cs224w 图神经网络 学习笔记(六)Spectral Clustering 谱聚类
课程链接:CS224W: Machine Learning with Graphs
课程视频:【课程】斯坦福 CS224W: 图机器学习 (2019 秋 | 英字)
目录
-
- 1 谱聚类分析的三个基本步骤
- 2 问题的引入——Graph Partitioning 图的分割
- 3 图分割的评价指标
- 4 图的谱——Spectral Graph Partitioning
- 5 图的矩阵(Matrix representations)
- 6 Find Optimal Cut
- 7 Spectral Clustering Algorithms 谱聚类算法(详细)
- 8. K-way Spectral Clustering
- 9. 拓展:基于motif的谱聚类 Motif-based Spetural Clustering
谱聚类是一种基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量进行聚类,从而达到对样本数据聚类的母的。谱聚类可以理解为将高维空间的数据映射到低维,然后在低维空间用其它聚类算法(如KMeans)进行聚类。
1 谱聚类分析的三个基本步骤
(1)Pre-processing 预处理
- Construct a matrix representation of the graph 构造图的矩阵表示
(2)Decomposition 分解
- Compute eigenvalues and eigenvectors of the matrix 计算矩阵的特征值和特征向量
- Map each point to a lower-dimensional representation based on one or more eigenvectors 将每个点映射到一个低维向量
(3)Grouping 聚类
- Assign points to two or more clusters, based on the new representation 根据降维后的向量进行分组
2 问题的引入——Graph Partitioning 图的分割
在讲到谱聚类之前,我们先来看一下我们要解决的问题。

给定一张无向图 G ( V , E ) G(V,E) G(V,E)中,谱聚类的任务可以定义为Bi-partitioning task,就是将图 G G G中的节点分为两个不相交的集合 A A A和 B B B。
那么,现在有两个问题需要解决:
-
How can we define a “good” partition of G G G? 怎么定义图 G G G的分割是好的?
好的分割主要由两个因素决定 (What makes a good partition?):
– Maximize the number of within-group connections 组内成员的连接尽可能的多
– Minimize the number of between-group connections 组间成员的连接尽可能的少 -
How can we efficiently identify such a partition? 怎样快速有效地识别这些分割?
这就需要一些评价指标。
3 图分割的评价指标
(1)Cut 和 Minimum-cut
Cut: Set of edges with one endpoint in each group.
第一个评价指标称作Cut,也就是将图的分割的情况表示为两个分割块的Edge cut的函数(Express partitioning objectives as a function of the “edge cut” of the partition)
c u t ( A , B ) = ∑ i ∈ A , j ∈ B ω i j cut(A,B)=\sum_{i \in A, j \in B} {\omega_{ij}} cut(A,B)=i∈A,j∈B∑ωij
如果是有权图, ω i j \omega_{ij} ωij为边的权值;如果是无权图, ω i j \omega_{ij} ωij为 { 0 , 1 } \{0,1\} { 0,1},连接为1,不连接为0。
下面就是一个例子:

前面说到,好的分割的标准之一就是不同分割块的成员之间的连接尽可能地少。所以使用cut这个标准来衡量图分割的目标就是找到Minimum-cut,也就是 a r g min A , B c u t ( A , B ) arg \min_{A,B} {cut(A,B)} argminA,Bcut(A,B)。
但是,cut这个指标只考虑了外部连接,没有考虑分割块内部的连接。这样会带来一个问题,就是最小的不一定是最优的,比如:

在此基础上,[Shi-Malik, ’97]提出了一个新的衡量图分割的指标Conductance。
(2)Conductance
Conductance的定义式如下:

