回顾总结
1.分布式思想
- 分布式计算
说明: 一项任务由多个服务器共同完成的.
例子: 假设一项任务单独完成需要10天,如果有10个人同时执行则一天完成. 大数据处理技术. - 分布式系统
说明: 将项目按照特定的功能模块及层级进行拆分.从而降低整个系统架构的耦合性问题. - 核心:无论将来项目怎么拆分,都是同一个系统. 口诀: 对外统一,对内相互独立
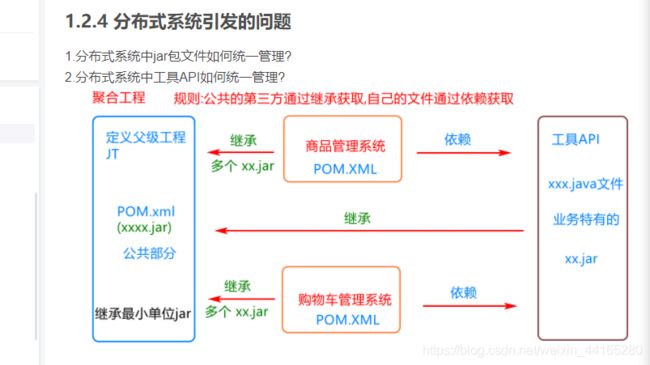
打包方式: pom 表示:该项目是一个聚合工程,里边包含了很多的小项目,并且该项目可以统一管理公共的jar包文件.
- POJO 与数据库映射的实体类对象
- VO : 数据展现层的对象 主要与页面JS进行数据交互的媒介
2.什么是json?

3.注解的作用?
- @RestController 返回值都是JSON数据
- @Component 将对象交给spring容器管理
- @Aspect 标识我是一个切面
- @RequestMapping 映射访问的路径
- @Controller 代表这个类会被spring接管,被注解的类中的所有方法,如果返回值是string,并且有具体页面可以跳转,那么就会被试图解释器解析
- @PathVariable 是用来对指定请求的URL路径里面的变量
4.CRUD
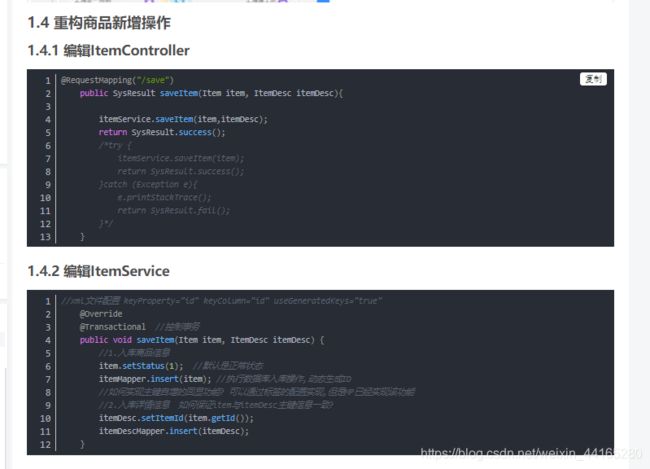
4.1 商品新增
4.2 商品修改
{
text:'编辑',
iconCls:'icon-edit',
handler:function(){
//获取用户选中的数据
var ids = getSelectionsIds();
if(ids.length == 0){
$.messager.alert('提示','必须选择一个商品才能编辑!');
return ;
}
if(ids.indexOf(',') > 0){
$.messager.alert('提示','只能选择一个商品!');
return ;
}
//需要找到一个空的div之后展现窗口
$("#itemEditWindow").window({
onLoad :function(){
//回显数据
var data = $("#itemList").datagrid("getSelections")[0];
data.priceView = KindEditorUtil.formatPrice(data.price);
//将data的数据回显到修改页面中.
$("#itemeEditForm").form("load",data);
.....
}



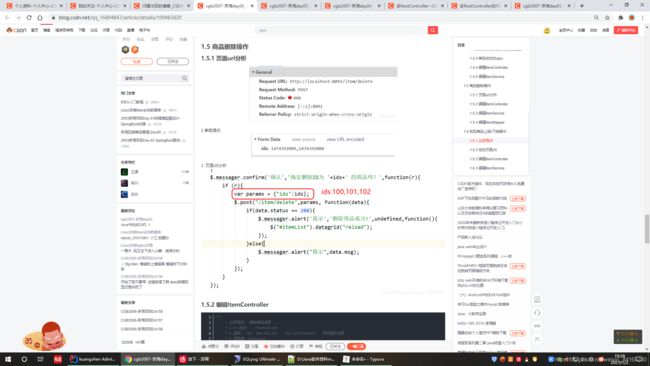
4.3 商品删除操作
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jt.mapper.ItemMapper">
<!--
Mybatis数据传参的原理:
规则: Mybatis只能接收单值传参!!!
如果有多个数据需要传值,则需要将多值封装为单值
方式:
1.利用对象传参
2.利用数组传参
3.利用Map集合传参
集合的写法:
数据类型是数组 collection="array"
数据类型是list集合 collection="list"
数据类型是Map集合 collection="map的key"
ids=100,101,102
collection: 获取传递集合的key
open="集合遍历前缀"
close="集合遍历后缀"
separator="分隔符"
item="当前遍历的对象"
-->
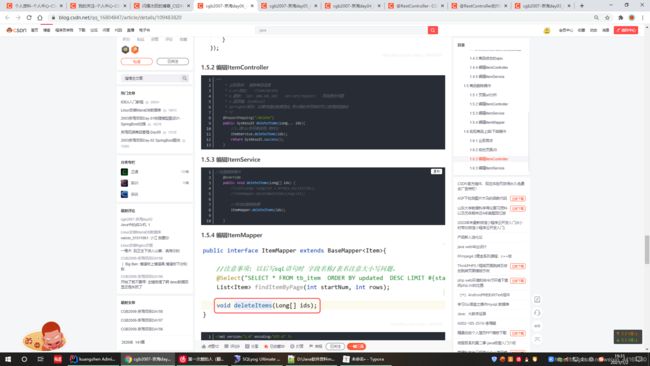
<delete id="deleteItems" >
DELETE FROM tb_item WHERE id in (
<foreach collection="array" item="id" separator=",">
#{
id}
</foreach>
)
</delete>
</mapper>
4.3.1 重构商品删除
编辑ItemService
//批量删除操作
@Override
@Transactional
public void deleteItems(Long[] ids) {
List<Long> longList = Arrays.asList(ids);
//itemMapper.deleteBatchIds(longList);
//手动的删除数据
itemMapper.deleteItems(ids);
itemDescMapper.deleteBatchIds(longList);
}
4.3.2 京淘购物车业务实现
4.3.3 实现购物车删除操作
4.3.4 业务分析
需求: 当用户点击页面删除按钮时,应该删除后端数据库记录,同时应该重定向到购物车列表页面.

