python爬虫第一天
python爬虫第一天
- python语言的基础知识
-
- 认识python
-
- python概述
- 安装Python开发环境
- Python的基本语句
-
- 输出
- 换行输出
- 输入
- 运算符和表达式
-
- 算术运算符
- 比较运算符
- 逻辑运算符
- 成员运算符
- 身份运算符
- 运算符优先级
- 判断语句和循环语句
-
- 条件判断语句:if语句
-
- 模块引入库
- 循环语句
-
- for...in循环
- while循环
- break和continue
- 字符串、列表、元组、字典
-
- 字符串
-
- Python转义字符表
- 字符串的常见操作
- 列表(List)
-
- for循环和list的联合使用:
- list的截取
- list的基础操作(增删改查)
- 元组(Tuple)
- 字典(Dict)
-
- 枚举函数
- 集合(Set)
- 小结:
- 函数
-
- 函数的定义和调用
- 文件操作
-
- 文件的定义
- 文件的打开与关闭
- 总结:
- 异常
-
-
- 捕获所有异常
- try...和finally的嵌套
-
视频课程链接
python语言的基础知识
认识python
python概述
python是一门解释型、面向对象的高级编程语言
python是开源免费的、支持交互的、可跨平台移植的脚本语言
面向对象的三大特性:
封装
继承
多态
python的典型应用:
web开发→Django,TurboGears,web2py等框架
科学计算→NumPy,SciPy,Matplotlib可以让Python程序员编写科学计算程序
服务器软件→Python对于各种网络协议的支持很完善,因此经常被用于编写服务器软件、网络爬虫
游戏→很多游戏使用C++编写图形显示等高性能模块,而使用Python或者Lua编写游戏的逻辑、服务器
桌面软件→PyQt、PySide、wxPython、PyGTK是Python快速开发桌面应用程序的利器
自动化脚本→大多数Linux发行版以及NetBSD、OpenBSD和MACOSX都集成了Python,可以在终端下直接运行Python
安装Python开发环境
- Python代码是以.py为扩展名的文本文件,要运行代码,需要安装Python解释器
- CPython是官方默认的编译器,安装Python之后直接获得该解释器
下载Python
下载链接
↓
安装Python
有几点需要注意一下,第一就是尽量不要安装到C盘,第二就是安装路径里面不要包含中文,第三就是要记得添加Python到PATH里面;添加Python到环境变量中
↓
下载IDE(集成开发环境)–PyCharm,安装PyCharm时也要注意能勾选的就全勾选上
下载PyCharm
python的缺点:
1.运行速度有一丢丢慢
因为python是解释性语言,运行时翻译为CPU能直接执行的机器码非常耗时,在超大型项目上很少用python
2.代码不能加密
解释型语言发布程序就是发布源代码,而C语言就可以编译好的机器码发出去,保密性强
Python的基本语句
注释
Python的单行注释符号:
#单行注释
python的单行注释可以写在语句的后面
Python的多行注释符号:
'''
这是第一行注释
这是第二行注释
'''
最简单的输出语句:print语句
print("标准化输出字符串")
应用:
print("hello,world")
→
 赋值语句和print语句的连用
赋值语句和print语句的连用
应用:
a = 10
print("输出字符串:",a)
→
![]()
变量及类型
变量可以是任意的数据类型,在程序中用一个变量名表示
变量名必须是大小写英文、数字和下划线的组合,并且不能用数字做开头,如:
>>>a = 1 #变量a是一个整数
>>>t_007 = 'T007' #变量t_007是一个字符串
变量名绝对不可以是关键字
变量的赋值
赋值(比如a = ‘ABC’ )时,Python解释器干了两件事:
- 在内存中创造了一个’ABC’的字符串
- 在内存中创建一个名为a的变量名,并且把它指向’ABC’
标识符和关键字
python中一些具有特殊功能的标识符,就是关键字
查询关键字的语句:
>>>import keyword
>>>keyword.kwlist
→
 三个>>>是表示一定要在python的环境下运行
三个>>>是表示一定要在python的环境下运行
输出
普通输出
print("hello,world")
格式化输出
格式化操作的目的
比如有以下代码
print("我今年10岁")
print("我今年11岁")
print("我今年12岁")
- 想一想
在输出年龄的时候,用了多次"我今年XX岁",能否简化一下程序呢???
- 答
字符串格式化
来看如下代码:
age = 10
print("我今年%d岁"%age)
age += 1
print("我今年%d岁"%age)
age += 1
print("我今年%d岁"%age)
↑在这里,d表示一个整型数字
这里补充一下常用的符号
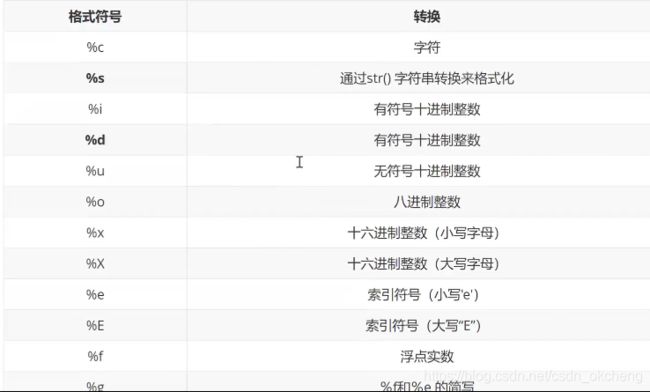 其中%s和%d是比较常用的
其中%s和%d是比较常用的
d表示decimal十进制的
s表示string字符串
应用:
name = '小美'
ctr = '中国'
print("我的名字是%s,我的国籍是%s"%(name,ctr))
基本输出的基本拼接:默认用空格去拼接
print("a","bb","ccc")
→
![]()
自定义拼接:
自定义分隔符
应用:
print("www","baidu","com",sep="." )
→
![]()
换行输出
单语句换行输出
print("1234567890---------")#会在一行显示
print("1234567890\n--------")#一行显示1234567890,另一行显示--------
多语句换行输出
print("hello",end="")#此句结束结果与下一句的结果不分行
print("world",end="\t")#此句结束结果与下一句的结果不分行,但是隔一个Tab
print("python",end="\n")#此句结束结果与下一句的结果分行
print("end")
→

