《流浪地球》豆瓣影评项目心得
做点笔记,不然啥也忘了。
文章目录
- 数据获取
-
- 爬取网页流程
- 安装selenium及配置chromedriver
- Xpath操作
- requests爬取
- 数据预处理
- selenium如何判断页面加载完成?
- selenium如何进行翻页?
- 完整代码
- 数据分析-词频统计
-
- 分词和设置停用词
- 词频统计
- 绘制词云
- 取好评和差评数据
- 完整代码
- 数据分析-评论数量及评分与时间的关系
-
- 设置plt字体
- 绘制评分数量饼图
- 评论数量和日期的关系
- 评论数量与时刻的关系
- 不同星级的评论数量与日期的关系
- 数据分析-居住城市及评论数量与城市的关系
-
- 获取评论最多的10个城市
- 获取评论数前5的城市的不同评分数量
数据获取
爬取网页流程
目标地址:https://movie.douban.com/subject/26266893/comments?status=P
爬取页面流程:
- selenium框架网页进行抓取
- 使用XPath解析获取短评
- 将数据转化pandas中的DataFrame
- selenium操作翻页,回到第一步
安装selenium及配置chromedriver
首先用conda新建一个环境,避免污染我原本的环境库
conda create -n liulangdiqiu python=3.6
The following NEW packages will be INSTALLED:
certifi: 2020.12.5-py36haa95532_0
pip: 20.3.3-py36haa95532_0
python: 3.6.12-h5500b2f_2
setuptools: 51.0.0-py36haa95532_2
sqlite: 3.33.0-h2a8f88b_0
vc: 14.2-h21ff451_1
vs2015_runtime: 14.27.29016-h5e58377_2
wheel: 0.36.2-pyhd3eb1b0_0
wincertstore: 0.2-py36h7fe50ca_0
zlib: 1.2.11-h62dcd97_4
Proceed ([y]/n)?
vs2015_runtime 100% |###############################| Time: 0:00:01 1.88 MB/s
vc-14.2-h21ff4 100% |###############################| Time: 0:00:00 8.66 MB/s
zlib-1.2.11-h6 100% |###############################| Time: 0:00:00 11.03 MB/s
sqlite-3.33.0- 100% |###############################| Time: 0:00:00 1.90 MB/s
python-3.6.12- 100% |###############################| Time: 0:00:04 4.26 MB/s
certifi-2020.1 100% |###############################| Time: 0:00:00 416.27 kB/s
wheel-0.36.2-p 100% |###############################| Time: 0:00:00 10.76 MB/s
setuptools-51. 100% |###############################| Time: 0:00:00 2.65 MB/s
pip-20.3.3-py3 100% |###############################| Time: 0:00:00 2.90 MB/s
#
# To activate this environment, use:
# > activate liulangdiqiu
#
# To deactivate an active environment, use:
# > deactivate
#
# * for power-users using bash, you must source
#
切换到新建好的liulangdiqiu环境
activate liulangdiqiu
安装selenium
(liulangdiqiu) C:\Users\Administrator>pip install selenium
Collecting selenium
Downloading selenium-3.141.0-py2.py3-none-any.whl (904 kB)
|████████████████████████████████| 904 kB 939 kB/s
Collecting urllib3
Downloading urllib3-1.26.2-py2.py3-none-any.whl (136 kB)
|████████████████████████████████| 136 kB 6.8 MB/s
Installing collected packages: urllib3, selenium
Successfully installed selenium-3.141.0 urllib3-1.26.2
(liulangdiqiu) C:\Users\Administrator>
后面要安装pip lis还有:
- lxml
- requests
- pandas
- wordcloud
- matplotlib
- jieba
用anaconda装库的话基本不会有什么问题的,但是我还是遇到了一些问题,我安装matplotlib出现了ERROR: Could not find a version that satisfies the requirement matplotlib (from versions: none),用anaconda装库能出现问题的话,不用想八成就是网络有问题了,换成清华源就解决了。
我是用pycharm写jupyter,pycharm得切换成conda的python interpreter

