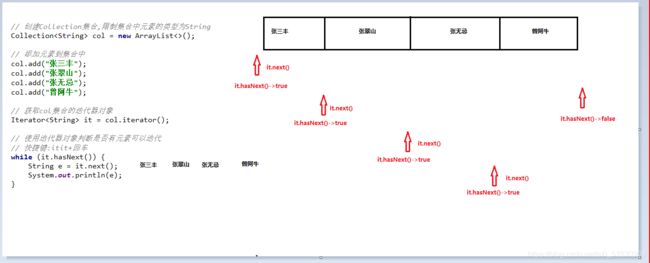
Iterator<String> it = col.iterator();
// 使用迭代器对象判断是否有元素可以迭代
/*while (it.hasNext()) {
// 如果有,就取出来
String e = it.next();
System.out.println(e);
}*/
// 快捷键:itit+回车
while (it.hasNext()) {
String e = it.next();
System.out.println(e);
}
}
}
知识点-- 迭代器的常见问题
目标
- 理解迭代器的常见问题
路径
- 常见问题一
- 常见问题二
常见问题一
-
在进行集合元素获取时,如果集合中已经没有元素可以迭代了,还继续使用迭代器的next方法,将会抛出java.util.NoSuchElementException没有集合元素异常。
public class Test1 { public static void main(String[] args) { /* 常见问题一:在进行集合元素获取时,如果集合中已经没有元素可以迭代了, 还继续使用迭代器的next方法,将会抛出java.util.NoSuchElementException没有集合元素异常。 */ // 创建Collection集合,限制集合中元素的类型为String Collection<String> col = new ArrayList<>(); // 添加元素到集合中 col.add("张三丰"); col.add("张翠山"); col.add("张无忌"); col.add("曾阿牛"); // 获取迭代器对象 Iterator<String> it = col.iterator(); // 循环迭代 while (it.hasNext()) { String e = it.next(); System.out.println(e); } System.out.println("==============================="); // 问题:报异常NoSuchElementException,没有找到集合元素异常 // String e = it.next(); // 解决办法:再重新获取一个迭代器 // 获取迭代器对象 Iterator<String> it1 = col.iterator(); // 循环迭代 while (it1.hasNext()) { String e = it1.next(); System.out.println(e); } } } -
解决办法: 如果还需要重新迭代,那么就重新获取一个新的迭代器对象进行操作
常见问题二
-
在进行集合元素迭代时,如果添加或移除集合中的元素 , 将无法继续迭代 , 将会抛出ConcurrentModificationException并发修改异常.
public class Test2 { public static void main(String[] args) { /* 常见问题二: 在进行集合元素迭代时,如果添加或移除集合中的元素 , 将无法继续迭代 , 将会抛出ConcurrentModificationException并发修改异常. */ // 创建Collection集合,限制集合中元素的类型为String Collection<String> col = new ArrayList<>(); // 添加元素到集合中 col.add("张三丰"); col.add("张翠山"); col.add("张无忌"); col.add("曾阿牛"); // 获取迭代器对象 Iterator<String> it = col.iterator(); // 循环迭代 while (it.hasNext()) { String e = it.next(); // 如果迭代出来的元素是张翠山,就添加一个殷素素到集合中 /*if (e.equals("张翠山")){ col.add("殷素素"); }*/ // 解决办法:换允许并发修改的集合 // 如果迭代出来的元素是张翠山,就删除该元素 /*if (e.equals("张翠山")){ col.remove(e); }*/ // 解决办法: 删除元素可以使用迭代器的remove()方法 if (e.equals("张翠山")){ it.remove(); } } System.out.println("col:"+col); } }
知识点-- 迭代器的实现原理
我们在之前案例已经完成了Iterator遍历集合的整个过程。当遍历集合时,首先通过调用t集合的iterator()方法获得迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取出,否则说明已到达了集合末尾,停止遍历元素。
Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素。在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,不指向任何元素,当第一次调用迭代器的next方法后,迭代器的索引会向后移动一位,指向第一个元素并将该元素返回,当再次调用next方法时,迭代器的索引会指向第二个元素并将该元素返回,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对元素的遍历。
知识点-- 增强for
增强for循环(也称for each循环)是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的。它的内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作。
格式:
for(元素的数据类型 变量名 : Collection集合or数组){
}
它用于遍历Collection和数组。通常只进行遍历元素,不要在遍历的过程中对集合元素进行增删操作。
代码演示
public class Test {
public static void main(String[] args) {
// 使用增强for循环遍历集合:
// 创建Collection集合,限制集合中元素的类型为String类型
Collection<String> col = new ArrayList<>();
// public boolean add(E e): 把给定的对象添加到当前集合中 。
col.add("张三丰");
col.add("张无忌");
col.add("张翠山");
col.add("曾阿牛");
// 快捷键: 集合名.for
for (String e : col) {
System.out.println(e);
}
System.out.println("============================================");
// 使用增强for循环遍历数组
String[] arr = {
"张三丰",
"张无忌",
"张翠山",
"曾阿牛"};
// 快捷键:数组名.for
for (String e : arr) {
System.out.println(e);
}
}
}
tips:
增强for循环必须有被遍历的目标,目标只能是Collection或者是数组;
增强for(迭代器)仅仅作为遍历操作出现,不能对集合进行增删元素操作,否则抛出ConcurrentModificationException并发修改异常
小结
增强for循环:
概述:jdk1.5之后提出的一个增强的for循环,底层采用的是迭代器
格式:
for(数据类型 变量名 : 数组名\集合名){
}
注意:增强for循环遍历操作的时候,不能对集合进行增删元素操作,否则会报并发修改异常
增强for循环主要用来遍历数组和集合
总结:
Collection集合的遍历方式: 迭代器,增强for循环
数组的遍历方式: 增强for循环,普通for循环(while)
第三章 泛型
-
集合不使用泛型的时候,存的时候什么类型都能存。但是取的时候就懵逼了。取出来啥也不是。
public class Test1 { public static void main(String[] args) { // 集合不使用泛型的时候,存的时候什么类型都能存。但是取的时候就懵逼了。取出来啥也不是。 // 创建一个单列集合,不指定泛型 Collection col = new ArrayList(); // 往集合中存储元素 col.add("itheima"); col.add("itcast"); col.add(100); col.add(3.14); System.out.println(col);// [itheima, itcast, 100, 3.14] // 取元素 // 需求:打印集合中字符串元素的字符长度 for (Object obj : col) { String str = (String)obj; System.out.println(str.length()); } } } -
使用泛型
- 使用泛型在编译期直接对类型作出了控制,只能存储泛型定义的数据
public class Test2 { public static void main(String[] args) { // 使用泛型在编译期直接对类型作出了控制,只能存储泛型定义的数据 // 创建一个单列集合,不指定泛型 Collection<String> col = new ArrayList<>(); // 往集合中存储元素 col.add("itheima"); col.add("itcast"); //col.add(100);// 编译报错 //col.add(3.14);// 编译报错 System.out.println(col);// [itheima, itcast] // 取元素 // 需求:打印集合中字符串元素的字符长度 for (String s : col) { System.out.println(s.length()); } } } -
泛型:可以在类或方法中预知地使用未知的类型。在使用的时候,确定泛型的具体数据类型