输入
password = input("请输入密码是:")
print('您刚刚输入的密码是:',password)
运算符和表达式
算术运算符
+
-
*
/
%#取余数
**#幂
//# 整除
比较运算符
==
!=
>
<
>=
<=
逻辑运算符
and
or
not
成员运算符
in
not in
身份运算符
is#is是判断两个标识符是不是引用自同一个对象 也即判断是否id(x) == id(y)
is not
运算符优先级
从上往下优先级越来越低:
**
* / % //
+ -
>> <<#左移右移运算符
&#位'AND'
^ | #位运算符
<= >= < >
<> == !=
= %= /= //= -= += *= **=# 赋值运算符
is is not
in not in
and or not
判断语句和循环语句
条件判断语句:if语句
- 计算机之所以能够做很多自动化的任务,就是因为它可以自己做条件判断
- Python指定任何的非0和非空值为True,0或者None为False
- Python编程中if语句用于控制程序的执行,基本形式为:
-
if 判断条件1 :
执行语句1
elif 判断条件2 :
执行语句2
else:
执行语句3
应用:
if True :
print("True")
else :
print("False")
↑注意这里的兰色的True不可以搞错大小写,并且为了保证格式优美,严格要求缩进一致
elif的应用:
score =77
if score >= 90 and score <=100 :
print("本次考试等级为A")
elif score >= 80 and score < 90 :
print("本次考试等级为B")
elif score >= 70 and score < 80 :
print("本次考试等级为C")
elif score >=60 and score < 70 :
print("本次考试等级为D")
else :
print("本次考试不合格")
注意:if函数可以嵌套
模块引入库
在python用import 或者 from …import 来导入相应的模块。
- 将整个模块(somemodule)导入,格式为:
import somemodule
- 从某个模块中导入某个函数,格式为:
from somemodule import somefunction
- 从某个模块中导入多个函数,格式为:
from somemodule import firstfunc,secondfunc,thirdfunc
- 将某个模块中的全部函数导入,格式为:
from somemodule import \*
生成随机数
1.第一行代码引入库
应用:
import random #引入随机数
x = random.randint(0,2) # 随机生成[0,2]之间的一个整数
print(x)

