2021-01-01 如何批量下载ERA5数据
由于笔者在工作中需要用到ERA5的雨水路径(Total column rain water)数据,因此需要批量下载该数据。本文将以下载Total column rain water为例,记录ERA5的批量下载(使用Python多线程并行下载)方法,以备日后查看。
本次示例的实现平台和工具:
操作系统:ubuntu20
下载工具:python3
特殊工具:ERA5官网指定的CDS API和密钥(详见后文)
注:本下载方案在windows和linux操作系统下均适用。
目录:
1 挑选需要的ERA5数据
1.1 进入官网挑选需要的ERA5 数据集
1.2 选择所需数据集中的具体数据(产品类型/变量/年/月/日/时刻/地理范围/数据类型)
2 下载ERA5数据
2.1 安装CDS API工具
2.2 获取ERA5数据的python 下载脚本
2.2.1 下载方法一:官网给出的python脚本
2.2.2 下载方法二:多线程并行下载的python脚本
正文如下:
1 挑选需要的ERA5数据
本文示例下载数据:
产品类型:ERA5再分析数据
变量:Total column rain water
时间:2018.07.04-2018.07.11时段内所有时刻
区域:全球
数据类型:grib
1.1 进入官网挑选需要的ERA5 数据集:https://cds.climate.copernicus.eu/#!/search?text=ERA5&type=dataset
1.2 选择所需数据集中的具体数据(产品类型/变量/年/月/日/时刻/地理范围/数据类型)
笔者根据需求,作出如下挑选:



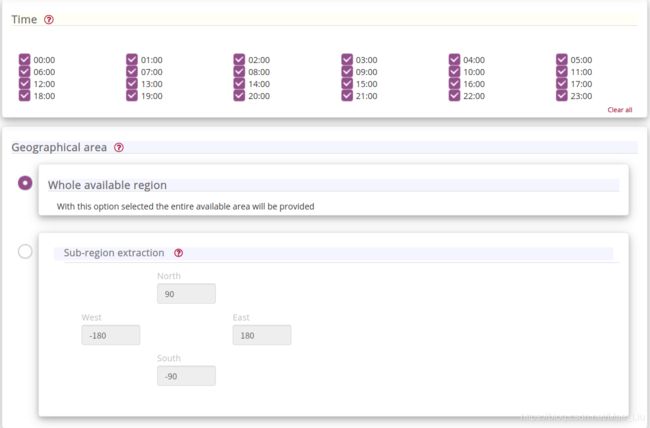

2 下载ERA5数据
2.1 安装CDS API工具
CDS API完整安装教程详见:https://cds.climate.copernicus.eu/api-how-to
该网页详细列举了不同操作系统下CDS API的安装方法:
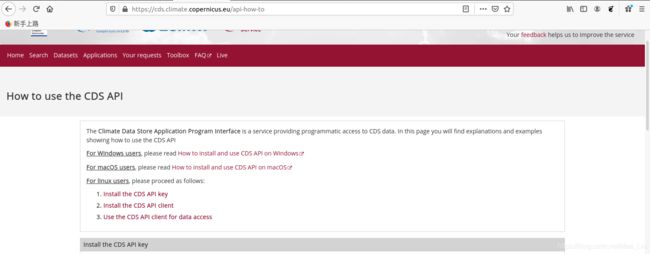 简单来讲:
简单来讲:
(1)每个已注册的用户可获得一个url和key,复制网页给出的url和key的代码,另存为指定目录下的“.cdsapirc”文件,一般放在计算机的用户目录下(linux系统:/home/用户名/,windows系统详见网页上的说明,好像是C盘的“用户”文件夹下)。
(2)在python环境下运行:pip install cdsapi,即可安装完毕。
2.2 获取ERA5数据的python 下载脚本
回到挑选数据的页面,完成挑选后点击"show API request"。即可获取官网示例的python下载脚本。
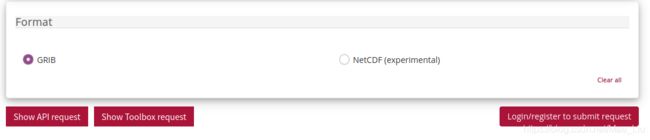
 2.2.1 下载方法一:
2.2.1 下载方法一:
直接使用官网示例的python下载脚本,它会将上述选取的所有数据下载到这一个名为"download.grib"的文件中,文件所在目录为当前此python脚本所在的目录。
2.2.2 下载方法二:
笔者编写的多线程并行下载的python脚本。此脚本会将每一个时刻的数据生成一个grib文件,放入脚本中指定的文件目录下。
"""
Created on Fri Jan 1 14:58:08 2021
@author: mae
This program download ERA5 rain water content during 2018.07.04-2017.07.11
using python multi-threaded execution.
notice:
1. This script requires url and key which can be found at web page:
https://cds.climate.copernicus.eu/api-how-to
2. after run the script, era5 data will be format individualy like:
'era5_' + '201807' + d + h + '_rain_water_sfc.grib'
"""
import cdsapi
import os
from multiprocessing import Process
c = cdsapi.Client()
def download(day, h):
c.retrieve(
'reanalysis-era5-single-levels',
{
'product_type':'reanalysis',
'format': 'grib',
'variable': 'total_column_rain_water',
'year': '2018',
'month': '07',
'day': day,
'time': h,
},
'era5_' + '201807' + d + h + '_rain_water_sfc.grib')
return 0
if __name__ == '__main__':
# define directory where you want data store in.
os.chdir("/where/data/put/in/")
days=['04', '05', '06','07', '08', '09','10', '11']
times=[
'00:00', '01:00', '02:00',
'03:00', '04:00', '05:00',
'06:00', '07:00', '08:00',
'09:00', '10:00', '11:00',
'12:00', '13:00', '14:00',
'15:00', '16:00', '17:00',
'18:00', '19:00', '20:00',
'21:00', '22:00', '23:00']
for day in days:
d = day
pro_list = []
for hour in times:
h = hour
p = Process(target=download, args=(day, h))
p.start()
pro_list.append(p)
for p in pro_list:
p.join()
print("主进程结束!")
del p
注:生成的文件名类似这样:era5_2018070400:00_rain_water_sfc.grib
有一个需要注意的小问题:文件名中含有冒号,linux系统是可以接受的,但windows系统好像不能接受文件名中含有冒号。解决方案(1):linux系统下打开终端,进入文件所在目录,运行
rename 's|:||g' *
即可将冒号删去。解决方案(2):window也有类似的批处理命令,有兴趣可以自行探索。解决方案(3):将笔者写的python代码稍作修改,可以改一下文件命名方式。:)
整理完毕!
参考文章:
[1] https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels?tab=form
[2] https://cds.climate.copernicus.eu/api-how-to
[3] https://blog.csdn.net/luqialiu3392/article/details/109895064
[4] https://blog.csdn.net/weixin_44975806/article/details/100083897