【物联网识别】cve_details漏洞爬虫 && 设备指纹库爬虫
设计要求
设计并制作出一种漏洞扫描平台,其要求如下:
( 1 )熟悉爬虫,爬取漏洞、设备详细数据,构建漏洞库、设备指纹库。
( 2 )使用 nmap 工具扫描网络,使用 zgrab2 工具辅助扫描网络。
( 3 )完成设备指纹识别,漏洞匹配过程。
( 4 )使用 nessus 工具验证漏洞。
( 5 )搭建可视化平台。
( 6 )完成设计报告
爬虫:
本项目中使用 python 语言对 CVE_Details、CNVD、 CNNVD、securityfocus、 ics_cnvd 等漏洞网站爬取不少于 100000 条漏洞详细信息,爬取“CVE 编号”、
“危害等级”、“漏洞类型”、“供应商”、“型号”、“设备类型”、“固件版本号”等
信息,构建 CVE 漏洞-设备信息映射库。同时,使用 python 语言对京东、亚马逊、淘宝等电商网站爬取不少于 100000
条设备详细信息,爬取“设备类型”、“设备品牌”、“设备型号”等信息,并将其
构建一个设备指纹库。
本节小目录 (本文为作者踩坑记录,先看别直接上手,代码在最后)
scrapy框架介绍
CVE_Details爬虫代码
CVE漏洞信息数据库
setting设置
设备信息爬虫(苏宁)
设备信息爬虫(京东)
我只要代码!(好嘞,哥)
scrapy框架
Scrapy是一个快速的高级Web爬网和Web爬网框架,用于对网站进行爬网并从其页面中提取结构化数据。

Scrapy Engine(引擎): 负责Spider、ItemPipeline、 Downloader、Scheduler中间的通讯, 信号、数据传递等,
Scheduler(调度器): 负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列, 入队,当引擎需要时,交还给引擎,
Downloader (下载器): 负责下载Scrapy Engine(引擎发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider (爬虫) : 它负责处理所有Responses,从中分析提取数据,获取ltem字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道): 负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤存储等)的地方.
Downloader Middlewares (下载中间件) : 你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares (Spider中间件) : 你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
运作流程:
1、从spider中获取到初始url给引擎,告诉引擎帮我给调度器;
2、引擎将初始url给调度器,调度器安排入队列;
3、调度器告诉引擎已经安排好,并把url给引擎,告诉引擎,给下载器进行下载;
4、引擎将url给下载器,下载器下载页面源码;
5、下载器告诉引擎已经下载好了,并把页面源码response给到引擎;
6、引擎拿着response给到spider,spider解析数据、提取数据;
7、spider将提取到的数据给到引擎,告诉引擎,帮我把新的url给到调度器入队列,把信息给到Item Pipelines进行保存;
8、Item Pipelines将提取到的数据保存,保存好后告诉引擎,可以进行下一个url的提取了;
9、循环3-8步,直到调度器中没有url,关闭网站(若url下载失败了,会返回重新下载)。
安装scrapy
直接用anaconda或者pip命令安装,推荐装入venv虚拟环境
conda install scrapy 或 pip install scrapy
可以在命令行直接输入scrapy验证是否安装成功
创建项目
scrapy startproject 项目名
就会创建以下目录结构的项目文件夹
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
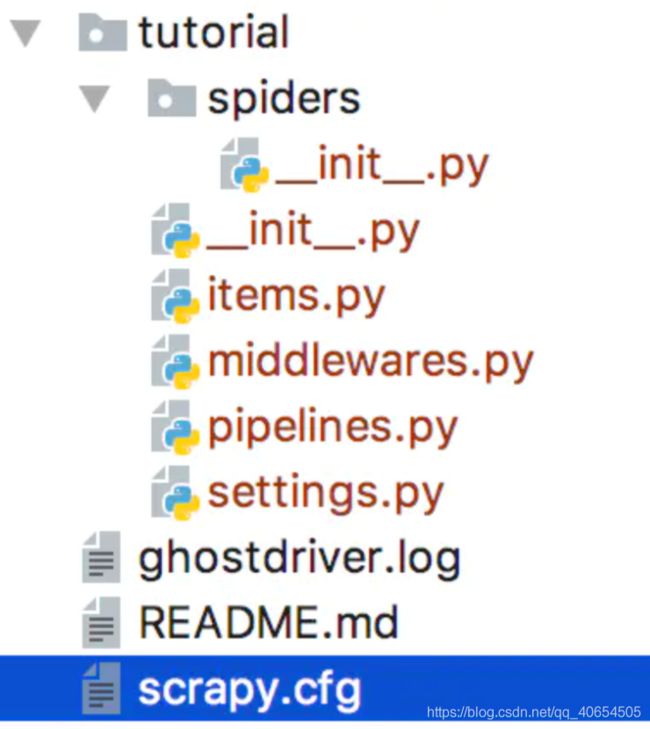
这些文件分别是:
scrapy.cfg: 项目的配置文件,现在可以先忽略。
tutorial/: 该项目的python模块。
tutorial/items.py: 项目中的item文件。
Item 是保存爬取到的数据的容器;其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
tutorial/pipelines.py: 项目中的pipelines文件。
Scrapy提供了pipeline模块来执行保存数据的操作。在创建的 Scrapy 项目中自动创建了一个 pipeline.py 文件,同时创建了一个默认的 Pipeline 类。比如我们可以在里面写把item提取的数据保存到mysql数据库的方法。
tutorial/settings.py: 项目的设置文件。
settings.py是Scrapy中比较重要的配置文件,里面可以设置的内容非常之多。
tutorial/spiders/: 放置spider代码的目录。爬虫文件就放在里面
创建爬虫
scrapy genspider 爬虫名 要爬取的网站域名 # 注意爬虫名不要和项目名冲突,网站域名指一级域名,如:baidu.com
生成的爬虫文件会放在文件夹项目名/spider/下为爬虫名.py
启动爬虫
scrapy crawl 爬虫名字 # 注意是名字,不是爬虫py文件
CVE_Details爬虫
先从setting讲起还是从网页讲起呢
不说话那就网页吧!
