hive学习笔记
文章目录
-
- 前言
-
- 推荐文章
- 库方面
-
- 创建库
- 修改库
- 删除库
- 描述库
- 表方面
-
- 前言
- 创建表
- 插入表
- 描述表
- 删除表
-
- 删除外部表
- 变更表
-
- 表本身属性层面
- 表字段层面
- 分区操作
- 查询表
- 报错汇总
- Mysql方面
-
- hive的元数据metastore
- 函数方面
- UDF
- Shell命令
-
- dfs
- ![-cat [-ignoreCrc] ...]
- 引文
- 后记
-
- 解决hive中文显示乱码
- 未消化,还需要阅读
前言
推荐文章
| 目的 | 文章链接 | 备注 |
|---|---|---|
| 测试1 | ||
| Hive分区表新增字段+重刷历史方法(避免旧分区新增字段为NULL) | https://blog.csdn.net/hjw199089/article/details/79056612 | 没怎么看 |
库方面
创建库
create database kegx_schema;
create database if not exists kegx_schema;
-- 修改数据库默认位置
create database kegx_schema location 'my/myhive.db';//要指定数据库名
CREATE DATABASE db_test LOCATION '/test/hello';
-- db_name,comment,location,owner_name,owner_type,parameters
-- db_test,"",hdfs://localhost:9000/test/hello,root,USER
-- 为数据库增加描述信息
create database kegx_schema comment 'hive by kegx';
-- 增加一些和其相关的键-值对属性信息
create database kegx_schema with dbproperties('name'='ke','data'='2021-01-02');
-- 查看
desc database extended kegx_schema;
-- 【注意】设置一个属性显示当前所在的数据库:hive>set hive.cli.print.current.db=true;hive会为每个数据库创建一个目录。数据库中的表以数据库的子目录形式存储;但default没有目录;数据库所在目录位于:${hive.metastore.warehouse.dir}
-- 使用数据库
use default;
修改库
-- 修改数据库,DBPROPERTIES通过键-值对属性值,来描述数据库信息。数据库其他元数据都是不可更改的,例如数据库名,数据库所在目录是不能修改的。
ALTER DATABASE db_test SET DBPROPERTIES('CREATETIME'='20200101');//在parameters列中显示{CREATETIME=20200101}
ALTER DATABASE db_test SET DBPROPERTIES('comment'='测试用的数据库');//在parameters列中显示{CREATETIME=20200101, comment=???????}
-- 【注意】数据库所在的目录位置是可以修改的,但是其底下的数据可不会自动跟着变。
-- 修改方式如下
alter (database|schema) database_name set location hdfs_path
alter database db_test set location 'hdfs://localhost:9000/test/hello';
alter schema db_test set location 'hdfs://localhost:9000/test/hello1';
实验如下
CREATE DATABASE db_test LOCATION '/test/hello';
create table db_test.employee (eud int,name String,salary String,destination String) COMMENT 'Employee table' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE;
dfs -ls /test/hello;
-- drwxr-xr-x - root supergroup 0 2021-01-03 14:26 /test/hello/employee
alter (database|schema) db_test set location 'hdfs://localhost:9000/test/hello1';
-- drop掉,然后dfs -ls /test/; 发现/test/hello1没了,但是/test/hello和底下的文件都还在
DROP DATABASE IF EXISTS db_test CASCADE;
dfs -ls /;
dfs -ls /test/;
dfs -ls /test/hello;
dfs -ls /test/hello1;
-- 结束这次实验
hadoop fs -rmr /test
删除库
-- 删除空数据库
DROP DATABASE IF EXISTS kegx_schema;
-- Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask.InvalidOperationException(message:Database kegx_schema is not empty. One or more tables exist.)
-- 避免数据库不存在而抛出警告信息
drop database if exists kegx_schema;
-- 删除非空数据库,cascade 强制删除。restrict(默认)不允许删除。
DROP DATABASE IF EXISTS kegx_schema CASCADE;
描述库
-- 查询数据库和表
show databases;
show tables;
-- 使用正则表达式:
show databases like '*关键字*';
DESC DATABASE kegx_schema;
--extended显示数据库详细信息
DESC DATABASE EXTENDED kegx_schema;
-- db_name,comment,location,owner_name,owner_type,parameters
-- kegx_schema,"",hdfs://localhost:9000/user/hive/warehouse/kegx_schema.db,root,USER,""
hadoop fs -ls /user/hive/warehouse
-- Found 1 items
-- drwxr-xr-x - root supergroup 0 2020-12-26 23:39 /user/hive/warehouse/student
表方面
前言
HIVE: 支持插入, 不支持删除和更新。
| 概念 | 解释 |
|---|---|
| 外部表、内部表 | 一般都使用外部表,因为外部表的删除不是真正的删除。 内部表(管理表)删除即真的删除了。尤其是这张表多个下游在用,只能是建立为外部表。 首先,未被external修饰的是内部表(managed table),被external修饰的为外部表(external table); 区别: 内部表数据由Hive自身管理,外部表数据由HDFS管理; 内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定; 删除内部表会直接删除元数据(metadata)及存储数据; 删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除; 对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;) |
创建表
•CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常
•EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
•LIKE 允许用户复制现有的表结构,但是不复制数据
•COMMENT可以为表与字段增加描述
•PARTITIONED BY 指定分区
•ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,
用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
•STORED AS
SEQUENCEFILE //序列化文件
| TEXTFILE //普通的文本文件格式
| RCFILE //行列存储相结合的文件
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname //自定义文件格式
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。
•LOCATION指定表在HDFS的存储路径
•CLUSTERED表示的是按照某列聚类,例如在插入数据中有两项“张三,数学”和“张三,英语”
若是CLUSTERED BY name,则只会有一项,“张三,(数学,英语)”,这个机制也是为了加快查询的操作。
-- 生成建表信息
show create table table_name;
实战
-- 创建客户信息表
