python基础语法--python语言及其应用
python基础语法
python引言
python
- python语言是一种高级动态、完全面向对象的语言。
- python中函数、模块、数字、字符串都是对象。
- python完全支持继承、重载、派生、多继承。
python程序
运行方式1:交互式运行python语句
运行方式2:保存源文件运行程序
交互式运行python语句
-
打开IDLE–科学计算器

IDLE里编程步骤
1."File->New File"打开文件编译器窗口。
2.输入代码。
3.“File ->Save”保存文件。
4.“Run->Run Module”运行,查看结果。
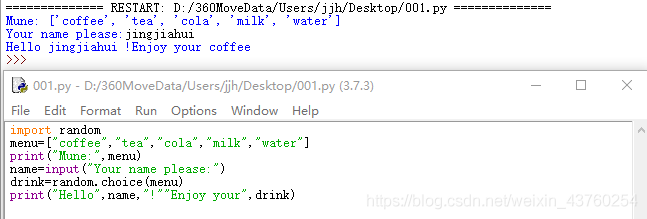
pycharm
- 语法高亮、代码检查、智能补全
- 快速修复、project管理、单元测试、导航功能
- Tools->Python Console 调出命令行界面来执行单条语句。
简单IDLE联系
- 注意对齐与缩进
- 注意字母大小写、空格
- 注意左右括号的配对
上机练习 1.0

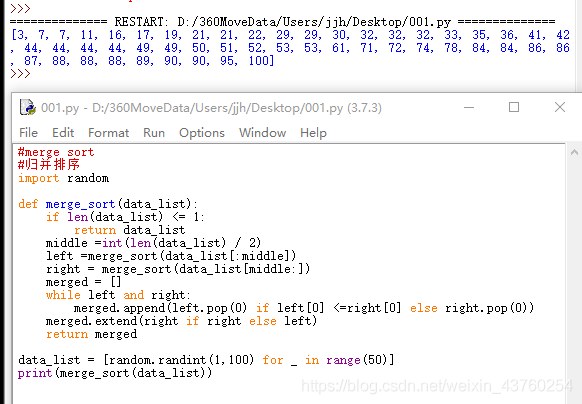

python语言介绍
python语言风格
- 优雅、明确、简单。
- 代码强制缩进。
- 程序是写给人读的,编程规范。
- python 哲学 import this
python数据的对象以及组织
数据:是信息的表现形式和载体。对现实世界实体和概念的抽象。
大数据:Volume、Velocity、Variety、Value、Veracity
python数据类型归纳
1.简单数据类型:int、float、complex(复数)、bool、str
2.容器类型用来组织这些值:list、tuple、set、dict
注:数据类型之间几乎都是可以转换的。
python组织方式
1.无组织、标签式组织数据、队列、图、栈、树等。
2.对大量的数据进行处理的时候、需要建立各种各样的数据组织,以便提高计算效率。
python计算和控制流
1.计算:计算是对现实世界处理和过程的抽象。
2.数据对象:各种类型的数据对象,可以通过各种运算组织成复杂的表达式。
3.运算语句:将表达式赋值给变量进行引用;赋值语句用来实现处理与暂存。
4.控制流语句:控制流语句用来组织语句描述过程。(顺序结构、条件分支、循环)。
5.定义语句:定义语句也用来组织语句,把一系列运算语句集合起来给一个名字。描述一个包含一系列处理过程的计算单元,主要为了源代码的各种复用。python可以定义函数、类等代码对象。调用函数或类也可以得到数据对象,python里所有可调用的事物称为callable。
python基本类型-数值型
1.整数:int-最大特点是不限制大小(python3)
2.计算:.+、-、*、/、//(整数取余)、%(求余数)、m**n(m的n次方)、abs(m)(求绝对值)、divmod(m,n)(会得到两个整数,一个是m//n,一个是m%n)。
3.判断:==、>=、<=、<、>(比较判断真或假)
4.数的进制:十进制、二进制、八进制、十六进制 例:常用的十进制是0-9,十个不同的符号,逢十进一。
5.十进制:xxx 二进制:0bxxx 八进制:0oxxx 十六进制:0xxxx
6.float浮点数类型:受到17位有效数字的限制。(避免相等判断)
7.复数类型(a+bj):.imag显示虚部,.real显示实部。复数不可以做大小比较。复数取模-abs。

8.数学函数模块:math函数-计算整数和浮点数。

9.数据函数模块:cmath函数-计算复数-平面直角坐标与极坐标转换。

python基本类型-逻辑值
1.逻辑类型(bool):仅包括真True或假False两个。
2.计算:与and(双目-同真为真)、或or(双目-有真为真)、非not(单目-真为假、假为真)
3.优先级:not>and>or(尽量使用小括号表示优先级)
4.None:None=无意义、不知道、假、空值。
python基本类型-字符串
1.字符串:字符串就是把一个个文字的字符“串起来”的数据。
2.文字字符:文字字符包含拉丁字母、数字、标点符号、特殊符号,以及各种语言文字字符。
3.表示方法:用双引号或者单引号都可以表示字符串,但必须成对,多行字符串用三个连续单引号或多引号表示。
4.特殊字符:用转义符号“\”表示。
| 转义字符 | 描述 |
|---|---|
| (在行尾时) | 续行符 |
| \ | 反斜杠符号 |
| ’ | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格 |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表 |
| \t | 横向制表 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数yy代表的字符 |
| \xyy | 十进制yy代表的字符 |
| \other | 其它字符以普通格式输出 |
5.字符的编号:0(第一个).1.2…正向或-1(最后一个).-2.-3…负向,用这种整数编号可以从字符串中抽取任何一个字符。
6.字符串是数据本身。名字是数据的标签。名字和字符串是“名”和“值”之间的关系。字符串数值只能是字符串类型,名字则可以关联任意类型的数值。
7.常见的字符串操作:
- 获取字符串的长度:len函数
- 切片操作(slice):s[start: end :step]–左闭右开即包含start不包含end。
- 加法(+):将两个字符串进行连接,得到新的字符串。
- 乘法(*):将字符串重复若干次,生成新的字符串。
- 判断字符串内容是否相同(==)。
- 判断字符串是否包含某个字符串(in)。
- 删除空格:
str.strip:去掉字符串前后的所有空格,内部的空格不受影响。
str.lstrip:去掉字符串前部(左部)的所有空格。 str.rstrip:去掉字符串后部(右部)的所有空格。 判断字母数字:
str.isalpha:判断字符串是否全部由字母构成。 str.isdigit:判断字符串是否全部由数字构成。
str.isalnum:判断字符串是否仅包含字母和数字。而不包含特殊字符。 - 字符串的高级操作: split:分割 、 join:合并upper/lower/swapcase:大小写相关、Ijust/center/rjust/:排版左中右对齐、replace:替换子串。
8.序列(sequence):能够按照整数顺序排列的数据。
9.序列的内部结构:可以通过0开始的连续整数来索引单个对象。可以执行切片,获取序列的一部分。可以通过len函数来获取序列中包含多少元素。可以用加法“+”来连接为更长的序列。可以用乘法“*”来重复多次,成为更长的序列。可以用“in”来判断某个元素是否在序列中存在。
变量与应用
1.给数据命名:命名语法:<名字> = <数据> 命名规则 :字母和数字组合而成,下划线“_”算字母,字母区分大小写。不带特殊字符(如空格、标点、运算符等)。名字的第一个字符必须是字母,而不能是数字。在python3开始文字的命名规则中,汉字算字母。
2.名字:名字就像一个标签一样,通过赋值来“贴”在某个数据数值上。名字与数值的关联,称为引用。关联数值后的名字,就拥有了数据的值和类型。一个数值可以和多个名字关联。
3.变量:与数值关联的名字也称作变量,表示名字的值和类型可以随时变化。变量可以随时指向任何一个数据对象,变量的类型随着指向的数据对象类型改变而改变。
4.赋值:名字与数据对象关联的过程,称为给变量的赋值。“==”(相等关系)是对数值的相等性进行判断。“=”(赋值号)则是计算等号右边式子的值,赋值给等号左边的变量。
5.赋值语句:通过赋值号将变量和表达式左右相连的语句。
6.赋值语句多种形式:<名字>=<数据>、a=b=c=1、a,b,c=7,8,9、price +=1(自运算)、price /=3+4
上机练习2.0

![]()

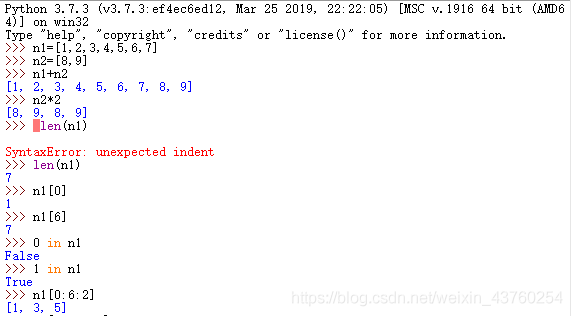
列表
1.数据收纳盒:用来收纳数据对象的数据类型,以一种规则的下标索引方式(收纳盒名字+数据序号)访问到每个数据。这种收纳盒师是一种序列。
2.列表可以删除、添加、替换、重排序列中的元素(可变类型)。
3.创建列表:方括号法[]、指明类型法list()。
4.列表的操作:
- 增长列表:append操作-在列表末尾加上一个数据对象 。insert操作-在列表中间指定位置插入一个数据对象。 extend操作-把两个列表中一个列表接在另一个列表后面。
- 缩减列表:pop操作-在列表中间指定位置提取并移除,无参数的pop默认移走最后一个。remove操作-根据列表中指定对象的值进行移除。clear操作-整个列表变成一个空列表。
- 列表是一种可变容器,可随意增减。但兵说不定所有的数据容器都能像列表这样可以继续添加新元素。
- 重新组织:reverse操作-把列表中的数据元素头尾反转重新排列。sort操作-把列表中的数据元素按照大小重新排列。reversed/sorted操作:得到对应重新排列的列表,而不影响原来的列表。

