202011-202012面试总结
一
1.总结一下你比较突出的项目
根据自身情况而定
2.tcp 三次握手四次断开 并且每次发送数据包是什么 以及tcp是什么状态
参考
tcp三次握手
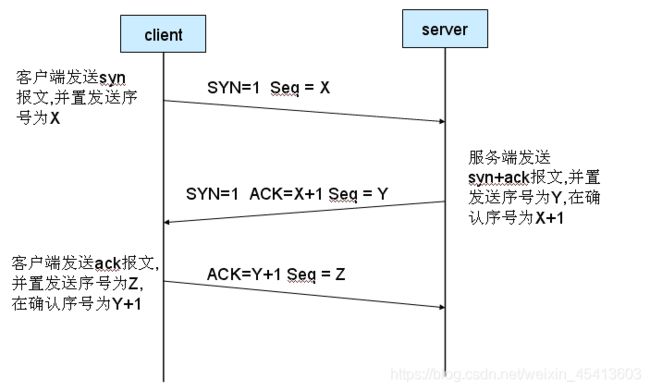
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接,如图1所示。
(1) 第一次握手:建立连接时,客户端A发送SYN包(SYN=j)到服务器B,并进入SYN_SEND状态,等待服务器B确认。
(2) 第二次握手:服务器B收到SYN包,必须确认客户A的SYN(ACK=j+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,此时服务器B进入SYN_RECV状态。
(3) 第三次握手:客户端A收到服务器B的SYN+ACK包,向服务器B发送确认包ACK(ACK=k+1),此包发送完毕,客户端A和服务器B进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据。
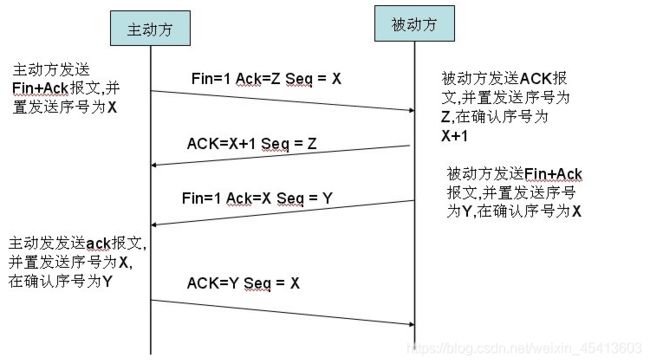
tcp四次断开
3.pod的创建过程
用户通过 REST API 创建一个 Pod
apiserver 将其写入 etcd
scheduluer 检测到未绑定 Node 的 Pod,开始调度并更新 Pod 的 Node 绑定
kubelet 检测到有新的 Pod 调度过来,通过 container runtime 运行该 Pod
kubelet 通过 container runtime 取到 Pod 状态,并更新到 apiserver 中

1.k8s高可用架构 是怎样的 包括api 以及调度器控制器怎么工作
这里master 有api-server 以及scheduler 和controller ,一般我们做的高可用只是针对api会做负载轮询调度 也就是说在api的上层通过lb来做代理,scheduler以及controller都是一个工作其余沉睡 ,如果工作的挂掉了 ,那么沉睡的会被唤醒 也只会唤醒一个,这里具体是etcd中会有一把锁 scheduler和controller会watch这把锁 watch到的就会开始工作 ,没有watch到的就会持续watch。
2.deployment 会有rs 那么 rs里面会有pod pod 最后名称的哈希值是怎么计算的 为什么扩缩容的时候原有的pod 最后的后缀哈希值不会变 但是我滚动更新的时候就会发生变化
这个没回答上来
3.deployment跟sts有什么本质的区别
deployment无序 sts是有序的 并且pv pvc也会略有不同 deployment pod公用一个 sts每个pod一个
4.怎么样控制不同部门的管理(这里结合config 跟rbac)
通过rbac给用户授权 不同的用户对应不同的权限 clusterrolebinding clusterrole 以及role rolebinding
5.那么说一下controller的 源码架构 是怎样的
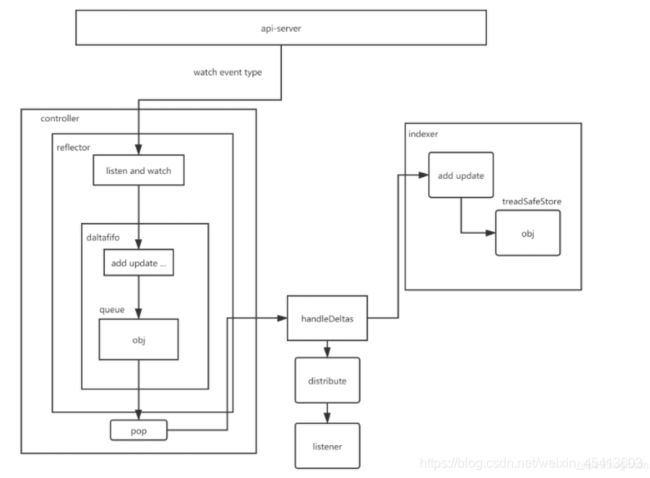
手绘图 以及描述工作流程
https://blog.csdn.net/weixin_45413603/article/details/107217076
6.informer 承担了一个什么样的角色
7yaml 中会影响调度器的调度 的字段有哪些
亲和度
nodename
nodeselector
污点容忍度
request
8.request跟limit 有什么本质的区别
request会影响调度
limit会影响pod被kill掉
9.存活检查跟就绪检查有什么区别