tips:泛型的作用是在创建对象时,将未知的类型确定具体的类型。当没有指定泛型时,默认类型为Object类型。
小结
略
知识点–定义和使用含有泛型的类
目标
- 定义和使用含有泛型的类
路径
- 定义含有泛型的类
- 确定泛型具体类型
讲解
定义含有泛型的类
-
格式:
定义含有泛型的类: public class 类名<泛型变量>{ } 泛型变量: 任意字母,一般会使用E -
案例:
public class MyGenericClass<E> {
// 成员变量
E e;
// 成员方法
public void method1(E e){
System.out.println(e);
}
}
使用含有泛型的类
- 创建泛型类对象的时候,指定泛型的具体数据类型
public class Test {
public static void main(String[] args) {
/*
使用含有泛型的类: 创建泛型类对象的时候,指定泛型的具体数据类型
*/
MyGenericClass<String> mc1 = new MyGenericClass<>();
mc1.e = "itheima";
mc1.method1("itcast");
System.out.println("==========================");
MyGenericClass<Integer> mc2 = new MyGenericClass<>();
mc2.method1(100);
}
}
知识点–定义和使用含有泛型的方法
定义含有泛型的方法
定义格式:
修饰符 <代表泛型的变量> 返回值类型 方法名(参数){ }
泛型变量可以是任意字母,一般会使用T
例如,
// 定义一个含有泛型的方法
public static <T> T method(T t){
System.out.println("method..."+t);
return t;
}
确定泛型具体类型
调用方法时,确定泛型的类型
public class Test {
public static void main(String[] args) {
/*
定义含有泛型的方法:
修饰符 <泛型变量> 返回值类型 方法名(形参列表){方法体}
注意: 泛型变量可以是任意字母,一般使用T
使用含有泛型的方法: 调用方法的时候,指定泛型的具体数据类型
*/
String res1 = method("itheima");
Integer res2 = method(100);
}
// 定义一个含有泛型的方法
public static <T> T method(T t){
System.out.println("method..."+t);
return t;
}
}
知识点–定义和使用含有泛型的接口
定义含有泛型的接口
定义格式:
修饰符 interface 接口名<代表泛型的变量> { }
例如,
public interface MyGenericInterface<E> {
public abstract void method1(E e);
public abstract void method2(E e);
}
确定泛型具体类型
使用格式:
1、定义实现类时确定泛型的类型
public class 类名 implements 接口名<具体的数据类型>{
}
例如
// 实现类实现接口的时候,确定接口泛型的具体数据类型
public class MyImp1 implements MyGenericInterface<String>{
@Override
public void method1(String s) {
System.out.println(s);
}
@Override
public void method2(String s) {
System.out.println(s);
}
}
此时,泛型E的值就是String类型。
2、始终不确定泛型的类型,直到创建对象时,确定泛型的类型
实现类实现接口的时候,不确定接口泛型的具体数据类型,创建实现类对象的时候确定泛型的具体数据类型
public class 类名<泛型变量> implements 接口名<泛型变量>{
}
例如
public class MyImp2<E> implements MyGenericInterface<E> {
@Override
public void method1(E e) {
System.out.println(e);
}
@Override
public void method2(E e) {
System.out.println(e);
}
}
确定泛型:
/*
* 使用
*/
public class GenericInterface {
public static void main(String[] args) {
// 创建实现类对象
MyImp2<String> imp2 = new MyImp2<>();
imp2.method1("java");
// 创建实现类对象
MyImp2<Integer> imp3 = new MyImp2<>();
imp3.method1(100);
}
}
小结
知识点-- 泛型通配符
通配符基本使用
泛型的通配符:不知道使用什么类型来接收的时候,此时可以使用?,?表示泛型通配符。
此时只能接受数据,不能往该集合中存储数据。
例如:
public class Test {
public static void main(String[] args) {
/*
泛型的通配符:不知道使用什么类型来接收的时候,此时可以使用?,?表示泛型通配符。
注意:泛型没有多态
*/
//ArrayList
Collection<Integer> list1 = new ArrayList<Integer>();
getElement(list1);
Collection<String> list2 = new ArrayList<String>();
getElement(list2);
}
public static void getElement(Collection<?> coll){
// 此时只能接受数据,不能往该集合中存储数据。
//coll.add("jack");// 编译报错
//coll.add(100);// 编译报错
for (Object obj : coll) {
System.out.println(obj);
}
}
}
//?代表可以接收任意类型
//泛型不存在继承关系 Collection
通配符高级使用----受限泛型
之前设置泛型的时候,实际上是可以任意设置的,只要是类就可以设置。但是在JAVA的泛型中可以指定一个泛型的上限和下限。
泛型的上限:
- 格式:
- 意义:
只能接收该类型及其子类
泛型的下限:
- 格式:
- 意义:
只能接收该类型及其父类型
比如:现已知Object类,String 类,Number类,Integer类,其中Number是Integer的父类
public class Test {
public static void main(String[] args) {
/*
通配符高级使用:
上限: 说明:只能接收该类类型或者其子类类型
下限: 说明:只能接收该类类型或者其父类类型
*/
// String,Number继承Object类,Integer类继承Number类
Collection<Integer> list1 = new ArrayList<Integer>();
Collection<String> list2 = new ArrayList<String>();
Collection<Number> list3 = new ArrayList<Number>();
Collection<Object> list4 = new ArrayList<Object>();
// getElement1(list1);
// getElement1(list2);// 编译报错
// getElement1(list3);
// getElement1(list4);
// getElement2(list1);
// getElement2(list2);// 编译报错
// getElement2(list3);
// getElement2(list4);// 编译报错
}
// 定义这个方法的形参只能接收list1,list3,list4
public static void getElement1(Collection<? super Integer> coll){
}
// 定义这个方法的形参只能接收list1,list3
public static void getElement2(Collection<? extends Number> coll){
}
}
小结
- ?表示泛型通配符,如果要对?泛型通配符的取值范围进行限制,可以使用泛型限定
第四章 数据结构
知识点-- 数据结构介绍
数据结构 : 其实就是存储数据和表示数据的方式。数据结构内容比较多,细细的学起来也是相对费功夫的,不可能达到一蹴而就。我们将常见的数据结构:堆栈、队列、数组、链表和红黑树 这几种给大家介绍一下,作为数据结构的入门,了解一下它们的特点即可。
小结:
- 数据结构其实就是存储数据和表示数据的方式
- 每种数据结构都有自己的优点和缺点,由于数据结构内容比较多,作为数据结构的入门,了解一下他们的特点即可
知识点-- 常见数据结构
目标:
- 数据存储的常用结构有:栈、队列、数组、链表和红黑树。我们分别来了解一下
步骤:
- 栈结构的特点
- 队列结构的特点
- 数组结构的特点
- 链表结构的特点
讲解:
数据存储的常用结构有:栈、队列、数组、链表和红黑树。我们分别来了解一下:
栈
- 栈:stack,又称堆栈,它是运算受限的线性表,其限制是仅允许在表的一端进行插入和删除操作,不允许在其他任何位置进行添加、查找、删除等操作。
简单的说:采用该结构的集合,对元素的存取有如下的特点
-
先进后出(即,存进去的元素,要在后它后面的元素依次取出后,才能取出该元素)。例如,子弹压进弹夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的子弹。
-
栈的入口、出口的都是栈的顶端位置。

这里两个名词需要注意:
- 压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
- 弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
队列
-
队列:queue,简称队,它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行取出并删除。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
- 先进先出(即,存进去的元素,要在后它前面的元素依次取出后,才能取出该元素)。例如,小火车过山洞,车头先进去,车尾后进去;车头先出来,车尾后出来。
- 队列的入口、出口各占一侧。例如,下图中的左侧为入口,右侧为出口。

数组
- 数组:Array,是有序的元素序列,数组是在内存中开辟一段连续的空间,并在此空间存放元素。就像是一排出租屋,有100个房间,从001到100每个房间都有固定编号,通过编号就可以快速找到租房子的人。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
-
查找元素快:通过索引,可以快速访问指定位置的元素
-
增删元素慢
-
指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。
-

-
**指定索引位置删除元素:**需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位置,原数组中指定索引位置元素不复制到新数组中。
-

链表
-
链表:linked list,由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。我们常说的链表结构有单向链表与双向链表,那么这里给大家介绍的是单向链表。

简单的说,采用该结构的集合,对元素的存取有如下的特点:
-
多个结点之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次类推,这样多个人就连在一起了。
-
查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素。
-
增删元素快:只需要修改链接下一个元素的地址值即可
-
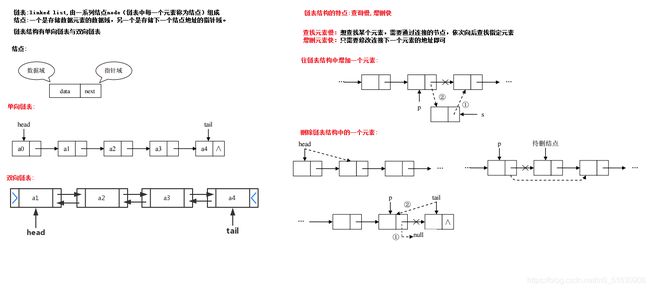
小结:
- 栈结构的特点:先进后出,栈的入口和出口都在栈顶的位置
- 队列结构的特点:先进先出,队列的入口和出口在队列的2侧
- 数组结构的特点:查询快,增删慢
- 链表结构的特点:查询慢,增删快
知识点-- 树基本结构介绍
- 树具有的特点
- 二叉树
- 二叉查找树
- 平衡二叉树
- 红黑树
树具有的特点:
- 每一个节点有零个或者多个子节点
- 没有父节点的节点称之为根节点,一个树最多有一个根节点。
- 每一个非根节点有且只有一个父节点
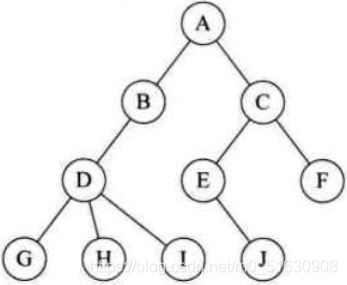
| 名词 | 含义 |
|---|---|
| 节点 | 指树中的一个元素 |
| 节点的度 | 节点拥有的子树的个数,二叉树的度不大于2 |
| 叶子节点 | 度为0的节点,也称之为终端结点 |
| 高度 | 叶子结点的高度为1,叶子结点的父节点高度为2,以此类推,根节点的高度最高 |
| 层 | 根节点在第一层,以此类推 |
| 父节点 | 若一个节点含有子节点,则这个节点称之为其子节点的父节点 |
| 子节点 | 子节点是父节点的下一层节点 |
| 兄弟节点 | 拥有共同父节点的节点互称为兄弟节点 |
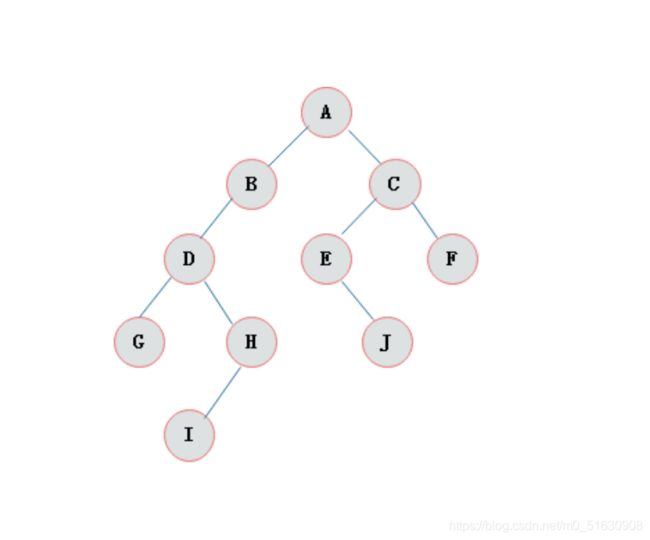
二叉树
如果树中的每个节点的子节点的个数不超过2,那么该树就是一个二叉树。
二叉查找树
二叉查找树的特点:
- 左子树上所有的节点的值均小于等于他的根节点的值
- 右子树上所有的节点值均大于或者等于他的根节点的值
- 每一个子节点最多有两个子树
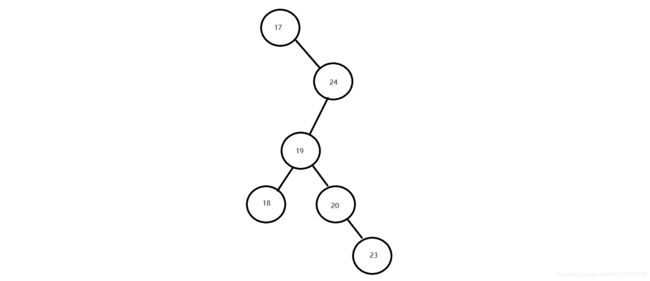
案例演示(20,18,23,22,17,24,19)数据的存储过程;

遍历获取元素的时候可以按照"左中右"的顺序进行遍历;
注意:二叉查找树存在的问题:会出现"瘸子"的现象,影响查询效率
平衡二叉树
概述
为了避免出现"瘸子"的现象,减少树的高度,提高我们的搜素效率,又存在一种树的结构:“平衡二叉树”
规则:它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
如下图所示:
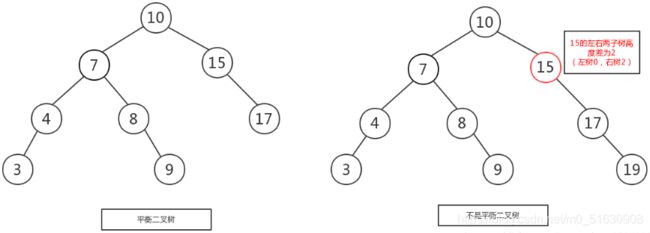
如下图所示,左图是一棵平衡二叉树,根节点10,左右两子树的高度差是1,而右图,虽然根节点左右两子树高度差是0,但是右子树15的左右子树高度差为2,不符合定义,
所以右图不是一棵平衡二叉树。
旋转
在构建一棵平衡二叉树的过程中,当有新的节点要插入时,检查是否因插入后而破坏了树的平衡,如果是,则需要做旋转去改变树的结构。
左旋:
左旋就是将节点的右支往左拉,右子节点变成父节点,并把晋升之后多余的左子节点出让给降级节点的右子节点;
右旋:
将节点的左支往右拉,左子节点变成了父节点,并把晋升之后多余的右子节点出让给降级节点的左子节点

举个例子,像上图是否平衡二叉树的图里面,左图在没插入前"19"节点前,该树还是平衡二叉树,但是在插入"19"后,导致了"15"的左右子树失去了"平衡",
所以此时可以将"15"节点进行左旋,让"15"自身把节点出让给"17"作为"17"的左树,使得"17"节点左右子树平衡,而"15"节点没有子树,左右也平衡了。如下图,

由于在构建平衡二叉树的时候,当有新节点插入时,都会判断插入后时候平衡,这说明了插入新节点前,都是平衡的,也即高度差绝对值不会超过1。当新节点插入后,
有可能会有导致树不平衡,这时候就需要进行调整,而可能出现的情况就有4种,分别称作左左,左右,右左,右右。
左左:只需要做一次右旋就变成了平衡二叉树。
右右:只需要做一次左旋就变成了平衡二叉树。
左右:先做一次分支的左旋,再做一次树的右旋,才能变成平衡二叉树。
右左:先做一次分支的右旋,再做一次树的左旋,才能变成平衡二叉树。
左左
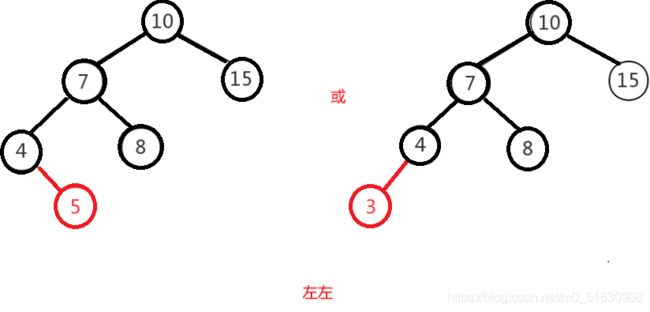
左左:只需要做一次右旋就变成了平衡二叉树。
左左即为在原来平衡的二叉树上,在节点的左子树的左子树下,有新节点插入,导致节点的左右子树的高度差为2,如下即为"10"节点的左子树"7",的左子树"4",插入了节点"5"或"3"导致失衡。
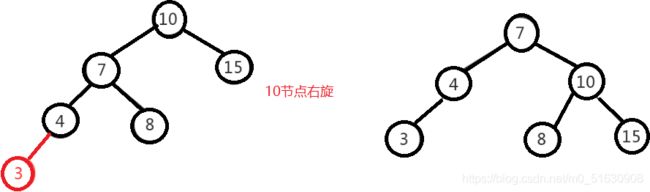
左左调整其实比较简单,只需要对节点进行右旋即可,如下图,对节点"10"进行右旋,

左右
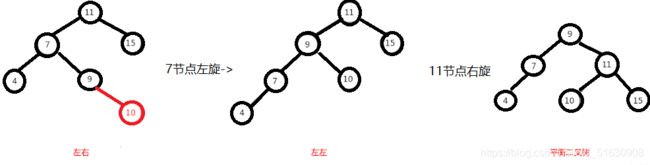
左右:先做一次分支的左旋,再做一次树的右旋,才能变成平衡二叉树。
左右即为在原来平衡的二叉树上,在节点的左子树的右子树下,有新节点插入,导致节点的左右子树的高度差为2,如上即为"11"节点的左子树"7",的右子树"9",
插入了节点"10"或"8"导致失衡。

左右的调整就不能像左左一样,进行一次旋转就完成调整。我们不妨先试着让左右像左左一样对"11"节点进行右旋,结果图如下,右图的二叉树依然不平衡,而右图就是接下来要
讲的右左,即左右跟右左互为镜像,左左跟右右也互为镜像。

左右这种情况,进行一次旋转是不能满足我们的条件的,正确的调整方式是,将左右进行第一次旋转,将左右先调整成左左,然后再对左左进行调整,从而使得二叉树平衡。
即先对上图的节点"7"进行左旋,使得二叉树变成了左左,之后再对"11"节点进行右旋,此时二叉树就调整完成,如下图:
右左
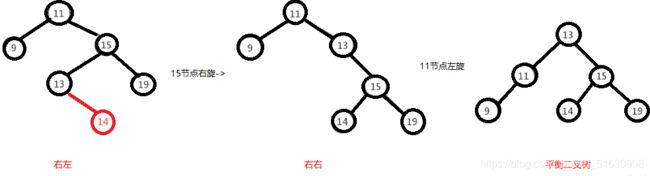
右左:先做一次分支的右旋,再做一次树的左旋,才能变成平衡二叉树。
右左即为在原来平衡的二叉树上,在节点的右子树的左子树下,有新节点插入,导致节点的左右子树的高度差为2,如上即为"11"节点的右子树"15",的左子树"13",
插入了节点"12"或"14"导致失衡。

前面也说了,右左跟左右其实互为镜像,所以调整过程就反过来,先对节点"15"进行右旋,使得二叉树变成右右,之后再对"11"节点进行左旋,此时二叉树就调整完成,如下图:
右右
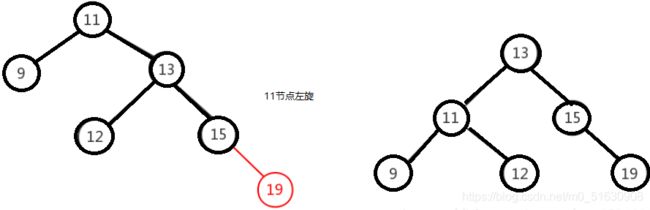
右右:只需要做一次左旋就变成了平衡二叉树。
右右即为在原来平衡的二叉树上,在节点的右子树的右子树下,有新节点插入,导致节点的左右子树的高度差为2,如下即为"11"节点的右子树"13",的左子树"15",插入了节点
"14"或"19"导致失衡。

右右只需对节点进行一次左旋即可调整平衡,如下图,对"11"节点进行左旋。
红黑树
红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构,它是在1972年由Rudolf Bayer发明的,当时被称之为平衡二叉B树,后来,在1978年被
Leoj.Guibas和Robert Sedgewick修改为如今的"红黑树"。它是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色,可以是红或者黑;
红黑树不是高度平衡的,它的平衡是通过"红黑树的特性"进行实现的;
红黑树的特性:
- 每一个节点或是红色的,或者是黑色的。
- 根节点必须是黑色
- 每个叶节点(Nil)是黑色的;(如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点)
- 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点;
如下图所示就是一个

在进行元素插入的时候,和之前一样; 每一次插入完毕以后,使用黑色规则进行校验,如果不满足红黑规则,就需要通过变色,左旋和右旋来调整树,使其满足红黑规则;
第五章 List接口
知识点-- List接口介绍
目标:
-
我们掌握了Collection接口的使用后,再来看看Collection接口中的子类,他们都具备那些特性呢?
