《设计模式的艺术》读书笔记
文章目录
- 预备知识:UML类图
-
- 类与类之间的关系
-
- 1. 关联关系
-
- (1) 双向关联
- (2) 单向关联
- (3) 自关联
- (4) 多重性关联
- (5) 聚合关系
- (6) 组合关系
- 2. 依赖关系
- 3. 泛化关系
- 4. 接口与实现关系
- 一、面向对象设计原则
-
- 1、单一职责原则(Single Responsibility Principle, SRP)
- 2、开闭原则(Open-Closed Principle, OCP)
- 3、里氏代换原则(Liskov Substitution Principle, LSP)
- 3、依赖倒转原则(Dependency Inversion Principle, DIP)
- 4、接口隔离原则(Interface Segregation Principle, ISP)
- 5、合成复用原则(Composite Reuse Principle, CRP)
- 6、迪米特法则(Law of Demeter, LoD)
- 二、六个创建型模式
-
- 1、简单工厂模式-Simple Factory Pattern——集中式工厂的实现
-
- 1)概述
- 2)结构
- 3)代码
- 4)简化
- 5)总结
-
- 1. 主要优点
- 2. 主要缺点
- 3. 适用场景
- 2、工厂方法模式-Factory Method Pattern——多态工厂的实现
-
- 1)概述
- 2)结构
- 3)代码
- 4)工厂方法的隐藏
- 5)总结
-
- 1. 主要优点
- 2. 主要缺点
- 3. 适用场景
- 3、抽象工厂模式-Abstract Factory Pattern——产品族的创建
-
- 1)产品等级结构与产品族
- 2)概述
- 3)结构
- 4)代码
- 5)“开闭原则”的倾斜性
- 6)总结
-
- 1. 主要优点
- 2. 主要缺点
- 3. 适用场景
- 4、单例模式-Singleton Pattern——确保对象的唯一性
-
- 1)动机
- 2)概述
- 3)结构
- 4)代码
- 5)饿汉式和懒汉式单例模式
-
- (1)问题引出
- (2)饿汉式(一开始就初始化单例对象)
- (3)懒汉式单例模式(需要时再实例化单例对象)
- 6)最终版本
- 7) 总结
-
- 1.主要优点
- 2.主要缺点
- 3.适用场景
- 5、原型模式-Prototype Pattern——对象的克隆
-
- 1)概述
- 2)结构
- 3)代码
- 4)浅克隆和深克隆
- 5)总结
-
- 1.主要优点
- 2.主要缺点
- 3.适用场景
- 6、建造者模式-Builder Pattern——复杂对象的组装与创建
-
- 1)概述
- 2)结构
- 3)代码
- 4)关于Director的进一步讨论
-
- 1.省略Director
- 2.钩子方法的引入
- 5)总结
-
- 1.主要优点
- 2.主要缺点
- 3.适用场景
- 三、七个结构型模式
-
- 1、适配器模式-Adapter Pattern——不兼容结构的协调
-
- 1)概述
- 2)对象适配器
- 3)类适配器模式
- 4)双向适配器
- 5)缺省适配器
- 6)代码
- 7) 总结
-
- 1. 主要优点
- 2. 主要缺点
- 3. 适用场景
- 2、桥接模式-Bridge Pattern——处理多维度变化
-
- 1)概述
- 2)示例
- 3)总结
-
- 1.主要优点
- 2.主要缺点
- 3.适用场景
- 3、组合模式-Composite Pattern——树形结构的处理
-
- 1)概述
- 2)结构
- 3)透明组合模式与安全组合模式
- 4)总结
- 4、装饰模式-Decorator Pattern——扩展系统功能
-
- 1)概述
- 2)结构
- 3)透明装饰模式与半透明装饰模式
- 4)注意事项
- 5)总结
- 5、外观模式-Facade Pattern——减少耦合
-
- 1)概述
- 2)结构
- 3)实现
- 4)抽象外观类
- 5)外观模式效果与使用场景
- 6)总结
- 6、享元模式-Flyweight Pattern——实现对象的复用
-
- 1)概述
- 2)结构
- 3)单纯享元模式和复合享元模式
- 4)几点补充
- 5)总结
- 7、代理模式-Proxy Pattern
-
- 1)概述
- 2)结构与实现
-
- 1. 远程代理
- 2.虚拟代理
- 3.缓冲代理
- 3)总结
- 四、十一个行为型模式
-
- 1、职责链模式-Chain of Responsibility Pattern——请求的链式处理
-
- 1)概述
- 2)结构与实现
- 3)解决方案
- 4)纯与不纯的职责链模式
- 5)总结
- 2、命令模式-Command Pattern——请求发送者与接收者解耦
-
- 1)概述
- 2)结构与实现
- 3)命令队列
- 4)撤销操作
- 5)请求日志
- 6)宏命令
- 7)总结
- 3、解释器模式-Interpreter Pattern——自定义语言的实现
-
- 1)概述
- 2)结构与实现
- 3)总结
- 4、迭代器模式-Iterator Pattern——遍历聚合对象中的元素
-
- 1)概述
- 2)结构与实现
- 3)总结
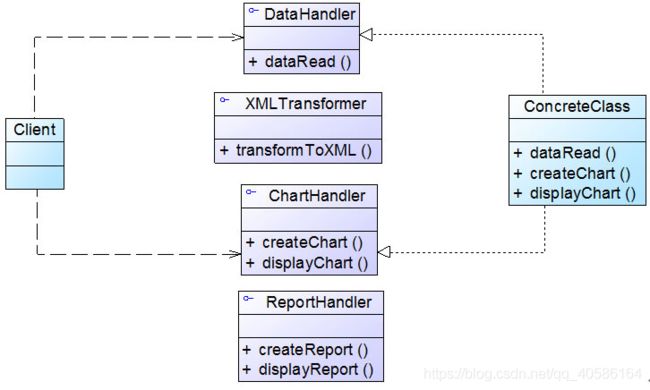
- 5、中介者模式-Mediator Pattern——协调多个对象之间的交互
-
- 1)概述
- 2)结构与实现
- 3)中介者与同事类的扩展
- 4)总结
- 6、备忘录模式-Memento Pattern——撤销功能的实现
-
- 1)概述
- 2)结构与实现
- 3)实现多次撤销
- 4)总结
- 7、观察者模式-Observer Pattern——对象间的联动
-
- 1)概述
- 2)结构与实现
- 3)总结
- 8、状态模式-State Pattern——处理对象的多种状态及其相互转换
-
- 1)概述
- 2)结构与实现
- 3)共享状态
- 4)总结
- 9、策略模式-Strategy Pattern——算法的封装与切换
-
- 1)概述
- 2)结构与实现
- 3)总结
- 10、模板方法模式-Template Method Pattern——基于继承的代码复用
-
- 1)概述
- 2)结构与实现
- 3)钩子方法的使用
- 4)总结
- 11、访问者模式-Visitor Pattern——操作复杂对象结构
-
- 1)概述
- 2)结构与实现
- 3)访问者模式与组合模式联用
- 4)总结
预备知识:UML类图
UML(统一建模语言)是当前软件开发中使用最为广泛的建模技术之一,通过使用UML可以构造软件系统的需求模型(用例模型)、静态模型、动态模型和架构模型。UML通过图形和文字符号来描述一个系统,它是绘制软件蓝图的标准语言。
在UML 2.0的13种图形中,类图是使用频率最高的UML图之一。
类图用于描述系统中所包含的类以及它们之间的相互关系,帮助人们简化对系统的理解,它是系统分析和设计阶段的重要产物,也是系统编码和测试的重要模型依据。
UML类图样式:https://blog.csdn.net/LoveLion/article/details/7838679

类与类之间的关系
1. 关联关系