与Cut相比,Conductance考虑了分割块的“体积”,使得分割后得到的不同的块更加平衡。但是,去得到最好的Conductance值是一个NP难度的问题。Spectral Graph Partitioning是一种得到近似优化值的方法。
4 图的谱——Spectral Graph Partitioning
- 设 A A A为无向图 G G G的邻接矩阵, a i j = { 0 , 1 } a_{ij}=\{0,1\} aij={ 0,1}。
- 设 n n n维向量 x = { x 1 , x 2 , ⋯ , x n } x=\{x_1,x_2,\cdots,x_n\} x={ x1,x2,⋯,xn}为图 G G G中 n n n个节点的标签/值(特征向量)。
则:
A ⋅ x = [ a 11 ⋯ a 1 n ⋮ ⋮ a n 1 ⋯ a n n ] [ x 1 ⋮ x n ] = [ y 1 ⋮ y n ] A \cdot x = \begin{bmatrix} a_{11} & \cdots & a_{1n} \\ \vdots & & \vdots \\ a_{n1} & \cdots & a_{nn}\\ \end{bmatrix} \begin{bmatrix} x_{1}\\ \vdots\\ x_{n}\\ \end{bmatrix} = \begin{bmatrix} y_{1}\\ \vdots\\ y_{n}\\ \end{bmatrix} A⋅x=⎣⎢⎡a11⋮an1⋯⋯a1n⋮ann⎦⎥⎤⎣⎢⎡x1⋮xn⎦⎥⎤=⎣⎢⎡y1⋮yn⎦⎥⎤
A ⋅ x A \cdot x A⋅x有什么含义呢?我们通过线性代数的知识可以知道, y i = ∑ j = 1 n A i j x j = ∑ ( i , j ) ∈ E x j y_i=\sum_{j=1}^n A_{ij}x_j = \sum_{(i,j) \in E} x_j yi=∑j=1nAijxj=∑(i,j)∈Exj,也就是说, y i y_i yi计算的是节点 i i i的邻居的标签之和。
令 A ⋅ x = λ ⋅ x A \cdot x = \lambda \cdot x A⋅x=λ⋅x,可以得到特征值(eigenvalues) λ i \lambda_i λi和相应的特征向量(eigenvectors) x ( i ) x^{(i)} x(i)。对于图 G G G来说,它的**谱(Spectrum)**定义为其一组特征向量 x ( i ) x^{(i)} x(i),且这组特征向量满足其对应的特征值为 Λ = { λ 1 , λ 2 , ⋯ , λ n } \Lambda = \{\lambda_1, \lambda_2, \cdots, \lambda_n\} Λ={ λ1,λ2,⋯,λn},其中 λ 1 ≤ λ 2 ≤ ⋯ ≤ λ n \lambda_1 \leq \lambda_2 \leq \cdots \leq \lambda_n λ1≤λ2≤⋯≤λn。
① 设 G G G为一个所有节点的度为 d d d的连通图(d-regular graph),设特征向量为 x = ( 1 , 1 , ⋯ , 1 ) x=(1,1, \cdots, 1) x=(1,1,⋯,1),则 d d d为图 G G G的邻接矩阵 A A A的特征值,且为最大特征值,即 λ n = d \lambda_n=d λn=d。【老师的PPT里面给了证明】
② 设图 G G G为两个不连通的d-regular graph组成,如下图所示。此时 λ n − 1 = λ n = d \lambda_{n-1}=\lambda_n=d λn−1=λn=d

推广:

- 如果d-regular graph是连通的,那么我们知道 x n = ( 1 , 1 , ⋯ , 1 ) x_n=(1,1, \cdots, 1) xn=(1,1,⋯,1)是图的一个特征向量。
- 由于邻接矩阵 A A A是实对称矩阵,属于矩阵 A A A不同特征值的特征向量是相互正交的,所以
对于剩下的特征向量来说, x n ⋅ x n − 1 = 0 x_n \cdot x_{n-1}=0 xn⋅xn−1=0,即 ∑ i x n [ i ] ⋅ x n − 1 [ i ] = ∑ i x n − 1 [ i ] = 0 \sum_i x_n[i] \cdot x_{n-1}[i]=\sum_ix_{n-1}[i]=0 ∑ixn[i]⋅xn−1[i]=∑ixn−1[i]=0。也就是说,第二大特征向量 x n − 1 x_{n-1} xn−1将剩下的点分成了两部分, x n − 1 > 0 x_{n-1}>0 xn−1>0的和 x n − 1 < 0 x_{n-1}<0 xn−1<0的。
这样一来,我们就有了将图的节点进行分割的方法。并且,将图和线性代数(矩阵)结合,提供了计算机参与的切入点。
5 图的矩阵(Matrix representations)
(1)邻接矩阵 Adjacency matrix A A A
邻接矩阵 A A A 是 n × n n \times n n×n 的矩阵, A = [ a i j ] A=[a_{ij}] A=[aij],如果节点 i i i和节点 j j j有边相连,则 a i j = 1 a_{ij}=1 aij=1。

邻接矩阵 A A A 具有以下三个特点:
- Symmetric matrix 对称矩阵
- Has n n n real eigenvalues 有 n n n个实特征值
- Eigenvectors are real-valued and orthogonal 特征向量均为实向量,且不同特征值对应的特征向量正交
(2)度矩阵 Degree Matrix D D D
度矩阵 D D D 是一个 n × n n \times n n×n 的对角矩阵, D = [ d i i ] D=[d_{ii}] D=[dii]。

(3)Laplacian matrix L L L
定义: L = D − A L=D-A L=D−A

Laplacian matrix L L L有以下属性:
- 令 x = ( 1 , 1 , ⋯ , 1 ) x=(1,1, \cdots,1) x=(1,1,⋯,1),则 L ⋅ x = 0 L \cdot x=0 L⋅x=0,因此(最小)特征值为 λ = λ 1 = 0 \lambda=\lambda_1=0 λ=λ1=0。那么对于特征值 λ 2 \lambda_2 λ2对应的特征向量 x x x来说, x x x是一个单位向量,即 x T x = ∑ i x i 2 = 1 x^Tx=\sum_i {x_i^2}=1 xTx=∑ixi2=1;且 x T λ 1 = ∑ i x i ⋅ 1 = ∑ i x i = 0 x^T \lambda_1=\sum_i {x_i \cdot 1}=\sum_i {x_i}=0 xTλ1=∑ixi⋅1=∑ixi=0。
- Eigenvalues are non-negative real numbers 特征值均为非负实数
- Eigenvectors are real (and always orthogonal) 特征向量均为实向量,且不同特征值对应的特征向量正交
- 对所有的 x x x, x T L x = ∑ i j L i j x i x j ≥ 0 x^T Lx=\sum_{ij} L_{ij} x_i x_j \geq 0 xTLx=∑ijLijxixj≥0。那么,我们来看一下图 G G G的 x T L x x^T Lx xTLx是什么含义呢?
x T L x = ∑ i , j = 1 n L i j x i x j = ∑ i , j = 1 n ( D i j − A i j ) x i x j = ∑ i , j = 1 n D i j x j 2 − ∑ ( i , j ) ∈ E 2 x i x j = ∑ ( i , j ) ∈ E x i 2 + x j 2 − 2 x i x j = ∑ ( i , j ) ∈ E ( x i − x j ) 2 \begin{aligned} x^T Lx & = \sum_{i,j=1}^n {L_{ij} x_i x_j}=\sum_{i,j=1}^n {(D_{ij}-A_{ij}) x_i x_j} \\ &= \sum_{i,j=1}^n {D_{ij} x_j^2}-\sum_{(i,j) \in E} {2 x_i x_j} \\ &= \sum_{(i,j) \in E} {x_i^2+x_j^2-2x_i x_j} \\ &= \sum_{(i,j) \in E} {(x_i-x_j)^2} \\ \end{aligned} xTLx=i,j=1∑nLijxixj=i,j=1∑n(Dij−Aij)xixj=i,j=1∑nDijxj2−(i,j)∈E∑2xixj=(i,j)∈E∑xi2+xj2−2xixj=(i,j)∈E∑(xi−xj)2 - L L L可以写作 L = N T N L=N^T N L=NTN
引理:对于对称矩阵 M M M,特征值
λ 2 = min x : x T ω 1 = 0 x T M x x T x \lambda_2=\min_{x:x^T \omega_1=0} \frac {x^T Mx}{x^Tx} λ2=x:xTω1=0minxTxxTMx
其中 ω 1 \omega_1 ω1是特征值 λ 1 \lambda_1 λ1对应的特征向量。
(关于这个引理的证明在老师的课件里面有)
那么对于Laplacian矩阵
λ 2 = min x : ∑ i x i = 0 x T L x x T x = min x : ∑ i x i = 0 ∑ ( i , j ) ∈ E ( x i − x j ) 2 ∑ i x i 2 = min x : ∑ i x i = 0 ∑ ( i , j ) ∈ E ( x i − x j ) 2 \lambda_2=\min_{x:\sum_i {x_i}=0} \frac {x^T Lx}{x^Tx}=\min_{x:\sum_i {x_i}=0} \frac {\sum_{(i,j) \in E} {(x_i-x_j)^2}} {\sum_i {x_i^2}}=\min_{x:\sum_i {x_i}=0} \sum_{(i,j) \in E} {(x_i-x_j)^2} λ2=x:∑ixi=0minxTxxTLx=x:∑ixi=0min∑ixi2∑(i,j)∈E(xi−xj)2=x:∑ixi=0min(i,j)∈E∑(xi−xj)2