安装chromedriver,chromedriver可以唤出谷歌浏览器用命令的方式操作Chrome。
chromedriver下载地址:http://chromedriver.storage.googleapis.com/index.html
查看自己谷歌版本,我是 87.0.4280.88,去那个网址去下载对应的chromedriver版本

比如87.0.4280.88版本的chromedriver:http://chromedriver.storage.googleapis.com/index.html?path=87.0.4280.88/
点击下载chromedriver_win32.zip
解压,将chromedriver.exe放入系统变量中
测试chromedriver,执行代码driver.get(url)会弹出谷歌浏览器
from selenium import webdriver
if __name__ == '__main__':
# 控制谷歌浏览器
driver = webdriver.Chrome()
url = r'https://movie.douban.com/subject/26266893/comments?status=P'
driver.get(url)
准备完毕后可以开始相应的爬取操作
Xpath操作
通过driver.page_source获取源码,再用etree获取dom树
dom = etree.HTML(driver.page_source, etree.HTMLParser(encoding='utf-8'))
dom树示例:

获取dom数后使用Xpath筛选出有用信息。
Xpath基本语法:
| 表达式 | 说明 |
|---|---|
| nodename | 选取nodename节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |


定位标签,找出xpath路径,比如我们要获取用户名称影志

那么他是在div class=comment-item 下的span class=comment-info 下的a标签中
那么代码可以写成:
names = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/a/text()')
如果是取评分,评分数据在class中,那么用@class把class属性值取出来
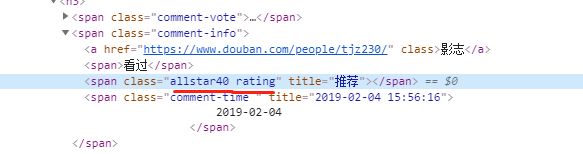
代码:
ratings = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/span[2]/@class')
requests爬取
requests爬取,这个比较容易,requests.get直接爬取网页源码,记得设置cookies和headers
web_data = requests.get(url, cookies=cookies, headers=headers).text
cookies在request headers中