存活失败会导致pod重启
就绪失败在svc的ep上不会有pod ip也就是说不会给pod引入流量
10.前面你说到了request 会影响到调度器 也就是说预分配 需要满足才可以调度那么 他怎么去判断节点是否满足条件
你在describe可以看到node的一些基础信息,他是通过这个来判断 用
总内存- system预留-kube预留-pod已经使用 = 可用
以及limit会不会作为判断的一个标准
limit不会影响调度
11.hpa 自定义以及k8s自带的 也就是v1 v2版本
hpa基于内存cpu 那么如何能自定义指标
自定义需要用到prome的指标结合adapter
12.informer里面有什么
informer的架构 这里可以看一下
https://blog.csdn.net/weixin_45413603/article/details/107995986
13 如果写了nodename 那么调度过程会不会走调度器
不会
1.prometheus 的架构
alertmanager 报警
webhook对接语音钉钉或者企业微信
grafana图表展示
prometheus 数据处理
exporter 数据收集agent
2.你基于prometheus 怎么去做的 项目方面怎么做的监控
redis cluster
es cluster
基础服务器以及k8s服务器
3.prometheus 你开发过什么
webhook and exporter
4.nginx 的log 只要404 状态码 的用户请求uri 然后我只要前10
这里主要是结合cat grep awk sort uniq -c
5. elk的常见架构 以及es的集群联邦
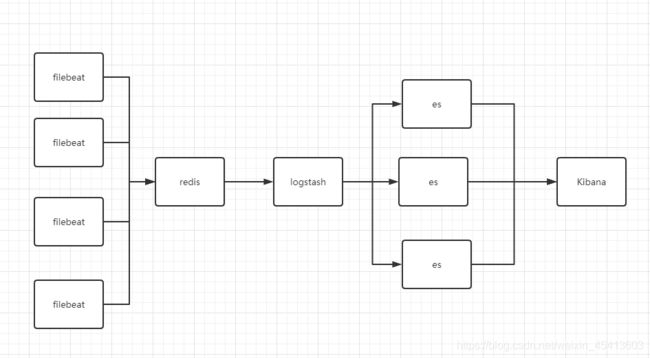
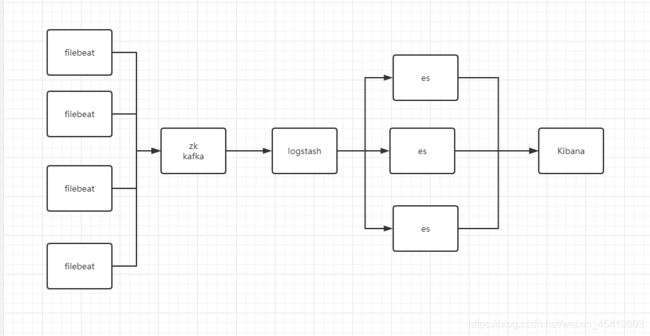
6.prometheus 的集群
prometheus集群主要是围绕多个prometheus共享一个tsdb 来做,但是数据量特别大之后特别消耗内存,这也只是解决了高可用问题
7.2xx 3xx 4xx 5xx 首先你怎么理解 状态码 200 正确 3xx重定向 4xx请求类 5xx 服务端错误
8.prometheus 遇到过瓶颈么怎么处理的
目前没有 但是量大了内存消耗会很高
9.prometheus 你的数据量大概有多少
目前中间件部分 一个月30g k8s集群具体没细看
10.接着前面的elk常见架构 的话
我回答说可以借助redis 或者kafka 以及zk 那么这两个架构的区别在哪里
redis是一个内存行 如果突增或者数据量大了 可能内存打满挂机 导致数据丢失
zk kafka是队列
11.容器cni flannel calico 做namespace隔离 那么核心是canel 他的核心处理是怎么做的隔离 能做什么隔离
这块没有怎么回答 就是可以做ns的隔离以及黑白名单
12.pod一直处于CrashLoopBackOff需要进去调试
这个可以使用ephemeralcontainers临时容器
https://kubernetes.io/zh/docs/concepts/workloads/pods/ephemeral-containers/
或者在高版本k8s使用k8s-debug
1.prometheus 可以通过信号reload 配置文件也可以通过接口reload配置文件 但是当数据量特别大的时候 reload如果需要10分钟以上 数据会出现断层 那么这个有没有什么好的处理方式,以及prometheus 启动过程中 携程处理 这块涉及到了 prometheus的启动流程的携程组 加载方式
2.如果容器没有bash 或者sh 也就是说没有解释器 那么我怎么进入容器
function e() {
set -u
ns=${
