python实现爬取微博相册所有图片
微博相册的批量爬取
文章目录
- 前言
- 一、分析实现思路
- 二、编写代码
-
- 1.引入库
- 2.多进程的编写
- 3.主函数的编写
- 结果
前言
微博有相册功能,那么我们如何批量下载相册中的所有照片呢?
提示:以下是本篇文章正文内容,下面案例可供参考
一、分析实现思路
因为微博相册也是前后端分离,所以我们先去抓包对应的json数据
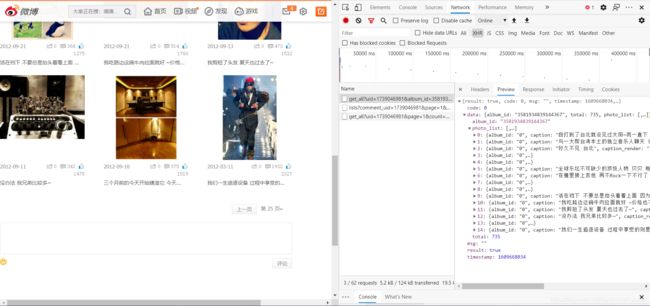
这里以李荣浩的相册为例,一共有25页:
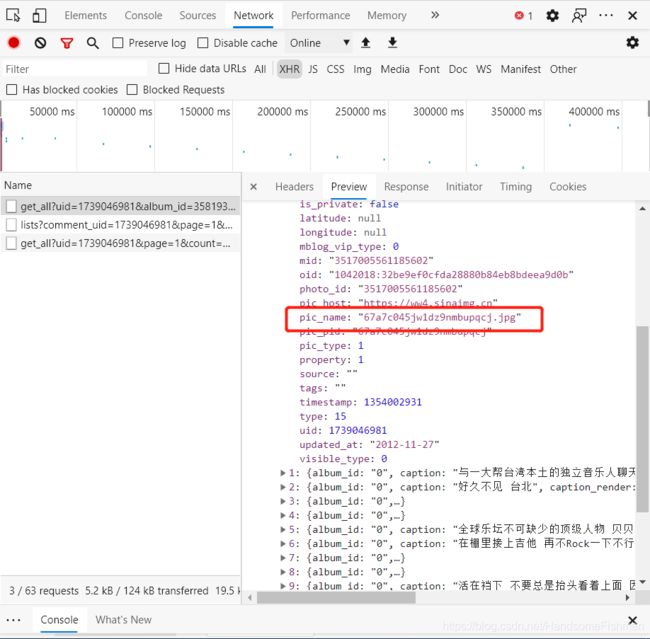
分析得出实际的链接应该为:‘https://wx4.sinaimg.cn/large/’ + pic_name
再来看看链接循环爬取的分析

这里只需要更改page的值即可实现循环爬取
二、编写代码
1.引入库
代码如下:
from fake_useragent import UserAgent # 伪装机型
from threading import Thread # 多进程
from queue import Queue # 队列
import requests
import random
headers = {
# cookie 每天会变化,需要即使更换
'cookie': 'SINAGLOBAL=74744724261.95033.1605948585466; wvr=6; '
'SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9Whrq6C5pCwQBNf5XnQhDpfE5JpX5KMhUgL.Fo'
'-cehB7eoqpSKM2dJLoIEBLxKBLBonL12BLxKqL1KnL12-LxKnLBKML1h.LxKMLBKqLB.zt; ALF=1641197487; '
'SSOLoginState=1609661488; '
'SCF=AqFdnOicaqrQ3UjYRBY-C8Kp3PwjrkfR1lPLA0W8mjbwb9rIU1MBf0l9kWk3ahdAXFldqtvqcZ7UW_ehPXfM1JE.; '
'SUB=_2A25y9QxgDeRhGeNI61YR8ijNzjuIHXVRg3qorDV8PUNbmtAKLVTukW9NSH08UxX8Md1T1NOxjdEP88XVg1aJmi7t; '
'_s_tentry=login.sina.com.cn; Apache=9994350802777.143.1609661492706; '
'ULV=1609661492740:9:6:2:9994350802777.143.1609661492706:1609657348149; UOR=,,www.baidu.com; '
'webim_unReadCount=%7B%22time%22%3A1609666074015%2C%22dm_pub_total%22%3A0%2C%22chat_group_client%22%3A0'
'%2C%22chat_group_notice%22%3A0%2C%22allcountNum%22%3A3%2C%22msgbox%22%3A0%7D; '
'WBStorage=8daec78e6a891122|undefined',
# 从哪里来
'referer': 'https://photo.weibo.com/6816603335/talbum/index',
# 伪装头
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66 ',
}
# 下载时图片的伪装头
fake = {
'User-Agent': UserAgent().random
}
# ip代理池
proxy_pool = [{
'HTTP': '183.166.70.110:9999'}, {
'HTTP': '58.22.177.215:9999'}, {