关联(Association)关系是类与类之间最常用的一种关系,它是一种结构化关系,用于表示一类对象与另一类对象之间有联系,如汽车和轮胎、师傅和徒弟、班级和学生等等。在UML类图中,用实线连接有关联关系的对象所对应的类,在使用Java、C#和C++等编程语言实现关联关系时,通常将一个类的对象作为另一个类的成员变量。在使用类图表示关联关系时可以在关联线上标注角色名,一般使用一个表示两者之间关系的动词或者名词表示角色名(有时该名词为实例对象名),关系的两端代表两种不同的角色,因此在一个关联关系中可以包含两个角色名,角色名不是必须的,可以根据需要增加,其目的是使类之间的关系更加明确。
如在一个登录界面类LoginForm中包含一个JButton类型的注册按钮loginButton,它们之间可以表示为关联关系,代码实现时可以在LoginForm中定义一个名为loginButton的属性对象,其类型为JButton。如图1所示:

对应的Java代码片段如下:
public class LoginForm {
private JButton loginButton; //定义为成员变量
……
}
public class JButton {
……
}
在UML中,关联关系通常又包含如下几种形式:
(1) 双向关联
默认情况下,关联是双向的。例如:顾客(Customer)购买商品(Product)并拥有商品,反之,卖出的商品总有某个顾客与之相关联。因此,Customer类和Product类之间具有双向关联关系,如图2所示:
 对应的Java代码片段如下:
对应的Java代码片段如下:
public class Customer {
private Product[] products;
……
}
public class Product {
private Customer customer;
……
}
(2) 单向关联
类的关联关系也可以是单向的,单向关联用带箭头的实线表示。例如:顾客(Customer)拥有地址(Address),则Customer类与Address类具有单向关联关系,如图3所示:

对应的Java代码片段如下:
public class Customer {
private Address address;
……
}
public class Address {
……
}
(3) 自关联
在系统中可能会存在一些类的属性对象类型为该类本身,这种特殊的关联关系称为自关联。例如:一个节点类(Node)的成员又是节点Node类型的对象,如图4所示:
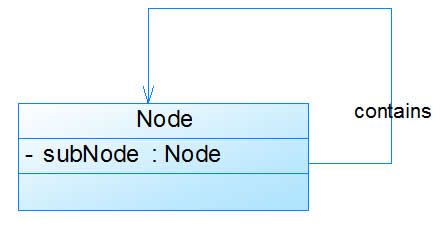
对应的Java代码片段如下:
public class Node {
private Node subNode;
……
}
(4) 多重性关联
多重性关联关系又称为重数性(Multiplicity)关联关系,表示两个关联对象在数量上的对应关系。在UML中,对象之间的多重性可以直接在关联直线上用一个数字或一个数字范围表示。
对象之间可以存在多种多重性关联关系,常见的多重性表示方式如下表所示:
| 表示方式 | 多重性说明 |
|---|---|
| 1…1 | 表示另一个类的一个对象只与该类的一个对象有关系 |
| 0…* | 表示另一个类的一个对象与该类的零个或多个对象有关系 |
| 1…* | 表示另一个类的一个对象与该类的一个或多个对象有关系 |
| 0…1 | 表示另一个类的一个对象没有或只与该类的一个对象有关系 |
| m…n | 表示另一个类的一个对象与该类最少m,最多n个对象有关系 (m≤n) |
例如:一个界面(Form)可以拥有零个或多个按钮(Button),但是一个按钮只能属于一个界面,因此,一个Form类的对象可以与零个或多个Button类的对象相关联,但一个Button类的对象只能与一个Form类的对象关联,如图5所示:

图5 多重性关联实例
图5对应的Java代码片段如下:
public class Form {
private Button[] buttons; //定义一个集合对象
……
}
public class Button {
……
}
(5) 聚合关系
聚合(Aggregation)关系表示整体与部分的关系。在聚合关系中,成员对象是整体对象的一部分,但是成员对象可以脱离整体对象独立存在。在UML中,聚合关系用带空心菱形的直线表示。例如:汽车发动机(Engine)是汽车(Car)的组成部分,但是汽车发动机可以独立存在,因此,汽车和发动机是聚合关系,如图6所示:

图6 聚合关系实例
在代码实现聚合关系时,成员对象通常作为构造方法、Setter方法或业务方法的参数注入到整体对象中,图6对应的Java代码片段如下:
public class Car {
private Engine engine;
//构造注入
public Car(Engine engine) {
this.engine = engine;
}
//设值注入
public void setEngine(Engine engine) {
this.engine = engine;
}
……
}
public class Engine {
……
}
(6) 组合关系
组合(Composition)关系也表示类之间整体和部分的关系,但是在组合关系中整体对象可以控制成员对象的生命周期,一旦整体对象不存在,成员对象也将不存在,成员对象与整体对象之间具有同生共死的关系。在UML中,组合关系用带实心菱形的直线表示。例如:人的头(Head)与嘴巴(Mouth),嘴巴是头的组成部分之一,而且如果头没了,嘴巴也就没了,因此头和嘴巴是组合关系,如图7所示:

图7 组合关系实例
在代码实现组合关系时,通常在整体类的构造方法中直接实例化成员类,图7对应的Java代码片段如下:
public class Head {
private Mouth mouth;
public Head() {
mouth = new Mouth(); //实例化成员类
}
……
}
public class Mouth {
……
}
2. 依赖关系
依赖(Dependency)关系是一种使用关系,特定事物的改变有可能会影响到使用该事物的其他事物,在需要表示一个事物使用另一个事物时使用依赖关系。大多数情况下,依赖关系体现在某个类的方法使用另一个类的对象作为参数。在UML中,依赖关系用带箭头的虚线表示,由依赖的一方指向被依赖的一方。例如:驾驶员开车,在Driver类的drive()方法中将Car类型的对象car作为一个参数传递,以便在drive()方法中能够调用car的move()方法,且驾驶员的drive()方法依赖车的move()方法,因此类Driver依赖类Car,如图1所示:
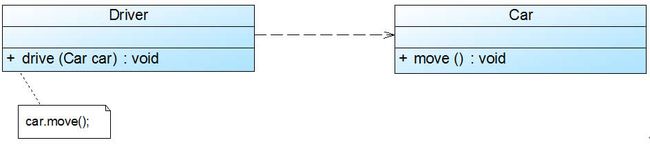
图1 依赖关系实例
在系统实施阶段,依赖关系通常通过三种方式来实现,第一种也是最常用的一种方式是如图1所示的将一个类的对象作为另一个类中方法的参数,第二种方式是在一个类的方法中将另一个类的对象作为其局部变量,第三种方式是在一个类的方法中调用另一个类的静态方法。图1对应的Java代码片段如下:
public class Driver {
public void drive(Car car) {
car.move();
}
……
}
public class Car {
public void move() {
......
