pandas-task-special.md
文章目录
- 【任务一】企业收入的多样性
-
- 【题目描述】一个企业的产业收入多样性可以仿照信息熵的概念来定义收入熵指标:
-
- 连接方法1
- 连接方法2
- 【任务二】组队学习信息表的变换
-
- 【题目描述】请把组队学习的队伍信息表变换为如下形态,其中“是否队长”一列取1表示队长,否则为0
- 解决方案
- 【任务三】美国大选投票情况
-
- 【题目描述】两张数据表中分别给出了美国各县(county)的人口数以及大选的投票情况,请解决以下问题:
【任务一】企业收入的多样性
【题目描述】一个企业的产业收入多样性可以仿照信息熵的概念来定义收入熵指标:
![]()
其中 p(xi)是企业该年某产业收入额占该年所有产业总收入的比重。在company.csv中存有需要计算的企业和年份,在company_data.csv中存有企业、各类收入额和收入年份的信息。现请利用后一张表中的数据,在前一张表中增加一列表示该公司该年份的收入熵指标 I。
df1 = pd.read_csv('./data/task_special/company.csv')
df2 = pd.read_csv('./data/task_special/company_data.csv')
df1.head(3)
表一
| 证券代码 | 日期 | |
|---|---|---|
| 0 | #000007 | 2014 |
| 1 | #000403 | 2015 |
| 2 | #000408 | 2016 |
表二
| 证券代码 | 日期 | 收入类型 | 收入额 | |
|---|---|---|---|---|
| 0 | 1 | 2008/12/31 | 1 | 1.08422e+10 |
| 1 | 1 | 2008/12/31 | 2 | 1.25979e+10 |
| 2 | 1 | 2008/12/31 | 3 | 1.45131e+10 |
下面是我的解题过程。
第一步是按照证券代码对两表进行连接操作,不过两个表的证券代码格式不一致,表一的是object个数,形式为”#00数字“的格式,表二是int型数字。我们需要统一。
连接方法1
方法一:将 df1的证券代码转为数字,再进行连接。
将复杂的形式简化比较简单,不过看了下题目是需要将指标增加在表一,因此尽可能不要改动表一比较好,于是我将表二改动以适应表一。
df1['证券代码']=[int(str(i).split('#')[-1]) for i in df1['证券代码']]
df1.merge(df2,on='证券代码',how='left').head(3)
连接结果
| 证券代码 | 日期_x | 日期_y | 收入类型 | 收入额 | |
|---|---|---|---|---|---|
| 0 | 7 | 2014 | 2008/12/31 | 1 | 8.63e+06 |
| 1 | 7 | 2014 | 2008/12/31 | 2 | 4.25842e+06 |
| 2 | 7 | 2014 | 2008/12/31 | 3 | 1.06108e+08 |
连接方法2
#连接方法2 df2的证券代码加上#和0
code_len=6
df2['证券代码']=['#'+(code_len-len(str(i)))*str(0)+
str(i) for i in df2['证券代码']]
df1.merge(df2,on='证券代码',how='left').head(3)
连接后
| 证券代码 | 日期_x | 日期_y | 收入类型 | 收入额 | |
|---|---|---|---|---|---|
| 0 | #000007 | 2014 | 2008/12/31 | 1 | 8.63e+06 |
| 1 | #000007 | 2014 | 2008/12/31 | 2 | 4.25842e+06 |
| 2 | #000007 | 2014 | 2008/12/31 | 3 | 1.06108e+08 |
连接后我又陷入了迷茫,这咋俩日期还不一致呢?不要慌,让我们打印一下具体情况,表二证券代码是从7号的,我们就打印下表二7号证券代码的数据。
df2.loc[df2['证券代码']==7]

好家伙,有356行数据,而且日期是从2008到2016这么多。我们再看看一共有多少种日期。
df2.loc[df2['证券代码']==7]['日期'].unique()
>>>输出为