接下来,我们一起学习Collection中的常用几个子类(
java.util.List集合、java.util.Set集合)。
路径:
- List接口的概述
- List接口的特点
List接口的概述
java.util.List接口继承自Collection接口,是单列集合的一个重要分支,习惯性地会将实现了List接口的对象称为List集合。
List接口特点
- 它是一个元素存取有序的集合。例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)。
- 它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
- 集合中可以有重复的元素。
tips:我们在基础班的时候已经学习过List接口的子类java.util.ArrayList类,该类中的方法都是来自List中定义。
知识点-- List接口中常用方法
List接口新增常用方法
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法,如下:
public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。public E get(int index):返回集合中指定位置的元素。public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
List集合特有的方法都是跟索引相关,我们在基础班都学习过。
List接口新增常用方法的使用
public class Test {
public static void main(String[] args) {
// 创建List集合,限制集合中元素的类型为String类型
List<String> list = new ArrayList<>();
// 往集合中添加元素
list.add("刘德华");
list.add("张学友");
list.add("黎明");
list.add("郭富城");
// - public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。
list.add(1, "古天乐");
System.out.println("list:" + list);// [刘德华, 古天乐, 张学友, 黎明, 郭富城]
// - public E get(int index):返回集合中指定位置的元素。
String e = list.get(1);
System.out.println("索引为1的元素:" + e);// 古天乐
// - public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。
String removeE = list.remove(1);
System.out.println("被删除的元素:"+removeE);// 古天乐
System.out.println("list:" + list);// [刘德华, 张学友, 黎明, 郭富城]
// - public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
String setE = list.set(1, "古天乐");
System.out.println("被修改的元素:"+setE);// 张学友
System.out.println("list:" + list);// [刘德华, 古天乐, 黎明, 郭富城]
}
}
- ArrayList集合
- LinkedList集合
- LinkedList源码分析
讲解:
ArrayList集合
java.util.ArrayList集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。
许多程序员开发时非常随意地使用ArrayList完成任何需求,并不严谨,这种用法是不提倡的。
LinkedList集合
java.util.LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合。
LinkedList是一个双向链表,那么双向链表是什么样子的呢,我们用个图了解下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I2v9CqCO-1605615110798)(img/1586798520302.png)]
实际开发中对一个集合元素的添加与删除经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法。这些方法我们作为了解即可:
public void addFirst(E e):将指定元素插入此列表的开头。public void addLast(E e):将指定元素添加到此列表的结尾。public E getFirst():返回此列表的第一个元素。public E getLast():返回此列表的最后一个元素。public E removeFirst():移除并返回此列表的第一个元素。public E removeLast():移除并返回此列表的最后一个元素。public E pop():从此列表所表示的堆栈处弹出一个元素。public void push(E e):将元素推入此列表所表示的堆栈。
LinkedList是List的子类,List中的方法LinkedList都是可以使用,这里就不做详细介绍,我们只需要了解LinkedList的特有方法即可。在开发时,LinkedList集合也可以作为堆栈,队列的结构使用。
public class Test {
public static void main(String[] args) {
// 创建LinkedList集合,限制集合中元素的类型为String
LinkedList<String> list = new LinkedList<>();
// 往集合中添加元素
list.add("刘德华");
list.add("张学友");
list.add("黎明");
list.add("郭富城");
// - public void addFirst(E e):将指定元素插入此列表的开头。
list.addFirst("古天乐");
// - public void addLast(E e):将指定元素添加到此列表的结尾。
list.addLast("梁朝伟");
System.out.println("list:"+list);// [古天乐, 刘德华, 张学友, 黎明, 郭富城, 梁朝伟]
// - public E getFirst():返回此列表的第一个元素。
String firstE = list.getFirst();
System.out.println("list集合的第一个元素:"+firstE);// 古天乐
// - public E getLast():返回此列表的最后一个元素。
String lastE = list.getLast();
System.out.println("list集合的最后一个元素:"+lastE);// 梁朝伟
// - public E removeFirst():移除并返回此列表的第一个元素。
String e1 = list.removeFirst();
System.out.println("被删除的第一个元素:"+e1);// 古天乐
// - public E removeLast():移除并返回此列表的最后一个元素。
String e2 = list.removeLast();
System.out.println("被删除的最后一个元素:"+e2);// 梁朝伟
System.out.println("list:"+list);// [刘德华, 张学友, 黎明, 郭富城]
// - public E pop():从此列表所表示的堆栈处弹出一个元素。相当于removeFirst()方法
String pop = list.pop();
System.out.println("被删除的第一个元素:"+pop);// 刘德华
System.out.println("list:"+list);// [张学友, 黎明, 郭富城]
// - public void push(E e):将元素推入此列表所表示的堆栈。相当于addFirst()方法
list.push("刘德华");
System.out.println("list:"+list);// [刘德华, 张学友, 黎明, 郭富城]
}
}
案例—集合综合案例
需求:
-
按照斗地主的规则,完成洗牌发牌的动作。
具体规则:使用54张牌打乱顺序,三个玩家参与游戏,三人交替摸牌,每人17张牌,最后三张留作底牌。
分析:
-
准备牌:
牌可以设计为一个ArrayList,每个字符串为一张牌。
每张牌由花色数字两部分组成,我们可以使用花色集合与数字集合嵌套迭代完成每张牌的组装。
牌由Collections类的shuffle方法进行随机排序。 -
发牌
将每个人以及底牌设计为ArrayList,将最后3张牌直接存放于底牌,剩余牌通过对3取模依次发牌。
-
看牌
直接打印每个集合。
实现:
package com.itheima.demo13_集合综合案例;
import java.util.ArrayList;
import java.util.Collections;
public class Test {
public static void main(String[] args) {
// 1.造牌:
// 1.1 创建一个扑克盒单列集合,用来存储54张牌
ArrayList<String> pokeBox = new ArrayList<>();
// 1.2 创建一个花色的单列集合,用来存储4种花色
ArrayList<String> colors = new ArrayList<>();
// 1.3 创建一个牌面值的单列集合,用来存储13个牌面值
ArrayList<String> numbers = new ArrayList<>();
// 1.4 往花色集合中添加4个花色
colors.add("♠");
colors.add("♥");
colors.add("♣");
colors.add("♦");
// 1.5 往牌面值集合中添加13个牌面值
for (int i = 2; i <= 10; i++) {
numbers.add(i + "");
}
numbers.add("J");
numbers.add("Q");
numbers.add("K");
numbers.add("A");
// 1.6 往扑克盒集合中添加大王,小王
pokeBox.add("大王");
pokeBox.add("小王");
// 1.7 花色集合和牌面值集合循环嵌套,生成牌,添加到扑克盒集合中
for (String number : numbers) {
for (String color : colors) {
// 造牌
String pai = color + number;
// 添加到扑克盒集合中
pokeBox.add(pai);
}
}
System.out.println("扑克牌:" + pokeBox);
System.out.println("扑克牌:" + pokeBox.size());
// 2.洗牌
// Collections.shuffle(List list);随机打乱传入的list集合元素的顺序
Collections.shuffle(pokeBox);
System.out.println("扑克牌:" + pokeBox);
System.out.println("扑克牌:" + pokeBox.size());
// 3.发牌:
// 3.1 创建4个单列集合,分别用来存储玩家1,玩家2,玩家3,底牌的牌
ArrayList<String> player1 = new ArrayList<>();
ArrayList<String> player2 = new ArrayList<>();
ArrayList<String> player3 = new ArrayList<>();
ArrayList<String> diPai = new ArrayList<>();
// 3.2 普通for循环遍历扑克盒集合
for (int i = 0; i < pokeBox.size(); i++) {
// 获取牌
String pai = pokeBox.get(i);
// 3.3 在循环中,判断遍历出来的元素
if (i >= 51) {
// 3.4 如果元素的索引>=51,该元素(牌)给底牌
diPai.add(pai);
} else if (i % 3 == 0) {
// 3.4 如果元素的索引%3==0,该元素(牌)给玩家1
player1.add(pai);
} else if (i % 3 == 1) {
// 3.4 如果元素的索引%3==1,该元素(牌)给玩家2
player2.add(pai);
} else {
// 3.4 如果元素的索引%3==2,该元素(牌)给玩家3
player3.add(pai);
}
}
// 3.5 展示牌
System.out.println("玩家1:"+player1+" 牌数:"+player1.size());
System.out.println("玩家2:"+player2+" 牌数:"+player2.size());
System.out.println("玩家3:"+player3+" 牌数:"+player3.size());
System.out.println("底牌:"+diPai);
}
}
第六章 Collections类
知识点-- Collections常用功能
讲解
-
java.utils.Collections是集合工具类,用来对集合进行操作。常用方法如下:
-
public static void shuffle(List list):打乱集合顺序。 -
public static:将集合中元素按照默认规则排序。void sort(List list) -
public static:将集合中元素按照指定规则排序。void sort(List list,Comparator )
代码演示:
package com.itheima.demo1_Collections工具类;
public class Student implements Comparable<Student>{
public String name;
public int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Student o) {
/*
事先写好排序规则:
前减后 升序
后减前 降序
前:this 后:参数o
*/
// eg:指定按照年龄升序排序
return this.age - o.age;
}
}
package com.itheima.demo1_Collections工具类;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* @Author: pengzhilin
* @Date: 2020/11/3 8:38
*/
public class Test {
public static void main(String[] args) {
// 创建List集合,限制集合中元素的类型为Integer类型
List<Integer> list = new ArrayList<>();
// 往集合中添加元素
list.add(100);
list.add(200);
list.add(300);
list.add(400);
list.add(500);
System.out.println("打乱顺序之前的集合:"+list);
// 打乱顺序
Collections.shuffle(list);
System.out.println("打乱顺序之后的集合:"+list);
System.out.println("====================================");
// 创建List集合,限制集合中元素的类型为Integer类型
List<Integer> list1 = new ArrayList<>();
// 往集合中添加元素
list1.add(500);
list1.add(200);
list1.add(300);
list1.add(400);
list1.add(100);
System.out.println("排序之前的集合:"+list1);
// 按照默认规则排序
Collections.sort(list1);
System.out.println("排序之后的集合:"+list1);
System.out.println("====================================");
// 创建List集合,限制集合中元素的类型为Student类型
List<Student> list2 = new ArrayList<>();
// 往集合中添加元素
Student stu1 = new Student("张三",18);
Student stu2 = new Student("李四",38);
Student stu3 = new Student("王五",28);
Student stu4 = new Student("赵六",48);
list2.add(stu1);
list2.add(stu2);
list2.add(stu3);
list2.add(stu4);
System.out.println("排序之前的集合:"+list2);
// 按照默认规则排序
Collections.sort(list2);
System.out.println("排序之后的集合:"+list2);
}
}
我们的集合按照默认的自然顺序进行了排列,如果想要指定顺序那该怎么办呢?
