python爬取豆瓣评论并进行数据可视化
使用python对豆瓣进行评论爬取,并数据可视化
文章目录
- 前言
- 一、思路分析
- 二、代码编写
-
- 1.引入库
- 2.解析页面数据
- 3.编写主函数
- 4.词云
- 5.评分柱状图
- 总结
前言
对豆瓣界面进行分析,没有前后端分离,对界面元素分析后,爬取相关信息并保存在csv表格中,然后进行数据分析。
提示:以下是本篇文章正文内容,下面案例可供参考
一、思路分析
分析豆瓣页面数据,以及怎样实现循环爬取。
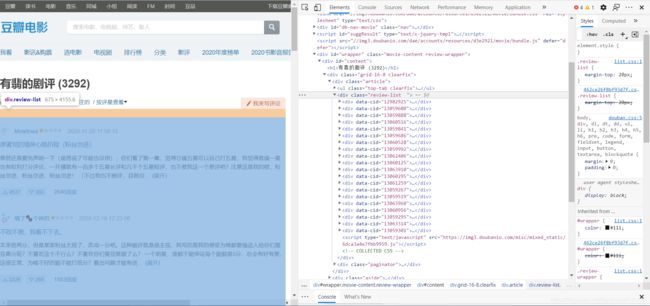
解析到class为review-list 的div中,存放着一片div列表,也就是评论界面。
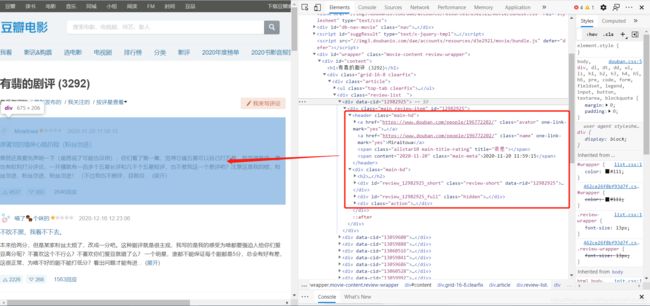
将其中的元素一一对应起来,接下来进行下一页爬取的分析。

get请求携带的start参数改变,并且步长是20,也就是20条数据。也就是说,循环请求的地址为:
https://movie.douban.com/subject/27069428/reviews?start=0
https://movie.douban.com/subject/27069428/reviews?start=20
https://movie.douban.com/subject/27069428/reviews?start=40
https://movie.douban.com/subject/27069428/reviews?start=60
…
接下来进行代码的编写。
二、代码编写
1.引入库
代码如下:
import csv
import requests
from lxml import etree
import random
from fake_useragent import UserAgent
# 伪装头
headers = {
'User-Agent': UserAgent().random,
'Host': 'movie.douban.com',
'Connection': 'keep-alive'
}
# 遍历用的url模板
base_url = 'https://movie.douban.com/subject/27069428/reviews?start={}'
# 代理池
proxy_pool = [{
'http': 'http://123.169.118.8:9999'}, {
'http': 'http://175.43.154.137:9999'}, {
'http': 'http://117.91.165.126:9999'}, {
'http': 'http://113.124.86.125:9999'}]
2.解析页面数据
代码如下:
def get_detail(url):
# 网页请求
response = requests.get(url=url, headers=headers, proxies=random.choice(proxy_pool)).text
response_data = etree.HTML(response)
# etree解析网页 获得评论的div列表
div_list = response_data.xpath('//div[@class="review-list "]/div')
for div in div_list:
# 获取对应的数据 评论人 评价 评论时间 评论标题 评论主体 赞成数 反对数 回复数
name = div.xpath('./div/header/a[@class="name"]/text()')[0]
level = div.xpath('./div/header/span[1]/@title')
# 有的评价为空 list列表取[0]会报错
if len(level):
level = level[0]
else:
level = '暂无评价'
time = div.xpath('./div/header/span[@class="main-meta"]/text()')[0]
title = div.xpath('./div/div/h2/a/text()')[0]
content = "".join(div.xpath('./div/div/div[1]/div[@class="short-content"]/text()')).replace("\n",
"").replace(" ", "").split("...")[0]
up = div.xpath('./div/div/div[@class="action"]/a[1]/span/text()')[0].replace("\n", "").replace(" ", "")
down = div.xpath('./div/div/div[@class="action"]/a[2]/span/text()')[0].replace("\n", "").replace(" ", "")
reply = div.xpath('./div/div/div[@class="action"]/a[3]/text()')[0]
detail = [name, level, time, title, content, up, down, reply]
# 返回对应的一条数据
yield detail
3.编写主函数
if __name__ == '__main__':
# 打开表格文件 注意编码格式
file = open('有翡.csv', 'w', newline='', encoding='utf-8-sig')
writer = csv.writer(file)
# 写表格的头部
writer.writerow(['评论人', '评价', '评论时间', '评论标题', '评论主体', '赞成数', '反对数', '回复数'])
# 循环遍历 爬取所有评论
for i in range(0, 1101, 20):
print('正在爬取start={}的数据'.format(i))
# 获得返回的数据
res = get_detail(base_url.format(i))
# 数据写入
writer.writerows(res)
结果表格为:

4.词云
直接上代码:
import os
import pandas as pd
from wordcloud import WordCloud
import jieba
all_content = ''
list_txt = []
data = pd.read_csv('test.csv')
for i in data['评论标题']:
all_content += str(i)
for c in jieba.cut(all_content):
if len(c) >= 2:
list_txt.append(c)
cut_text = " ".join(list_txt)
wordcloud = WordCloud(font_path="C:/Windows/Fonts/simfang.ttf",
background_color='white',
scale=32,
mode='RGBA',
margin=1).generate(cut_text)
filename = "test.png"
wordcloud.to_file(filename)
os.startfile(filename)
两张结果图片分别为:
评论标题:
评论主体:
在舍友的指点下,成功将词云的代码只用一行实现,代码如下:
import pandas as pd
from wordcloud import WordCloud
import jieba
WordCloud(font_path="C:/Windows/Fonts/simfang.ttf", background_color='white', scale=16).generate(" ".join([c for c in jieba.cut("".join(str((pd.read_csv('test.csv')['评论主体']).tolist()))) if len(c) > 1])).to_file("test.png")
5.评分柱状图
数据清洗直接上代码:
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('test.csv')['评价']
star = []
for level in data:
if level == '力荐':
star.append(5)
elif level == '推荐':
star.append(4)
elif level == '还行':
star.append(3)
elif level == '较差':
star.append(2)
elif level == '很差':
star.append(1)
else:
star.append(0)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(12, 8))
plt.hist(star, bins=17)
plt.xlabel('评价等级(0表示没有评分)', size=18)
plt.ylabel('人数', size=20)
plt.savefig('评分.jpg')
结果图:

总结
以上就是今天要讲的内容,本文仅仅简单介绍了爬虫的使用和数据可视化的冰山一角,以后再见吧!
注:案例仅供学习