player1 = input("请输入下列三个数字中的一种:石头(0)、剪刀(1)、布(2)")
player1 = int(player1)
import random
comp1 = random.randint(0,2)
print(comp1)
if player1 == comp1 :
print("平手了")
elif player1 == 0 and comp1 == 1 or player1 == 1 and comp1 == 2 or player1 == 2 and comp1 == 0 :
print("你赢了")
elif player1 == 0 and comp1 == 2 or player1 == 1 and comp1 == 0 or player1 == 2 and comp1 == 1:
print("你输了")
↑错因:用户输入了0、1或2之后,是字符串,还需要用一个int()函数转化为常量,这是方法一;方法二是将判断条件里的0 更换为’0’
循环语句
for…in循环
for…in循环可以依次把list或tuple中的元素迭代出来
应用:
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
>>> for i in range(0,10,3):
... print(i)
...
0
3
6
9
a = ["aa","bb","cc","dd"]
for i in range(len(a)):
print(i,a[i])
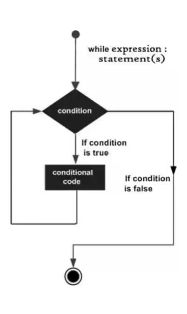
while循环
while循环逻辑图:
i = 0
while i < 5:
print("当前是第%d次执行循环"%(i+1))
print("i=%d"%i)
i += 1
#1-100求和
a = 2
b = 1
while a < 101 :
b = b+a
print(b)
a += 1
注意这里的最后一句一定要是a 的自加语句
while语句的特例:
while语句和else关键字的连用
应用:
count = 0
while count < 5:
print(count,"小于5")
count += 1
else:
print(count,"大于或等于5")
→

break和continue
break语句可以跳出for 和while的循环体
continue语句跳过当前循环,直接进行下一轮循环
pass是空语句,一般用做占位语句,不做任何事情
>>>for letter in 'Room':
...if letter == 'o':
... pass
... print('pass')
... print(letter)
→

应用:
i = 0
while i < 10:
i = i+1
print("-"*30)
if i == 5:
break #结束整个循环
print(i)
→

i = 0
while i < 10:
i = i+1
print("-"*30)
if i == 5:
continue #结束本次循环(上个while)
print(i)
→


a1 = 1
b1 = 1
while a1 <= 9:
print(a1, "*", b1, "=", a1 * b1, end="\t", sep="")
if a1 > b1:
b1 += 1
continue
else:
print("\n")
a1 += 1
b1 = 1
continue
else:
pass
↑(while实现)正确答案
for i in range(1,10):#从1(含)开始,到10(不含)结束,步进值默认为1
for j in range(1,i+1):
print(i,"*",j,"=",i*j,end="\t",sep="")
print("")
↑(for实现)正确答案
字符串、列表、元组、字典
字符串
python的核心数据类型
String (字符串)
- Python的字符串可以使用单引号、双引号和三引号(三个单引号或者三个双引号)括起来,使用反斜杠转义特殊字符
- Python3源码文件默认以UTF-8编码,所有字符串都是Unicode字符串
- 支持字符串拼接、截取等多种运算
应用:
word = '字符串'
sentence = "这是一个句子。"
paragraph = """
这是
一个
段落
"""
双引号和单引号的区别:就是双引号之中可以再加单引号,但是不能再加双引号(除非用转义字符)
Python转义字符表