小结
- java.utils.Collections是集合工具类,用来对集合进行操作。
常用方法如下:
- public static void shuffle(List<?> list):打乱集合顺序。
- public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。
默认规则: 事先写好的规则
默认规则排序: 要求集合元素所属的类必须实现Comparable接口,重写compareTo方法,在该方法中事先写好排序规则
知识点-- Comparator比较器
public class Test {
public static void main(String[] args) {
// 创建List集合,限制集合中元素的类型为Integer类型
List<Integer> list1 = new ArrayList<>();
// 往集合中添加元素
list1.add(500);
list1.add(200);
list1.add(300);
list1.add(400);
list1.add(100);
System.out.println("排序之前的集合:" + list1);
// 按照指定规则排序--->(降序)
Collections.sort(list1, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
// 指定排序规则: 前减后升序,后减前降序
// 前: 参数1 后:参数2
return o2 - o1;
}
});
System.out.println("排序之后的集合:" + list1);
// 按照指定规则排序--->(升序序)
Collections.sort(list1, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
// 指定排序规则: 前减后升序,后减前降序
// 前: 参数1 后:参数2
return o1 - o2;
}
});
System.out.println("排序之后的集合:" + list1);
System.out.println("=========================================");
// 创建List集合,限制集合中元素的类型为Student类型
List<Student> list2 = new ArrayList<>();
// 往集合中添加元素
Student stu1 = new Student("赵丽颖", 18);
Student stu2 = new Student("杨紫", 38);
Student stu3 = new Student("迪丽热巴", 28);
Student stu4 = new Student("杨颖", 48);
list2.add(stu1);
list2.add(stu2);
list2.add(stu3);
list2.add(stu4);
System.out.println("排序之前的集合:" + list2);
// 按照年龄降序排序
Collections.sort(list2, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o2.age - o1.age;
}
});
System.out.println("排序之后的集合:" + list2);
// 按照姓名长度降序排序
Collections.sort(list2, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o2.name.length() - o1.name.length();
}
});
System.out.println("排序之后的集合:" + list2);
System.out.println("================================");
// 需求:先按照姓名长度降序排序,如果姓名长度相同,按照年龄升序排序
Collections.sort(list2, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
// 如果姓名长度不相等
if (o1.name.length() != o2.name.length()) {
return o2.name.length() - o1.name.length();
} else {
// 如果姓名长度相等
return o1.age - o2.age;
}
}
});
System.out.println("排序之后的集合:" + list2);
}
}
小结
public static <T> void sort(List<T> list,Comparator<? super T> comp):将集合中元素按照指定规则排序。
指定规则: 通过参数Comparator接口指定排序规则
知识点-- 可变参数
- 可变参数的使用
- 注意事项
- 应用场景: Collections
可变参数的使用
在JDK1.5之后,如果我们定义一个方法需要接受多个参数,并且多个参数类型一致,我们可以对其简化.
格式:
修饰符 返回值类型 方法名(参数类型... 形参名){ }
代码演示:
package com.itheima.demo3_可变参数;
public class Test {
public static void main(String[] args) {
/*
*/
method1(10,20,30,40,50);
int[] arr = {
10,20,30,40,50};
//method2(arr);
//method3();
//method3(arr);
//method3(10,20,30,40);
//method3(10,20,30,40,50);
//method3(10,20,30,40,50,60);
//method4("itheima");
//method4("itheima",100);
//method4("itheima",100,200);
}
public static void method4(String str,int... nums){
}
// eg:定义一个方法,该方法需要接收5个int类型的数(jdk1.5)
public static void method3(int... nums){
for (int i = 0; i < nums.length; i++) {
System.out.println(nums[i]);
}
}
public static void method2(int[] nums){
for (int i = 0; i < nums.length; i++) {
System.out.println(nums[i]);
}
}
// eg:定义一个方法,该方法需要接收5个int类型的数(以前)
public static void method1(int num1,int num2,int num3,int num4,int num5){
}
}
注意事项
1.一个方法只能有一个可变参数
2.如果方法中有多个参数,可变参数要放到最后。
应用场景: Collections
在Collections中也提供了添加一些元素方法:
public static :往集合中添加一些元素。
代码演示:
public class CollectionsDemo {
public static void main(String[] args) {
// 创建ArrayList集合,限制集合中的元素为String类型
ArrayList<String> list = new ArrayList<>();
// 往集合中添加一些元素(13个牌面值)
Collections.addAll(list,"2","A","K","Q","J","10","9","8","7","6","5","4","3");
System.out.println(list);
}
}
小结
可变参数:
格式: 修饰符 返回值类型 方法名(参数类型... 形参名){
}
作用: 如果我们定义一个方法需要接受多个参数,并且多个参数类型一致,我们就可以使用可变参数对其简化.
注意事项:
1.一个方法只能有一个可变参数
2.方法中的可变参数一定要放在末尾
使用场景:
public static <T> boolean addAll(Collection<T> c, T... elements):往集合中添加一些元素。
第七章 Set接口
知识点–Set接口介绍
目标
- Set接口介绍
路径
- Set接口
讲解
Set接口:也称Set集合,是单列集合,继承了Collection接口,所以拥有了Collection中的所有方法
特点:元素无索引,元素不可重复(唯一)
实现类:
HashSet类: 元素存取无序,元素无索引,元素不可重复(唯一)
底层采用的是哈希表结构存储数据,由哈希表保证元素唯一
LinkedHashSet类:元素存取有序,元素无索引,元素不可重复(唯一)
底层采用的是链表+哈希表结构存储数据,由哈希表保证元素唯一,由链表保证元素存取有序
TreeSet类:可以对元素进行排序,元素无索引,元素不可重复(唯一)
底层采用的是二叉树结构存储数据,从而保证元素唯一
注意:
Set集合没有特殊的方法,都是使用Collection集合中的方法
Set集合遍历只能使用迭代器,或者增强for循环
知识点–HashSet集合
讲解
java.util.HashSet是Set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不能保证不一致)。
我们先来使用一下Set集合存储,看下现象,再进行原理的讲解:
public class Test {
public static void main(String[] args) {
/*
HashSet类: 元素存取无序,元素无索引,元素不可重复(唯一)
*/
// 创建HashSet集合,限制集合中元素的类型为String类型
HashSet<String> set = new HashSet<>();
// 往集合中添加元素
set.add("nba");
set.add("cba");
set.add("bac");
set.add("abc");
set.add("nba");
System.out.println(set);// [cba, abc, bac, nba]
}
}
知识点–HashSet集合存储数据的结构(哈希表)
-
哈希表底层结构以及HashSet保证元素唯一原理
-
哈希表底层结构
-
HashSet保证元素唯一原理
哈希表底层结构
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用数组处理冲突,同一hash值的链表都存储在一个数组里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gxIAFIfe-1605617452410)(img\1587659262084.png)]
HashSet保证元素唯一原理
HashSet集合保证元素唯一的原理:底层是哈希表结构,哈希表保证元素唯一依赖于hashCode()和equals方法();
1.当HashSet集合存储元素的时候,就会调用该元素的hashCode()方法计算哈希值
2.判断该哈希值对应的位置上,是否有相同哈希值的元素
3.如果该哈希值对应的位置上没有相同哈希值的元素,那么就直接存储
4.如果该哈希值对应的位置上有相同哈希值的元素,那么就产生了哈希冲突
5.如果产生了哈希冲突,就得调用该元素的equals()方法与该哈希值位置上的所有元素进行一一比较:
如果该哈希值位置上有任意一个元素与该元素相等,那么就不存储
如果该哈希值位置上所有元素与该元素都不相等,那么就直接存储
补充:
Object类: hashCode()和equals()方法;
hashCode():Object类中的hashCode()方法是根据地址值计算哈希值
equals方法():Object类中的equals()方法是比较地址值
public class Demo {
public static void main(String[] args) {
// 创建一个HashSet集合,限制集合中元素的类型为String
HashSet<String> set = new HashSet<>();
// 往集合中添加一些元素
set.add("nba");
set.add("cba");
set.add("bac");
set.add("abc");
set.add("nba");
// 遍历打印集合
for (String e : set) {
System.out.println(e);// cba abc bac nba
}
System.out.println("nba".hashCode());// nba:108845
System.out.println("cba".hashCode());// cba:98274
System.out.println("bac".hashCode());// bac:97284
System.out.println("abc".hashCode());// abc:96354
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3cAUqb9P-1605617452418)(img\image-20201103102035017.png)]
小结
略
扩展 HashSet的源码分析
3.4.1 HashSet的成员属性及构造方法
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable{
//内部一个HashMap——HashSet内部实际上是用HashMap实现的
private transient HashMap<E,Object> map;
// 用于做map的值
private static final Object PRESENT = new Object();
/**
* 构造一个新的HashSet,
* 内部实际上是构造了一个HashMap
*/
public HashSet() {
map = new HashMap<>();
}
}
- 通过构造方法可以看出,HashSet构造时,实际上是构造一个HashMap
3.4.2 HashSet的add方法源码解析
public class HashSet{
//......
public boolean add(E e) {
return map.put(e, PRESENT)==null;//内部实际上添加到map中,键:要添加的对象,值:Object对象
}
//......