编辑CartController
/**
* 完成购物车删除操作
* 1.url地址: http://www.jt.com/cart/delete/562379.html
* 2.请求参数: 562379 itemId /userId
* 3.返回值结果: 重定向到系统首页
*/
@RequestMapping("/delete/{itemId}")
public String deleteCarts(Cart cart){
long userId = 7L;
cart.setUserId(userId);
cartService.deleteCarts(cart);
return "redirect:/cart/show.html";
}
编辑CartService
@Override
public void deleteCarts(Cart cart) {
cartMapper.delete(new QueryWrapper<>(cart));
}
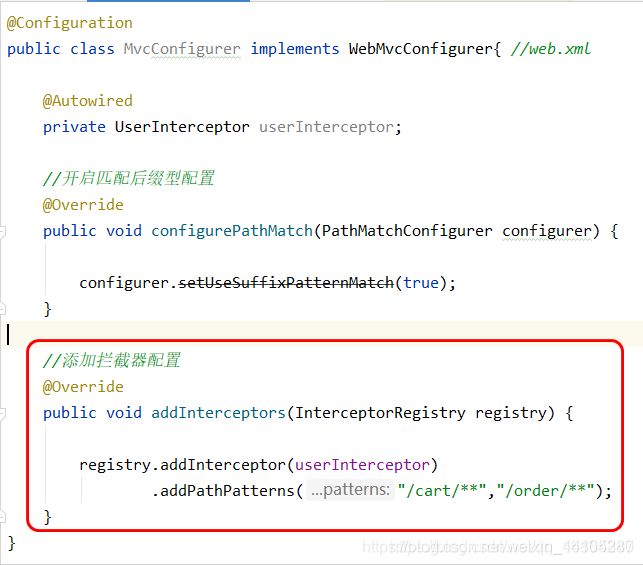
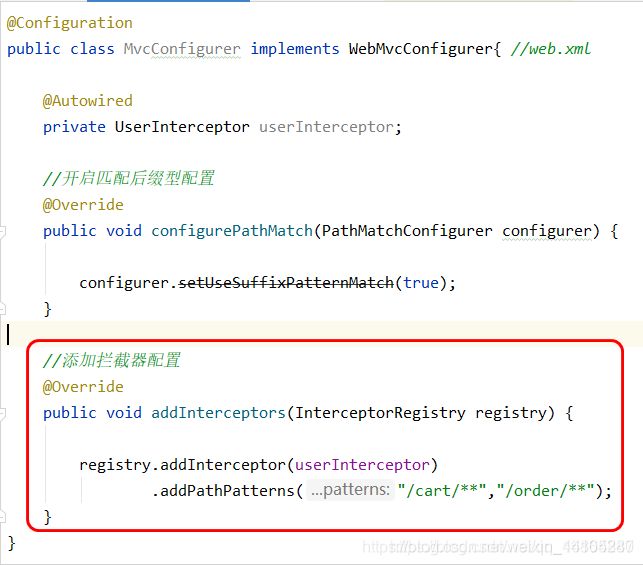
4.3.5 购物车权限控制
需求说明
当用户在没有登录的条件下不允许访问敏感业务. 购物车操作/订单操作等. 如何实现???
答:使用拦截器的机制
4.3.6 编辑配置类
4.3.7 编辑拦截器
package com.jt.interceptor;
import com.jt.util.CookieUtil;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import org.springframework.web.servlet.HandlerInterceptor;
import redis.clients.jedis.JedisCluster;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@Component //将拦截器交给spring容器管理
public class UserInterceptor implements HandlerInterceptor {
private static final String JT_TICKET="JT_TICKET";
@Autowired
private JedisCluster jedisCluster;
/**
* 返回值说明:
* 1.false 表示拦截 一般都要配合重定向的方式使用.
* 2.true 表示放行
*
* 如何实现业务:
* 判断用户是否登录: Cookie数据 检查redis中的数据.
* 重定向到系统登录页面.
*
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//1.校验Cookie中是否有结果
Cookie cookie = CookieUtil.getCookie(request, JT_TICKET);
//2.校验Cookie是否有效
if(cookie != null){
String ticket = cookie.getValue();
if(StringUtils.hasLength(ticket)){
//执行后续任务 校验redis中是否有结果
if(jedisCluster.exists(ticket)){
//表示用户登录过 直接返回true
return true;
}
}
//没有结果,则cookie数据有误,应该删除
CookieUtil.addCookie(response, JT_TICKET, "", "/", "jt.com", 0);
}
//3.如果数据为空,则重定向到系统首页
response.sendRedirect("/user/login.html");
return false; //表示拦截....
}
}
4.4 ThreadLocal介绍
名词解释: 本地线程变量
工作原理
作用: 在线程内部(一个线程)实现数据的共享.
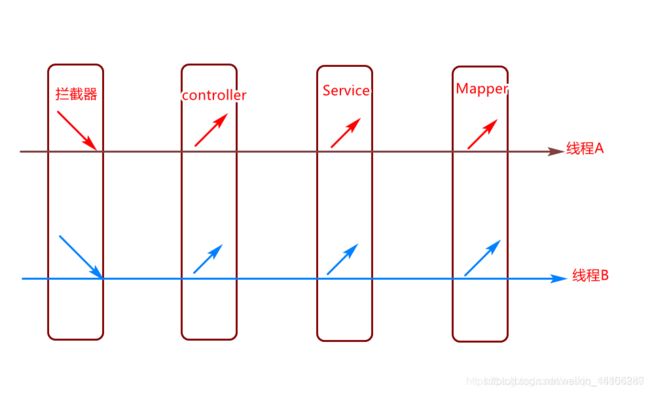
ThreadLocal工具API编辑
package com.jt.util;
import com.jt.pojo.User;
public class UserThreadLocal {
private static ThreadLocal<User> threadLocal = new ThreadLocal<>();
public static void setUser(User user){
threadLocal.set(user);
}
public static User getUser(){
return threadLocal.get();
}
public static void remove(){
threadLocal.remove();
}
}
重构拦截器
package com.jt.interceptor;
import com.jt.pojo.User;
import com.jt.util.CookieUtil;
import com.jt.util.ObjectMapperUtil;
import com.jt.util.UserThreadLocal;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import org.springframework.web.servlet.HandlerInterceptor;
import redis.clients.jedis.JedisCluster;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@Component //将拦截器交给spring容器管理
public class UserInterceptor implements HandlerInterceptor {
private static final String JT_TICKET="JT_TICKET";
@Autowired
private JedisCluster jedisCluster;
/**
* 返回值说明:
* 1.false 表示拦截 一般都要配合重定向的方式使用.
* 2.true 表示放行
*
* 如何实现业务:
* 判断用户是否登录: Cookie数据 检查redis中的数据.
* 重定向到系统登录页面.
*
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//1.校验Cookie中是否有结果
Cookie cookie = CookieUtil.getCookie(request, JT_TICKET);
//2.校验Cookie是否有效
if(cookie != null){
String ticket = cookie.getValue();
if(StringUtils.hasLength(ticket)){
//执行后续任务 校验redis中是否有结果
if(jedisCluster.exists(ticket)){
String json = jedisCluster.get(ticket);
User user = ObjectMapperUtil.toObject(json,User.class);
//利用Request对象将数据进行传递 最为常见的参数传递的方式
request.setAttribute("JT_USER", user);
//ThreadLocal机制
UserThreadLocal.setUser(user);
//表示用户登录过 直接返回true
return true;
}
}
//没有结果,则cookie数据有误,应该删除
CookieUtil.addCookie(response, JT_TICKET, "", "/", "jt.com", 0);
}
//3.如果数据为空,则重定向到系统首页
response.sendRedirect("/user/login.html");
return false; //表示拦截....
}
//为了防止内存泄露,将多余的数据删除
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
//移除request对象
request.removeAttribute("JT_USER");
//移除threadLocal数据
UserThreadLocal.remove();
}
}
4.5 用户登录
4.5.1 单点登录业务实现
单点登录(SingleSignOn,SSO),就是通过用户的一次性鉴别登录。当用户在身份认证服务器上登录一次以后,即可获得访问单点登录系统中其他关联系统和应用软件的权限,同时这种实现是不需要管理员对用户的登录状态或其他信息进行修改的,这意味着在多个应用系统中,用户只需一次登录就可以访问所有相互信任的应用系统。这种方式减少了由登录产生的时间消耗,辅助了用户管理,是目前比较流行