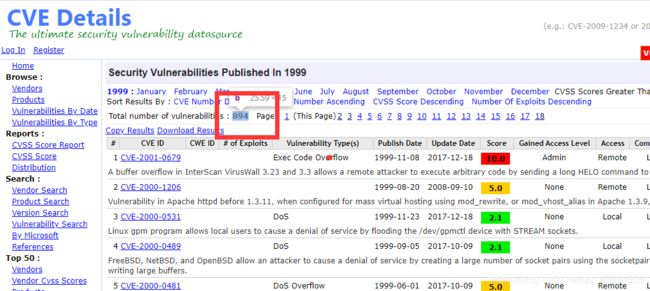
访问https://www.cvedetails.com可以进入CVE_Details的主页面,这就是我们的重要漏洞库来源,看左边Browse–>vulnerabilities by data 点进去会发现自有记录以来所有的漏洞数量信息,按照年->月->页数来爬取太麻烦,跳过月,直接按照每年的爬取
随便点进一个年份,发现url为https://www.cvedetails.com/vulnerability-list/year-1999/vulnerabilities.html感觉可以替换里面的年份,试试果然可以成功访问,由于每年漏洞数量和页数不一样,页数的最大值不好搞,,直接选择前面这个简单的漏洞数量,然后进行除以50的向上取整运算,就能得到页数
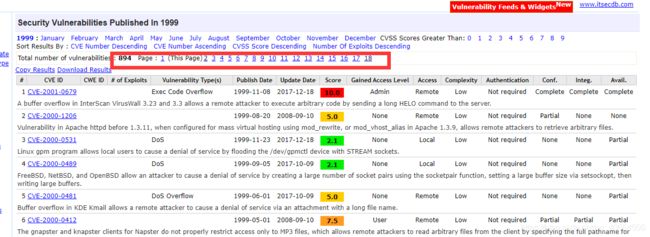
再观察观察每一页的url,发现第2页开始url就变复杂了
https://www.cvedetails.com/vulnerability-list.php?vendor_id=0&product_id=0&version_id=0&page=3&hasexp=0&opdos=0&opec=0&opov=0&opcsrf=0&opgpriv=0&opsqli=0&opxss=0&opdirt=0&opmemc=0&ophttprs=0&opbyp=0&opfileinc=0&opginf=0&cvssscoremin=0&cvssscoremax=0&year=1999&month=0&cweid=0&order=1&trc=894&sha=8fdcb89732c98600636042e1eff8c1b2ff5cb25d
尝试过后发现几个重要的参数,page(页数), year(年份), trc(这个就是数量,去掉也没事)
问题解决,通过 year构造的url --> 得到页数并构造页数的url --> 得到每一条cve链接 -->访问cve页面爬取信息返回管道
最重要的是xpath选择器,推荐看官方文档的介绍,然后推荐一个很方便尝试的方式,比如第一步,我们访问用year构造的url,然后用选择器得到页数,可以像下面一样在cmd中输入
scrapy shell https://www.cvedetails.com/vulnerability-list/year-1999/vulnerabilities.html
可以很方便的进行选择器的调试,我通常在这里试验选择器效果
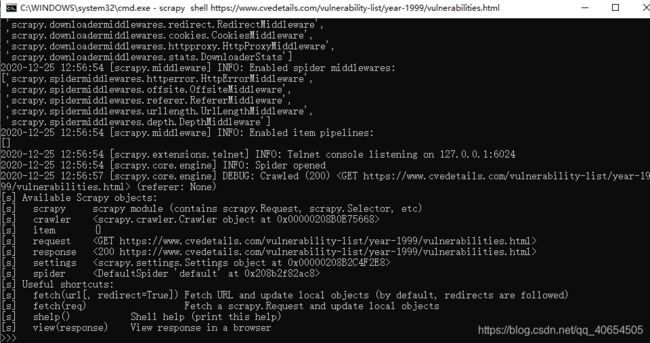
回到这个网页,只需要获取这个div下的b标签

在cmd里试验
>>> response.selector.xpath('//div[@class="paging"]')
[, ]
>>> response.selector.xpath('//div[@class="paging"]').get()
''
>>> response.selector.xpath('//div[@class="paging"]/b').get()
'894'
>>> response.selector.xpath('//div[@class="paging"]/b/text()').get()
'894'
轻松到手!于是可以开始写了,在生成的py文件里应该有默认代码,稍微改改就能自己用
class CveDetailSpider(scrapy.Spider):
name = 'cve_detail'
allowed_domains = ['https://www.cvedetails.com']
start_urls = [
"https://www.cvedetails.com/vulnerability-list/year-" + str(i) + "/vulnerabilities.html" for i in range(1999, 2021)
] # 建议大家这里改为range(2020, 1998, -1)倒序爬取
def parse(self, response):
# 得到页数,生成url
# 获取cve的数量
nums = response.selector.xpath('//div[@id="pagingb"]/b/text()').get()
# 向上取整算出页数
pages = ceil(int(nums)/50)
# 遍历年份1999-2020年
for year in range(1999, 2021):
# 遍历页数
for page in range(1, pages+1):
# 通过page,year,nums生成页面的url
newurl = self.get_url(str(page), str(year), str(nums))
yield scrapy.Request(url=newurl, callback=self.parse1, dont_filter=True)
scrapy默认从start_urls[] 寻找可爬取的url,然后默认调用parse()进行访问,注意ceil()方法需要导入math库函数,from math import ceil
get_url()是我写的生成url的函数,如下代码
yield 两句话搞定,首先它相当于return,同时它还是一个生成器
def get_url(self, page, year, trc):
return "https://www.cvedetails.com/vulnerability-list.php?vendor_id=0&product_id=0&version_id=0&page={}&hasexp=0&opdos=0&opec=0&opov=0&opcsrf=0&opgpriv=0&opsqli=0&opxss=0&opdirt=0&opmemc=0&ophttprs=0&opbyp=0&opfileinc=0&opginf=0&cvssscoremin=0&cvssscoremax=0&year={}&month=0&cweid=0&order=1&trc={}&sha=ef7bb39664f094781e7b403da0e482830f5837d6".format(page, year, trc)
yield scrapy.Request()有两个参数,url和回调函数,我写了另外一个回调函数parse1()来处理下阶段的页面解析
继续使用cmd进行分析(上一次的退出命令是exit())
scrapy shell https://www.cvedetails.com/vulnerability-list.php?vendor_id=0&product_id=0&version_id=0&page=3&hasexp=0&opdos=0&opec=0&opov=0&opcsrf=0&opgpriv=0&opsqli=0&opxss=0&opdirt=0&opmemc=0&ophttprs=0&opbyp=0&opfileinc=0&opginf=0&cvssscoremin=0&cvssscoremax=0&year=1999&month=0&cweid=0&order=1&trc=894&sha=8fdcb89732c98600636042e1eff8c1b2ff5cb25d
这页面简单,我们只需要获取一个一个的链接,就在这些字的a标签下

尝试一下,就能用response.selector.xpath('//div[@id="searchresults"]/table/tr[@class="srrowns"]/td[@nowrap]/a/@href').get()定位到了,但是get()只能匹配到一个,可以用getall()将页面上的全部拿到手
>>> response.selector.xpath('//div[@id="searchresults"]/table/tr[@class="srrowns"]/td[@nowrap]/a/@href').getall()
['/cve/CVE-2019-1020019/', '/cve/CVE-2019-1020018/', '/cve/CVE-2019-1020017/', '/cve/CVE-2019-1020016/', '/cve/CVE-2019-1020015/', '/cve/CVE-2019-1020014/', '/cve/CVE-2019-1020013/', '/cve/CVE-2019-1020012/', '/cve/CVE-2019-1020011/', '/cve/CVE-2019-1020010/', '/cve/CVE-2019-1020009/', '/cve/CVE-2019-1020008/', '/cve/CVE-2019-1020007/', '/cve/CVE-2019-1020006/', '/cve/CVE-2019-1020005/', '/cve/CVE-2019-1020004/', '/cve/CVE-2019-1020003/', '/cve/CVE-2019-1020002/', '/cve/CVE-2019-1020001/', '/cve/CVE-2019-1010319/', '/cve/CVE-2019-1010318/', '/cve/CVE-2019-1010317/', '/cve/CVE-2019-1010316/', '/cve/CVE-2019-1010315/', '/cve/CVE-2019-1010314/', '/cve/CVE-2019-1010312/', '/cve/CVE-2019-1010311/', '/cve/CVE-2019-1010310/', '/cve/CVE-2019-1010309/', '/cve/CVE-2019-1010308/', '/cve/CVE-2019-1010307/', '/cve/CVE-2019-1010306/', '/cve/CVE-2019-1010305/', '/cve/CVE-2019-1010304/', '/cve/CVE-2019-1010302/', '/cve/CVE-2019-1010301/', '/cve/CVE-2019-1010300/', '/cve/CVE-2019-1010299/', '/cve/CVE-2019-1010298/', '/cve/CVE-2019-1010297/', '/cve/CVE-2019-1010296/', '/cve/CVE-2019-1010295/', '/cve/CVE-2019-1010294/', '/cve/CVE-2019-1010293/', '/cve/CVE-2019-1010292/', '/cve/CVE-2019-1010290/', '/cve/CVE-2019-1010287/', '/cve/CVE-2019-1010283/', '/cve/CVE-2019-1010279/', '/cve/CVE-2019-1010275/']
