spacy处理流程
原生流程组件

流程是依次定义在模型的meta.json文件里面的,原生组件需要二进制数据来进行预测;
- 函数用来读取一个doc,修改并且返回它
- 可以利用
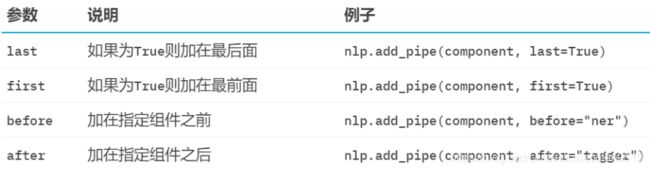
nlp.add_pipe来添加组件
def custom_component(doc):
#deal with doc
return doc
nlp.add_pipe(custom_component)
设置定制化属性
通过._属性来读取
doc._.title = "My document"
token._.is_color = True
span._.has_color = True
使用set_extension方法在全局Doc,Token或Span上注册;
from spacy.tokens import Doc, Token, Span
Doc.set_extension("title", default=None)
Token.set_extension("is_color", default=False)
Span.set_extension("has_color", default=False)
扩展属性类别
- 特性
from spacy.tokens import Token
Token.set_extension("is_color", default=False)
doc = nlp(text)
doc[2]._.is_color = True
- 属性
设置一个取值器(getter)和一个可选的赋值器(setter)函数;
取值器只有当你提取属性值的时候才会被调用;
from spacy.tokens import Token
def get_is_color(token):
colors = ["红色", "黄色", "蓝色"]
return token.text in colors
Token.set_extension("is_color", getter=get_is_color)
doc = nlp(text)
print(doc[2]._is_color, "-", doc[2].text)
- 方法
作为一个实例的方法引入一个函数;
可以向扩展函数中传入参数
from spacy.tokens import Doc
def has_token(doc, token_text):
in_doc = token_text in [token.text for token in doc]
return in_doc
Doc.set_extension("has_token", method=has_token)
doc = nlp(text)
处理大规模语料
使用nlp.pipe的方法;
在nlp.pipe中设置as_tuple=True,这样可以传入一些(text, context)的元组;
data = [(text, {"id": 1, "page_number": 15})]
for doc, context in nlp.pipe(data, as_tuple=True):
print(doc.text, context["page_number"])
from spacy.tokens import Doc
Doc.set_extension("id", default=None)
Doc.set_extension("page_number", default=None)
data = []
for doc, context in nlp.pipe(data, as_tuple=True):
doc._.id = context["id"]
doc._.page_number = context["page_number"]