| 方法名称 | 使用例子 | 说明 |
|---|---|---|
| append | alist.append(item) | 列表末尾添加元素 |
| insert | alist.insert(i,item) | 列表中i位置插入元素 |
| pop | alist.pop() | 删除最后一个元素,并返回其值 |
| pop | alist.pop(i) | 删除第i个袁术,并返回其值 |
| sort | alist.sor() | 将表中元素排序 |
| reverse | alist.reverse() | 将表中元素反向排序 |
| del | del alist[i] | 删除第i个元素 |
| index | alist.index(item) | 找到item的首次出现位置 |
| count | alist.count(item) | 返回item在列表中出现的次数 |
| remove | alist.remove(item) | 将item的首次出现删除 |
元组
1.元组是不能再更新(不可变)序列。元组在保留列表大多数功能的同时,去掉了一些灵活性以换取更高的处理性能。
2.创建元组:圆括号法()、指明类型法tuple().
3.列表或元组中保存的各个数据称作元素,类型没有限制。
- 合并:加法运算(+)-连接两个列表/元组。乘法运算(*)-复制n次,生成新列表/元组。
- 列表/元组大小 len():列表/元组中元素的个数。
- 索引:alist[n]或atupie[n]-求编号为n的元素。可以用赋值语句给列表中的任何一个位置重新赋值。但元组属于不可变类型,索引只能获取对应位置中的数据值,不可重新赋值。
- 切片: alist[start: end :step] atuple[start: end :step] (左闭右开)
- 查找:in操作-判断某个元素是否存在于列表/元组中。index操作-指定的数据在列表/元组的哪个位置。count操作:指定的数据在列表/元组中出现过几次。
- 计算:sum函数-将列表中所有的数据元素累加。min/max函数-返回列表中最小/最大的数据元素。
字典
1.标签收纳盒:给数据贴上标签,就可以通过具有 特定含义的名字或者别的记号来获取数据。
2.通过标签(或者关键字)来索引数据,区别于列表或元组通过连续的整数来索引。
3.字典容器中保存着一些连的key-value对。通过键key来索引元素value。字典中的元素value没有任何顺序,可以是任意类型,甚至也可以是字典。字典的键值key可以是任意不可变类型(数值/字符串/元组)。
4.创建一个字典:花括号法和指明类型法
5.在字典中的每一项称为数据项,字典中保存的各个标签-数据值(key-value)。标签与数据值之间用冒号“:”连接。
6.批量添加数据项:例:student = dict.fromkeys((“name”,“age”))
7.字典是可变类型,可添加、删除、替换元素。
- 合并字典:updata方法。
- 增长字典:“关联”操作、updata操作-以key=value的形式批量添加数据项。
- 缩减字典:del操作-删除指定标签的数据项。 pop操作-删除指定的数据项并返回数据项。 popitem操作-删除并返回任意一个数据项。 clear操作-清空字典
8.字典大小:len函数
9.标签索引:dict[key] 获取字典中指定标签的数据值。更新指定标签的数据项。get操作不是变量,不能更改。
10.获取字典的标签、数据值和数据项:keys函数-返回字典中所有标签。 values函数-返回字典中的所有数据值。 items函数-将每个数据项表示为二元元组,返回所有数据项。
11.在字典中查找:in操作-判断字典是否存在某个标签。in操作和values函数的组合-判断字典中是否存在某个数据值。
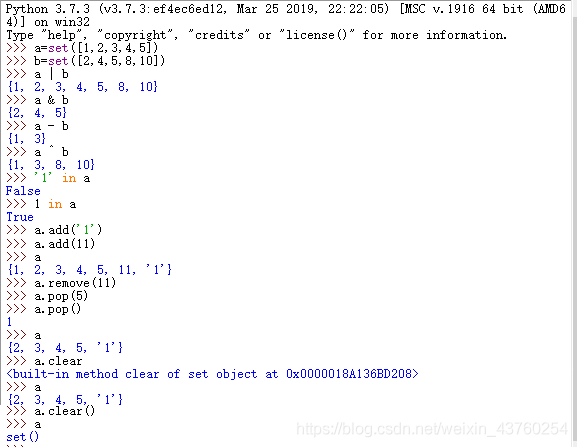
集合
1.标签带:通过改造字典类型,去掉关联数据值,只留下标签的新容器类型。
2.集合是不重复元素的集合。
3.创建一个集合:{}或者set() 用set()创建空集、用set()从其他序列转换生成集合。
4.集合会自动忽略重复数据,集合中不能加入可变类型数据。
5.增长集合:add-添加一个数据。 update-批量添加数据。
6.缩减集合:remove/discard-删除指定数据。pop-删除任意数据并返回值。clear-清空集合。
7.集合大小:len函数
8.访问集合中的元素:in-判断元素是否属于集合。 pop-删除数据元素的同时,返回它的值取遍所有元素之后,集合成为一个空集。可以用copy操作先给集合做一个替身。
9.集合运算
| 运算 | 运算符 | 新集合方法 | 更新原集合方法 |
|---|---|---|---|
| 并 | alb | union | update |
| 交 | a&b | intersection | intersection_update |
| 差 | a-b | difference | difference_update |
| 对称差 | a^b | symmetric_difference | symmetric_difference_update |
10.交集:isdisjoint():两集合交集是否为空。适用于快速去除重复的数据项。适用于判断元素是否在一组数据中,如果这些数据的次序不重要,使用集合可以获得比列表更好的性能。
可变类型和不可变类型
1.列表:可以接长、拆短的积木式收纳盒。 元组:固定长短的收纳盒。
2.不可变类型:一旦创建就无法修改数据值的数据类型。(整数、浮点数、复数、逻辑值、元组、字符串)
3.可变类型:可以随时改变的数据类型。(列表、字典、集合)
4.灵活性强会花费一些计算或者存储的代价去维护这些强大的功能。
5. 变量引用特征:可变类型的变量操作需要注意,多个变量通过赋值引用同一个可变类型变量时,通过其中任何一个变量改变了可变类型对象,其它变量也随之改变。
建立复杂的数据结构
1.用方括号[]创建的列表、用圆括号()创建元组、用花括号{}创建字典、每种类型中,都可以通过方括号[]对单个元素进行访问。
2.对于列表和元组,方括号里都是整型的偏移量。对于字典,方括号里是键。都能返回元素值。
3.将这些内置数据结构自由的组织成更大、更复杂的结构。创建自定义数据结构的过程中,唯一的限制来自于这些内置数据类型本身。
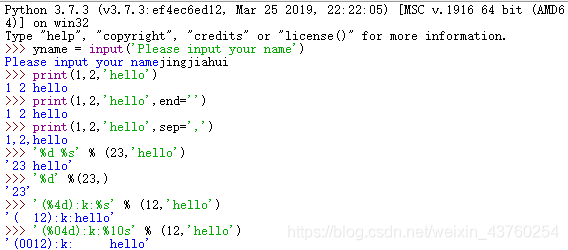
输入和输出
1.input函数:input(prompt)-显示提示信息prompt,由用户输入内容,input()返回值是字符串,通过int()函数将字符串类型强制转换为整型。
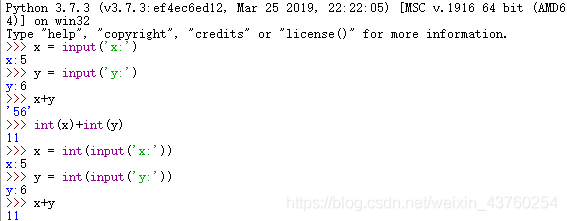
2.print函数:print([object,…][,sep=’’][,end=’\n’][,file=sys.stdout])-打印各变量值的输出。sep-表示变量之间用什么字符串隔开,缺省是空格。end-表示以这个字符串结尾,缺省为换行。file-指定了文本将要发送到的文件、标准流或其它类似的文件的对象,默认是sys.stdout(标准输出/终端输出)。
3.print函数-格式化字符串:print函数默认把对象打印到stdout流,并且添加了一些自动的格式化(可以自定义分隔符和行末符)。
上机练习3.0