 字符串的截取
字符串的截取
应用:
str = "chengdu"
print(str)
print(str[0:6])#str[起始位置:结束位置(默认为最后一个):步进值]
→
![]() 字符串的连接
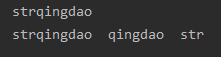
字符串的连接
1.可以使用加号
2.可以使用逗号
应用:
str = qingdao
print("str"+str,str,"str")
→
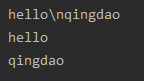
r在字符串中的应用
print(r"hello\nqingdao")
print("hello\nqingdao")#使用转义字符
→
字符串的常见操作
- capitalize()将字符串的第一个字符转换为大写
- center(width,fillchar)返回一个指定宽度居中的字符串,fillchar为填充的字符,默认为空格
- count(str,beg = 0,end=len(string))返回str在string里面出现的次数,如果beg或者end指定则返回指定范围内str出现的次数
-
- bytes.decode(encoding=“utf-8”,errors=“strict”)
Python3中没有decode方法,但我们可以使用bytes对象的decode()方法来解码给定的bytes对象,这个bytes对象可以由str.encode()来编码返回
- bytes.decode(encoding=“utf-8”,errors=“strict”)
-
- encode(encoding=“utf-8”,errors=“strict”)
以encoding指定的编码格式编码字符串,如果出错默认报一个ValueError的异常,除非errors指定的是’ignore’或者’replace’
- encode(encoding=“utf-8”,errors=“strict”)
- endswith(suffix,beg=0,end=len(string))检查字符串是否以obj结束,如果beg或者end指定则检查指定范围内是否以obj结束,如果是,返回True,否则返回False
- expandtabs(tabsize=8)把字符串string中的tab符号转为空格,tab符号默认的空格数是8
- find(str,beg=0,end=len(string))检测str是否包含在字符串中,如果指定范围beg和end,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1
- index(str,beg=0,end=len(string))跟find()方法一样,只不过如果str不在字符串中会报一个异常
-
- isalnum()如果字符串至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False
- isalpha()如果字符串至少有一个字符并且所有字符都是字母则返回True,否则返回False
- isdigit()如果字符串只包含数字则返回True,否则返回False
- islower()如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是小写,则返回True,否则返回False
-
- isnumeric()如果字符串中只包含数字字符,则返回True,否则返回False
- isspace()如果字符串中只包含空白,则返回True,否则返回False
- istitle()如果字符串是标题化的(见title())则返回True,否则返回False
- isupper()如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是大写,则返回True,否则返回False
-
- join(seq)以指定字符串作为分隔符,将seq中所有的元素(的字符串表示)合并为一个新的字符串
-
- len(string)返回字符串的长度
- [ljust(width,fillchar)]返回一个原字符串左对齐,并使用fillchar填充至长度为width的新字符串,fillchar默认为空格
- lower()转换字符串中所有大写字符为小写
-
- lstrip()截掉字符串左边的空格或指定字符
- maketrans()创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标
- max(str)返回字符串str中最大的字母
- min(str)返回字符串str中最小的字母
- [replace(old,new,max)]把将字符串中的str1替换为str2,如果max指定,则替换不超过max次
- rfind(str,beg=0,end=len(string))类似于find()函数,不过是从右边开始查找
- rindex(str,beg=0,end=len(string))类似于index(),不过是从右边开始
- [rjust(width,fillchar)]返回一个原字符串右对齐,并使用fillchar(默认空格) 填充至长度width的新字符串
- rstrip()删除字符串字符串末尾的空格
-
- split(str="",num=string.count(str)num=string.count(str))以str为分隔符截取字符串,如果num有指定值,则仅截取num+1个子字符串
- [splitlines(keepends)]按照行(’\r’,’\r\n’,’\n’)分隔,返回一个包含各行作为元素的列表,如果参数keepends为False。如果beg和end指定值,则在指定值范围内检查。
- [strip(chars)]在字符串上执行lstrip()和rstrip()
- swapcase()将字符串中的大写转换为小写,小写转换为大写
- title()返回"标题化"的字符串,就是说所有单词都是以大写开始的,其余字母均为小写(见istitle())
- translate(table,deletechars="")根据str给出的表(包含256个字符)转换string的字符,要过滤掉的字符放到deletechars参数中
- upper()转换字符串中的小写字母为大写
- zfill(width)返回长度为width的字符串,原字符串右对齐,前面填充0
- isdecimal()检查字符串是否只包含十进制字符,如果是返回True,否则返回False
列表(List)
列表非常像其他语言的数组
- 列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
- 列表是写在方括号之间、用逗号分隔开的元素列表
- 列表索引值以0为开始值,-1为从末尾的开始位置
- 列表可以使用+操作符进行拼接,使用*表示重复
定义一个空列表:
namelist = []
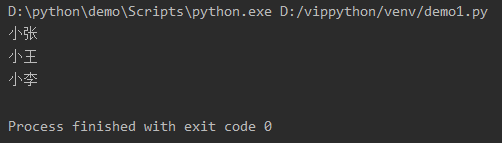
for循环和list的联合使用:
namelist = ['小张','小王','小李']
for namelist in range(0,3)
print namelist
→
 len()函数可以得到列表的长度
len()函数可以得到列表的长度
namelist = ['小张','小王','小李']
print(len(namelist))
→
3
list的截取
应用:
list = ['abcd',786,2.23,'runoob',70.2]
print(list[1:3])
→
![]()
list的基础操作(增删改查)