随便点进一个知道下一次跳转是"https://www.cvedetails.com"+爬取的url,所以parse1()也会写了
def parse1(self, response):
# xpath爬取url列表
detailurls = response.selector.xpath('//div[@id="searchresults"]/table/tr[@class="srrowns"]/td[@nowrap]/a/@href').getall()
for detailurl in detailurls:
# for循环构造每个子页面url
durl = "https://www.cvedetails.com" + detailurl
yield scrapy.Request(url=durl, callback=self.parse2, dont_filter=True)
这里又用yield回调了parse2(),没错我就是命名天才,略略略
老规矩,cmd
scrapy shell https://www.cvedetails.com/cve/CVE-1999-1567/
找到需要爬取的目标点,CVE编号,危害等级,漏洞类型,供应商,型号,设备类型,固件版本号
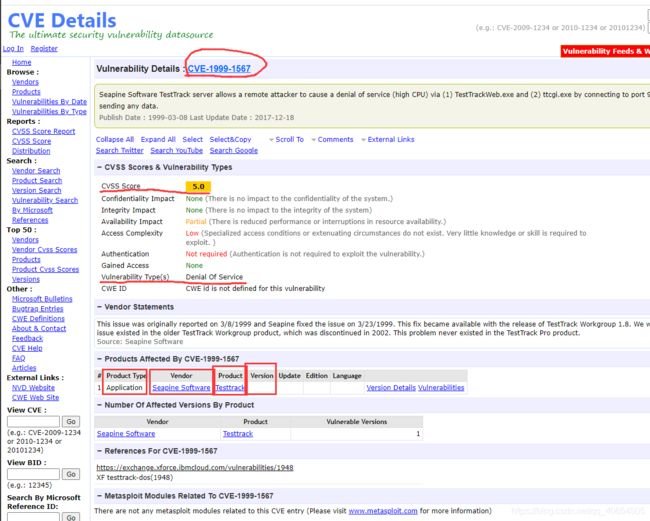
# CVE编号
cveid = response.selector.xpath('//h1/a/text()').get()
# 危害等级
score = response.selector.xpath('//div[@class="cvssbox"]/text()').get()
注意有的页面危害等级为0.0有可能是信息丢失也有可能是保密信息,反正页面没显示,写个判断直接跳过
if score == '0.0':
return None
然后是漏洞类型,这个有点麻烦,为空的时候很难定位,有字的时候直接锁定就行了,所以我获取了整个表格倒数第二个标签信息,再用re正则表达式匹配标签的信息,如果findall()匹配不到就会返回空列表,这我很喜欢,两句代码搞定
vulntype = re.findall(r'">(.*?)', response.selector.xpath('//table[@id="cvssscorestable"]/tr').getall()[-2])
vulntype = '' if vulntype == [] else vulntype[0]
接下来的设备就比较麻烦了,因为很有可能一个漏洞对应很多个设备同时很多个版本,总之,直接把设备列表的每一行都获取到就行了
>>> response.selector.xpath('//table[@id="vulnprodstable"]/tr').getall()[1:]
['\n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t1\t\t\t\t\t\t\t \n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\tApplication\t\t\t\t\t\t\t \n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\tSeapine Software\t\t\t\t\t\t\t \n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\tTesttrack\t\t\t\t\t\t\t \n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t \n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t \n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t \n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t \n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t Version Details Vulnerabilities\t\t\t\t\t\t\t \n\t\t\t\t\t\t ']
很恶心,不过没关系,两个规则直接匹配
rule1 = re.compile(r'(.*)')
rule2 = re.compile(r'\s+(.*?)\s+ ')
vendor,product,_ = rule1.findall(make)
producttype,_,_,version,_,_,_,_ = rule2.findall(make)
emmmm,正则有问题的可以隔壁去看看正则表达式,反正我也是用一次查一次
最后实例化管道,然后每一行的设备都和cveid他们存入管道,通过管道存入数据库,下面是parse2()代码
def parse2(self, response):
# CVE编号,危害等级,漏洞类型,供应商,型号,设备类型,固件版本号
cveid = response.selector.xpath('//h1/a/text()').get()
score = response.selector.xpath('//div[@class="cvssbox"]/text()').get()
if score == '0.0':
return None
vulntype = re.findall(r'">(.*?)', response.selector.xpath('//table[@id="cvssscorestable"]/tr').getall()[-2])
vulntype = '' if vulntype == [] else vulntype[0]
makes = response.selector.xpath('//table[@id="vulnprodstable"]/tr').getall()[1:]
rule1 = re.compile(r'(.*)')
rule2 = re.compile(r'\s+(.*?)\s+ ')
for make in makes:
vendor,product,_ = rule1.findall(make)
producttype,_,_,version,_,_,_,_ = rule2.findall(make)
item = CveDetailsItem()
item['cveid'],item['score'],item['vulntype'],item['vendor'],item['product'],item['producttype'],item['version'] = cveid,score,vulntype,vendor,product,producttype,version
yield item
再贴一个完整的爬虫代码吧
# -*- coding: utf-8 -*-
import scrapy
from math import ceil
import re
from cve_details.items import CveDetailsItem
class CveDetailSpider(scrapy.Spider):
name = 'cve_detail'
allowed_domains = ['https://www.cvedetails.com']
start_urls = [
"https://www.cvedetails.com/vulnerability-list/year-" + str(i) + "/vulnerabilities.html" for i in range(1999, 2021)
]
def get_url(self, page, year, trc):
return "https://www.cvedetails.com/vulnerability-list.php?vendor_id=0&product_id=0&version_id=0&page={}&hasexp=0&opdos=0&opec=0&opov=0&opcsrf=0&opgpriv=0&opsqli=0&opxss=0&opdirt=0&opmemc=0&ophttprs=0&opbyp=0&opfileinc=0&opginf=0&cvssscoremin=0&cvssscoremax=0&year={}&month=0&cweid=0&order=1&trc={}&sha=ef7bb39664f094781e7b403da0e482830f5837d6".format(page, year, trc)
def parse(self, response):
# 得到页数,生成url
nums = response.selector.xpath('//div[@id="pagingb"]/b/text()').get() # 获取cve的数量
pages = ceil(int(nums)/50) # 算出页数
for year in range(1999, 2021):
for page in range(1, pages+1):
newurl = self.get_url(str(page), str(year), str(nums))
yield scrapy.Request(url=newurl, callback=self.parse1, dont_filter=True)