因为 ∑ i x i = 0 \sum_i {x_i}=0 ∑ixi=0,所以所求的解有正有负,而最理想的情况就是使尽可能少的边经过“0轴”。
6 Find Optimal Cut
我们还是回到最开始的问题——怎样得到图的最佳分割?
[Fiedler '73]提出了一种寻找最佳切分点的方案:

参考:【CS224W课程笔记】Spectral Clustering

7 Spectral Clustering Algorithms 谱聚类算法(详细)
最后,我们再来回顾一下谱聚类算法的三个步骤:
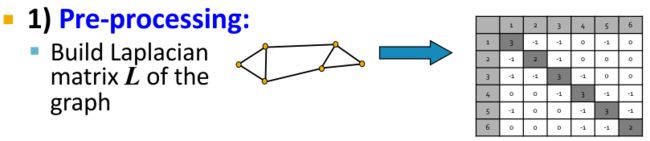
(1)Pre-processing 预处理
- Construct a matrix representation of the graph 构造图的矩阵表示
(2)Decomposition 分解
- Compute eigenvalues and eigenvectors of the matrix 计算矩阵的特征值和特征向量
- Map each point to a lower-dimensional representation based on one or more eigenvectors 将每个点映射到一个低维向量

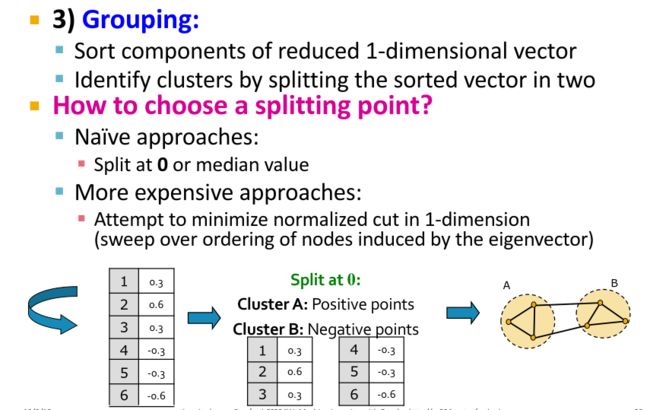
(3)Grouping 聚类
- Assign points to two or more clusters, based on the new representation 根据降维后的向量进行分组
下面是一些案例:
| 例1 | 例2 | 例3 |
|---|---|---|
 |
 |
 |
8. K-way Spectral Clustering
怎样将图上的节点分成 k k k类呢?有两种方法:
(1) 递归 Recursive bi-partitioning [Hagen et al., ’92]
递归利用二分算法,将图进行划分。但是递归方法效率比较低,且比较不稳定。
(2)Cluster multiple eigenvectors [Shi-Malik, ’00]
通过特征向量进行聚类。该方法目前比较常用,且效果较好。

