自学javase回顾(8/10)
1、Java数组排序和查找算法—Arrays工具类
2、Java枚举类型Enum
3、Java异常Exception
1、排序和查找算法—Arrays工具类
一、数组的两种常见排序方法:冒泡排序法和选择排序法
【1】冒泡排序:
数据的两种常见排序方法:
1、冒泡排序法
int[] array={
5,2,4,6,1};
核心思维;
①冒泡排序是每次循环采用了“两两元素”比对大小然后相互对调的方法,直到把最大值放到最右边。
②每一次循环都要进行多次比较,如果左边数>右边数,则大的数交换位置到右边,
第一次循环对比原来数5,2,4,6,1的结果:2,4,5,1,6 剩余数据之间对转次数4次 5-1=4 (n-1)n表示每次循环后所剩余元素个数 5比2换,5比4换,5比6不换,6比1换(一共四次) 第一次循环完让6去了最右边,
第二次循环对比剩下数2,4,5,1的结果:2,4,1,5 剩余数据之间对转次数3次 4-1=3 以此类推 第二次循环完让5去了最右边
第三次循环对比剩下数2,4,1的结果:2,1,4 剩余数据之间对转次数2次 3-1=2 第三次循环完让4去了最右边
第四次循环对比剩下数2,1的结果:1,2 剩余数据之间对转次数1次 2-1=1 第四次循环完让2去了最右边
2、为什么每次循环完都会少一个数?
因为有第一层for循环的i巧妙作用是给第二个for卡死一个最大范围而已,然后第二层for循环j<i会随着i减少而缩小范围,因此每次少一个最右边的数(即最大值)
每次比完最大值都会去到最右边,最大值就不用了比了以此类推进行i次排序即可, 每次循环完就可以去掉一个最右边的最大值。
2、特点(死记硬背规律);乘法口诀表 j < i
①冒泡排序是两for“先倒再正”;对比后每次循环完(最大值)的元素都轮流去了最右边; 1 2 4 5 6
②冒泡排序的次数规律(死记):元素的个数为n;1、总共需要循环次数;n-1次。(因为循环一次就卡走一个最大元素,到最后两个元素循环比完就全部输出了就不用循环了,因此n-1)
2、每一次循环中剩余数据之间对转(对比)次数;n-1次 对比=对转
3、而总共需要对比(对转)次数;
(简单方便易懂) ①用元素个数n;n(n-1)/2 ;5*4/2=10
(少用,因为要涉及到每次循环中对比次数要n-1) ②具体到等差求和公式也行; (首项+末项)*项数/2 把每次循环的对比次数累加求和也行 4+3+2+1= (1+4)*4/2=10
3、总结重点;
出,只是每次比完后的元素顺序会改变,都是比较上次比完的数组顺序结果。
因此每次比完后顺序变了而已,其他一律不变的。①这个排序算法,不改变原数组内任何元素东西,只是改变顺序,其他一律不变。
②这个排序算法他甚至是不输出和遍历任何结果的(两个for内没任何输出,只比较),只是在里面比较然后对调位置而已。
②因此,其实每次循环都只是在比较{
5,2,4,6,1}这个数组内的元素,然后不输
③而最大值会去了最右边,因此每次比完后,下一次可以忽略不比了,比剩下元素的顺序即可。但是记住冒泡排序核心;
*/
package com.bipowernode.javaSE.排序算法;
public class 冒泡排序算法 {
public static void main(String[] args) {
int count = 0;
int[] array = {
9,8,10,7,6,0,11}; //死记规律;一共循环7-1次,每次循环要对比也是n-1次(n表示每次循环后所剩余元素个数)
//死记先倒序遍历再正序
//这里的数组名就看成是固定的数字即可,只是不写死而已,看成普通数字for循环不要当成遍历数组,前面循环都是读出下标数字而已,
// 真正比在第二个for里面然后,在array[j]>array[j+1]开始
for(int i=array.length-1; i>0; i--){
//外层第一次for循环表示;本来的array.length-1是表示元素最大的下标的数值,
// 但这里array.length-1表示该数组是可以最多循环n-1次的,也就是可以让数组排序n-1次。(n表示元素的个数)
// 同时这里i的巧妙作用是给第二个for卡死一个最大范围而已,每次j
//注意,这里不是遍历数组,只是普通的数字,遍历要array[i]输出
for(int j=0;j<i;j++){
//内层第二次for循环表示;才开始遍历数组的元素出来比较,同时,第二层for循环j
//例如;i为6j为0-5下标六个数【下面有j+1因此比的时候会是七个数比】 i为5j为0-4下标五个数【下面有j+1因此比的时候会是六个数比】
// i为4j为0-3下标 i为3j为0-2下标 i为2j为0-1下标 i为1j为0下标(一个数)【下面有j+1因此比的时候会是两个数比】
//注意,这里不是遍历数组,只是普通的数字,遍历要array[j]输出
count++;
if(array[j]>array[j+1]){
//表示 让每一次的循环中所剩余数据的两两元素对比和对调轮流对比一次.
int y=array[j]; //array[j]盒子里面的值先暂时放去y盒子里, 此时array[j]的盒子为空, int y=array[j];
array[j]=array[j+1]; // array[j+1]的值对调到array[j]的盒子里,鸠占鹊巢, 此时array[j+1]的盒子为空, array[j]=array[j+1];
array[j+1]=y; //于是最后让放在y盒子的array[j]的值调转到array[j+1]中, array[j+1]=y;等于array[j+1]=array[j];
//总结;y盒子相当于是一个中间暂时盒子,让array[j]和array[j+1]盒子里面的值互相调位置
}
}
}
System.out.println(count);//计数两两元素一共具体比较了几次 21次
//此时程序执行到这里已经是数组已经是排序好的,直接在两个for外面再次遍历就是排序好的。(注意上面for只是比较,不会输出和改变任何东西,只改变顺序)
for(int i3:array){
System.out.println(i3);//
}
}
}
//比较的是下标。不是具体里面的具体的值多大。
//i;7-1 七个数 遍历下标为6开始,也就是第五个数据开始到1结束 循环length-1次(元素个数-1=6次) 1 6 4 2 5
//j;0-6 七个数 遍历下标为0开始, 也就是第一个数到第i个结束 循环i次 (6次) 1 循环 5 2 4 6 6 循环 5 2 4 4 循环 5 2 5循环2
【2】选择排序:
2、选择排序法;
int[] i={
5,2,4,6,1};
选择排序是每次循环里找出最小的元素和前面的数据“对调位置”,直到放到最左边。
第一次循环:1,2,4,6,5
第二次循环:2,4,6,5
第三次循环:4,6,5
第四次循环:5,6
第五次循环:6
每次循环取出最右边的元素:1,2,4,5,6
选择排序的规律:元素的个数为n,总共需要循环n次,每次循环对调1次,对比n-1次。
3、选择排序;是每次循环里找出最小的元素值和前面的数据“对调位置”,直到把最小值放到最左边。(选择就是可以自己找出最小值去放到最左边)
冒泡排序;是每次循环采用了“两两元素”比对大小然后相互对调的方法,直到把最大值放到最右边。(冒泡就是每次最大的泡泡先出去)
总体而言选择排序比冒泡排序效率高;efficient/effective
②选择排序的次数规律(死记):元素的个数为n;1、总共需要循环次数;n-1次。(因为循环一次就卡走一个最大元素,到最后两个元素循环比完就全部输出了就不用循环了,因此n-1)
2、每一次循环中剩余数据之间对转(对比)次数;n-1次 对比=对转
3、而总共需要对比(对转)次数;
(简单方便易懂) 用元素个数n;n(n-1)/2 ;5*4/2=10
*/
package com.bipowernode.javaSE.排序算法;
public class 选择排序算法 {
public static void main(String[] args) {
int count = 0;
int[] array = {
5,2,4,6,1};
for(int i=0;i<array.length;i++){
//i是代表数组中假设起点下标为i的坐标是最小的
int min=i; //给i盒子的元素,暂存到最小值的min盒子中
for(int j=i+1;j<array.length;j++){
//巧妙之处;这里的i+1下标是为了排除了上一次已经在最左边的i下标最小值,此时i+1下标就永远确保是上一次比较过之后最小值的的右边一位元素。
count++;
if(array[j]<array[i]){
//比较j(即i+1)i右边一位和假设最左边最小值i比较;(注意此时i下标元素是暂存到min盒子中)
min=j; //因此如果j比i小成立,则说明还有右边的i+1是比左边的i还要小,则会把j(i+1)转存的min盒子中,代替i成为当前最小值。
}
}
//如果上面程序if不成立,是j(i+1)>i的话,说明这时的i还相比之下是最小值min,则证明31行的猜想是对的,说明最小值int min=i成立;不需要对换位置。下面的if(min!=i)也不需要执行了。直接比较下一个次
//如果上面程序if成立,是j(i+1)
//需要拿着这个更小的j数和最左边的i交换位置。
//这个if代表min盒子存的已经不是原来的i了,就需要执行这里了;
if(min!=i){
//(注意 能执行到这里说明此时min盒子存的已经是更小值j(i+1)了),最小值已经不是i了。说明已经存在更小的j值,需要和最左边i对换位置成为暂时的下一个最左边最小值