def parse1(self, response):
detailurls = response.selector.xpath('//div[@id="searchresults"]/table/tr[@class="srrowns"]/td[@nowrap]/a/@href').getall()
for detailurl in detailurls:
durl = "https://www.cvedetails.com" + detailurl
yield scrapy.Request(url=durl, callback=self.parse2, dont_filter=True)
def parse2(self, response):
# CVE编号,危害等级,漏洞类型,供应商,型号,设备类型,固件版本号
cveid = response.selector.xpath('//h1/a/text()').get()
score = response.selector.xpath('//div[@class="cvssbox"]/text()').get()
if score == '0.0':
return None
vulntype = re.findall(r'">(.*?)', response.selector.xpath('//table[@id="cvssscorestable"]/tr').getall()[-2])
vulntype = '' if vulntype == [] else vulntype[0]
makes = response.selector.xpath('//table[@id="vulnprodstable"]/tr').getall()[1:]
rule1 = re.compile(r'(.*)')
rule2 = re.compile(r'\s+(.*?)\s+ ')
for make in makes:
vendor,product,_ = rule1.findall(make)
producttype,_,_,version,_,_,_,_ = rule2.findall(make)
item = CveDetailsItem()
item['cveid'],item['score'],item['vulntype'],item['vendor'],item['product'],item['producttype'],item['version'] = cveid,score,vulntype,vendor,product,producttype,version
yield item
# print(cveid,score,vulntype,vendor,product,producttype,version)
CVE漏洞信息数据库
这部分是写在pipelines.py里的,不过因为里面要调用items咱先在items.py声明一下
import scrapy
class CveDetailsItem(scrapy.Item):
# define the fields for your item here like:
cveid = scrapy.Field()
score = scrapy.Field()
vulntype = scrapy.Field()
vendor = scrapy.Field()
product = scrapy.Field()
producttype = scrapy.Field()
version = scrapy.Field()
open_spider()运行蜘蛛时将自动调用此方法
close_spider()关闭蜘蛛时将自动调用此方法
process_item()每个项目管道组件都调用此方法
简单点说,我在open_spider里写了每次运行爬虫都检查数据库,如果有这个表,就删掉,然后重建表,process_item里就接收爬虫发过来的信息,然后存入数据库中,close_spider就负责在爬虫结束的时候关门
没啥好说的,这部分主要是mysql的安装和navicat与数据库的连接,建议出门左转百度去,直接上代码
import pymysql
class CveDetailsPipeline:
tb = 'cve_details'
number = 0
def open_spider(self, spider):
print("开始爬虫!")
db = spider.settings.get('MYSQL_DB_NAME','cve_db')
host = spider.settings.get('MYSQL_HOST','127.0.0.1')
port = spider.settings.get('MYSQL_PORT', 3306)
user = spider.settings.get('MYSQL_USER','root')
passwd = spider.settings.get('MYSQL_PASSWORD','root')
self.db_conn =pymysql.connect(host=host, port=port, db=db, user=user, passwd=passwd, charset='utf8')
self.db_cur = self.db_conn.cursor()
self.db_cur.execute("DROP TABLE IF EXISTS %s"%self.tb)
sql = """CREATE TABLE IF NOT EXISTS %s (
id int PRIMARY KEY AUTO_INCREMENT,
cveid varchar(32) NOT NULL,
score varchar(16),
vulntype varchar(100),
vendor varchar(56),
product varchar(56),
producttype varchar(32),
version varchar(32)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
"""
self.db_cur.execute(sql%self.tb)
print('建表完成!')
def process_item(self, item, spider):
if item != None:
values = (
pymysql.escape_string(item['cveid']), # CVE编号
pymysql.escape_string(item['score']), # 危害等级
pymysql.escape_string(item['vulntype']), # 漏洞类型
pymysql.escape_string(item['vendor']), # 供应商
pymysql.escape_string(item['product']), # 型号
pymysql.escape_string(item['producttype']), # 设备类型
pymysql.escape_string(item['version']) # 固件版本号
)
# print(type(item['cveid']),type(item['score']),type(item['vulntype']),type(item['vendor']),type(item['product']),type(item['producttype']),type(item['version']))
sql = '''INSERT INTO cve_details(cveid,score,vulntype,vendor,product,producttype,version) VALUES(%s,%s,%s,%s,%s,%s,%s)'''
self.db_cur.execute(sql, values)
self.number += 1
if self.number >= 200:
self.db_conn.commit()
self.number = 0
return item
def close_spider(self, spider):
print("结束爬虫!")
self.db_conn.commit()
self.db_conn.close()
效果如下

setting
这里有很多可以自定义的东西,默认都是被注释的
BOT_NAME = 'demo1’ Scrapy项目的名字
SPIDER_MODULES = ['demo1.spiders'] Scrapy搜索spider的模块列表
NEWSPIDER_MODULE = 'demo1.spiders' 使用 genspider 命令创建新spider的模块。
ROBOTSTXT_OBEY = False是否遵守机器人协议,遵守会有很多限制爬取的文件
CONCURRENT_REQUESTS = 32并发线程数,默认16,然后我改的1000感觉没啥效果,果然python的多线程都是假的,
DOWNLOAD_DELAY = 2爬取延时,一般1就行了,默认3,为了防止爬太快对服务器造成过大负担然后被反爬(封ip)
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Referer':'https://www.cvedetails.com/vulnerability-list/',
}
爬虫伪造文件头,避免被当成爬虫,给自己带的面具,user-agent在f12里copy,referer就是跳转链接,比如百度里访问任何一个网页都是通过百度跳转,referer就是baidu.com
ITEM_PIPELINES = {
'cve_details.pipelines.CveDetailsPipeline': 300,
}
这个就是管道的声明,300是优先级,数字越低优先级越高
AUTOTHROTTLE_DEBUG = False启用会显示很多调节统计的信息
前面的都是被注释了,下面这俩得自己写上去,不然有可能跟我一样跑了一半网络波动连续几十个请求失败,然后没有重新加入访问队列
RETRY_ENABLED:True 是否开启重试
RETRY_TIMES:5 重试次数
运行效果图:
还有一个更简单的方法,还记得setting里面的ROBOTSTXT_OBEY吗,直接访问网站的robots.txt,里面文件夹下可以访问的网址都挨个列好了~

看到这是不是以为就完了?如果这么认为就真的完了,看看数据库…
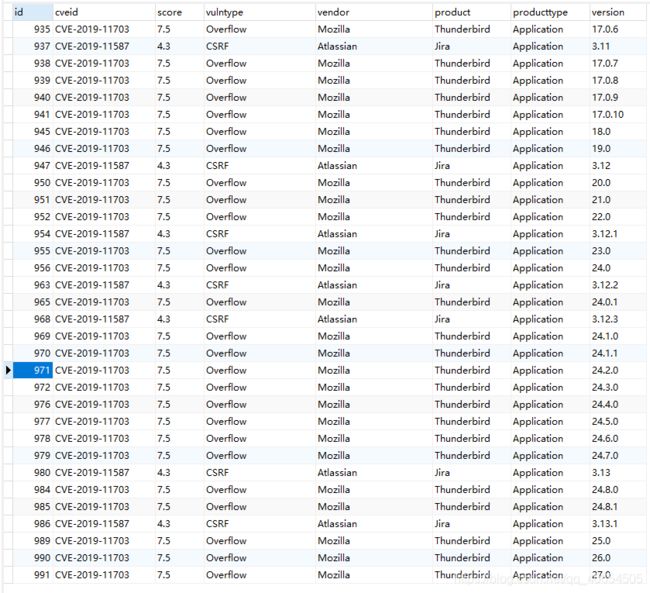
回到cev_details数据库,这个爬虫我运行了一下午加一整晚,存了75w+数据还没停止,数据库里筛选观察发现好多重复数据,淦,这爬虫一直在循环爬,于是停止开始数据库去重处理,下面一条是根据cveid,vulntype,vendor,product,version来筛选出重复项的id,并删除这些id
mysql> delete from cve_details where id in (select id from (select max(id) as ID,cveid,vulntype,vendor,product,version,count(*) as c from cve_details group by cveid,vulntype,vendor,product,version having c>1) as t);
Query OK, 3736 rows affected (3.81 sec)
每次删除数量在3k5左右,我可是有75w+数据呢,估计55w+都是重复数据,不可能一次一次运行吧,赶紧写了个函数,运行
CREATE DEFINER=`root`@`localhost` PROCEDURE `mydel`()
BEGIN
while exists (select max(id) as ID,count(*) as c from cve_details group by cveid,vulntype,vendor,product,version having c>1) do
delete from cve_details where id in (select id from (select max(id) as ID,count(*) as c from cve_details group by cveid,vulntype,vendor,product,version having c>1) as t);
end while;
END
i7-7700的cpu瞬间就让sql多占用了15%资源,磁盘读取占用1m/s,感觉还是很慢,洗个澡去
洗澡回来发现数据库删完还有3k条了。。。自闭
为了从源头上止损,我重新修改完善了爬虫,完美解决问题,只对爬虫文件cve_detail.py作了如下修改:
- 设置了访问过目录的记录表
goturls = set() - 将
start_urls列表改成了start_requests()函数,这样写比列表的功能相比多加了一个meta参数,可以传递年份值,方便后续构造新的url parse()内我新添了sha变量用于记录页面上获取的认证,每一个year的sha都不一样,如果不修改就会导致后面的翻页功能失效,永远爬取第一页
下面贴完整代码:
# -*- coding: utf-8 -*-
import scrapy
from math import ceil
import re
from cve_details.items import CveDetailsItem
class CveDetailSpider(scrapy.Spider):
name = 'cve_detail'
allowed_domains = ['https://www.cvedetails.com']
goturls = set()
def start_requests(self):
for i in range(2020, 1998, -1):
url = "https://www.cvedetails.com/vulnerability-list/year-" + str(i) + "/vulnerabilities.html"
yield scrapy.Request(url=url, meta={
'year' : i})
def get_url(self, page, year, trc, sha):
return "https://www.cvedetails.com/vulnerability-list.php?vendor_id=0&product_id=0&version_id=0&page={}&hasexp=0&opdos=0&opec=0&opov=0&opcsrf=0&opgpriv=0&opsqli=0&opxss=0&opdirt=0&opmemc=0&ophttprs=0&opbyp=0&opfileinc=0&opginf=0&cvssscoremin=0&cvssscoremax=0&year={}&month=0&cweid=0&order=1&trc={}&sha={}".format(page, year, trc, sha)
def parse(self, response):
# 得到页数,生成url
nums = response.selector.xpath('//div[@id="pagingb"]/b/text()').get() # 获取cve的数量
pages = ceil(int(nums)/50) # 算出页数
sha = response.selector.xpath('//a[@title="Go to page 1"]/@href').get()
if sha != None:
sha = sha.split('=')[-1] # 获取sha
else:
return None
for page in range(1, pages+1):
newurl = self.get_url(str(page), str(response.meta['year']), str(nums), sha)
if newurl not in self.goturls:
self.goturls.add(newurl)
yield scrapy.Request(url=newurl, callback=self.parse1, dont_filter=True)
else:
print('p0访问重复!!!')
break
def parse1(self, response):
detailurls = response.selector.xpath('//div[@id="searchresults"]/table/tr[@class="srrowns"]/td[@nowrap]/a/@href').getall()
for detailurl in detailurls:
durl = "https://www.cvedetails.com" + detailurl
if durl not in self.goturls:
self.goturls.add(durl)
yield scrapy.Request(url=durl, callback=self.parse2, dont_filter=True)
else:
print('p1访问重复!!!')
break
def parse2(self, response):
# CVE编号,危害等级,漏洞类型,供应商,型号,设备类型,固件版本号
cveid = response.selector.xpath('//h1/a/text()').get()
score = response.selector.xpath('//div[@class="cvssbox"]/text()').get()
vulntype = re.findall(r'">(.*?)', response.selector.xpath('//table[@id="cvssscorestable"]/tr').getall()[-2])
vulntype = '' if vulntype == [] else vulntype[0]
makes = response.selector.xpath('//table[@id="vulnprodstable"]/tr').getall()[1:]
rule1 = re.compile(r'(.*)')
rule2 = re.compile(r'\s+(.*?)\s+ ')
for make in makes:
if 'No vulnerable product found' in make:
continue
vendor,product,_ = rule1.findall(make)
producttype,_,_,version,_,_,_,_ = rule2.findall(make)
item = CveDetailsItem()
item['cveid'],item['score'],item['vulntype'],item['vendor'],item['product'],item['producttype'],item['version'] = cveid,score,vulntype,vendor,product,producttype,version
yield item
爬了21w断电就停止了,然后使用上面的数据库去重函数,因为在网站上每一个漏洞下的设备还有其他参数,好像叫update,连续几条其他参数全部相同,只有这个修改了,但我们每做过滤直接放入数据库了,所以需要去重处理
CREATE DEFINER=`root`@`localhost` PROCEDURE `mydel`()
BEGIN
while exists (select max(id) as ID,count(*) as c from cve_details group by cveid,vulntype,vendor,product,version having c>1) do
delete from cve_details where id in (select id from (select max(id) as ID,count(*) as c from cve_details group by cveid,vulntype,vendor,product,version having c>1) as t);
end while;
END

从21w条变成了16.7w条!!成功了!!!!