create external table if not exists `kegx_schema.CUSTOMER_INFORMATION`(`ID` int comment '主键',`BATCH_DATETIME` TIMESTAMP comment '批次日期',`ECIF_NUMBER` STRING comment '企业客户信息整合号', `CUST_NUMBER` STRING comment '客户号',`CUST_ORGANIZATION_NUMBER` int comment '客户所属机构号',`CUST_ID_CARD_NUMBER` STRING comment '客户身份证号',`CUST_MAX_ARREARS` int comment '客户最大欠款额度',`CUST_NAME` string comment '客户名称',`CUST_ADDRESS` array comment '客户常用联系住址',`CUST_MAP` map comment '客户关系MAP',constraint CUSTOMER_information_pk primary key (ID) disable novalidate) comment '客户信息表'
partitioned by (BATCH_DATE string)
row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':'
TBLPROPERTIES ('creator'='kgx','crate_time'='2021-01-01');
-- 复制客户信息表
CREATE TABLE IF NOT EXISTS kegx_schema.test AS SELECT * FROM `kegx_schema.CUSTOMER_INFORMATION` ; //-- 没有分隔符啥的,需要自己加row format,也不是非分区表
CREATE TABLE kegx_schema.test LIKE kegx_schema.CUSTOMER_INFORMATION;
-- 创建账户信息表
create external table if not exists `kegx_schema.ACCOUNT_INFORMATION`(
`ID` int comment '主键',`BATCH_DATETIME` TIMESTAMP comment '批次日期',`ECIF_NUMBER` STRING comment '企业客户信息整合号',
`ACCOUNT_NUMBER` STRING comment '账户号',`ACCOUNT_ORGANIZATION_NUMBER` int comment '账户所属机构号',ACCOUNT_TYPE STRING comment '账户类型',
`ACCOUNT_BALANCE` int comment '账户额度',`CUST_ADDRESS` array comment '客户当年各月的余额,如2020;1;2;3;4;5;6;7;8;9;10;11;12',
`OVERDUE_IN_THE_LAST_MONTH` string comment '最近一个月逾期情况',`OVERDUE_MAP` map comment '逾期情况MAP<近X月,欠款数>,如<-3,1000>近三个月欠款1000',
constraint account_information_pk primary key (ID) disable novalidate) comment '账户信息表'
partitioned by (BATCH_DATE string)
row format delimited fields terminated by ',' collection items terminated by ';' map keys terminated by ':'
TBLPROPERTIES ('creator'='kgx','crate_time'='2021-01-01');
-- 创建客户逾期信息表
create external table if not exists `kegx_schema.CUST_OVERDUE_INFO`(
`ID` int comment '主键',
`BATCH_DATETIME` TIMESTAMP comment '批次日期',
`ECIF_NUMBER` STRING comment '企业客户信息整合号',
`CUST_NUMBER` STRING comment '客户号',
`CUST_ORGANIZATION_NUMBER` INT comment '客户所属机构号',
`OVERDUE_IN_THE_LAST_MONTH` STRING comment '最近一个月逾期情况',
`OVERDUE_IN_THE_LAST_THREE_MONTH` STRING comment '最近三个月逾期情况',
`OVERDUE_IN_THE_LAST_SIX_MONTH` STRING comment '最近六个月逾期情况',
`OVERDUE_IN_FUTURE` DECIMAL(22,2) comment '未来一个月预测的逾期情况,=最近一个月逾期情况X70%+最近三个月逾期情况X20%+最近六个月逾期情况X10%',
constraint cust_overdue_info_pk primary key (ID) disable novalidate) comment '客户逾期信息表'
partitioned by (BATCH_DATE string)
row format delimited fields terminated by ',' collection items terminated by ';' map keys terminated by ':'
TBLPROPERTIES ('creator'='kgx','crate_time'='2021-01-01');
插入表
创建数据
-- 创建数据
[root@localhost kegx_workspace]# vim data_CUSTOMER_INFORMATION.txt
1,2021-01-02 21:16:15,ecif20210010000001,2333000000199603010919,156,440883199603010919,20000,柯小鑫,广东省广州市-广东省佛山市-天津市,father:柯爸爸-mother:柯妈妈
2,2021-01-02 21:16:15,ecif20210010000002,2333000000199603010919,156,440883199603010919,20000,野比大雄,广东省广州市-广东省佛山市-天津市,father:野比二柱子-mother:野比妈妈
[root@localhost kegx_workspace]# cat data_CUSTOMER_INFORMATION.txt
[root@localhost kegx_workspace]# touch data_ACCOUNT_INFORMATION.txt
[root@localhost kegx_workspace]# chmod 777 data_ACCOUNT_INFORMATION.txt
[root@localhost kegx_workspace]# vim data_ACCOUNT_INFORMATION.txt
1,2021-01-03 15:35:15,ecif20210010000001,233300000019960301091901,156,1,10000,2020;0;0;0;0;0;0;0;0;0;0;100000,0,-1:10;-3:0;-6:0;-12:0;-18:0;-24:0
2,2021-01-03 15:35:15,ecif20210010000001,233300000019960301091902,156,2,20000,2020;0;0;0;1000000;100000;0;0;0;0;0,0,-1:0;-3:0;-6:0;-12:0;-18:0;-24:0
3,2021-01-03 15:35:15,ecif20210010000002,233300000019960301091901,156,1,10000,2020;0;0;0;0;0;0;0;0;0;0;0;10000,0,-1:0;-3:0;-6:0;-12:0;-18:0;-24:0
4,2021-01-03 15:35:15,ecif20210010000002,233300000019960301091902,156,2,30000,2020;0;10000;0;10000;0;0;0;0;0;0;0;10000,0,-1:5;-3:10;-6:0;-12:0;-18:0;-24:0
5,2021-01-03 15:35:15,ecif20210010000002,233300000019960301091903,156,3,30000,2020;0;10000;0;0;0;0;10000;0;0;0;0;10000,0,-1:0;-3:0;-6:0;-12:0;-18:0;-24:0
[root@localhost kegx_workspace]# cat data_ACCOUNT_INFORMATION.txt
插入数据
-- hive中加载数据:local模式,载入数据
hive> load data local inpath '/app/kegx_workspace/data_CUSTOMER_INFORMATION.txt' overwrite into table kegx_schema.CUSTOMER_INFORMATION partition (BATCH_DATE='20210102');
-- 非local模式,载入数据
