機器學習-筆記
概論
- 核心: 數據+模型
- 分類:
- 有監督學習(Supervised learning):透過大量已標記的數據輸入進行回歸預測,如:分類(已經知道有哪些類別)學習
- 無監督學習(Unsupervised learning): 聚類
- 步驟:
- 數據採集與標記
- 特徵選擇
- 數據清洗
- 模型選擇
- 模型訓練
- 模型測試
- 模型保存與加載
- 數據:
- 數據集&訓練樣本:所有蒐集到的資料
- 特徵:資料的分類法,開始越多越好,接著做特徵選擇
- 數據標記:賦予數據值
- 數據清洗:去重&降噪&統一度量
- 模型訓練
- 模型選擇:線性方程...
- 訓練集:測試集=8:2
- 交叉驗證集合(可選)
- 語言:
- python: numpy,pandas,scikit-learn(都放在jupyter上)
- 通用規則:
- 不同機器學習法調用不同的評估對象參數(因為從頭寫一個訓練模型很難,因此大多是分析數據後選擇合適機器學習法)
- 所有評估模型都有模型接口
- 不同算法但有相同的接口: (如下)
- fit(X,y)訓練模型:X代表數據y代表已標記數據
- predict()預測:返回最有可能類
- score()評價:返回模型預測準確率
基礎理論
- 過擬合與欠擬合
- 模型選擇錯誤導致: 無法藉由提高數據量增加準確率
- 過擬合:模型擬合樣本,但無法預測 -> 訓練數據集與交叉驗證數據集擬合佳,但總體準確率低
- 欠擬合:無法擬合樣本,也無法預測 -> 兩個集合準確率都差
- 改善方法:
- 過擬合: 減少與優化特徵選取
- 其他: 增加多項式的特徵,增加數據量
- 成本函數
- 成本:所有訓練樣本與模型的誤差平均值
- 成本函數:f(模型參數)=成本 -> 找出模型參數使得成本最小
- 如最小二乘法:一階多項式(模型)有無窮多種係數組合(模型參數)
- 模型準確性:
- 測試數據集(不屬於訓練數據集)的成本 minimun
- 交叉驗證數據集
- 原因: 訓練數據集找出每個模型最佳參數,交叉驗證數據集找出最佳模型,最後才用測試數據集驗證準確性(確保此時模型沒看過數據)
- 比例: 6:2:2 (訓:交:測)
- 學習曲線:
- 準確率為縱坐標,數據量為橫坐標 -> 表達數據量與準確率的關係
- 查準率,召回率
- 原因: 某些事件先驗機率太低,如癌症塞檢得病率0.5%,若每次都判陰性準確率可達99.5%
- 查準率PScore: TruePositive/TruePositive+FalsePositive 如:正確判斷得病/正確判斷得病+錯誤判斷為得病
- 召回率RScore: TruePoistive/TruePositive+FalseNegative 如:正確判斷得病/正確判斷得病+錯誤判斷未得病
- F1Score = 2*PR/P+R -> sklean.metrics.f1_score()
K-近鄰算法
- 步驟:
- 一開始有已標記樣本集合X,待標記樣本x
- 計算x與X內所有元素的距離,放入Distance中
- 對Distance排序,取最小的前k個,得到集合X’
- X’中出現最多次的類別就是x的類別
- 細節:
- 特性: 抗造能力強,運算量大
- 參數: k
- 變種:
- 依據距離在計算Distance時調整權重 函數:KNeighborsClassifier( n_neighbors=2, weights=“distance”)
- 不選前k個,而選距離在n以內的所有 函數:RadiusNeighborsClassifier( n_neighbors=2, radius=500.0)
- K-D Tree(效率優化):把距離數據紀錄在樹中,A&B距離遠B&C距離近->A&C距離遠
- 補充:
- 卡方值: 計算假設是否成立,運用期望值原理,查表算假設成立機率
線性回歸算法
- 原理:找到對應的係數使得成本函數(均方差)最小
- 批量梯度下降算法:
-
一階線性回歸:
- 兩個參數+成本函數=三維空間
- 俯視時可得等高線,每回合向低處前進
- 每次往最低點走一步
-
決定方向:偏導函數 決定步長:學習率函數F(x)
- 公式(第一個thita是’)
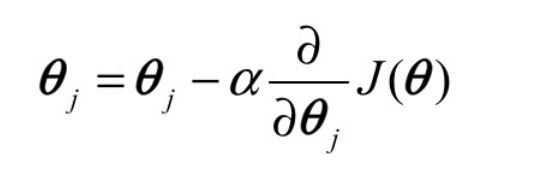
- 矩陣形式[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pd2x0ZEB-1600169933288)(https://i.imgur.com/BiKStzv.jpg)]
- 公式(第一個thita是’)
-
成本函數:
- 一般形式 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UnCH0Uj1-1600169933290)(https://i.imgur.com/NelS6Fv.jpg)]
- 矩陣形式:(矩陣好處:能使用分部運算) [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ldEcFPRF-1600169933293)(https://i.imgur.com/tPSkKbO.jpg)]
其中thita是n+1維向量,X是方陣,h(X)、y分別代表預期成本與真實成本
-
步驟:
- 確定學習率&起始點
