豆瓣电影(一):网络爬虫
夏日炎炎,屋外三十多度的烈日温度,着实一点出门的欲望都无了,小编还是窝在宿舍里当个“肥宅”吧。豆瓣爬虫属于动静结合的数据类型,即列表页动态、详情页静态。对豆瓣高分电影信息进行详细爬取,并存入Excel表格,后续再对数据进行数据分析,简单可视化展示。
操作环境: Windows10、Python3.6、Pycharm、谷歌浏览器
目标网址: https://movie.douban.com/ (豆瓣电影)
相关文章: 拉钩爬虫、腾讯招聘爬虫、新笔趣阁爬虫、链家网爬虫
目录
-
- 一、分析网页
-
- 1.1、ajax加载
- 1.2、接口链接
- 1.3、电影详情页
- 二、请求响应
-
- 2.1、构建params
- 2.2、翻页
- 2.3、列表页请求
- 三、提取数据
-
- 3.1、xpath语法
- 3.2、re正则
- 四、存入Excel
-
- 4.1、Excel表头
- 五、项目总结
一、分析网页
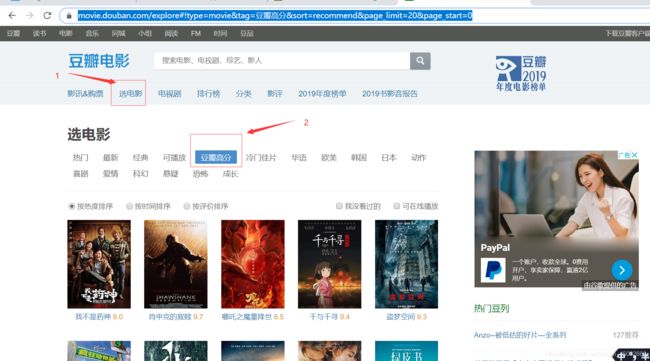
目标网站:1、点击选电影;2、选择高分电影分类。
1.1、ajax加载
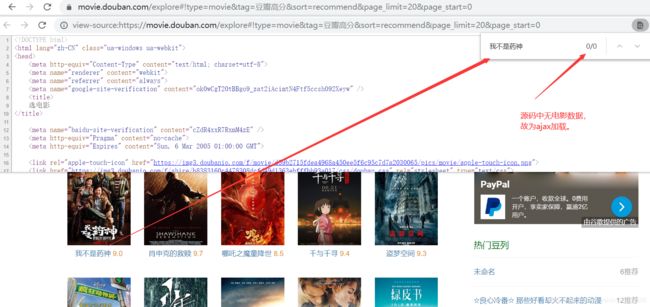
随意选择复制一个电影名字段,右键点击选择源码,快捷键Ctrl+F查看数据是否存在。
1.2、接口链接
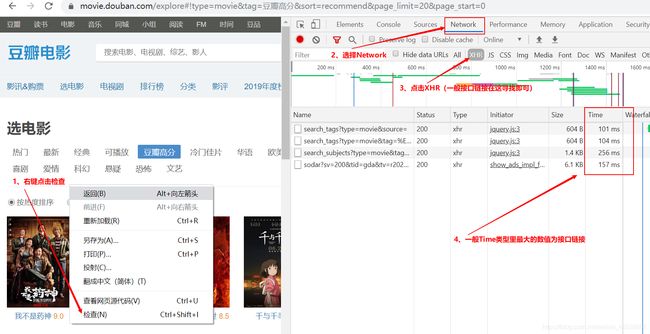
快速寻找ajax加载的接口链接方法:
1、右键点击检查;
2、选择Network;
3、点击XHR;(一般接口链接处于XHR中)
4、查看Time类型里的最大数值链接
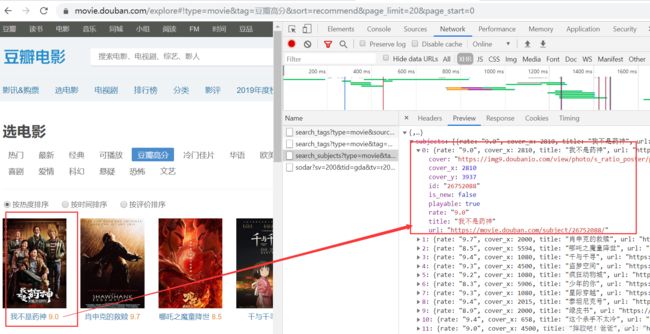
接口链接正确,如图可知rate参数为评分,title为电影名,url为电影详情链接。
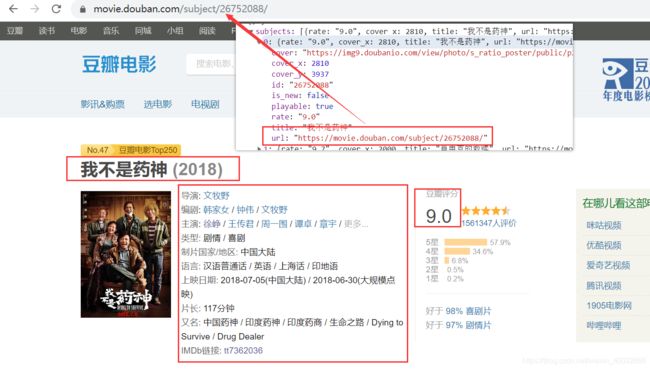
1.3、电影详情页
json数据中的url为电影详情页链接,提取电影详情页中的电影名、导演、编剧、主演、评分等等。
二、请求响应
导入爬虫项目需要的库,并设置全局请求头,以便列表页及详情页的调用请求身份。
# 导入爬虫需要的库
import json
import re
import requests
import openpyxl
import time
# 全局请求头 处理基本反爬
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
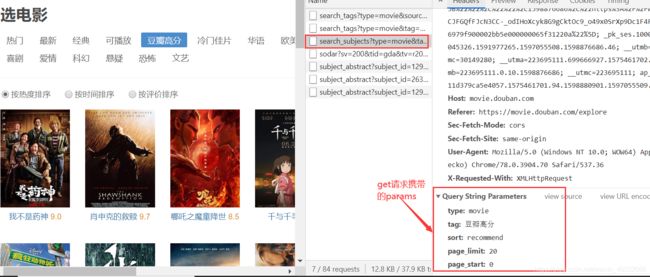
2.1、构建params
get请求携带的params参数,定一个get_params函数写params参数的构建, 传入电影分类与页数,以便每次列表页请求的携带调用。
def get_params(tag,pn):
'''