hadoop fs -put /app/kegx_workspace/data_CUSTOMER_INFORMATION.txt /user/hive/warehouse/kegx_schema.db/CUSTOMER_information
描述表
describe kegx_schema.CUSTOMER_INFORMATION;
describe extended kegx_schema.CUSTOMER_INFORMATION;
desc kegx_schema.CUSTOMER_INFORMATION;
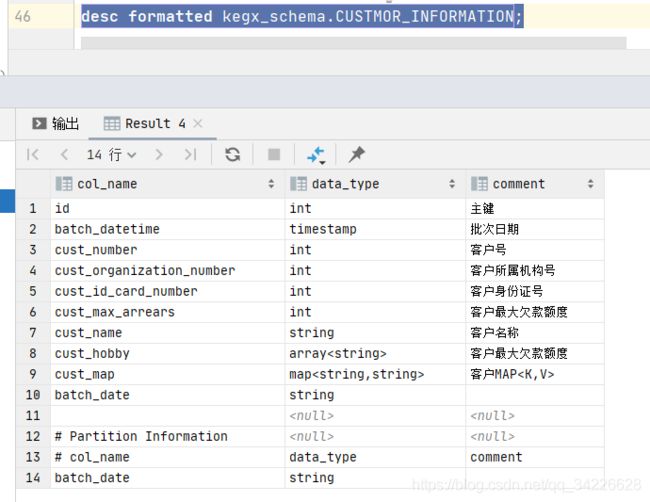
desc formatted kegx_schema.CUSTOMER_INFORMATION;
# col_name data_type comment
id int 主键
batch_datetime timestamp 批次日期
cust_number int 客户号
cust_organization_number int 客户所属机构号
cust_id_card_number int 客户身份证号
cust_max_arrears int 客户最大欠款额度
cust_name string 客户名称
cust_hobby array 客户最大欠款额度
cust_map map 客户MAP
# Partition Information
# col_name data_type comment
batch_date string
# Detailed Table Information
Database: kegx_schema
OwnerType: USER
Owner: root
CreateTime: Sat Jan 02 20:44:38 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://localhost:9000/user/hive/warehouse/kegx_schema.db/CUSTOMER_information
Table Type: EXTERNAL_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
EXTERNAL TRUE
bucketing_version 2
comment 客户信息表
crate_time 2020-02-29
creator kgx
numFiles 0
numPartitions 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1609591478
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
collection.delim -
field.delim ,
mapkey.delim :
serialization.format ,
# Constraints
# Primary Key
Table: kegx_schema.CUSTOMER_information
Constraint Name: CUSTOMER_information_pk
Column Names: id
Time taken: 0.779 seconds, Fetched: 58 row(s)
#
describe extended kegx_schema.CUSTOMER_INFORMATION;
id int 主键
batch_datetime timestamp 批次日期
cust_number string 客户号
cust_organization_number int 客户所属机构号
cust_id_card_number string 客户身份证号
cust_max_arrears int 客户最大欠款额度
cust_name string 客户名称
cust_address array 客户常用联系住址
cust_map map 客户关系MAP
batch_date string
# Partition Information
# col_name data_type comment
batch_date string
Detailed Table Information
Table(tableName:CUSTOMER_information, dbName:kegx_schema, owner:root, createTime:1609639985, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:主键),
FieldSchema(name:batch_datetime, type:timestamp, comment:批次日期), FieldSchema(name:cust_number, type:string, comment:客户号), FieldSchema(name:cust_organization_number, type:int, comment:客户所属机构号), FieldSchema(name:cust_id_card_number, type:string, comment:客户身份证号), FieldSchema(name:cust_max_arrears, type:int, comment:客户最大欠款额度), FieldSchema(name:cust_name, type:string, comment:客户名称), FieldSchema(name:cust_address, type:array, comment:客户常用联系住址), FieldSchema(name:cust_map, type:map, comment:客户关系MAP), FieldSchema(name:batch_date, type:string, comment:null)],
location:hdfs://localhost:9000/user/hive/warehouse/kegx_schema.db/CUSTOMER_information, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{mapkey.delim=:, collection.delim=-, serialization.format=,, field.delim=,}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[FieldSchema(name:batch_date, type:string, comment:null)], parameters:{creator=kgx, totalSize=166, EXTERNAL=TRUE, numRows=0, rawDataSize=0, crate_time=2021-01-01, numFiles=1, numPartitions=1, transient_lastDdlTime=1609639985, bucketing_version=2, comment=客户信息表}, viewOriginalText:null, viewExpandedText:null, tableType:EXTERNAL_TABLE, rewriteEnabled:false, catName:hive, ownerType:USER)
Constraints Primary Key for kegx_schema.CUSTOMER_information:[id], Constraint Name: CUSTOMER_information_pk
Time taken: 0.111 seconds, Fetched: 17 row(s)
删除表
删除外部表
-- 测试使用truncate命令删除外部表:
truncate table mytable;
#FAILED: SemanticException [Error 10146]: Cannot truncate non-managed table mytable. (state=,code=0)
-- 分析,查看表结构
describe extended tablename
desc formatted tablename;
-- 原因:truncate不能删除外部表,只能删除内部表
-- 删除外部表
-- (1)删除该表分区:
alter table tablename drop partition(load_date='2018-11-23',p_hou16);
-- (2)删除hdfs中的数据
hadoop fs -ls /home/tablename
-- (3)可以将外部表变为内部表,再删除内部表。不建议为了删除外部表而先将其转化为内部表,这样会将该表关联的HDFS路径中的数据也一并删除的。创建外部表的初衷并不是为了删除它,这只是为了删除数据的简单方式。
ALTER TABLE tablename SET TBLPROPERTIES('EXTERNAL'='False');
drop table tablename;
变更表
表本身属性层面
-- 表本身属性层面
-- 重命名表
ALTER TABLE table_name RENAME TO new_table_name;
ALTER TABLE kegx_schema.CUST_OVERDUE_INFO1 RENAME TO kegx_schema.CUST_OVERDUE_INF;
ALTER TABLE table_name SET TBLPROPERTIES table_properties table_properties:
:[property_name = property_value…..] -- 用户可以用这个命令向表中增加metadata
-- 添加表注释、修改表注释的语句相同.【注意】comment一定要是小写的,不能是COMMENT,且必须要【加单引号】!