实现步骤:
1.用户输入用户名和密码之后点击登录按钮开始进行登录操作.
2.JT-WEB向JT-SSO发送请求,完成数据校验
3.当JT-SSO获取数据信息之后,完成用户的校验,如果校验通过则将用户信息转化为json.并且动态生成UUID.将数据保存到redis中. 并且返回值uuid.
如果校验不存在时,直接返回"不存在"即可.
4.JT-SSO将数据返回给JT-WEB服务器.
5.如果登录成功,则将用户UUID保存到客户端的cookie中.
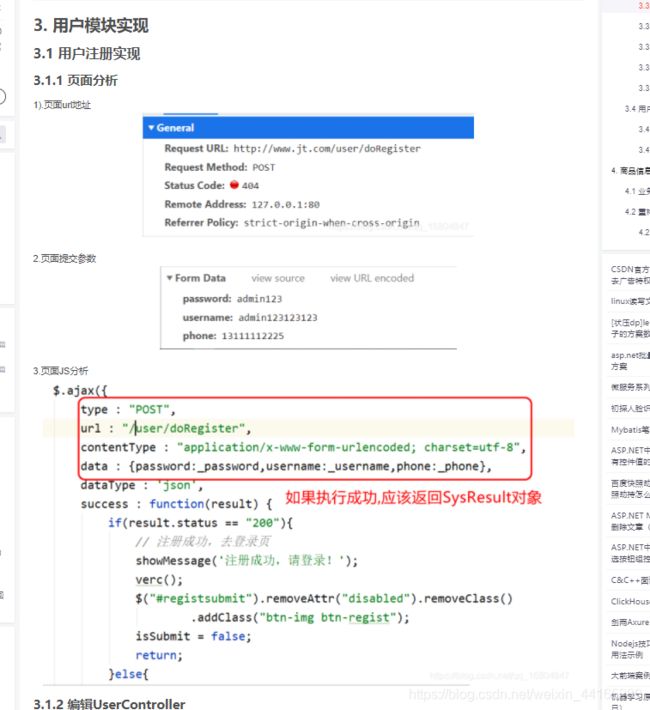
4.5.2 页面URL分析
1).url请求
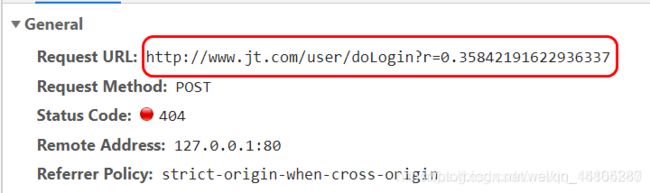
2).url参数
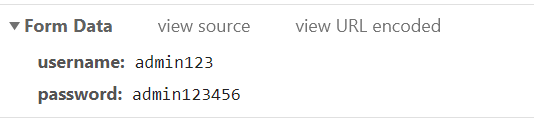
3).页面JS分析
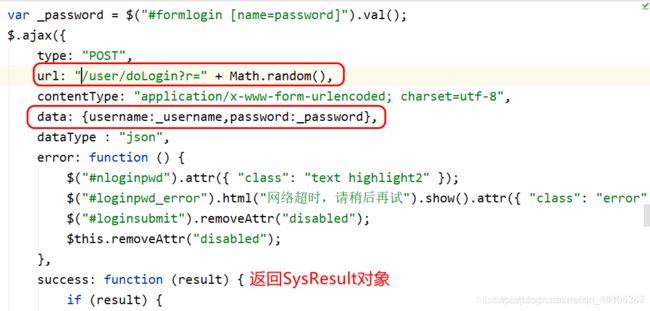
4.5.3 编辑JT-SSO的UserController
/**
* 业务说明:
* 通过跨域请求方式,获取用户的JSON数据.
* 1.url地址: http://sso.jt.com/user/query/efd321aec0ca4cd6a319b49bd0bed2db?callback=jsonp1605775149414&_=1605775149460
* 2.请求参数: ticket信息
* 3.返回值: SysResult对象 (userJSON)
* 需求: 通过ticket信息获取user JSON串
*/
@RequestMapping("/query/{ticket}")
public JSONPObject findUserByTicket(@PathVariable String ticket,String callback){
String userJSON = jedisCluster.get(ticket);
if(StringUtils.isEmpty(userJSON)){
return new JSONPObject(callback, SysResult.fail());
}else{
return new JSONPObject(callback, SysResult.success(userJSON));
}
}
4.5.4 页面效果展现

4.5.5 用户登出操作
4.5.6 退出业务逻辑
当用户点击退出操作时,应该重定向到系统首页. 同时删除redis信息/Cookie信息.
5.富文本编辑器
简介: KindEditor是一套开源的HTML可视化编辑器,主要用于让用户在网站上获得所见即所得编辑效果,兼容IE、Firefox、Chrome、Safari、Opera等主流浏览器。
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<link href="/js/kindeditor-4.1.10/themes/default/default.css" type="text/css" rel="stylesheet">
<script type="text/javascript" charset="utf-8" src="/js/kindeditor-4.1.10/kindeditor-all-min.js"></script>
<script type="text/javascript" charset="utf-8" src="/js/kindeditor-4.1.10/lang/zh_CN.js"></script>
<script type="text/javascript" charset="utf-8" src="/js/jquery-easyui-1.4.1/jquery.min.js"></script>
<script type="text/javascript">
$(function(){
KindEditor.ready(function(){
KindEditor.create("#editor")
})
})
</script>
</head>
<body>
<h1>富文本编辑器</h1>
<textarea style="width:700px;height:350px" id="editor"></textarea>
</body>
</html>


6. 反向代理
简介:反向代理服务器位于用户与目标服务器之间,但是对于用户而言,反向代理服务器就相当于目标服务器,即用户直接访问反向代理服务器就可以获得目标服务器的资源。同时,用户不需要知道目标服务器的地址,也无须在用户端作任何设定。反向代理服务器通常可用来作为Web加速,即使用反向代理作为Web服务器的前置机来降低网络和服务器的负载,提高访问效率。 [1]
特点:
\1. 反向代理服务器位于用户与目标服务器之间
\2. 对于用户而言,以为代理服务器就是真实的服务器.
\3. 反向代理机制保护了真实的服务器信息.
4. 反向代理一般称之为服务端代理.
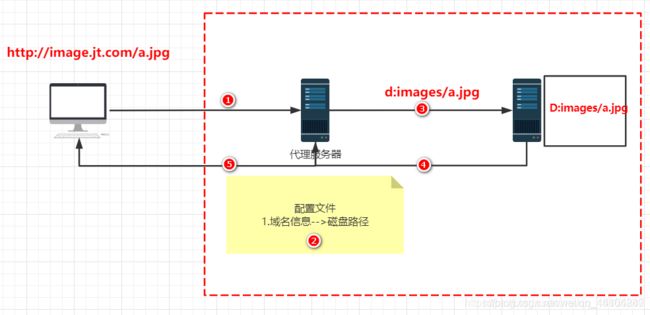
步骤:
1.当用户发起请求时,该请求被代理服务器拦截.
2.代理服务器查询自己的配置文件,根据url地址获取真实的服务器信息.
3.由代理服务器根据真实的服务器信息,获取数据.
4.真实的服务器接收请求之后,将数据返回给代理服务器.
5.代理服务器接收到服务器数据之后,将数据回传给用户,本次代理结束.
6.1 正向代理说明
正向代理,意思是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端才能使用正向代理。
特点:
1.代理服务器位于用户与真实服务器之间的
2.客户非常清楚自己访问的服务到底是谁?
3.服务器不清楚访问自己的服务器到底是谁,以为只是代理服务器访问.
4.正向代理称之为客户端代理.保护了客户的信息
6.2 Nginx
6.2.1 Nginx服务器介绍
Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点(俄文:Рамблер)开发的,第一个公开版本0.1.0发布于2004年10月4日。
其将源代码以类BSD许可证的形式发布,因它的稳定性、丰富的功能集、示例配置文件和低系统资源的消耗而闻名。2011年6月1日,nginx 1.0.4发布。
Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,在BSD-like 协议下发行。其特点是占有内存少,并发能力强,事实上nginx的并发能力在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。
特点:
1.占用内存少 不超过2M
2.并发能力强 5万/秒 tomcat 150-220个/秒
3.开发语言 C语言

6.3 nginx高级用法
6.3.1 nginx负载均衡机制
说明: 为了提升后台服务器的处理能力,可以增加服务器.实现负载均衡的策略.

6.3.2 动态获取服务器端口号.
请求路径: http://manage.jt.com/getPort 获取到当前的服务器端口号信息.
package com.jt.controller;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class PortController {
@Value("${server.port}")
private String port;
/**
* 获取端口号信息
*/
@RequestMapping("/getPort")
public String getPort(){
return "当前访问的服务器的端口号为:"+port;
}
}
6.4 nginx负载均衡测试
6.4.1 轮询策略
说明: 按照nginx.conf中配置文件的顺序依次访问.