:param tag: 电影分类
:param pn: 页数
:return: 返回请求体
'''
params = {
# 请求体
"type": "movie",
"tag": str(tag),
"sort": "recommend",
"page_limit": "20",
"page_start": str(pn),
}
return params
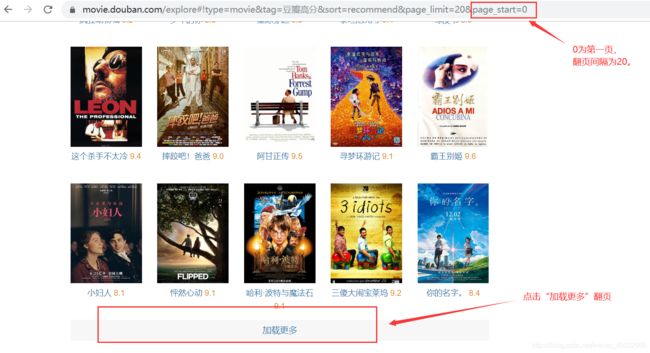
2.2、翻页
电影列表页为点击“加载更多”翻页,而不是下拉翻页等。只能自己手动查看“豆瓣高分”这一分类的总页数为 25 ,不能像之前的动态项目那样提取json数据中的总数来while循环翻页。
for pn in range(0,500,20): # 翻页 间隔20
# 获取请求体
params = get_params('豆瓣高分',pn)
2.3、列表页请求
测试请求列表页,这里设置一页验证结果。另外需要注意的爬虫程序请求速率过快的情况下,会被豆瓣服务器反爬机制识别,进而封掉识别请求的ip。这时使用time模块延迟睡眠即可。
for pn in range(0,20,20): # 翻页 间隔20
# 获取请求体
params = get_params('豆瓣高分',pn)
# 请求列表页数据并编码
response = requests.get(url=url, headers=HEADERS, params=params).text
time.sleep(1.2) # 睡眠1.2秒,防止识别到是爬虫被封ip
print(response)
请求返回的数据一一对应,结果无误。
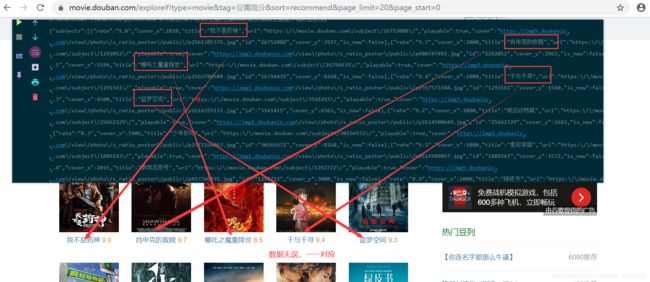
三、提取数据
json.loads(): 将已编码的 JSON 字符串解码为 Python 对象
提取json数据比静态数据简单许多,直接一层层剥取到想要的数据即可。这里获取电影id、电影名、电影详情页链接。
def get_detail_url(url):
'''
获取电影详情页链接
:param url:列表页通用链接
'''
for pn in range(0,20,20): # 翻页 间隔20
# 获取请求体
params = get_params('豆瓣高分',pn)
response = requests.get(url=url, headers=HEADERS, params=params).text # 请求列表页数据并编码
time.sleep(1.2) # 睡眠1.2秒,防止识别到是爬虫被封ip
jsons = json.loads(response) # 将源码数据转换成json数据
for data in jsons['subjects']:
id = data['id'] # 电影id
title = data['title'] # 电影名