-- 以下2个语句都正确:
ALTER TABLE table_name SET TBLPROPERTIES('comment' = '表的新注释');
alter table table_name set tblproperties('comment' = '表的新注释');
-- 语句不报错,但并不是修改表注释,只是在TBLPROPERTIES下新加了一个叫COMMENT的属性,用show create table能看到。
ALTER TABLE table_name SET TBLPROPERTIES('COMMENT' = '表的新注释');
-- 改变表文件格式与组织,这个命令修改了表的物理存储属性
ALTER TABLE table_name SET FILEFORMAT file_format
ALTER TABLE table_name CLUSTERED BY(userid) SORTED BY(viewTime) INTO num_buckets BUCKETS
-- 更改表的属性
alter table table_name set TBLPROPERTIES ('EXTERNAL'='TRUE') -- 内部表转内部表
alter table table_name set TBLPROPERTIES ('EXTERNAL'='FALSE') -- 外部表转内部表
-- 修改表的字节编码
alter table table_name set serdeproperties ('serialization.encoding'='utf-8');
-- 创建/删除视图
CREATE VIEW [IF NOT EXISTS] view_name [ (column_name [COMMENT column_comment], ...) ][COMMENT view_comment][TBLPROPERTIES (property_name = property_value, ...)] AS SELECT
•增加视图
•如果没有提供表名,视图列的名字将由定义的SELECT表达式自动生成
•如果修改基本表的属性,视图中不会体现,无效查询将会失败
•视图是只读的,不能用LOAD/INSERT/ALTER
•删除视图 DROP VIEW view_name
表字段层面
修改字段类型有诸多限制,格外注意,可能导致写入成功但查询失败。
-- 增加、删除分区
-- 增加
ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ...
partition_spec:
: PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
alter table kegx_schema.ACCOUNT_INFORMATION ADD IF NOT EXISTS partition(BATCH_DATE='20210104');
-- 如果存在就显示,如果不存在就不显示
show partitions kegx_schema.ACCOUNT_INFORMATION partition(BATCH_DATE='20210104');
-- 显示分区的详细信息,可以查看字段//Location: hdfs://localhost:9000/test
desc formatted kegx_schema.ACCOUNT_INFORMATION partition(BATCH_DATE='20210104');
-- 删除 ALTER TABLE table_name DROP partition_spec, partition_spec,...
alter table kegx_schema.ACCOUNT_INFORMATION drop partition(BATCH_DATE='20210103');
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
-- 【建议】别用id来玩
ALTER TABLE kegx_schema.ACCOUNT_INFORMATION CHANGE COLUMN id sub_id String COMMENT '备用主键';
ALTER TABLE kegx_schema.ACCOUNT_INFORMATION partition(BATCH_DATE='20210103') CHANGE COLUMN id sub_id String COMMENT '备用主键';
-- 修改内部表的字段长度
alter table kegx_schema.CUST_OVERDUE_INFO change OVERDUE_IN_FUTURE OVERDUE_IN_FUTURE DECIMAL(25,2);
alter table kegx_schema.CUST_OVERDUE_INFO change column OVERDUE_IN_FUTURE at DECIMAL(22,2);
ALTER TABLE table_name [PARTITION partition_spec] ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) [CASCADE|RESTRICT]
-- ADD是代表新增一字段,字段位置在所有列后面(partition列前) REPLACE则是表示替换表中所有字段。最后添加CASCADE倾泻、串联,否则新增的列在旧分区中不可见,查询数据时为NULL,重新刷数据时仍为NULL。相似问题见:hive分区表增加字段新增字段值为空的bug
-- 表添加一列
ALTER TABLE table_name ADD COLUMNS (new_col INT);
-- 表添加一列并增加列字段注释
ALTER TABLE table_name ADD COLUMNS (new_col INT COMMENT 'a comment');
desc table_name partition(BATCH_DATE='某一分区');// -- 未看到增加的字段,但是select 无论带不带分区都能看到新字段
desc table_name;// -- 增加了字段
ALTER TABLE table_name ADD COLUMNS (new_col1 INT COMMENT 'a comment') CASCADE;
-- 表删除一列,删除一个字段
不支持
-- 删除字段(使用新schema表结构替换原有的)
ALTER TABLE table_name REPLACE COLUMNS(id BIGINT, name STRING);
-- 记得最后加上CASCADE,然后desc table_name可见表结构变了,但是底层的数据没有丢失。dfs -ls 或者hadoop fs -ls
-- 更新列
alter table table_name replace columns (column_new_name new_type COMMENT col_comment);
补充【重要】
[COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
This command will allow users to change a column’s name, data type, comment, or position, or an arbitrary 任意 combination组合 of them. The PARTITION clause is available in Hive 0.14.0 and later; see Upgrading Pre-Hive 0.13.0 Decimal Columns for usage. A patch for Hive 0.13 is also available (see HIVE-7971).