int y=array[min]; //更小值j(i+1)和i元素之间互换位置的固定算法 再次注意;min盒子存的已经更小值j(i+1)
array[min]=array[i];//让j(i+1)转存的i盒子中,代替i成为当前最小值。再去和下一个右边比。
array[i]=y;
// int y是桌子,array[min]是左手(苹果),array[i]是右手(草莓)
}
}
System.out.println(count);//10次 n(n-1)/2
//上面两个for分别,已经排序好了数组。直接在最外面遍历即可
for(int i3:array){
System.out.println(i3);//1 2 4 5 6
}
}
}
二、数组的两种常见查找方法:普通法查找和二分法查找、
第一种; 一个一个挨着找,直到找到为止;
第二种; 二分法查找(算法),效率较为高
【1】普通法查找:
1、挨个查找
int[] array={
5,2,4,6,1};
例如想找元素为4的下标,就一次性全部遍历出来,然后按照条件挨个查找就是这样的
package com.bipowernode.javaSE.查找算法;
public class 普通法查找 {
public static void main(String[] args) {
int[] array = {
5, 2, 4, 6, 1};
for (int i=0; i<array.length ; i++){
if(array[i]==6){
System.out.println(i);//3
return;
}
}
System.out.println("不存在该元素");//不能在for里面写,不然会循环一次都输出一次,要确保全部循环遍历之后才确定有没有;
}
}
【2】二分法查找:(前提排序好的)
1、二分法查找是对半查找,这个查找方法是基于“有顺序”的查找方法(就是得提前用冒泡或者选择排序好)。
流程;
1、二分法查找是对半查找,这个查找方法是基于“有顺序”的查找方法(就是得提前用冒泡或者选择排序好)。
2、先记下第一个元素的下标和最后一个元素的下标,这两个下标加和除以二(不管奇数还是偶数都能除,int类型结果一定为整数),得到的这个数字就是数组的中间的那个元素的下标,(就是得到中间数的下标)
3、查找的元素就是从中间元素开始找,
①如果中间元素<查找元素就往右边查找,中间元素比目标元素小,然后从中间元素的右侧第一个元素作为“起点下标”开始找,再次(起点+终点下标)/2。。。。。。。一直反复下去,知道中间元素等于要查找的元素
②如果中间元素>查找元素就往左边查找,中间元素比目标元素大,则往中间元素的左边第一个(end=mid-1)的元素作为“终点下标”开始找。再次(起点+终点下标)/2。。。。。。。一直反复下去,知道中间元素等于要查找的元素
4、举例int[] dest={
1,2,4,5,6};,先排序好才去查找,下面假如要找6
第一次寻找结果:5,6 中间元素下标:(0+5)/2 = 2 下标,得出4,4<6,说明要从中间元素的右侧+1第一个元素即5,6开始去找
第二次寻找结果:6 中间元素下标:(4+5)/2 = 4 下标,得出6,6=6,说明中间元素和查找元素一直。查找完毕
*/
package com.bipowernode.javaSE.查找算法;
import static java.util.Arrays.binarySearch;//alt+enter导入该方法,直接可以调该方法,但是这里我们自己按alt+shift+enter重写,因为可以方便自己看
public class 二分法查找 {
public static void main(String[] args) {
int[] i={
1,2,4,5,6};
int index = binarySearch(i,6);
System.out.println(index);//4
}
/* private static int binarySearch(int[] array, int dest) {
}*/
public static int binarySearch(int[] array,int dest){
//按alt+shift+enter可以直接生成重写该上一行的Array类中的方法;private变为public即可
int begin=0; //int[] i1表示;被检索的下标。int dest表示;被检索的元素/目标元素
int end=array.length-1;
int mid=(begin+end)/2;
while (begin<=end){
//只要开始元素的下标一直在结束元素的下标左边(即比他小)就有机会继续循环,直到找到“begin=end”才会return终止循环
if(dest==array[mid]){
//begin<=end的巧妙之处在于,最终当begin=end时,则说明开始和结束下标为同一个元素了,此时中间元素mid=(end+end)/2结果比为=end了
// 说明到最后筛选只剩下最后一个end元素都还没找到dest目标元素的话,那么该end元素就必须要作为mid来和dest目标元素来比较是否相等,是return mid ,不是,return -1
//通俗来讲就是;都筛剩下最后一个元素了,如果还不是最终dest元素就说明不存在该元素了,就return -1,是的话mid就作为最终的目标 return mid;
return mid; //中间元素一开始就是要找的元素,直接return中间元素结束循环即可
}else if(array[mid] < dest){
//中间元素比目标元素小,则往中间元素的右边第一个(begin=mid+1)的元素作为起点下标开始找。
begin=mid+1; //
mid=(begin+end)/2;
}else if(array[mid] > dest){
//中间元素比目标元素大,则往中间元素的左边第一个(end=mid-1)的元素作为终点下标开始找
end=mid-1;
mid=(begin+end)/2;
}
}
//相当于else,while不成功就else这里的return
return -1; //返回-1,表示元素不存的。 用上面三个while加if来找元素,如果无法找到目标元素,则无法执行while,直接来return -1;
//总之
}
}
三、Arrays工具类:java.util.Arrays
1、算法在java中实际上不精通也能工作,因为java中已经封装好了。
你要使用什么算法功能直接去调方法即可
例如;java.util.Array类就提供了一个数组工具类。
2、java.util.Arrays工具类的方法(sort排序和binarySearch查找方法):(最多的就是排序和二分法查找);
①sort排序方法工具:进行数组排序 Arrays.sort(i)排序方法;(排完序记得遍历数组即可查看结果)
②binarySearch二分法查找方法工具:进行数组查找(基于排序好的数组),查找的那个元素如果有则返回“非零”,具体是元素的int类型下标。
如果不存在则返回-1。
Arrays.binarySearch(数组名,元素名);
3、算法一般是Arrays工具类的调方法即可,但是面试很大概率会考;一定要大致理解意思
【1】java面试一般是远程面试,可以拍照记一记。
【2】冒泡或者选择排序最好就去画数字排数字,数组一次一次交换
【3】二分法查找最好就去画图。
package com.bipowernode.javaSE.排序算法;
import java.util.Scanner;
import java.util.Arrays;
public class Arrays工具类 {
public static void main(String[] args) {
// System.gc();123
System.out.println("请出入您的名字");
Scanner s = new Scanner(System.in);
String str = s.next();
System.out.println("请输出你密码");
int i = s.nextInt();
if ( str.equals("涂岳新")&& i == 123456){
System.out.println("你是真的涂岳新,成功进入系统,下面即将可以看到Arrays工具类的答案");
}else {
System.out.println("你是假的,你是臭椰果,不能看到下面的答案");
return;
}
Test.dosome();
}
}
/*①foreach一维数组;
for(元素的类型 遍历的变量名:数组名或者集合名){
System.out.println(遍历的变量名);
}*/
//演示java.util.Arrays工具类的方法(sort排序和binarySearch查找方法)
class Test {
public static void dosome( ) {
int[] i = {
7, 4, 8}; //演示sort方法工具
Arrays.sort(i);
for (int i5 : i) {
System.out.println(i5);// 4 7 8
}
int[] x={
5,2,4,6,1}; //演示binary方法工具(基于已经调用sort方法排序好的数组)
Arrays.sort(x);//这里已经把数组排序为int[] x={1,2,3,4,5,6};
int index =Arrays.binarySearch(x,6);//就是看x数组里面有没有6这个元素
System.out.println(index == -1 ? "该元素不存在" : "有该元素并且下标是" + index);//
}
}
排序查找用法高级案例:
为什么要遍历里面五个数都为默认值-1?
