将预训练模型应用于长文本阅读理解
摘要:
基于transformers预训练模型(如BERT、RoBERTa)的表现突出,预训练模型基本作为模型的baseline,但是由于self-attention的矩阵计算时间复杂度为 ,导致输入长度限制为512个token。面对长文本时,效果不如短文本表现得那么好。因此,本文从两个方面来提出解决方法。
,导致输入长度限制为512个token。面对长文本时,效果不如短文本表现得那么好。因此,本文从两个方面来提出解决方法。
我们小组的主题为长文本阅读理解,分别阅读了四篇papers。这些文章从不同方法提出了关于长文本阅读理解的解决方法。基于预训练模型Bert目前解决的方法如下:1.截断法,2.Pooling法,3.补充法,4.模型压缩法。
截断法和Pooling法都是比较直观的方法,应用比较广泛。而我们今天主要讨论以补充法和模型压缩法为主。
补充法:
《Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension》
Bert采用full self-attention这样获取的信息是最丰富,虽然有弊端,但是可能是相对较优解。因此有人不修改预训练模型,只是增加trick。第一篇文章来自ACL2020的《Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension》(这篇论文之前分享过,如果想了解更多详细的内容,点击链接)
论文提出通过增强学习让模型学习决定输入每段的长度。同时通过循环机制让每段文本流动,让机器做决定的时候可以参考除本段之外的信息。循环机制实现可使用gated recurrence和LSTM recurrence。通过上述方法可以在CoQA,QuAC以及TriviaQA数据集上取得较好的效果。
模型架构:
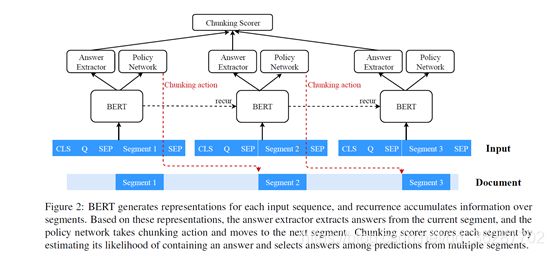
如上图所示,BERT生成每个输入句子的representation,利用了LSTM的循环机制,将前一个的输出作为当前的输入,获取到之前段落的信息。答案提取器利用之前块的信息和当前块的信息从当前段落中提取答案。策略网络通过强化学习来决定下一块的大小。最后将每个块提出的答案进行打分,选择分数最高的作为最终答案。
这里说下基于策略的强化学习(policy-based RL):
RL的思想是:环境environment输入给智能体agent一个状态s,agent根据策略![]() 做出一个行为a,然后得到环境给它的奖励r的同时环境转移到了下一个状态。
做出一个行为a,然后得到环境给它的奖励r的同时环境转移到了下一个状态。 为模型的参数。如下图所示
为模型的参数。如下图所示
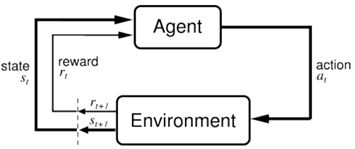
其中环境与智能体交互,环境给智能体的是状态和奖励,智能体做出的行为会改变环境的状态。所以我们要清楚状态、行为、奖励是什么:
1.状态是模型的输入,在本文中当然就是切割后的某一段文本片段segment
2.行为是模型的输出,本文的目的是让模型学会自己分割文章,那么输出的自然是下一次切分的滑动步长,行为空间定义为{-32,64,128,256,512} (这是论文中对CoQA数据集设定的action space)。
3.奖励是要预先定义好的,见论文的公式11,如下所示。
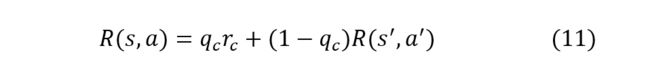
其中![]() 是模型预测当前segment包含答案的概率,它是由前一个segment的循环状态和当前segment的CLS的表示通过LSTM得到的。
是模型预测当前segment包含答案的概率,它是由前一个segment的循环状态和当前segment的CLS的表示通过LSTM得到的。![]() 是模型从当前的segment提取出答案位置的概率,
是模型从当前的segment提取出答案位置的概率,![]() 是未来的累计奖励。
是未来的累计奖励。
这里需要知道的是当前的segment包含有答案时,如果模型预测的当前segment包含答案的概率较高,也就是![]() 值比较高,那么当前状态下采取行为a的奖励主要是由
值比较高,那么当前状态下采取行为a的奖励主要是由![]() 决定的。
决定的。
而如果当前的segment没有包含答案,那么 ![]() =0,而如果模型预测当前segment包含答案的概率较小,也就是
=0,而如果模型预测当前segment包含答案的概率较小,也就是![]() 值比较小,那么
值比较小,那么![]() 比较大,所以当前状态采取行为a的奖励主要由未来的累计奖励决定。但是在
比较大,所以当前状态采取行为a的奖励主要由未来的累计奖励决定。但是在![]() =0的情况下,模型预测当前segment包含答案的概率较大,那么
=0的情况下,模型预测当前segment包含答案的概率较大,那么![]() 比较小,显然此时模型获得的奖励就比较少。
比较小,显然此时模型获得的奖励就比较少。
在循环切分机制当中,对于不包含有答案的segment,仍然会保留下来作为样本参与训练,因为整个切分过程是在一篇document上连续切分的,中间断了显然是不行的,而且我们需要让模型学会避免切分出这种不包含answer的segment。给一个例子,如下图所示。

