数据分析实战(二) 基于美国人口adult数据集R语言分析实战
目录
-
-
-
- 一、数据集介绍
- 二、数据预处理
- 三、描述型统计分析
- 四、机器学习及模型比较
-
-
一、数据集介绍
数据来源于UCI数据库,网址为adult数据集(下载下来是dat文件,可以用txt文本打开)。该数据集共32560条数据,15个变量,具体变量名及含义如下表所示。
| 变量名 | 含义 | 类型 |
|---|---|---|
| age | 年龄 | 数值型 |
| workclass | 工作类型 | 类别型 |
| fnlwgt | 编号 | 数值型 |
| education | 受教育程度 | 类别型 |
| education.num | 受教育时间 | 数值型 |
| marital.status | 婚姻状况 | 类别型 |
| occupation | 职位 | 类别型 |
| relationship | 家庭关系 | 类别型 |
| race | 种族 | 类别型 |
| sex | 性别 | 类别型 |
| capital.gain | 资本收益 | 数值型 |
| capital.loss | 资本损失 | 数值型 |
| hours.per.week | 每周工作小时 | 数值型 |
| native.country | 原籍 | 类别型 |
| class | 收入阶层 | 类别型(>50K和<50K) |
二、数据预处理
(1) 数据读取
setwd("C:/Users/dell/Desktop")
rm(list=ls())
#读取数据
adult<-read.table("adult.txt",header=T,sep=",")
#添加变量名
colname<-c("age","workclass","fnlwgt","education","education.num",
"marital.status","occupation","relationship",
"race","sex","capital.gain","capital.loss","hours.per.week",
"native.country","class")
colnames(adult)<-colname
#连续变量
varcontinue <- c("age","fnlwgt","education.num","capital.gain","capital.loss","hours.per.week")
#连续变量转化为数值型并与因子型变量合并
adult <- cbind(lapply(adult[,varcontinue],function(x) as.numeric(as.character(x))),adult[,setdiff(colname,varcontinue)])
str(adult) #查看各变量类型
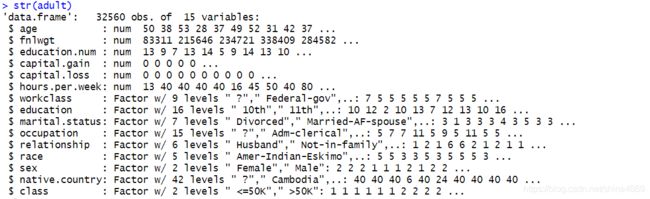
为方便后续分析,各类别型变量已转为因子型。
(2) 缺失值识别
sum(is.na(adult)) #查看缺失值情况
#尝试观察是否存在非NA型缺失值
table(adult$workclass)
table(adult$occupation)
table(adult$native.country)

首先,对原数据集利用is.na函数判断是否存在NA型缺失值,结果发现并没有。但是,从workclass、occupation、native.country这三个因子型变量的统计来看,都含有"?"。故需要将其转化为R语言能够识别的缺失值,并对其删除。
(3) 缺失值处理
#将原数据的问号替换为缺失值,注意问号前有1个空格
adult$workclass[adult$workclass==" ?"]<-NA
adult$occupation[adult$occupation==" ?"]<-NA
adult$native.country[adult$native.country==" ?"]<-NA
#观察是否替换成功
table(adult$workclass)
table(adult$occupation)
table(adult$native.country)
#删除缺失值,生成新数据
adult1<-na.omit(adult)
print(nrow(adult)) #原数据总条数
print(nrow(adult1)) #现数据总条数
print(nrow(adult)-nrow(adult1)) #缺失值条数

从上图可知,?已完全删除。删除缺失值后,查看新的数据总条数如下所示

从结果来看,缺失值共2399条。
三、描述型统计分析
以下以收入阶层class为研究中心,探究不同因素下群体收入是否存在显著差异。
(1) 探究不同教育程度的收入等级差异
library(ggplot2)
library(Rmisc) # multiplot(多图绘制)
# 封装绘图函数
# data:数据源,xlab:x轴数据,fillc:填充颜色,pos:调整位置,xname:x轴标签文本,yname:y轴标签文本
fun_bar <- function(data, xlab, fillc, pos, xname, yname) {
ggplot(data, aes(xlab, fill = fillc)) +
geom_bar(position = pos) +
labs(x = xname, y = yname) +
coord_flip() + # 使图形倒置
theme_minimal() # ggplot图形的一种背景主题
}
## 探索不同教育程度的群体的收入等级(pos=‘stack’指定使用堆积条形图)
p1 <- fun_bar(data = adult1, xlab = adult1$education, fillc = adult1$class,
pos = 'stack', xname = 'education', yname = 'count')
## 探索不同教育程度的群体的收入等级(pos=‘fill’指定使用百分比堆积条形图)
p2 <- fun_bar(data = adult1, xlab = adult1$education, fillc = adult1$class,
pos = 'fill', xname = 'education', yname = 'per count')