因为确保要盒子里不是0-101内的数字,这样就不会放随机数进去的时候,
发现重复而无法将随机数放进数组盒子里
*/
package com.bipowernode.javaSE.数组算法;
import java.lang.reflect.Array;
import java.util.Arrays;
import java.util.Random;
public class 数组默认值即栈帧为负1案例 {
public static void main(String[] args) {
/*
编写程序,生成5个不重复的随机数[0-100]。重复的话就重复生成。
最后,把这五个随机数放到数组里面,同样也要求数组这五个随机数不重复。
*/
//长度为5的int数组。默认值都是0
int[] array = new int[5];
//创建Random对象
Random r = new Random();
//循环,生成随机数
for (int i = 0;i<array.length;i++ ){
array[i] = -1;//动态初始化默认值都是0才对,但这里为什么要遍历里面五个数都为默认值-1?
// 因为确保要盒子里不是0-101内的数字,这样就不会放随机数进去的时候,发现重复而无法将随机数放进数组盒子里
}
int index = 0;
while(index < array.length){
int num = r.nextInt(101);//生成0-100随机数
//下面这一步最重要,传方法返回boolean,看数组是否存在重复随机元素。
if (!contains(array,num)){
//这里额外写一个方法返回布尔,来判断array数组有没有这个随机数num,如果false就代表盒子没有这个随机数,就能就把随机数num放进去对应下标的数组里面。
array[index] = num;
index++;//index++放里面就可以,无限循环while,直到五个随机数能够不重复进入盒子。
} //如果放到if外面,这个while循环就只能够循环5次了。这样有重复也只能五次,五次之后随机数还没进完盒子里,盒子里就会出现-1的默认值,出bug
}
//到这里才算最后都判断完了,不会出现重复的五个随机数,才一次性全部遍历该数组
for (int i = 0;i<array.length;i++){
System.out.println("第"+i+"随机数是:"+array[i]);
}
}
/*
* 单独编写一个方法,这个方法专门用来判断数组中是否包含某个元素;
* @param array02 int数组 原来int数组传进
* @param key 元素 num随机数传进
* @param return true表示包含,false表示不包含
* */
public static boolean contains(int[] array02,int key){
//int[] array继承了上面的元数组array,int key继承了上面的随机数num。
// 第一种方法;包含某个元素方法会有bug,
//下面这个方案虽然用算法,效率高,但是有bug,出现重复数-1,因为提前排序了。
/*//对数组进行排序
Arrays.sort(array);
//对数组进行二分法查找
//二分法查找结果,如果>=0说明存在这个元素,并且找到了。
int index = Arrays.binarySearch(array, key);//就是看array数组里面有没有key这个具体元素,并返回该的元素int类型下标
return index >= 0;//如果index >= 0成立,则表示true表示包含,小于0则false表示不包含*/
// 第二种方法;直接遍历一个一个筛选,无bug,但是效率慢。
for (int i = 0;i<array02.length;i++){
if (array02[i]==key){
return true; //如果数组的里面的值= 随机数元素 key 返回true 说明存在这个元素,不能放进盒子
}
return false; //返回false 说明数组没有这个随机元素,可以把随机数num放进去了
}
return false; //这里为什么也要写return false,因为上面只是if语句判断手否,但是最外层for一旦不符合i
//因此这里写 return false/或者 return true都行。因为这里只是为了for不满足条件而返回布尔,从而去结束该contains方法而已。
//上面的if (!contains(array,num),只会用到判断if里面的是true/false否。
}
}
2、Java枚举类型Enum类
枚举(就是example number 一个引用类,大多用于充当返回值类型的。)
一、什么是枚举?
①字面意思来说就是列出所有成员的意思。在java程序中就是“充当返回类型”指定返回值数目和具体内容。
②枚举自身关键字:enum(小写)
③
【1】Java 中的每一个枚举都继承自 java.lang.Enum 类。
【2】当定义一个枚举类型时,每一个枚举类型成员都可以看作是 Enum 类的“实例”,这些枚举成员默认都被 final、public, static 修饰。
【3】当使用枚举类型成员时,直接使用枚举名称调用成员即可(Color.RED)。
【4】所有枚举实例都可以调用 Enum 类的方法。( Status.一般.ordinal();)
④枚举具体作用: ,可以充当一个方法的“返回值类型”,去返回多种情况的的指定结果。((升级版的true/false))
⑤语法结构:修饰符 + enum + 枚举名{}
(枚举名和枚举内容为常量大写,可以为中文和英文)
【1】任意两个枚举成员不能具有相同的名称,且它的常数值必须在该枚举的基础类型的范围之内,多个枚举成员之间使用逗号分隔。
【2】如果没有显式地声明基础类型的枚举,那么意味着它所对应的基础类型是 int。
【3】当使用该enum类的内容属性时,要用枚举引用名.返回结果;(因为是引用类型)。Result.计算成功 /Status.优秀 /Season.Spring
【4】下面代码举例定义了表示性别的枚举类型 SexEnum 和一个表示颜色的枚举类型 Color。
public enum SexEnum
{
Male,Female;
}
public enum Color
{
RED,BLUE,GREEN,BLACK;
}
之后便可以通过枚举类型名直接引用常量,如 SexEnum.Male、Color.RED。采用枚举类型,改造程序。
二、先暂时了解捕捉异常语法;
try {
//程序执行到此处,表示以上代码没有异常
}catch (Exception e){
//程序执行到此处,表示以上代码捕捉到了异常,
}
三、总结,枚举时候时机;
当程序的返回结果超过两种情况,就不适合用三目运算符或者布尔true/false了。
当有三种,四种,五种或更多情况的时候,布尔无法满足需求了。就需要用到枚举(布尔升级版),即字面意思来说就是列出所有返回情况的意思。
每一种情况都能细数出来并且,能一枚一枚列举出来。
A、枚举基本概念代码展示:
package 枚举Enum;
public class 枚举基本概念 {
public static void main(String[] args) {
// System.out.println(10/0);//Exception in thread "main" java.lang.ArithmeticException: / by zero?
/* int result = divide(10,2);
System.out.println(result);//返回1,计算成功
int result2 = divide(10,0);
System.out.println(result2);//返回0,计算失败*/
//使用基本类型符合业务需求。
boolean result = divide(10,2);
System.out.println(result ? "计算成功":"计算失败");
boolean result2 = divide(10,0);
System.out.println(result2 ? "计算成功":"计算失败");
//使用枚举类型
Result r = divide2(10,1);
System.out.println(r);
Result r2 = divide2(10,0);
System.out.println(r2);
}
/**
*设计程序,计算两个int类型的商,计算成功返回1,计算失败返回0
* @param a int类型数据
* @param b int类型数据
* @return 1表示计算成功,0表示失败
*/
//这种有设计缺陷;因为我们只想知道计算是否成功,因此返回int类型不恰当偏离了需求,最好返回布尔类型。
/* public static int divide(int a,int b){ //设计缺陷,
try {
int c = a/b; //数学语法中,除数b不能为0。比如10/0;就会出现异常(Exception in thread "main" java.lang.ArithmeticException:/ by zero?)
//程序执行到此处,表示以上代码没有异常,返回1。
return 1;
}catch (Exception e){
//程序执行到此处,表示以上代码捕捉到了异常,返回0.
return 0;
}
}*/
//这种就不错,计算成功返回true,计算失败返回false。
public static boolean divide(int a,int b){
try {
int c = a/b; //数学语法中,被除数不能为0。比如10/0;就会出现异常(Exception in thread "main" java.lang.ArithmeticException:/ by zero?)
//程序执行到此处,表示以上代码没有异常,返回true。
return true;
}catch (Exception e){
//程序执行到此处,表示以上代码捕捉到了异常,返回false.
return false;
}
}
//使用枚举类型之后的效果
public static Result divide2(int a,int b){
try {
int c = a/b; //数学语法中,被除数不能为0。比如10/0;就会出现异常(Exception in thread "main" java.lang.ArithmeticException:/ by zero?)