The CASCADE|RESTRICT clause is available in Hive 1.1.0. ALTER TABLE CHANGE COLUMN with CASCADE command changes the columns of a table’s metadata, and cascades the same change to all the partition metadata. RESTRICT is the default, limiting column change only to table metadata.
ALTER TABLE CHANGE COLUMN CASCADE clause条款、分句 will override the table partition’s column metadata regardless of the table or partition’s protection mode. Use with discretion慎重.
The column change command will only modify Hive’s metadata, and will not modify data不会修改底层数据. Users should make sure the actual data layout of the table/partition conforms with the metadata definition定义.
Example:
CREATE TABLE test_change (a int, b int, c int);
// First change column a's name to a1.
ALTER TABLE test_change CHANGE a a1 INT;
// Next change column a1's name to a2, its data type to string, and put it after column b.
ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;
// The new table's structure is: b int, a2 string, c int.
// Then change column c's name to c1, and put it as the first column.
ALTER TABLE test_change CHANGE c c1 INT FIRST;
// The new table's structure is: c1 int, b int, a2 string.
// Add a comment to column a1
ALTER TABLE test_change CHANGE a1 a1 INT COMMENT 'this is column a1';
实验
-- 复制客户信息表
CREATE TABLE IF NOT EXISTS kegx_schema.test AS SELECT * FROM `kegx_schema.CUSTOMER_INFORMATION` ; //没有分隔符啥的,也不是非分区表
CREATE TABLE kegx_schema.test LIKE kegx_schema.CUSTOMER_INFORMATION;
load data local inpath '/app/kegx_workspace/data_CUSTOMER_INFORMATION.txt' overwrite into table kegx_schema.test partition (BATCH_DATE='20210103');
show partitions kegx_schema.test;
show partitions kegx_schema.test partition (BATCH_DATE='20210103');
load data local inpath '/app/kegx_workspace/data_CUSTOMER_INFORMATION.txt' overwrite into table kegx_schema.test;
select * from kegx_schema.test limit 20;
select * from kegx_schema.test where BATCH_DATE='20210103' limit 20;
truncate table kegx_schema.test;
// 创建测试表
drop table kegx_schema.test;
CREATE TABLE IF NOT EXISTS kegx_schema.test (id BIGINT, name STRING);
desc formatted kegx_schema.test;
desc formatted kegx_schema.test partition (BATCH_DATE='20210103');
dfs -ls /user/hive/warehouse/kegx_schema.db/test;
dfs -cat /user/hive/warehouse/kegx_schema.db/test/data_CUSTOMER_INFORMATION.txt;
dfs -ls /user/hive/warehouse/kegx_schema.db/test/batch_date=20210103;
dfs -cat /user/hive/warehouse/kegx_schema.db/test/batch_date=20210103/data_CUSTOMER_INFORMATION.txt;//-- 可见数据没丢
// 添加字段
ALTER TABLE kegx_schema.test ADD COLUMNS(t_1 STRING) CASCADE ;
// 删除字段(使用新schema替换原有的)
ALTER TABLE kegx_schema.test REPLACE COLUMNS(id BIGINT, name STRING) CASCADE;
select * from kegx_schema.test where BATCH_DATE='20210103' limit 20;// -- 因为新的表结构(hive称为schema)id BIGINT, name STRING所以select 出来就是 `ID` int comment '主键',`BATCH_DATETIME` TIMESTAMP comment '批次日期',即第一个第二列的值
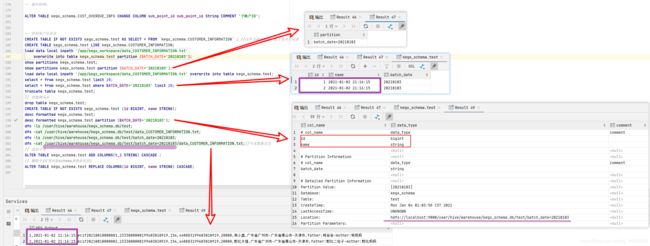
实验
-- 让某个分区表的数据到一个不合法的路径
alter table kegx_schema.ACCOUNT_INFORMATION ADD IF NOT EXISTS partition(BATCH_DATE='20210104') LOCATION 'hdfs://localhost:9000/test/';
show partitions kegx_schema.ACCOUNT_INFORMATION partition(BATCH_DATE='20210104');//-- 如果存在就显示,如果不存在就不显示
desc formatted kegx_schema.ACCOUNT_INFORMATION partition(BATCH_DATE='20210104');//-- 显示分区的详细信息,可以查看字段//Location: hdfs://localhost:9000/test
alter table kegx_schema.ACCOUNT_INFORMATION drop partition(BATCH_DATE='20210104');
load data local inpath '/app/kegx_workspace/data_ACCOUNT_INFORMATION.txt' overwrite into table kegx_schema.ACCOUNT_INFORMATION partition (BATCH_DATE='20210104');
dfs -ls /;
dfs -ls /test;//-- hadoop fs -ls /test//也看不到数据,但是就是能select 出来
dfs -rmr /test;
select * from `kegx_schema.ACCOUNT_INFORMATION` AS a where BATCH_DATE='20210104' limit 10;
在此特地的提一下 “desc formatted test partition(ds=20190903);” 这个SQL,为什么呢?
可能有人会问,记这些有啥用,等你被坑的时候,你就知道了?