这种方法有以下几个优点:
- Approximates the optimal cut 更接近最优分割——Can be used to approximate optimal k-way normalized cut
- Emphasizes cohesive clusters 着重于更凝聚的类别——①Increases the unevenness in the distribution of the data 考虑了数据的不均匀性 ②Associations between similar points are amplified, associations between dissimilar points are attenuated 相似点之间的关联被放大,不同点之间的关联被减弱 ③The data begins to “approximate a clustering” “近似聚类”
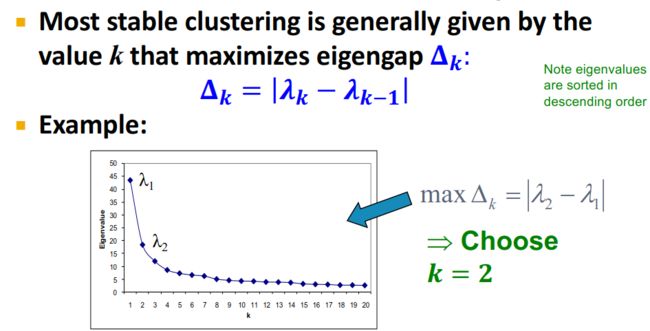
那么,怎么选择 k k k呢?——How to select k k k?——通过两个连续的特征值之间的差来确定。
9. 拓展:基于motif的谱聚类 Motif-based Spetural Clustering
前面讲到的都是基于两个节点之间的关系的聚类,那么,如果我们想要基于Motif进行聚类呢?比如说下面这张图,我们给定一个图结构,并给定不同的Motif结构,就可以得到不同的聚类结果。

我们可以将Conductance的定义进行相应的推广:

下面是一个计算的例子。因为分割线 S S S经过一个Motif,且Motif类中包含10个节点,可以知道 ϕ M ( S ) = 1 10 \phi_M(S)=\frac {1}{10} ϕM(S)=101。

类似的,问题就变成了给定图 G G G和Motif结构,找到分割方式使得 ϕ M ( S ) \phi_M(S) ϕM(S)最小。同样的,需要通过近似算法——Motif Spectral Clustering来得到最优结果。

同样的,近似算法分为三步:
(1)预处理 Pre-processing
定义矩阵 W i j ( M ) W_{ij}^{(M)} Wij(M),其中 w i j ( M ) w_{ij}^{(M)} wij(M)表示图 G G G中的边 ( i , j ) (i,j) (i,j)在给定的Motif结构 M M M中参与的次数。下图是一个例子:

用矩阵形式表示:

(2) Decomposition 分解
第二步是分解,定义度矩阵 D i j ( M ) = ∑ j w i j ( M ) D_{ij}^{(M)}=\sum_{j}w_{ij}^{(M)} Dij(M)=∑jwij(M),定义拉布拉斯矩阵 L ( M ) = D ( M ) − W ( M ) L^{(M)}=D^{(M)}-W^{(M)} L(M)=D(M)−W(M),计算特征值与特征向量 L ( M ) x = λ 2 x L^{(M)}x=\lambda_2 x L(M)x=λ2x,由得到的特征向量 x x x来对图进行分割。
(3)Grouping 分组
这一步和之前的谱聚类方法类似。