array(['2008/12/31', '2009/12/31', '2010/12/31', '2011/12/31',
'2012/12/31', '2013/12/31', '2014/12/31', '2015/12/31',
'2016/12/31'], dtype=object)
一共九种日期,日期是从08-16年每年最后一天。好了这下大概理解题意了。
结果还是理解错了题意。。。不过做到最后一步才发现,将错就错了。重要的是知识点的掌握,后续再完善。
- 我们要找表一证券代码对应表二证券代码的所有数据
- 同一证券代码再去找表一对应年限的收入额,汇总收入额
- 2的结果和该证券代码对应所有年限的收入额进行一些计算。
现在我们完成了1,继续完成2,3。
任务2.同一证券代码再去找表一对应年限的收入额,汇总收入额。
首先我们将刚刚通过证券代码连接的表记为df3,再将日期_y也就是原表二的日期只保留年份,方便和表一的日期对比。
df3['日期_y']=[i.split('/')[0] for i in df3['日期_y']]
更新完日期后的表3前五行
| 证券代码 | 日期_x | 日期_y | 收入类型 | 收入额 | |
|---|---|---|---|---|---|
| 0 | #000007 | 2014 | 2008 | 1 | 8.63e+06 |
| 1 | #000007 | 2014 | 2008 | 2 | 4.25842e+06 |
| 2 | #000007 | 2014 | 2008 | 3 | 1.06108e+08 |
| 3 | #000007 | 2014 | 2008 | 4 | 1.54509e+07 |
| 4 | #000007 | 2014 | 2008 | 5 | 2.08143e+07 |
接着我们分别计算同一证券代码和该证券代码下指定日期的收入总和以及同一证券代码所有日期的的收入总和。自然而想到分组求和。
同一证券代码和该证券代码下指定日期的收入总和
res1=df3.groupby(['证券代码','日期_x'])['收入额'].agg([('single_sum','sum')]).reset_index()
res1.head(5)
| 证券代码 | 日期_x | single_sum | |
|---|---|---|---|
| 0 | #000007 | 2014 | 2.05236e+10 |
| 1 | #000403 | 2015 | 6.24456e+10 |
| 2 | #000408 | 2016 | 6.51739e+10 |
| 3 | #000408 | 2017 | 6.51739e+10 |
| 4 | #000426 | 2015 | 8.72652e+10 |
同一证券代码所有日期的的收入总和
| 证券代码 | all_sum | |
|---|---|---|
| 0 | #000007 | 2.05236e+10 |
| 1 | #000403 | 6.24456e+10 |
| 2 | #000408 | 1.30348e+11 |
| 3 | #000426 | 2.61796e+11 |
| 4 | #000511 | 1.95463e+11 |
最后就只剩3. 将2的结果和该证券代码对应所有年限的收入额进行一些计算。
res=res1.merge(res2,on=['证券代码'],how='left')
res.head(5)
| 证券代码 | 日期_x | single_sum | all_sum | |
|---|---|---|---|---|
| 0 | #000007 | 2014 | 2.05236e+10 | 2.05236e+10 |
| 1 | #000403 | 2015 | 6.24456e+10 | 6.24456e+10 |
| 2 | #000408 | 2016 | 6.51739e+10 | 1.30348e+11 |
| 3 | #000408 | 2017 | 6.51739e+10 | 1.30348e+11 |
| 4 | #000426 | 2015 | 8.72652e+10 | 2.61796e+11 |
计算每行的熵
res['entropy']=[ -(i/j)*math.log2((i/j)) for i,j in
zip(res.single_sum,res.all_sum)]
df1['entropy']=res['entropy']
df1.head(5)
| 证券代码 | 日期 | entropy | |
|---|---|---|---|