从图中来看,学历对收入阶层的影响的确是有一定作用。例如,对于硕士(master)和博士(Doctorate)来说,收入>50K的群体明显要多一些。此外,还有Prof-school(专门学院)大部分群体工资也都在50K以上。(主要培养职业型人才,一开始我以为是技校hhh。百度才知道这种学院出来的人才是社会的精英,具备高薪和崇高的社会地位)
(2) 探索受教育年限对收入的影响
p3 <- fun_bar(data = adult1, xlab = adult1$education.num, fillc = adult1$class,
pos = 'stack', xname = 'education.num', yname = 'count')
p4 <- fun_bar(data = adult1, xlab = adult1$education.num, fillc = adult1$class,
pos = 'fill', xname = 'education.num', yname = 'per count')
multiplot(p3,p4,cols = 1)

不难看出,受教育年限越长,收入>50k的群体占比越大。
(3) 探究婚姻状况对收入的影响
p5 <- fun_bar(data = adult1, xlab = adult1$marital.status, fillc = adult1$class,
pos = 'stack', xname = 'marital.status', yname = 'count')
p6 <- fun_bar(data = adult1, xlab = adult1$marital.status, fillc = adult1$class,
pos = 'fill', xname = 'marital.status', yname = 'per count')
multiplot(p5, p6,cols = 1)
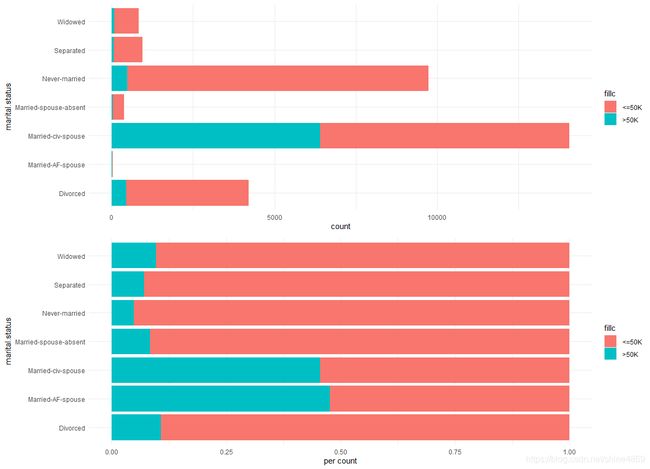
可以发现,married-civ-spouse(已婚平民配偶)和married-AF-spouse(已婚军属)类型的收入>50k群体占比大。
(4) 探究性别、年龄、受教育年限、每周工作时间与收入关系
bar_sex <- fun_bar(data = adult1, xlab = adult1$sex, fillc = adult1$class,
pos = 'fill', xname = 'sex', yname = 'per count')
box_age <- ggplot(adult1, aes(x = class, y = age ,fill = class))+
geom_boxplot()+theme_bw()+labs(x = 'class', y = 'age')
box_edu <- ggplot(adult1, aes(x = class, y = education.num ,fill = class))+
geom_boxplot()+theme_bw()+labs(x = 'class', y = 'education.num')
box_work <- ggplot(adult1, aes(x = class, y = hours.per.week ,fill = class))+
geom_boxplot()+theme_bw()+labs(x = 'class', y = 'hours.per.week')
multiplot(bar_sex,box_age, box_edu, box_work, cols = 2)

从图中大致可以发现,收入高的群体一般男性居多、年龄较大、每周工作时间较长、受教育年限较长。
四、机器学习及模型比较
(1) 构建训练集和测试集
train=sample(1:nrow(adult1),0.7*nrow(adult1))
adult1_train <- adult1[train,]
adult1_test <- adult1[-train,]
(2) 随机森林分析
library(randomForest)
library(caret) # confusionMatrix
#建立随机森林模型进行预测,并可视化重要变量
set.seed(1234)
#首先在训练集上训练,并剔除序号fnlwgt变量
rf_model <- randomForest(class ~.-fnlwgt, data = adult1_train, importance =T)
pred_rf <- predict(rf_model, adult1_train, type = 'class')
varImpPlot(rf_model) #绘制变量重要性曲线
confusionMatrix(pred_rf, adult1_train$class) #混淆矩阵
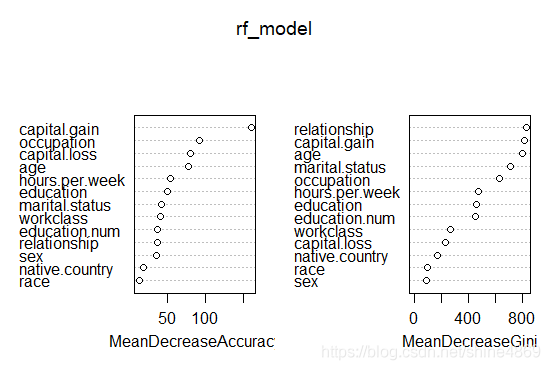
左图显示的是平均减少的准确率,右图显示的是平均减少的基尼系数。以左图为例,其中每个点即代表移除相应的特征后平均减少的准确率,故越高的变量越重要。不难看出,caption.gain(资本增值)、occpation(职业)较为重要。输出的混淆矩阵如下所示:
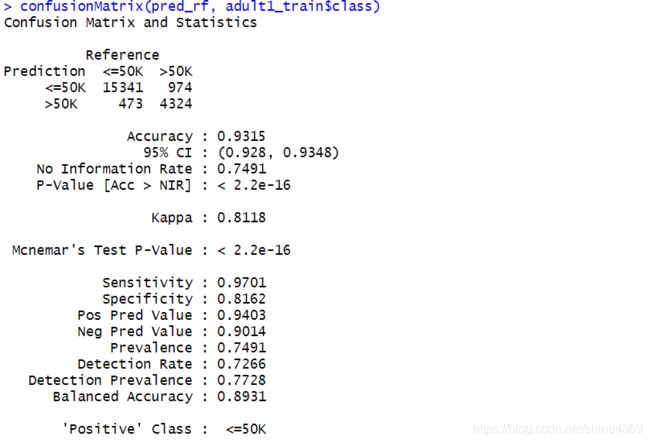
从结果不难看出,随机森林在训练集上准确率为93.15%,共有15341+4324个样本判断正确,473+974个样本判断错误。
以下,再在测试集上进行验证:
pred_rf_test <- predict(rf_model, adult_test, type = 'class')
confusionMatrix(pred_rf_test, adult1_test$class)