//程序执行到此处,表示以上代码没有异常,
return Result.计算成功;
}catch (Exception e){
//程序执行到此处,表示以上代码捕捉到了异常,
return Result.计算失败;
}
}
}
enum Result{
//英文
计算成功,计算失败;
}
B、枚举的switch案例:
package 枚举Enum;
public class 枚举switch案例 {
public static void main(String[] args) {
Season s = Season.Spring;
switch (s){
//switch 支持 枚举类型,int,String
case Autumn://引号
System.out.println("秋天");
break;
case Spring:
System.out.println("春天");
break;
case Summer:
System.out.println("夏天");
break;
case Winter:
System.out.println("冬天");
break;
}
}
}
enum Season{
Spring,Summer,Autumn,Winter;
}
C、枚举的if使用案例:
*/
package 枚举Enum;
import java.text.ParseException;
public class 枚举if案例 {
public static void main(String[] args) throws ParseException {
System.out.println(grade(70));//优秀
}
public static Status grade(int mark){
if(mark<60){
return Status.差;
}
else if(mark>60 && mark<70){
return Status.一般;
}
else {
return Status.优秀;
}
}
}
enum Status{
//中文
差,一般,优秀;
}
3、Java异常Exception
一、什么是java异常机制?
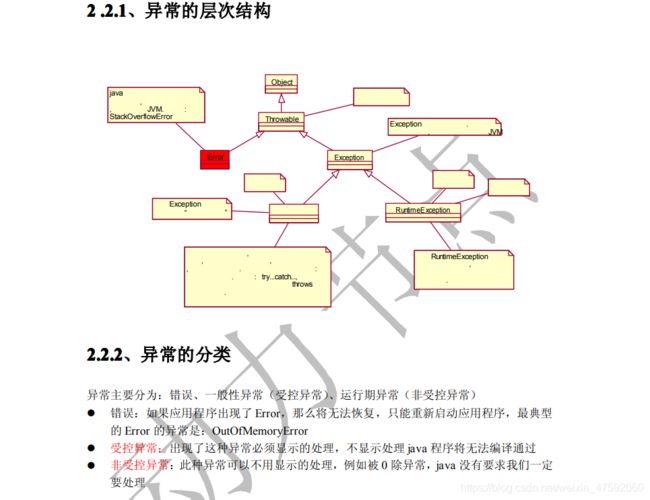
一般来说,系统在处理代码异常过程有二种结果:
1、(编译期)编译直接报错( 代码语法和环境错误(Error),只要出现错误不能处理,只有一个结果终止程序,退出JVM。
2、 (运行期)编译期虽然通过了,但却抛出了异常: 分别为编译(Exception)和运行(RuntimeException)异常。(切记都是运行时期的)
①代码和环境错误就是;代码语法错误和运行环境不正确,
②而编译和运行异常是:属于检查逻辑层面的。
例如空指针异常、数组下标越界、数字格式化异常、对象转换异常。这些逻辑错误就是异常,是可以通过程序改写来解决的。
二、Java异常分为两种异常:
!!!前提十分重要:(所有异常都出现在运行阶段,因为发生异常系统会new异常类对象报错,编译阶段new不了对象,因此只能在运行阶段出异常=new出异常类)
1、编译时异常(Exception异常 SubClass以及它的子类):
编译时异常并不是编译时出现的异常,也是在运行阶段发生的异常。
叫编译异常(受检/受控异常)是因为;程序员在编译前必须提前对这种异常做预先处理,如果没有做处理,就会报错。
2、运行时异常(RuntimeException):
运行时异常,是在运行阶段出现的异常,
叫运行异常(未受检/非受控异常)是因为;程序员可以对其做提前处理,也可以不做处理。
3、区别:编译异常比运行异常,所发生的概率要高很多。因此要预先处理,这样程序员不用一起同时处理两种异常,会活的很累。
三、如何处理异常过程:(java有一套完善机制,可给程序员自己去改正止损)
A、代码和环境错误(Error)的改正过程就是:
程序员自己增改查删,去完善和修改代码逻辑或者语法不对的地方等等。
(一般自己加if,for,while等等去判断)
B、编译和运行异常改正的过程为两种。(甩锅throws和背锅trycatch)
1、在方法名声明的位置后,(即谁调用我,我就向上抛给这个调用者,调用者是指在哪个方法作用域调用这个带有异常方法的方法名)使用throws继续一级一级向上抛出异常,抛给上一级调用者处理,直到有人去trycatch捕捉。
(即抛出异常去推卸责任交给上一级去甩锅处理,直到有人去承担捕捉这个责任,如果最后到上级也就是main向JVM上报没办法解决的话就会报错)。
2、上一级方法使用try…catch语句去捕捉异常(自行背锅处理,那么异常在捕捉之后就不会继续上报了)。
一般在main方法捕捉。(捕捉成功后,后面代码就可以执行)
3、两种区别:一个态度是甩锅让调用者处理。一个态度是自己背锅处理。
异常处之前语句可以正常执行,等执行到异常处:
①如果选择throws上报调用者处理异常之后,就会立马类似return中断该方法的作用域,异常后面的语句无法继续执行。(下面有执行顺序案例)
② 如果选择tryCatch捕捉了异常之后,即不会影响trycatch作用域之外的语句执行的,方法也不会结束。
四、异常注意点!!!!!!:
①所有异常都出现发生在运行阶段 ,因为发生异常系统会new异常类对象报错,编译阶段是new不了对象(没加载出来),因此只能在运行阶段出异常=new出异常类
②不管是sun内置异常类还是自定义异常类,自己手动去new异常类出来时是不会报错的,只是上报throws或者throw手动抛出后就一定要处理。
内置异常类,用来sun当我们出错时,自动给我们new,然后报错提醒我们,也相当于return中断程序
自定义异常类,是我们自己new,用来传递异常信息去提醒别人,并且也可以相当于return中断程序。
③因此new异常类和其他正常类一样可以new对象,但是new异常类对象并不是指去中断当前程序(因为并没有throws或者throw手动抛出,JVM会当成一个正常的类),、
真正的出异常是指这个类方法的源代码去把相关的异常抛出了,没去处理。
④异常try捕捉机制的好处!!!!;
tryCatch捕捉异常成功后,他不会耽误后面的代码程序执行,使得java程序很健壮和容错率高。
trycatch像关异常的监狱,会拘禁和处理所以的异常,然后不让异常影响trycatch外面的程序继续执行。
⑤如果有多个异常,就算处理捕捉成功,方法f1.printStackTrace();也只打印第一个异常源头。(而且是放在程序最后才输出红字)
而System.out.println(n.getMessage());是打印自定义的异常信息,因此可以打印输出多个,并且按顺序输出。
⑥try…Catch里面的异常类型可以转换,捕捉内部的异常类型可以多态,放该异常的父类异常类也行,也会指向该子类的异常类。(一般不用)
⑦ throw 关键字 VS throws 关键字 区别?