我来介绍一下这个坑,其实也不是坑吧,个人认为就是有一点不合理,怎么说呢?对于OLAP来讲,确实增减字段不是很厚道,但是大部分业务会有这样的场景,比如A表里面有10个字段,我需要临时加一个字段,怎么办?
加个字段呗? alter table test add columns(age int); – 非分区表,正常的
BUT常用的是分区表,不可行,常见的一个现象就是,导入导出、查询分区表的数据的时候,会出现某一列无数据,有时候报错,慌不?查看创表语句发现,确实加上了字段了呀,但是就是无法进行导出操作?报不存在字段,慌不?
不要慌:其实是你操作不对,也不算是Hive的bug吧,Hive已经提供了解决方案,如下:
示例:alter table test_partition partition(year=2018) add columns(age int); – 往 year=2018 分区里面添加字段
这样写,只能针对与一个分区,进行添加字段,能批量对历史分区也加上字段么?
示例:alter table table_for_test_add_column add columns (added_column string COMMENT ‘新添加的列’) CASCADE;
那么我们就可以继续happy的玩耍了~ 验证各种操作都正常~
分区操作
分区操作
1)修改分区名
alter table table_name partition(dt='partition_old_name') rename to partition(dt='partition_new_name')
2)修改分区属性
alter table table_name partition column (dt partition_new_type)
3)修改分区位置
alter table table_name partition (createtime='20190301') set location "new_location"
4)添加分区
alter table table_name add partition (partition_name = 'value') location '***'
--示例
alter table table_name add IF NOT EXISTS partition (createtime='20190301') location '/user/hive/warehouse/testdw/js_nk_wn'
--还可以同时添加多个分区,只需要在后面继续追加就行
alter table table_name add partition (createtime='20190301') location '/user/hive/warehouse/dept_part' partition (createtime='20190228') location '/user/hive/warehouse/dept_part'
5)删除分区
--删除一级分区
alter table table_name drop if exists partition(createtime='20190301')
--删除二级分区
alter table table_name drop if exists partition (month='02',day='12')
查询表
--
show partitions kegx_schema.CUSTOMER_INFORMATION;
--
select * from `kegx_schema.CUSTOMER_INFORMATION` AS a where BATCH_DATE='20210103' limit 10;
报错汇总
问题排查的思路:查看hive.log.本人用ROOT用户,所以地址是/tmp/root/hive.log
其中我用的是root用户,建议参考我的onenote笔记。
Mysql方面
#hive元数据
CREATE DATABASE db_hive;
drop table user_test;
create table user_test
(
id int auto_increment comment 'id' primary key,
username varchar(50) null comment '用户名称',
sex varchar(5) null,
address varchar(100) null,
birthday datetime not null
)
charset = utf8;
select * from kgxdb.user_test limit 20;
# mysql 寻找hive元数据的信息,例如为啥中文乱码
# 但是在这里要非常严重强调的一点:hive的元数据metastore在mysql的数据库,不管是数据库本身,还是里面的表编码都必须是latin1(CHARACTER SET latin1 COLLATE latin1_bin)!!!!!
# 验证方式:(可以通过客户端软件在数据库上右键属性查看,也可以通过命令查看)
show create database db_hive;
# db_hive,CREATE DATABASE `db_hive` /*!40100 DEFAULT CHARACTER SET utf8 */ /*!80016 DEFAULT ENCRYPTION='N' */
hive的元数据metastore
#hive系统表(hive的元数据metastore)
-- ①修改表字段注解和表注解
alter table db_hive.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table db_hive.TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
-- ②修改分区字段注解:
alter table db_hive.PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table db_hive.PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
-- ③修改索引注解:
alter table db_hive.INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
select * from db_hive.COLUMNS_V2;
函数方面
show functions '';
show functions like '*crypt*';
desc function aes_encrypt;
desc function extended aes_encrypt;
-- y6Ss+zCYObpCbgfWfyNWTw==
SELECT base64(aes_encrypt('ABC', '1234567890123456'));
-- 模糊查询函数名
show functions "a.*";
show functions "a.";// -- SHOW FUNCTIONS is deprecated不赞成, please use SHOW FUNCTIONS LIKE instead.
show functions "ab.";
show functions ".s";
show functions "*.s";
show functions ".bs";
-- 模糊查询表名
show tables "*.test.*"
-- 该语句输出匹配正则表达式的自定义和内置的函数,使用’.*’输出所有函数。需要注意的是正则表达式中必须要有点号,否则不会匹配成功
UDF
--extended显示数据库详细信息
DESC DATABASE EXTENDED db_test;
default,Default Hive database,hdfs://localhost:9000/user/hive/warehouse,public,ROLE,""
DESC DATABASE EXTENDED default;
create table student(id int,name string,sex string);
Shell命令
dfs
hive (default)> dfs -ls /;
![-cat [-ignoreCrc] …]
等价于没有进入hive控制台的命令
hive> !pwd;
/app/apache-hive-3.1.2-bin/bin
hive> !ls -lrt;
total 52
-rwxr-xr-x. 1 root root 884 Aug 23 2019 schematool
-rwxr-xr-x. 1 root root 832 Aug 23 2019 metatool
-rwxr-xr-x. 1 root root 3064 Aug 23 2019 init-hive-dfs.sh
-rwxr-xr-x. 1 root root 880 Aug 23 2019 hplsql
-rwxr-xr-x. 1 root root 885 Aug 23 2019 hiveserver2
-rwxr-xr-x. 1 root root 1900 Aug 23 2019 hive-config.sh
-rwxr-xr-x. 1 root root 881 Aug 23 2019 beeline
-rwxr-xr-x. 1 root root 10158 Aug 23 2019 hive
drwxr-xr-x. 3 root root 4096 Dec 26 19:02 ext
-rw-------. 1 root root 6797 Dec 27 00:56 nohup.out
hive> !tail -5f nohup.out;
OK
OK
OK
OK
OK
引文
后记
解决hive中文显示乱码
参考文章https://www.cnblogs.com/DreamDrive/p/7469476.html
因为我们知道 metastore 支持数据库级别,表级别的字符集是 latin1,那么我们只需要把相应注释的地方的字符集由 latin1 改成 utf-8,就可以了。用到注释的就三个地方,表、分区、视图。如下修改分为两个步骤:
(1)、进入数据库 Metastore 中执行以下 5 条 SQL 语句
-- ①修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
-- ② 修改分区字段注解:
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
-- ③修改索引注解:
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
(2)、修改 metastore 的连接 URL,即hive-site.xml。
cd /app/apache-hive-3.1.2-bin/conf
vim hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://IP:3306/db_name?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
其中遇到报错,Xml文件中不能使用&,要使用他的转义&来代替。
Caused by: com.ctc.wstx.exc.WstxUnexpectedCharException: Unexpected character '=' (code 61); expected a semi-colon after the reference for entity 'characterEncoding'
Xml文件中不能使用&,要使用他的转义&来代替。
测试结果:

以上就能完美的解决这个问题.