}
3.4.3 HashMap的put方法源码解析
public class HashMap{
//......
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//......
static final int hash(Object key) {
//根据参数,产生一个哈希值
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//......
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; //临时变量,存储"哈希表"——由此可见,哈希表是一个Node[]数组
Node<K,V> p;//临时变量,用于存储从"哈希表"中获取的Node
int n, i;//n存储哈希表长度;i存储哈希表索引
if ((tab = table) == null || (n = tab.length) == 0)//判断当前是否还没有生成哈希表
n = (tab = resize()).length;//resize()方法用于生成一个哈希表,默认长度:16,赋给n
if ((p = tab[i = (n - 1) & hash]) == null)//(n-1)&hash等效于hash % n,转换为数组索引
tab[i] = newNode(hash, key, value, null);//此位置没有元素,直接存储
else {
//否则此位置已经有元素了
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))//判断哈希值和equals
e = p;//将哈希表中的元素存储为e
else if (p instanceof TreeNode)//判断是否为"树"结构
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//排除以上两种情况,将其存为新的Node节点
for (int binCount = 0; ; ++binCount) {
//遍历链表
if ((e = p.next) == null) {
//找到最后一个节点
p.next = newNode(hash, key, value, null);//产生一个新节点,赋值到链表
if (binCount >= TREEIFY_THRESHOLD - 1) //判断链表长度是否大于了8
treeifyBin(tab, hash);//树形化
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))//跟当前变量的元素比较,如果hashCode相同,equals也相同
break;//结束循环
p = e;//将p设为当前遍历的Node节点
}
}
if (e != null) {
// 如果存在此键
V oldValue = e.value;//取出value
if (!onlyIfAbsent || oldValue == null)
e.value = value;//设置为新value
afterNodeAccess(e);//空方法,什么都不做
return oldValue;//返回旧值
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
}
知识点-- HashSet存储自定义类型元素
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一.
public class Person{
/**
* 姓名
*/
public String name;
/**
* 年龄
*/
public int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
创建测试类:
public class Demo {
public static void main(String[] args) {
// 创建多个Person对象
Person p1 = new Person("张三", 18);
Person p2 = new Person("李四", 38);
Person p3 = new Person("王五", 28);
Person p4 = new Person("张三", 18);
// 创建HashSet集合对象,限制集合中元素的类型为Person
HashSet<Person> set = new HashSet<>();
// 往集合中添加Person对象
set.add(p1);
set.add(p2);
set.add(p3);
set.add(p4);
// 遍历打印集合中的元素
for (Person p : set) {
System.out.println(p);
}
System.out.println(p1.hashCode());
System.out.println(p2.hashCode());
System.out.println(p3.hashCode());
System.out.println(p4.hashCode());
}
}
知识点-- LinkedHashSet
我们知道HashSet保证元素唯一,可是元素存放进去是没有顺序的,那么我们要保证有序,怎么办呢?
在HashSet下面有一个子类java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。
演示代码如下:
public class Test {
public static void main(String[] args) {
/*
LinkedHashSet: 元素存取有序,元素无索引,元素唯一
底层采用的是链表+哈希表结构存储数据,由哈希表保证元素唯一,由链表保证元素存取有序
*/
// 创建LinkedHashSet集合,限制集合中元素的类型为String
LinkedHashSet<String> set = new LinkedHashSet<>();
// 往集合中添加元素
set.add("nba");
set.add("cba");
set.add("bac");
set.add("abc");
set.add("nba");
System.out.println(set);// [nba, cba, bac, abc]
// set集合遍历只能使用迭代器,或者增强for循环
for (String s : set) {
System.out.println(s);
}
}
}
- 知道使用TreeSet集合的特点并能够使用TreeSet集合
特点
TreeSet集合是Set接口的一个实现类,底层依赖于TreeMap,是一种基于红黑树的实现,其特点为:
- 元素唯一
- 元素没有索引
- 使用元素的自然顺序对元素进行排序,或者根据创建 TreeSet 时提供的
Comparator比较器
进行排序,具体取决于使用的构造方法:
public TreeSet(): 根据其元素的自然排序进行排序
public TreeSet(Comparator<E> comparator): 根据指定的比较器进行排序
演示
案例演示自然排序(20,18,23,22,17,24,19):
public static void main(String[] args) {
//无参构造,默认使用元素的自然顺序进行排序
TreeSet<Integer> set = new TreeSet<Integer>();
set.add(20);
set.add(18);
set.add(23);
set.add(22);
set.add(17);
set.add(24);
set.add(19);
System.out.println(set);
}
控制台的输出结果为:
[17, 18, 19, 20, 22, 23, 24]
案例演示比较器排序(20,18,23,22,17,24,19):
public static void main(String[] args) {
//有参构造,传入比较器,使用比较器对元素进行排序
TreeSet<Integer> set = new TreeSet<Integer>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
//元素前 - 元素后 : 升序
//元素后 - 元素前 : 降序
return o2 - o1;
}
});
set.add(20);
set.add(18);
set.add(23);
set.add(22);
set.add(17);
set.add(24);
set.add(19);
System.out.println(set);
}
控制台的输出结果为:
[24, 23, 22, 20, 19, 18, 17]
小结
略
第八章 Map集合
知识点-- Map概述
Map<K,V>接口:也称为双列集合,是所有双列集合的顶层父接口,所以在该接口中定义了所有双列集合共有的方法.
K:限制键的类型 V:限制值的类型
特点:
1.Map集合是以键值对的形式存储数据
2.Map集合的键是唯一的,值可以重复,如果键重复了,那么值就会覆盖
3.Map集合是根据键取值
实现类:键唯一,值可以重复,如果键重复了,那么值就会覆盖
HashMap集合: 键值对存取无序,底层采用的是哈希表存储结构
LinkedHashMap集合: 键值对存取有序,底层采用的是链表+哈希表存储结构
TreeMap集合: 可以对键进行排序,从而对键值对排序,底层采用的是二叉树存储结构
知识点-- Map的常用方法
Map接口中定义了很多方法,常用的如下:
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。public V get(Object key)根据指定的键,在Map集合中获取对应的值。public boolean containsKey(Object key):判断该集合中是否有此键public Set: 获取Map集合中所有的键,存储到Set集合中。keySet() public Set: 获取到Map集合中所有的键值对对象的集合(Set集合)。
Map接口的方法演示
public class Test {
public static void main(String[] args) {
/*
Map的常用方法:
- public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。添加\修改
- public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。
- public V get(Object key) 根据指定的键,在Map集合中获取对应的值。
- public boolean containsKey(Object key):判断该集合中是否有此键
- public boolean containsValue(Object value):判断该集合中是否有此值
- public Set keySet(): 获取Map集合中所有的键,存储到Set集合中。
- public Collection values(): 获取Map集合中所有的值,存储到Collection集合中。
- public Set> entrySet(): 获取到Map集合中所有的 键值对对象 的集合(Set集合)。
Entry: 表示键值对对象,由于Entry是Map的内部接口,所以Map.Entry
*/
// 创建Map集合,限制集合中的键和值的类型都为String类型
Map<String,String> map = new HashMap<>();
// 增删改查的方法:
// 添加键值对到集合中
map.put("黄晓明","杨颖");
map.put("文章", "马伊琍");
map.put("谢霆锋", "王菲");
System.out.println(map);// {文章=马伊琍, 谢霆锋=王菲, 黄晓明=杨颖}
// 修改
String putE = map.put("文章", "姚笛");
System.out.println("被替换的值:"+putE);// 马伊琍
System.out.println(map);// {文章=姚笛, 谢霆锋=王菲, 黄晓明=杨颖}
// 删除文章这个键对应的键值对
String v1 = map.remove("文章");
System.out.println("被删除的键值对的值:"+v1);// 姚笛
System.out.println(map);// {谢霆锋=王菲, 黄晓明=杨颖}
// 查询:获取黄晓明这个键对应的值
String v2 = map.get("黄晓明");
System.out.println("黄晓明这个键对应的值:"+v2);// 杨颖
System.out.println("========================================================");
// 判断的方法:
boolean res1 = map.containsKey("文章");
boolean res2 = map.containsKey("黄晓明");
System.out.println("文章这个键是否存在:"+res1);// false
System.out.println("黄晓明这个键是否存在:"+res2);// true
boolean res3 = map.containsValue("马伊琍");
boolean res4 = map.containsValue("杨颖");
System.out.println("马伊琍这个值是否存在:"+res3);// false
System.out.println("杨颖这个值是否存在:"+res4);// true
System.out.println("========================================================");
// 获取功能的方法