红色字体代表的是answer,第一次切分时,固定到max_seq_length为止,也就是图片中的黄色部分,第二次切分时,向右滑动128个单词,滑动有点多,答案到右边界,也就是蓝色部分chunk 2,第三次切分下模型向左移动了16个单词,目的是使得第三个chunk包含答案更多的上下文,也就是图片中的橘色部分,显然这种切分方式比固定切分要好,而且固定的切分方式是不会向左移动的。
结果:
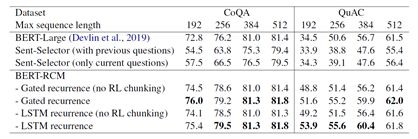
根据此表我们可以看出来,当最大长度max_seq_len限制为512的时候,其实这种循环切分的机制并没有比BERT-large有什么明显的效果,主要原因是,CoQA和QuAC数据集的文章大部分不是特别的长

根据上图我们了解到,CoQA和QuAC的训练集合的文章长度平均为352和516个单词,显然很多文章并不需要切分。因此Recurrent chunking机制发挥不了什么作用,但是随着最大长度的减小,比如,当最大长度限制为192的时候,也就是说当一篇文章会被切分成很多长度不超过192的segment的时候,循环切分的方式明显好于baseline。
下表是在TriviaQA数据集上的实验结果:
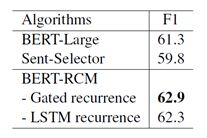
因为TriviaQA数据集比较长,max_seq_len固定为512的情况下,显然循环切分机制效果要好于baseline的,说明循环切分机制适用于处理长文本。
《CogLTX: Applying BERT to Long Texts》
当然也有人从其他角度来考虑不同处理方法,第二篇文章来自NIPS2020的《CogLTX: Applying BERT to Long Texts》,机构为清华大学、阿里巴巴。该论文受到人的认知过程启发,用类似的方法来处理长文本。如果将 BERT 的 512 输入字符限制比作人的工作记忆,那么既然人思考问题时能够找到关键的少量信息,并在工作记忆中推理出结果,BERT 的 512 也应该远远足够,关键是对于特定的问题,我们要最终用的是真正关键的那部分信息。(CogLTX: Cognize Long TeXts)
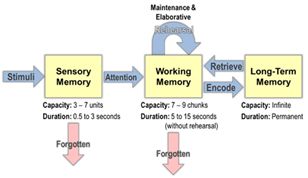
人脑的工作机制:
事实上,人脑正是通过回忆和注意力,协调长期记忆和短期记忆(工作记忆)的使用策略来完成对长文本的理解。下图是分层注意力机制的图解,工作记忆从当前的感知记忆空间或者长期记忆中抽取关键信息进行深层理解,然而这些信息如果没有被不断重演(rehearsal)就会在大约 5-15s 后逐渐忘掉,剩余的有用的信息来进行继续的推理。
因此,CogLTX 遵循一种特别简单直观的范式,即 抽取关键的句子 => 通过 BERT 得到答案 这样的两步流程。常见的几种任务都可以用这种范式来解决。比如下图列举了问答任务、文本分类任务、序列标注任务的处理方法。

MemRecall 关键信息抽取:
对于关键信息的认识本身也是智能的重要部分。最直观的想法是通过信息检索的办法(例如 BM25:文本相似度评分)来抽取关键句,但是仔细一想就会发现这其实是不可行的,因为下游任务的不确定性,无法建模成信息检索的形式。例如,文本分类任务如果用 BM25 去检索,则无法定义查询(query)是什么。因此抽取的模型也要与任务息息相关。
其次就是直接检索的方式过于粗糙,同时对于无法处理多跳推理的信息。而人在工作记忆中的思考是一个时序的过程,会不断忘记被错误检索的信息而将空间留给新信息。因此,我们模仿这样的过程设计了 MemRecall,其核心是一个对于每个字词进行相关度打分的评分(judge)模型,也用 BERT 实现。MemRecall 的过程如下图所示。