计算和控制流
1.“冯.诺伊曼结构”计算机:冯.诺伊曼-计算机之父。
2. 计算机硬件五大部件:
- 运算器:进行算术和逻辑运算。
- 控制器:控制计算机持续协调运行。
- 存储器:存储数据和逻辑。
- 输入设备:从计算机外部获取数据。
- 输出设备:将计算结果反馈给外界。
3.计算机内部运行过程-基本步骤:
(1)控制器从存储器中取出程序语句和额外数据。
(2)数据齐全的语句交给运算器进行算术或者逻辑运算。
(3)运算结果再存回存储器。
(4)控制器确定下一条程序语句,回到步骤1继续。
例:赋值语句<变量>=<表达式>
python语言的赋值语句很好地对应了“运算”和“存储”。
赋值语句的执行语句语义为:计算表达式的值,存储起来,贴上变量标签以便将来引用。与计算机运行过程中的“计算”和“存储”相对应。
“控制器确定下一条程序语句”即对应“控制”。
控制流程
1.控制流程:在计算机运行过程中,“下一条语句”决定了计算机是能够自动调整、自动反复操作,还是只能像计算器那样一步接着一步计算。这种决定“下一条语句”的机制,在程序设计语言中称作“控制流程”。
2.python语句中的控制流程:
- 顺序结构:按照语句队列前后顺序来确定下一条将要执行的语句。
- 条件分支结构:根据当前情况选择下一条语句发位置。
- 循环结构:周而复始地执行一系列语句。
3.简单类型与容器类型:
- 简单类型和容器类型之间的关系,就像玻璃珠与盒子、苹果与口袋
- 简单类型是实体对象。
- 容器类型是结构,将实体对象进行各种组织和编排。
| 类别 | 对象实体 | 容器 |
|---|---|---|
| 数据 | 数值类型、逻辑类型、字符串类型 | 列表、元组、字典、集合、子集 |
| 计算 | 赋值语句 | 顺序结构、条件分支结构、循环结构 |
4.计算语句和结构语句:就像简单类型和容器类型之间的关系。用顺序、条件分支和循环结构,来对各个赋值语句进行编排,最终成为解决问题的程序。
控制流-条件分支结构
1.条件分支:让程序有了判断力,根据计算机内部的情况(如变量值),来决定下一步做什么,这样的控制流程,就称为条件分支。根据预设条件来控制下一步该运行哪段语句。
2.基本要素:预设的判断条件、达成条件后执行的语句。
3.扩展要素:当体哦阿健不满足执行的语句、多条件时那个满足执行那个条件。
条件语句
1.条件语句:
if<逻辑表达式>:
<语句块1>
......
else:
<语句块2>
- if和else都是“保留字”
- “逻辑表达式”是指所有运算的结果为逻辑类型(True或False)的表达式。
- “语句块”就是条件满足后执行的一组语句
- 冒号表示语句层次。
- 各种数据类型中某些值会自动转换为False,其它值则是True
2.多种情况的条件语句:
- 用else子语句进行判定
- 使用elif语句进行判定
if <逻辑表达式1>:
<语句块1>
elif <逻辑表达式2>:
<语句块2>
elif <逻辑表达式3>:
......
else:
<语句块n>
条件循环
1.循环结构:让计算机执行冗长单调的重复性任务。根据需要对一系列操作进行设定次数或者设定条件的重复,这样的控制流程,就称作循环结构。作用-能持续对大量数据进行处理,在长时间里对一些未知的状况进行连续监测循环结构。
2.循环结构的基本要素:
- 循环前提和执行语句-在执行这组语句之前,计算机会检查循环前提是否存在,只要存在,就会反复执行这组语句,直到循环前提消失。
- 循环前提的类型:(1)从某个容器或者潜在的数据集中逐一获取数据项,什么时候取不到数据项了,循环的前提就消失。(2)只要逻辑表达式计算结果为真(True),循环的前提就存在,什么时候逻辑表达式计算结果为假(False),循环的前提就消失了。
3.与条件分支结构的区别:循环结构会多次检查循环前提。
4.扩展要素:当循环前提消失,停止执行这组语句的时候,执行一次另一组语句。
5.while循环语法:
while<逻辑表达式>:
<语句块>
break #强制跳出循环,不会执行else。
continue #略过余下循环语句
<代码块>
else:#条件不满足退出循环,则执行
<语句块>
- while、else:保留字
- 逻辑表达式:指所有运算的结果为逻辑类型(True或False)的表达式。
- 语句块:一组语句。
6.循环嵌套:双重或多重嵌套
- 中断程序运行:CTRL+C
- 通过修改程序中range函数的参数,还可以验证其它范围内的连续整数。
迭代循环
1.迭代循环:
- python语句中for语句实现了循环结构的第一种循环前提。
for<循环变量>in<可迭代循环>:
<语句块1>
break #跳出循环
continue #略过余下循环语句
else:#迭代完毕,则执行
<语句块2>
(1)for、in和else都是“保留字”
(2)可迭代对象表示从这个数据对象中可以逐个取出数据项赋值给“循环变量”。
(3)可迭代对象有很多 类型,如字符串、列表、元组、字典、集合等,也可以有后面提到的生成器、迭代器等。
2.range函数:
(1)range(<终点>)
返回一个从0开始到终点的数列
(2)range(<起点>,<终点>)
从0以外的任务整数开始构造数列
(3)range(<起点>,<终点>,<步长>)
修改数列的步长,通过将步长设置为负数能够实现反向数列。
range构建的数列,包含起点整数,而不包含终点整数。
(4)range类型的对象
直接当作序列或转换为list或者tuple等容器类型。

嵌套循环中的跳出和继续
- 都只能在循环内部使用。
- 均作用于离它们最近的一层循环。
- break是跳出当前循环并结束本层循环。
- continue是略过余下循环语句并接着下一次循环。
上机实验4.0
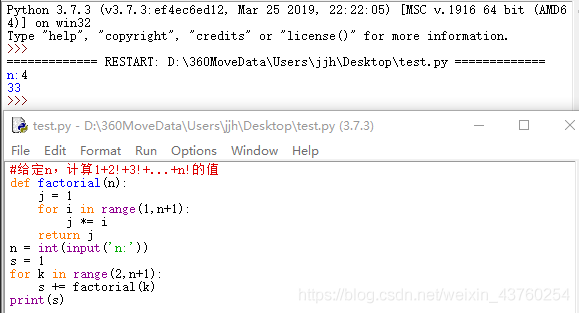
1.给定n,计算1+2!+3!+…+n!的值。
def factorial(n):
j = 1
for i in range(1,n+1):
j *= i
return j
n = int(input('n:'))
s = 1
for k in range(2,n+1):
s += factorial(k)
print(s)
2.给定y和m,计算y年m月有几天?-——注意闰年
date = {
input('请输入年份:'): input('请输入月份:')}
for Y, M in date.items():
Year = int(Y)
Month = int(M)
if Month == 2:
if (Year % 400 == 0) or (Year % 4 == 0) and (Year % 100 != 0):
print('%d年%d月有%d天' % (Year, Month, 29))
else:
print('%d年%d月有%d天' % (Year, Month, 28))
elif Month == 1 or 3 or 5 or 7 or 8 or 10 or 12:
print('%d年%d月有%d天' % (Year, Month, 31))
else:
print('%d年%d月有%d天' % (Year, Month, 30))

3.给定字符串s和数字n,打印把字符串s向右移动n位的新字符串。例如:abcd和1,返回dabc。
s = input('请输入一个字符串:')
n = int(input('请输入数字:'))
Newlist = s[-1:-n-1:-1]+s[0:len(s)-n]
print(Newlist)
4.给定一个英文数字字符串,打印相应阿拉伯数字字符串 例如:one-four-five-nine,返回1459。
s = input('输入英文数字字符串:')
list1 = s.split('-')
str2 = ' '
dict1 = {
'zero': '0', 'one': '1', 'two': '2', 'three': '3', 'four': '4', 'five': '5', 'six': '6', 'seven': '7', 'eight': '8', 'nine': '9'}
for i in list1:
str1 = dict1[i]
str2 = str2 + str1
print(str2)
代码组织:函数(def)
1.封装:容器是对数据的封装。函数是对语句的封装。类是对方法和属性的封装。
2.函数:程序中实现明确功能的代码段可以封装成一个函数,以便复用。
3.定义函数:
用del语句创建一个函数 ,用return关键字指定函数返回的值
def<函数名>(<参数表>):
<缩进的代码段>
return<函数返回值>
4.调用函数:
<函数名>(<参数>) 注意括号!
无返回值:<函数名>(<参数表>)
返回值赋值:v = <函数名>(<参数表>)
5.局部变量:在函数内部定义的参数以及变量。只在该函数定义范围内有效,函数外边无法访问到
6.全局变量:在函数外部定义的,作用域是整个代码段。
7.global关键字:在哈桑农户内部使用与全局变量同名的变量时,若未在函数内进行定义,则使用全局变量的值。一旦在函数内部进行定义,python会在函数内部创建一个局部变量,与全局变量就不相关了。使用global关键字可以在函数中改变全局变量的值。
8.map函数:有时候需要对列表中每个元素做一个相同的处理,得到新列表。
map(func,list1,list2...)
函数func有几个参数,后面跟几个列表。
9.匿名函数lambda:有时候函数只使用一次,其名称也就不重要,可以无需飞身去def一个。
lambda表达式:返回一个匿名函数。
lambda<参数表>:<表达式>
函数的参数
1.参数:传入到函数的值。当调用含参数的函数时,这些参数的值会被复制给函数中的对应参数。
2.形式参数:函数创建和定义过程中,函数名后面括号里的参数。
3.实际参数:函数在调用过程中传入的参数。
形式参数只是代表一个位置、一个变量名。实际参数是一个具体内容,赋值到变量的值。

4.定义函数的参数:定义函数时,参数可以有两种。
一种是在参数表中写明参数名key的参数,固定了顺序和数量的固定参数。
def func(key1,key2,key3...):
def func(key1,key2=value2..):
一种是定义时还不知道会有多少参数传入的可变参数。
def func(*args): #不带key的多个参数。-print
def func(**kwargs): #key=val形式的多个参数。

