python爬取岗位数据并分析_Python分析爬取拉勾网数据分析,运营,产品经理岗位
一,模块及读取数据
数据为2019.7.31爬取的拉勾网北京市数据分析,运营,产品经理岗位招聘数据及上海市数据分析岗位招聘数据,下载在最下面
一,模块及读取数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
# 不发出警告
plt.rcParams['font.sans-serif'] =['SimHei'] # 解决中文显示问题-设置字体为黑体
plt.rcParams['axes.unicode_minus'] =False # 解决保存图像是负号'-'显示为方块的问题
import jieba
from wordcloud import WordCloud
from scipy.misc import imread,imresize
import os
os.chdir('C:/Users/Administrator/Desktop/北京python数据分析/')
# 创建工作路径
#读取数据
df01 =pd.read_csv('beijing_lagou.csv',encoding = 'utf-8')
df = df01.copy()
df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True)
二,数据处理
# 由于CSV文件内的数据是字符串形式,先用正则表达式将字符串转化为列表,再取区间的均值
pattern = '\d+'
df['work_year'] = df['工作年限'].str.findall(pattern)
# 数据处理后的工作年限
avg_work_year = []
# 工作年限
for i in df['work_year']:
# 如果工作经验为'不限'或'应届毕业生',那么匹配值为空,工作年限为0
iflen(i) == 0:
avg_work_year.append(0)
# 如果匹配值为一个数值,那么返回该数值
elif len(i) == 1:
avg_work_year.append(int(''.join(i)))
# 如果匹配值为一个区间,那么取平均值
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list)/2
avg_work_year.append(avg_year)
df['工作经验'] =avg_work_year
# 将字符串转化为列表,再取区间的前25%,比较贴近现实
df['salary'] = df['薪资'].str.findall(pattern)
# 月薪
avg_salary = []
for k in df['salary']:
int_list = [int(n) for n in k]
avg_wage = int_list[0]+(int_list[1]-int_list[0])/4
avg_salary.append(avg_wage)
df['月工资'] =avg_salary
# 将学历不限的职位要求认定为最低学历:大专\
df['学历要求'] = df['学历要求'].replace('不限','大专')
三, 2019年8月北京市数据分析等岗位薪资直方图
sns.set()
sns.set_style("ticks")
plt.rcParams['font.sans-serif'] =['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] =False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
#####薪资直方图
sns.distplot(df['月工资'],bins = 10,hist = True,kde = False,norm_hist=False,
rug = True,vertical = False,
color = 'blue',label = '2019年8月北京市数据分析薪资',axlabel = '工资 (千元)')
plt.savefig('2019年8月北京市数据分析薪资.jpg', dpi=200)
plt.legend()

北京市数据分析薪资
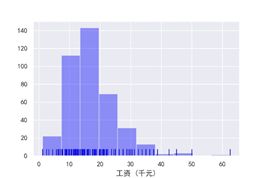
上海市数据分析薪资
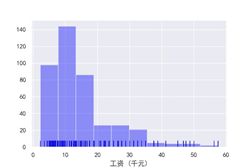
北京市运营薪资
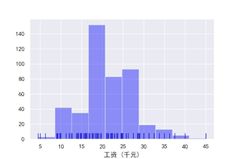
北京市产品经理薪资
#结论:2019年8月北京市数据分析薪资大部分处于15~20k之间,上海市数据分析薪资大部分处于10~20k之间,北京市运营薪资大部分处于5~20k之间,北京市产品经理薪资大部分处于16~30k之间,产品经理工资最高
四, 2019年8月北京市各区数据分析岗位占比饼图
count = df['工作地点'].value_counts()
count = count.loc[['朝阳区', '昌平区', '东城区', '大兴区', '西城区', '海淀区', '石景山区', '通州区', '延庆区']] # 调整顺序
plt.pie(count, labels =count.keys(),labeldistance=1.05,autopct='%2.2f%%',pctdistance=0.6,radius=1.5,startangle=150)
plt.axis('equal') # 使饼图为正圆形
#plt.legend(loc='upper left',bbox_to_anchor=(-0.2,0.9))
plt.title("2019年8月北京市各区数据分析岗位占比")
plt.savefig('2019年8月北京市各区数据分析岗位占比.jpg', dpi=200)
plt.show()
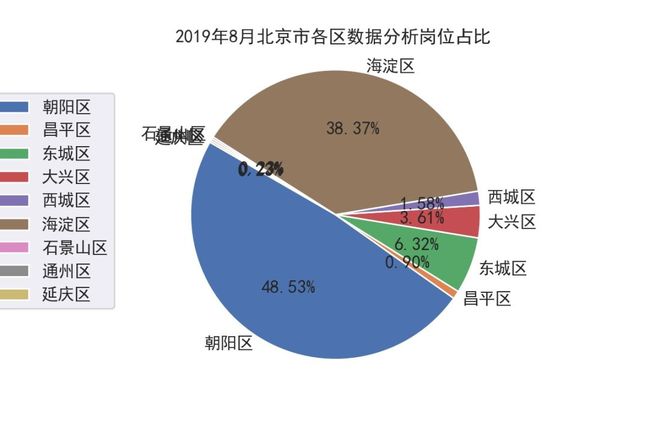
北京市数据分析各区占比