2-"default"}
container_id=`kubectl -n $ns describe pod $1 | grep -Eo 'docker://.*$' | head -n 1 | awk -F '//' '{print $2}'`
if [ "$container_id" != "" ]
then
echo "container_id:$container_id"
pid=`docker inspect -f {
{
.State.Pid}} $container_id`
echo "pid:$pid"
echo "enter pod netns successfully for $ns/$1"
nsenter -n --target $pid
fi
}
3.在容器启动失败以后无限重启 怎么进入容器排查问题
没回答上来
4.然后就是基于k8s的污点以及亲和度问了一些问题
亲和度用的特别多以后有什么影响
对于调度器消耗会特别大
5.k8s使用grpc协议有没有什么弊端
没回答上来我对grpc不是很了解 我就知道他是http链接复用
二
1.linux oom
Linux有一个特性:OOM Killer,一个保护机制,用于避免在内存不足的时候不至于出现严重问题,把一些无关的进程优先杀掉,即在内存严重不足时,系统为了继续运转,内核会挑选一个进程,将其杀掉,以释放内存,缓解内存不足情况,不过这种保护是有限的,不能完全的保护进程的运行。
该问题是low memory耗尽,因为内核使用low memory来跟踪所有的内存分配。
当low memory耗尽,不管high memory剩多少,oom-killer都会杀死进程,以保持系统的正常运行。
2.proc跟内核的关联
/proc目录是系统模拟出来的一个文件系统,本身并不存在于磁盘上,其中的文件都表示内核参数的信息,这些信息分两类,一类是可都可写的,这类参数都在“/proc/sys”目录下,另一类是只读的,就是“/proc/sys”目录之外的其他目录和文件,当然这只是一种惯例,实际在其他目录下建立可读写的/proc文件也是可以的。
3.cpu使用率 cpu负载理解
平均负载(load average)是指某段时间内占用cpu时间的进程和等待cpu时间的进程数,这里等待cpu时间的进程是指等待被唤醒的进程,不包括处于wait状态进程。
cpu使用率反映的是当前cpu的繁忙程度,忽高忽低的原因在于占用cpu处理时间的进程可能处于io等待状态但却还未释放进入wait。
4.tcp timewait
参考
https://cloud.tencent.com/developer/article/1589962
https://zhuanlan.zhihu.com/p/101702312
通信双方建立TCP连接后,主动关闭连接的一方就会进入TIME_WAIT状态。
客户端主动关闭连接时,会发送最后一个ack后,然后会进入TIME_WAIT状态,再停留2个MSL时间(后有MSL的解释),进入CLOSED状态。
下图是以客户端主动关闭连接为例,说明这一过程的。
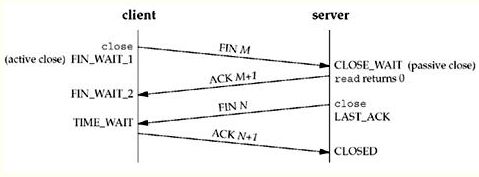
TCP/IP协议就是这样设计的,是不可避免的。主要有两个原因:
1)可靠地实现TCP全双工连接的终止
TCP协议在关闭连接的四次握手过程中,最终的ACK是由主动关闭连接的一端(后面统称A端)发出的,如果这个ACK丢失,对方(后面统称B端)将重发出最终的FIN,因此A端必须维护状态信息(TIME_WAIT)允许它重发最终的ACK。如果A端不维持TIME_WAIT状态,而是处于CLOSED 状态,那么A端将响应RST分节,B端收到后将此分节解释成一个错误(在java中会抛出connection reset的SocketException)。