调用函数的参数
一种是没有名字的位置参数
func(arg1,arg2,arg3...)
会按照前后顺序对应到函数参数传入
一种是带key的关键字参数
func(key1=arg1,key2=arg2...)
由于指定了key,可以不按照顺序对应。
如果混用,所有位置参数必须在前,关键字参数必须在后。
上机练习.5.0
1.水仙花数的判定:创建一个函数,接受一个参数n(n>=100),判断这个数是否为水仙花数。结果返回True或False。
水仙花数:满足如果这个数为m位数,则每个位上的数字的m次幂之和等于它本身。
例如:1^ 3+5^ 3+3^ 3=153,1^ 4+6^ 4+3^ 4+4^ 4=1634
1.2创建一个函数,接受一个参数max(max>=1000),调用上题编写的判断函数,求100到max之间的水仙花数。
x=int(input('请输入大于1000的整数:'))
def daff(num):
a=len(str(num))
daff_sum=0
for y in str(num):
daff_sum=int(y)**a+daff_sum
return daff_sum
for i in range(100,x):
sum=daff(i)
if sum==i:
print('水仙花数为:'+str(i))
2.创建一个函数,接受两个字符串作为参数,返回两个字符串字符集合的并集。
例如:接受的两个字符串为“abc”和“bcd”,返回set([‘a’,‘b’,‘c’,‘d’])
def add(a,b):# 定义两个参数的函数
set1 = set(set(a)|set(b))
return sorted(set1)# 将set1排序
a,b = input().split()# 把空格符分开的字符串分割
print(add(a,b))
引用扩展模块
1.模块就是程序:每一个扩展名为.py的python程序都是一个独立的模块。模块能定义函数、类和变量,让你能够有逻辑的组织你的python代码段。
2.组织结构:包是放在一个文件夹里的模块集合。
3.模块引用方式:
引用方法1:
import <模块> [as <别名>]
- 将模块中的函数等名称导入当前程序。
- 在调用模块中的函数的时候,需要加上模块的命名空间。
- 可以给导入的命名空间替换一个新的名字。
引用方法2:<模块>.<名称> # 用模块中的几个函数。
from <模块> import <函数>
- 引入模块中的某个函数
- 调用时不需要再加上命名空间。
引用方法3:
from <模块> import *
- 将模块中所有的名称都导入现在的空间,如math中不用math.pi,直接pi=π。但由于是模块内命名完全导入,可能与原空间命名重复、丢失。
4.标准库:
- 数学和数学模块
| 库名 | 功能 |
|---|---|
| numbers | 数字抽象基类 |
| math | 数学函数 |
| cmath | 复数的数学函数 |
| decimal | 十进制定点和浮点算术 |
| fractions | 有理数 |
| random | 生成伪随机数 |
| statistics | 数学统计功能 |
- 数据类型
| 库名 | 功能 |
|---|---|
| datetime | 基本日期和时间类型 |
| calendar | 与日历相关的一般功能 |
| collections | 容器数据类型 |
| heapq | 堆队列算法 |
| bisect | 数组二分算法 |
| array | 高效的数值数组 |
| weakref | 弱引用 |
| types | 动态类型创建和内置类型的名称 |
| copy | 浅层和深层复制操作 |
| pprint | 格式化输出 |
| reprlib | 备用repr()实现 |
| enum | 支持枚举 |
- 功能编程模块
| 库名 | 功能 |
|---|---|
| itertools | 为高效循环创建迭代器的函数 |
| functools | 可调用对象的高阶函数和操作 |
| operator | 标准运算符作为函数 |
- 数据持久化
| 库名 | 功能 |
|---|---|
| pickle | python对象序列化 |
| copyreg | 注册pickle支持功能 |
| shelve | python对象持久化 |
| marshal | 内部python对象序列化 |
| dbm | 与Unix“数据库”的接口 |
| sqlite3 | SQLite数据库的DB-API 接口 |
- 数据压缩和存档
| 库名 | 功能 |
|---|---|
| zlib | 与gzip兼容的压缩 |
| gzip/bz2 | 支持zip/bzip2文件 |
| lzma | 使用LZMA算法进行压缩 |
| zipfile | 使用ZIP存档 |
| tarfile | 读取和写入tar归档文件 |
- 文件格式
| 库名 | 功能 |
|---|---|
| csv | CSV文件读写 |
| configparser | 配置文件解析器 |
| netrc | netrc文件处理 |
| xdrlib | 对XDR数据进行编码和解码 |
| plistlib | 生成并解析Mar OS X .plist文件 |
- 文件和目录访问
| 库名 | 功能 |
|---|---|
| pathlib | 面向对象的文件系统路径 |
| os.path | 常见的路径名操作 |
| fileinput | 迭代多个输入流中的行 |
| stat | 解释stat()结果 |
| filecmp | 文件和目录比较 |
| tempfile | 生成临时文件和目录 |
| glob | Unix样式路径名模式扩展 |
| fnmaych | Unix文件名模式匹配 |
| linecache | 随机访问文本行 |
| shutil | 高级文件操作 |
| macpath | Mac OS 9路径操作函数 |
- 通用操作系统服务
| 库名 | 功能 |
|---|---|
| os | 其他操作系统服务 |
| io | 用于处理流的核心工具 |
| time | 时间访问和转换 |
| argparse 用于命令行选项,参数和子命令的解析器 | |
| getopt | 用于命令行选项的c风格解析器 |
| logging | python的日志记录工具 |
| getpass 便携式密码输入 | |
| curses 字符单元格显示的终端处理 | |
| platform | 访问底层平台的标识数据 |
| errno | 标准errno系统符号 |
| ctypes | python的外部函数库 |
- 并发执行
| 库名 | 功能 |
|---|---|
| threading | 基于线程的并行性 |
| multiprocessing | 基于进程的并行性 |
| concurrent.futures | 启动并行任务 |
| subprocess | 子流程管理 |
| sched | 事件调度程序 |
| queue | 同步的队列表 |
| _thread | 低级线程API |
- 加密服务
| 库名 | 功能 |
|---|---|
| hashlib | 安全哈希和消息摘要算法接口 |
| hmac | 用于消息身份验证的密钥哈希算法 |
| secrets | 生成用于管理机密的安全随机数 |
- 网络和进程间通信
| 库名 | 功能 |
|---|---|
| asyncio | 异步I/O |
| socket | 低级网络接口 |
| ssl | 套接字对象的TLS/SSL包装器 |
| select | 等待I/O完成 |
| selectors | 高级I/O复用 |
| asyncore | 异步套接字处理程序 |
| asynchat | 异步套接字命令/响应处理程序 |
| signal | 设置异步事件的处理程序 |
| mmap | 内存映射文件支持 |
- 互联网数据处理
| 库名 | 功能 |
|---|---|
| 电子邮件和MIME处理包 | |
| json | JSON编码器和解码器 |
| mailbox | 以各种格式处理邮箱 |
| mimetypes | 将文件名映射到MIME类型 |
| base64 | Base16/Base32/Base64/Base85数据编码 |
| binhex | 对binhex4文件进行编码和解码 |
| binascii | 在二进制和ASCII之间进行转换 |
| quopri | 对MIME引用的可打印数据进行编码和解码 |
| uu | 对uuencode文件进行编码和解码 |
-互联网协议和支持
| 库名 | 功能 |
|---|---|
| webbrowser | web浏览器控制器 |
| cgi | 通用网关接口支持 |
| cgitb | CGI脚本的回溯管理器 |
| wsgiref | WSGI实现程序和参考实现 |
| urllib | URL处理模块 |
| http | HTTP模块 |
| smtpd | SMTP服务器 |
| telnetlib | Telnet客户端 |
| socketserver | 网络服务器的框架 |
| xmlrpc | XMLRPC服务器和客户端模块 |
| ftplib/poplib/imaplib/nntplib/smiplib | FTP/POP3/IMAP4/NNTP/SMTP协议客户端 |
| ipaddress | IPv4 /IPv6操作库 |
- 多媒体服务
| 库名 | 功能 |
|---|---|
| audioop | 处理原始音频数据 |
| aifc | 读写AIFF和AIFC文件 |
| sunau | 读取和写入Sun AU文件 |
| wave | 读写WAV文件 |
| chunk | 读取IFF分块数据 |
| colorsys | 颜色系统之间的转换 |
| imghdr | 确定图像的类型 |
| sndhdr | 确定声音文件的类型 |
| ossaudiodev | 访问兼容OSS的音频设备 |
- 结构化标记处理工具
| 库名 | 功能 |
|---|---|
| html | 超文本标记语言支持 |
| xml | XML处理模块 |
- 程序框架
| 库名 | 功能 |
|---|---|
| turtle | 海龟作图库 |
| cmd | 支持面向行的命令解释器 |
| shlex | 简单的词法分析 |
- 图形用户界面
| 库名 | 功能 |
|---|---|
| tkinter | Tcl/Tk的python接口 |
5.命名空间:表示标识符的可见范围。一个标识符可以在多个命名空间中定义,在不同命名空间中的含义互不相干。
dir(<名称>)函数:列出名称的属性。
help(<名称>)函数:显示参考手册。
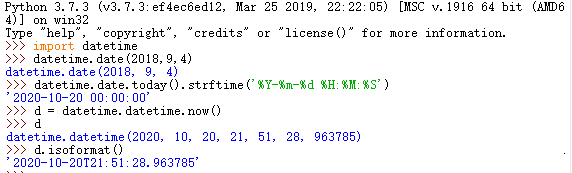
datetime模块
1.datetime主要的类:
可对date、time、datetime三种时间模式进行单独管理。
datetime.date() --处理日期(年月日)
datetime.time() --处理时间(时分秒、毫秒)
datetime.datetime() --处理日期+时间
datetime.timedelta() --处理时段(时间间隔)
2.获取今天的日期:
datetime.date.today()
datetime.datetime.now()
3.修改日期格式:使用strftime格式化
datetime.datetime.isoformat()
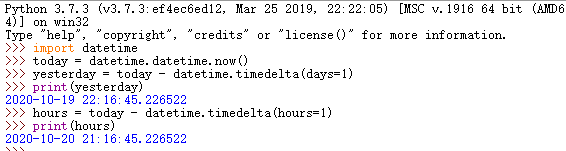
4.时间戳:时间戳是指格林威治时间1970年01月01日00时00分00秒起至现在的总秒数。
将日期转换为时间戳(纪元时间)
timetuple函数:将时间转换成struct_time格式。
time.mktime函数:返回用秒数来表示时间的浮点数。
将时间戳转换成日期:datetime.date.fromtimestamp()
5.timedelta()方法:时间上的加减法,表示两个时间点的间隔。
calendar模板
1.calendar模块:根日历相关的若干函数和类,可以生成文本形式的日历。
2.常用函数:
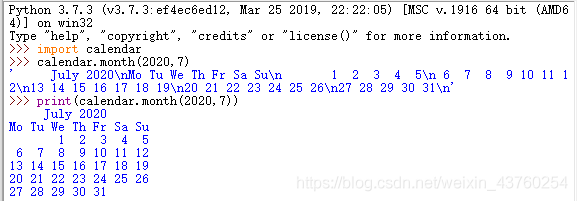
calendar.calendar(<年>):返回多行字符串
calendar.month(<年>,<月>):返回多行字符串
calendar.prmonth(<年>,<月>):相当于print(calendar.month(<年>,<月>))
calender.prcal(<年>) :相当于print(calendar.prcal(<年>))
3.calendar.monthcalendar()
- 返回某一年的某一个月份日历,是一个嵌套列表。
- 最里层的列表含有七个元素,代表一周(从周一到周日)
- 如果没有本月的日期,则为0。