href_url = data['url'] # 详细电影链接
print(id,title,href_url)
if __name__ == '__main__':
url = 'https://movie.douban.com/j/search_subjects'
get_detail_url(url) # 获取详情页链接
代码执行部分结果为:
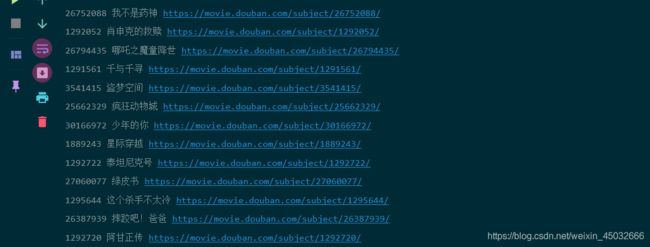
定义一个get_detail_data函数,传入获取到的id、电影名、详情页链接,继续写请求规则。
response.status_code: 返回状态码
def get_detail_data(id,title,href_url):
'''
获取电影详情页数据
:param id: # 电影id
:param title: # 电影名
:param href_url: # 电影详情链接
:return:
'''
response = requests.get(url=href_url,headers=HEADERS) # 请求详情页
if response.status_code == 200: # 判断是否请求成功
text = response.text # 编码
print(text)
else:
print('详情页请求失败。。。')
代码部分输出结果为:
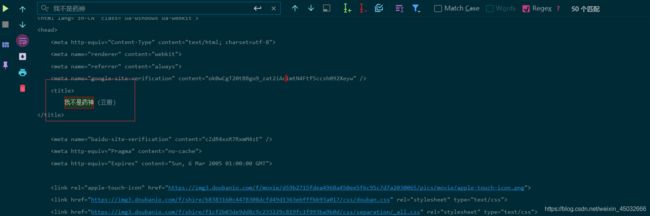
3.1、xpath语法
请求详情页成功,进而提取详情数据。首先导入parsel库,即import parsel。将请求编译好的源码转化为Selector对象,以便于xpath或css语法提取数据。
import parsel
sele = parsel.Selector(text) # 转化为Selector对象
使用xpath语法提取数据,可在网页查看中按Ctrl + 快捷键,在出现的小框框内写xpath或者css语法提取数据。例如:导演。
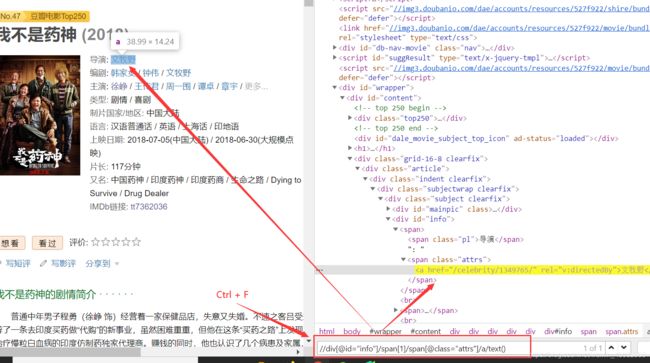
以此类推,剩余有规律的属性字段皆可用xpath语法提取数据。例如:导演、编剧、电影评分、主演、电影类型、简介。
’’.join(): 将列表数据合并成字符串数据
extract_first()与get(): 同为获取一个,返回字符串型数据。
extract与getall(): 同为获取全部,返回列表型数据。
# 导演
director = sele.xpath('//div[@id="info"]/span[1]/span[@class="attrs"]/a/text()').extract_first()
# 编剧
scriptwriter = '/'.join(sele.xpath('//div[@id="info"]/span[2]/span[@class="attrs"]//a/text()').getall())
