DataWhale_Pandas Task Special:第一次综合练习
【任务一】企业收入的多样性
【题目描述】一个企业的产业收入多样性可以仿照信息熵的概念来定义收入熵指标:
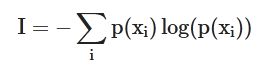
其中 p(xi) 是企业该年某产业收入额占该年所有产业总收入的比重。在company.csv中存有需要计算的企业和年份,在company_data.csv中存有企业、各类收入额和收入年份的信息。现请利用后一张表中的数据,在前一张表中增加一列表示该公司该年份的收入熵指标 I 。
【数据下载】链接:https://pan.baidu.com/s/1leZZctxMUSW55kZY5WwgIw 48 密码:u6fd
>>>df1 = pd.read_csv('company.csv')
>>>df2 = pd.read_csv('company_data.csv')
>>>df1.head()
证券代码 日期
0 #000007 2014
1 #000403 2015
2 #000408 2016
3 #000408 2017
4 #000426 2015
>>>df2.head()
证券代码 日期 收入类型 收入额
0 1 2008/12/31 1 1.084218e+10
1 1 2008/12/31 2 1.259789e+10
2 1 2008/12/31 3 1.451312e+10
3 1 2008/12/31 4 1.063843e+09
4 1 2008/12/31 5 8.513880e+08import numpy as np
import pandas as pd
Company = pd.read_csv('data/Task06/1/Company.csv')
Company_data = pd.read_csv('data/Task06/1/Company_data.csv')
#提取年份,同时统一'证券代码'这一个特征的格式
Company_data['日期'] = Company_data['日期'].apply(lambda x:int(x.split('/')[0]))
Company_data['证券代码'] = Company_data['证券代码'].astype(str).apply(lambda x:'#'+(x.zfill(6)))
#收入中有负数,采用绝对值
Company_data['收入额'] = abs(Company_data['收入额'])
#根据收入类型求和
Company_sum = Company_data.groupby(['证券代码','日期','收入类型']).sum()
Company_sum.reset_index(inplace=True)
#求年收入
Company_data_all=Company_data[['证券代码','日期','收入额']].groupby(['证券代码','日期']).sum()
Company_data_all.reset_index(inplace=True)
Company_data_all.rename(columns={"收入额":"年收入额"},inplace=True)
#并表算熵
df=pd.merge(Company_sum,Company_data_all,how='left',on=['证券代码','日期'])
df['p'] = df['收入额']/df['年收入额']
df['I'] = -df['p']*np.log(df['p'])
df_i = df[['证券代码','日期','I']].groupby(['证券代码','日期']).sum()
df_i.reset_index(inplace=True)
pd.merge(Company,df_i,on=['证券代码','日期'],how='left')【任务二】组队学习信息表的变换
【题目描述】请把组队学习的队伍信息表变换为如下形态,其中“是否队长”一列取1表示队长,否则为0
是否队长 队伍名称 昵称 编号
0 1 你说的都对队 山枫叶纷飞 5
1 0 你说的都对队 蔡 6
2 0 你说的都对队 安慕希 7
3 0 你说的都对队 信仰 8
4 0 你说的都对队 biubiu 20
... ... ... ... ...
141 0 七星联盟 Daisy 63
142 0 七星联盟 One Better 131
143 0 七星联盟 rain 112
144 1 应如是 思无邪 54
145 0 应如是 Justzer0 58
【数据下载】链接:https://pan.baidu.com/s/1ses24cTwUCbMx3rvYXaz-Q 30 密码:iz57
import pandas as pd
import numpy as np
df = pd.read_excel('data/Task06/3/组队信息汇总表(Pandas).xlsx')
df.head()
df_duizhang=df.melt(id_vars = ['所在群', '队伍名称'],
value_vars = [ '队长编号', '队员1 编号', '队员2 编号','队员3 编号', '队员4 编号', '队员5 编号', '队员6 编号', '队员7 编号', '队员8 编号','队员9 编号','队员10编号'],
var_name = '是否队长',
value_name = '编号')
df_zuyuan=df.melt(id_vars = ['所在群', '队伍名称'],
value_vars = [ '队长_群昵称', '队员_群昵称','队员_群昵称.1', '队员_群昵称.2','队员_群昵称.3','队员_群昵称.4','队员_群昵称.5', '队员_群昵称.6','队员_群昵称.7','队员_群昵称.8','队员_群昵称.9'],
var_name = '昵称类型',
value_name = '昵称')
#df_duizhang.head(10)
df_duizhang['是否队长']=df_duizhang['是否队长'].apply(lambda x: 1 if x=='队长编号' else 0)
df_result=pd.concat([df_df_duizhang,df_zuyuan[['昵称']]],axis=1)
df_result=df_result[['是否队长','队伍名称','昵称','编号']]
df_result.sort_values(by=['队伍名称','是否队长'],ascending=False,inplace=True)
df_result.dropna(inplace=True)
df_result['编号']=df_result['编号'].astype(int)
df_result.head()
【任务三】美国大选投票情况
【题目描述】两张数据表中分别给出了美国各县(county)的人口数以及大选的投票情况,请解决以下问题:
- 有多少县满足总投票数超过县人口数的一半
- 把州(
state)作为行索引,把投票候选人作为列名,列名的顺序按照候选人在全美的总票数由高到低排序,行列对应的元素为该候选人在该州获得的总票数
# 此处是一个样例,实际的州或人名用原表的英语代替
拜登 川普
威斯康星州 2 1
德克萨斯州 3 4
- 每一个州下设若干县,定义拜登在该县的得票率减去川普在该县的得票率为该县的
BT指标,若某个州所有县BT指标的中位数大于0,则称该州为Biden State,请找出所有的Biden State
【数据下载】链接:https://pan.baidu.com/s/182rr3CpstVux2CFdFd_Pcg 29 提取码:q674