【1】thorws 是声明和处理异常的方式 ,而throw 是自己抛出异常的方式(然后再throws或者trycatch)
【2】throws:用来声明一个方法可能产生的所有异常,代表自己不能任何处理而是将异常往上传,谁调用我我就抛给谁。
用在方法声明后面,跟的是异常类名,可以跟多个异常类名,用逗号隔开
表示向调用者抛出异常,由该方法的调用者来处理
向上上报后,会中断当前程序,因此具体异常后面放语句是执行不到的。
throws表示出现异常的一种可能性,并不一定会发生这些异常。(但是也要处理)
【3】throw:则是用来抛出一个具体已发生的的异常类型。(通常用于中断程序,相当于return,必须要处理)
用在方法体内,跟的是异常对象名,只能抛出一个异常对象名
① throw就是有意而为之,自己手动抛出并且一定要处理异常,(有意传递给别人异常信息,中断程序)
②手动抛出后会中断当前程序,因此throw手动抛出自定义异常,后面放语句也是执行不到的。因此throw n 相当于 return 语句,但捕捉分支的 finally一定 会执行的
【4】因此有两种方式:
①要么是向上继续抛出一个异常给调用者(throws 异常),
要么是自己捕获异常try…catch代码块(但是尽量先上报再捕捉)
②要么在main中自定义异常后throw手动抛出的话,就直接用try当场捕捉处理
要么在其他方法自定义异常后throw手动抛出后一般先throws上报处理,到mian再try捕捉。
五、异常是以类的形式存在的;
异常类,;是一个模板(即发生了什么异常)
异常对象;实际存在的个体,(即谁发生了异常)
因此其实每次出现了异常jvm都会,没都会自动new该异常类的对象出来。
2、实际应用
火灾(异常类);
2020年9月9号 小明家里发生了火灾(异常对象)
2020年9月10号 张三家里发生了火灾(异常对象)
钱包丢了(异常类);
2020年9月9号 小红丢了钱包(异常对象)
2020年9月10号 李四丢了钱包(异常对象)
*/
public class 异常是以类和对象存在的 {
public static void main(String[] args) {
//通过“异常类”实例化“异常对象”
NullPointerException 空指针 = new NullPointerException();
System.out.println(空指针.toString()); //java.lang.NullPointerException
NumberFormatException 数字格式化 = new NumberFormatException();
System.out.println(数字格式化.toString()); //java.lang.NumberFormatException
}
}
六、如何取得异常对象的具体信息 :getMessage VS printStackTrace()
常用的方法主要有两种:
① 取得异常描述信息:getMessage()
② 取得异常的堆栈信息(比较适合于程序调试阶段):printStackTrace(); 【常用】
1、System.out.println(n.getMessage());构造信息方法;(不全面)
获得异常的基本信息,作用是:打印new的异常类中参构造方法中的自定义的异常信息
2、n.printStackTrace();方法(静态方法,可以用类,也可以用引用调)
【1】(建议多使用这个方法,养成好习惯,异常信息就使用这个犯法追踪全面,异常信息不要用system输出打印方法。)
【2】作用:是在命令行,打印异常信息在程序中出错的位置及原因,下面的程序还是可以执行的
【3】注意:并不是指发生了真的异常从而终结和退出程序,而是指把这个异常信息打印出来(what异常,why异常,where异常),(自上而下去看代码异常信息。因为是一环扣一环的) ,。
三:区别???
1、一个是输出的自定义的异常信息。(优点:自定义异常中常用,可以输出多个,并且按顺序输出)
2、一个是异常类自带的红色报错信息。(缺点:并非全部异常信息,只输出一个源头异常并且在程序最后输出)
package java1.pjpowernode.javaSE.异常.异常方法汇总;
public class 异常类的常用方法汇总 {
public static void main(String[] args) {
NullPointerException n = new NullPointerException("不好意思,空指针异常了");//
//new异常类和其他类一样可以new对象,但是new异常类对象并不是指去中断当前程序(因为并没有抛出,JVM会当成一个正常的类),
// 真的异常是指这个类方法的源代码去把相关的异常抛出了,没去处理。
System.out.println(n.getMessage());//n.getMessage());作用是打印new的异常类中参构造方法中的自定义的信息
n.printStackTrace();//printStacktrace 作用是 :在命令行打印异常信息在程序中出错的位置及原因
for (int i= 0;i<3;i++){
//下面的方法还是可以继续执行的
System.out.println(i);
}
System.out.println("你好");
}
}
/*输出顺序;
不好意思,空指针异常了
0
1
2
你好
java.lang.NullPointerException: 不好意思,空指针异常了
at java1.pjpowernode.javaSE.异常.异常方法汇总.异常类的常用方法汇总.main(异常类的常用方法汇总.java:23)
*/
六、内置异常VS自定义异常?
1、 为什么要自定义异常??
因为sun内置的异常类,不能够完全满足我们实际开发中遇到的异常。
实际业务中很多异常都是和具体的特殊业务内容挂钩的,JDK中不会有的。
2、 怎么自定义异常?(两步骤)
第一步:编写一个类,去继承Exception和RuntimeException.(看是编译还是运行异常,具体看业务遇到的异常发生的概率高不高,高的话选择编译异常,提前去处理)
第二步:提供两个构造方法,一个无参构造,一个带有String s参数(放异常信息)的有参构造。
3、 注意:如果是如果是编译异常,一旦抛出必须提前处理。
①如果在main中自定义异常后throw手动抛出的话,就直接用try当场捕捉处理
②其他方法自定义异常后throw手动抛出后一般先上报处理,到mian再try捕捉
内置异常和自定义异常展示:
package java1.pjpowernode.javaSE.异常.异常基础Exception;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class 内置异常和自定义异常举例 {
public static void main(String[] args){
//自定义Exception编译异常
MyException1 m1 = new MyException1("用户名不能为空");
try {
throw m1; //因为这是编译异常,因此一旦抛出必须提前处理。
// 如果在main中自定义异常后throw手动抛出的话,就直接用try当场捕捉处理,在其他方法自定义异常后throw手动抛出后一般先上报处理,到mian再try捕捉
} catch (MyException1 myException1) {
System.out.println(m1.getMessage());//打印异常信息
m1.printStackTrace();
}
//自定义运行RuntimeException异常
MyException2 m2 = new MyException2("用户名不能为空");
try {
throw m2; //但运行异常可以处理,可以不处理
} catch (MyException2 myException2) {
System.out.println(m2.getMessage());//打印异常信息
m2.printStackTrace();
}
//这里为sun公司JDK内置的io类,源代码里面会自带throws抛出一个FileNotFoundException编译异常。
try {
FileInputStream f = new FileInputStream("错误的文件路径"); //不用抛出异常,因为源代码会里面已经抛出了一个另外的异常。
} catch (FileNotFoundException e) {
System.out.println(e.getMessage());
e.printStackTrace();
}
//系统JDK自带的运行异常,可预先处理可不处理
NullPointerException n = new NullPointerException("空指针异常"); //自带的运行异常,手动new不会报错的。要手动把异常抛出或者上报,不处理就会报错
throw n; //实际也会报错的
//运行异常,可以不提前处理,但是也会报错,如下
/*Exception in thread "main" java.lang.NullPointerException: 空指针异常
at java1.pjpowernode.javaSE.异常.异常基础Exception.内置异常和自定义异常举例.main(内置异常和自定义异常举例.java:54)
*/
/*
但是如果是真异常,不处理一样后面也会报错
Exception in thread "main" java.lang.NullPointerException
at java1.pjpowernode.javaSE.异常.异常基础Exception.自定义异常.main(自定义异常.java:37)
*/
}
}
Throws深入学习一下:
1、throws抛出异常如果是编译异常,就必须预先处理(抛给上级或者自己捕捉),
不做预先处理,会让该方法直接报错处理,(因为抛出的异常没有处理)
2、throws抛出的异常类型必须和 出错的异常类型一致。不然无效(一般IDEA会提示)
throw注意点:一个方法体当中的代码如果执行到出现异常处之后,如果throws上报给调用者的话,则此方法体会立即马上结束作用域,如果调用者继续throws上报,则也会继续结束调用者的方法体。相当于return;(结束方法体)
trycatch捕捉后不会结束作用域,不影响后面的方法程序执行。
2、编译和运行异常(Exception)改正的过程为两种。(甩锅和背锅)
1、在方法名声明的位置后后,(谁调用我,我就抛给谁)使用throws继续上抛出异常,抛给调用者处理(抛出推卸责任交给上一级去甩锅处理,如果上级没办法解决就会报错)。
2、上一级方法使用语句,try…catch捕捉异常(自行背锅处理,那么异常在捕捉之后就不会继续上抛了)。一般在main方法捕捉
*/
public class Throws深入学习 {
public static void main (String[] args){
//main向上抛给JVM去处理,如果JVM处理得了就不报错,处理得了就不会
/*
运行异常:
一、程序执行到此处,假如发生了算数异常ArithmeticException: / by zero
底层JVM会new一个异常对象出来,然后抛出,后面的程序System.out.println("算数异常ArithmeticException");就无法执行了。
二、由于是在maiThrows深入学习n方法调用的10/0,因此ArithmeticException异常会向上抛给main方法,
main方法没有处理,就会再次抛给JVM,JVM就会接到异常然后new异常类对象终止程序。
三、public class ArithmeticException extends RuntimeException {}
从源代码可知道;
ArithmeticException父类是RuntimeException属于运行异常,因此可以不用做预见处理。
*/
// System.out.println(10/0);
System.out.println("算数异常ArithmeticException");
/*异常解决方法:
第一种;在调用该doSome方法所处的(main)方法名声明后,继续使用throws抛出异常
(抛出推卸责任交给上一级去甩锅处理,如果上级没办法解决就会报错)。
第二种;使用try{}catch(){},自己背锅捕捉异常
*/
// doSome();//因为该方法抛出了编译异常,就必须预先处理(抛给上级或者自己捕捉),ClassNotFoundException编译异常不做预先处理,不然会让该方法直接报错处理,
try{
doSome();
System.out.println("try没搜索到dosome方法有异常,就不会跳去catch分支捕捉异常,是直接输出这里的语句然后就结束了捕捉");
}catch (ClassNotFoundException e){
e.printStackTrace();
}
}
/**
* 编译异常;
*一、声明一个doSome方法,然后抛出一个“throws ClassNotFoundException类没找到异常”,因为有可能会出现这个异常。
*二、public class ClassNotFoundException extends ReflectiveOperationException {
* public class ReflectiveOperationException extends Exception}
* 三、源代码可得: ClassNotFoundException父类是Exception,属于编译异常,如果做预先处理就会报错。
* @throws ClassNotFoundException
*/
public static void doSome()throws ClassNotFoundException{
//doSome方法向上抛给了main,这里是灰色字是因为实际没有异常,只是抛出一个模拟的异常去处理。
System.out.println("ClassNotFoundException类没找到异常");
}
}
算数异常ArithmeticException
ClassNotFoundException类没找到异常
try没搜索到dosome方法有异常,就不会跳去catch分支捕捉,是直接输出这里的语句就结束了
tryCatch捕捉深入学习:
一、try...catch种类区分;?????? .