cookies字符串转字典处理
cookies_split = cookies_str.split(';')
cookies = {
}
for i in cookies_split:
k, v = i.split('=', 1)
cookies[k] = v
headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.115'}
requests.get获取网页源码后,在用dom解析和xpath就能获取数据了
web_data = requests.get(url, cookies=cookies, headers=headers).text
user_dom = etree.HTML(web_data, etree.HTMLParser(encoding='utf-8'))
user_address = user_dom.xpath('//div[@class="user-info"]/a/text()')
print(user_address)
数据预处理
获取下来的数据存在噪声,不一致,不完整等问题,需要进行数据清洗,数据集成,数据变换,数据归约操作(刚背完的数据挖掘课程,大草)
这里只是简单的数据清晰和数据变换,这种简单的for in if写法在预处理里很常见
# 处理评分数据
ratings_ = ['' if 'rating' not in i else int(re.findall('\d{2}', i)[0]) for i in ratings]
# 处理入会时间
load_times_ = ['' if i == [] else i[1].strip()[:-2] for i in load_times]
# 处理居住城市
cities_ = ['' if i==[] else i[0] for i in cities]
数据整合到一起到一个DataFrame中
data = pd.DataFrame({
'用户名': names,
'居住城市': cities_,
'加入时间': load_times_,
'评分': ratings,
'发表时间': times,
'短评正文':message,
'赞同数量':votes,
})
selenium如何判断页面加载完成?
主要用到selenium中这三个类,By,WebDriverWait和expected_conditions
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
首先用WebDriverWait设置超时时间,超过限制则视为加载失败
# 超时时间设为10秒,超过10秒报错
wait = WebDriverWait(driver, 10)
用wait里的until方法设定超时,expected_conditions判断元素是否可被点击,By.CSS_SELECTOR,dom树中另外一种访问目标节点的方式,通过selector判断是否存在来判断页面是否加载成功
F12拷贝selector过来,截不了图只能拍照了(doge
写成代码就是这样,一直等待,等待10s,超过10s视为加载页面失败,通过EC判断页面是否加载好,阻塞等待
wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#comments > div:nth-child(20) > div.comment > h3 > span.comment-info > a')
)
)
selenium如何进行翻页?
判断元素是否存在, 判断元素是否可被点击,click()执行翻页操作
# 有的话点击翻页
# 判断元素是否可被点击,等待十秒钟阻塞判断
confirm_bnt = wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#paginator > a.next')
)
)
# 执行翻页操作
confirm_bnt.click()
完整代码
#%%
import time
import re
from selenium import webdriver
from lxml import etree
import requests
import pandas as pd
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#%%
def get_web_data(dom=None, cookies_str=None):
"""获取每页评论数据
:param dom:
:param cookies_str:
:return:
"""
# 用户名称
names = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/a/text()')
print("names: ", names)
print("len(names): ", len(names))
# 评分
ratings = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/span[2]/@class')
print(ratings)
# 发布时间
times = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/span[@class="comment-time "]/@title')
print(times)
# 评论正文
message = dom.xpath('//div[@class="comment-item "]//div[@class="comment"]//span[@class="short"]/text()')
print(message)
# 20个用户的首页
user_url = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/a/@href')
print(user_url)