# 电影评分
movie_rating = sele.xpath('//strong[@class="ll rating_num"]/text()').extract_first()
if movie_rating == None:
movie_rating = 'None'
# 主演
protagonist = '/'.join(sele.xpath('//span[@class="actor"]//span[@class="attrs"]//a/text()').extract())
# 电影类型
movie_type = sele.xpath(
"//div[@class='subject clearfix']/div[@id='info']/span[@property='v:genre']/text()").extract()
movie_type = '/'.join(movie_type)
# 电影简介
movie_summary = ''.join(sele.xpath('//div[@id="link-report"]/span//text()').getall()).strip(
'©豆瓣')
wording = sele.xpath('//div[@id="link-report"]/span/a/text()').get()
if wording == '(展开全部)':
movie_summary = ''.join(sele.xpath('//span[@class="all hidden"]//text()').getall()).strip('©豆瓣')
3.2、re正则
正则表达式概念: 正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,用来检索、替换那些符合规则的文本,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
剩余的字段数据:制片地区、语言、上映日期、片长、IMBD链接均在网页中属于不规律字段,若继续使用xpath语法提取这些字段信息的话,结果确实每个电影的字段顺序对应不上,即出现 “片长字段” 出现的是 “语言” 信息。
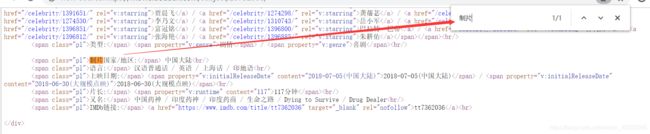
那么这些不规律的字段数据可以使用re正则匹配提取,导入模块import re。注意:re正则使用的是源码匹配,而不是parsel转化的Selector对象。这里以“制片地区”字段为例:
re.findall: 提取全部,为列表型数据,则最后[0]提取第一个数据。
pro_areas: 变量,为匹配的正则表达式。
text: 网页源码,提供正则匹配文本。
import re
# 制片地区
pro_areas = r'制片国家/地区: (.*?)