上图展示了MemRecall在QA的使用,x被分为40个blocks,第一步将 和
和![]() 放入z中经过筛选。在下一步
放入z中经过筛选。在下一步![]() 中的“old school”将有助于检索答案
中的“old school”将有助于检索答案![]() 。
。
首先假设:存在短文本![]() 可以完全表达原长文本
可以完全表达原长文本![]() 的语义:
的语义:

那么令![]() 代替
代替![]() 输入原来的模型即可,如何得到
输入原来的模型即可,如何得到![]()
1.先通过动态规划算法将长文本![]() 分割为
分割为![]() 。
。
2.使用MemRecall对原长句中的子句进行打分,MemRecall结构如图,而公式如下式:
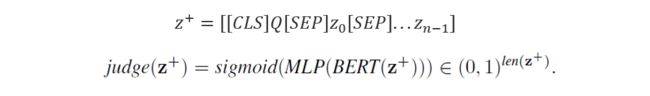
3.从而选择出分数最高的子句组成![]() 再进行训练,这样一来的话,CogLTX相当于使用了了两个bert,MemRecall中bert就是负责打分,另一个bert执行原本的NLP任务。
再进行训练,这样一来的话,CogLTX相当于使用了了两个bert,MemRecall中bert就是负责打分,另一个bert执行原本的NLP任务。

训练:
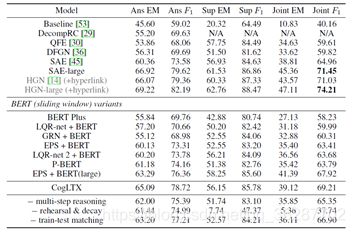
上图展示了在HotpotQA数据集上,CogLTX的表现是优于7个BERT的变体。SAE是优于CogLTX的,论文解释是SAE更适合HotpotQA但是SAE不能解决长文本的内存问题。
这篇文章的方法本质上仍然是一个先匹配检索再排序的方法。并没有直接解决bert的不能输入长文本的问题。
模型压缩法
接下来,介绍模型压缩法其实主要针对预训练模型的full self-attention进行修改,提出了稀疏化attention 矩阵,来提高模型的表现。
《Blockwise Self-Attention for Long Document Understanding》
首先介绍来自EMNLP2019的《Blockwise Self-Attention for Long Document Understanding》,机构为清华大学、Facebook AI。这篇论文在self-attention的基础上引入sparse block结构,如下图所示。
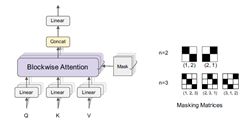
上图是Blockwise Multi-head Attention,关键思想是引入一个稀疏masking矩阵在 的attention矩阵。右边为masking矩阵,n为head数量,当n=2时,随机50%被设置为非0,n=3时,随机1/3被设置为0。(当然被mask的越多,占用的内存和计算时间就会变少。)
的attention矩阵。右边为masking矩阵,n为head数量,当n=2时,随机50%被设置为非0,n=3时,随机1/3被设置为0。(当然被mask的越多,占用的内存和计算时间就会变少。)

上图随着序列长度的增加,内存的变化情况。可以看到这样BlockBERT的占用的内存在比BERT确实少了很多。
在下游任务上,对长文本进行分块,步长为128。文本长度分为512和1024两种情况。模型效果如下。