①一个try+一个catch分支;
②一个try+多个catch分支;例如
相当于if...else if...else if
try {
方法名/语句;//尝试捕捉方法
}catch(OneException e) {
异常名.方法 //处理第一个异常
}catch(TwoException e) {
异常名.方法 //处理第二个异常。可以处理,但是system下面只会输出第一个异常源头。注意
}finally {
//最后一定执行的语句。
}
二、try...catch详细语法介绍;
(trycatch像关异常的监狱,会拘禁和处理所以的异常,然后不让异常影响trycathc外面的程序继续执行。)
1、try 中包含了可能产生异常的方法或者具体代码语句。(相当于尝试搜索异常)
2、catch 中包含一个或多个catch,catch 中是需要捕获的异常。(相当于捕捉异常)
3、try深入学习!!!!!(try后面可以放:带异常的方法,java语句,throw e;, new异常对象。)
①如果try语句内部发现方法代码出异常的话:
会直接跳去下面catch捕捉异常,就永远不会输出try内部的语句,会去输出catch内部的方法去处理异常。(注意;捕捉成功后,后面代码才可以执行)。
②如果try语句内部发现方法代码没有出异常的话:
则不会跳转到 catch 中捕捉异常,任旧输出try内部的原来的方法和语句。(徐晃一枪,说明没有抛出异常,没啥事发生。任旧像原来一样执行)
4、catch及其catch分支深入学习!!!!!
③catch写多个分支的时候,异常处理顺序:必须遵守自上而下,从小到大(从子类异常到父类异常).不然报错。(必须遵守)
④Catch里面的异常类型可以转换,捕捉内部的异常类型可以多态,放该异常的父类异常类也行,也会指向该子类的异常类。(一般不用)
*/
package java1.pjpowernode.javaSE.异常.异常处理法方式;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class tryCatch捕捉深入学习 {
public static void main(String[] args) {
// 第一个案例;一个try一个catch分支;
int i1 = 100;
int i2 = 0;
//try 里是出现异常的代码
//不出现异常的代码最好不要放到 try 作用
try {
//当出现被 0 除异常,程序流程会执行到“catch(ArithmeticException ae)”语句
//被 0 除表达式以下的语句永远不会执行。
int i3 = i1/i2;
//如果是真有异常,永远不会执行。
System.out.println(i3);
//采用 catch 可以拦截异常。
//ae 代表了一个 ArithmeticException 类型的局部变量
//采用 ae 主要是来接收 java 异常体系给我们 new 的 ArithmeticException 对象
//采用 ae 可以拿到更详细的异常信息
}catch(ArithmeticException ae) {
System.out.println("被 0 除了");
}
//第二个案例;一个try多个catch分支;
try{
//new一个sun已经写好的异常类,IO输入流,此异常类构造方法的源代码会 抛出了一个throws FileNotFoundException异常
FileInputStream f = new FileInputStream("D:\\前端和java资料\\资料");//错误的路径,因为要指向具体文件的
//因此这里只能输出第一个异常;"第一个异常处理,该文件不存在或者被删除"
f.read();//调用的该类read方法源代码也抛出了一个异常throws IOException,本来要去处理的,但是上面已经出异常了,相等于return下面的语句已经不执行了。
}catch (FileNotFoundException f1){
System.out.println("第一个异常处理,该文件不存在或者被删除");
f1.printStackTrace();
}catch (IOException io){
io.printStackTrace();
System.out.println("第二个异常处理,读取文件失败"); //可以处理,但是下面这里就不会输出,
// 因此只输出源头异常,第一个异常已经相当于return,终结程序了。
}
}
}
Throws和tryCatch联用深入学习:
一、为什么要throws和tryCatch联合使用?
因为:①一般情况下,不建议main方法去throws异常,因为JVM处理不了的话,就只能终结程序,
②一般建议在main方法try...catch捕捉异常。(捕捉成功后,后面代码才可以执行)
③因此一般处理异常流程是;throws从异常源头先上报,在方法声明处使用throws继续上抛出异常,抛给上一级“调用者”处理。
上报到main方法时,就要一般建议使用try...catch捕捉异常,自己背锅解决,不要让JVM总部知道处理。
二、
总的结果:
main begin
m1 begin
m2 begin
该文件不存在,也可能被删除了
java.io.FileNotFoundException: D:\前端和java资料\资料 (拒绝访问。)
main over
三、为什么输出时没有m1和m2的over,却有main的over有?
【1】因为m3方法调用者即m2选择是throws上报m3的异常,因此如果m2调用者这里不trycatch的话,而是选择继续throws上报,则 m3();后面的语句m2 over不会执行到,直接结束m2调用者的作用域。(m1类似上述这样)
【2】 而到了m1方法调用者即main方法这里,选择的是trycatch m1的异常,则不会影响m1();后面的"main over"语句的执行
*/
package java1.pjpowernode.javaSE.异常.异常处理法方式;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class Throws和tryCatch联合使用 {
public static void main(String[] args){
//m1向上抛给JVM调用者去处理,如果JVM处理得了就不报错,因此尽量在
System.out.println("main begin");
try {
m1(); //m1方法调用者main选择的是trycatch m1的异常,则不会影响m1();后面的"main over"语句的执行。
System.out.println("try这里发现方法出异常的话,这里不会执行,会直接跳去下面catch捕捉异常,就不会输出try内部的语句");
//只要有异常这里都不会的东西都不会输出
}catch (FileNotFoundException f){
System.out.println("该文件不存在,也可能被删除了");
System.out.println(f.toString());//java.io.FileNotFoundException: D:\前端和java资料\资料 (拒绝访问。)
}
System.out.println("main over");
}
private static void m1() throws FileNotFoundException{
//main调用的m1,因此m1向上抛给main方法调用者去处理。
System.out.println("m1 begin");
m2();//因为m2方法调用者m1选择是throws上报名m2的异常,因此如果m1调用者这里不trycatch的话,
//而是选择继续throw上报,则 m2();后面的语句不会执行到,直接结束m1调用者的作用域
System.out.println("m1 over");
}
private static void m2() throws FileNotFoundException{
//m1调用的m2,因此m2向上抛给m1调用者去处理。
System.out.println("m2 begin");
m3();//因为m3方法调用者即m2选择是throws上报m3的异常,因此如果m2调用者这里不trycatch的话,
//而是选择继续throws上报,则 m3();后面的语句不会执行到,直接结束m2调用者的作用域
System.out.println("m2 over");
}
private static void m3()throws FileNotFoundException {
//m2调用的m3,因此m3向上抛给m2调用者去处理。
//创建一个IO输入流对象,指向某个文件
//public FileInputStream(String name) throws FileNotFoundException {
// this(name != null ? new File(name) : null);
//为什么报错?
// 因为从源代码得知,该类对象抛出了一个FileNotFoundException异常,这是编译异常,不做预先处理就会报错。
//解决办法?