}
……
}
3. 泛化关系
泛化(Generalization)关系也就是继承关系,用于描述父类与子类之间的关系,父类又称作基类或超类,子类又称作派生类。在UML中,泛化关系用带空心三角形的直线来表示。在代码实现时,我们使用面向对象的继承机制来实现泛化关系,如在Java语言中使用extends关键字、在C++/C#中使用冒号“:”来实现。例如:Student类和Teacher类都是Person类的子类,Student类和Teacher类继承了Person类的属性和方法,Person类的属性包含姓名(name)和年龄(age),每一个Student和Teacher也都具有这两个属性,另外Student类增加了属性学号(studentNo),Teacher类增加了属性教师编号(teacherNo),Person类的方法包括行走move()和说话say(),Student类和Teacher类继承了这两个方法,而且Student类还新增方法study(),Teacher类还新增方法teach()。如图2所示:
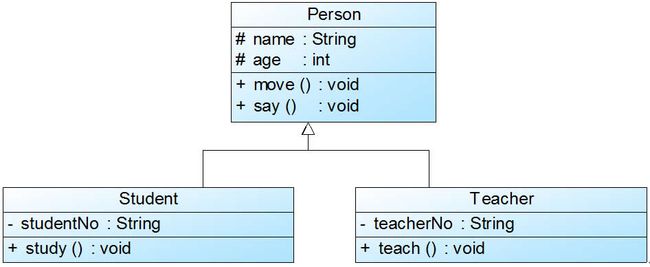
图2 泛化关系实例
图2对应的Java代码片段如下:
//父类
public class Person {
protected String name;
protected int age;
public void move() {
……
}
public void say() {
……
}
}
//子类
public class Student extends Person {
private String studentNo;
public void study() {
……
}
}
//子类
public class Teacher extends Person {
private String teacherNo;
public void teach() {
……
}
}
4. 接口与实现关系
在很多面向对象语言中都引入了接口的概念,如Java、C#等,在接口中,通常没有属性,而且所有的操作都是抽象的,只有操作的声明,没有操作的实现。UML中用与类的表示法类似的方式表示接口,如图3所示:
 图3 接口的UML图示
图3 接口的UML图示
接口之间也可以有与类之间关系类似的继承关系和依赖关系,但是接口和类之间还存在一种实现(Realization)关系,在这种关系中,类实现了接口,类中的操作实现了接口中所声明的操作。在UML中,类与接口之间的实现关系用带空心三角形的虚线来表示。例如:定义了一个交通工具接口Vehicle,包含一个抽象操作move(),在类Ship和类Car中都实现了该move()操作,不过具体的实现细节将会不一样,如图4所示:
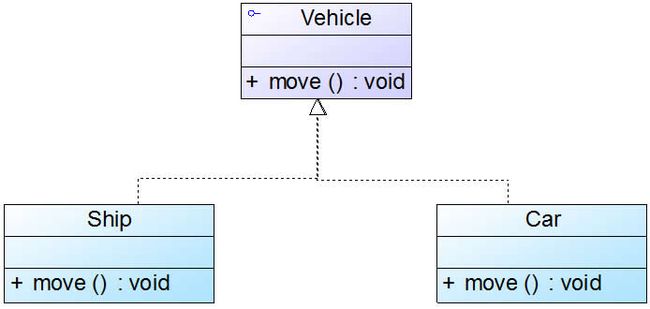 图4 实现关系实例
图4 实现关系实例
实现关系在编程实现时,不同的面向对象语言也提供了不同的语法,如在Java语言中使用implements关键字,而在C++/C#中使用冒号“:”来实现。图4对应的Java代码片段如下:
public interface Vehicle {
public void move();
}
public class Ship implements Vehicle {
public void move() {
……
}
}
public class Car implements Vehicle {
public void move() {
……
}
}
一、面向对象设计原则
表1 7种常用的面向对象设计原则
| 设计原则名称 | 定 义 | 使用频率 |
|---|---|---|
| 单一职责原则(Single Responsibility Principle, SRP) | 一个类只负责一个功能领域中的相应职责 | ★★★★☆ |
| 开闭原则(Open-Closed Principle, OCP) | 软件实体应对扩展开放,而对修改关闭 | ★★★★★ |
| 里氏代换原则(Liskov Substitution Principle, LSP) | 所有引用基类对象的地方能够透明地使用其子类的对象 | ★★★★★ |
| 依赖倒转原则(Dependence Inversion Principle, DIP) | 抽象不应该依赖于细节,细节应该依赖于抽象 | ★★★★★ |
| 接口隔离原则(Interface Segregation Principle, ISP) | 使用多个专门的接口,而不使用单一的总接口 | ★★☆☆☆ |
| 合成复用原则(Composite Reuse Principle, CRP) | 尽量使用对象组合,而不是继承来达到复用的目的 | ★★★★☆ |
| 迪米特法则(Law of Demeter, LoD) | 一个软件实体应当尽可能少地与其他实体发生相互作用 | ★★★☆☆ |
1、单一职责原则(Single Responsibility Principle, SRP)
单一职责原则是最简单的面向对象设计原则,它用于控制类的粒度大小。单一职责原则定义如下:
一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因。