# 赞同数量
votes = dom.xpath('//div[@class="comment-item "]//div[@class="comment"]//span[@class="votes vote-count"]/text()')
print(votes)
cookies = {
}
# 如果cookies_str是字符串类型,把它转换成dict类型
# 如果本来就是dict类型,就不用转换
#
if isinstance(cookies_str, str):
cookies_split = cookies_str.split(';')
cookies = {
}
for i in cookies_split:
k, v = i.split('=', 1)
cookies[k] = v
elif isinstance(cookies_str, dict):
cookies=cookies_str
else:
print('cookie格式错误!')
exit(-1)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.115'}
print(cookies)
cities = []
load_times = []
for url in user_url:
web_data = requests.get(url, cookies=cookies, headers=headers).text
# print(web_data)
user_dom = etree.HTML(web_data, etree.HTMLParser(encoding='utf-8'))
# 用户居住地
user_address = user_dom.xpath('//div[@class="user-info"]/a/text()')
print(user_address)
# 用户加入时间
user_loadtime = user_dom.xpath('//div[@class="user-info"]/div[@class="pl"]/text()')
print(user_loadtime)
time.sleep(2)
cities.append(user_address)
load_times.append(user_loadtime)
print(cities)
print(load_times)
# 处理评分数据
ratings_ = ['' if 'rating' not in i else int(re.findall('\d{2}', i)[0]) for i in ratings]
# 处理入会时间
load_times_ = ['' if i == [] else i[1].strip()[:-2] for i in load_times]
# 处理居住城市
cities_ = ['' if i==[] else i[0] for i in cities]
data = pd.DataFrame({
'用户名': names,
'居住城市': cities_,
'加入时间': load_times_,
'评分': ratings,
'发表时间': times,
'短评正文':message,
'赞同数量':votes,
})
return data
if __name__ == '__main__':
# cookies字符串
cookies_str = 'll="118281"; bid=O1uK5c3kpkk; douban-fav-remind=1; __yadk_uid=tzmcu8gNXL0HMt947paVrfYuqi5Q5kdO; __utmc=30149280; __utmc=223695111; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1609765511%2C%22https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3Dmovie.douban%26ie%3DUTF-8%22%5D; _pk_ses.100001.4cf6=*; dbcl2="188585896:ukzBkIQRQeg"; ck=os8P; push_noty_num=0; push_doumail_num=0; _pk_id.100001.4cf6=e05eccee7e5d55f5.1607061433.4.1609766003.1609752843.; __utma=30149280.1665223328.1609745856.1609745856.1609766003.2; __utmb=30149280.0.10.1609766003; __utmz=30149280.1609766003.2.2.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login; __utma=223695111.724509044.1609745856.1609745856.1609766003.2; __utmb=223695111.0.10.1609766003; __utmz=223695111.1609766003.2.2.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login'
# 控制谷歌浏览器
driver = webdriver.Chrome()
url = r'https://movie.douban.com/subject/26266893/comments?status=P'
driver.get(url)
# 保存所有数据
all_data = pd.DataFrame()
# 超时时间设为10秒,超过10秒报错
wait = WebDriverWait(driver, 10)
while True:
# 一直等待,等待10s,超过10s终止,通过EC判断页面是否加载好
# 判断元素是否可被点击
# By.CSS_SELECTOR,dom树中另外一种访问目标节点的方式,
# 拷贝selector过来
wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#comments > div:nth-child(20) > div.comment > h3 > span.comment-info > a')
)
)
# 网页源码解析,得到dom文件
dom = etree.HTML(driver.page_source, etree.HTMLParser(encoding='utf-8'))
print(dom)
# 首页数据获取
data = get_web_data(dom,cookies_str)
# axis=0, 按列进行拼接
all_data = pd.concat([all_data, data], axis=0)
# condition 后页能否被点击
# 查找后页的CSS selector:'#paginator > a.next',如果
# 有这个selector说明还能点击下一页,如果找不到抛出NoSuchElementException
# 的错误
if not driver.find_element_by_css_selector('#paginator > a.next'):
# 没有就终止循环
break
# 有的话点击翻页
# 判断元素是否可被点击,等待十秒钟阻塞判断
confirm_bnt = wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#paginator > a.next')
)
)
# 执行翻页操作
confirm_bnt.click()
print(all_data)
all_data.to_csv('all_data.csv', index=None, encoding='gbk')
数据分析-词频统计
分词和设置停用词
词频统计一个作用是做词云,词云需要把一些无关的助词,标点给去掉,将停用词保存到一个文件,pd使用apply方法除去停用词
with open('stoplist.txt', 'r', encoding='utf-8') as f:
stop_words = f.read()
['\n', '', ' '] + stop_words.split()
data_cut = data['短评正文'].apply(jieba.lcut)
data_cut.apply(lambda x: [i for i in x if i not in stop_words])
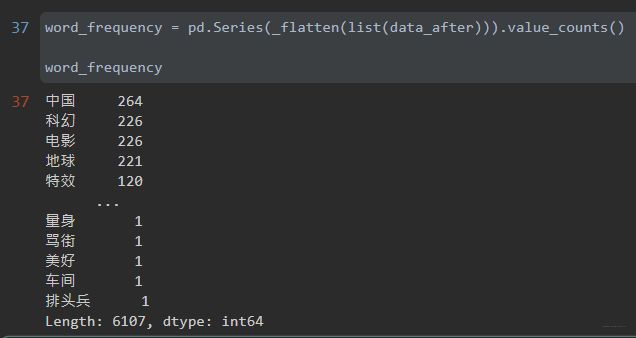
词频统计
pd.Series是一个一维数组,是基于NumPy的ndarray结构。Pandas会默然用0到n-1来作为series的index,但也可以自己指定index(可以把index理解为dict里面的key)。
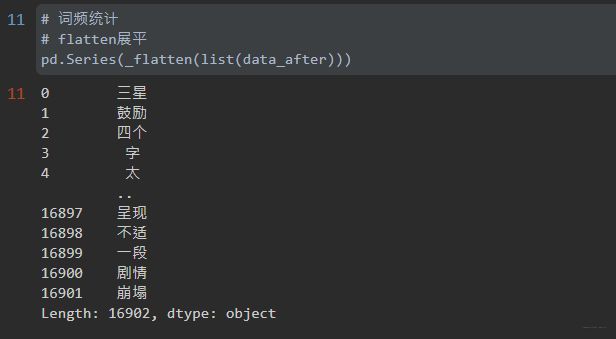
再用tkinter中的_flatten,展平二维数组,.value_counts()统计词频
word_frequency = pd.Series(_flatten(list(data_after))).value_counts()
绘制词云
使用wordcloud中的WordCloud绘制词云,配合plt展示,为了中文支持要设置中文字体font_path
mask = plt.imread(img)
wc = WordCloud(font_path=r'C:/Windows/Fonts/simkai.ttf', mask=mask,
background_color='white')
wc.fit_words(word_frequency)
plt.axis('off')
plt.imshow(wc)
取好评和差评数据
用大于小于逻辑判断取出一维的True or False数组index,通过data[index]取出索引位置值为True的数据
# 小于30差评,大于30好评
#%%
data['评分']
index_negative = data['评分'] < 30
index_postive = data['评分'] >= 30
#%%
data[index_postive]
#%%
data[index_negative]
完整代码
#%%
import pandas as pd
import jieba
from tkinter import _flatten
import matplotlib.pyplot as plt
from wordcloud import WordCloud
#%%
with open('stoplist.txt', 'r', encoding='utf-8') as f:
stop_words = f.read()
#%%
['\n', '', ' '] + stop_words.split()
#%%
data = pd.read_csv('douban.csv', encoding='GB18030')
#%%
def my_word_cloud(data=None, stop_word=None, img='aixin.jpg'):
data_cut = data['短评正文'].apply(jieba.lcut)
data_after = data_cut.apply(lambda x: [i for i in x if i not in stop_words])
word_frequency = pd.Series(_flatten(list(data_after))).value_counts()
mask = plt.imread(img)
wc = WordCloud(font_path=r'C:/Windows/Fonts/simkai.ttf', mask=mask,
background_color='white')
