很久之前就学习了Python的爬虫了,也用来做过一些项目(主要是一些课程项目),但时间比较紧,一直没有空把它写下来,这个暑假,我可能会逐渐更新Python爬虫的相关知识。
https://xueqiu.com/6863349742...
https://xueqiu.com/6863349742...
https://xueqiu.com/6863349742...
https://xueqiu.com/6863349742...
https://xueqiu.com/6863349742...
https://xueqiu.com/6863349742...
https://xueqiu.com/6863349742...
项目1:实现批量爬取百度图片
先简单的介绍下这个项目。当你需要下载大量图片的时候,或许你会去百度图片里一张张右键下载,但这样未免太麻烦了,有了这个工具,你直接运行下程序,输入你想要下载图片的关键字,然后输入你想要下载图片的数量,你就成功下载图片了!
下面给下演示程序的截图:
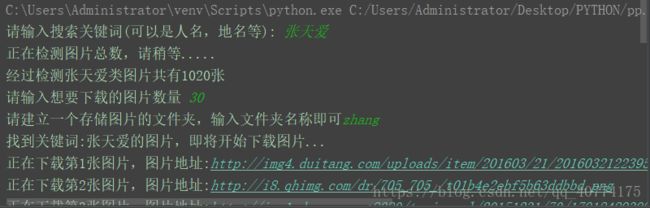
几秒钟后,我去C盘文件夹下,就有了30张,张天爱的图片啦!

是不是觉得,这样下载起来比较方便........
好了,言归正传,下面开始一步步教大家,怎么实现它!
- Python的IDE,我想大家应该都有吧,我用的是pycharm,大家可以去官网上下载,这里顺带给大家推荐一个免费试用它的方法,当然,仅限于在校大学生(如果你是高中生的话,可能需要麻烦一点,去百度找注册码,大概每个月会更新一次的样子)
首先,你先到jetBrains 官网,官网链接在这!打开后。
你点击右上角的人物标志,进入账号登录页面。
之后,你在打开这个注册账号的链接:学生账号注册链接,

点击立即申请!
你会进入这个页面:

这里需要一个学校的公邮,这个公邮去哪里找呢?你可以去你所在学校的官网找找,每个在校大学生都可以申请200个学校公邮的(反正我们学校是这样),你可以搜索你们学校的邮箱系统,去查看具体怎么申请,每个学校可能不同。
申请好了以后,你在回到一开始让你进入的登录页面,登录以后,就可以免费下载使用了。
2 .安装爬虫需要的包
(1)如果你使用的是pycharm,那么你安装包会非常的方便,在pycharm里找的Terminal 点击,输入pip install ....就可以安装包了,当然如果是你首次运行的话,可能需要你更新pip工具,这你最好去官网重新下载下pip,这样你以后会很方便,这里就不在具体讲怎么更新pip了,以后有时间在写写吧。
(2) 依次键入pip install BeautifulSoup
pip insatll requests
pip install lxml
(3)下面将分别介绍他们的用途:
BeautifulSoup 是用来获取一个页面里面的各个标签及里面的内容,我们主要用到它里面的find(),find_All()函数,具体用法将在后面一一介绍
requests 是用来获取网页信息的,也就是说,我们给它一个url,它能把这个url对应的页面信息全部反馈给我们,这时候我们在用beautifulSoup里的函数对他们进行处理
lxml 是一个解析器,python里有专门的解析器,html.parser,但是lxml的解析速度优于html_parser,所以建议使用lxml
- Python正则表达式基础
要想提升写爬虫的能力,那么你必须学会正则表达式,它可以让你用简短的代码实现你想要的功能。
详细的知识,可以到这里去看.python 正则表达式
下面我会介绍,本次项目里使用到的技巧:
首先你先打开百度图片 ,也就是这个页面 百度图片
然后,你可以随便输入你想要查看的图片....(不好意思,我还是输入了,zhang tian ai)