未消化,还需要阅读
创建/删除函数
创建暂时函数
以下的语句创建由class_name实现的暂时函数,该函数被创建后仅仅能够在当前会话中使用。会话结束后函数失效。
实现函数的类能够是Hive类路径中的随意类。能够使用Add Jar语句向Hive类路径加入类。
CREATE TEMPORARY FUNCTION function_name AS class_name
删除暂时函数
使用以下的语句能够删除当前会话中的暂时函数:
DROP TEMPORARY FUNCTION [IF EXISTS] function_name
创建永久函数
在Hive-0.13版本号及之后的版本号中,自己定义函数能够被注冊到元存储中,这样用户能够在每次会话中都引用函数而不必每次都创建函数。以下是创建永久函数的语句:
CREATE FUNCTION[db_name.]function_name AS class_name [USINGJAR|FILE|ARCHIVE 'file_uri' [, JAR|FILE|ARCHIVE 'file_uri'] ]
在该语句中能够使用USING从句加入Jar文件、普通文件或者归档文件,当函数第一次使用时,这些文件将会加入到Hive环境中。
若Hive不是以本地模式执行,file_uri是非本地URI,比方能够使HDFS路径。
能够使用參数hive.exec.mode.local.auto设置本地模式,将该參数的值设置为true则为本地模式,默觉得false。假设指定了db_name,则函数将加入到指定的数据库,否则加入到当前数据库。引用当前数据库中的函数仅仅需指定函数名,引用非当前数据库中的函数则须要使用全限定函数名db_name. function_name。
删除永久函数
删除永久函数的语句为:
DROP FUNCTION[IF EXISTS] function_name
Show语句
在前面学习各种DDL语句时,已经或多或少的使用了一些show语句。比方show databases、show tables等。以下将会系统全面地学习各种show语句。
Show Databases
完整的show databases语句例如以下,还能够使用LIKE从句利用正則表達式对数据库进行过滤,只是通配符仅仅能是*(随意字符)或者|(其他选择),通配符须要使用单引號。
SHOW (DATABASES|SCHEMAS) [LIKE identifier_with_wildcards];
演示代码例如以下:
hive> show databases like 'lea*';
OK
learning
Time taken:0.304 seconds, Fetched: 1 row(s)
hive> show schemas like 'lea*';
OK
learning
Time taken:0.223 seconds, Fetched: 1 row(s)
Show Tables
Show Tables
SHOW TABLES [IN database_name] [identifier_with_wildcards];
该语句列出当前数据库中全部的表和视图。若使用IN从句则列出指定数据库中的全部表和视图,还能够使用正則表達式进行过滤,通配符和show databases中的通配符使用同样的规则,即仅仅能使用*和|。表和视图依照字母顺序列出。
show Partitions
SHOW PARTITIONS table_name [PARTITION(partition_desc)]
该语句以字母顺序列出指定表中的全部分区。还能够通过指定部分分区来过滤结果集:
hive> show partitions people;
OK
department=1/sex=0/howold=23
Time taken: 4.75seconds, Fetched: 1 row(s)
hive> show partitions people partition(department='1');
OK
department=1/sex=0/howold=23
Time taken:0.716 seconds, Fetched: 1 row(s)
hive> show partitions people partition(department='2');
OK
Time taken:0.376 seconds
从Hive-0.13版本号開始还能够指定数据库:
hive> show partitions learning.people;
OK
department=1/sex=0/howold=23
Time taken: 0.25seconds, Fetched: 1 row(s)
Show Table/Partition Extended
SHOW TABLE EXTENDED[IN|FROM database_name] LIKE identifier_with_wildcards [PARTITION (partition_desc)]
该语句列出匹配正則表達式的全部表的信息。假设指定了PARTITION从句则不能使用正則表達式。该语句的输出包含基础表信息和文件系统信息,如totalNumberFiles,totalFileSize, maxFileSize, minFileSize,lastAccessTime和 lastUpdateTime。假设使用了PARTITION则输出指定分区的文件系统信息。
Show Table Properties
SHOW TBLPROPERTIES table_name;
SHOW TBLPROPERTIES table_name (‘属性名’);
上面的第一个语句以每行一个的格式列出表table_name全部属性,属性和属性值之间以tab分隔。第二个语句输出指定属性的值。
hive> show tblproperties table_properties;
OK
numFiles 0
last_modified_by hadoop
last_modified_time 1402456050
COLUMN_STATS_ACCURATE false
transient_lastDdlTime 1402456050
comment learning alter properties
numRows -1
totalSize 0
telephone 1234567
rawDataSize -1
Time taken:0.247 seconds, Fetched: 10 row(s)
hive> show tblproperties table_properties('telephone');
OK
1234567
Time taken:0.355 seconds, Fetched: 1 row(s)
Show Create Table
SHOW CREATETABLE ([db_name.]table_name|view_name)
该语句输出创建指定表或者视图的语句。例如以下:
hive> show create table people;
OK