- 增↓
append整体追加
namelist = ['小张','小王','小李']
print("-----增加操作之前的效果------")
for i in namelist:
print(i)
nametemp = input("请输入要查询的姓名")
namelist.append(nametemp)
print("-----增加操作之后的效果------")
for i in namelist:
print(i)
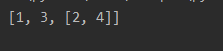
append追加可以追加list
a = [1,3]
b = [2,4]
a.append(b)
print(a)
→
extend逐一追加
a = [1,3]
b = [2,4]
a.extend(b)
print(a)
→
![]()
insert插入
a = [0,1,2]
a.insert(1,3) #第一个变量表示下标,第二个表示插入元素
print(a)
→
![]()
- 删↓
del namelist[下标值]
movieName = ["加勒比海盗","黑客帝国","第一滴血","指环王","速度与激情"]
print("-----删除操作之前的效果------")
for i in movieName:
print(i)
del movieName[2]
print("-----删除操作之后的效果------")
for i in movieName:
print(i)
→

pop:
movieName = ["加勒比海盗","黑客帝国","第一滴血","指环王","速度与激情"]
print("-----删除操作之前的效果------")
for i in movieName:
print(i)
movieName.pop()
print("-----删除操作之后的效果------")
for i in movieName:
print(i)
→

remove直接移除第一个:
movieName = ["加勒比海盗","黑客帝国","第一滴血","指环王","速度与激情"]
print("-----删除操作之前的效果------")
for i in movieName:
print(i)
movieName.remove("指环王")
print("-----删除操作之后的效果------")
for i in movieName:
print(i)
→

- 改↓
namelist[下标值] = 修改后字符串
namelist = ['小张','小王','小李']
print("-----修改操作之前的效果------")
for i in namelist:
print(i)
namelist[1] = "小红"
print("-----修改操作之后的效果------")
for i in namelist:
print(i)
→

- 查↓
in /not in
findName = input("请输入你要查找的学生姓名:")
namelist = ['小张','小王','小李']
if findName in namelist:
print("在学员名单中找到了相同的名字")
else:
print("很抱歉,没有找到")
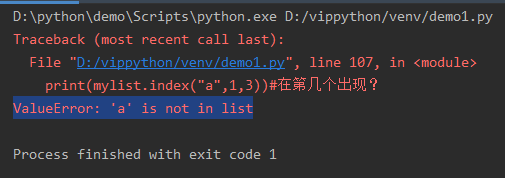
index查找
mylist = ["a","b","c","a","b"]
print(mylist.index("a",1,4))#在第几个出现?
→
3
mylist = ["a","b","c","a","b"]
print(mylist.index("a",1,3))#这里的报错也可以通过捕捉或者异常处理使得程序继续进行
→
 >count查找
>count查找
mylist = ["a","b","c","a","b"]
print(mylist.count("c"))#“c”一共出现了几次?
→
1
- 排序↓
sort排序
a = [1,4,2,3]
print(a)
a.sort()#默认升序排列
print(a)
a.sort(reverse=True)#降序排列
print(a)
→