其中,RoBERTa-1seq只是在MLM任务上进行预训练,RoBERTa-2seq在MLM和NSP两个任务上进行预训练。
在一些长文本数据集如SearchQA、HotpotQA上效果还算不错。虽然能够扩展输入的长度,有效减少内存消耗,但是最终表现提升并不是太明显。
思考:利用这样的稀疏masked方法是比较符合直觉的,主要的贡献是对减少内存消耗和运行时间都有很明显的效果,而对下游任务的表现并没有比baseline好太多。
《Longformer: The Long-Document Transformer》
因此,来自AI2的《Longformer: The Long-Document Transformer》这篇论文提出了longformer模型,将原本得self-attention改为局部attention加上基于任务的global attention(如分类只需要在[CLS]位置加上global attention),并将position embedding的长度增加,能够增加输入长度,在QA上效果超过了RoBERTa。
Attention Pattern:
分为三种方式:下图(a)为标准的attention矩阵
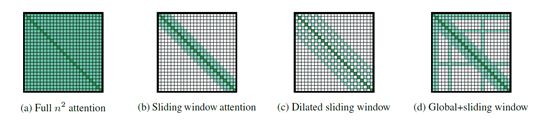
1.Sliding Window: 为上图(b)所示,使用一个固定大小的window attention,叠多层类似的window attention来扩大感受野。顶层可以访问所有输入位置,并且能够构建包含整个输入信息的representation,类似CNNs。对每一个token,只对其附近 个计算attention。复杂度为
个计算attention。复杂度为![]() 。
。 为输入长度。同时论文认为,根据任务不同,每层的窗口大小可以不同。
为输入长度。同时论文认为,根据任务不同,每层的窗口大小可以不同。
2.Dilated Sliding Window:为上图的(c)所示,空洞滑窗在cv一直应用,是为了扩大感受野。同理,论文为了给每个token扩大感受野,采用这种技术。间隔为 ,窗口为,感受野为
,窗口为,感受野为![]() 。即使用一个很小的可以将覆盖的token扩大成千上百。在多头attention中,不同head设置不同大小的间隔或者不带间隔,可以让有的head关注local context,有的head关注longer context。
。即使用一个很小的可以将覆盖的token扩大成千上百。在多头attention中,不同head设置不同大小的间隔或者不带间隔,可以让有的head关注local context,有的head关注longer context。
3.Global attention:为上图(d)所示,为了能够应对不同任务所需要的representation,在特定位置上引入了global attention,对于分类任务,只用在[CLS]上使用global attention,在QA中为question提供global attention。只是很少的位置上使用global,因此复杂度认为![]() .
.
预训练与Finetuning:
和Bert一样,Longformer也进行预训练能够更好适应长文本任务。最后模型可以处理4096个token的长度。
预训练使用masked language modeling(MLM),目的是为了预测那些随机被masked的token。因为MLM预训练很贵,在RoBERTa的基础上进行预训练。只做一些小的改变来支持Longformer的注意机制。同时Longformer的注意力机制可以插入任何其他预训练模型不用改变model结构。
Attention Pattern:
论文使用滑动窗口机制,window大小为512,之前使用空洞滑窗会降低性能。可能是因为不能匹配预训练RoBERTa的weights。
Position Embeddings:
RoBERTa使用的是绝对位置embeddings最大位置为512。为了支持长文本,论文将位置embeddings扩展为4096。初始化是将之前512个位置信息复制到4096的位置信息上。

MLM training:
Base和large模型,两个模型都训练65k个数据。Batch_size=64,lr=3e-5,linear warmup=500 steps。其他超参和RoBERTa一样。
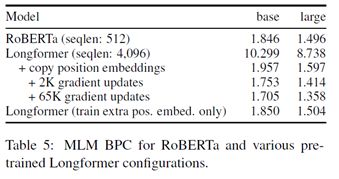
最后一层为冻结RoBERTa的参数只训练position embedding。
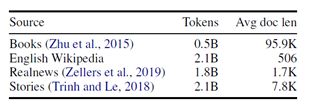
训练数据来源为:
下游任务:
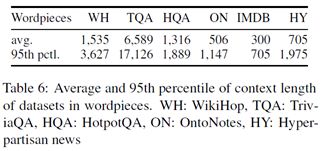
上图为数据集的平均长度和95%的长度。
MRC/QA任务:
针对WikiHop加一个classification layer 、TriviaQA使用loss function去预测answer span。对WikiHop的问题和答案应用global attention,对TriviaQA的问题应用global attention。
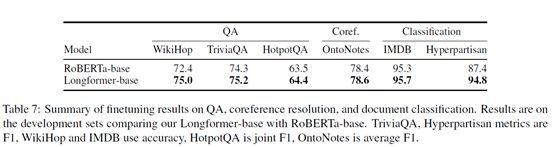
使用large在多个QA数据集取得SOTA结果
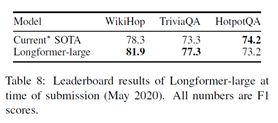
可以看到,该模型和第一篇文章有些类似,都是将self-attention稀疏化。但是Longformer不仅考虑到local attention也考虑了global attention,相对严谨一些。减少了内存消耗,同时修改了position embedding 扩展了输入的长度。
总结:
以上,本文探讨了四篇论文对MRC长文本的解决方法,主要从两大方面进行考虑。看到当前处理长文本的不同思考方式,从最开始的切分分块、增加trick、对self-attention进行修改、对position embedding进行扩展。可能对position embedding进行扩展会是之后一种较为流行的方法,扩展的方式除了不断复制进行扩展,可能也会有其他更好的扩展方式。比如苏剑林提出的层次分解位置编码。