'
pro_area = re.findall(pro_areas, text)[0]
print(title,pro_area)
代码输出结果无误,re提取成功。

以此类推,提取的所有字段结果并将其填入空列表中。
print(
'id:',id+'\n','电影名:',title+'\n','导演:',director+'\n','编剧:',scriptwriter+'\n',
'电影评分:',movie_rating + '\n','主演:', protagonist + '\n', '电影类型:', movie_type + '\n',
'语言:', Language + '\n','制片地区:', pro_area + '\n', '上映日期:',movie_pubdate + '\n',
'片长:', length + '\n', 'IMBD链接:', IMBD_link + '\n', '电影简介:',movie_summary
)
print('*' * 150)
data_list.append([id, title, director, scriptwriter, movie_rating, protagonist, movie_type, pro_area,
movie_pubdate, length, IMBD_link, movie_summary])
代码输入部分结果为:

四、存入Excel
4.1、Excel表头
openpyxl.Workbook(): 创建excel簿
wb.create_sheet(簿名): 写入簿名
row: 行
column: 列
value: 值
wb.save(文件名): 保存文件名
# 创建一个excel薄
wb = openpyxl.Workbook()
sheet1 = wb.create_sheet('movie')
# 写入excel表头
sheet1.cell(row=1, column=1, value='id')
sheet1.cell(row=1, column=2, value='电影名')
sheet1.cell(row=1, column=3).value = '导演'
sheet1.cell(row=1, column=4).value = '编剧'
sheet1.cell(row=1, column=5).value = '电影评分'
sheet1.cell(row=1, column=6).value = '主演'
sheet1.cell(row=1, column=7).value = '电影类型'
sheet1.cell(row=1, column=8).value = '制片地区'
sheet1.cell(row=1, column=9).value = '上映日期'
sheet1.cell(row=1, column=10).value = '片长'
sheet1.cell(row=1, column=11).value = 'IMBD链接'
sheet1.cell(row=1, column=12).value = '电影简介'
wb.save('豆瓣高分电影.xlsx')
定义save_excel函数,用于写Excel存储数据功能。
def save_excel(data_list):
wb = openpyxl.load_workbook('豆瓣高分电影.xlsx')
sheet = wb['movie'] # 选择簿名
for d in data_list: # 遍历列表数据
sheet.append(d) # 写入数据
wb.save('豆瓣高分电影.xlsx') # 保存
“豆瓣高分”电影分类共25页,每页至多20条数据。运行保存的文件结果为500条数据,成功提取无误。
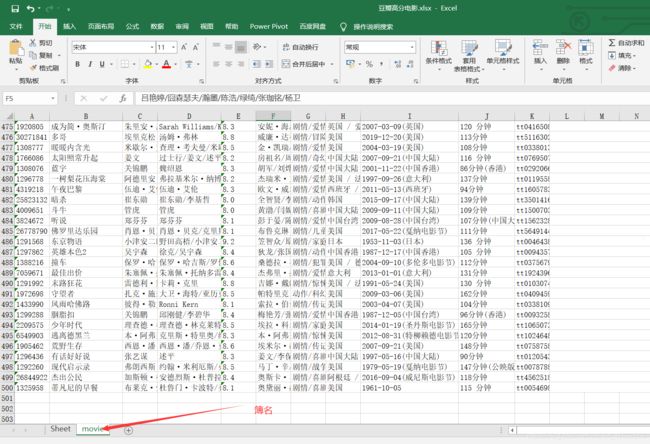
五、项目总结
豆瓣电影爬虫需要注意的地方有两点:
一、反爬机制
豆瓣的反爬措施是封禁频繁请求ip,少则几个小时,多则一天。使用time模块 time.sleep睡眠1至2秒即可。
二、匹配规则
电影详情页字段的匹配,有规律的字段数据则使用xpath语法提取,反之无规律且错乱位置的则使用re正则匹配提取。
此次项目到此结束,若有小伙伴有疑惑的地方,可在评论区留言,小编看到会尽快一一回复;此项目有需要改进的地方,也请大佬不吝赐教,感谢!
注:本项目仅用于学习用途,若用于商业用途,请自行负责!!