在测试集上准确率为86.27%,共有6347+1460个样本判断正确,750+492个样本判断错误。
(3) SVM分析
library(kernlab) # ksvm()
library(caret) # confusionMatrix
# 建立支持向量机模型(kernel='rbfdot'指定使用径向基函数)
set.seed(1234)
#剔除变量fnlwgt,在训练集上训练
svm_model <- ksvm(class ~.-fnlwgt, data = adult1_train, kernel = 'rbfdot')
pred_svm <- predict(svm_model, adult1_train, type = 'response')
confusionMatrix(pred_svm, adult1_train$class)
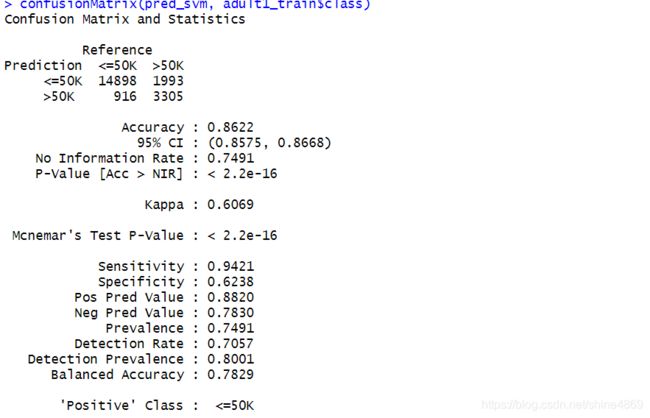
SVM在训练集上准确率为86.22%,共有14898+3305个样本判断正确,1933+916个样本判断错误。
以下,再在测试集上进行验证:
pred_svm_test <- predict(svm_model, adult1_test, type = 'response')
confusionMatrix(pred_svm_test, adult1_test$class)

SVM在测试集上准确率为85.74%,共有6402+1357个样本判断正确,437+853个样本判断错误。
(4) 模型比较(ROC曲线)
单从准确率的角度来看,随机森林的确要高一些,但在训练集和测试集上的准确率差别相比SVM在训练集和测试集的准确率差别更大一些。以下,将从ROC曲线的角度来判断两者模型优劣。
library(pROC)
#roc()函数适用于数值型数据,所以需要数据类型转换
red_rf_test<-as.numeric(pred_rf_test)
pred_svm_test<-as.numeric(pred_svm_test)
adult1_test$class <-as.numeric(adult1_test$class)
par(mfrow=c(1,2))
roc(pred_rf_test,adult1_test$class, plot=TRUE, print.thres=TRUE, print.auc=TRUE,main="随机森林ROC")
roc(pred_svm_test,adult1_test$class, plot=TRUE, print.thres=TRUE, print.auc=TRUE,main="支持向量机ROC")
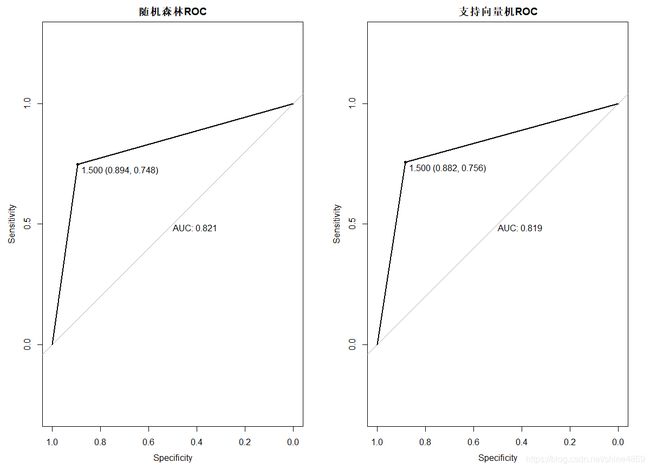
从AUC的值来看,随机森林较SVM稍好一点,但相差并不大。