设备信息爬虫(苏宁)
爬取“设备类型”、“设备品牌”、“设备型号”等信息,并将其
构建一个设备指纹库。
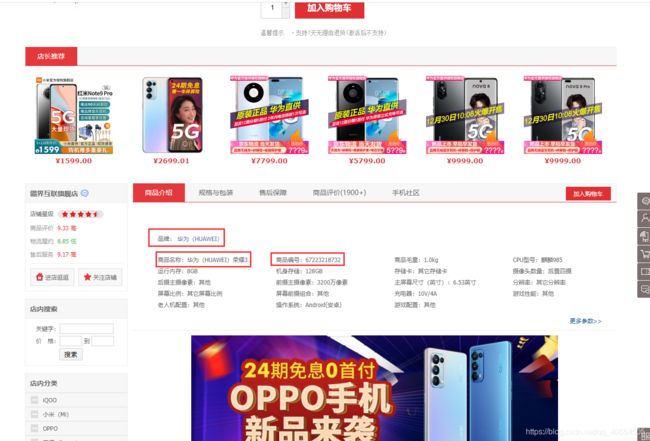
想到这我人傻了,cve漏洞库里全是英文,淘宝京东爬下来设备类型不得全是中文吗,比如前段时间的小米9漏洞,淘宝里设备类型就是”小米9“,设备型号也是”小米9“…这还怎么做cve和设备映射啊,这一瞬间我甚至想到了语义相似度分析,淦,想太复杂了,经过各个网站分析,淘宝不停弹窗登录,需要写模拟登陆,算了,京东和亚马逊都挺好的,我因为一些原因选择了苏宁易购,不过几个网站都差不多,可以类比着写,先谈谈思路吧,有cve的设备几乎都离不开“网络设备”“智能家居”等等关键词,而这只是一小部分,所以不能写个递归页面url的无脑爬虫,可以通过关键词控制范围,这是个不错的想法
来到苏宁的首页https://www.suning.com/,随便搜个东西,发现换了一个一级域名https://search.suning.com/,看来搜索功能就是在这个域名上实现的了,看看robots爬虫协议,https://search.suning.com/robots.txt
User-agent: EtaoSpider
Disallow: /
User-Agent: *
Disallow: /emall/
Disallow:/*.do
Disallow:/*cityId*
Disallow:/*%E4%BB%A3%E5%BC%80%E5%8F%91%E7%A5%A8*/
Disallow:/*iy*
Disallow:/*sc*
只有不允许爬的这些地址,话说上面那个url编码%E4%BB%A3%E5%BC%80%E5%8F%91%E7%A5%A8解码之后是代开发票,哈哈哈,那就别爬这些吧,反正这些都应该被屏蔽了
搜索”网络设备“进入https://search.suning.com/网络设备/页面,可以看到有好多商品,怎么翻都翻不完,能感觉到是动态刷新的,不信咱试试,打开cmd,scrapy shell https://search.suning.com/%E7%BD%91%E7%BB%9C%E8%AE%BE%E5%A4%87/这个url编码就是”网络设备“加密后的,地址栏可以直接复制,每个商品都是一个li标签,直接输出li标签的个数
>>> len(response.selector.xpath('//ul[@class="general clearfix"]/li').getall())
30
直接页面打开f12,用选择工具找到商品,数出商品的个数可远远不止30个,为了排除缓存影响页面上重新搜索一个“网络的设备”,别动鼠标滚轮,f12数出来果然是30,看来下拉果然会加载更多商品,在f12里的network选择XHR,然后页面往下划就能看到一个奇怪的东西混入gif大军
https://search.suning.com/emall/searchV1Product.do?keyword=%E7%BD%91%E7%BB%9C%E8%AE%BE%E5%A4%87&ci=157162&pg=01&cp=0&il=0&st=0&iy=0&isDoufu=1&isNoResult=0&n=1&sesab=BCAABBABCAAA&id=IDENTIFYING&cc=351&paging=1&sub=0&jzq=470
经实验发现paging是切换页面的关键,这个时候是不是就拿去scrapy shell里面尝试了,但是仔细看看这个路径/emall/是被robots.txt禁止了的。这里就不建议大家继续尝试了,毕竟人家超市都规定宠物不得入内,就没必要非要带着小仓鼠进去
如果,我是说如果,还想获得那些公开数据的话,可以用selenium模拟浏览器,或者scrapy里在setting里修改ROBOTSTXT_OBEY = False,线程数量调低,延时调高,一定不要频繁访问页面造成电商服务器损失,毕竟技术本无罪的前提是不打扰人家
所以这个/email/接口的参数就是paging需要遍历一遍,每个页面有30个商品信息,然后用xpath选择器选中每个标签下的标题,它的内有商品链接,访问链接xpath选择这三个参数返回items就行了
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8pVhrXJy-1609680323068)(image-20201226122000677.png)]
由于后台还在跑上一个爬虫。。我还是新建一个项目吧,scrapy startproject devices创建项目,cd ./devices/spiders进入爬虫目录,scrapy genspider device search.suning.com创建爬虫
下面直接讲解代码:
setting.py
BOT_NAME = 'devices'
SPIDER_MODULES = ['devices.spiders']
NEWSPIDER_MODULE = 'devices.spiders'
ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 50
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Referer':'https://search.suning.com/',
}
ITEM_PIPELINES = {
'devices.pipelines.DevicesPipeline': 300,
}
AUTOTHROTTLE_DEBUG = False
# 是否开启重试
RETRY_ENABLED:True
# 重试次数
RETRY_TIMES:5
setting里都是说过的,之前讲的有点乱,建议ctrl+f搜索
items.py
import scrapy
class DevicesItem(scrapy.Item):
brand = scrapy.Field()
modlenumber = scrapy.Field()
producttype = scrapy.Field()
这里在item对象里写了三个管道里需要用到的变量,品牌,型号,类型,这里的取名最好跟之前cve表名字对应,当然如果自己认识就无所谓了
searchdevice.py
import scrapy
from devices.items import DevicesItem
class SearchdeviceSpider(scrapy.Spider):
name = 'searchdevice'
allowed_domains = ['https://search.suning.com/']
def start_requests(self):
keys = [
'手机',
'电脑',
'电视',
'空调',
'影音',
'外设',
'数码',
'网络设备',
'智能家居',
]
for key in keys:
url = 'https://search.suning.com/emall/searchV1Product.do?keyword={}&ci=157162&pg=01&cp=0&il=0&st=0&iy=0&isDoufu=1&isNoResult=0&n=1&sesab=ACAABBABCCAA&id=IDENTIFYING&cc=351&sub=0&jzq=319&paging='.format(key)
# 记录页面号
yield scrapy.Request(url, dont_filter=True, meta={
'i' : 0, 'url' : url})
def parse(self, response):
# 检查页面是否溢出,
if len(response.body) <= 500:
return None
urls = response.selector.xpath('//div[@class="title-selling-point"]/a/@href').getall()
for url in urls:
yield scrapy.Request("https:"+url, callback=self.parse1, dont_filter=True, meta={
'i' : response.meta['i']})
yield scrapy.Request(response.meta['url']+str(response.meta['i']+1), dont_filter=True, meta={
'i' : response.meta['i']+1, 'url' : response.meta['url']}, callback=self.parse)
def parse1(self, response):
brand = response.selector.xpath('//div[@id="kernelParmeter"]/ul/li/span/a/text()').get()
producttype, modlenumber = response.selector.xpath('//div[@id="kernelParmeter"]/ul/li/@title').getall()[1:3]
# print('品牌:{},类型:{},型号:{}'.format(brand, producttype, modlenumber))
item = DevicesItem()
item['brand'], item['producttype'], item['modlenumber'] = brand, producttype, modlenumber
return item
启动爬虫默认读取start_url列表里或者start_requests()函数里的信息,最开始的url都是从这里生成的,我用搜索关键词替换url,生成可以直接访问的链接,注意我把后面的重要参数&paging=放到了最后,方便下一步的添加页数,当然经过试验这样的url是可以正常访问的
start_requests()函数调用scrapy.Request(),会默认回调给parse()
parse()内通过html的body长度小于500则该页面是空的,如果没超过500就爬取所有商品链接通过yield回调给parse1()进行数据的转存,而yield的特性是在parse1()执行结束之后会返回上一次yield的位置也就是for循环内,知道for循环结束,最后执行一句控制递归的yield,他负责给start_requests()生成的url添加页数并自增
parse1()就是将3个获取的信息放入item对象里返回给管道存储
pipelines.py
import pymysql
class DevicesPipeline:
tb = 'device'
number = 0
def open_spider(self, spider):
print("开始爬虫!")
