Python可视化(8):Pandas—数据的分组与聚合groupby,agg,apply
数据的分组与聚合
-
- 1. 分组与聚合的原理
- 2. 使用 groupby()方法拆分数据
-
- 2.1 按列名进行分组
- 2.2 按Series对象进行分组
- 2.3 按字典进行分组
- 2.4 按函数进行分组
- 3. 聚合数据
-
- 3.1 使用内置统计方法聚合数据
- 3.2 使用agg方法聚合数据
- 3.3 使用apply方法聚合数据
- 3.4 使用transform方法聚合数据
- 【练习】运动员信息表操作
数据来源: 文件在网盘里哟,除此之外还有其他文件资料呐。

链接:12讲Pandas—数据的分组与聚合
提取码:2p61
1. 分组与聚合的原理
在Pandas中,分组是指使用特定的条件将原数据划分为多个组,聚合在这里指的是,对每个分组中的数据执行某些操作,最后将计算的结果进行整合。
分组与聚合的过程大概分为以下三步:


2. 使用 groupby()方法拆分数据
该方法提供的是分组聚合步骤中的拆分功能,能根据索引或字段对数据进行分组。其常用参数与使用格式如下。

by参数的特别说明:
- 如果传入的是一个函数则对索引进行计算并分组。
- 如果传入的是一个字典或者Series则字典或者Series的值用来做分组依据。
- 如果传入一个列表或NumPy数组则数据的元素作为分组依据。
- 如果传入的是字符串或者字符串列表则使用这些字符串所代表的字段作为分组依据。
import pandas as pd
import numpy as np
detail = pd.read_excel(r"C:\meal_order_detail.xlsx")
print(detail.head())
2.1 按列名进行分组
如果DataFrame对象的某一列数据符合划分成组的标准,则可以将该列当做分组键来拆分数据集。
# 将订单详情按照 order_id 进行分组
detailGroup = detail[["order_id", "dishes_name"]].groupby(by="order_id")
detailGroup
注意:
- groupby()方法会返回一个 GroupBy对象,类似Series与DataFrame,是pandas提供的一种对象。
- 用groupby方法分组后的结果并不能直接查看,而是被存在内存中,输出的是内存地址。
- 使用Series调用groupby()方法返回的是SeriesGroupBy对象。
- 使用DataFrame调用groupby()方法返回的是DataFrameGroupBy对象。
如果要查看每个分组的具体内容,则可以使用 for 循环遍历 DataFrameGroupBy 对象。
# 遍历分组对象
for i in detailGroup:
print(i)
# 可以转换成字典查看
dicGroup = dict(i for i in detailGroup)
# 转换成字典后可以查看任意分组的内容
print(dicGroup[137])
print("-"*30)
# 可以转换成列表查看3个组
lst = list(detailGroup)[:3]
print(lst)
2.2 按Series对象进行分组
a = range(1,10)
ser = pd.Series(data=list(a)) # 索引可变
print(ser)
# 使用自定义的Series类对象作为分组键
group = detail[["order_id","# 使用自定义的Series类对象作为分组键
group = detail[["order_id","dishes_name"]].groupby(by=ser)
print(group)
# 查看分组后的数据
for i in group
print(i)"]].groupby(by=ser)
print(group)
# 查看分组后的数据
for i in group:
print(i)

注意:
- 自定义series对象作为分组键时,是先对series的values进行分组,然后对应到需要分组的对象数据。
- 如果Series对象与Pandas对象的索引长度不相同时,则只会将具有相同索引的部分数据进行分组。
2.3 按字典进行分组
当使用字典对DataFrame进行分组时,则需要确定轴的方向及字典中的映射关系,即字典中的键为列名,字典的值为自定义的分组名。
print(detail.dtypes)
# 定义分组关系 字典
dic = {
'order_id': '第一组', 'dishes_id': '第一组', 'dishes_name': '第一组',
'counts':'第二组', 'amounts':'第二组'}
group = detail.groupby(by=dic, axis=1)
for i in group:
print(i)
2.4 按函数进行分组
将函数作为分组键会更加灵活,任何一个被当做分组键的函数都会在各个索引值上被调用一次,返回的值会被用作分组名称。
import pandas as pd
df = pd.DataFrame({
'a': [1, 2, 3, 4, 5],
'b': [6, 7, 8, 9, 10],
'c': [5, 4, 3, 2, 1]},
index=['Sun', 'Jack', 'Alice', 'Helen', 'Job'])
print(df)
# 使用内置函数len进行分组
gg = df.groupby(by=len)
for i in gg:
print(i)
3. 聚合数据
3.1 使用内置统计方法聚合数据
GroupBy对象常用的描述性统计方法