- 反转↓
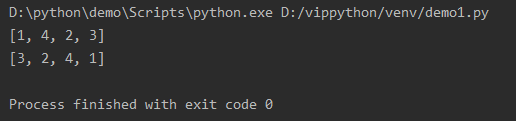
reverse反转
a = [1,4,2,3]
print(a)
a.reverse()
print(a)
→
二维数组及其嵌套
schoolNames = [['北京大学','清华大学'],['天津大学','南开大学','天津师范大学'],['山东大学','中国海洋大学']]
print(schoolNames[0][0])
→
![]()
练习:
8个老师随机分配到3个教室里
className = [[],[],[]]
teacherName = ["A","B","C","D","E","F","G","H"]
import random
for tName in teacherName:
index = random.randint(0,2)
className[index].append(tName)
print (className)
↑↓
className = [[],[],[]]
teacherName = ["A","B","C","D","E","F","G","H"]
import random
for tName in teacherName:
index = random.randint(0,2)
className[index].append(tName)
i = 1
for cName in className:
print("第%d个教室的人数为:%d"%(i,len(cName)))
for tName in cName:
print("人名字分别为:%s"%tName,end="\t")
i += 1
print("\n")
print("-"*10)

1
products = [["iphone",6888],["MacPro",14800],["小米6",2499],["Coffee",31],["Book",60],["Nike",699]]
print("-"*5,"商品列表","-"*5)
for product in products:
print(products.index(product),"\t",product[0],"\t",product[1])
↑↓
products = [["iphone",6888],["MacPro",14800],["小米6",2499],["Coffee",31],["Book",60],["Nike",699]]
print("-"*5,"商品列表","-"*5)
for i,item in enumerate(products):
print(str(i)+"\t"+item[0]+str(item[1]))
2个人答案:
products = [["iphone", 6888], ["MacPro", 14800], ["小米6", 2499], ["Coffee", 31], ["Book", 60], ["Nike", 699]]
for product in products:
print("您想买%s吗?它的商品编号是%d,它的价格是%d" % (product[0], products.index(product), product[1]))
shuru = input("您想继续购买什么商品吗?请输入“yes”并按回车表示您想,输入“q”并按回车来表示您不想:")
if shuru.isdigit():
shuru = int(shuru)
while shuru in "yes":
buys = []
buy = input("请输入您想购买的一个商品的商品编号,没有则输入“q”:")
buys.extend(buy)
if buy in "q":
buys.pop()
break
print("选择结束,感谢惠顾~")
print(buys)
for f_buy in buys:
print(f_buy, products[int(f_buy)][0], products[int(f_buy)][1])
第2题正确答案:
products = [["iphone", 6888], ["MacPro", 14800], ["小米6", 2499], ["Coffee", 31], ["Book", 60], ["Nike", 699]]
shopping_car =[0 for i in range(6)]#每个商品各自买了几件
count = 0#买了吗?
sum = 0#一共花费
while True:
id = input("请输入您想购买的商品编码:")
if id.isdigit():
id = int(id)#将输入的id转化为整型
if id < 0 or id > len(products):#输入规范
print("不够规范,请重输")
continue
else:
count += 1
shopping_car[id] += 1
print(shopping_car)
elif id =="q" and id.isalpha():
if count == 0:
print("您什么都没买,欢迎下次光临")
else:
print("您一共购买了:")
i = 0
for num in shopping_car:
if num != 0:
print(num,products[i][0],num*products[i][1],sep="\t")
sum += products[i][1]*num#注意是价格*数量
i += 1#i自加成为循环
print(sum)
exit()#系统退出
元组(Tuple)
tuple与list类似,不同之处在于tuple的元素不能修改
- tuple写在小括号里,元素之间用逗号隔开
- 元组的元素不可变,但可以包含可变对象,如list
- 注意:单元素tuple,必须含逗号
应用:
元组嵌套列表的修改
t2 = ('a','b',['A','B'])
t2[2][0] = 'X'
print(t2)
→
![]()
- 增↓
tup1 = (12,34)
tup2 = (56,78)
tup = tup1 +tup2
print(tup)
- 删↓
tup1 = (12,34)
del tup1
print(tup)
字典(Dict)
dict(字典)
- 字典是无序的对象集合,使用键-值对儿存储,具有极快的查找速度
- 键(key)必须使用不可变类型
- 同一个字典中,键具有唯一性
info = {
"name":"吴彦祖","age":18}# 字典的定义
print(info["name"])
print(info["age"])# 字典的访问
print(info.get("gender","m"))#使用get方法没有找到对应的键,返回"m",不写默认返回None
→