4.判别闰年:
普通闰年:能被4整除但不能被100整除的年份。
世纪闰年:能被400整除的年份。
calendar.isleap(<年>)
5.计算某个月共有多少天,从周几开始:
calendar.monthrange(2018,9)
- 从0开始,依次为周一、周二…
6.计算某天是周几:
calendar.weekday(2018,8,15)
- 返回0-6,依次对应的是周一到周日。
time模块
1.time.time方法:获得现在当前机器的时间,精度较高。
2.时间戳的用处:对程序运行多长时间进行计时。
3.获得当前的时间:time.asctime() /time.ctime()
4.将元组数据转化为日期:
t = (2018,8,13,11,42,31,0,0,0)
time.asctime(t)
out:'Mon Aug 13 11:42:31 2018'
这一系列的数值分别对应年、月、日、时、分、秒、周几、一年中的第几天、是否为夏令时间。
5.利用索引获取时间信息:
struct_time类
time.localtime()
out:time.struct_time(tm_year=2018,tm_mon=8,tm_mday=13,tm_hour=12,tm_min=24,tm_sec=11,tm_wday=0,tm_yday=225,tm_isdst=0)
6.索引获取时间信息:
t = time.localtime()
year =t[0]
out:2018
7.让程序运行到某处便暂停:
time.sleep()
for x in range(3):
print(x)
t1 =time.time()
time.sleep(1)
t2 = time.time()
print(t2-t1)
算术模块
1.math模块:
math模块支持浮点数运算。
math.sin()/math.cos()/math.tan()
math.pi #π=3.14159.....
math.log(x,a)#以a为低的x的对数
math.pow(x,y)# x^y^
2.cmath模块:
cmath模块支持复数运算。
cmath.polar()#极坐标
cmath.rect()#笛卡尔坐标/直角坐标
cmath.exp(x)#e^x^
cmath.log(x,a)#以a为底的x的对数
cmathlog10(x)#以10 为底x的对数
cmath.sqrt(x)#x的平方根
3.decimal模块:
小数-固定精度的浮点数
生成小数
from decimal import Decimal
Decimal(‘0.1’)
小数计算
Decimal(‘0.1’)+Decimal(‘0.1’)+Decimal(‘0.10’)-Decimal(‘0.3’)
out:Decimal(‘0.0’)
4.fractions模块
分数-实现了一个有理数对象
生成分数
from fractions import Fraction
Fraction(1,4)/Fraction(‘0.25’)
浮点数转换为分数
Fraction.from_float(1.75)
- 尽管可以把浮点数转换为分数,在某些情况这么做会有不可避免的精度损失,因为这个数字在其最初的浮点形式上是不精确的。
5.random模块:
伪随机数
计算机中的随机函数是按照一定算法模拟生成的,其结果是确定的,是可预见的。
随机数种子
随机种子相同,随机数的序列也是相同的。
random.seed(a=None)
random.random(),生成范围在[0,1)之间的随机实数。
random.unifrom(),生成指定范围的内的随机浮点数。
random.randint(m,n)生成指定范围[m,n]内的整数。
random.randrange(a,b,n)可以在[a,b)范围内,按n递增的集合中随机选择一个数。
random.getrandbits(k),生成k位二进制的随机整数。
random.choice(),从指定序列中随机选择一个元素。
random.sample(),能指定每次随机元素的个数。
random.shuffle(),可以将可变序列中所有元素随机排序。
持久化模块
1.临时性对象:类创建的对象并不是真正的数据库记录。存储在内存中而不是在文件中,关闭python,实例将消失。
2.对象持久化:对象在创建它们的程序退出之后依然存在。
3.标准库模块-对象持久化:
pickle:任意python对象格式化和解格式化。
dbm:实现一个可通过键访问的文件系统,以存储字节串。
shelve:按照键把pickle处理后的对象存储到一个文件中。
4.shelve模块:
提供基本的存储操作,通过构造一个简单的数据库,像操作字典一样按照键存储和获取本地的python对象,使其可以跨程序运行而保持持久化。其中键必须是字符串,且是唯一的。值可以是任何类型的python对象。
5.shelve与字典类型的区别:一开始必须打开shelve,并且在修改后需要关闭它。
6.数据处理:不支持类似SQL的查询工具。但只要通过键获取到保存在文件的对象,就可以像正常的数据对象一样处理。
7.shelve 常用操作:
- 将任何数据对象,保存到文件中去
d = shelve.open(filename)
open函数在调用时返回一个shelf对象,通过该对象可以存储内容。 - 类似字典形式访问,可读可写
d[key] = data
value = d[key]
del d[key] - 操作完成后,记得关闭文件。
d.close()
文件文本读写模块
1.普通文件:数据持久化的最简单类型。仅仅是在一个文件名下的字节流,把数据从文件读入内容,从内存写入文件。
2.open()函数:
f = open(filename[,mode[,buffering]])
- f:open()返回的文件对象。
- filename:文件的字符名。
- mode:可选参数,打开模式和文件类别。
- buffering:可选参数文件的缓冲区,默认为-1。
3.mode第一个字母表明对其的操作:
- ‘r’表示读模式。
- ‘w’表示写模式。
- ‘x’表示在文件不存在的情况下新创建并写文件。
- ‘a’表示在文件末尾追加写内容。
- ‘+’表示读写模式。
4.mode第二个字母是文件类型:
- ‘t’表示文本类型。
- ‘b’表示二进制文件。
5.文件的写操作:
- f.write(str)
- f.writelines(strlist):写入字符串列表
6.文件的读操作:
- f.read()
- f.readline():返回一行
- f.readlines():返回所有行、列表
7.文件的关闭:
文件打开后要记得关闭,关闭的作用是终止对外部文件的连接,同时将缓存区的数据刷新到硬盘上。
调用close()方法:f.close()
使用上下文管理器:确保在退出后自动关闭文件
with open(‘textfile’,‘rt’) as myfile:
myfile.read()
8.结构化文本文件:csv
1.纯文本文件,以“,”为分隔符。
- 值没有类型,所有值都是字符串。
- 不能指定字体颜色等样式。
- 不能指定单元格的宽高,不能合并单元格
- 没有多个工作表
- 不能嵌入图像图表
2.文件读取 - reader:
re = cav.reader()
接受一个可迭代对象(比如csv文件),能返回一个生成器,可以从其中解析出内容。
3.文件读取 - DicReader:
re = csv.DictReader()
- 与reader类似
- 但返回的每一个单元格都放在一个元组的组内。
4.文件写操作:
w = csv.wriiter()
w.witerow(rows)
- 当文件不存在时,自动生成。
- 支持单行写入和多行写入。
字典数据写入:
w = csv.DictWriter()
w.writeheader()
w.writerow(rows)
5.openpyxl模块:
- 用来读写扩展名为xlsx/xlsm/xltx/xltm的文件。
- Workbook类是对工作簿的抽象。
- Worksheet类是对表格的抽象。
- Cell类是对单元格的抽象文件写操作。
操作之前先导入第三方库 - 安装: pip install openpyxl
- 导库:from openpyxl import workbook
创建Excel文件
一个workbook对象代表一个excel文档,使用该方法创建一个worksheet对象后才能打开一个表。
from openpyx1 import Workbook
wb =Workbook()
ws = wb.active
读取Excel文件
from openpyx1 import load_workbook
wb = load_workbook(filename)
ws = wb.file.active
获取单元格信息 - 获取Cell对象
c = wb[‘sheet’][‘A1’]
c =wb[‘sheet’].cell(row=1,column=1) - c.coordinate:返回单元格坐标。
- c.value:返回单元格的值。
- c.row:返回单元格所在的行坐标。
- c.column:返回单元格所在列坐标。
6.结构化文本文件:PDF
轻松处理pdf文件的库-PyPDF2
- 包含了PdfFileReader、PdfFileMerger、PageObject和PdfFileWriter四个主要类。
- 能进行读写、分割、合并、文件转换等多种操作。
- 只能从PDF文档中提取文本并返回为字符串,而无法提取图像、图表或其他媒体。
- 读取PDF文件:
readFile = open(‘test.pdf’,‘rb’)
pdfFileReader = PdfFileReader(raedFile) - pdfFileReader类
.getNumPages():计算PDF文件总页数。
.getPage(index):检索指定编号的页面。 - PDF文件的写操作
writeFile = ‘output.pdf’
pdfFileWriter = PdfFileWriter() - pdfFileWriter类
.addPage(pageOb):根据每页返回的PageObject,写入到文件。
.addBlankPage():在文件的最后一页后面写入一个空白页,保存到新文件。 - 合并多个文件
pdf_merger = PdfFileMerger()
pdf_merger_append(‘python2018.pdf’)
pdf_mergermerge(20,‘insert.pdf’)
pdf_merger.write(‘merge.pdf’) - 单个页面操作-PageObject类
.extractText():按照顺序提取文本。
.getContents():访问页面内容。
.rotateClockwise(angle):顺时针旋转。
.scale(sx,sy):改变页面大小。
上机实验6.0
1.阶乘累加(n=1~100)各需要多长时间。
2.将一篇文章写入一个文本文件。
3.读出文本文件,统计单词数输出
4.读出文本文件,随机输出其中的10个单词。
简单图形界面模块
1.图形用户界面GUI:
- GUI是人机交互的图形化界面设计,包括展示数据用的小控件、输入的方法、菜单、按钮以及窗口等。
- 用户通过鼠标、键盘等输入设备操纵屏幕上的图标或菜单选项、来执行命令、调用文件、启动程序等日常任务。
2.easygui模块:
- 可以显示各种对话框、文本框、选择框与用户交互。
- 功能演示-easygui.egdemo()
3.easygui常用函数:
- 消息窗口:easygui.mshbox()-显示一条消息和提供一个“ok”按钮。用户可以指定任意的消息和标题,甚至重写“ok”按钮的内容。
- 按钮选项:easygui.choicebox()-为用户提供了一个可选择的列表,使用序列(元组或列表)作为选项。
- 显示文本:easygui.textbox()-用于显示文本类容text参数可以是字符串、列表或者元组类型。
- 输入密码:easygui.passwordbox(-)类似于enterbox(),但是用户输入的内容是用“*”显示出来的。
- 打开文件:easygui.fileopenbox()-返回用户选择的文件名(带完整路径)Default参数指定了一个默认路径。
海龟作图
1.海龟作图:turtle module:
python内置,随时可以使用,其意象为模拟海龟在沙滩上爬行而留下的足迹。
2.turtle模块:
内置模块,从logo语言借鉴而来。
3.属性:
位置、方向、画笔(颜色、线条宽度等)
4.指令:
- 画笔运动命令:前/后移动、左/右移动、作画速度等
- 画笔控制命令:抬起/放下、画笔宽度、画笔颜色、填充颜色等
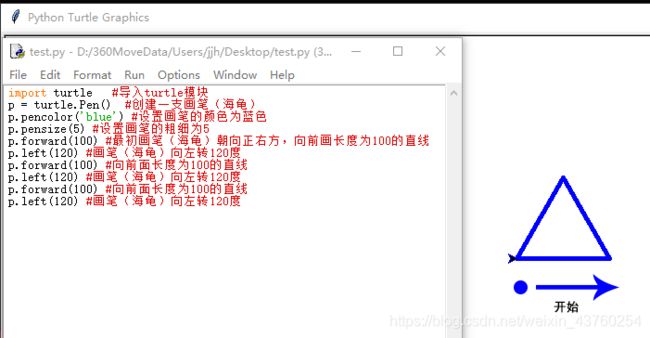
import turtle #导入turtle模块
p = turtle.Pen() #创建一支画笔(海龟)
p.pencolor('blue') #设置画笔的颜色为蓝色
p.pensize(5) #设置画笔的粗细为5
p.forward(100) #最初画笔(海龟)朝向正右方,向前画长度为100的直线
p.left(120) #画笔(海龟)向左转120度
p.forward(100) #向前面长度为100的直线
p.left(120) #画笔(海龟)向左转120度
p.forward(100) #向前面长度为100的直线
p.left(120) #画笔(海龟)向左转120度
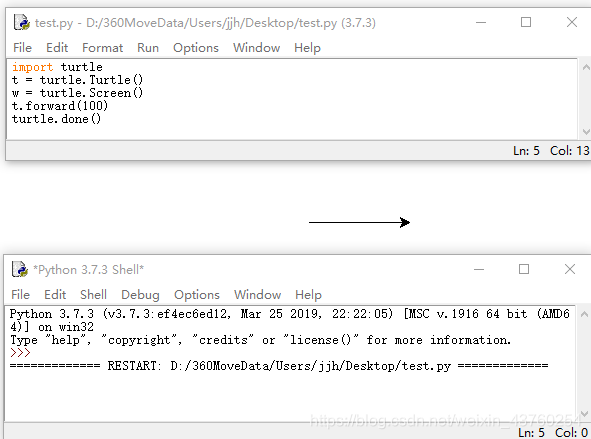
5.画直线
import turtle
t = turtle.Turtle()
w = turtle.Screen()
t.forward(100)
turtle.done()
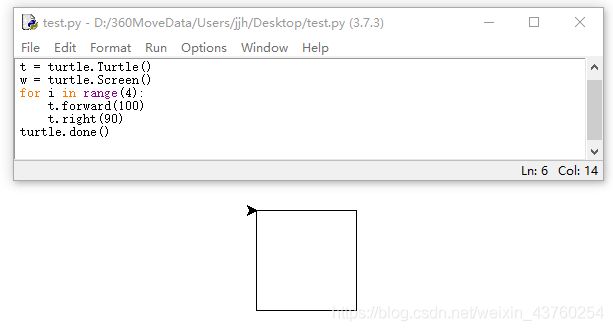
6.画正方形
import turtle
t = turtle.Turtle()
w = turtle.Screen()
for i in range(4):
t.forward(100)
t.right(90)
turtle.done()
7.画多边形
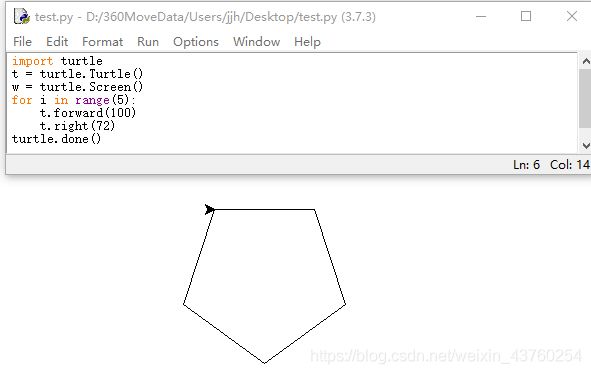
import turtle
t = turtle.Turtle()
w = turtle.Screen()
for i in range(5):
t.forward(100)
t.right(72)
turtle.done()
import turtle
t = turtle.Turtle()
w = turtle.Screen()
for i in range(6):
t.forward(100)
t.right(60)
turtle.done()
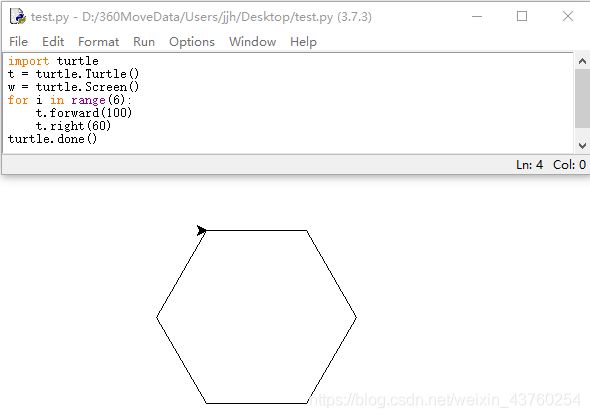
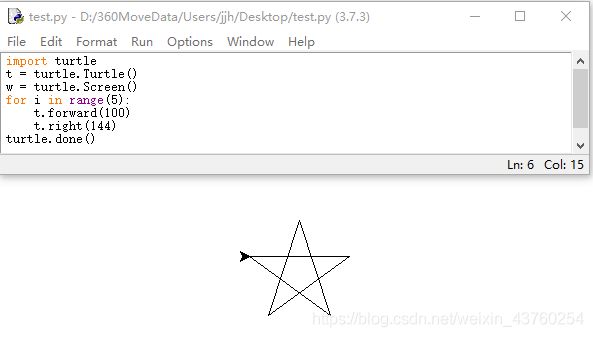
8.画五角星
import turtle
t = turtle.Turtle()
w = turtle.Screen()
for i in range(5):
t.forward(100)
t.right(144)
turtle.done()
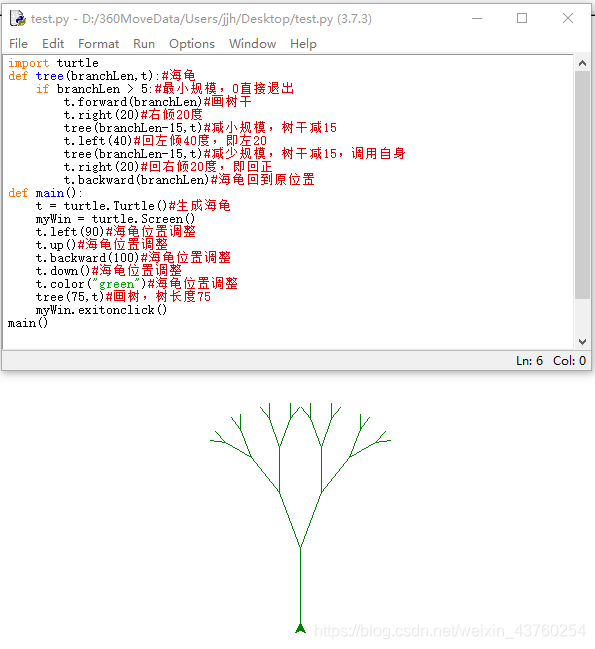
9.调用递归画树
- 分形树:代码
import turtle
def tree(branchLen,t):#海龟
if branchLen > 5:#最小规模,0直接退出
t.forward(branchLen)#画树干
t.right(20)#右倾20度
tree(branchLen-15,t)#减小规模,树干减15
t.left(40)#回左倾40度,即左20
tree(branchLen-15,t)#减少规模,树干减15,调用自身
t.right(20)#回右倾20度,即回正
t.backward(branchLen)#海龟回到原位置
- 分形树:运行
注意海龟作图次序:先画树干、再画右树枝、最后画左树枝:与递归函数里面的流程一致。
def main():
t = turtle.Turtle()#生成海龟
myWin = turtle.Screen()
t.left(90)#海龟位置调整
t.up()#海龟位置调整
t.backward(100)#海龟位置调整
t.down()#海龟位置调整
t.color("green")#海龟位置调整
tree(75,t)#画树,树长度75
myWin.exitonclick()
main()
10.绘制分行图
- 分行的基本概念:部分与整体以某种方式相似的形体。
- 分形学之父:数学家曼德勃罗。
- 分形图:曼德勃罗集
- Hibert 曲线:空间填充曲线,可以线性地贯穿二维或者更高维度的每个离散单元并进行排序和编码。可用于将高维空间中没有良好顺序的数据映射到一维空间。
- 谢尔宾斯基三角形:由3个相同的谢尔宾斯基三角形按照品字形拼叠而成。面积为0,周长趋向于无穷大。我们只能画出维度(degree)有限的近似图形。
上机实验7.0
1.利用turtle模块,进行图形绘制
选择“正方形”,绘制一个边长100的绿色正方形。
选择“五角星”,绘制一个边长为100的红色五角星。
import turtle
p = turtle.Pen()
p.pencolor("green")
p.pensize(5)
for i in range(4):
p.forward(100)
p.right(90)
turtle.done()
import turtle
p = turtle.Pen()
p.pencolor("red")
p.pensize(7)
for i in range(5):
p.forward(100)
p.right(144)
turtle.done()
2.调用turtle模块画一颗树,包括枝干和树叶,并涂上颜色。
import turtle
def tree(branchLen,t):
if branchLen > 5:
t.forward(branchLen)
t.right(20)
tree(branchLen-15,t)
t.left(40)
tree(branchLen-15,t)
t.right(20)
t.backward(branchLen)
def main():
t = turtle.Turtle()
mywin = turtle.Screen()
turtle.bgcolor('lightgrey')
t.left(90)
t.up()
t.backward(100)
t.down()
t.color("green")
tree(75,t)
mywin.exitonclick()
main()
turtle.done()
面向对象.什么是对象?
1.对象的基本概念:
- 万物皆对象,python中所有事物都是以对象形式存在、从简单的数值类型、到复杂的代码模块,都是对象。
- 对象:即表示客观世界问题空间中的某个 具体事物,又表示软件系统解空间中的基本元素。
- 对象 = 属性 +方法:对象以id作为标识,既包含数据(属性),也包含代码(方法),是某一类具体事物的特殊实例。