'HTTP': '175.44.109.28:9999'},
{
'HTTP': '175.42.128.211:9999'}, {
'HTTP': '113.121.76.254:9999'}, {
'HTTP': '175.42.122.166:9999'},
{
'HTTP': '175.42.122.233:9999'}, {
'HTTP': '113.121.42.214:9999'}, {
'HTTP': '113.195.152.127:9999'},
{
'HTTP': '175.42.129.78:9999'}, {
'HTTP': '171.35.213.172:9999'}, {
'HTTP': '113.121.37.163:9999'}]
# 访问json数据的url
url = 'https://photo.weibo.com/photos/get_all'
2.多进程的编写
代码如下:
class SpiderImg(Thread):
# 初始化
def __init__(self, d):
Thread.__init__(self)
self.data = d
# 重写run方法
def run(self):
# 当队列不为空的时候下载对应的url下的图片
while not self.data.empty():
# 取队列
a = self.data.get()
# 获得id和url数据
i_id = list(a.keys())[0]
i_url = list(a.values())[0]
# 访问链接取得数据
img = requests.get(url=i_url, headers=fake, proxies=random.choice(proxy_pool)).content
# 将文件写入指定路径下的文件夹
with open('E:/SpiderImg/李荣浩/{}.jpg'.format(i_id), 'wb') as t:
t.write(img)
print(i_id + '.jpg' + ' ' * 4 + '下载完毕' + '.' * 4)
为了开启多进程爬取图片
3.主函数的编写
代码如下:
if __name__ == '__main__':
# 初始化队列
data_queue = Queue()
# 循环
for i in range(1, 26):
params = {
'uid': '1739046981',
'album_id': '3581934839144367',
'count': '30',
'page': i,
'type': '3',
'__rnd': '1609667183074'
}
print('正在爬取第{}页'.format(i) + '.' * 4)
response = requests.get(url=url, params=params, headers=headers).json()
# 解析数据
photo_list = response.get('data').get('photo_list')
for photo in photo_list:
# 取得其中的pic_name 和 pic_name
pic_name = photo.get('pic_name')
pic_name = photo.get('photo_id')
photo_url = 'https://wx4.sinaimg.cn/large/' + pic_name
# 添加到队列中
data_queue.put({
photo_id: photo_url})
# 开启多进程,根据队列中存放的url数据,下载图片
for w in range(64):
spider = SpiderImg(data_queue)
spider.start()
结果
程序运行结果:
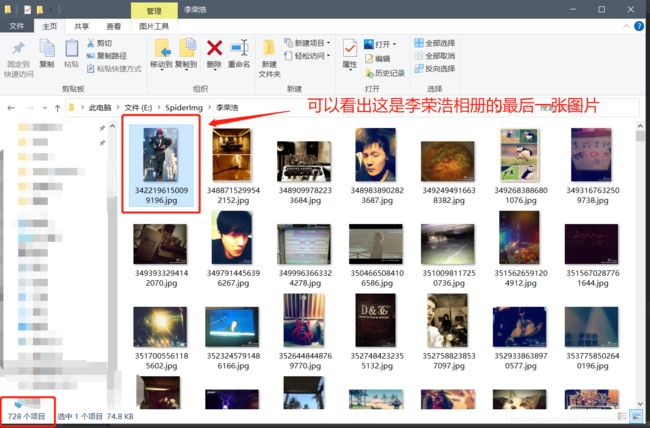
注:案例仅供学习