单一职责原则告诉我们:一个类不能太“累”!在软件系统中,一个类(大到模块,小到方法)承担的职责越多,它被复用的可能性就越小,而且一个类承担的职责过多,就相当于将这些职责耦合在一起,当其中一个职责变化时,可能会影响其他职责的运作,因此要将这些职责进行分离,将不同的职责封装在不同的类中,即将不同的变化原因封装在不同的类中,如果多个职责总是同时发生改变则可将它们封装在同一类中。
单一职责原则是实现高内聚、低耦合的指导方针,它是最简单但又最难运用的原则
2、开闭原则(Open-Closed Principle, OCP)
开闭原则定义:一个软件实体应当对扩展开放,对修改关闭。即软件实体应尽量在不修改原有代码的情况下进行扩展。
在开闭原则的定义中,软件实体可以指一个软件模块、一个由多个类组成的局部结构或一个独立的类。
为了满足开闭原则,需要对系统进行抽象化设计,抽象化(多态)是开闭原则的关键。
3、里氏代换原则(Liskov Substitution Principle, LSP)
定义:所有引用基类(父类)的地方必须能透明地使用其子类的对象。
里氏代换原则告诉我们,在软件中将一个基类对象替换成它的子类对象,程序将不会产生任何错误和异常,反过来则不成立,如果一个软件实体使用的是一个子类对象的话,那么它不一定能够使用基类对象。例如:我喜欢动物,那我一定喜欢狗,因为狗是动物的子类;但是我喜欢狗,不能据此断定我喜欢动物,因为我并不喜欢老鼠,虽然它也是动物。
里氏代换原则是实现开闭原则的重要方式之一,由于使用基类对象的地方都可以使用子类对象,因此在程序中尽量使用基类类型来对对象进行定义,而在运行时再确定其子类类型,用子类对象来替换父类对象。
在使用里氏代换原则时需要注意如下几个问题:
- 子类的所有方法必须在父类中声明,或子类必须实现父类中声明的所有方法。根据里氏代换原则,为了保证系统的扩展性,在程序中通常使用父类来进行定义,如果一个方法只存在子类中,在父类中不提供相应的声明,则无法在以父类定义的对象中使用该方法。
- 我们在运用里氏代换原则时,尽量把父类设计为抽象类或者接口,让子类继承父类或实现父接口,并实现在父类中声明的方法,运行时,子类实例替换父类实例,我们可以很方便地扩展系统的功能,同时无须修改原有子类的代码,增加新的功能可以通过增加一个新的子类来实现。里氏代换原则是开闭原则的具体实现手段之一。
举例:
在Sunny软件公司开发的CRM系统中,客户(Customer)可以分为VIP客户(VIPCustomer)和普通客户(CommonCustomer)两类,系统需要提供一个发送Email的功能,原始设计方案如图1所示:
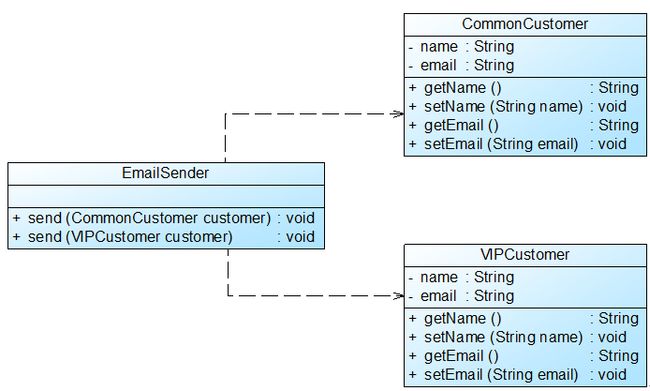
在对系统进行进一步分析后发现,无论是普通客户还是VIP客户,发送邮件的过程都是相同的,也就是说两个send()方法中的代码重复,而且在本系统中还将增加新类型的客户。为了让系统具有更好的扩展性,同时减少代码重复,使用里氏代换原则对其进行重构:
在本实例中,可以考虑增加一个新的抽象客户类Customer,而将CommonCustomer和VIPCustomer类作为其子类,邮件发送类EmailSender类针对抽象客户类Customer编程,根据里氏代换原则,能够接受基类对象的地方必然能够接受子类对象,因此将EmailSender中的send()方法的参数类型改为Customer,如果需要增加新类型的客户,只需将其作为Customer类的子类即可。
重构后的结构如图2所示:
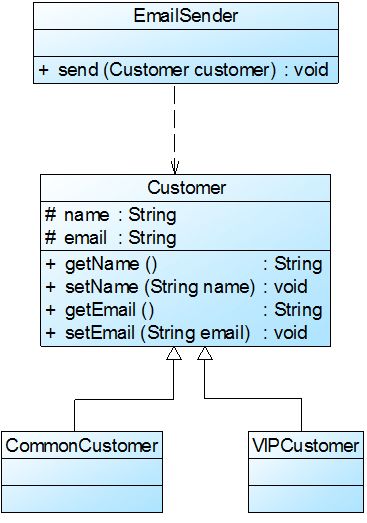
里氏代换原则是实现开闭原则的重要方式之一。在本实例中,在传递参数时使用基类对象,除此以外,在定义成员变量、定义局部变量、确定方法返回类型时都可使用里氏代换原则。针对基类编程,在程序运行时再确定具体子类。
3、依赖倒转原则(Dependency Inversion Principle, DIP)
定义:抽象不应该依赖于细节,细节应当依赖于抽象。换言之,要针对接口编程,而不是针对实现编程。
依赖倒转原则要求我们在程序代码中传递参数时或在关联关系中,尽量引用层次高的抽象层类,即使用接口和抽象类进行变量类型声明、参数类型声明、方法返回类型声明,以及数据类型的转换等,而不要用具体类来做这些事情。为了确保该原则的应用,一个具体类应当只实现接口或抽象类中声明过的方法,而不要给出多余的方法,否则将无法调用到在子类中增加的新方法。
在实现依赖倒转原则时,我们需要针对抽象层编程,而将具体类的对象通过依赖注入(DependencyInjection, DI)的方式注入到其他对象中,依赖注入是指当一个对象要与其他对象发生依赖关系时,通过抽象来注入所依赖的对象。常用的注入方式有三种,分别是:构造注入,设值注入(Setter注入)和接口注入。构造注入是指通过构造函数来传入具体类的对象,设值注入是指通过Setter方法来传入具体类的对象,而接口注入是指通过在接口中声明的业务方法来传入具体类的对象。这些方法在定义时使用的是抽象类型,在运行时再传入具体类型的对象,由子类对象来覆盖父类对象。
例子:
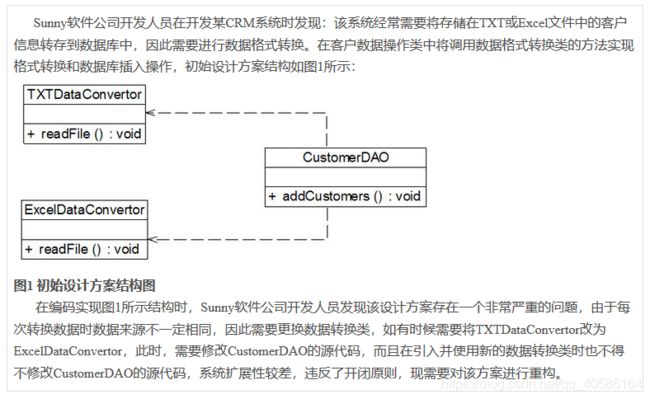
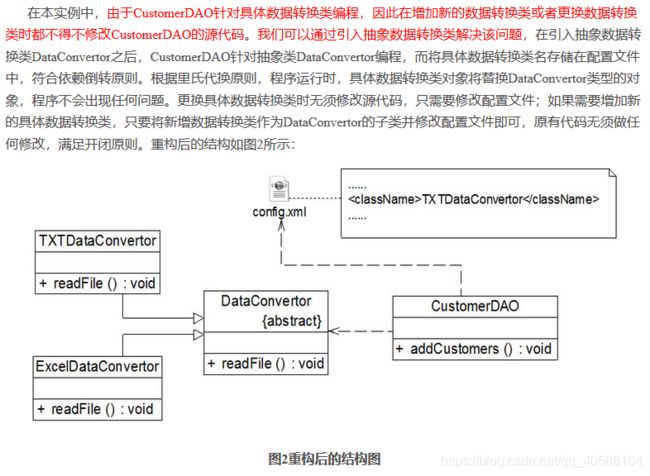
在上述重构过程中,我们使用了开闭原则、里氏代换原则和依赖倒转原则,在大多数情况下,这三个设计原则会同时出现,开闭原则是目标,里氏代换原则是基础,依赖倒转原则是手段,它们相辅相成,相互补充,目标一致,只是分析问题时所站角度不同而已。