CREATE TABLE `people`(
`name` string,
`age` int,
`mobile` string COMMENT 'change column name',
`birthday` date,
`address` string)
PARTITIONED BY (
`department` string,
`sex` string,
`howold` int)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED ASINPUTFORMAT
'org.apache.hadoop.mapred.SequenceFileInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.mapred.SequenceFileOutputFormat'
LOCATION
'hdfs://hadoop:9000/user/hive/warehouse/learning.db/people'
TBLPROPERTIES (
'last_modified_by'='hadoop',
'last_modified_time'='1402539133',
'transient_lastDdlTime'='1402539133')
Time taken:0.477 seconds, Fetched: 22 row(s)
Show Indexes
SHOW [FORMATTED](INDEX|INDEXES) ON table_with_index [(FROM|IN) db_name]
该语句输出特定表上的全部索引信息,包含索引名称、表名、被索引的列名、保存索引的表名、索引类型和凝视。假设使用FORMATTED。会为上述信息加入列标题,例如以下图所看到的:
Show Columns
SHOW COLUMNS(FROM|IN) table_name [(FROM|IN) db_name]
该语句输出给定表中包括分区列的全部列:
hive> show columns in people;
OK
name
age
mobile
birthday
address
department
sex
howold
Time taken:0.493 seconds, Fetched: 8 row(s)
Show Functions
SHOW FUNCTIONS"a.*"
该语句输出匹配正則表達式的自己定义和内置的函数,使用’.*’输出全部函数。
需要注意的是正則表達式中必需要有点号,否则不会匹配成功,见以下的样例:
hive>show functions 'av*';
OK
Timetaken: 0.022 seconds
hive>show functions 'av.*';
OK
avg
Timetaken: 0.039 seconds, Fetched: 1 row(s)
Show Locks
SHOW LOCKS;
SHOW LOCKS EXTENDED;
SHOW LOCKS PARTITION ();
SHOW LOCKS PARTITION () EXTENDED;
上述语句显示表或者分区上的锁,当使用Hive事务时,上述语句返回以下的信息:
数据库名称
表名称
分区名称(若表存在分区)
锁的状态,能够是以下的一种:
获得:请求者拥有锁
等待:请求者等待锁
终止:锁已经超时但还未被清理
锁的类型。能够是以下的一种:
独占锁:其他不论什么用户不可在同一时间拥有该锁(大多数DDL语句使用该锁。如删除表)。
共享读锁:随意数量的共享读锁能够同一时候锁定同样的资源(读操作取得该锁,令人困惑的是,插入操作也取得共享读锁)。
共享写锁:随意数量的共享读锁能够同一时候锁定同样的资源。但其他共享写锁不同意锁定已经被共享写锁定的资源(更新和删除使用共享写锁)。
若存在与锁关联的事务,则显示其ID
锁的持有者最后一次发送心跳(表明其还存活)的时间
假设锁被获得,则显示获得锁的时间
请求锁的用户
用户执行的主机
Show Transactions
SHOW TRANSACTIONS
事务是在Hive-0.13版本号中引进的。管理员使用该语句查询当前打开或者终止的事务。包含例如以下信息:
事务ID
事务状态
启动事务的用户
事务启动时所在的主机
Show Compactions
SHOW COMPACTIONS
该语句显示当Hive事务被使用时,全部正在被压缩或者预定压缩的表和分区,包含以下的信息:
数据库名称
表名
分区名称(假设存在分区)
主压缩还是次要压缩
压缩的状态:
初始化:在队列中等待压缩
工作:正在被压缩
准备清除:压缩已经结束。旧文件被安排清除
假设处于工作状态,显示压缩线程的线程ID
假设处于工作状态或者准备清除状态。显示压缩開始的时间
Describe语句
Describe Database
DESCRIBE DATABASE db_name
该语句显示给定数据库的凝视(假设设置的话),在HDFS上的路径和数据库的拥有者。例如以下所看到的:
hive>describe database learning;
OK
learning hdfs://hadoop:9000/user/hive/warehouse/learning.db hadoop
Time taken:0.088 seconds, Fetched: 1 row(s)
hive>describe database default;
OK
default Default Hive database hdfs://hadoop:9000/user/hive/warehouse public
Time taken:0.216 seconds, Fetched: 1 row(s)
Describe Table/View/Column
DESCRIBE [EXTENDED|FORMATTED] [db_name.]table_name[DOT col_name ( [DOT field_name] |[DOT '$elem$'] | [DOT '$key$'] | [DOT '$value$'] )* ]
该语句显示给定表包含分区列在内的全部列,假设使用了extendedkeyword,则以Thrift序列化形式显示表的元数据,假设使用formattedkeyword,则以表格形式显示元数据。
假设表拥有复合类型的列,能够通过使用表名.复合列名('$elem$'用于数组,'$key$'用于map的键,'$value$'用于map的键值)查看该列的属性。对于视图DESCRIBE EXTENDED or FORMATTED能够用来获取视图的定义。两个相关的属性被提供:由用户指定的原始视图定义和由Hive内部使用的扩展定义。
Describe Partition
DESCRIBE [EXTENDED|FORMATTED] [db_name.]table_name PARTITION partition_spec
该语句显示指定分区列的元数据。
https://blog.csdn.net/qq_34226628/article/details/111737188 ↩︎