爬虫入门学习笔记
爬虫入门学习笔记
整了这么久,终于轮到爬虫了,之前一直对爬虫有所向往,现在学起来也是觉得很有意思,主要是通过一些大佬的博客来学习的,以下是我学习爬虫的学习笔记。
安装requests和BeautifulSoup4
安装request:
python本身提供的urllib没有python社区的requests库好用,现在主流都是用request来制作爬虫
- 打开cmd控制台
- pip安装指令
pip install requests
安装BeautifulSoup4:
有了requests模块,可以使用他的get()方法来下载网页,但是下载的是网页的源代码,不利于信息的检索,所以有这个库来对其解析
- 打开cmd控制台
- pip安装指令
pip install bs4
开始写第一个爬虫,爬取百度网页
爬取网页有几个步骤
- 指定你要爬取的url
- 使用
requests的get方法来发起请求,返回响应对象 - 获取响应数据,转换成我们看得懂的形式
- 将爬取的内容储存
导入数据库
import requests
指定URL
u="https://www.baidu.com/"
使用get方法爬取
response=requests.get(url=u)
设置编码为“utf-8”,不然网页打开是乱码
response.encoding = "utf-8"
获取响应数据,以text的形式给page
page=response.text
查看到response的形式是这个,所以要用.text来把他转化成文本格式

储存,把内容写进创建的baidu.html文件中
with open("baidu.html","w",encoding="utf-8") as f:
f.write(page)
然后发现文件夹里就多了一个baidu的html文件
我的第二个爬虫,动态页面的爬取
我们使用百度搜索一个东西,比如搜素爬虫,用上一个爬虫的方法不能爬取这个,要爬取动态页面,要给爬虫一个header
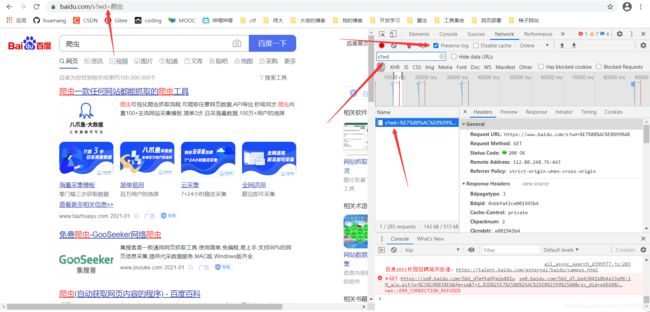
找到这个user-agent,这个是给服务器说明访问的浏览器的信息(可以理解为一个身份证)
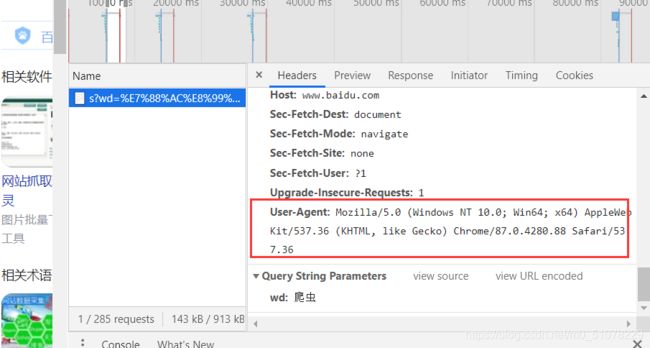
在爬虫文件中创建一个字典
idcard={
'User-Agent':'xxxxxxxxxxxxxxxxxxxxxxxxxx'}
在调用get()方法的时候给他一个headers属性,内容是刚刚创建的字典
然后剩下的操作还是看那四部
import requests
url="https://www.baidu.com/s?wd=爬虫"
idcard={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
response=requests.get(url=url,headers=idcard) # 给他headers属性
file=response.text
with open ("wd.html","w",encoding='utf-8') as wd:
wd.write(file)
发现文件中有wd.html文件了,打开就是搜索爬虫得到的网页了