4、接口隔离原则(Interface Segregation Principle, ISP)
定义:使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口。
根据接口隔离原则,当一个接口太大时,我们需要将它分割成一些更细小的接口,使用该接口的客户端仅需知道与之相关的方法即可。每一个接口应该承担一种相对独立的角色,不干不该干的事,该干的事都要干。
举例:

C++中可以使用多重继承来组合多个小接口。
在使用接口隔离原则时,我们需要注意控制接口的粒度,接口不能太小,如果太小会导致系统中接口泛滥,不利于维护;接口也不能太大,太大的接口将违背接口隔离原则,灵活性较差,使用起来很不方便。一般而言,接口中仅包含为某一类用户定制的方法即可,不应该强迫客户依赖于那些它们不用的方法。
5、合成复用原则(Composite Reuse Principle, CRP)
合成复用原则又称为组合/聚合复用原则(Composition/Aggregate Reuse Principle, CARP),其定义如下:
尽量使用对象组合,而不是继承来达到复用的目的。
在面向对象设计中,可以通过两种方法在不同的环境中复用已有的设计和实现,即通过组合/聚合关系或通过继承,但首先应该考虑使用组合/聚合,组合/聚合可以使系统更加灵活,降低类与类之间的耦合度,一个类的变化对其他类造成的影响相对较少;其次才考虑继承,在使用继承时,需要严格遵循里氏代换原则,有效使用继承会有助于对问题的理解,降低复杂度,而滥用继承反而会增加系统构建和维护的难度以及系统的复杂度,因此需要慎重使用继承复用。
一般而言,如果两个类之间是“Has-A”的关系应使用组合或聚合,如果是“Is-A”关系可使用继承。“Is-A"是严格的分类学意义上的定义,意思是一个类是另一个类的"一种”;而"Has-A"则不同,它表示某一个角色具有某一项责任。
6、迪米特法则(Law of Demeter, LoD)
迪米特法则又称为最少知识原则(LeastKnowledge Principle, LKP),其定义如下:
一个软件实体应当尽可能少地与其他实体发生相互作用。
如果一个系统符合迪米特法则,那么当其中某一个模块发生修改时,就会尽量少地影响其他模块,扩展会相对容易,这是对软件实体之间通信的限制,迪米特法则要求限制软件实体之间通信的宽度和深度。迪米特法则可降低系统的耦合度,使类与类之间保持松散的耦合关系。
如果一个系统符合迪米特法则,那么当其中某一个模块发生修改时,就会尽量少地影响其他模块,扩展会相对容易,这是对软件实体之间通信的限制,迪米特法则要求限制软件实体之间通信的宽度和深度。迪米特法则可降低系统的耦合度,使类与类之间保持松散的耦合关系。
迪米特法则还有几种定义形式,包括:不要和“陌生人”说话、只与你的直接朋友通信等,在迪米特法则中,对于一个对象,其朋友包括以下几类:
- 当前对象本身(this);
- 以参数形式传入到当前对象方法中的对象;
- 当前对象的成员对象;
- 如果当前对象的成员对象是一个集合,那么集合中的元素也都是朋友;
- 当前对象所创建的对象。
任何一个对象,如果满足上面的条件之一,就是当前对象的“朋友”,否则就是“陌生人”。在应用迪米特法则时,一个对象只能与直接朋友发生交互,不要与“陌生人”发生直接交互,这样做可以降低系统的耦合度,一个对象的改变不会给太多其他对象带来影响。
迪米特法则要求我们在设计系统时,应该尽量减少对象之间的交互,如果两个对象之间不必彼此直接通信,那么这两个对象就不应当发生任何直接的相互作用,如果其中的一个对象需要调用另一个对象的某一个方法的话,可以通过第三者转发这个调用。简言之,就是通过引入一个合理的第三者来降低现有对象之间的耦合度。
在将迪米特法则运用到系统设计中时,要注意下面的几点:在类的划分上,应当尽量创建松耦合的类,类之间的耦合度越低,就越有利于复用,一个处在松耦合中的类一旦被修改,不会对关联的类造成太大波及;在类的结构设计上,每一个类都应当尽量降低其成员变量和成员函数的访问权限;在类的设计上,只要有可能,一个类型应当设计成不变类;在对其他类的引用上,一个对象对其他对象的引用应当降到最低。
举例:
二、六个创建型模式
创建型模式将对象的创建和使用分离,在使用对象时无须关心对象的创建细节,从而降低系统的耦合度,让设计方案更易于修改和扩展。每一个创建型模式都采用不同的解决方案来回答三个问题:创建什么(what)、由谁创建(who)、何时创建(when)。
1、简单工厂模式-Simple Factory Pattern——集中式工厂的实现
工厂模式是最常用的一类创建型设计模式,通常我们所说的工厂模式是指工厂方法模式,它也是使用频率最高的工厂模式。本章将要学习的简单工厂模式是工厂方法模式的“小弟”,它不属于GoF 23种设计模式,但在软件开发中应用也较为频繁,通常将它作为学习其他工厂模式的入门。此外,工厂方法模式还有一位“大哥”——抽象工厂模式。这三种工厂模式各具特色,难度也逐个加大,在软件开发中它们都得到了广泛的应用,成为面向对象软件中常用的创建对象的工具。
1)概述
简单工厂模式并不属于GoF 23个经典设计模式,但通常将它作为学习其他工厂模式的基础,它的设计思想很简单,其基本流程如下:
首先将需要创建的各种不同对象(例如各种不同的Chart对象)的相关代码封装到不同的类中,这些类称为具体产品类,而将它们公共的代码进行抽象和提取后封装在一个抽象产品类中,每一个具体产品类都是抽象产品类的子类;然后提供一个工厂类用于创建各种产品,在工厂类中提供一个创建产品的工厂方法,该方法可以根据所传入的参数不同创建不同的具体产品对象;客户端只需调用工厂类的工厂方法并传入相应的参数即可得到一个产品对象。
简单工厂模式定义如下:
简单工厂模式(Simple Factory Pattern):定义一个工厂类,它可以根据参数的不同返回不同类的实例,被创建的实例通常都具有共同的父类。因为在简单工厂模式中用于创建实例的方法是静态(static)方法,因此简单工厂模式又被称为静态工厂方法(Static Factory Method)模式,它属于类创建型模式。
2)结构
简单工厂模式的要点在于:当你需要什么,只需要传入一个正确的参数,就可以获取你所需要的对象,而无须知道其创建细节。简单工厂模式结构比较简单,其核心是工厂类的设计,其结构如图1所示:
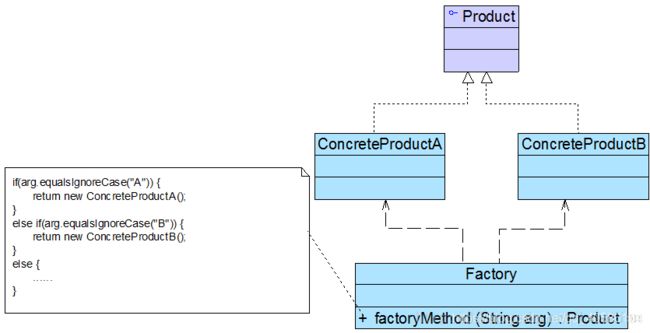
在简单工厂模式结构图中包含如下几个角色:
-
Factory(工厂角色):工厂角色即工厂类,它是简单工厂模式的核心,负责实现创建所有产品实例的内部逻辑;工厂类可以被外界直接调用,创建所需的产品对象;在工厂类中提供了静态的工厂方法factoryMethod(),它的返回类型为抽象产品类型Product。
-
Product(抽象产品角色):它是工厂类所创建的所有对象的父类,封装了各种产品对象的公有方法,它的引入将提高系统的灵活性,使得在工厂类中只需定义一个通用的工厂方法,因为所有创建的具体产品对象都是其子类对象。
-
ConcreteProduct(具体产品角色):它是简单工厂模式的创建目标,所有被创建的对象都充当这个角色的某个具体类的实例。每一个具体产品角色都继承了抽象产品角色,需要实现在抽象产品中声明的抽象方法。
在简单工厂模式中,客户端通过工厂类来创建一个产品类的实例,而无须直接使用new关键字来创建对象,它是工厂模式家族中最简单的一员。
3)代码
有一家生产处理器核的厂家,它只有一个工厂,能够生产两种型号的处理器核。客户需要什么样的处理器核,一定要显示地告诉生产工厂。下面给出一种实现方案。
enum CTYPE {
COREA, COREB};
class SingleCore
{
public:
virtual void Show() = 0;
};
//单核A
class SingleCoreA: public SingleCore
{
public:
void Show() {
cout<<"SingleCore A"<<endl; }
};
//单核B
class SingleCoreB: public SingleCore
{
public:
void Show() {
cout<<"SingleCore B"<<endl; }
};
//唯一的工厂,可以生产两种型号的处理器核,在内部判断
class Factory
{
public:
SingleCore* CreateSingleCore(enum CTYPE ctype)
{
if(ctype == COREA) //工厂内部判断
return new SingleCoreA(); //生产核A
else if(ctype == COREB)
return new SingleCoreB(); //生产核B
else
return NULL;
}
};
int main() {
SingleCore* core = Factory::CreateSingleCore(COREA);
}
4)简化
有时候,为了简化简单工厂模式,我们可以将抽象产品类和工厂类合并,将静态工厂方法移至抽象产品类中,如下图所示:
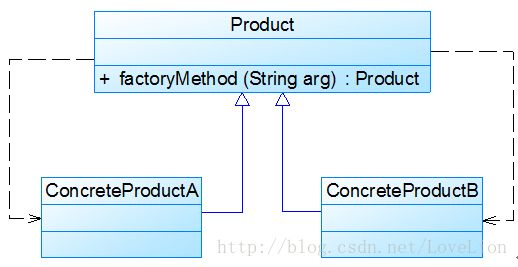
在图3中,客户端可以通过产品父类的静态工厂方法,根据参数的不同创建不同类型的产品子类对象,这种做法在JDK等类库和框架中也广泛存在。
5)总结
简单工厂模式提供了专门的工厂类用于创建对象,将对象的创建和对象的使用分离开,它作为一种最简单的工厂模式在软件开发中得到了较为广泛的应用。
1. 主要优点
简单工厂模式的主要优点如下:
- 工厂类包含必要的判断逻辑,可以决定在什么时候创建哪一个产品类的实例,客户端可以免除直接创建产品对象的职责,而仅仅“消费”产品,简单工厂模式实现了对象创建和使用的分离。
- 客户端无须知道所创建的具体产品类的类名,只需要知道具体产品类所对应的参数即可,对于一些复杂的类名,通过简单工厂模式可以在一定程度减少使用者的记忆量。
- 通过引入配置文件,可以在不修改任何客户端代码的情况下更换和增加新的具体产品类,在一定程度上提高了系统的灵活性。
2. 主要缺点
简单工厂模式的主要缺点如下:
- 由于工厂类集中了所有产品的创建逻辑,职责过重,一旦不能正常工作,整个系统都要受到影响。
- 使用简单工厂模式势必会增加系统中类的个数(引入了新的工厂类),增加了系统的复杂度和理解难度。
- 系统扩展困难,一旦添加新产品就不得不修改工厂逻辑,违背“开闭原则”,在产品类型较多时,有可能造成工厂逻辑过于复杂,不利于系统的扩展和维护。