2.创建对象:
对象是类的实例,是程序的基本单元。
要创建一个新的对象,首先必须定义一个类,用以指明该类型的对象所包含的内容(属性和方法)。
同一类(class)的对象具有相同的属性和方法,但属性值和id不同。
对象的名称
赋值语句给予对象以名称,对象可以有多个名称(变量引用),但只有一个id。
例: a =complex(1,2)
对象实现了属性和方法的封装,是一种数据抽象机制。
提高了软件的重用性、灵活性、扩展性
引用形式
<对象名>.<属性名>
可以跟一般的变量一样用在赋值语句和表达式中。
例:“abc”.upper()
(1+2j).real
(1+2j).imag
python语言动态的特征,使得对象可以随时增加或者删除属性或者方法。
3.面向对象编程
面向对象编程(oop)是一种程序设计范型,同时也是一种程序开发方法。
程序中包含各种独立而又能互相调用对象每个对象都能接受、处理数据并将数据传递给其他对象。
4.传统程序设计
将程序看作一系列函数或指令的集合。
类的定义与调用
1.类是对象的模板,封装了对应现实实体的性质和行为。实例对象是类的具体化。把类比作模具,对象则是用模具制造出来的零件。
2.类的出现,为面向对象编程的三个最重要的特性提供了实现的手段。
封装性、继承性、多态性
和函数相似,类是一系列代码的封装
python中约定,类名用大写字母开头,函数用小写字母开头,以便区分。
3.class语句:
class<类名>:
<一系列方法的调用>
4.类的初始化:
class<类名>
def_init_(self,<参数表>):
def<方法名>(self,<参数表>):
_ init _()是一个特殊的函数名,用于根据类的定义创建实例对象,第一个参数必须为self。
5.调用类:
<类名>(<参数>)
调用类会创建一个对象,(注意括号!)
obj = <类名>(<参数表>)
返回一个对象实例
类方法中的self指这个对象实例!
使用(.)操作符来调用对象里的方法。
t = turtle.Pen()
t.forward(100)6
t.left(90)
类定义的特殊方法
1.特殊方法:
也被称作魔术方法,在类定义中实现一些特殊方法,可以方便地使用python中一些内置操作。
所有特殊方法的名称以两个下划线(_)开始和结束。
2.对象构造器:
_ init _(self,[…)
对象的构造器,实例化对象时调用。
3.析构器
_ del _(sef,[…)
销毁对象时调用。
from os.path import join
class FileObject:
'''给文件对象进行包装从而确认在删除时文件流关闭'''
def_init_(self,filepath='-',filename='sample.txt'):
#读写模式打开一个文件
self.file = open(join(filepath,filename),'r+')
def_del_(self):
self.file.close()
del self.file
4.算术操作符:
_ add _ (self,other):使用+操作符。
_ sub _ (self,other):使用-操作符。
_ mul _ (self,other):使用操作符。
_ div _ (self,other):使用/操作符。
5.反运算:
当左操作数不支持相应的操作时被调用。
_ radd _ (self,other), _ rsub _ (self,other)
6.大小比较:
_ eq _ (self,other):使用==操作符
_ ne _ (self,other):使用!=操作符
_ It _ (self,other):使用<操作符
_ gt _ (self,other):使用>操作符
_ le _ (self,other):使用<=操作符
_ ge _ (self,other):使用>=操作符
7.字符串操作:
不仅数字类型可以使用像+( _ add_())和_(_ sub _())的数学运算符,例如字符串类型可以使用+进行拼接,使用进行复制。
_ str _ (self):自动转化为字符串。
_ repr _ (self):返回一个用来表示对象的字符串。
_ len _ (self):返回元素个数。
其它特殊方法参见python官网。
自定义对象的排序
1.列表排序方法sort():对原列表进行排序,改变原序列内容。如果列表中的元素都是数字,默认升序排序。通过添加参数 reverse= True可改为降序排序。 1.继承:如果一个类别A继承自另一个类别B,就把继承者A称为子类,被继承的类B称为父类、基类、或者超类。 3.父类与子类定义:如果两个类具有“一般”-“特殊”的逻辑关系,那么特殊类就可以作为一般类的“子类”来定义,从“父类”继承属性和方法。 5.关于self: 1.创建一个类People:包含属性name,city、可以转换为字符串形式(str)包含方法moveto(self,newcity)、可以按照city排序、创建4人对象,放到列表进行排序。 1.代码运行可能会意外各种错误:程序的逻辑错误、用户输入不合法等都会引发异常、从而导致程序崩溃。可以利用Python提供的异常处理机制在异常出现时及时捕捉并处理。 针对不同异常可以设置多个except。 如果try语句块运行时没有出现错误,会跳过except语句块执行finally语句块内容。 1.什么是推导式: 1.什么是生成器: 两个数的商:输入两个数,输出它们的商,采用例外处理来处理两种错误,给出用户友好的提示信息 1.Pillow库 1.web应用 4.Flask是一种非常容易上手的python web开发框架。功能非常强大,支持很多专业web开发需要的扩展功能。例如:Facebook认证和数据库集成。只需要具备基本的Python开发技能,就可以开发出一个web应用出来。 5.表单插件Flask-WTF 1.搜索引擎蜘蛛: 返回文档中符合条件的所有tag,是一个列表。 相当于find——all()中limit = 1,返回一个结果 1.numpy矩阵处理库 3.matplotlib绘图库 5.定制线型
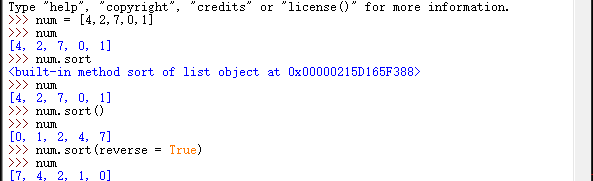
如果元素都是字符串,则会按照字母表顺序排列。