| 0 | #000007 | 2014 | -0 |
| 1 | #000403 | 2015 | -0 |
| 2 | #000408 | 2016 | 0.5 |
| 3 | #000408 | 2017 | 0.5 |
| 4 | #000426 | 2015 | 0.528321 |
【任务二】组队学习信息表的变换
【题目描述】请把组队学习的队伍信息表变换为如下形态,其中“是否队长”一列取1表示队长,否则为0

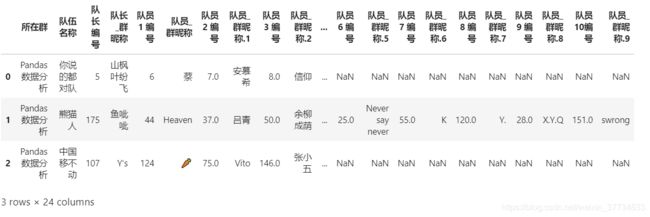
首先看下原表格样式
df=pd.read_excel('./data/task_special/组队信息汇总表(Pandas).xlsx')
df.head(3)
解决方案
这个题拿到手想了很久宽表转换成长表,但是怎么想都不对,因为题目要求的转换后数据数量就不一样,而长宽表的相互转换是只改变形式不改变数量和数值的。
对第一行数据去除空值后看下
df.loc[0].dropna().to_markdown()
| 0 | |
|---|---|
| 所在群 | Pandas数据分析 |
| 队伍名称 | 你说的都对队 |
| 队长编号 | 5 |
| 队长_群昵称 | 山枫叶纷飞 |
| 队员1 编号 | 6 |
| 队员_群昵称 | 蔡 |
| 队员2 编号 | 7.0 |
| 队员_群昵称.1 | 安慕希 |
| 队员3 编号 | 8.0 |
| 队员_群昵称.2 | 信仰 |
| 队员4 编号 | 20.0 |
| 队员_群昵称.3 | biubiu |
回顾之前的作业想到有类似的操作。
每个队伍的人数都不同,因此将每个队伍的信息抽取出来整理,然后加入列表,最后将这些信息合并。下面是我的主要代码:
L=[]
team_num=len(df)
cols=['是否队长','队伍名称','昵称','编号']
for i in range(team_num):
df1=df.loc[i].dropna()
team_mem=int((len(df1)-2)/2)
for i in range(team_mem):
#是否队长
if i == 0:
L.append(pd.DataFrame([1,df1[1],df1[3+2*i],
df1[3+2*i-1]]).T)
else:
L.append(pd.DataFrame([0,df1[1],df1[3+2*i],
df1[3+2*i-1]]).T)
res = pd.concat(L)
res.index=[i for i in range(len(res))]
res.columns=cols
res.tail(5)
看下最后几列,现在已经满足条件了。
| 是否队长 | 队伍名称 | 昵称 | 编号 | |
|---|---|---|---|---|
| 141 | 0 | 七星联盟 | Daisy | 63 |
| 142 | 0 | 七星联盟 | One Better | 131 |
| 143 | 0 | 七星联盟 | rain | 112 |
| 144 | 1 | 应如是 | 思无邪 | 54 |
| 145 | 0 | 应如是 | Justzer0 | 58 |
打印下自己小队的嘿嘿。
| 是否队长 | 队伍名称 | 昵称 | 编号 | |
|---|---|---|---|---|
| 125 | 1 | Attention!keep干饭 | 阿芒Aris | 21 |
| 126 | 0 | Attention!keep干饭 | Alex | 152 |
| 127 | 0 | Attention!keep干饭 | Jie | 95 |
| 128 | 0 | Attention!keep干饭 | 梦想家 | 104 |
【任务三】美国大选投票情况
【题目描述】两张数据表中分别给出了美国各县(county)的人口数以及大选的投票情况,请解决以下问题:
- 有多少县满足总投票数超过县人口数的一半
- 把州(state)作为行索引,把投票候选人作为列名,列名的顺序按照候选人在全美的总票数由高到低排序,行列对应的元素为该候选人在该州获得的总票数
# 此处是一个样例,实际的州或人名用原表的英语代替
拜登 川普
威斯康星州 2 1
德克萨斯州 3 4
- 每一个州下设若干县,定义拜登在该县的得票率减去川普在该县的得票率为该县的BT指标,若某个州所有县BT指标的中位数大于0,则称该州为Biden State,请找出所有的Biden State
时间不够充裕,第三题待思考。