- while(確定是否收斂)疊代
-
- 模型優化
- 增加多項式的係數,如:x1x2
- 歸一化係數(加快收斂速度)
- 隨機梯度下降算法: 每次運算佈取平均,而是取隨機一個點
- 標準方程:X(XTX)-1XT*y = b
邏輯回歸算法
- 特色:輸出是離散值(0&1)
- 預測函數
- Sigmoid(Logistic)函數 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0oBMz9DC-1600169933295)(https://i.imgur.com/FFQrZso.jpg)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LxLZxUwa-1600169933296)(https://i.imgur.com/b1MTbDL.jpg)]
- g(z) = P(y = 1|X,係數thita)
- 即當係數與輸入分別為X&Thita時成立的機率
- 其中 z = thita*X
- z = 0 是判斷邊界
- 預測函數回傳值有兩個(陰性機率&陽性機率)誰高選誰
- 評分時不只看正確率,還要看機率
- 成本函數:
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oOuDTzjB-1600169933297)(https://i.imgur.com/Ouk85Uc.jpg)]
- 原因: 預測函數是e,所以成本用對數可得漂亮數學式
- 多元類別:
- 從y = 0開始,0當一個類1~n當一個類 得預測函數h0(x)
- 找Max(h0,h1…hn),最大的就屬於該類
- 正則化:(正則懲罰)
- 原因: 避免某項參數權重獨大->過擬合
- 成本函數[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9XDSxmc0-1600169933299)(https://i.imgur.com/shRCLNk.jpg)]
- 疊代函數[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ccR6L89k-1600169933300)(https://i.imgur.com/DAt35rd.jpg)]
- L1,L2正則范數
- L1 = |thita1| + |thita2|+…
- L2 = sqrt(thita12 + thita22 + …)
- L1盡量產生更多的0
- L2使參數值盡量小
- 學習曲線畫法:
- 找出部分數據來畫出曲線
- 找出的數據0&1比例應與全部數據一致
- 優化: Conjugate Gradient、BFGS、L-BFGS 等’
決策樹
- 信息熵:
- 公式[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mYiLHWS1-1600169933301)(https://i.imgur.com/XHNKonU.jpg)]
- 單位:bit
- 舉例
- 紅白球各一半: H(x)=2*{(1/2)*log2(1/2)}=1
- 全白球 H(x)= 0
- 信息增益:
- 在建構決策樹的過程中應優先選擇信息增益量大的特徵作為劃分依據
- 舉例:
- 小紅球1,小黑球2,大黃球1,大白球4
- 基礎信息熵:H(x) = 1/8log1/8*2+ 1/4log1/4+ 1/2log1/2 = 1.75
- 信息增益:基礎信息熵 - [小球,大球]信息熵
- 最後跟其他劃分法的信息增益做比較選出最優
- 決策樹建構:
- ID3算法(步驟)(改進版算法:C 4.5):
- 計算初始信息熵
- 逐一計算各劃分法信息增益,選出劃分法(迴圈)
- 終止條件: 特徵使用完畢,信息熵足夠低
- 注意事項
- 離散化: 須把連續分部的特徵改為離散值
- 正則化: 分的類別越多->信息增益越高->增加正則懲罰(正比於類別數)
- CART算法:
- 方法同
- 信息熵公式=P(x)(1-P(x))
- ID3算法(步驟)(改進版算法:C 4.5):
- 剪枝
- 前剪枝
- 信息增益小於閾值停止增枝
- 樣本數過少停止增枝
- 後剪枝
- 若合併後信息熵增加量小於閾值,則合併
- 子樹中最多的特徵 = 合併後子樹特徵
- 降低错误率剪枝法:
- 自底而上: 挑子樹合併
- 以大多數原則執行合併過程
- 合併後以交叉驗證集檢驗是否該合併
- 直到無法合併時停止
- 前剪枝
- 語法SkLearn:
- ·criterion:特征选择算法。⼀种是基于信息熵,另外⼀种是基于基 尼不纯度。有研究表明,这两种算法的差异性不⼤,对模型的准确性没 有太⼤的影响。相对⽽⾔,信息熵运算效率会低⼀些,因为它有对数运 算。更详细的信息,可通过搜索decision tree gini vs.entropy获取。
- ·splitter:创建决策树分⽀的选项,⼀种是选择最优的分⽀创建原 则,另外⼀种是从排名靠前的特征中,随机选择⼀个特征来创建分⽀, 这个⽅法和正则项的效果类似,可以避免过拟合问题。 ·max_depth:指定决策树的最⼤深度。通过指定该参数,⽤来解决 模型过拟合问题。
- ·min_samples_split:这个参数指定能创建分⽀的数据集的⼤⼩,默 认是2。如果⼀个节点的数据样本个数⼩于这个数值,则不再创建分 ⽀。这也是⼀种前剪枝的⽅法。