2.通用函数sorted():类似sort(),但返回的是排好序的列表副本,原列表内容不变。

只有当列表中的所有元素都是统一类型的时候sort()和sorted()才会正常工作。
3.特殊方法_ It _:
由于python的可扩展性,每种数据类型可以定义特殊方法:
def_It_(self,y)
返回True视为比y“小”,排在前。
返回False视为比y“大”,排在后。
只要类定义中定义了特殊方法_ It _,任何自定义类都可以使用x类的继承
2.代码复用:利用继承可以从已有类中衍生出新的类、添加或修改部分功能。新类具有旧类中的各种属性和方法,而不需要进行任何复制。class Lar:
def_init_(self,name):
self.name = name
self.remain_mile=0
def fill_fuel(self,miles):#加燃料里程
self.remain_mile = miles
def run(self,miles):#跑miles英里
print(self.name,end=':')
if self.remain_mile >= miles:
self.remain_mile -= miles
print("run %d miles!" %(miles,))
else:
print("fuel out!")
class GasCar(Car):
sef fill_fuel(self,gas):#加汽油gas升
self.remain_mile = gas *6.0#每升跑6英里
class ElecCar(Car):
def fill_fuel(self,power):#充电power度
self.remain_mile = power *3.0#每度电3英里
class<子类名>)<父类名>):
def<重定义方法>(self,…):
4.覆盖:子类对象可以调用父类方法,除非这个方法在子类中重新定义了。如果子类同名方法覆盖了父类的方法,仍然还可以调用父类的方法。
子类还可以添加父类中没有的方法和属性。class GasCar(Car):
def_init_(self,name,capacity):#名称和排量
super()._init_(name)#父类初始化方法,只有名称
self.capacity = capacity#增加了排量属性
在类的定义中,所有方法的首个参数一般都是self。
self的作用:在类内部,实例化过程中传入的所有数据都赋给这个变量,
self实际上代表对象实例。
<对象>.<方法>(<参数>)
等价于:
<类>.<方法>(<对象>,<参数>)上机实验8.0
2.创建一个类Teacher:是People的子类,新增属性school、moveto方法改为newschool、按照school排序、创建4个教师对象,放到列表进行排序。
3.创建一个mylist类,集成自内置数据类型list(列表):增加一个方法“累乘”product、def product(self):返回所有数据项的乘积。例外处理
2.语法错误:SyntaxError
print “Hello world”
3.除以0错误:ZeroDivisionError
4/0
4.列表下标越界:IndexError
alist[1,2,3,4]
alist[4]
5.类型错误:TypeError
mix=[‘zero’,'one,'3,4,5,6,7]
mix.sort()
6.访问变量不存在:NameError
x
7.字典关键字不存在:KeyError
adict = {“A”:1,“B”:2,“C”:3,“D”:4}
adict[“E”]
8.未知变量属性:AttributeError
alist=[1,2,3,4]
alist.sorted()
以上这些错误会引起程序中止退出,如果希望掌控意外,就需要在可能出现错误的地方设置陷阱捕捉错误。
9.捕捉错误:
try:
<检测语句>
except<错误类型>[as e]:
<处理异常>
try:#为缩进的代码设置陷阱
except:#处理错误代码
try:
<检测语句>
except<错误类型>[as e]:
<处理异常>
finally:
<语句块>
finally:#无论出错否,都有执行的代码
try:
<检测语句>
except <错误类型>[as e]:
<处理异常>
else:
<语句块>
else:#没有出错执行的代码
推导式
推导式是从一个或者多个迭代器快速简洁地创建数据结构的一种方法。
将循环和条件判断结合,从而避免语法冗长的代码。
可以用来生成列表、字典和集合。
2.列表推导式:
[<表达式> for <变量> in <可迭代对象> if <逻辑条件>]
3.字典推导式:
[<建筑表达式> : <元素表达式> for <变量> in <可迭代对象> if <逻辑条件>]
3.集合推导式:
{<元素表达式> for <变量> in <可迭代对象> if <逻辑条件>}
4.与推导式一样的语法:
(<元素表达式> for <变量> in <可迭代对象> if <逻辑条件>)
返回一个生产器对象,也是可迭代对象。
但生成器并不立即产生全部元素,仅在要用到元素的时候才生成,可以极大节省内存。
除了通过生成器推导式创建生成器,还可以使用生成器函数。生成器函数
1.生成器是用来创建数据序列一种对象。
2.使用它可以迭代庞大的序列,且不需要在内存中创建和存储整个序列
3.通常生成器是为迭代器产生数据的。
生成器是迭代器的一种实现。
2.生成器函数:
1.如果要创建一个比较大的序列,生成器推导式将会比较复杂,一行表达式无法容纳,这时可以定义生成器函数。
2.生成器函数与普通函数:
yield:立刻返回一个值,下一次迭代生成器函数时,从yield语句后的语句继续执行,直到再次yield返回,或终止。
return:终止函数的执行,下次调用会重新执行函数。
3.协同程序:
可以运行的独立函数调用,函数可以暂停或挂起,并在需要的时候从离开的地方继续或重新开始。
例:函数even_number返回一个生成器对象。def even——number(max):
n=0
while n <max:
yield n
n +=2
for i in even_number(10):
printf(i)
上机实验9.0
1.除数为0。
2.输入了非数值。
编写一个推导式,生成包含100以内所有勾股数(i,j,k)的列表。
编写一个生成器函数,能够生成斐波那契数列
斐波那契数列:由前两项数列得第三项。图像处理库
Python里的图像处理库
PIL:Python Image Library
功能强大,可以对图像做各种处理,包括缩放、裁剪、旋转、滤镜、文字、调色板等等。
2.图像处理步骤
(1)打开图像:image.open(<路径+图像名+文件格式>):Pillow库能自动根据文件内容确定格式,若图片在程序目录下,则不需要附带路径,直接将图像名+文件格式作为参数。
(2)处理图像:image模块中提供了大量处理图像的方法。
(3)存取或显示图像:
in.show()
im.save(<文件名>)
3.PIL图像操作:缩略图
thumbnail函数:thumbnail(size,Image.ANTIALIAS) 参数size为一个元组,指定生成缩略图的大小。直接对内存中的原图进行修改,但是修改后的图片需要保存,处理后的图片不会被拉伸。
4.小程序:PIL生成验证码from PIL import Image, ImageFont, ImageDraw, ImageFilter
import random
# 绘制验证码
img = Image.new('RGB', (200, 100), color='White')
draw_obj = ImageDraw.Draw(img)
def get_color():
#生成随机颜色
return random.randint(0, 255), random.randint(0, 255), random.randint(0, 255)
def get_char():
# 生成随机数字或字母的组合
import string
return random.choice(string.ascii_letters+string.digits)
for i in range(200):
for j in range(100):
draw_obj.point((i, j), fill=get_color())
font = ImageFont.truetype('C:\\Windows\\Fonts\\phagspab.ttf', 60)
for i in range(4):
draw_obj.text((i * 50, random.randint(0,50)), text=get_char(), font=font, fill=random.choice(['red','blue','yellow','black']))
# 加干扰线-随机加50条干扰线
for i in range(50):
draw_obj.line((random.randint(0,200),random.randint(0,100),random.randint(0,200),random.randint(0,100)),fill='black')
img.filter(ImageFilter.EMBOSS)
img.show()
web服务框架
web应用已经成为目前最热门的应用软件形式。
web应用通过web服务器提供服务,客户端采用浏览器或者尊徐HTTP协议的客户端。
用于需要处理HTTP传输协议,很多web开发框架涌现。
2.什么是框架
web服务器会处理与浏览器客户端交互的HTTP协议具体细节,但对具体内容的处理还需要自己编写代码。一个web框架至少要具备处理浏览器客户端请求和服务器响应能力。
3.框架的特性
框架可能具备这些特性中的一个或多种。
一个web服务器测试:
在浏览器中访问http://127.0.0.1:5000/(本机端口)这个服务器会返回一行文字。from flask import Flask
app = Flask( _ name _ )
@app.route("/")
def hello():
return"hello world!"
if_ name _ =="_ main _":
app.run()
使用Flask-WTF时,每个表单都抽象成一个类。网络爬虫
爬虫是按照一定的规则,自动地提取并保存网页中信息的程序。
蜘蛛沿着网络抓取猎物,通过一个节点之后,顺着该节点的连线继续爬行到下一个节点,最终爬完整个网络的全部节点。
通过向网站发起请求获取资源,提取其中有用的信息。
2.requests库:
Python实现的一个简单易用的HTTP库。支持HTTP持久连接和连接池、SSL证书验证、cookies处理、流式上传等。
向服务器发起请求并获取响应,完成访问网页的步骤。
简洁、容易理解,是最友好的网络爬虫库。
3.requests库-http请求类型
requesrs.
返回的是一个response对象
4.requests库-response对象
包含服务器返回的所有信息,l如状态码、编码形式、文本内容等:也包含请求的request信息。
.status_code:HTTP请求的返回状态。
.text:HTTP响应内容的二进制形式。
.content:HTTP响应内容的二进制形式。
.encoding:(从HTTP header中)分析响应内容的编码方式。
.apparent_encoding:(从内容中)分析响应内容的编码方式。
5.定制请求头
requests的请求接口有一个名为headers的参数,向它传递一个字典来完成请求头定制。
6.设置代理:
一些网站设置了同一IP访问次数的限制,可以在发送请求时指定proxies参数来替换代理,解决这一问题。
7.Beautiful Soup
使用requests库下载了网页并转换成字符串后,需要一个解析器来处理HTML和XML,解析页面格式,提取有用的信息。
解析器
使用方法
优势
python标准库
BeautifulSoup(markup,“html.parser”)
Pythond 内置标准库、文档容错能力强
lxml HXML解析器
BeautifulSoup(markup,“lxml”)
Pythond 内置标准库、文档容错能力强
lxml XML解析器
BeautifulSoup(markup,[“lxml-xml”])BeautifulSoup (markup,“xml” )
速度快、唯一支持xml的解析器
Html5lib
BeautifulSoup(markup,“html5lib”)
最好的容错性、以浏览器的方式解析文档
find_all(name,attrs,recursive,string,**kwargs)
find(name,attrs,recursive,string,**kwargs)
name:对标签名称的检索字符串。
attrs:对标签属性值的检索字符串。
recursive:是否对子节点全部检索,默认为True。
string:<>…中检索字符串。
**kwargs:关键词参数列表。
8.爬虫的基本流程
数据可视化
numpy是python用于处理大型矩阵的一个速度极快的数学库。可以做向量和矩阵的运算,包括各种创建矩阵的方法,以及一般的矩阵运算、求逆、求转置。
它的很多底层的函数都是用c写的,可以得到普通python中无法达到的运行速度。
2.numpy方法
创建矩阵 a = np.matrix([])
矩阵求逆 a.I
矩阵转置 a.T
矩阵乘法 a*b或np.dot(a,b)
np.shape:数组形状,矩阵则为n行m列。
np.size:对象元素的个数。
np.dtype:指定当前numpy对象的整体数据。
matplotlib是python的一个绘图库。它包含了大量的工具,可以使用这些工具创建各种图形。
python科学计算社区经常使用它完成数据可视化的工作。
4.绘制函数图像基本思路
通过将图像上一些点的坐标连接起来,即可绘制函数的近似图像,当点越多时,所绘图像接近函数图像。
numpy.linspace(, ,)
生成一个存放等差数列的数组,数组元素为浮点型,脑哈姆三个参数,分别是:数列起始值、终止值(默认包含自身)、数列元素个数。
可以设定图形颜色、线条线型、以及做标注等。
plot()函数的绘制样式参数表示。
颜色
表示方法
颜色
表示方法
blue
‘b’
yellow
‘y’
cyan
‘c’
white
‘w’
green ‘g’
red
‘r’
black
‘k’
magenta
‘m’
线型
表示方法
点型
表示方法
实线
-
圆形
o
短线
- -
叉
x、+
短点相同线 -.
三角形
^、v、<、>
虚电线
:
五角星
*