因而,要实现TCP全双工连接的正常终止,必须处理终止过程中四个分节任何一个分节的丢失情况,主动关闭连接的A端必须维持TIME_WAIT状态 。
2)允许老的重复分节在网络中消逝
TCP分节可能由于路由器异常而“迷途”,在迷途期间,TCP发送端可能因确认超时而重发这个分节,迷途的分节在路由器修复后也会被送到最终目的地,这个迟到的迷途分节到达时可能会引起问题。在关闭“前一个连接”之后,马上又重新建立起一个相同的IP和端口之间的“新连接”,“前一个连接”的迷途重复分组在“前一个连接”终止后到达,而被“新连接”收到了。为了避免这个情况,TCP协议不允许处于TIME_WAIT状态的连接启动一个新的可用连接,因为TIME_WAIT状态持续2MSL,就可以保证当成功建立一个新TCP连接的时候,来自旧连接重复分组已经在网络中消逝。
5.tcp状态有哪些
CLOSED: 这个没什么好说的了,表示初始状态。
LISTEN: 这个也是非常容易理解的一个状态,表示服务器端的某个SOCKET处于监听状态,可以接受连接了。
SYN_RCVD: 这个状态表示接受到了SYN报文,在正常情况下,这个状态是服务器端的SOCKET在建立TCP连接时的三次握手会话过程中的一个中间状态,很短暂,基本上用netstat你是很难看到这种状态的,除非你特意写了一个客户端测试程序,故意将三次TCP握手过程中最后一个ACK报文不予发送。因此这种状态时,当收到客户端的ACK报文后,它会进入到ESTABLISHED状态。
SYN_SENT: 这个状态与SYN_RCVD遥想呼应,当客户端SOCKET执行CONNECT连接时,它首先发送SYN报文,因此也随即它会进入到了SYN_SENT状态,并等待服务端的发送三次握手中的第2个报文。SYN_SENT状态表示客户端已发送SYN报文。
ESTABLISHED:这个容易理解了,表示连接已经建立了。
FIN_WAIT_1: 这个状态要好好解释一下,其实FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。而这两种状态的区别是:FIN_WAIT_1状态实际上是当SOCKET在ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET即进入到FIN_WAIT_1状态。而当对方回应ACK报文后,则进入到FIN_WAIT_2状态,当然在实际的正常情况下,无论对方何种情况下,都应该马上回应ACK报文,所以FIN_WAIT_1状态一般是比较难见到的,而FIN_WAIT_2状态还有时常常可以用netstat看到。
FIN_WAIT_2:上面已经详细解释了这种状态,实际上FIN_WAIT_2状态下的SOCKET,表示半连接,也即有一方要求close连接,但另外还告诉对方,我暂时还有点数据需要传送给你,稍后再关闭连接。
TIME_WAIT: 表示收到了对方的FIN报文,并发送出了ACK报文,就等2MSL后即可回到CLOSED可用状态了。如果FIN_WAIT_1状态下,收到了对方同时带FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。
6.503 502的区别
502 Bad Gateway错误、504 Bad Gateway timeout 网关超时 可能是web服务器故障、程序进程不够
501 服务器不具备完成请求的功能。例如,服务器无法识别请求方法时可能会返回此代码。
503 服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态。(服务不可用)
505 服务器不支持请求中所用的 HTTP 协议版本。(HTTP 版本不受支持)
7.进程线程区别
进程
一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。