//第一、(谁调用我,我就抛给谁)在方法声明的位置上使用throws继续上抛出给调用者处理。
// 第二、使用try...catch语句自己捕捉异常。(那么异常抛到此处就不会上报了)
//这里为sun公司JDK内置的io类,源代码里面会自带throws抛出一个FileNotFoundException编译异常。
System.out.println("异常处之前的语句还是可以执行的");
FileInputStream f = new FileInputStream("D:\\前端和java资料\\资料");
System.out.println("选择throws上报后,异常后面这里是执行不到的");
}
}
main begin
m1 begin
m2 begin
异常处之前的语句还是可以执行的
该文件不存在,也可能被删除了
java.io.FileNotFoundException: D:\前端和java资料\资料 (拒绝访问。)
main over
异常中finally关键字的使用:
try...catch 和 finally联用
finally 表示,不管是出现异常,还是没有出现异常,finally 里的代码都执行,finally 和
catch 可以分开使用,但 finally 必须和 try 一块使用,如下格式使用 finally 也是正确的
第一种;
try {
方法名/语句;//尝试捕捉方法
}catch(OneException e) {
异常名.方法 //处理第一个异常
}catch(TwoException e) {
异常名.方法 //处理第二个异常。可以处理,但是system下面只会输出第一个异常源头。注意
}finally {
//最后一定执行的语句。
}
第二种;
try {
}finally {
}
*/
package java1.pjpowernode.javaSE.异常.异常处理法方式;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class 异常中finally关键字的使用 {
public static void main(String[] args) {
FileInputStream fis = null;//最外面先定义一个流篮子,默认值为null
{
try {
System.out.println(123); //异常处之前可以执行
fis = new FileInputStream("D:\\前端和java资料\\资料");//编译异常,必须提前处理
//错误的路径,因为要指向具体文件的
System.out.println("源代码方法抛出FileNotFoundException异常,发现异常后这里就不会执行,直接跳去catch");
fis.read();//编译异常,必须提前处理
System.out.println("源代码方法抛出IOException异常,发现异常后这里就不会执行,直接跳去catch");
String s = null; //空指针异常,属于运行异常。系统不会提前报错,可以处理也可以不用处理
System.out.println(s);
System.out.println("直接发生异常,发现异常后这里就不会执行,直接跳去catch");
} catch (FileNotFoundException e) {
e.printStackTrace();
}catch (IOException IO){
IO.printStackTrace();
}catch (NullPointerException n){
n.printStackTrace();
}finally {
if ( fis != null){
try {
fis.close(); //使用完IO流之后一定要close关闭,不然系统会很危险。//但是该方法也会抛出一个异常。也要多处理一次
} catch (IOException e) {
e.printStackTrace();
}
}
}
System.out.println("trycatch语句里面的异常捕捉成功后,不会影响trycatch作用域之外的即这里的程序执行");
}
}
}
finally深入学习以及面试题:
package java1.pjpowernode.javaSE.异常.异常处理法方式;
public class 异常中finally深入学习以及面试题 {
public static void main(String[] args) {
System.out.println(print());
System.out.println(print1());
//finally VS return;语句 (两者先优先进入finally,再进入try的return终结程序)
try {
System.out.println("第一步先try执行");
return; //return最后执行,因为return必然结束方法作用域。但是finally又必须执行,因此sun规定,finally可以先执行
}finally {
System.out.println("finally第二步执行");
}
// System.out.println("这里报错无法执行,因为已经return已经结束整个main方法了");
}
//finally VS System.exit(0); (JVM强制退出,finally才能不执行)
public static void doSome(){
try {
System.out.println("第一步先try执行");
System.exit(0); //第二步执行退出JVM,不会执行finally了
}finally {
System.out.println("finally不会执行,因为强制退出了");
}
// System.out.println("这里报错无法执行,因为已经return已经结束整个main方法了");
}
//try有return值; VS finally无return值; ( 优先进入try的return 值,然后无视finally直接结束程序)。
//finally面试题:以下结果100和原因?
// 原因:为什么是100呢?java有两条亘古不变的道理。
//第一、 java方法体中的代码必须遵循自上而下的逐行顺序!!!
// 第二、 java中,return语句一旦执行,整个方法必须结束。
public static int print(){
int i = 100;
try {
System.out.println("第一步还是这里");
return i;
}finally {
i++; //结果100
}
}
//try有return值; VS finally也有return值; ( 两者都有return值;,优先进入finally的return 值,然后无视try直接结束程序)。
public static int print1(){
int i = 100;
try {
System.out.println("第一步还是这里");
return i;
}finally {
i++;
return i; //结果101
}
}
}
100
第一步还是这里
101
第一步先try执行
finally第二步执行
final 和 finally 和finalize区别?
final 和 finally 和finalize区别?
第一、
final是java语言中的一个关键字。
final表示;不可变的(adj修饰的东西不能变)。
作用;修饰变量、方法、类等。被修饰的东西东西不可变
注意:抽象类abstract不能和final组合,这两个关键字是完全对立的。 一起修饰就是非法组合。编译会直接报错
final修饰的局部变量:只能赋值一次,不能再次赋值。
final修饰的引用:无法重新再次new对象赋值,重复的对象也不行,但是可以修改对象里面具体的属性。
final修饰实例变量:必须在声明的时候就要手动赋值。(强烈推荐)(没修饰之前系统会给默认值!)
final修饰的常量:也表示固定的,不可变的常量。(本身常量就自带public static +final +类型+常量名)
final修饰的方法:无法被继承inheritance和重写overwrite
final修饰的类:无法被继承。
第二、
finally也是一个关键字。
finally表示:最终地,(adv最终一定会执行的语句块)。
作用;和try在捕捉异常机制中组合使用。最终一定去执行的语句;比如关闭一些IO流。
第三、
finalize是Object类中的一个方法,是一个方法名(标识符):
作用;当一个java类对象即将被垃圾回收器回收的时候,垃圾回收器GC会自动调用该方法。
异常和方法覆盖权限详解:
1、子类重写父类的方法,重写之后不能抛出更多数量的编译Exception异常,只能更少或者相等。(编译异常)
2、子类重写父类的方法,重写之后可以抛出更多数量的RuntimeException运行异常,也可以更少或者相等。(运行异常)
3、子类相比父类异常,可以放不同类型的异常,因为重写了。但是一定要异常数量不能多于父类的异常
4、但是一般实际开发,都是直接复制粘黏父类方法即可,父类有什么异常直接继承就行,不要画蛇添足。
package java1.pjpowernode.javaSE.异常.异常进阶学习;
public class 异常和方法覆盖权限 {
public static void main(String[] args) {
}
}
class Animal{
public void doSome(){
}
public void doit()throws Exception{
}
}
class Cat extends Animal{
// public void doSome()throws Exception{}
/*错误:(19, 16) java: java1.pjpowernode.javaSE.异常.异常进阶学习.Cat中的doSome()无法覆盖java1.pjpowernode.javaSE.异常.异常进阶学习.Animal中的doSome()
被覆盖的方法未抛出java.lang.Exception*/
//直接报错,因为子类不能比父类多异常
public void doSome()throws RuntimeException{
//运行异常可以数量比父类多,
}
public void doit(){
//编译正常,子类异常比父类更少或者一样都可以的
}
}
class Dog extends Animal{
}
异常throw综合案例一:
2、怎么自定义异常(全流程)=return中断?