db = spider.settings.get('MYSQL_DB_NAME','cve_db')
host = spider.settings.get('MYSQL_HOST','127.0.0.1')
port = spider.settings.get('MYSQL_PORT', 3306)
user = spider.settings.get('MYSQL_USER','root')
passwd = spider.settings.get('MYSQL_PASSWORD','root')
self.db_conn =pymysql.connect(host=host, port=port, db=db, user=user, passwd=passwd, charset='utf8')
self.db_cur = self.db_conn.cursor()
# 三句话为删表重建,往数据库补充数据注释掉
self.db_cur.execute("DROP TABLE IF EXISTS %s"%self.tb)
sql = """CREATE TABLE IF NOT EXISTS %s (
id int PRIMARY KEY AUTO_INCREMENT,
brand varchar(56),
modlenumber varchar(32),
producttype varchar(128)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
"""
self.db_cur.execute(sql%self.tb)
print('建表完成!')
def process_item(self, item, spider):
if item != None:
sql = 'INSERT INTO {}(brand,modlenumber,producttype) VALUES("{}","{}","{}")'.format(self.tb,item['brand'],item['modlenumber'],item['producttype'])
print(sql)
self.db_cur.execute(sql)
self.number += 1
if self.number >= 10:
self.db_conn.commit()
self.number = 0
return item
def close_spider(self, spider):
print("结束爬虫!")
self.db_conn.commit()
self.db_conn.close()
这个管道就简单了,启动爬虫链接数据库,删表重建,过程中由爬虫parse1()传递来的信息直接被存入数据库
不过就在刚刚。。。导致我的ip被网站反爬机制给ban了,于是继续调低线程,增大延迟,换ip之后继续,以龟速爬完了1300条,没听错,这站根据我的关键词就只有1300条

服了服了,还是换成京东吧,然后使用selenium模拟点击,
设备信息爬虫(京东)
试验之后就感觉selenium不适合弄爬虫。。。明明就是用做测试自动化的,以前还能做做鼠标验证码,现在有机器学习之后谁还用它啊,呜呜呜害得我死机了,根据速度算了下10w条估计得9小时
# -*- coding: utf-8 -*-
import scrapy
from devices_jd.items import DevicesJdItem
from selenium import webdriver
from selenium.webdriver.chrome.options import Options # 使用无头浏览器
from selenium.webdriver.common.keys import Keys
import time
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
class DeviceJdSpider(scrapy.Spider):
name = 'device_jd'
allowed_domains = ['www.jd.com']
driver = webdriver.Chrome()
url = 'https://search.jd.com/Search?keyword={keyword}&enc=utf-8&wq=%E6%89%8B%E6%9C%BA&pvid=24e8b53d9f164ee092d0bcabf99212d9'
keyword = iter([
'手机',
'智能设备',
'电脑',
'游戏设备',
'外设产品',
'网络产品',
'办公设备',
'智能家居',
'生活电器',
'电视',
'空调',
'洗衣机',
'冰箱',
'厨卫'
])
# 实例化一个浏览器对象
def __init__(self):
self.browser = webdriver.Chrome(chrome_options=chrome_options)
super().__init__()
def start_requests(self):
urls = self.url.format(keyword=next(self.keyword))
self.driver.get(urls)
time.sleep(3)
yield scrapy.Request(url=urls, dont_filter=True)
def parse(self, response):
while True:
for _ in range(0,170):
self.driver.find_element_by_tag_name('body').send_keys(Keys.ARROW_DOWN) #在这里使用模拟的下方向键
time.sleep(0.01)
time.sleep(0.5)
try:
producturls=self.driver.find_elements_by_xpath('//div[@class="p-name p-name-type-2"]/a')
for producturl in producturls:
yield scrapy.Request(url=producturl.get_attribute('href'), callback=self.senditem, dont_filter=True)
except Exception as e:
print(e)
# print(self.driver.find_element_by_class_name('pn-next').get_attribute("title") is "")
if self.driver.find_element_by_class_name('pn-next').get_attribute("title") is not "":
self.driver.find_element_by_tag_name('body').send_keys(Keys.ARROW_RIGHT) #在这里使用模拟的右方向键
time.sleep(1)
else:
break
yield self.start_requests()
def senditem(self, response):
producttype = response.xpath('//div[@class="item"]/a/text()').extract()[0]
brand = response.xpath('//ul[@id="parameter-brand"]/li/a/text()').extract()[0]
product = response.xpath('//ul[@class="parameter2 p-parameter-list"]/li/text()').extract()
productname = product[0][5:]
productid = product[1][5:]
item = DevicesJdItem()
item['producttype'],item['brand'],item['productname'],item['productid'] = producttype,brand,productname,productid
# print('类型:' + producttype)
# print('品牌:' + brand)
# print('名称:' + productname)
# print('编号:' + productid)
try:
modlenumber = response.xpath('//dl[@class="clearfix"]/dd/text()').extract()[3]
item['modlenumber'] = modlenumber
# print('型号:' + modlenumber)
except Exception as e:
print(e)
yield item
def close(self, spider):
self.browser.quit()
大致意思就是根据关键词搜索,这时页面上有30个商品,然后键盘模拟向下按,页面下划到底触发ajax再刷新30个,这时一次性获取整个页面的60个商品链接送入下一个函数获取信息存库,然后模拟键盘右键翻页,以此循环
太慢了太慢了,于是重新研究页面,页面下滑触发动态刷新时,f12的network里选择XHR可以看到有新的请求,头文件能找到请求的url,类似下面(不影响的参数被我删了)
https://search.jd.com/Search/s_new.php?keyword=%E6%89%8B%E6%9C%BA%E5%8D%8E%E4%B8%BA&qrst=1&suggest=1.def.0.base&wq=%E6%89%8B%E6%9C%BA%E5%8D%8E%E4%B8%BA&ev=exbrand_%E5%8D%8E%E4%B8%BA%EF%BC%88HUAWEI%EF%BC%89%5E&page=2&s=27&scrolling=y&log_id=1609148178669.7303&tpl=3_M&isList=0
经过不懈努力,我发现了其中奥秘,keyword,wq为搜索内容的url编码,一个页面为两个page,上面是单数下面是偶数,s控制着显示第*件物品,因为每一整页会显示4-6个广告,我设置page加1则s+28,留出两个广告位,即使重复了之后也能在数据库去重,log_id为当前微秒级的时间戳
代码不难理解,首先声明url和搜索关键词keyword,url内预留了参数的位置方便插入,keyword被我改写成生成器,之后可以使用next()控制循环,(for也可以控制生成器的循环,只是这里不大好用)
class DeviceJdSpider(scrapy.Spider):
name = 'device_jd'