7 .Linux
7.1 命令说明:
1."|" 管道 管道之前查询的结果,当做管道之后的参数(条件)进行操作.
\2. kill 杀死进程
kill PID号 普通关闭进程 (弱关闭)
kill -15 PID号 必须关闭,但是可以执行后续操作.
kill -9 PID号 强制关闭, 不给任何时间执行后续任务.
关闭服务器命令: ps -ef | grep java
7.2 关于查看命令学习
cat 输出文件所有的内容
more 输出文档所有的内容,分页输出,空格浏览下一屏,q退出
less 用法和more相同,只是通过PgUp、PgOn键来控制
tail 用于显示文件后几号,使用频繁
tail -10 nginx.conf 查看nginx.conf的最后10行
tail –f nginx.conf 动态查看日志,方便查看日志新增的信息
ctrl+c 结束查看
tar -xvf 解压
7.3 脚本启动tomcat服务器
说明: Linux中的脚本一般采用shell脚本.
步骤:
1.编辑start.sh的脚本文件
2.命令: vim /etc/my.cnf,编辑二进制日志文件:
8 .数据库相关学习
8.1 数据库备份策略
8.2 数据库冷备份
说明:通过数据库工具,定期将数据库文件进行转储,保证数据的安全性. (一般2-3天)
缺点:
1.备份时由于突发的情况,可能导致备份失败.需要反复备份.
2.由于冷备份是定期备份.所以可能导致数据的丢失.
核心:
数据必须备份.备份的数据是恢复的最后有效的手段.


8.3 数据库热备份
说明:可以通过数据库机制,自动的实现数据的备份操作.
优点: 可以实现自动化的操作,并且是实时备份.
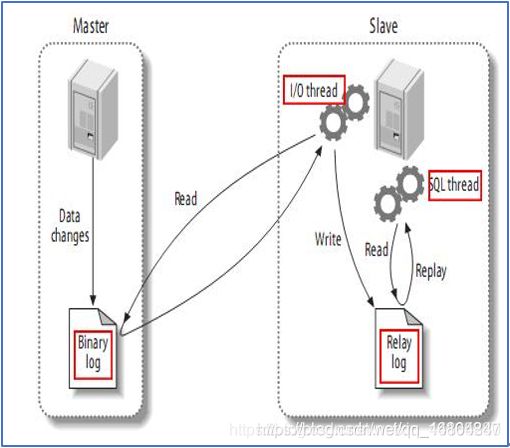
备份实现原理:
- 当数据库主机的数据发生变化时,会将修改的数据写进二进制日志文件中.
- 从库中通过IO线程,读取主库的二进制日志文件,获取之后,将数据保存到中继(临时存储)日志中.
- 从库开启sql线程,之后读取中继日志中的数据,之后将数据同步到从库中.
8.4 数据库主从测试
注意事项:
1.修改主库的数据,从库会跟着同步数据.
2.如果修改从库数据,则主从的关系将会终止.
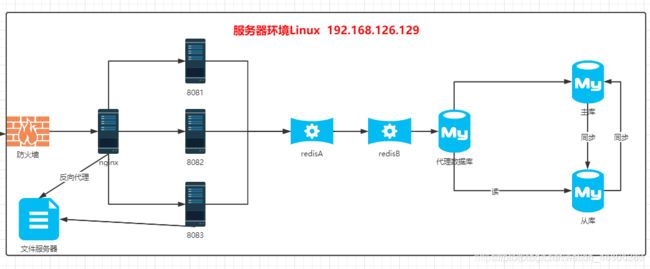
8.5 数据库读写分离/负载均衡实现
8.5.1 数据库优化策略
说明:通过代理数据库可以实现数据库的读写分离/数据库负载均衡操作,进一步的提升了整体架构的能力.

8.5.2 Mycat

8.5.3 Mycat特性
支持SQL92标准
支持MySQL、Oracle、DB2、SQL Server、PostgreSQL等DB的常见SQL语法
遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。
基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群。
支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster
基于Nio实现,有效管理线程,解决高并发问题。
支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数,支持跨库分页。
支持单库内部任意join,支持跨库2表join,甚至基于caltlet的多表join。
支持通过全局表,ER关系的分片策略,实现了高效的多表join查询。
支持多租户方案。
支持分布式事务(弱xa)。
支持XA分布式事务(1.6.5)。
支持全局序列号,解决分布式下的主键生成问题。
分片规则丰富,插件化开发,易于扩展。
强大的web,命令行监控。
支持前端作为MySQL通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb 、巨杉。
支持密码加密
支持服务降级
支持IP白名单
支持SQL黑名单、sql注入攻击拦截
支持prepare预编译指令(1.6)
支持非堆内存(Direct Memory)聚合计算(1.6)
支持PostgreSQL的native协议(1.6)
支持mysql和oracle存储过程,out参数、多结果集返回(1.6)
支持zookeeper协调主从切换、zk序列、配置zk化(1.6)
支持库内分表(1.6)
集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)。
8.5.4 Mycat负载均衡测试
修改从库中的数据库.刷新列表页面.检查是否有负载均衡的效果.
注意事项: 如果测试完成,记得将数据修改 保证一致.
8.6 实现数据库高可用
8.6.1 搭建策略
8.6.2 问题说明
说明:如果根据如下的配置实现数据库的代理,如果数据库主库宕机,则直接影响整个程序的执行.所以需要实现高可用机制.
高可用实现的问题:
如果实现了数据库高可用,可以自动的切换数据库,由于用户直接操作了从库,当主库启动时发现数据不一致时,主从同步的状态将会终止.
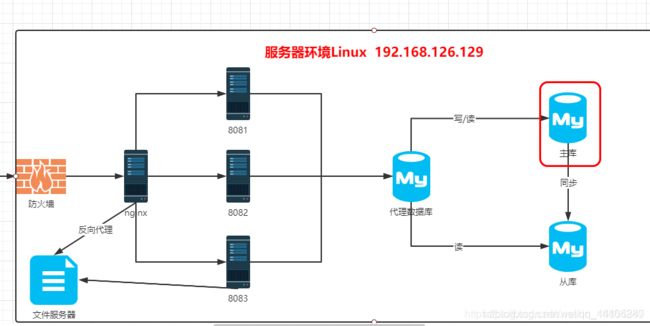
8.6.3 双击热备(双主模式)
说明:可以通过数据库双主模式实现数据库高可用.
双主模式实质都是主机,互相备份.