wc.fit_words(word_frequency)
plt.axis('off')
plt.imshow(wc)
#%%
data # 爬取的500条评论数据
#%%
data['短评正文'] # 只读获取评论正文
#%%
data['短评正文'].apply(jieba.lcut) # 分词
#%%
data_cut = data['短评正文'].apply(jieba.lcut)
# 去除停用词
data_cut.apply(lambda x: [i for i in x if i not in stop_words])
#%%
# 去停用词后的data frame
data_after = data_cut.apply(lambda x: [i for i in x if i not in stop_words])
#%%
# 词频统计
# flatten展平
pd.Series(_flatten(list(data_after)))
#%%
word_frequency = pd.Series(_flatten(list(data_after))).value_counts()
word_frequency
#%%
mask = plt.imread('aixin.jpg')
#%%
wc = WordCloud(font_path=r'C:/Windows/Fonts/simkai.ttf', mask=mask,
background_color='white')
#%%
wc.fit_words(word_frequency)
#%%
plt.imshow(wc)
plt.axis('off')
#%%
my_word_cloud(data=data, stop_word=stop_words)
#%%
data
#%%
# 小于30差评,大于30好评
data['评分']
#%%
index_negative = data['评分'] < 30
index_negative
#%%
index_postive = data['评分'] >= 30
#%%
# 好评词云
my_word_cloud(data=data[index_postive], stop_word=stop_words)
#%%
# 差评词云
my_word_cloud(data=data[index_negative], stop_word=stop_words)
#%%
# 整体词云
my_word_cloud(data=data, stop_word=stop_words)
#%%
数据分析-评论数量及评分与时间的关系
设置plt字体
plt不支持中文,要设置字体
plt.rcParams['font.sans-serif'] = 'SimHei'
绘制评分数量饼图
# 统计评分数量
num = data['评分'].value_counts()
#%%
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.pie(num, autopct='%.2f %%', labels=num.index)
plt.title('<流浪地球> 豆瓣短评评分分布')
评论数量和日期的关系
统计不同日期的评论发表数量
time_num = data['发表时间'].apply(lambda x: x.split(' ')[0]).value_counts()
time_numsort = time_num.sort_index()
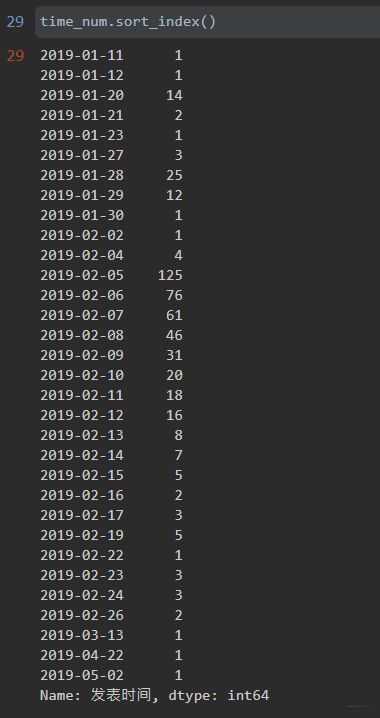
绘制折线图
plt.plot(x,y),x轴的x数组用range代替了,0到max_len,再用xticks替换x轴
# x轴修改,坐标刻度
plt.plot(range(len(time_numsort)), time_numsort)
plt.xticks(range(len(time_numsort)), time_numsort.index, rotation=45)
# 添加网格
plt.grid()
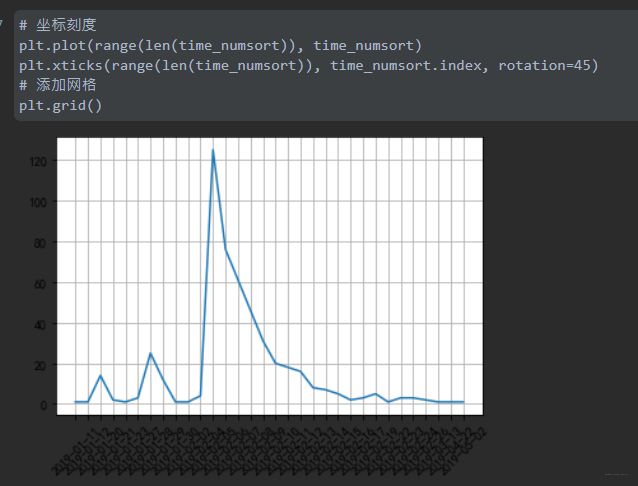
评论数量与时刻的关系
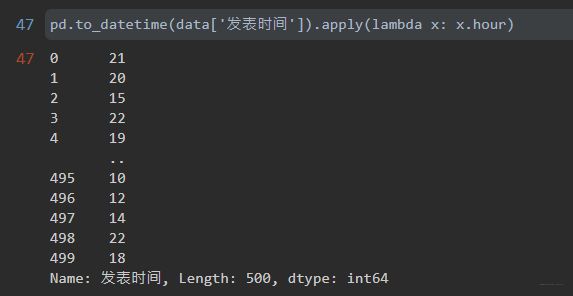
to_datetime字符串转化为时间戳格式
pd.to_datetime(data['发表时间'])
时间戳.hour可以直接获取该时间戳对应的小时,第一次知道
pd.to_datetime(data['发表时间']).apply(lambda x: x.hour)
统计不同小时下的发表评论数,sort_index是为了从小时0开始递增排序
hour_num = pd.to_datetime(data['发表时间']).apply(lambda x: x.hour).value_counts()
hour_numsort = hour_num.sort_index()
绘制折线图,和之前一致
plt.plot(range(len(hour_numsort)), hour_numsort)
# 修改坐标刻度
plt.xticks(range(len(hour_numsort)), hour_numsort.index)
# 添加网格
plt.grid()
plt.title("评论数据随时刻的变化情况")
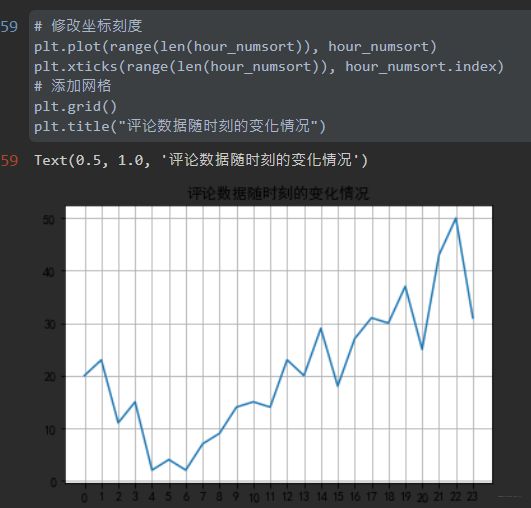
横坐标表示小时,纵坐标表示评论数
不同星级的评论数量与日期的关系
x轴是日期,递增增长,先获取x轴的内容
#%%
# 取所有行,两列
data.loc[:,['发表时间', '评分']]
# 取出日期
data['发表时间'] = data['发表时间'].apply(lambda x: x.split(' ')[0])
# 去重,按值排序
date = data['发表时间'].drop_duplicates().sort_values()
print(date)