- 增↓
info = {
"name":"吴彦祖","age":18}
newID = input("请输入新的学号")
info["id"] = newID#赋值就是增
print(info["id"])
- 删↓
del删除
info = {
"name":"吴彦祖","age":18}
print("删除前:%s"%info["name"])
del info["name"]
#print("删除后:%s"%info["name"]) #删除键值对儿之后再次访问会报错
python快捷键:快速全注释: ctrl + /
clear全清空
info = {
"name":"吴彦祖","age":18}
print("清空前:%s"%info)
info.clear()
print("清空后:%s"%info)
→
![]()
- 改↓
info = {
"name":"吴彦祖","age":18,"id":2021}
newID = input("请输入新的学号")
info["id"] = newID#赋值就是改
print(info["id"])
- 查↓(可以理解为遍历)
info = {
"id":1,"name":"吴彦祖","age":18}
print(info.keys()) #得到所有的键(列表)
print(info.values()) #得到所有的值(列表)
print(info.items())# 得到所有的项(列表)
#遍历所有的值
info = {
"id":1,"name":"吴彦祖","age":18}
for key in info.keys():
print(key)
for key,value in info.items():
print("key=%s,value=%s"%(key,value))
→

枚举函数
enumerate()
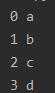
mylist = ["a","b","c","d"]
for i,x in enumerate(mylist):
print(i,x)
→
集合(Set)
- 集合与dict类似,也是一组key的集合,但是不会存储value。由于key不能重复,所以,在set中,没有重复的key
- set是无序的,重复元素在set中自动被过滤
语法:
s = set([1,2,3])
print(s)
→
![]()
小结:
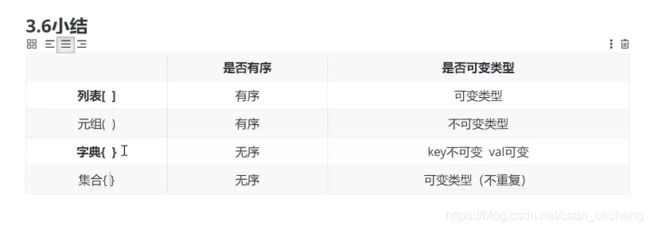
集合: ([ ])
.
函数
函数的定义和调用
定义函数的语法:
def 函数名():
代码
应用:函数的定义与调用↓
def printinfo():
print("-"*30)
print("人生苦短,我用Python")
print("-"*30)
printinfo()
→

带参数的函数
def add2Num(a,b):
c = a + b
print(c)
add2Num(11,22)
→
33
带返回值的函数
def add2Num(a,b)
return a+b
print(add2Num(11,22))
→
33
返回多个值的函数
def divid(a,b):
shang = a//b#//表示整除
yushu = a%b#%表示a除以b取余数
return shang,yushu
sh,yu = divid(5,2)
print("商:%d,余数:%d"%(sh,yu))
→
![]()
全局变量和局部变量
def test1():
a =300
print("test1-------修改前:a = %d"%a)
test1()
→
![]()
def test1():
a =300
print("修改前:a = %d"%a)
def test2():
a = 500
print("修改前:a = %d"%a)
test1()
test2()
→
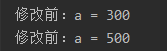
↑局部变量是发生在函数内部的变量
局部变量的优先级默认大于全局变量,如果想要全局变量的优先级更大,需要使用global函数,参考下面的例子:
a = 100
def test1():
global a #声明这里的a是全局变量a
print("test1------a = %d"%a)
a = 200
print("test1------a = %d"%a)
test1()#这一句是为了调用test1*()函数
→