Set<String> keys = map.keySet();
System.out.println("所有的键:"+keys);// 所有的键:[谢霆锋, 黄晓明]
Collection<String> values = map.values();
System.out.println("所有的值:"+values);// 所有的值:[王菲, 杨颖]
// 获取所有的键值对对象
Set<Map.Entry<String, String>> entrys = map.entrySet();
for (Map.Entry<String, String> entry : entrys) {
System.out.println(entry);
}
}
}
tips:
使用put方法时,若指定的键(key)在集合中没有,则没有这个键对应的值,返回null,并把指定的键值添加到集合中;
若指定的键(key)在集合中存在,则返回值为集合中键对应的值(该值为替换前的值),并把指定键所对应的值,替换成指定的新值。
知识点–Map的遍历
方式1:键找值方式
通过元素中的键,获取键所对应的值
分析步骤:
- 获取Map中所有的键,由于键是唯一的,所以返回一个Set集合存储所有的键。方法提示:
keyset() - 遍历键的Set集合,得到每一个键。
- 根据键,获取键所对应的值。方法提示:
get(K key)
public class Demo {
public static void main(String[] args) {
// 创建Map集合对象,限制键的类型为String,值的类型为String
Map<String, String> map = new HashMap<>();
// 往map集合中添加键值对
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("谢霆锋", "王菲");
// 遍历map集合
// 获取集合中所有的键 Set keySet()方法
Set<String> keys = map.keySet();
// 遍历所有的键的集合
for (String key : keys) {
// 在循环中,根据键找值 V get(K key)方法
String value = map.get(key);
System.out.println("键:"+key+",值:"+value);
}
}
}
方式2:键值对方式
Entry接口:简称Entry项,表示键值对对象,用来封装Map集合中的键值对
Entry接口:是Map接口中的内部接口,在外部使用的时候是这样表示: Map.Entry
Map集合中提供了一个方法来获取所有键值对对象:
public Set> entrySet()
根据键值对对对象获取键和值:
- public K getKey():获取Entry对象中的键。
- public V getValue():获取Entry对象中的值。
Map遍历方式二:根据键值对对象的方式
1.获取集合中所有键值对对象,以Set集合形式返回。 Set> entrySet()
2.遍历所有键值对对象的集合,得到每一个键值对(Entry)对象。
3.在循环中,可以使用键值对对对象获取键和值 getKey()和getValue()
public class Demo {
public static void main(String[] args) {
// 创建Map集合对象,限制键的类型为String,值的类型为String
Map<String, String> map = new HashMap<>();
// 往map集合中添加键值对
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("谢霆锋", "王菲");
// 获取集合中所有键值对对象 Set> entrySet()
Set<Map.Entry<String, String>> entrySet = map.entrySet();
// 遍历所有键值对对象的集合
for (Map.Entry<String, String> entry : entrySet) {
// 在循环中,可以使用键值对对对象获取键和值 getKey()和getValue()
String key = entry.getKey();
String value = entry.getValue();
System.out.println("键:"+key+",值:"+value);
}
}
}
知识点-- HashMap存储自定义类型
练习:每位学生(姓名,年龄)都有自己的家庭住址。那么,既然有对应关系,则将学生对象和家庭住址存储到map集合中。学生作为键, 家庭住址作为值。
注意,学生姓名相同并且年龄相同视为同一名学生。
编写学生类:
public class Student {
public String name;
public int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
编写测试类:
package com.itheima.demo10_HashMap存储自定义类型;
import java.util.HashMap;
import java.util.Set;
/**
* @Author: pengzhilin
* @Date: 2020/11/3 12:07
*/
public class Test {
public static void main(String[] args) {
/*
实现类:键唯一,值可以重复,如果键重复了,那么值就会覆盖
HashMap集合: 键值对存取无序,底层采用的是哈希表存储结构,由哈希表保证键唯一
结论:如果键是自定义类型,那么该键所属类要重写hashCode和equals方法
练习:每位学生(姓名,年龄)都有自己的家庭住址。
那么,既然有对应关系,则将学生对象和家庭住址存储到map集合中。学生作为键, 家庭住址作为值。
注意,学生姓名相同并且年龄相同视为同一名学生。
*/
// 创建HashMap集合,限制集合中键的类型为Student,值的类型为String
HashMap<Student,String> map = new HashMap<>();
// 添加键值对到集合中
Student stu1 = new Student("张三", 18);
Student stu2 = new Student("李四", 38);
Student stu3 = new Student("王五", 28);
Student stu4 = new Student("赵六", 48);
Student stu5 = new Student("张三", 18);
map.put(stu1, "深圳");
map.put(stu2, "北京");
map.put(stu3, "上海");
map.put(stu4, "广州");
map.put(stu5, "香港");
// 获取map集合所有的键
Set<Student> keys = map.keySet();
// 循环遍历所有的键
for (Student key : keys) {
// 根据键找值
String value = map.get(key);
System.out.println(key+"="+value);
}
}
}
- 当给HashMap中存放自定义对象时,如果自定义对象作为key存在,这时要保证对象唯一,必须复写对象的hashCode和equals方法(如果忘记,请回顾HashSet存放自定义对象)。
- 如果要保证map中存放的key和取出的顺序一致,可以使用
java.util.LinkedHashMap集合来存放。
知识点–LinkedHashMap介绍
目标
- 我们知道HashMap保证成对元素唯一,并且查询速度很快,可是成对元素存放进去是没有顺序的,那么我们要保证有序,还要速度快怎么办呢?
路径
- LinkedHashMap
讲解
- 通过链表结构可以保证元素的存取顺序一致;
- 通过哈希表结构可以保证的键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
public class Test {
public static void main(String[] args) {
/*
实现类:键唯一,值可以重复,如果键重复了,那么值就会覆盖
LinkedHashMap集合: 键值对存取有序,底层采用的是链表+哈希表存储结构,
由哈希表保证键唯一,由链表保证键值对存取有序
结论:如果键是自定义类型,那么该键所属类要重写hashCode和equals方法
*/
// 创建LinkedHashMap集合,限制集合中键的类型为Student,值的类型为String
LinkedHashMap<Student,String> map = new LinkedHashMap<>();
// 添加键值对到集合中
Student stu1 = new Student("张三", 18);
Student stu2 = new Student("李四", 38);
Student stu3 = new Student("王五", 28);
Student stu4 = new Student("赵六", 48);
Student stu5 = new Student("张三", 18);
map.put(stu1, "深圳");
map.put(stu2, "北京");
map.put(stu3, "上海");
map.put(stu4, "广州");
map.put(stu5, "香港");
// 获取map集合所有的键
Set<Student> keys = map.keySet();
// 循环遍历所有的键
for (Student key : keys) {
// 根据键找值
String value = map.get(key);
System.out.println(key+"="+value);
}
}
}
知识点–TreeMap集合
TreeMap介绍
TreeMap集合和Map相比没有特有的功能,底层的数据结构是红黑树;可以对元素的**键进行排序,排序方式有两种:自然排序和比较器排序;到时使用的是哪种排序,取决于我们在创建对象的时候所使用的构造方法;
构造方法
public TreeMap() 使用自然排序
public TreeMap(Comparator<? super K> comparator) 通过比较器指定规则排序
案例演示
public class Test {
public static void main(String[] args) {
/*
TreeMap集合: 可以对键进行排序,从而对键值对排序,底层采用的是二叉树存储结构
TreeMap的构造方法:
public TreeMap() 使用自然排序
默认规则排序:事先写好的排序规则
事先写好的排序规则:要求键所属的类必须实现Comparable接口,重写compareTo方法,在该方法中写好排序规则
public TreeMap(Comparator comparator) 通过比较器指定规则排序
*/
// 默认规则:
// 创建TreeMap集合,限制键的类型为Integer类型,值的类型为String类型
TreeMap<Integer,String> map = new TreeMap<>();
// 添加键值对到集合中
map.put(500,"深圳");
map.put(300,"广州");
map.put(200,"北京");
map.put(400,"上海");
map.put(100,"香港");
map.put(500,"澳门");
System.out.println(map);
System.out.println("==============================");
// 指定规则: 降序
// 创建TreeMap集合,限制键的类型为Integer类型,值的类型为String类型
TreeMap<Integer,String> map1 = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
// 添加键值对到集合中
map1.put(500,"深圳");
map1.put(300,"广州");
map1.put(200,"北京");
map1.put(400,"上海");
map1.put(100,"香港");
map1.put(500,"澳门");
System.out.println(map1);
}
}
案例-- Map集合练习
分析
- 获取一个字符串对象
- 创建一个Map集合,键代表字符,值代表次数。
- 遍历字符串得到每个字符。
- 判断Map中是否有该键。
- 如果没有,第一次出现,存储次数为1;如果有,则说明已经出现过,获取到对应的值进行++,再次存储。
- 打印最终结果
实现
方法介绍
public boolean containKey(Object key):判断该集合中是否有此键。
代码:
public class Test {
public static void main(String[] args) {
/*
Map集合练习:
需求:输入一个字符串中每个字符出现次
*/
// 分析:
// 1.创建Map集合,限制键的类型为Character,值的类型为Integer
Map<Character, Integer> map = new HashMap<>();
// 2.创建Scanner对象
Scanner sc = new Scanner(System.in);
// 3.获取键盘录入的字符串
System.out.println("请输入一个字符串:");
String str = sc.nextLine();
// 4.遍历字符串的每一个字符
for (int i = 0; i < str.length(); i++) {
// 5.在循环中,获取字符串的字符,该字符作为map集合的键
char cKey = str.charAt(i);