同理可以取y轴内容
data['评分'].drop_duplicates().sort_values()

接着统计不同星级在不同日期里的个数,当前data数据:

构建一张二维表,用来统计不同星级在不同日期里的个数
tmp = pd.DataFrame(0,
index=date.drop_duplicates().sort_values(),
columns=data['评分'].drop_duplicates().sort_values()
)
print(tmp)

遍历数据并统计
for i,j in zip(data['发表时间'], data['评分']):
tmp.loc[i,j] +=1

除去最后一列
# iloc通过下标位置索引
tmp = tmp.iloc[:, :-1]
绘图
# 行和列
n,m = tmp.shape
# 设置画布参数大小
plt.figure(figsize=(10,5))
for i in range(m):
plt.plot(range(n), (-1 if i < 2 else 1) * tmp.iloc[:, i])
# 填充颜色
plt.fill_between(range(n), (-1 if i < 2 else 1) * tmp.iloc[:, i],
alpha=0.5)
# 网格线
plt.grid()
# 图例,不同线代表什么内容
plt.legend(tmp.columns)
# 横轴取日期
plt.xticks(range(n), tmp.index, rotation=45)
plt.show()

数据分析-居住城市及评论数量与城市的关系
获取评论最多的10个城市
统计评论最多的10个城市
#%%
data = pd.read_csv('douban.csv', encoding='GB18030')
#%%
data
#%%
data['居住城市']
#%%
city_value_count = data['居住城市'].value_counts()[:10]
#%%
city_value_count