文件操作
文件的定义
文件,就是把一些数据存放起来,可以让程序下一次执行的时候直接使用,而不必重新制作一份,省时省力
文件的打开与关闭
- 打开
在 python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件
语法:
open(文件名,访问模式)
f = open('test.txt','w')#打开时如果未找到文件则会新建一个文件
- 关闭
f.close()
访问模式:
 - 读取
- 读取
f = open("test.txt","r")
content = f.read(5)#read不是只从开头就开始读5个,而是从上次执行的地方开始数5个开头
print(content)
f.close()
→
![]()
f = open("test.txt","r")
content = f.readlines()#readlines是将整个文档都帮你读取出来。所有的结果以列表显示
print(content)
f.close()
→
![]()
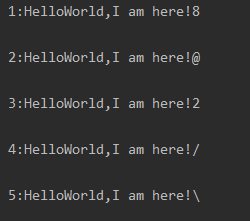
readlines和for循环的联合使用:
f = open('test.txt','r')
content = f.readlines()
i = 1
for temp in content:
print(i,":",temp)
#↑↓
#print("%d:%s"%(i,temp))
i += 1
f.close()
→
- 写入
f.write()
语法:
f = open('test.txt','w')
f.write("HelloWorld,I am here!")
f.close()
→

总结:
os模块的重要
文件重命名
os模块中的 rename()可以完成对文件的重命名操作
rename(需要修改的文件名,新的文件名)
import os
os.rename('test.txt','test1.txt')
删除文件
创建文件夹
获取当前目录
改变默认目录
获取目录列表
删除文件夹
异常
异常:
异常是可以预知的
看如下示例:
print'-------test--1------'
open('123.txt','r')
print'-------test--2------'
运行结果:
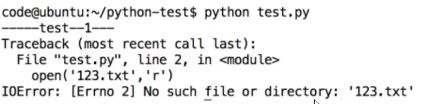
说明:
打开一个不存在的文件123.txt,当找不到123.txt文件时,就会抛出给我们一个 IOError类型的错误,No such file or directory:123.txt(没有123.tx这样的文件或目录)
异常捕获↓:
try:
print("-------test--1----")
f = open('123.txt','r')#用只读模式打开了一个不存在的文件,报错
print("-------test--2----")#这句代码不会被执行
except IOError:#文件没找到,属于IOError=输入输出异常
pass#pass只有一个占位功能
→

多种异常捕获:
try:
print("------test---1------")
f = open("test1.txt","r")
print("------test---2------")
print(num)#这里的num是一个没有定义的变量
except(NameError,IOError):#将可能产生的所有异常类型,都放到下面的小括号中
print("产生错误了")
→

异常类型获取:
except…as…
try:
print("------test---1------")
f = open("test1.txt","r")
print("------test---2------")
print(num)#这里的num是一个没有定义的变量
except(NameError,IOError) as result:#将可能产生的所有异常类型,都放到下面的小括号中
print("产生错误了")
print(result)
→

捕获所有异常
这里需要参考上文
except Exception as result:#Exception就表示所有的异常
print(result)
try…和finally的嵌套
这里嵌套的原因是:
我们进行此次操作的前提是不知道123.txt文件是否确实存在的;无论发生什么,finally保证文件一定可以关闭,出现任何问题,又可以用exception做一个完整的记录
import time#引入时间模块,因为后面会有休息
try:
f = open("123.txt","r")#如果这里能打开,后面一定要关闭,如果这里文件名是空的,那么后面也不需要在意;这里的打开方式为只读
try:
while True:#写成一个无限循环语句,直到读不到任何内容
content = f.readline()#f.readline()函数和f.readlines()函数不同,是只读取指定txt文件的从上次运行位置开始的一行
if len(content) == 0:
break# 中断整个循环
time.sleep(2) #休息2s
print(content)
finally:
f.close()
print("文件关闭")
except Exception as result:
print("发生异常。。。")