人工智能基础
第一章 序论
1.如果一个问题或者任务不可计算,那么对这个问题或任务的描述哪一句是正确的(C )
A.该问题或任务所需计算时间是非线性增加的
B.该问题或任务所需计算时间是线性增加的
C.图灵机不可停机
D.无法将该问题或任务所需数据一次性装入内存进行计算
不可求解=图灵机不可停机,凡是可计算的函数都能用图灵机计算,凡是存在有效过程的计算都能被图灵机实现
2.下面哪一句话准确描述了摩尔定律(A )
A.摩尔定律描述了计算机的计算速度每一年半增长一倍的规律
B.摩尔定律描述了计算机内存大小随时间不断增长的规律
C.摩尔定律描述了互联网所链接节点随时间不断增长的规律
D.摩尔定律描述了计算机的体积大小随时间不断减少的规律
3. 下面哪个方法于20世纪被提出来,用来描述对计算机智能水平进行测试(B )
A.费马定理
B.图灵测试
C.摩尔定律
D.香农定律
4.1955年,麦卡锡、明斯基、香农和诺切斯特四位学者首次提出“artificial intelligence(人工智能)”这个概念时,希望人工智能研究的主题是( D )
A.人工智能伦理
B.避免计算机控制人类
C.全力研究人类大脑
D.用计算机来模拟人类智能
人工智能的主题是:让机器能像人那样认知思考和学习,即用计算机模拟人工智能
5.下面哪一句话是正确的 ( D )
A.机器学习就是深度学习
B.人工智能就是机器学习
C.人工智能就是深度学习
D.深度学习是一种机器学习的方法
机器学习可分为监督学习,无监督学习。区别在于监督学习的数据有标签,相当于只是做数据的区分。无监督学习没有数据标签,需要自己进行学习。
深度学习是机器学习的一种。
6. 以逻辑规则为核心的逻辑推理、以数据驱动为核心的机器学习和以问题引导为核心的强化学习是三种人工智能的方法,下面哪一句话的描述是不正确的( A)
A.目前以数据驱动为核心的机器学习方法可从任意大数据(无论数据是具备标签还是不具备标签)中来学习数据模式,完成给定任务
B.目前以数据驱动为核心的机器学习方法需要从具有标签的大数据中来学习数据模式,完成给定任务
C.强化学习的基本特征是智能体与环境不断进行交互,在交互过程不断学习来完成特定任务
D.以逻辑规则为核心的逻辑推理方法解释性强
强化学习是和环境交互,得到某个行动的评价,然后找到最优路径。AlphaGo和人类棋手对弈就是强化学习。
7.下面对人类智能和机器智能的描述哪一句是不正确的( B )
A.人类智能具备直觉和顿悟能力,机器智能很难具备这样的能力
B.人类智能和机器智能均具备常识,因此能够进行常识性推理
C.人类智能具有自适应特点,机器智能则大多是“依葫芦画瓢”
D.人类智能能够自我学习,机器智能大多是依靠数据和规则驱动
8.我们常说“人类是智能回路的总开关”,即人类智能决定着任何智能的高度、广度和深度,下面哪一句话对这个观点的描述不正确( D )
A.机器智能和人类智能相互协同所产生的智能能力可超越人类智能或机器智能
B.机器智能目前无法完全模拟人类所有智能
C.人类智能是机器智能的设计者
D.机器智能目前已经超越了人类智能
9.下面哪句话描述了现有深度学习这一种人工智能方法的特点( A )
A.小数据,大任务
B.大数据,大任务
C.大数据,小任务
D.小数据,小任务
深度学习是有监督学习的一种,这个小大的描述很迷。
10.德国著名数学家希尔伯特在1900年举办的国际数学家大会中所提出的“算术公理的相容性 (the compatibility of the arithmetical axioms)”这一问题推动了可计算思想研究的深入。在希尔伯特所提出的这个问题中,一个算术公理系统是相容的需要满足三个特点。下面哪个描述不属于这三个特点之一( D )
A.完备性,即所有能够从该形式化系统推导出来的命题,都可以从这个形式化系统推导出来。
B. 一致性,即一个命题不可能同时为真或为假
C.可判定性,即算法在有限步内判定命题的真伪
D.复杂性,即算法性能与输入数据大小相关
记住形式化系统的三个特征:可判断性,完备性,一致性。
第二章 命题与逻辑
析取:V
合取: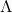
假言推理: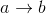
与消解:![]()
与导入:![]()
双重否定
消解、归结:![]() ,
,![]()
FOIL算法
输入目标谓词,背景知识样例,正例和反例,得到推理结果。
比如Father(x,y)代表x是y的父亲,已知其他的谓词:Mother(x,y),Sibling(x,y),Couple(x,y)
已知样例和反例(比如A是B的父亲,A和C是couple=>则A不是C父亲为反例)
最后得到推理结果,例如:(Mother(x,y)VCouple(z,x))->Father(z,y)(x是y的母亲,zx为夫妻,则z是y的父亲)
伪代码:
while(推理规则覆盖任何反例)begin
对于所有未添加的规则,计算信息增益:![]() (m*是指新的,m是指之前的。)
(m*是指新的,m是指之前的。)
选择信息增益最大的添加入推理规则
删去不符合推理规则的样例
end
如何计算信息增益:
对于一条规则,其和已知规则组合在一起,统计m+为正例数量,m-为反例数量。
比如Couple(x,y)的信息增益:当前没有已知信息,因此规则为
Couple(x,y)->Father(x,y)
Couple(x,z)->Father(x,y)
Couple(z,y)->Father(x,y)
....