9. Redis
说明:通过缓存服务器可以有效提升用户的访问效率
注意事项:
1.缓存的数据结构 应该选用 K-V结构 只要key唯一 那么结果必然相同…
2.缓存中的数据不可能一直存储,需要定期将内存数据进行优化 LRU算法…
3.缓存要求运行速度很快, C语言实现… 运行在内存中.
4.如果缓存运行的数据在内存中,如果断电/宕机,则内存数据直接丢失. 实现内存数据的持久化操作(磁盘).
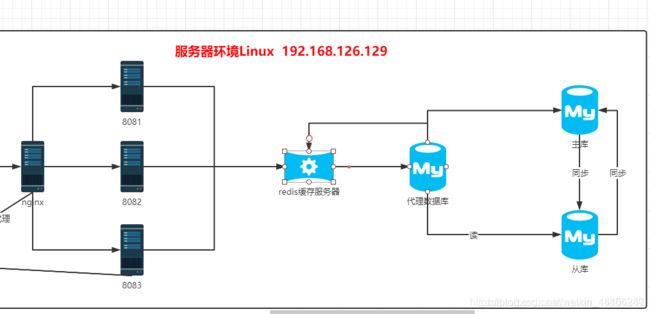
9.2 Redis缓存服务器
网址: http://www.redis.cn/
9.2.1 Redis介绍
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
nginx: 3-5万/秒
redis: 读: 11.2万/秒 写: 8.6万/秒 平均10万/秒
吞吐量: 50万/秒
9.3 SpringBoot整合Redis
9.3.1 导入jar包
<!--spring整合redis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
</dependency>
9.3.2 入门案例
package com.jt;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.params.SetParams;
public class TestRedis {
/**
* 1.实现redis测试
* 报错检查:
* 1.检查redis.conf配置文件 1.ip绑定问题 2.保护模式问题 3.后台启动问题
* 2.检查redis启动方式 redis-server redis.conf
* 3.检查防火墙
* */
@Test
public void test01(){
Jedis jedis = new Jedis("192.168.126.129",6379);
jedis.set("2007", "redis入门案例");
System.out.println(jedis.get("2007"));
}
/**
* 我想判断是否有key数据,如果没有则新增数据,如果有则放弃新增 */
@Test
public void test02(){
Jedis jedis = new Jedis("192.168.126.129",6379);
// if(!jedis.exists("2007")){ //判断数据是否存在.
// jedis.set("2007", "测试案例2222");
// }
//setnx作用: 如果有数据,则不做处理.
jedis.setnx("2007", "测试高级用法");
System.out.println(jedis.get("2007"));
}
/**
* 需求:
* 向redis中添加一个数据.set-key-value,要求添加超时时间 100秒.
* 隐藏bug: 代码执行过程中,如果报错,则可能删除失败.
* 原子性: 要么同时成功,要不同时失败.
* 解决方法: 将入库操作/超时时间一齐设定. setex
*/
@Test
public void test03() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129",6379);
//jedis.set("2007", "测试时间");
//隐藏含义: 业务需要 到期删除数据
//jedis.expire("2007", 100);
jedis.setex("2007", 100, "测试时间");
System.out.println(jedis.ttl("2007")+"秒");
}
/**
* 1.如果数据存在,则不操作数据 setnx
* 2.同时设定超时时间,注意原子性 setex
* 参数说明:
* 1. XX = "xx"; 只有key存在,则进行操作
* 2. NX = "nx"; 没有key,进行写操作
* 3. PX = "px"; 毫秒
* 4. EX = "ex"; 秒
*/
@Test
public void test04() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129",6379);
SetParams setParams = new SetParams();
setParams.xx().ex(100);
jedis.set("2007", "bbbbb",setParams);
System.out.println(jedis.get("2007"));
}
}
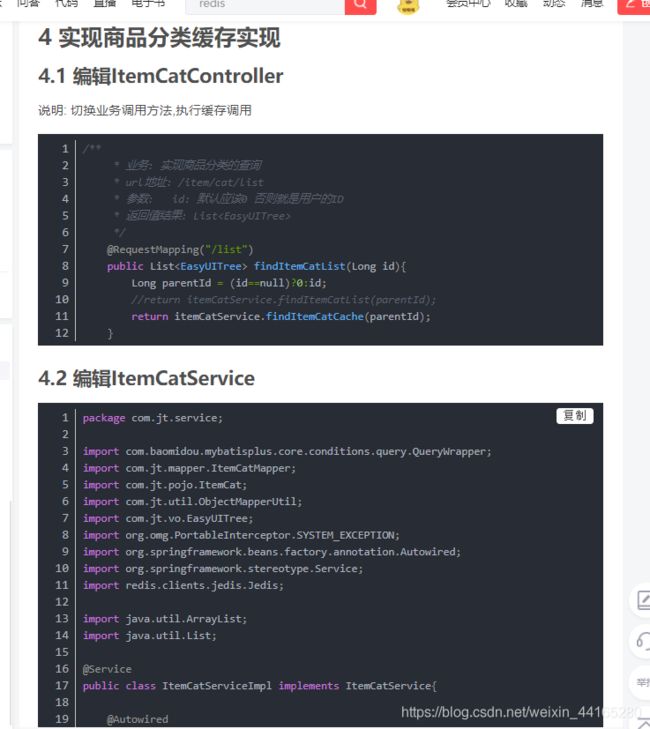
package com.jt.service;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.jt.mapper.ItemCatMapper;
import com.jt.pojo.ItemCat;
import com.jt.util.ObjectMapperUtil;
import com.jt.vo.EasyUITree;
import org.omg.PortableInterceptor.SYSTEM_EXCEPTION;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import redis.clients.jedis.Jedis;
import java.util.ArrayList;
import java.util.List;
@Service
public class ItemCatServiceImpl implements ItemCatService{
@Autowired
private ItemCatMapper itemCatMapper;
@Autowired(required = false) //程序启动是,如果没有改对象 暂时不加载
private Jedis jedis;
@Override
public String findItemCatName(Long itemCatId) {
return itemCatMapper.selectById(itemCatId).getName();
}
@Override
public List<EasyUITree> findItemCatList(Long parentId) {
//1.准备返回值数据
List<EasyUITree> treeList = new ArrayList<>();
//思路.返回值的数据从哪来? VO 转化 POJO数据
//2.实现数据库查询
QueryWrapper queryWrapper = new QueryWrapper();
queryWrapper.eq("parent_id",parentId);
List<ItemCat> catList = itemCatMapper.selectList(queryWrapper);
//3.实现数据的转化 catList转化为 treeList
for (ItemCat itemCat : catList){
long id = itemCat.getId(); //获取ID值
String text = itemCat.getName(); //获取商品分类名称
//判断:如果是父级 应该closed 如果不是父级 则open
String state = itemCat.getIsParent()?"closed":"open";
EasyUITree easyUITree = new EasyUITree(id,text,state);
treeList.add(easyUITree);
}
return treeList;
}
/**
* Redis:
* 2大要素: key: 业务标识+::+变化的参数 ITEMCAT::0
* value: String 数据的JSON串
* 实现步骤:
* 1.应该查询Redis缓存
* 有: 获取缓存数据之后转化为对象返回
* 没有: 应该查询数据库,并且将查询的结果转化为JSON之后保存到redis 方便下次使用
* @param parentId
* @return
*/
@Override
public List<EasyUITree> findItemCatCache(Long parentId) {
Long startTime = System.currentTimeMillis();
List<EasyUITree> treeList = new ArrayList<>();
String key = "ITEMCAT_PARENT::"+parentId;
if(jedis.exists(key)){
//redis中有数据
String json = jedis.get(key);
treeList = ObjectMapperUtil.toObject(json,treeList.getClass());
Long endTime = System.currentTimeMillis();
System.out.println("查询redis缓存的时间:"+(endTime-startTime)+"毫秒");
}else{
//redis中没有数据.应该查询数据库.
treeList = findItemCatList(parentId);
//需要把数据,转化为JSON
String json = ObjectMapperUtil.toJSON(treeList);
jedis.set(key, json);
Long endTime = System.currentTimeMillis();
System.out.println("查询数据库的时间:"+(endTime-startTime)+"毫秒");
}
return treeList;
}
}
9.4 Redis持久化策略
9.4.1 什么是持久化
说明:Redis运行环境在内存中,如果redis服务器关闭,则内存数据将会丢失.
需求: 如何保存内存数据呢?
解决方案: 可以定期将内存数据持久化到磁盘中.
持久化策略规则:
当redis正常运行时,定期的将数据保存到磁盘中,当redis服务器重启时,则根据配置文件中指定的持久化的方式,实现数据的恢复.(读取数据,之后恢复数据.)
9.4.2 RDB模式
9.4.3 RDB模式特点说明
1).RDB模式是Redis默认的策略.
2).RDB模式能够定期(时间间隔)持久化. 弊端:可能导致数据的丢失.
3).RDB模式记录的是内存数据的快照.持久化效率较高. 快照只保留最新的记录.
9.4.4 RDB模式命令
1.save命令: 将内存数据持久化到磁盘中 主动的操作 会造成线程阻塞
2.bgsave命令: 将内存数据采用后台运行的方式,持久化到文件中. 不会造成阻塞.
3.默认的持久化的机制
save 900 1 如果在900秒内,执行了1次更新操作,则持久化一次
save 300 10 如果在300秒内,执行了10次更新操作,则持久化一次
save 60 10000 如果在60秒内,执行了10000次更新操作,则持久化一次
9.4.5 AOF模式
9.4.6 AOF模式特点
1).AOF模式默认条件下是关闭的.需要手动开启
2).AOF模式记录的是用户的操作过程,所以可以实现实时持久化操作.
3).AOF模式由于记录的是实时的操作过程,所以持久化文件较大.需要定期维护.
9.4.7 启动AOF模式
说明:如果一旦开启AOF模式,则以AOF模式为准.
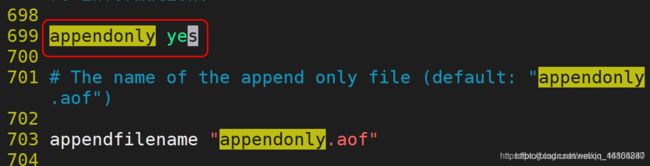
9.4.8 关于持久化操作总结
1.当内存数据允许少量丢失时,采用RDB模式 (快)
2.当内存数据不允许丢失时,采用AOF模式(定期维护持久化文件)
3.一般在工作中采用 RDB+AOF模式共同作用,保证数据的有效性.
9.4.9 面试题
问题: 如果小李(漂亮妹子)在公司服务器中执行了flushAll命令,问怎么办?
答: 需要找到aof文件之后,删除flushAll命令 之后重启redis,执行save命令即可.
9.5.0内存优化策略
9.5.1 为什么需要内存优化
说明: 由于redis在内存中保存数据.如果一直存储,则内存数据必然溢出.所以需要定期维护内存数据的大小.
维护策略: 删除旧的不用的数据,保留新的常用的数据
9.5.2 LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
计算维度: 时间T
注意事项: LRU算法是迄今为止内存中最好用的数据置换算法.
9.5.3 LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
维度: 使用次数
9.5.4 随机算法
随机算法.
9.5.5 TTL算法
根据剩余的存活时间,将马上要超时的数据提前删除.
9.5.6 关于缓存面试问题
问题出发点:
由于缓存失效,导致大量的用户的请求,直接访问数据库服务器.导致负载过高,从而引发整体宕机的风险!!!
9.5.7 缓存穿透
说明: 用户频繁访问数据库中不存在的数据,可能出现缓存穿透的现象.如果该操作是高并发操作,则可能直接威胁数据库服务器.
解决方案:
1.采用IP限流的方式 降低用户访问服务器次数. IP动态代理(1分钟变一次)
2.微服务的处理方式: 利用断路器返回执行的业务数据即可不执行数据库操作 从而保护了数据库.
3.微服务处理方式: API网关设计. 不允许做非法操作
9.5.8 缓存击穿
说明: 由于redis中某个热点数据由于超时/删除等操作造成数据失效.同时用户高并发访问该数据,则可能导致数据库宕机.该操作称之为 缓存击穿.
解决方案: 可以采用多级缓存的设计. 同时数据的超时时间采用随机数的方式.
9.5.9 缓存雪崩
说明: 由于redis内存数据大量失效.导致用户的访问命中率太低.大量的用户直接访问数据库,可能导致数据库服务器宕机. 这种现象称之为缓存雪崩.
解决:
1.采用多级缓存.
2.设定不同的超时时间
3.禁止执行 flushAll等敏感操作.
9.6.0 Redis分片说明
说明: 如果需要Redis存储海量的内存数据,使用单台redis不能满足用户的需求,所以可以采用Redis分片机制实现数据存储.
注意事项:
如果有多台redis,则其中的数据都是不一样的…
9.6.1 Redis哨兵机制
9.6.2 分片机制存在的问题
说明: redis分片主要的作用是实现内存数据的扩容.但是如果redis分片中有一个节点宕机,则直接影响所有节点的运行. 能否优化?
实现策略: 采用Redis哨兵机制实现Redis节点高可用.
9.6.3 哨兵机制工作原理
1).当哨兵启动时,会链接redis主节点,同时获取所有节点的状态信息
2).当哨兵连续3次通过心跳检测机制(PING-PONG),如果发现主机宕机,则开始选举.
3).哨兵内部通过随机算法筛选一台从机当选新的主机.其他的节点应该当新主机的从.