allowed_domains = ['www.jd.com']
url = 'https://search.jd.com/Search/s_new.php?keyword={keyword}&qrst=1&suggest=1.def.0.base&wq={keyword}&ev=exbrand_%E5%8D%8E%E4%B8%BA%EF%BC%88HUAWEI%EF%BC%89%5E&page={page}&s={s}&scrolling=y&log_id={time}&tpl=3_M&isList=0'
keyword = iter([
'手机',
'智能设备',
'电脑',
'游戏设备',
'外设产品',
'网络产品',
'办公设备',
'智能家居',
'生活电器',
'电视',
'空调',
'洗衣机',
'冰箱',
'厨卫'
])
然后是开始的url,用time.time()生成时间戳,'%.4f'%(ti*1000)这里乘1000是将秒换成毫秒,与参数s统一格式,回调parse函数并传入参数keyword,page,s,import time必须放在函数内,,,,不然报错
def start_requests(self):
import time
ti = time.time()
keyword, page, s, time = next(self.keyword), 1, 1, '%.4f'%(ti*1000)
urls = self.url.format(keyword=next(self.keyword), page=page, s=s, time=time)
yield scrapy.Request(url=urls, dont_filter=True, meta={
'keyword' : keyword, 'page' : 1, 's' : 1})
获取每个商品的url并遍历回调给下一个处理函数senditem,然后给page加一并判断是否超过100页,如果没有就递归parse函数,如果超过就再次执行start_requests生成新的url,重新执行一轮
def parse(self, response):
# 爬取当前页面每个商品的url
producturls=response.selector.xpath('//div[@class="p-name p-name-type-2"]/a/@href').getall()
for producturl in producturls:
producturl = response.urljoin(producturl)
yield scrapy.Request(url=producturl, callback=self.senditem, dont_filter=True)
import time
page = response.meta['page'] + 1
if response.meta['page'] <= 200:
ti = time.time()
keyword, s, time = response.meta['keyword'], response.meta['s']+28, '%.4f'%(ti*1000)
urls = self.url.format(keyword=keyword, page=page, s=s, time=time)
yield scrapy.Request(url=urls, callback=self.parse, dont_filter=True, meta={
'keyword' : keyword, 'page' : page, 's' : s})
yield self.start_requests()
最后一个处理函数就是简单的用选择器选择需要的数据,然后返回管道存入数据库
类型

品牌,名称,编号
型号

def senditem(self, response):
producttype = response.xpath('//div[@class="item"]/a/text()').extract()[0]
brand = response.xpath('//ul[@id="parameter-brand"]/li/a/text()').extract()[0]
product = response.xpath('//ul[@class="parameter2 p-parameter-list"]/li/text()').extract()
productname = product[0][5:]
productid = product[1][5:]
item = DevicesJdItem()
item['producttype'],item['brand'],item['productname'],item['productid'] = producttype,brand,productname,productid
# print('类型:' + producttype)
# print('品牌:' + brand)
# print('名称:' + productname)
# print('编号:' + productid)
try:
modlenumber = response.xpath('//dl[@class="clearfix"]/dd/text()').extract()[3]
item['modlenumber'] = modlenumber
# print('型号:' + modlenumber)
except Exception as e:
print(e)
item['modlenumber'] = ''
yield item
访问次数过多被京东要求必须登录了。。。
这里我为了避免被反爬盯上给加了cookie和ip池,项目地址如下,star挺高的
proxy项目github:https://github.com/jhao104/proxy_pool
redis数据库:d:\redis-x64-5.0.10
输入命令redis-server.exe redis.windows.conf后,不要关闭,不要关闭
重新打开cmd窗口输入 redis-cli.exe -h 127.0.0.1 -p 6379
然后我运行bug挺多的,懒得改了,直接删掉ip池,不要代理了,ban了就换ip换cookie换关键字继续爬
第一轮结束,并没有想象中的反爬机制,关键字爬完了也才1w6行,计划中是14个关键词 x 100页 x 60个商品 = 8w4,哪缺这么多呢
'downloader/request_bytes': 37494632, # 请求字节大小
'downloader/request_count': 17296, # 请求次数
'downloader/request_method_count/GET': 17296, # GET请求次数
'downloader/response_bytes': 546113423, # 响应字节大小
'downloader/response_count': 17296, # 响应次数
'downloader/response_status_count/200': 17296, # 状态码为200的次数
'elapsed_time_seconds': 10582.425024,
'finish_reason': 'finished', # 爬虫结束原因
'finish_time': datetime.datetime(2021, 1, 3, 5, 29, 35, 462412), # 爬虫结束时间
'item_scraped_count': 15879,
'log_count/DEBUG': 33175, # 日志记录DEBUG等级次数
'log_count/ERROR': 10, # 日志记录ERROR等级次数
'log_count/INFO': 174, # 日志记录INFO等级次数
'request_depth_max': 201, # 最大请求深度
'response_received_count': 17296, # 接收响应次数
'scheduler/dequeued': 17296,
'scheduler/dequeued/memory': 17296,
'scheduler/enqueued': 17296,
'scheduler/enqueued/memory': 17296,
'start_time': datetime.datetime(2021, 1, 3, 2, 33, 13, 37388) # 爬虫开始时间
emmmm如果看懂了再回来补补,时间紧就这样吧
爬下来的数据再进行一次去重就搞定了
我只要代码!(好嘞,哥)
都是scrapy爬虫,只需要安装scrapy框架,配置好mysql数据库就能运行,
配置文件都在setting.py,设备信息爬虫需要在京东官网上复制最好是(已登录)的cookie,如果完成之后还要继续下一轮则更换ip,cookie,以及spiders/device_jd.py里的关键词
github地址:
这是cve漏洞爬虫
这是设备信息爬虫
cve漏洞库去重函数
CREATE DEFINER=`root`@`localhost` PROCEDURE `mydel`()
BEGIN
while exists (select max(id) as ID,count(*) as c from cve_details group by cveid,vulntype,vendor,product,version having c>1) do
delete from cve_details where id in (select id from (select max(id) as ID,count(*) as c from cve_details group by cveid,vulntype,vendor,product,version having c>1) as t);
end while;
END
设备指纹库去重函数
CREATE DEFINER=`root`@`localhost` PROCEDURE `shebei`()
BEGIN
while exists (select max(id) as ID,count(*) as c from device_jd group by productid,productname,modlenumber having c>1) do
delete from device_jd where id in (select id from (select max(id) as ID,count(*) as c from device_jd group by productid,productname,modlenumber having c>1) as t);
end while;
END