- ·min_samples_leaf:创建分⽀后的节点样本数量必须⼤于等于这个 数值,否则不再创建分⽀。这也是⼀种前剪枝的⽅法。
- ·max_leaf_nodes:除了限制最⼩的样本节点个数,该参数可以限制 最⼤的样本节点个数。
- ·min_impurity_split:可以使⽤该参数来指定信息增益的阈值。决策 树在创建分⽀时,信息增益必须⼤于这个阈值,否则不创建分⽀。
- 優化:
- 重新劃分數據->不同決策樹&選擇不同特徵係數->多次取平均
- 同時決定多個特徵係數:from sklearn.model_selection import GridSearchCV
集合算法
- 自動聚合算法(Bootstrap Aggregating):
- 使用"有放回"的採樣機制,訓練出多個模型,當需要預測時用多個成果取平均(回歸)\投票(分類)
- 有放回:每次取樣完後將樣本放回樣池
- 特點:增加抗噪能力,增加訓練量
- 語法: BaggingClassifier和BaggingRegressor
- 正向激勵算法(boosting):
- 初始時賦予每項樣本權重,進行訓練
- 對模型預測錯誤的樣本增加權重,繼續訓練(迴圈)
- 越後面的模型投票時權重越高(準確性越高)
- 特點:訓練無法並行(串行:依賴於上一個模型)
- AdaBoost算法
- 語法: AdaBoostClassifier和AdaBoostRegressor
- 隨機森林(參數:t顆樹,每顆樹f個特徵):
- 建造決策樹:
- 在樣池中以有回放的方式採集樣本
- 在特徵池中以無回放的方式選f個特徵
- 以採得的訓集訓練模型(重複t次)
- 利用森林決策(平均\投票)
- 特點:降低某個特徵獨佔(同正則懲罰)
- 語法: RandomForestClassifier 和 RandomForestRegressor
- 建造決策樹:
- ExtraTrees
- 隨機森林在種樹時會以信息增益來選擇特徵,但ExtraTrees隨機選
- 語法: ExtraTreesClassifier和ExtraTreesRegresso
支持向量機SVM(SupportVectorMachine)
-
原理:
- 找到一個超平面使得支持向量離超平面的間距最大
- 支持向量:離超平面最近的樣本(在經過高維投影後)
- 間距:支持向量與超平面距離*2
- InShort:在y(i)(wTx(i) +b)≥1的前提下,求解ǁwǁ2的最⼩值(L2范數)
-
鬆弛係數
- 原理:藉由正則懲罰避免因部分數據導致過擬合
- R參數: 正則懲罰大小參數
- ε: 不符合模型樣本與超平面距離
- InShort:在y(i)(wTx(i) +b)≥ 1 - εi 的前提下,求解ǁwǁ2+R*εi的最⼩值(L2范數)
-
核函數:
- 意義 : 代表兩向量的相似性
- 拉格朗日乘子法(在滿足後式條件下,使得前式最小,其中alpha為學習參數) [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sdOyju4R-1600169933301)(https://i.imgur.com/F2dvJPW.jpg)]
- 由 數值分析\二次規劃\SMO序列最小優化法 推得核函數
- 新預測函數(其中K(x)代表核函數)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Il6EQdJz-1600169933302)(https://i.imgur.com/5C1MbWQ.jpg)]
- 常見核函數:
- 最簡單形式(內積): xT(i) x(j)
- 多項式形式[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kT5lwGhf-1600169933303)(https://i.imgur.com/3oCkjhK.jpg)]缺點: 有3個參數 & n不能太大
- 高斯核函數(鐘形曲線)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-talmAZLE-1600169933304)(https://i.imgur.com/Uerm4SF.jpg)]特點:可升到無窮多維,只有一個參數,但升太高維易過擬合
- 意義 : 代表兩向量的相似性
-
相似性函數:
- 原理: 當無法找出超平面時,升維找->利用相似性函數升維
- 如: [x] -> [x,2x2]
-
模型選擇
- 特徵量小&樣本量小: 選擇簡單模型避免過擬合(如邏輯)
- 特征量大&样本量大: 可選擇複雜模型(高斯\多項式(最複雜))
樸素貝葉斯算法
- 原理:
- 貝葉斯定理:
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z5hEwrAp-1600169933304)(https://i.imgur.com/MyKHeuV.jpg)]
- 在B事件發生的前提下A事件發生的機率
- 例子:酒測器判斷酒駕者準確率100%判斷非酒駕者誤判率5%,酒駕率0.1% -> 當酒測器判定為酒駕(B)時真的為酒駕(A)機率 = (0.1%*100%)/(0.1%+99.9%*5%) = 1.96%