- 简单工厂模式由于使用了静态工厂方法,造成工厂角色无法形成基于继承的等级结构。
3. 适用场景
在以下情况下可以考虑使用简单工厂模式:
- 工厂类负责创建的对象比较少,由于创建的对象较少,不会造成工厂方法中的业务逻辑太过复杂。
- 客户端只知道传入工厂类的参数,对于如何创建对象并不关心。
2、工厂方法模式-Factory Method Pattern——多态工厂的实现
1)概述
在工厂方法模式中,我们不再提供一个统一的工厂类来创建所有的产品对象,而是针对不同的产品提供不同的工厂,系统提供一个与产品等级结构对应的工厂等级结构。工厂方法模式定义如下:
定义一个用于创建对象的接口,让子类决定将哪一个类实例化。工厂方法模式让一个类的实例化延迟到其子类。工厂方法模式又简称为工厂模式(Factory Pattern),又可称作虚拟构造器模式(Virtual Constructor Pattern)或多态工厂模式(Polymorphic Factory Pattern)。工厂方法模式是一种类创建型模式。
2)结构
工厂方法模式提供一个抽象工厂接口来声明抽象工厂方法,而由其子类来具体实现工厂方法,创建具体的产品对象。工厂方法模式结构如图2所示:
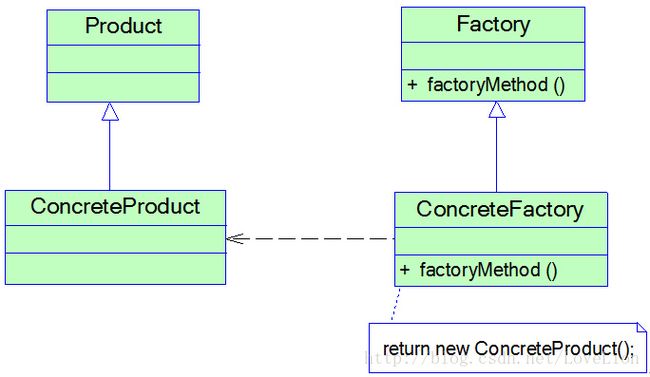
在工厂方法模式结构图中包含如下几个角色:
-
Product(抽象产品):它是定义产品的接口,是工厂方法模式所创建对象的超类型,也就是产品对象的公共父类。
-
ConcreteProduct(具体产品):它实现了抽象产品接口,某种类型的具体产品由专门的具体工厂创建,具体工厂和具体产品之间一一对应。
-
Factory(抽象工厂):在抽象工厂类中,声明了工厂方法(Factory Method),用于返回一个产品。抽象工厂是工厂方法模式的核心,所有创建对象的工厂类都必须实现该接口。
-
ConcreteFactory(具体工厂):它是抽象工厂类的子类,实现了抽象工厂中定义的工厂方法,并可由客户端调用,返回一个具体产品类的实例。
3)代码
这家生产处理器核的产家赚了不少钱,于是决定再开设一个工厂专门用来生产B型号的单核,而原来的工厂专门用来生产A型号的单核。这时,客户要做的是找好工厂,比如要A型号的核,就找A工厂要;否则找B工厂要,不再需要告诉工厂具体要什么型号的处理器核了。下面给出一个实现方案。
class SingleCore
{
public:
virtual void Show() = 0;
};
//单核A
class SingleCoreA: public SingleCore
{
public:
void Show() {
cout<<"SingleCore A"<<endl; }
};
//单核B
class SingleCoreB: public SingleCore
{
public:
void Show() {
cout<<"SingleCore B"<<endl; }
};
class Factory
{
public:
virtual SingleCore* CreateSingleCore() = 0;
};
//生产A核的工厂
class FactoryA: public Factory
{
public:
SingleCoreA* CreateSingleCore() {
return new SingleCoreA; }
};
//生产B核的工厂
class FactoryB: public Factory
{
public:
SingleCoreB* CreateSingleCore() {
return new SingleCoreB; }
};
int main() {
Factory* fac =new FactoryA;
SingleCore* core = fac->CreateSingleCore();
}
4)工厂方法的隐藏
有时候,为了进一步简化客户端的使用,还可以对客户端隐藏工厂方法,此时,在工厂类中将直接调用产品类的业务方法,客户端无须调用工厂方法创建产品,直接通过工厂即可使用所创建的对象中的业务方法。
如果对客户端隐藏工厂方法,抽象工厂类将修改为下图所示:
class Factory
{
public:
void Show(){
SingleCore* core = this->CreateSingleCore();
core->Show();
}
virtual SingleCore* CreateSingleCore() = 0;
};
调用将改为:
Factory* fac =new FactoryA;
fac->Show();
通过将业务方法的调用移入工厂类,可以直接使用工厂对象来调用产品对象的业务方法,客户端无须直接使用工厂方法,在某些情况下我们也可以使用这种设计方案。
5)总结
工厂方法模式是简单工厂模式的延伸,它继承了简单工厂模式的优点,同时还弥补了简单工厂模式的不足。工厂方法模式是使用频率最高的设计模式之一,是很多开源框架和API类库的核心模式。
1. 主要优点
工厂方法模式的主要优点如下:
- 在工厂方法模式中,工厂方法用来创建客户所需要的产品,同时还向客户隐藏了哪种具体产品类将被实例化这一细节,用户只需要关心所需产品对应的工厂,无须关心创建细节,甚至无须知道具体产品类的类名。