10. AOP实现redis缓存
10.1 现有代码存在的问题
1.如果直接将缓存业务,写到业务层中,如果将来的缓存代码发生变化,则代码耦合高,必然重写编辑代码.
2.如果其他的业务也需要缓存,则代码的重复率高,开发效率低.
解决方案: 采用AOP方式实现缓存.
10.2 AOP实现步骤
公式: AOP(切面) = 通知方法(5种) + 切入点表达式(4种)
10.2.1 通知复习
1.before通知 在执行目标方法之前执行
2.afterReturning通知 在目标方法执行之后执行
3.afterThrowing通知 在目标方法执行之后报错时执行
4.after通知 无论什么时候程序执行完成都要执行的通知
上述的4大通知类型,不能控制目标方法是否执行.一般用来记录程序的执行的状态.
一般应用与监控的操作.
5.around通知(功能最为强大的) 在目标方法执行前后执行.
因为环绕通知可以控制目标方法是否执行.控制程序的执行的轨迹.
10.2.2 切入点表达式
1.bean(“bean的ID”) 粒度: 粗粒度 按bean匹配 当前bean中的方法都会执行通知.
2.within(“包名.类名”) 粒度: 粗粒度 可以匹配多个类
3.execution(“返回值类型 包名.类名.方法名(参数列表)”) 粒度: 细粒度 方法参数级别
4.@annotation(“包名.类名”) 粒度:细粒度 按照注解匹配
10.2.3 AOP入门案例
package com.jt.aop;
import lombok.extern.apachecommons.CommonsLog;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Controller;
import org.springframework.stereotype.Service;
import java.util.Arrays;
@Aspect //标识我是一个切面
@Component //交给Spring容器管理
public class CacheAOP {
//切面 = 切入点表达式 + 通知方法
//@Pointcut("bean(itemCatServiceImpl)")
//@Pointcut("within(com.jt.service.ItemCatServiceImpl)")
//@Pointcut("within(com.jt.service.*)") // .* 一级包路径 ..* 所有子孙后代包
//@Pointcut("execution(返回值类型 包名.类名.方法名(参数列表))")
@Pointcut("execution(* com.jt.service..*.*(..))")
//注释: 返回值类型任意类型 在com.jt.service下的所有子孙类 以add开头的方法,任意参数类型
public void pointCut(){
}
/**
* 需求:
* 1.获取目标方法的路径
* 2.获取目标方法的参数.
* 3.获取目标方法的名称
*/
@Before("pointCut()")
public void before(JoinPoint joinPoint){
String classNamePath = joinPoint.getSignature().getDeclaringTypeName();
String methodName = joinPoint.getSignature().getName();
Object[] args = joinPoint.getArgs();
System.out.println("方法路径:"+classNamePath);
System.out.println("方法参数:"+ Arrays.toString(args));
System.out.println("方法名称:"+methodName);
}
@Around("pointCut()")
public Object around(ProceedingJoinPoint joinPoint){
try {
System.out.println("环绕通知开始");
Object obj = joinPoint.proceed();
//如果有下一个通知,就执行下一个通知,如果没有就执行目标方法(业务方法)
System.out.println("环绕通知结束");
return null;
} catch (Throwable throwable) {
throwable.printStackTrace();
throw new RuntimeException(throwable);
}
}
}
10.3 AOP实现Redis缓存
10.3.1 业务实现策略
1).需要自定义注解CacheFind
2).设定注解的参数 key的前缀,数据的超时时间.
3).在方法中标识注解.
4).利用AOP 拦截指定的注解.
5).应该使用Around通知实现缓存业务.
10.3.2 编辑自定义注解
@Target(ElementType.METHOD) //注解对方法有效
@Retention(RetentionPolicy.RUNTIME) //运行期有效
public @interface CacheFind {
public String preKey(); //定义key的前缀
public int seconds() default 0; //定义数据的超时时间.
}
10.3.3 方法中标识注解