绘图
# 设置字体
plt.rcParams['font.sans-serif'] = 'SimHei'
# 使用柱状图
plt.bar(range(len(city_value_count)), city_value_count)
# 设置标题
plt.title('评论数量最多的十个城市')
# 设置x轴
plt.xticks(range(len(city_value_count)), city_value_count.index,
rotation=45)
for i,j in enumerate(city_value_count):
plt.text(i, j, j, ha='center', va='bottom')
补充一下plt.text
plt.text(x, y, s, fontsize, verticalalignment,horizontalalignment,rotation , **kwargs)
- x,y表示标签添加的位置,默认是根据坐标轴的数据来度量的,是绝对值,也就是说图中点所在位置的对应的值,特别的,如果你要变换坐标系的话,要用到transform=ax.transAxes参数。
- s表示标签的符号,字符串格式,比如你想加个“143”,更多的是你标注跟数据有关的主体,你如实写便是。
- fontsize顾名思义就是你加标签字体大小了,取整数。
- verticalalignment表示垂直对齐方式 ,可选 ‘center’ ,‘top’ , ‘bottom’,‘baseline’ 等
- horizontalalignment表示水平对齐方式 ,可以填 ‘center’ , ‘right’ ,‘left’ 等
- ha='center’点在注释中间(right,center,left),va='bottom’点在注释底部 (‘top’, ‘bottom’, ‘center’, ‘baseline’)
效果图:
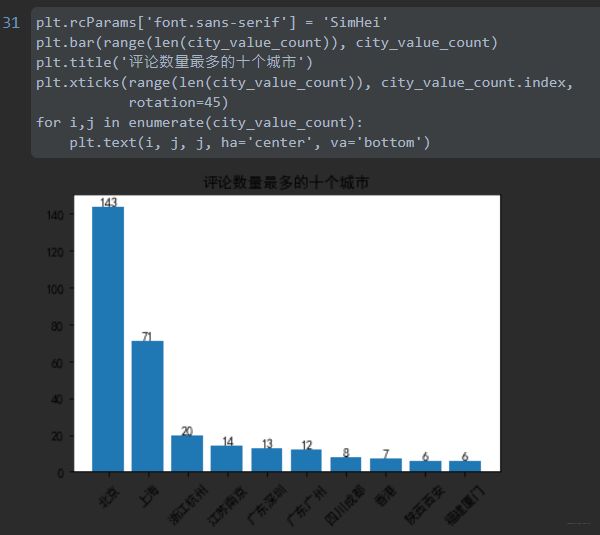
获取评论数前5的城市的不同评分数量
选取评论数最多的5个城市
# 选取评论数最多的5个城市
city_top5 = city_value_count[:5]
city_top5

获取每个城市的不同评分的数量
tmp = pd.DataFrame(0,
index=data['评分'].drop_duplicates().sort_values(),
columns=data['居住城市'].drop_duplicates()
)
print(tmp)
for i,j in zip(data['评分'], data['居住城市']):
tmp.loc[i,j] += 1
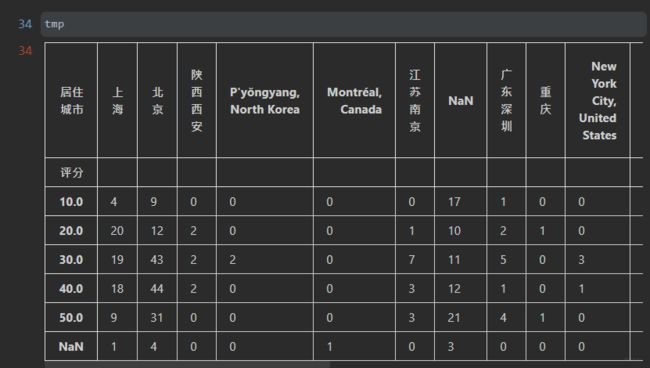
只选取评论数最多的5个城市数据
# 选取评论数最多的5个城市
city_top5 = city_value_count[:5]
city_top5
#%%
# 选取评论数最多的5个城市数据
tmp = tmp.loc[:, city_top5.index]
tmp
#%%
# 去掉nan行
tmp = tmp.iloc[:5, :]

绘图
n,m = tmp.shape
plt.figure(figsize=(10, 5))
plt.rcParams['axes.unicode_minus'] = False
for i in range(m):
plt.plot(range(n), tmp.iloc[:, i])
plt.fill_between(range(n), tmp.iloc[:, i], alpha=0.5)
plt.grid()
plt.title('评分与居住城市之间的关系')
plt.legend(tmp.columns)
plt.xticks(range(n), tmp.index, rotation=45)
plt.show()

补充fill_between 填充两个函数之间的区域
plt.fill_between(x, 0, y, facecolor=‘green’, alpha=0.3)

可以看到,用了这个函数的几个参数:
- x:第一个参数表示覆盖的区域,我直接复制为x,表示整个x都覆盖
- 0:表示覆盖的下限
- y:表示覆盖的上限是y这个曲线
- facecolor:覆盖区域的颜色
- alpha:覆盖区域的透明度[0,1],其值越大,表示越不透明