注意:先点击右上角,切换成传统翻页版,因为这样有利于我们爬取图片!这里一定要注意,很多网友问我,为啥他打开百度图片,每一页不是60张图片。因为你直接打开的网页,不便于翻页操作,并且每一页的图片数量不相同。所以,我选择爬取的方法是,从传统翻页版爬取图片。
接着,你右键检查网页源代码(如果你用的是谷歌浏览器),那么你可以在里面直接搜索 objURL 或者URL

现在我们发现了我们需要图片的url了,现在,我们要做的就是将这些信息爬取出来(网页中有objURL,hoverURL...但是我们用的是objURL,因为这个是原图),如何获取objURL?当然你可以暴力写个程序跑一遍,但是这程序写起来.....
那我们该如何用正则表达式实现呢?其实只需要一行代码.....
![]()
就是这么简单,我想你如果看了正则表达式,一定可以轻松的写出或者理解这句话。
经过我的实验,我发现传统翻页版的百度图片,每一页有60张图片。这也是为啥后面我写代码,用了t+60。
4 . BeautifulSoup知识介绍
同样的我先给出文档链接,具体细节大家自己研究,我这里只介绍这个项目用到的知识。BeautifulSoup 文档
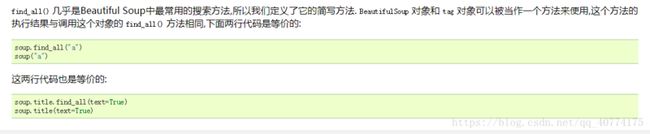
我们主要用到的是find()和find_All()函数:

- requests 介绍
requests博大精深,我们这里只不过是用了它的一个功能而已。
html = requests.get(url) 我们将url传进去,它就会得到这个url里面的信息,具体的,大家可以在python里运行试试.- 项目实现思路
首先需要写一个下载图片的函数,其次还有检测图片数量的函数,还有最后的推荐函数(推荐函数,主要是根据你键入的文本,在百度图片里找到相似的内容,返回给用户,类似于百度搜索的最下面)
首先是图片下载函数:下面是部分代码

具体思路就是根据正则表达式,找到url,然后完成下载。
其次是推荐函数:

推荐函数,主要公能是把百度的相关搜索提示返回给用户,实现很简单,但需要注意编码的问题(关于python编码格式的问题,我觉得能写10000字,以后有空再慢慢写吧)。
还有是检测图片数量函数,它的主要思路是通过计算能翻的页数来估算总数量,比如一个页面有20张图片,那么我点下一页50次,那么就说明有1000张图片....虽然这样很傻(哈哈)
因为有些图片可能有很多张(估计要翻页10000多次),所以为了能在几秒内下载好图片,我把图片是上限设为了1020张,也就是说即使有100000张图片,我也就先告诉你只有1020张(当然你也可以把它设置为无限,可能会慢一点)
7 主函数
主函数主要是一些逻辑上的问题,为的就是让用户使用更便捷而已,具体我就不一一解释,我想大家看源码比看我写 的文字更有感觉。
之前会出现下载重复的bug,现在已经解决了。
8 源代码:
1. # -*- coding: utf-8 -*-
2. """
3. Created on Sun Sep 13 21:32:25 2020
5. @author: ydc
6. """
11. import re
12. import requests
13. from urllib import error
14. from bs4 import BeautifulSoup
15. import os
17. num = 0
18. numPicture = 0
19. file = ''
20. List = []
23. def Find(url, A):
24. global List
25. print('正在检测图片总数,请稍等.....')
26. t = 0
27. i = 1
28. s = 0
29. while t < 1000:
30. Url = url + str(t)
31. try:
32. # 这里搞了下
33. Result = A.get(Url, timeout=7, allow_redirects=False)
34. except BaseException:
35. t = t + 60
36. continue
37. else:
38. result = Result.text
39. pic_url = re.findall('"objURL":"(.*?)",', result, re.S) # 先利用正则表达式找到图片url
40. s += len(pic_url)
41. if len(pic_url) == 0:
42. break
43. else:
44. List.append(pic_url)
45. t = t + 60
46. return s
49. def recommend(url):
50. Re = []
51. try:
52. html = requests.get(url, allow_redirects=False)
53. except error.HTTPError as e:
54. return
55. else:
56. html.encoding = 'utf-8'
57. bsObj = BeautifulSoup(html.text, 'html.parser')
58. div = bsObj.find('div', id='topRS')
59. if div is not None:
60. listA = div.findAll('a')
61. for i in listA:
62. if i is not None:
63. Re.append(i.get_text())
64. return Re
67. def dowmloadPicture(html, keyword):
68. global num
69. # t =0
70. pic_url = re.findall('"objURL":"(.*?)",', html, re.S) # 先利用正则表达式找到图片url
71. print('找到关键词:' + keyword + '的图片,即将开始下载图片...')
72. for each in pic_url:
73. print('正在下载第' + str(num + 1) + '张图片,图片地址:' + str(each))
74. try:
75. if each is not None:
76. pic = requests.get(each, timeout=7)
77. else:
78. continue
79. except BaseException:
80. print('错误,当前图片无法下载')
81. continue
82. else:
83. string = file + r'' + keyword + '_' + str(num) + '.jpg'
84. fp = open(string, 'wb')
85. fp.write(pic.content)
86. fp.close()
87. num += 1
88. if num >= numPicture:
89. return
92. if __name__ == '__main__': # 主函数入口
94. ##############################
95. # 这里加了点
96. headers = {
97. 'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
98. 'Connection': 'keep-alive',
99. 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
100. 'Upgrade-Insecure-Requests': '1'
101. }
103. A = requests.Session()
104. A.headers = headers
105. ###############################
107. word = input("请输入搜索关键词(可以是人名,地名等): ")
108. # add = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%BC%A0%E5%A4%A9%E7%88%B1&pn=120'
109. url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&pn='
111. # 这里搞了下
112. tot = Find(url, A)
113. Recommend = recommend(url) # 记录相关推荐
114. print('经过检测%s类图片共有%d张' % (word, tot))
115. numPicture = int(input('请输入想要下载的图片数量 '))
116. file = input('请建立一个存储图片的文件夹,输入文件夹名称即可')
117. y = os.path.exists(file)
118. if y == 1:
119. print('该文件已存在,请重新输入')
120. file = input('请建立一个存储图片的文件夹,)输入文件夹名称即可')
121. os.mkdir(file)
122. else:
123. os.mkdir(file)
124. t = 0
125. tmp = url
126. while t < numPicture:
127. try:
128. url = tmp + str(t)
130. # 这里搞了下
131. result = A.get(url, timeout=10, allow_redirects=False)
132. except error.HTTPError as e:
133. print('网络错误,请调整网络后重试')
134. t = t + 60
135. else:
136. dowmloadPicture(result.text, word)
137. t = t + 60
139. print('当前搜索结束,感谢使用')
140. print('猜你喜欢')
141. for re in Recommend:
142. print(re, end=' ')
好了,就先写这么多。欢迎大家转载。如有问题,欢迎给我留言。
2019年4月2日 第3次更新
这次有网友想要爬取大量的图片作为训练材料。他想要300种不同的图片,每种100张,如果还是按之前的代码去运行,就需要他输入300次图片的名称,这样是非常浪费时间的。所以这里对代码进行一些改进,你只需要把你想要爬取图片的名称,编辑到一个txt文件,然后输入你需要的数量就行。
使用方法:
首先将你需要下载的图片名称写到一个txt文本上,文本的名字叫name即可。
按行输入,每行放一个名字。
将name.txt放入和你当前python文件同一目录下即可。