第一步: 编写一个类,去继承Exception和RuntimeException.(看是编译还是运行异常,具体看业务遇到的异常发生的概率高不高,高的话选择编译异常,提前去处理)
第二步: 提供两个构造方法,一个无参构造,一个带有String s参数(其实就是放异常信息)的有参构造。
第三步: 在方法中,把这个自定义异常创建new出来,然后有参构造里面写上异常信息,
第四步: 再把这个异常自己有意而为之去抛出throw xxx;(手动抛出)。
注意1;看new的这个异常是编译还是运行异常,如果是编译异常就会马上提前报错,必须要提前处理。
注意2;如果要处理异常,new自定义异常后尽量不要自己先去try捕捉这样没有意义,(因为你是有意而为之去抛出一个异常提醒别人,)(除非一开始异常就在main方法)
一般处理方式是要先往上throws抛出。要让上级调用者知道你的异常,最后上抛到main方法再去捕捉(因为你自定义异常就是要让别人注意和小心)。
/*
//看老杜视频181集
//要求用户名长度必须在6-14.否则出异常报错。
用户密码也必须在6-14.否则出异常报错
*/
package java1.pjpowernode.javaSE.异常.异常进阶学习;
import java.util.Scanner;
public class 异常综合案例1 {
public static void main(String[] args) {
/* System.out.println("请出入您的名字");
System.out.println("请输出你密码");
Scanner s = new Scanner(System.in);*/
//这里可以不用键盘输入,直接在注册方法,传用户参数
User user = new User();
try {
//到了main方法再选择捕捉
user.register("abcdefg","1234566611111");
} catch (illegalException e) {
e.printStackTrace();
System.out.println(e.getMessage());
}
}
}
class User{
public User() {
}
//用户注册方法。
/**
* @param username 用户名长度必须在6-14.否则出异常报错
* @param password 用户密码也必须在6-14.否则出异常报错
* @throws illegalException
*/
public void register(String username, String password) throws illegalException {
if (username==null || username.length()<6 ||username.length()>14){
//用户名必须
/* System.out.println("用户名不合法");//原来的处理方式,用return
return;*/
illegalException i = new illegalException("用户名不合法");//现在处理方式,new自定义一个不合法异常,抛出。
throw i;//抛出具体会发生的异常,这里不是main方法,因此选择throws上报先,到main方法调用者,再去捕捉。
}if (password==null || password.length()<6 ||password.length()>14){
illegalException i1 = new illegalException("用户名密码不合法");//现在处理方式,new自定义一个不合法异常,抛出。
throw i1;//抛出具体会发生的异常,这里不是main方法,因此选择throws上报先,到main方法调用者,再去捕捉。
} else {
System.out.println("尊敬的"+username+"用户,恭喜您注册成功");
}
}
}
class illegalException extends Exception{
public illegalException() {
}
public illegalException(String message) {
super(message);
}
}
异常压栈弹栈案例2:
1、异常不仅分为编译和运行异常。还分为内置好异常和自定义异常。因此在开发中很常用!!!
2、为什么要自定义异常??
A、人为原因:(主要是为了传递信息,让上级调用者知道你这的异常,要让别人注意和防范,因此一般是throws上报让调用者知道和防范,不要自己去捕捉,没意义。到最后到JVMmain方法再去捕捉)
因为sun内置的异常类,不能够完全满足我们实际开发中遇到的异常。
实际业务中很多异常都是和具体的特殊业务内容挂钩的,JDK中不会有的。
B、具体程序原因;可以抛出异常,终结一个方法,不用return;
(当一个方法被执行后,有两种方式退出这个方法。
第一种方式是return终止当前方法
另外一种退出方式是,在方法执行过程中遇到了异常,并且这个异常没有在方法体内得到处理,
因此和之前的栈数据结构模拟,那里直接不用return来终结程序,直接new一个自定义异常,然后手动抛出,更高级一点)
*/
package java1.pjpowernode.javaSE.异常.异常进阶学习;
public class 自定义异常类开发案例 {
public static void main(String[] args) {
//创建一个栈对象,动态初始化容量为10
MyStack stack = new MyStack(); //这里是通过无参构造给数组赋值,和设置容量长度。也可以直接有参构造,自己赋默认值MyStack stack = new MyStack(new Object[10]);
//调用压栈方法。
try {
stack.push(new Object()); //因为引用类型,实际保存的都是内存地址,因此下面这三个都是输出对象的内存地址,因为输出引用,实际是去调toString方法,没重写toString方法只能直接输出地址。
stack.push(new Husband());//传过去实现多态Object obj = new Husband();
stack.push(new Wife());
stack.push("字符串类型对象");
stack.push(new Object());
stack.push(new Object());
stack.push(new Object());
stack.push(new Object());
stack.push(new Object());
stack.push(new Object());//栈帧为为第9时,已经满了,无法继续压栈。
stack.push(new Object());//压栈失败
stack.push(new Object());//同上
} catch (MyStackOperationException测试 myStackOperationException测试) {
// myStackOperationException测试.printStackTrace();
System.out.println(myStackOperationException测试.getMessage());
}
//开始弹栈
try {
stack.pop();
stack.pop();
stack.pop();
stack.pop();
stack.pop();
stack.pop();
stack.pop();
stack.pop();
stack.pop();
stack.pop();//此时栈帧指向-1时,栈已经空了,无法再继续往外弹出。
stack.pop();//弹栈失败了。
} catch (MyStackOperationException测试 myStackOperationException测试) {
// myStackOperationException测试.printStackTrace();
System.out.println(myStackOperationException测试.getMessage());
}
}
}
class MyStack{
private Object[] elements; //数组属性
private int index; //栈帧属性,即数组空盒子的下标=elements.length
//如果index等于0,代表栈帧指向栈顶部元素第一个元素.
//如果index等于-1,代表栈帧指向栈顶部元素的还要再上一个位置。
//因此如果index=elements.length-1(9)就说明栈帧满了。
//无参构造方法
public MyStack() {
//通过无参构造自己给参数赋默认值
this.elements = new Object[10];//
this.index = -1;//下标即每一块栈帧
}
//压栈方法,当一个方法A被调用时就产生了一个栈帧 F1,并被压入到栈中,
public void push(Object obj) throws MyStackOperationException测试 {
if (this.index >= elements.length-1){
//如果index=elements.length-1(9)就说明栈帧满了。
/*System.out.println("栈已经满了,压栈失败");
return;//直接而暴力中断当前方法;*/
//直接用自定义异常去终结程序
MyStackOperationException测试 m = new MyStackOperationException测试("压栈失败,栈已满"); //new自定义异常
throw m; //(手动抛出自定义异常)这里一开始会报错,因为这里是编译异常,必须要提前处理。
// 不要自己new异常然后自己去捕捉没有意义,尽量要用往上throws抛出方式。要让上级调用者知道你的栈已满信息。
}else{
//能执行到这说明栈没满,就继续下一个数组盒子去压栈
this.index++;//因此this.index = -1;是最好的,因为判断完然后自加++完下标为0,即数组第一个盒子。
this.elements[index]=obj; //接着把obj引用数据放进下一个盒子当中。即把当前obj数据压入栈中。(压栈)
System.out.println("压栈"+ obj.toString() +"成功,栈帧指向:" + index);//压完栈后,输出压栈状态。指向那个栈帧(盒子)
}
}
//弹栈方法。遵循“先进后出”/“后进先出”原则
/**弹栈方法。遵循“先进后出”/“后进先出”原则
*弹栈方法,从数组中往外取元素。每取出一个元素,栈帧往回移动一位即下标往回移动一位。直到栈空了,直到栈为-1时。(倒序弹栈,正序压栈)
* @return
*/
public void pop() throws MyStackOperationException测试 {
if (index < 0){
//此时index下标已经为9了,
MyStackOperationException测试 m = new MyStackOperationException测试("压栈失败,栈已满"); //new自定义异常
throw m; //(手动抛出)这里一开始会报错,因为是编译异常,要提前处理。不要自己new异常然后自己去捕捉没有意义,要往上抛出。要让上级调用者知道你的栈已满信息。
//程序执行到这里,说明栈还没空,可以继续弹。每取出一个元素,栈帧往回移动一位即下标往回移动一位。直到栈空了,即直到栈帧指向-1时。(倒序弹栈,正序压栈)
}else{
System.out.println("弹栈"+ elements[index]+"元素成功。");//此时的下标index已经为9,可以直接弹栈,先把对应的盒子元素弹出,再去往回换上一个下标继续弹上一个下标元素
index--;//(倒序弹栈,正序压栈)
System.out.println("栈帧指向"+index); //为什么要分开,因为弹出之后,当前的栈帧已经自动释放了,因此栈帧要往回指向的是上一个栈帧。
}
}
//有参构造方法
public MyStack(Object[] elements) {
this.elements = elements;
}
//getset封装该数组,不管用不用得上,要保持一个良好的习惯。
public Object[] getElements() {
return elements;
}
public void setElements(Object[] elements) {
this.elements = elements;
}
}
//编写一个类测试 Object[] elements怎么个万能法?
class Objects{
public static void dosome(){
Object[] o = {
new Husband(),new Wife(),"String字符串"};
}
}
//编写一个丈夫类
class Husband{
}
//编写一个妻子类
class Wife{
}