这里有几个人就需要几个Couple,比如4个人,就有C(4,2)=6个式子,Father里的x,y是不变的
路径排序算法
知识图谱中假设有4个人,则每个人是一个点,他们已知的关系有3条,则有3条边。
然后将四个人两两组合代入3条边,成立为1,不成立为0,得到6个3维特征向量,和一个标签,正例记为1,负例记为-1。
对分类器进行训练,最后输入待检测的关系,如果输出1则为正例,否则为负例。
1.如果命题p为真、命题q为假,则下述哪个复合命题为真命题(C )
2.下面哪个复合命题与“如果秋天天气变凉,那么大雁南飞越冬”是逻辑等价的( B)
A.如果大雁不南飞越冬,那么秋天天气变凉
B.如果大雁不南飞越冬,那么秋天天气没有变凉
逆否命题等价
3.下面哪一句话对命题逻辑中的归结(resolution)规则的描述是不正确的( D )
A.在两个析取复合命题中,如果命题q及其反命题分别出现在这两个析取复合命题中,则通过归结法可得到一个新的析取复合命题,只是在析取复合命题中要去除命题q及其反命题。
B.对命题q及其反命题应用归结法,所得到的命题为假命题
4.下面哪一句话对命题范式的描述是不正确的( D )
析取是或,因此只要包含至少一个不成立即可。
5.下面哪个逻辑等价关系是不成立的( A )
6.下面哪个谓词逻辑的推理规则是不成立的( C )
7.知识图谱可视为包含多种关系的图。在图中,每个节点是一个实体(如人名、地名、事件和活动等),任意两个节点之间的边表示这两个节点之间存在的关系。下面对知识图谱的描述,哪一句话的描述不正确(B )
8.如果知识图谱中有David和Mike两个节点,他们之间具有classmate和brother关系。在知识图谱中还存在其他丰富节点和丰富关系(如couple, parent等)前提下,下面描述不正确的是( A )
C.可以从知识图谱中形成brother
9.在一阶归纳学习中,只要给定目标谓词,FOIL算法从若干样例出发,不断测试所得到推理规则是否还包含反例,一旦不包含负例,则学习结束,展示了 “归纳学习”能力。下面所列出的哪个样例,不属于FOIL在学习推理规则中所利用的样例。
10.下面对一阶归纳推理(FOIL)中信息增益值(information gain)阐释不正确的是( B )
与正反例数目有关,与背景知识样例无关。(背景知识指的是不能既是父亲又是Couple这样的)
因果图
如果a和b有因果关系,可以用点和边a->b表示。
那么很多事件a,b,c,...,可以用有向图表示他们的因果关系。
称为因果图。
计算因果图的联合概率:![]()
即:d个变量的联合概率是d个变量与其父节点的条件概率之积
因果图的基本元素
链式结构:X->Z->Y,X,Y条件独立
分连:X<-Z->Y,X,Y条件独立
汇连:X->Z<-Y,X,Y相关
结点的相关性:与事件的独立性类似。
判断方法:D分离法
1.如果链和分连中的Z被限定
2.或者汇连中的Z及其后代不被限定
则X,Y的道路被阻塞。当所有道路被阻塞,则X,Y独立。
干预
do(x=a):去掉指向x的边,并将x的值固定为a。
意思是不考虑x的影响
1.基于知识图谱的路径排序推理方法可属于如下哪一种方法( D )
A.因果推理
B.监督学习(即利用标注数据)
C.无监督学习(即无标注数据)
D.一阶逻辑推理
对已知的路径关系进行学习,如果是正例则为路径为1,如果是负例则路径为-1,因此为监督学习
2.下面哪个步骤不属于基于知识图谱的路径排序推理方法中的一个步骤( A)
A.定义和选择do算子操作
B.定义和选择若干标注训练数据
C.定义和选择某一特定的分类器
D.定义和选择训练数据的特征
定义do算子是干预因果关系
3.在基于知识图谱的路径排序推理方法中,最后训练所得分类器的功能是( C )
A.给定两个实体(知识图谱中的两个节点),判断其是否存在超过小于一定长度的路径