// 6.在循环中,判断遍历出来的字符在map集合中是否存在该键
boolean flag = map.containsKey(cKey);
// 7.在循环中,如果不存在,字符作为键,值为1,存储到map集合中
// 8.在循环中,如果存在,获取该字符键对应的值,进行+1后作为新的值
// 然后在重新存储到集合中
if (flag == false){
map.put(cKey,1);
}else{
Integer oldValue = map.get(cKey);// 获取该字符键对应的值
Integer newValue = oldValue + 1;// +1
map.put(cKey,newValue);
}
}
// 9.最后打印map集合
System.out.println(map);
}
}
小结
略
第九章 集合的嵌套
- List嵌套List
- List嵌套Map
- Map嵌套Map
讲解
List嵌套List
public class Test1 {
public static void main(String[] args) {
/*
集合的嵌套:
- List嵌套List
- List嵌套Map
- Map嵌套Map
结论:任何集合内部都可以存储其它任何集合
*/
// List嵌套List
// 创建一个List集合,限制元素类型为String
List<String> list1 = new ArrayList<>();
// 往集合中添加元素
list1.add("王宝强");
list1.add("贾乃亮");
list1.add("陈羽凡");
// 创建一个List集合,限制元素类型为String
List<String> list2 = new ArrayList<>();
// 往集合中添加元素
list2.add("马蓉");
list2.add("李小璐");
list2.add("白百何");
// 创建一个List集合,限制元素类型为List集合 (List集合中的元素是List集合)
List<List<String>> list = new ArrayList<>();
list.add(list1);
list.add(list2);
// 遍历
for (List<String> e : list) {
for (String name : e) {
System.out.println(name);
}
System.out.println("=============");
}
System.out.println(list);
}
}
List嵌套Map
public class Test2 {
public static void main(String[] args) {
/*
List嵌套Map:
*/
// 创建Map集合对象
Map<String,String> map1 = new HashMap<>();
map1.put("it001","迪丽热巴");
map1.put("it002","古力娜扎");
// 创建Map集合对象
Map<String,String> map2 = new HashMap<>();
map2.put("heima001","蔡徐坤");
map2.put("heima002","李易峰");
// 创建List集合,用来存储以上2个map集合
List<Map<String,String>> list = new ArrayList<>();
list.add(map1);
list.add(map2);
System.out.println(list.size()); // 2
for (Map<String, String> map : list) {
// 遍历获取出来的map集合对象
Set<String> keys = map.keySet();// 获取map集合所有的键
// 根据键找值
for (String key : keys) {
System.out.println(key + ","+ map.get(key));
}
}
}
}
Map嵌套Map
public class Test3 {
public static void main(String[] args) {
/*
Map嵌套Map:
*/
// 创建Map集合对象
Map<String,String> map1 = new HashMap<>();
map1.put("it001","迪丽热巴");
map1.put("it002","古力娜扎");
// 创建Map集合对象
Map<String,String> map2 = new HashMap<>();
map2.put("heima001","蔡徐坤");
map2.put("heima002","李易峰");
// 创建Map集合,把以上2个Map集合作为值存储到这个map集合中
Map<String, Map<String, String>> map = new HashMap<>();
map.put("传智博客",map1);
map.put("黑马程序员",map2);
System.out.println(map.size());// 2
// 获取map集合中的所有键
Set<String> keys = map.keySet();
// 遍历所有的键
for (String key : keys) {
// 根据键找值
Map<String, String> value = map.get(key);
// 遍历value这个Map集合
Set<String> keySet = value.keySet();
for (String k : keySet) {
String v = value.get(k);
System.out.println(k+","+v);
}
}
}
}
小结
第十章 模拟斗地主洗牌发牌
需求
按照斗地主的规则,完成洗牌发牌的动作。
具体规则:
- 组装54张扑克牌
- 54张牌顺序打乱
- 三个玩家参与游戏,三人交替摸牌,每人17张牌,最后三张留作底牌。
- 查看三人各自手中的牌(按照牌的大小排序)、底牌
规则:手中扑克牌从大到小的摆放顺序:大王,小王,2,A,K,Q,J,10,9,8,7,6,5,4,3
分析
1.准备牌:
完成数字与纸牌的映射关系:
使用双列Map(HashMap)集合,完成一个数字与字符串纸牌的对应关系(相当于一个字典)。
2.洗牌:
通过数字完成洗牌发牌
3.发牌:
将每个人以及底牌设计为ArrayList,将最后3张牌直接存放于底牌,剩余牌通过对3取模依次发牌。
存放的过程中要求数字大小与斗地主规则的大小对应。
将代表不同纸牌的数字分配给不同的玩家与底牌。
4.看牌:
通过Map集合找到对应字符展示。
通过查询纸牌与数字的对应关系,由数字转成纸牌字符串再进行展示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SBQcW3jM-1605617452427)(img/1587798350909.png)]
实现
package com.itheima.demo17_斗地主综合案例;
import java.util.*;
public class Test {
public static void main(String[] args) {
// 1. 造牌
// 1.1 创建Map集合,限制键的类型为Integer,值的类型为String
Map<Integer, String> map = new HashMap<>();
// 1.2 创建一个花色的单列集合,用来存储4个花色
ArrayList<String> colors = new ArrayList<>();
Collections.addAll(colors, "♠", "♥", "♣", "♦");
// 1.3 创建一个牌面值的单列集合,用来存储13个牌面值
ArrayList<String> numbers = new ArrayList<>();
Collections.addAll(numbers, "2", "A", "K", "Q", "J", "10", "9", "8", "7", "6", "5", "4", "3");
// 1.4 定义一个int类型的标记变量,初始值为0
int mark = 0;
// 1.5 大王作为键,标记作为值,添加到Map集合中,然后标记+1
map.put(mark++, "大王");
// 1.6 小王作为键,标记作为值,添加到Map集合中,然后标记+1
map.put(mark++, "小王");
// 1.7 牌面值作为外层循环,花色作为内层循环,来拼接牌,并添加到集合中
for (String number : numbers) {
for (String color : colors) {
// 组装牌
String pai = color + number;
// 把牌添加到集合中
map.put(mark++, pai);
}
}
System.out.println(map);
System.out.println(map.size());
// 2.洗牌:
// 2.1 获取所有牌的标记(keySet()方法),得到Set集合
Set<Integer> keys = map.keySet();
// 2.2 创建ArrayList集合,用来存储所有牌的标记
ArrayList<Integer> list = new ArrayList<>();
// 2.3 把Set集合中所有的标记存储到ArrayList集合中
list.addAll(keys);
// 2.4 使用Collections.shuffle()方法打乱牌的标记
Collections.shuffle(list);
System.out.println("打乱顺序后的标记:" + list);
System.out.println("list:" + list.size());// 54
// 3.发牌:
// 3.1 创建4个ArrayList集合,分别用来存储底牌,玩家1,玩家2,玩家3的牌的标记
ArrayList<Integer> play1Mark = new ArrayList<>();
ArrayList<Integer> play2Mark = new ArrayList<>();
ArrayList<Integer> play3Mark = new ArrayList<>();
ArrayList<Integer> diPaiMark = new ArrayList<>();
// 3.2 循环遍历打乱顺序后的标记
for (int i = 0; i < list.size(); i++) {
// 3.3 在循环中,获取标记,判断标记到底给谁:
Integer paiMark = list.get(i);
if (i >= 51) {
// 3.4 如果标记的索引>=51,给底牌
diPaiMark.add(paiMark);
} else if (i % 3 == 0) {
// 3.4 如果标记的索引%3==0,给玩家1
play1Mark.add(paiMark);
} else if (i % 3 == 1) {
// 3.4 如果标记的索引%3==1,给玩家2
play2Mark.add(paiMark);
} else {
// 3.4 如果标记的索引%3==2,给玩家3
play3Mark.add(paiMark);
}
}
// 3.5 对各个玩家手上的标记进行从小到大排序
Collections.sort(play1Mark);
Collections.sort(play2Mark);
Collections.sort(play3Mark);
Collections.sort(diPaiMark);
// 3.6 创建4个ArrayList集合,分别用来存储底牌,玩家1,玩家2,玩家3的牌
ArrayList<String> play1 = new ArrayList<>();
ArrayList<String> play2 = new ArrayList<>();
ArrayList<String> play3 = new ArrayList<>();
ArrayList<String> diPai = new ArrayList<>();
// 3.7 循环遍历排好序的标记,在循环中去map集合中获取牌
// 循环遍历玩家1排好序的标记
for (Integer paiMark : play1Mark) {
// 根据标记去Map集合中获取牌
String pai = map.get(paiMark);
// 把牌添加到集合中
play1.add(pai);
}
// 循环遍历玩家2排好序的标记
for (Integer paiMark : play2Mark) {
// 根据标记去Map集合中获取牌
String pai = map.get(paiMark);
// 把牌添加到集合中
play2.add(pai);
}
// 循环遍历玩家3排好序的标记
for (Integer paiMark : play3Mark) {
// 根据标记去Map集合中获取牌
String pai = map.get(paiMark);
// 把牌添加到集合中
play3.add(pai);
}
// 循环遍历底牌排好序的标记
for (Integer paiMark : diPaiMark) {
// 根据标记去Map集合中获取牌
String pai = map.get(paiMark);
// 把牌添加到集合中
diPai.add(pai);
}
// 3.8 展示牌
System.out.println("玩家1:" + play1 + ",数量:" + play1.size());
System.out.println("玩家2:" + play2 + ",数量:" + play2.size());
System.out.println("玩家3:" + play3 + ",数量:" + play3.size());
System.out.println("底牌:" + diPai);
}
}