上海市数据分析各区占比

北京市运营各区占比
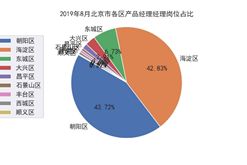
上海市产品经理各区占比
#结论:2019年8月北京市数据分析,运营,产品经理的公司最多的是朝阳区、其次是海淀区。再次是东城区,准备去北京工作的小伙伴大概知道去哪租房了吧
五, 学历要求直方图
dfxlyq = df['学历要求'].value_counts()
dfxlyq = pd.DataFrame(dfxlyq)
dfxlyq = dfxlyq.reset_index()
dfxlyq.columns = ['最低要求学历','招聘人数']
sns.barplot(x="招聘人数", y="最低要求学历", data=dfxlyq,
palette = 'Blues',edgecolor = 'w')
plt.savefig('2019年8月北京市数据分析学历要求.jpg', dpi=200)
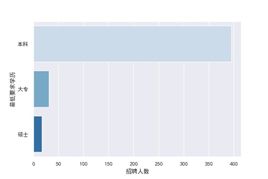
北京市数据分析学历要求
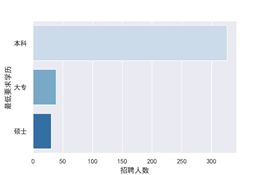
上海市数据分析学历要求
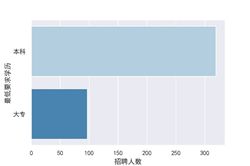
北京市运营学历要求

北京市产品经理学历要求
#结论:2019年8月北京市数据分析,运营,产品经理的最低要求学历大部分都是本科,适合学渣打拼啊,且北京市数据分析岗位招聘本科岗位数略多于上海市
六, 工作年限要求直方图
#######工作年限要求直方图
sns.set_context("paper")
dfgznx = df['工作年限'].value_counts()
dfgznx = pd.DataFrame(dfgznx)
dfgznx = dfgznx.reset_index()
dfgznx.columns = ['工作年限','招聘人数']
sns.barplot(x="招聘人数", y="工作年限", data=dfgznx,
palette = 'GnBu_r',edgecolor = 'w')
plt.savefig('2019年8月北京市数据分析工作年限要求.jpg', dpi=200)

北京市数据分析经验要求
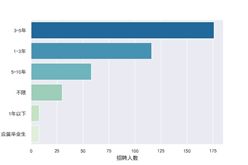
上海市数据分析经验要求

北京市运营经验要求
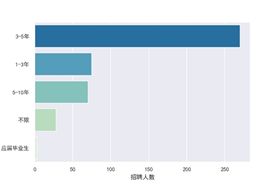
北京市产品经理经验要求
#结论:2019年8月北京市数据分析,产品经理岗位,企业最需要能直接干活的经验多的成手,运营岗位最需要经验不多的下手七, 福利待遇词云图
text = ''
for line in df['福利待遇']:
text += line
# 使用jieba模块将字符串分割为单词列表
cut_text = ''.join(jieba.cut(text))
color_mask =imread('C:/Users/Administrator/Desktop/cloud.jpg') #设置背景图
cloud = WordCloud(
background_color = 'white',
# 对中文操作必须指明字体
font_path='C:\windows\Fonts\STZHONGS.TTF',
mask = color_mask,
max_words = 50,
max_font_size = 200
).generate(cut_text)
# 保存词云图片
cloud.to_file('word_cloud.jpg')
plt.imshow(cloud)
plt.axis('off')
plt.show()

北京市数据分析待遇词云图

上海市数据分析待遇词云图

北京市运营待遇词云图

上海市产品经理待遇词云图
#结论:扁平管理就是得多干活,弹性工作就是要加班八,导出LV0及LV1数据分析岗位公司表
ssss = df[df['学历要求']!='硕士'][df['工作经验']<2][df['月工资']<17]
ssss.drop(ssss[ssss['工作年限'].str.contains('应届毕业生')].index,inplace=True)
ssss.sort_values(by = '月工资',inplace = True,ascending=False)
ssss.reset_index(inplace=True)
del ssss['index']
ssss.to_excel('C:/Users/Administrator/Desktop/lv0shujufenxi.xlsx')
vvvv = df[df['学历要求']!='硕士'][df['工作经验']<=2][df['月工资']<20]
vvvv.drop(vvvv[vvvv['工作年限'].str.contains('应届毕业生')].index,inplace=True)
vvvv.sort_values(by = '月工资',inplace = True,ascending=False)
vvvv.reset_index(inplace=True)
del vvvv['index']
vvvv.to_excel('C:/Users/Administrator/Desktop/lv1shujufenxi.xlsx')
——End——
关注公众号“冬瓜书单”
回复关键字“拉勾网数据,
可获得2019.7.31爬取的拉勾网北京市数据分析,运营,产品经理岗位招聘数据及上海市数据分析岗位招聘数据