B.判断一个给定实体(知识图谱中的一个节点)是否存在邻接节点
C.给定两个实体(知识图谱中的两个节点),判断其是否具有分类器所表达的关系(即节点之间是否具有分类器所能够辨认的关系)
D.给定两个实体(知识图谱中的两个节点),判断其是否存在超过一定长度的路径
路径排序的目的就是训练完训练器然后得到一个新的推理规则。
4.下面对辛普森悖论描述不正确的是( C )
A. 为了克服辛普森悖论,需要从观测结果中寻找引发结果的原因,由果溯因。
B.在某些情况下,忽略潜在的“第三个变量”,可能会改变已有的结论,而我们常常却一无所知。
C.辛普森悖论的原因在于数据之间相互不关联。
D.如果忽略了一些潜在因素,可能会导致全部数据上观察到的结果却在部分数据上不成立。
辛普森悖论是指,对于总体的观测得到的结果可能和部分得到的结果不同。即:![]() ,因此是数据之间互相关联。
,因此是数据之间互相关联。
5.下面哪个描述的问题不属于因果分析的内容(A )
A.购买了A商品的顾客是否会购买B商品
B.如果商品价格涨价一倍,预测销售量P′(sales)的变化
C.如果广告投入增长一倍,预测销售量的增长
D.如果放弃吸烟,预测癌症P′(cancer) 的概率
因果就是有如果(?)
6.下面哪个说法是不正确的( C )
A.一个有向无环图唯一地决定一个联合分布
B.在有向无环图中,父辈节点“促成”了孩子节点的取值
C.一个联合分布不能唯一地决定有向无环图
D.一个有向无环图无法唯一地决定一个联合分布
联合分布只表示有向无环图的一部分,无法唯一的确定。
7.在因果推理中,D-分离(d-separation)的作用是(A )
A.用于判断集合A中变量是否与集合B中变量相互独立(给定集合C)
B.用于判断集合A中变量是否与集合B中变量是否存在链接
C.用于判断集合A中变量是否与集合B中变量是否不存在链接
D.用于判断集合A中变量是否与集合B中变量相关(给定集合C)
注意是独立而非相关。
8.下面对干预(intervention)和do算子(do-calculus)描述不正确的是(A )
得分/总分
A.do(x)=a表示将DAG中指向节点x的所有节点取值均固定为a
B.do(x)=a表示将DAG中指向节点x的有向边全部切断,并且将x的值固定为常数a
C.do算子的意思可理解为 “干预”(intervention)
D.干预(intervention)指的是固定(fix)系统中某个变量,然后改变系统,观察其他变量的变化
9.下面对反事实推理 (counterfactual model)描述不正确的是(A )
A.条件变量对于结果变量的因果性就是A成立时B的状态与A取负向值时“反事实”状态(B')之间的差异。如果这种差异存在且在统计上是显著的,说明条件变量与结果变量不存在因果关系。
B.反事实推理是用于因果推理的一种方法。
C.事实是指在某个特定变量(A)的影响下可观测到的某种状态或结果(B)。“反事实”是指在该特定变量(A)取负向值时可观测到的状态或结果(B')。
D.条件变量对于结果变量的因果性就是A成立时B的状态与A取负向值时“反事实”状态(B')之间的差异。如果这种差异存在且在统计上是显著的,说明条件变量与结果变量存在因果关系。
10.下面对通过因果图来进行因果推理所存在不足描述不正确的是( B )
A.DAG 作为一种简化的模型,在复杂系统中可能不完全适用,需要将其拓展到动态系统(如时间序列)。
B.因果图无法刻画数据之间的联合分布。
C.在因果推理中引入了do算子,即从系统之外人为控制某些变量。但是,这依赖于一个假定:干预某些变量并不会引起 DAG 中其他结构的变化。
D.难以得到一个完整的DAG用于阐述变量之间的因果关系或者数据生成机制,使得 DAG 的应用受到的巨大的阻碍。
第三章 搜索求解