爬虫etree配合xpath语句的学习并爬取b站分类表
xpath是XML的路径语言,常与lxml库一起来解析网站
完整详解这个博客中有比较详细介绍
下面介绍我的学习思路
安装lxml
控制台pip install lxml没啥好说的
导入库
import requests
from lxml import etree
通过etree.HTML()来解析网站,把网页数据解析
请求信息,处理信息
- 要爬取b站的信息,url设置到b站
url='https://www.bilibili.com/'
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
- 把爬取的信息文本化(以text的形式爬取)
response=requests.get(url=url,headers=header).text
- 根据大佬的博客所说,把解析网站比喻成把网页数据变成一个大树,我们只取里面的几片叶子
tree=etree.HTML(response)
- 接触到了xpath
leaf=tree.xpath('//div[@id="primaryChannelMenu"]/span/div[2]/a/span/text()')
这时候print(leaf)就有结果了![]()
返回了一个列表,里面成功爬取了分类
xpath详解
我自己的语法理解:
- 每递进一层就加一个/标签名
- 开头就是//两个斜杠就是直接跳转,不从开头开始一层一层的推
- 选择标签内的
属性就用@属性名 - 选择有特殊标记的标签的语法
//标签名[@属性名="xxx"] - 一层一层的推下去推到最后的时候选择要取得的信息:
1,如果是标签里的文本信息就在最后加/text()如/a/span/text()
2,如果是标签里面的属性就在最后加/@属性名如/a/@href - 如果是很多兄弟元素可以使用
标签名[排序数字]来选择例如div[1],这个排列数字是从1开始的,意思是第几个
例题
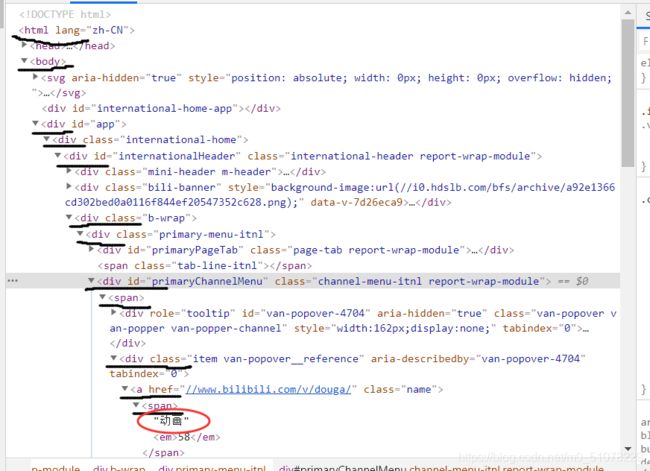
从根部开始,一级一级的找到了‘动画’
xpath就可以写成:
/html/body/div[2]/div/div[1]/div[3]/div/div[2]/span[1]/div/a/span/text()
div[2]表示的是同级下第二个div,因为上面的svg标签里还有个div标签
优化写法:
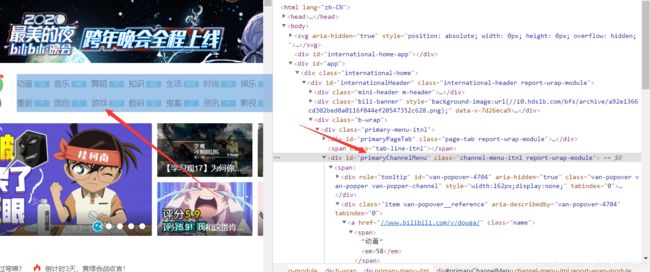
因为我只要爬取这里的分类标签,所以:
//div[@id=“primaryChannelMenu”]/span[1]/div/a/span/text()
这里只爬取了第一个“动画”,要爬取全部分类还得改一下
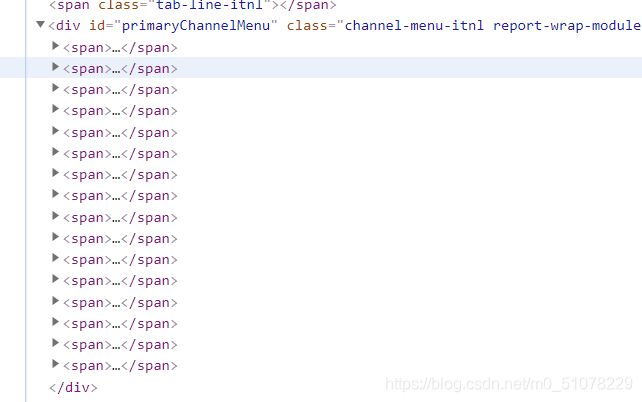
这里有一排span标签,每一个都是一个分类,要把他里面的所以分类名爬取出来,我们就不要给span排列数字了,让他全选中
leaf=tree.xpath('//div[@id="primaryChannelMenu"]/span/div[2]/a/span/text()')
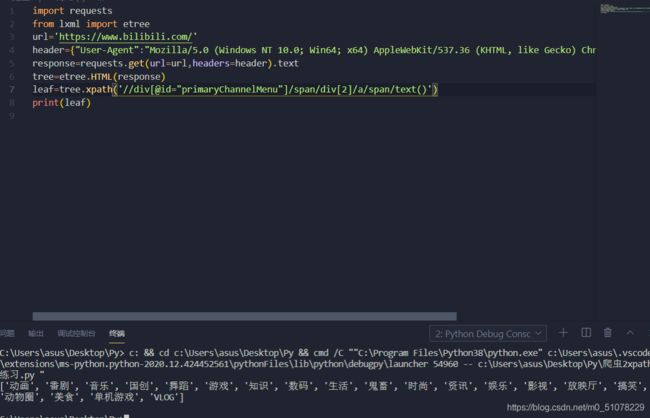
成功!!!