10.3.4 编辑CacheAOP
package com.jt.aop;
import com.jt.anno.CacheFind;
import com.jt.util.ObjectMapperUtil;
import lombok.extern.apachecommons.CommonsLog;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Controller;
import org.springframework.stereotype.Service;
import redis.clients.jedis.Jedis;
import java.lang.reflect.Method;
import java.util.Arrays;
@Aspect //标识我是一个切面
@Component //交给Spring容器管理
public class CacheAOP {
@Autowired
private Jedis jedis;
/**
* 注意事项: 当有多个参数时,joinPoint必须位于第一位.
* 需求:
* 1.准备key= 注解的前缀 + 用户的参数
* 2.从redis中获取数据
* 有: 从缓存中获取数据之后,直接返回值
* 没有: 查询数据库之后再次保存到缓存中即可.
*
* 方法:
* 动态获取注解的类型,看上去是注解的名称,但是实质是注解的类型. 只要切入点表达式满足条件
* 则会传递注解对象类型.
* @param joinPoint
* @return
* @throws Throwable
*/
@Around("@annotation(cacheFind)")
public Object around(ProceedingJoinPoint joinPoint,CacheFind cacheFind) throws Throwable {
Object result = null; //定义返回值对象
String preKey = cacheFind.preKey();
String key = preKey + "::" + Arrays.toString(joinPoint.getArgs());
//1.校验redis中是否有数据
if(jedis.exists(key)){
//如果数据存在,需要从redis中获取json数据,之后直接返回
String json = jedis.get(key);
//1.获取方法对象, 2.获取方法的返回值类型
MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();
//2.获取返回值类型
Class returnType = methodSignature.getReturnType();
result = ObjectMapperUtil.toObject(json,returnType);
System.out.println("AOP查询redis缓存!!!");
}else{
//代表没有数据,需要查询数据库
result = joinPoint.proceed();
//将数据转化为JSON
String json = ObjectMapperUtil.toJSON(result);
if(cacheFind.seconds() > 0){
jedis.setex(key, cacheFind.seconds(), json);
}else{
jedis.set(key,json);
}
System.out.println("AOP查询数据库!!!");
}
return result;
}
/* @Around("@annotation(com.jt.anno.CacheFind)")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
//1.获取目标对象的Class类型
Class targetClass = joinPoint.getTarget().getClass();
//2.获取目标方法名称
String methodName = joinPoint.getSignature().getName();
//3.获取参数类型
Object[] argsObj = joinPoint.getArgs();
Class[] argsClass = null;
//4.对象转化为class类型
if(argsObj.length>0){
argsClass = new Class[argsObj.length];
for(int i=0;i
/* //切面 = 切入点表达式 + 通知方法
//@Pointcut("bean(itemCatServiceImpl)")
//@Pointcut("within(com.jt.service.ItemCatServiceImpl)")
//@Pointcut("within(com.jt.service.*)") // .* 一级包路径 ..* 所有子孙后代包
//@Pointcut("execution(返回值类型 包名.类名.方法名(参数列表))")
@Pointcut("execution(* com.jt.service..*.*(..))")
//注释: 返回值类型任意类型 在com.jt.service下的所有子孙类 以add开头的方法,任意参数类型
public void pointCut(){
}*/
/**
* 需求:
* 1.获取目标方法的路径
* 2.获取目标方法的参数.
* 3.获取目标方法的名称
*/
/* @Before("pointCut()")
public void before(JoinPoint joinPoint){
String classNamePath = joinPoint.getSignature().getDeclaringTypeName();
String methodName = joinPoint.getSignature().getName();
Object[] args = joinPoint.getArgs();
System.out.println("方法路径:"+classNamePath);
System.out.println("方法参数:"+ Arrays.toString(args));
System.out.println("方法名称:"+methodName);
}
@Around("pointCut()")
public Object around(ProceedingJoinPoint joinPoint){
try {
System.out.println("环绕通知开始");
Object obj = joinPoint.proceed();
//如果有下一个通知,就执行下一个通知,如果没有就执行目标方法(业务方法)
System.out.println("环绕通知结束");
return null;
} catch (Throwable throwable) {
throwable.printStackTrace();
throw new RuntimeException(throwable);
}
}*/
}
11. 跨域
什么是跨域
由于业务需要,通常A服务器中的数据可能来源于B服务器. 当浏览器通过网址解析页面时,如果页面内部发起ajax请求.如果浏览器的访问地址与Ajax访问地址不满足同源策略时,则称之为跨域请求.
跨域要素:
1.浏览器
2.解析ajax
3.违反了同源策略
11.1 JSONP跨域访问
11.2 JSONP介绍
JSONP(JSON with Padding)是JSON的一种“使用模式”,可用于解决主流浏览器的跨域数据访问的问题。由于同源策略,一般来说位于 server1.example.com 的网页无法与不是 server1.example.com的服务器沟通,而 HTML 的
11.3 JSONP原理说明
1.利用javaScript中的src属性可以跨域的访问.
<script type="text/javascript" src="http://manage.jt.com/test.json"></script>
2.提前准备一个回调函数 callback()
/*定义回调函数 */
function hello(data){
alert(data.name);
}
3.将返回值结果进行特殊的格式封装. callback(JSON数据)
hello({
"id":"1","name":"tom"})
11.4 JSONP高级API
11.5 编辑前端WEB页面
<html>
<head>
<meta charset="UTF-8">
<title>JSONP测试title>
<script type="text/javascript" src="http://manage.jt.com/js/jquery-easyui-1.4.1/jquery.min.js">script>
<script type="text/javascript">
$(function(){
//让页面加载完成之后再次执行
alert("测试访问开始!!!!!")
$.ajax({
url:"http://manage.jt.com/web/testJSONP",
type:"get", //jsonp只能支持get请求
dataType:"jsonp", //dataType表示返回值类型
jsonp: "callback", //指定参数名称
jsonpCallback: "hello", //指定回调函数名称
success:function (data){
//data经过jQuery封装返回就是json串
alert(data.id);
alert(data.name);
//转化为字符串使用
//var obj = eval("("+data+")");
//alert(obj.name);
}
});
})
script>
head>
<body>
<h1>JSON跨域请求测试h1>
body>
html>
11.5.1 JSONP页面请求分析
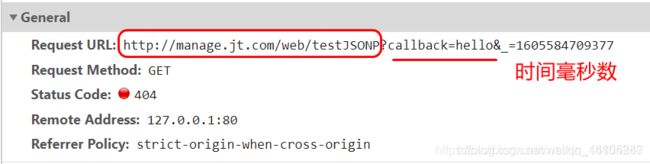
毫秒数作用: 由于浏览器进行业务请求时可能有缓存操作,所以添加毫秒数,避免浏览器将结果缓存.导致业务异常.
11.5.2 编辑后端服务器
package com.jt.web;
import com.fasterxml.jackson.databind.util.JSONPObject;
import com.jt.pojo.ItemDesc;
import com.jt.util.ObjectMapperUtil;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class WebJSONPController {
/**
* 完成JSONP跨域访问
* url地址: http://manage.jt.com/web/testJSONP?callback=hello&_=1605584709377
* 参数: callback 回调函数的名称
* 返回值: callback(json)
*/
@RequestMapping("/web/testJSONP")
public JSONPObject testJSONP(String callback){
ItemDesc itemDesc = new ItemDesc();
itemDesc.setItemId(1000L).setItemDesc("JSONP远程调用!!!");
JSONPObject jsonpObject = new JSONPObject(callback, itemDesc);
return jsonpObject;
}
}
11.6 CORS跨域实现
11.6.1 CORS介绍
因为出于安全的考虑, 浏览器不允许Ajax调用当前源之外的资源. 即浏览器的同源策略.
CORS需要浏览器和服务器同时支持。目前,所有主流浏览器都支持该功能,IE浏览器不能低于IE10。在浏览器端, 整个CORS通信过程都是浏览器自动完成,在请求之中添加响应头信息,如果服务器允许执行跨域访问.,则浏览器的同源策略放行.