# 按“order_id”进行分组,求每个分组的平均值
detailGroup = detail[["order_id","counts","amounts"]].groupby(by="order_id")
detailGroup.mean()
detailGroup.std()
3.2 使用agg方法聚合数据
如果内置方法无法满足聚合要求时,则可以自定义函数,将它作为参数传给agg()方法,实现Pandas对象的聚合运算。

(1)对每一列数据应用相同函数
通过agg()方法进行聚合,最简单的方式就是给该方法的func参数传入一个或几个函数,这个函数既可以是内置的,也可以自定义的。
import numpy as np
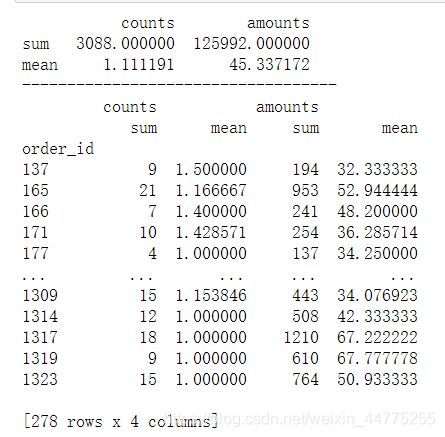
print(detail[["counts","amounts"]].agg([np.sum, np.mean]))
# 分组后的数据使用方法一样
print("-"*35)
print(detailGroup.agg([np.sum, np.mean]))
(2) 对不同列数据应用不同函数
如果希望对不同的列使用不同的函数,则可以在agg()方法中传入一个{“列名”:“函数名”}格式的字典。
(3) 对不同列数据应用数目不同的函数
此时只需要将字典对应key的value变为列表,列表元素为多个目标的统计函数即可!
# detail的 菜品销售量counts求总和, 售价amounts求均值
ag = detail[["counts", "amounts"]].agg({
"counts":np.sum, "amounts":np.mean})
print(ag)
# detail的 菜品销售量counts求总和, 售价amounts求总和、均值
mg = detail[["counts", "amounts"]].agg({
"counts":np.sum, "amounts":[np.mean, np.std]})
print(mg)

3.3 使用apply方法聚合数据

# apply: 订单详情表的菜品销售量与售价 平均值
ap = detail[["counts","amounts"]].apply(np.mean)
print(ap)
# apply: GroupBy对象聚合, 平均值
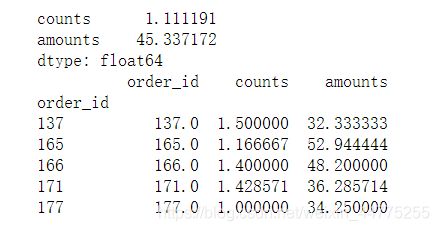
pg = detailGroup.apply(np.mean).head()
print(pg)
3.4 使用transform方法聚合数据
(1) transform方法能够对整个DataFrame的所有元素进行操作。且transform方法只有一个参数“func”,表示对DataFrame操作的函数。
(2) 同时transform方法还能够对DataFrame分组后的对象GroupBy进行操作.
(3) 保持与原数据集形状相同
trGroup = detail[["counts","amounts"]].transform(lambda x:x*a2)
print(trGroup)
【练习】运动员信息表操作
需求:
- 运动员信息表.csv
- 输出男篮分组信息
- 计算男篮的平均年龄、身高和体重
- 添加“体质指数”列 BMI = weight/(height^2)
# 读取运行员信息表.csv文件中的内容
info = pd.read_csv("./运动员信息表.csv", encoding="gbk")
print(info)
sports = info.groupby("项目")
basketball = dict(i for i in sports)["篮球"]
basketball_male = basketball.groupby("性别")
basketball_male = dict(i for i in basketball_male)["男"]

basketball_male[["年龄(岁)","身高(cm)","体重(kg)"]].agg(np.mean)
def BMI(df):
weight = df["体重(kg)"]
height = df["身高(cm)"]/100
return weight/(height**2)
bmi = BMI(basketball_male)
print(bmi)
print("--"*20)
basketball_male["体质指数"] = bmi
print(basketball_male)
完整代码:
print("运动员信息表为:\n", info)
group = info.groupby("项目")
basketball = dict(i for i in group)["篮球"]
group1 = basketball.groupby("性别")
basketball = dict(i for i in group1)["男"]
print("男篮信息表为:\n", basketball)
result = basketball[["年龄(岁)", "身高(cm)", "体重(kg)"]].agg(np.mean)
print(f"男篮平均:{result}\n")
def BMI(df):
weight = df["体重(kg)"]
height = df["身高(cm)"]/100
bmi = weight/(height**2)
return bmi
basketball["体质指数"] = BMI(basketball)
print(basketball)
