豆瓣爬虫 详情页保存成Excel
需求爬取豆瓣电影详情页详细数据。
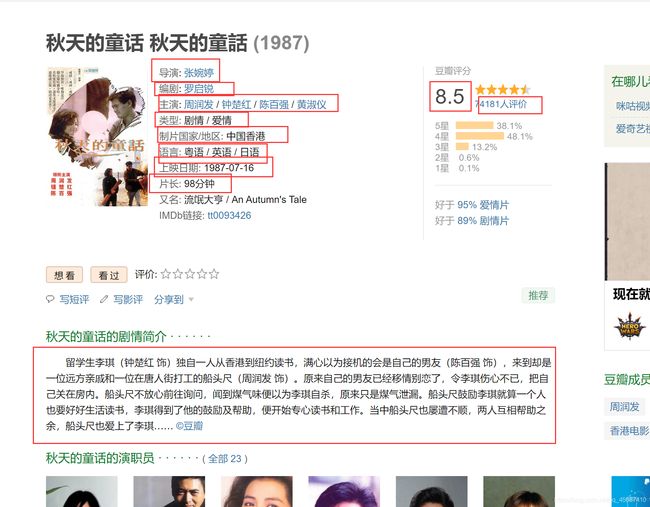
排名
链接
电影名
主演
评分
评价人数
年份
类型
制片国家/地区
导演
语言
上映日期
片长
简介
源码如下:
import requests, json, openpyxl
from lxml import etree
wb = openpyxl.Workbook()
sheet = wb.active
sheet_name = ['排名',
'链接',
'电影名',
'主演',
'评分',
'评价人数',
'年份',
'类型',
'制片国家/地区',
'导演',
'语言',
'上映日期',
'片长',
'简介', ]
sheet.append(sheet_name)
cookies = {
'bid': 'T1pobNIY2xA',
'_pk_ses.100001.4cf6': '*',
'ap_v': '0,6.0',
'__utma': '30149280.46113801.1609672274.1609672274.1609672274.1',
'__utmb': '30149280.0.10.1609672274',
'__utmc': '30149280',
'__utmz': '30149280.1609672274.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)',
'll': '108306',
'__gads': 'ID=9e971e9c816e8aaf-223428846fc50036:T=1609672817:RT=1609672817:S=ALNI_MbmGrmVOFv7ZU2C7adncg96wVYIiA',
'_vwo_uuid_v2': 'D72C5CC24844EA6AE251E23BA45ED89E2|016333adb19ffc86280dfa34d395f363',
'__yadk_uid': 'mYyQ8d9QTNklGOSDl4hvt8aOrtzHZtb2',
'_pk_id.100001.4cf6': '737624c4b4767a89.1609672273.1.1609673262.1609672273.',
}
headers = {
'Connection': 'keep-alive',
'Accept': '*/*',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66',
'X-Requested-With': 'XMLHttpRequest',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85%E7%89%87&type=11&interval_id=100:90&action=',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
interval_id = ["19:10" ]
# interval_id = ['100:90', '90:80', '80:70', '70:60', '60:50', '50:40', '40:30', '30:20', '20:10', '10:0', ]
for id in interval_id:
params = (
('type', '11'),
('interval_id', id),
('action', ''),
('start', '0'),
('limit', '1000'),
)
response = requests.get('https://movie.douban.com/j/chart/top_list', headers=headers, params=params,
cookies=cookies)
js = json.loads(response.text)
print(len(js))
for i in js:
print('+' * 90)
print(f'爬取第{js.index(i)}个')
# 排名
paiming = i['rank']
# 电影名
dianyingname = ''.join(i['title'])
# 主演
zhuyan = ' / '.join(i['actors'])
# 评分
pingfen = ''.join(i['score'])
# 年份
nianfen = ''.join(i['release_date'])
# 类型
leixing = ' / '.join(i['types'])
# 制片国家/地区
diqu = ''.join(i['regions'])
# 评价人数
pingjiarenshu = i['vote_count']
# url详细页
url_xiangxiye = ''.join(i['url'])
print(url_xiangxiye)
# 请求网页
res = requests.get(url_xiangxiye, headers=headers, cookies=cookies)
# 分析网页
html = etree.HTML(res.text)
# 打印上一页面信息
print('排 名\t', paiming)
print('电影名\t', dianyingname)
print('主 演\t', zhuyan)
print('评 分\t', pingfen)
print('年 份\t', nianfen)
print('类 型\t', leixing)
print('制片国家/地区\t', diqu)
print('评价人数\t', pingjiarenshu)
# 进行定位取值
# 导演
daoyan = ''.join(html.xpath('//div[@id="info"]/span[1]/span[@class="attrs"]/a/text()'))
print('导 演\t', daoyan)
# 编剧
bianju = ' / '.join(html.xpath('//div[@id="info"]/span[2]/span[@class="attrs"]/a/text()'))
print('编 剧\t', bianju)
# 语言
for i in range(0, 20):
yuyan1 = ''.join(html.xpath(f'//*[@id="info"]/text()[{i}]'))
# print(yuyan1)
if '语' in yuyan1:
yuyan = ''.join(html.xpath(f'//*[@id="info"]/text()[{i}]'))
else:
print('语 言\t', yuyan)
# 上映日期
for i in range(1, 20):
shangyingriqi1 = ''.join(html.xpath(f'//*[@id="info"]/span[{i}]/text()'))
if '上映日期' in shangyingriqi1:
shangyingriqi = ''.join(html.xpath(f'//*[@id="info"]/span[{i + 1}]/text()'))
break
try:
print(shangyingriqi)
except NameError:
shangyingriqi = '无'
# 片长
for i in range(1, 20):
pianchang1 = ''.join(html.xpath(f'//*[@id="info"]/span[{i}]/text()'))
if '片长' in pianchang1:
pianchang = ''.join(html.xpath(f'//*[@id="info"]/span[{i + 1}]/text()'))
try:
print('片 长\t', pianchang)
except NameError:
pianchang = '无'
# 简介
jianjie = ''.join(html.xpath('//span[@property="v:summary"]/text()')).replace(' ', '').replace('\n',
'').replace(
'\u3000', '')
print('简 介\t', jianjie)
shuju = [paiming,
url_xiangxiye,
dianyingname,
zhuyan,
pingfen,
pingjiarenshu,
nianfen,
leixing,
diqu,
bianju,
yuyan,
shangyingriqi,
pianchang,
jianjie, ]
sheet.append(shuju)
wb.save('shuju.xlsx')
print('程序运行完毕')