11.7 关于跨域说明
1.什么叫跨域 浏览器解析Ajax时,发起url请求违反了同源策略时,称之为跨域.
2.什么时候用跨域 一般A服务器需要从B服务器中获取数据时,可以采用跨域的方式.
3.什么是JSONP JSONP是JSON的一种使用模式 利用javaScript中的src属性进行跨域请求.(2.自定义回调函数,3.将返回值进行特殊格式封装)
4.什么是CORS CORS是当前实现跨域的主流方式,现在所有的主流浏览器都支持,需要在服务器端配置是否允许跨域的配置. 只要配置了(在响应头中添加允许跨域的标识),则同源策略不生效,则可以实现跨域.
12. HttpClient
12.1 业务需求说明

12.2 HttpClient介绍
HTTP 协议可能是现在 Internet 上使用得最多、最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源。虽然在 JDK 的 java net包中已经提供了访问 HTTP 协议的基本功能,但是对于大部分应用程序来说,JDK 库本身提供的功能还不够丰富和灵活。HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。HttpClient 已经应用在很多的项目中,比如 Apache Jakarta 上很著名的另外两个开源项目 Cactus 和 HTMLUnit 都使用了 HttpClient。现在HttpClient最新版本为 HttpClient 4.5 .6(2015-09-11)
12.3 SOA思想
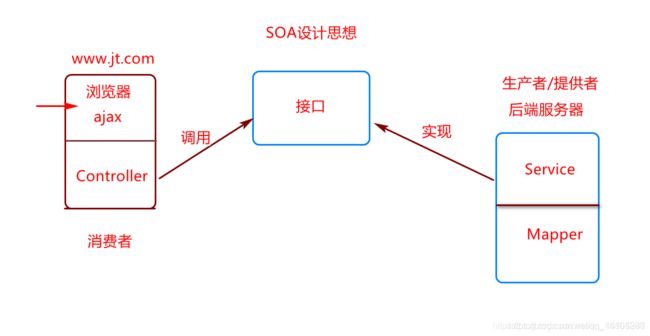
12.4 SOA思想介绍
面向服务的架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)*进行*拆分,并通过这些服务之间定义良好的接口和协议**联系起来。接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。这使得构建在各种各样的系统中的服务可以以一种统一和通用的方式进行交互。
12.5 RPC介绍(调用形式的统称)
12.5.1 RPC介绍
RPC(Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务
本地过程调用:如果需要将本地student对象的age+1,可以实现一个addAge()方法,将student对象传入,对年龄进行更新之后返回即可,本地方法调用的函数体通过函数指针来指定。
远程过程调用:addAge方法在其他的服务器中,如果需要调用则必须通过远程的方式通知其他服务器帮我完成业务调用.
总结: 利用第三方的服务器,帮我完成业务调用的过程.
理解: 分布式环境中 业务调用几乎都是RPC的.
13. 微服务
13.1 什么是微服务
说明:
\1. 为了降低代码的耦合性,将项目进行了拆分.按照功能模块拆分为若干个项目.该项目称之为服务.(分布式思想).
\2. 如果采用微服务的结构,要求服务器如果出现了故障应该实现自动化的故障的迁移(高可用HA)
13.2 现有服务分析
说明:由于nginx负载均衡/反向代理都需要人为的配置,并且出现了问题不能及时的实现故障的迁移,所以需要升级为微服务的架构的设计.
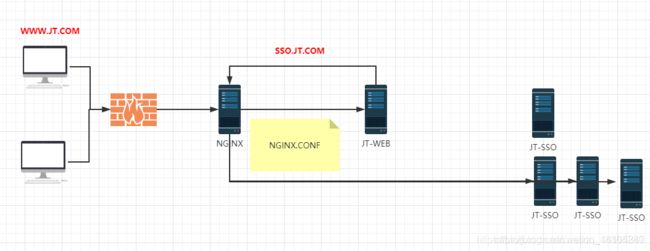
13.3 微服务架构设计

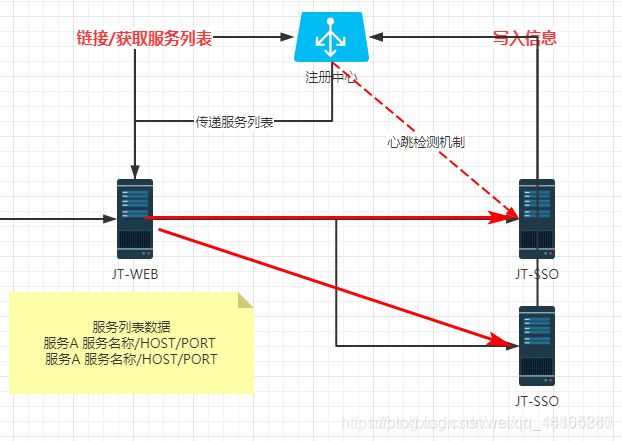
实现步骤:
\1. 服务提供者启动时,.将自己的信息注册到注册中心中.
\2. 注册中心接受到了用户的请求之后,更新服务列表信息.
\3. 当消费者启动时,首先会链接注册中心,获取服务列表数据.
\4. 注册中心将自己的服务列表信息同步给客户端(消费者)
\5. 消费者接收到服务列表数据之后,将信息保存到自己的本地.方便下次调用
\6. 当消费者接收到用户的请求时,根据自己服务列表的信息进行负载均衡的操作,选择其中一个服务的提供者,根据IP:PORT 进行RPC调用.
\7. 当服务提供者宕机时,注册中心会有心跳检测机制,如果检查宕机,则更新本地的服务列表数据,并且全网广播通知所有的消费者更新服务列表.
13.4 zk为什么集群一般都是奇数个?
公式: 存活的节点 > N/2
常识: 最小的集群的单位3台.
例子:
1个节点能否搭建集群? 1-1 > 1/2 假的 1个节点不能搭建集群
2个节点能否搭建集群? 2-1 > 2/2 假的 2个节点不能搭建集群
3个节点能否搭建集群? 3-1 > 3/2 真的 3个节点能搭建集群
4个节点能否搭建集群? 4-1 > 4/2 真的 4个节点能搭建集群
3个节点最多允许宕机1台,否则集群崩溃.
4个节点最多允许宕机1台,否则集群崩溃.
12
搭建奇数台和偶数台其实都可以,但是从容灾性的角度考虑,发现奇数和偶数的效果相同,.所以搭建奇数台.
13.5 ZK集群选举规则
说明: zk集群选举采用最大值(myid)优先的算法实现,如果集群中没有主机,则开始选举(超半数即可),如果有主机,则选举结束.
考题: 1 2 3 4 5 6 7 依次启动时
问题1:谁当主机? 4当主机
问题2:谁永远不能当选主机? 1,2,3
14. Dubbo框架
14.1 Dubbo介绍
Apache Dubbo |ˈdʌbəʊ| 提供了六大核心能力:面向接口代理的高性能RPC调用,智能容错和负载均衡,服务自动注册和发现,高度可扩展能力,运行期流量调度,可视化的服务治理与运维。

调用原理图:

生产者和消费者
14.2 Dubbo高可用测试
14.2.1 测试需求
1).测试当服务器宕机,用户访问是否受影响. 用户访问不受影响. zk心跳检测机制
2).测试当zk集群宕机,用户访问是否受影响. 不受影响 消费者在本地有服务列表数据,自己维护.
3).测试是否有负载均衡的效果 用户访问有负载均衡的效果
14.2.2 Dubbo负载均衡
14.2.3 负载均衡方式
1.服务端负载均衡(集中式负载均衡)
说明: 用户访问服务器时不清楚真实的服务器到底是谁,由负载均衡服务器动态动态管理.
典型代表: NGINX
一般nginx服务器做反向代理使用,负载均衡只是提供的功能.
2.客户端负载均衡
说明:采用微服务架构时,当消费者访问服务提供者时,由于框架内部已经实现了负载均衡的策略,所以消费者访问提供者时已经完成了负载均衡的机制.所以将所有的压力平衡到了各个消费者中.