尝试图片的爬取
这个网站很简单,结构都很简单,爬取里面的图片
先附上完整的代码
import requests
from lxml import etree
url="https://www.qqtn.com/article/article_292075_1.html"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
response=requests.get(url=url,headers=header).text
tree=etree.HTML(response)
leaf=tree.xpath('//div[@id="zoom"]/p/img/@src')
for i in leaf:
a=requests.get(url=i,headers=header).content
name=i.split("/")[-1]
with open(name,"wb") as f:
f.write(a)
详解如下
导入库
import requests
from lxml import etree
设置响应头,把爬取网页信息并处理
url="https://www.qqtn.com/article/article_292075_1.html"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
response=requests.get(url=url,headers=header).text
tree=etree.HTML(response)
写xpath语句
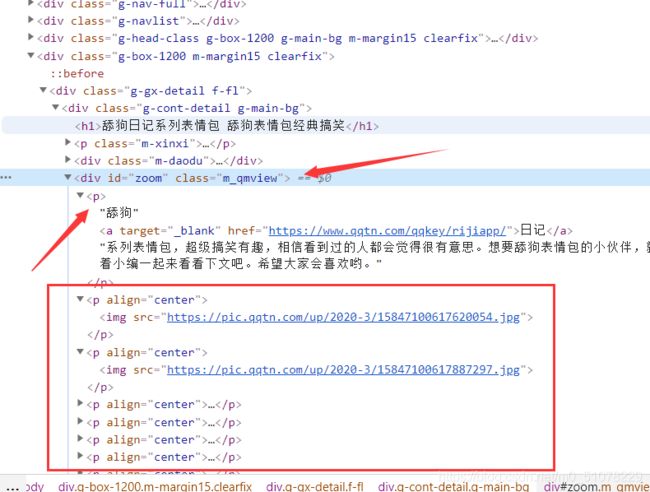
leaf=tree.xpath('//div[@id="zoom"]/p/img/@src')
图片是id="zoom"的div里面的,所以可以双斜杠直接跳到这,发现第一个p没有图片而是文字介绍,不过没关系,第二个开始的p开始才有img标签,所以直接这样写可以忽略掉第一个p,最后选择img标签里的src属性
图片的储存
这个时候直打印leaf出来的是图片的地址的列表

我们要提取里面的图片并保存,就遍历这个列表,每次循环将图片保存下来
for i in leaf:
a=requests.get(url=i,headers=header).content
name=i.split("/")[-1]
with open(name,"wb") as f:
f.write(a)
- 因为每次循环的
i都是地址,所以我们继续用requests.get()方法来爬取图片网站,爬取下来要用二进制的形式来保存,就是加上.content(图片,视频,音频都是要用二进制来爬取的,要爬取文字就用.text) - 命名图片,看他的地址
https://pic.qqtn.com/up/2020-3/15847100617620054.jpg最后是xxxx.jpg,所以我们用字符串的切片split()以"/"来对地址切片,选择倒数第一片就是xxxx.jpg了 - 储存图片,命名是完整的,有jpg的后缀,所以我们直接open就行,注意打开方式是"wb",因为我们前面是用二进制的形式爬取的内容,所以"b"不能忘记了
运行
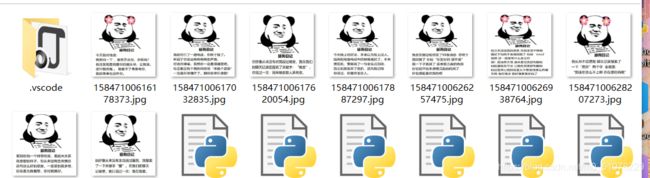
成功!!!