- 樸素:兩個事件互相獨立(xi之間互相獨立)
- 數學關係 P(X1|X2,…,Xn,C) = P(X1|C)
- 貝葉斯定理:
- 數學推導:
- x為輸入值Ck為是類別k的機率,欲求k個類別中最大的P(Ck|x) [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GWZiR6Ow-1600169933305)(https://i.imgur.com/Ubz4Daa.jpg)]
- P(x)固定 -> P(Ck|x)正比於P(Ck)P(x|Ck) = P(x)*P(Ck) = P(X1,X2…Xn)*P(Ck)
- X樸素[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EJxqDiDM-1600169933307)(https://i.imgur.com/myO8GVr.jpg)] -> P(x1,x2…,Ck) = P(X1|Ck)* P(X2|Ck)* …*P(Ck)
- 推得:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-25q1OUN1-1600169933308)(https://i.imgur.com/f6dj3yQ.jpg)]
- 概率統計
- 概率密度函數(ProbabilityDensityFunction) \ 概率質量函數(ProbabilityMassFunction)): 輸入一個連續\離散的值,該函數能回傳該值可能發生的機率
- 多項式分布
- 事件數 = 2 (Cnk pk(1-p)k ) [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cjUmAoj1-1600169933309)(https://i.imgur.com/z2u35ik.jpg)]
- 事件數 = n (xi代表事件x發生次數)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vfngfUNq-1600169933310)(https://i.imgur.com/r3DuhfU.jpg)]
- 高斯分布
- 公式 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tn79NtKf-1600169933311)(https://i.imgur.com/CXypHnP.jpg)]
- 用途:
- 先利用數據集算出平均與標準差
- 再帶入x即得到所求機率
- TF-IDF:
- TF(TermFrequency):詞頻=出現次數/總字數
- IDF(InverseDocumnetFrequency)(當權重用):
- 逆向文檔頻率指數=log(文檔總數/出現該詞彙文檔數)
- 全部文檔都有出現 -> IDF=0
- 步驟:
- 每個詞彙視為一個向量
- 向量的值=TF*IDF
- 產生一個稀疏矩陣
PCA算法
- 原理: 以距離平方最小為前提,將數據映射到n-1線性空間(投影后的节点尽量分散)
- 用途:透過數據降維增加機器學習效率
- 数学: 待探讨
- 步驟:
- 歸一化: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RuhiJnxs-1600169933312)(https://i.imgur.com/sWy0lr7.jpg)] x = 新的特徵值, a = 舊特徵值, u = 平均, s = 值域
- 奇異值分解:將歸一化後矩陣X->XTX = sigma,接著對sigma做奇異值分解 -> 特徵向量
- 數據還原率:
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1XhiCcGz-1600169933312)(https://i.imgur.com/WoPVyvF.jpg)]
- 計算方法:(其中S是SVD分解中的方陣)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WwDlTdE9-1600169933313)(https://i.imgur.com/lmqnWEv.jpg)]
K-均值算法
- 步驟:
- 輸入值: 分k類,共x個樣本
- 隨機生成k個聚類中心 (選擇隨機的k個樣本)
- 將樣本歸類到與他最近的聚類中心(成本函數最小),移動聚類中心到該類所有樣本的平均值,重複此步直到中心不再移動
- 成本函數 = sigma |xj-uj|2
- 選擇錯誤的起始點 -> 收斂到局部最優 -> 重複步驟2,3多次;取最終成本函數最小者
- 合適k值(1)業務需求為主(2)畫出k-成本函數圖:找出圖中拐點
- 数列相似度指标:
- Adjust Rand Index: 不相似->0,相似->1(无视顺序)
- 齐次性: 每个类别的元素来自同一个类别 数值 -> 1
- 完整性: 每个类别的元素都被分到同一个类别 数值-> 1
- 輪廓係數(不用事先標記)(介於[-1,1]越接近1分類效果好):[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6yxmfQW2-1600169933314)(https://i.imgur.com/juX7UJ2.jpg)]