在Window10系统中安装Pandas并行加速库Modin的流程及效果测试
目录
- 安装动机
- Modin库简介
- 安装流程
-
- 1. 在Windows设置中调整设置
- 2. 在Windows应用商店中下载Ubuntu
- 3. 配置Ubuntu
- 4. 安装Modin库
-
- 先说说我的安装方法
- 接下来说说官方的方案:
- Modin库性能测试
-
- read_csv 测试
- fill_na 测试
- 总结
- 鸣谢
安装动机
最近在用Pandas处理一些大数据集时明显感受到了Pandas的缺陷:只能使用CPU的一个核心来计算,对于我新买的8核16线程的机子来说,有大量资源都被浪费了。
本着加速Pandas运行的动机,上网搜索了很多能充分利用本地CPU资源的措施,但是看了一些诸如threading, multiprocessing之类的库,还是感觉环境的部署有些难以理解,其中的运用也有一些限制(比如自定义函数必须有返回值),对于像我这样非CS专业背景的人来说还是不够友好。最终发现了这个号称能够实现一行代码加速Pandas运行的Modin库(事实上也确实如此),鼓捣了一整天之后终于成功实现了Pandas的充分并行加速。
虽然使用起来非常方便,但在安装过程中走了不少弯路,网上也没有非常明确的信息指导安装,因此写下这篇文章,以免后来者再重蹈覆辙。
Modin库简介

Modin 是加州大学伯克利分校 RISELab 的一个早期项目,旨在促进分布式计算在数据科学领域的应用。它是一个多进程的数据帧(Dataframe)库,具有与 Pandas 相同的应用程序接口(API),使用户可以加速他们的 Pandas 工作流。
在一台 8 核的机器上,用户只需要修改一行代码,Modin 就能将 Pandas 查询任务加速 4 倍。
该系统是为希望程序运行得更快、伸缩性更好,而无需进行重大代码更改的 Pandas 用户设计的。这项工作的最终目标是能够在云环境中使用 Pandas。
如果对Modin库具体的工作流程感兴趣,请参考机器之心的知乎文章-想让pandas运行更快吗?那就用Modin吧
安装流程
必须要指出的是,只有Window 10系统才能支持以下的安装流程
由于Windows环境下并不直接支持Ray,而Ray是安装Modin所必须的,因此我们需要使用WSL(适用 Linux 的 Windows 子系统),整体的流程也因此比以往pip即可的流程变得复杂了一些
总体来说分为四步:
-
在Windows设置中调整设置
-
在Windows应用商店中下载Ubuntu
-
配置Ubuntu
-
安装Modin库
1. 在Windows设置中调整设置
在控制面板中搜索“功能”


选中后会设置一段时间(约20s),之后会重启
2. 在Windows应用商店中下载Ubuntu
在Windows应用商店中搜索Ubuntu,安装。一切按照默认设置即可。

3. 配置Ubuntu
安装好之后会要求设置用户名和密码(这部分忘记截图了,但是内容也比较少)
用户名:小写字母即可。不能设置大写或下划线等,会报错
密码:密码是隐形的,所以如果你按下键盘之后发现没有动静,不要怀疑是卡住了,确保输入正确后按下回车,会让你再次输入确认的
4. 安装Modin库
先说说我的安装方法
因为我在使用官方方法时遇到了一些问题,但是又没查询到解决的方案,所以自己另辟蹊径,竟然也成功了。
直接打开cmd,建议挂上VPN,输入:
pip install modin[all]
就会连Modin带Ray一起安装,测试使用时只有很少的情况会无法成功导入,但只要再次尝试import,通常都会成功(这部分下文细谈)
接下来说说官方的方案:
Install Ray with
pip install -U ray. For the latest wheels (a snapshot of the master branch), you can use the instructions at Latest Snapshots (Nightlies).
也就是在Linux环境中输入pip install -U ray安装Ray,然后再pip install modin安装Modin即可
在这里我出现了一个问题:我的Linux中没有pip模块,所以我回到了Windows环境中pip了。
如果没有pip模块,应该先安装pip.exe。接下来的步骤是引用的@a013067506e4在其博客里的方法,但未经过我的测试:
- 使用以下代码安装Ray(这里加了个豆瓣的源)
pip.exe install -U ray -i https://pypi.doubanio.com/simple/- 然后再使用以下代码安装Modin
pip.exe install modin -i https://pypi.doubanio.com/simple/
Modin库性能测试
首先导入,非常方便
# 用modin.pandas 代替 pandas,并仍旧命名为pd
import modin.pandas as pd
import numpy as np
read_csv 测试
CPU配置:AMD R7 4800H(8核)

19.2s。接下来看看普通Pandas的速度

42.8s。使用Modin可以提速一倍以上。
事实上我第一次读取这个数据集的时候花费时差大概在一分半钟左右…
fill_na 测试
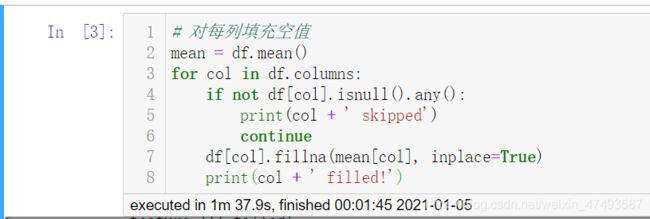
使用Modin填充空值,需要97.9s

但是使用普通Pandas,只需要1s…
说明modin对于一些函数的支持还是不够好,甚至比普通的Pandas还慢许多
具体的原因我也没有理解,所以可以看到modin并非对所有pandas接口都能加速,但如果使用普通接口速度过于慢的时候,换用modin也许是个有益的尝试。事实上在运行代码时我也在监视着任务管理器,发现启动多线程也是需要一些时间的,这意味着,如果数据集不够大(或者任务量不够大),多线程带来的好处可能还不及启动多线程的时间成本
总结
- 安装modin比较麻烦,但使用起来很简单,可以用来作为pandas运行速度较慢时的加速尝试
- 根据官方文档,modin支持约71%的pandas接口,若没有覆盖到的接口则会自动使用标准pandas接口(如to_csv)。所以理论上来说,使用modin本应该是个绝对占优策略
- 但是在实际测试中,发现部分接口的速度还不如用pandas,原因未知。因此终极建议是:先用普通接口,如果所有接口都使用后还是很慢,再使用modin
鸣谢
感谢在我安装过程中提供支持的三篇博客
- 简书-windows10下安装Modin,作者@a013067506e4
- CSDN-mac python3.8使用modin.pandas报错Please pip install modin[ray] to install compatible Ray version.,作者@大脸猿
- 知乎-pandas升级版——modin,作者 @马东什么
最后,感谢我家亲爱的@上财李荣浩 大晚上帮我测试了好几个算法的时间(帮他微博涨粉!)(也可以关注CSDN-上财李荣浩!)