线程
进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。
与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
区别
线程具有许多传统进程所具有的特征,故又称为轻型进程(Light—Weight Process)或进程元;而把传统的进程称为重型进程(Heavy—Weight Process),它相当于只有一个线程的任务。在引入了线程的操作系统中,通常一个进程都有若干个线程,至少包含一个线程。
根本区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位
资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行
8.虚拟内存如何分配
只有实际使用的进程才会分配物理内存 虚拟内存是物理内存的映射
详解请看https://blog.csdn.net/weixin_45413603/article/details/110334598
三
1.一台服务器16g内存 那么用了8g 有4g的cache 剩余4g 能否启动一个jvm为6的java程序
2.目前阿里云rds是做的对原ip放行策略 也就是针对微服务所在服务器ip放行 那么会导致 比如说 我1程序 只需要访问1程序的数据库那么2数据库也给1数据库放行了 这个怎么做限制 现在很不安全
部署pod的时候使用node亲和度锁定一批节点
3.yaml如果服务数量上了200 很难管理这个的话有没有什么好的方法
这里主要是helm 的chart包管理方式
4.那么举个例子哈 java应用有jvm min根max 那么每个程序都不太一样 如果是你200个服务你怎么去做这块的限制 就是更方便的去做 不需要每个都去修改
给开发提供一个规范让开发去遵守
1.你对运维这个职业怎么理解
2.公司内部有开发有项目经理甚至我们公司还有艺术家这么多种的职位 你觉得运维部门怎么样能够实现部门的价值
3.而且你在这个团队中你怎么实现你的价值呢
4.你觉得一个团队的氛围应该是什么样子或者说你期望什么样的团队氛围
这些是价值观问题需要根据个人理解来回答
1.2层跟3层如何寻址
二层局域网寻址过程:
在局域网内部用广播寻址
寻址基于广播
如果局域网里的一台电脑要发信息给另一台主机
先进行寻址 寻址的方法就是向网络发送一个广播
网络里的主机和网关都能接收到信息
如果主机比对发现数据包是发给它的
就会把自己的mac地址回复给发广播的主机
当拿到目标的MAC地址后
下次通信将发送具体数据包给网卡已经固化的主机
(在数据包的包头里面固化mac地址)
只能目标主机才能接收到数据包 比较自己网卡的mac地址和发来的数据包的地址 匹配一致就接收数据包
补充:mac地址是48位二进制数的字符串,6个字节,用冒号分割,前三个字节是厂家ID,后三个字节是设备ID)
三层网络寻址过程:
本机发送数据包,在本网段没有发现目标主机,就会发给网关设备
在这里,本机是不知道自己网段的网关的mac地址的,首先进行二层寻址,前面我们已经知道,网关设备也会接收到广播,所有设备都会比对,网关设备对比确定MAC地址后,发现是发给自己的数据包,就会给本机返回数据包。第二次发送数据包会在IP头加上目标的IP,MAC头写上本地网关的ip地址,通过HUB或者交换机把数据包转发给网关,网关接收来自一个网络接口的数据包,根据其中所含的目的IP地址。再进行路由和转发。
2.1个vlan 有多少个vlanid
交换机一般可以划分255个vlan,每个vlan的id,可以是1~4094之间的任意数字。 所以用户在VLAN ID输入框位置输入从 1 到bai 4094 之间的一个 VLAN ID 编号即可。
3.在linux上使用docker 能否跑win容器
不能