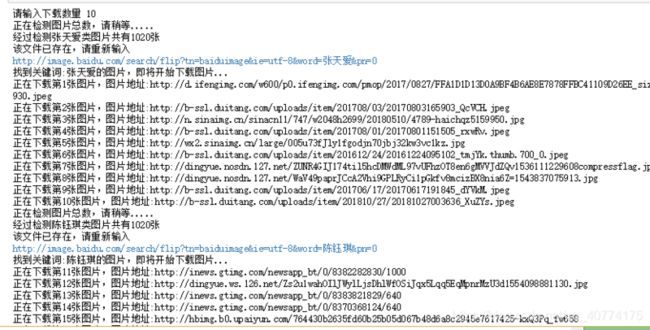
代码:
1. # -*- coding: utf-8 -*-
2. """
3. Created on Sun Sep 13 21:35:34 2020
5. @author: ydc
6. """
8. import re
9. import requests
10. from urllib import error
11. from bs4 import BeautifulSoup
12. import os
14. num = 0
15. numPicture = 0
16. file = ''
17. List = []
20. def Find(url, A):
21. global List
22. print('正在检测图片总数,请稍等.....')
23. t = 0
24. i = 1
25. s = 0
26. while t < 1000:
27. Url = url + str(t)
28. try:
29. # 这里搞了下
30. Result = A.get(Url, timeout=7, allow_redirects=False)
31. except BaseException:
32. t = t + 60
33. continue
34. else:
35. result = Result.text
36. pic_url = re.findall('"objURL":"(.*?)",', result, re.S) # 先利用正则表达式找到图片url
37. s += len(pic_url)
38. if len(pic_url) == 0:
39. break
40. else:
41. List.append(pic_url)
42. t = t + 60
43. return s
47. def recommend(url):
48. Re = []
49. try:
50. html = requests.get(url, allow_redirects=False)
51. except error.HTTPError as e:
52. return
53. else:
54. html.encoding = 'utf-8'
55. bsObj = BeautifulSoup(html.text, 'html.parser')
56. div = bsObj.find('div', id='topRS')
57. if div is not None:
58. listA = div.findAll('a')
59. for i in listA:
60. if i is not None:
61. Re.append(i.get_text())
62. return Re
64. def dowmloadPicture(html, keyword):
65. global num
66. # t =0
67. pic_url = re.findall('"objURL":"(.*?)",', html, re.S) # 先利用正则表达式找到图片url
68. print('找到关键词:' + keyword + '的图片,即将开始下载图片...')
69. for each in pic_url:
70. print('正在下载第' + str(num + 1) + '张图片,图片地址:' + str(each))
71. try:
72. if each is not None:
73. pic = requests.get(each, timeout=7)
74. else:
75. continue
76. except BaseException:
77. print('错误,当前图片无法下载')
78. continue
79. else:
80. string = file + r'' + keyword + '_' + str(num) + '.jpg'
81. fp = open(string, 'wb')
82. fp.write(pic.content)
83. fp.close()
84. num += 1
85. if num >= numPicture:
86. return
89. if __name__ == '__main__': # 主函数入口
92. headers = {
93. 'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
94. 'Connection': 'keep-alive',
95. 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
96. 'Upgrade-Insecure-Requests': '1'
97. }
99. A = requests.Session()
100. A.headers = headers
103. ###############################
106. tm = int(input('请输入每类图片的下载数量 '))
107. numPicture = tm
108. line_list = []
109. with open('./name.txt', encoding='utf-8') as file:
110. line_list = [k.strip() for k in file.readlines()] # 用 strip()移除末尾的空格
112. for word in line_list:
113. url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&pn='
114. tot = Find(url,A)
115. Recommend = recommend(url) # 记录相关推荐
116. print('经过检测%s类图片共有%d张' % (word, tot))
117. file = word + '文件'
118. y = os.path.exists(file)
119. if y == 1:
120. print('该文件已存在,请重新输入')
121. file = word+'文件夹2'
122. os.mkdir(file)
123. else:
124. os.mkdir(file)
125. t = 0
126. tmp = url
127. while t < numPicture:
128. try:
129. url = tmp + str(t)
130. #result = requests.get(url, timeout=10)
131. # 这里搞了下
132. result = A.get(url, timeout=10, allow_redirects=False)
133. print(url)
134. except error.HTTPError as e:
135. print('网络错误,请调整网络后重试')
136. t = t + 60
137. else:
138. dowmloadPicture(result.text, word)
139. t = t + 60
140. numPicture = numPicture + tm
142. print('当前搜索结束,感谢使用')
如遇到bug或者有新的需求,可以给我留言。