通过Python爬取必应壁纸,学XPath
前言
在上一篇文章中讲述了如何使用XPath来提取数据,那么这篇文章就紧随其后,来教各位小伙伴如何使用XPath进行实战,获取网页的信息。
所以我今天带来的内容就是获取必应壁纸。
准备工作
工欲善其事,必现利其器。玩爬虫也是同样的道理。
首先,安装好两个库:lxml与requests。
pip install lxml
pip install requests
需求分析
爬取的网址:https://bing.ioliu.cn/
抓包分析
首先打开开发者工具,随便点击一张图片进入它的高清大图,点击network进行抓包,在点击图片的下载按钮。

点击下载按钮之后,你会发现,浏览器向图中的网址发起了请求,点击进去之后发现这个就是高清图片的链接地址。
从而我们的第一个需求就是获取所有图片的链接地址。
获取图片链接
为什么要获取图片链接呢?
首先,你思考一下,每一张图片你都要点击下载按钮来将图片保存到本地吗?如果你不懂爬虫那当然没有办法了。但是,我们懂爬虫的人还会这么干吗?
既然每一次点击下载按钮,浏览器都是向对应的高清大图发起请求,那么也就是说我们可以获取到所有的图片链接,然后利用Python模拟浏览器向这些链接发起请求,即可下载这些图片。
链接如下:
https://h2.ioliu.cn/bing/LoonyDook_ZH-CN1879420705_1920x1080.jpg?imageslim
关于翻页
打开网页之后,你会发现起码有100页的图片。那这100页的图片怎么样获取呢?
很简单,依然还是先分析每一页的URL地址,看看有没什么变化规律。
# 第二页
https://bing.ioliu.cn/?p=2
# 第三页
https://bing.ioliu.cn/?p=3
其实看到上面的URL变化之后,我想你也应该明白了变化的规律了吧。
功能实现
构造每一页的链接
其实就是实现简单的翻页功能。
具体代码示例如下所示:
def get_page_url():
page_url = []
for i in range(1,148):
url = f'https://bing.ioliu.cn/?p={i}'
page_url.append(url)
return page_url
上面代码的功能是构造每一页的链接。将链接保存在page_url中。
获取每一页中的图片链接
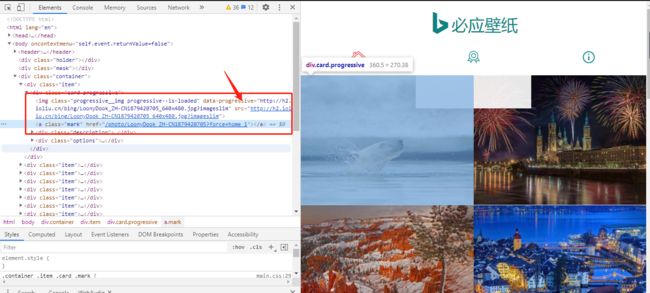
在上图中你会发现,图片的链接就藏在了data-progressive里面,这不就是img标签的属性吗?有何难?
但是细心的朋友就会发现,这个链接和我们最开始抓包的链接是不一样的,到底哪里不一样呢?
我们来具体看看
https://h2.ioliu.cn/bing/LoonyDook_ZH-CN1879420705_1920x1080.jpg?imageslim
http://h2.ioliu.cn/bing/LoonyDook_ZH-CN1879420705_640x480.jpg?imageslim
发现了吗?分辨率是不一样的。其他都相同的,那只要将分辨率替换掉就可以了呀。
具体代码如下所示:
def get_img_url(urls):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
}
img_urls = []
count = 1
for url in urls[:3]:
time.sleep(5)
text = requests.get(url, headers=headers).content.decode('utf-8')
html = etree.HTML(text)
img_url = html.xpath('//div[@class="item"]//img/@data-progressive')
img_url = [i.replace('640x480', '1920x1080') for i in img_url]
print(f'正在获取第{count}页链接')
img_urls.extend(img_url)
count += 1
return img_urls
上面的代码是获取每一页的图片链接,将链接保存在img_urls中。
保存图片
def save_img(self, img_urls):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
}
count = 1
for img_url in img_urls:
content = requests.get(img_url, headers=headers).content
print(f'正在下载第{count}张')
with open(f'../image/{count}.jpg', 'wb') as f:
f.write(content)
count += 1
保存图片的代码还是比较简单的,可以将获取到的所有图片链接作为参数传进来,进行逐个访问,即可。
最后
本次分享到这里就结束了,如果你读到了这里,那说明本篇文章对你还是有所启发的,这也是我分享的初衷。
路漫漫其修远兮,吾将上下而求索。
我是啃书君,一个专注于学习的人,你懂的越多,你不懂的越多。更多精彩内容,我们下期再见!