- 基于工厂角色和产品角色的多态性设计是工厂方法模式的关键。它能够让工厂可以自主确定创建何种产品对象,而如何创建这个对象的细节则完全封装在具体工厂内部。工厂方法模式之所以又被称为多态工厂模式,就正是因为所有的具体工厂类都具有同一抽象父类。
- 使用工厂方法模式的另一个优点是在系统中加入新产品时,无须修改抽象工厂和抽象产品提供的接口,无须修改客户端,也无须修改其他的具体工厂和具体产品,而只要添加一个具体工厂和具体产品就可以了,这样,系统的可扩展性也就变得非常好,完全符合“开闭原则”。
2. 主要缺点
工厂方法模式的主要缺点如下:
- 在添加新产品时,需要编写新的具体产品类,而且还要提供与之对应的具体工厂类,系统中类的个数将成对增加,在一定程度上增加了系统的复杂度,有更多的类需要编译和运行,会给系统带来一些额外的开销。
- 由于考虑到系统的可扩展性,需要引入抽象层,在客户端代码中均使用抽象层进行定义,增加了系统的抽象性和理解难度,且在实现时可能需要用到DOM、反射等技术,增加了系统的实现难度。
3. 适用场景
在以下情况下可以考虑使用工厂方法模式:
- 客户端不知道它所需要的对象的类。在工厂方法模式中,客户端不需要知道具体产品类的类名,只需要知道所对应的工厂即可,具体的产品对象由具体工厂类创建,可将具体工厂类的类名存储在配置文件或数据库中。
- 抽象工厂类通过其子类来指定创建哪个对象。在工厂方法模式中,对于抽象工厂类只需要提供一个创建产品的接口,而由其子类来确定具体要创建的对象,利用面向对象的多态性和里氏代换原则,在程序运行时,子类对象将覆盖父类对象,从而使得系统更容易扩展。
3、抽象工厂模式-Abstract Factory Pattern——产品族的创建
工厂方法模式通过引入工厂等级结构,解决了简单工厂模式中工厂类职责太重的问题,但由于工厂方法模式中的每个工厂只生产一类产品,可能会导致系统中存在大量的工厂类,势必会增加系统的开销。此时,我们可以考虑将一些相关的产品组成一个“产品族”,由同一个工厂来统一生产,这就是抽象工厂模式的基本思想。
1)产品等级结构与产品族
在工厂方法模式中具体工厂负责生产具体的产品,每一个具体工厂对应一种具体产品,工厂方法具有唯一性,一般情况下,一个具体工厂中只有一个或者一组重载的工厂方法。但是有时候我们希望一个工厂可以提供多个产品对象,而不是单一的产品对象,如一个电器工厂,它可以生产电视机、电冰箱、空调等多种电器,而不是只生产某一种电器。为了更好地理解抽象工厂模式,我们先引入两个概念:
- 产品等级结构:产品等级结构即产品的继承结构,如一个抽象类是电视机,其子类有海尔电视机、海信电视机、TCL电视机,则抽象电视机与具体品牌的电视机之间构成了一个产品等级结构,抽象电视机是父类,而具体品牌的电视机是其子类。
- 产品族:在抽象工厂模式中,产品族是指由同一个工厂生产的,位于不同产品等级结构中的一组产品,如海尔电器工厂生产的海尔电视机、海尔电冰箱,海尔电视机位于电视机产品等级结构中,海尔电冰箱位于电冰箱产品等级结构中,海尔电视机、海尔电冰箱构成了一个产品族。
产品等级结构与产品族示意图如下图所示:
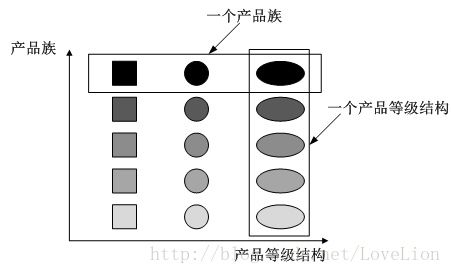
图3 产品族与产品等级结构示意图
在上图中,不同颜色的多个正方形、圆形和椭圆形分别构成了三个不同的产品等级结构,而相同颜色的正方形、圆形和椭圆形构成了一个产品族,每一个形状对象都位于某个产品族,并属于某个产品等级结构。图3中一共有五个产品族,分属于三个不同的产品等级结构。我们只要指明一个产品所处的产品族以及它所属的等级结构,就可以唯一确定这个产品。
当系统所提供的工厂生产的具体产品并不是一个简单的对象,而是多个位于不同产品等级结构、属于不同类型的具体产品时就可以使用抽象工厂模式*抽象工厂模式是所有形式的工厂模式中最为抽象和最具一般性的一种形式。抽象工厂模式与工厂方法模式最大的区别在于,工厂方法模式针对的是一个产品等级结构,而抽象工厂模式需要面对多个产品等级结构,一个工厂等级结构可以负责多个不同产品等级结构中的产品对象的创建。当一个工厂等级结构可以创建出分属于不同产品等级结构的一个产品族中的所有对象时,抽象工厂模式比工厂方法模式更为简单、更有效率。抽象工厂模式示意图如图4所示:
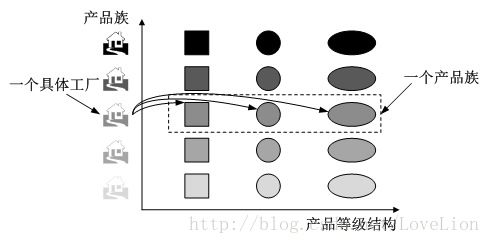
图4 抽象工厂模式示意图
在图4中,每一个具体工厂可以生产属于一个产品族的所有产品,例如生产颜色相同的正方形、圆形和椭圆形,所生产的产品又位于不同的产品等级结构中。如果使用工厂方法模式,图4所示结构需要提供15个具体工厂,而使用抽象工厂模式只需要提供5个具体工厂,极大减少了系统中类的个数。
2)概述
抽象工厂模式为创建一组对象提供了一种解决方案。与工厂方法模式相比,抽象工厂模式中的具体工厂不只是创建一种产品,它负责创建一族产品。抽象工厂模式定义如下:
提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。抽象工厂模式又称为Kit模式,它是一种对象创建型模式。(Kit:配套元件)
3)结构
在抽象工厂模式中,每一个具体工厂都提供了多个工厂方法用于产生多种不同类型的产品,这些产品构成了一个产品族,抽象工厂模式结构如下图所示:
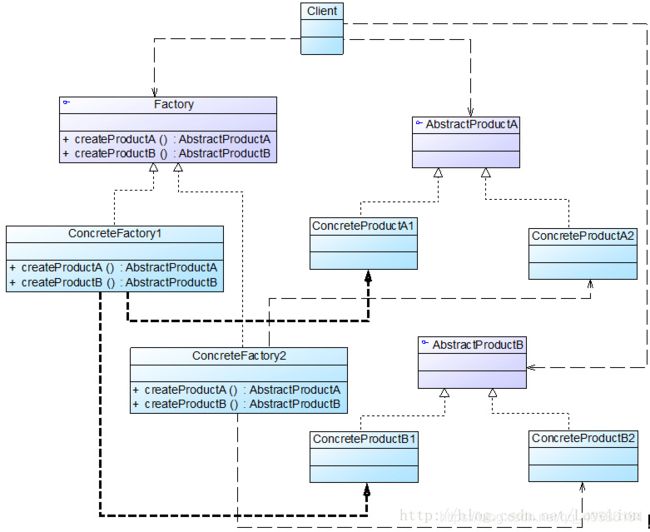
在抽象工厂模式结构图中包含如下几个角色:
- AbstractFactory(抽象工厂):它声明了一组用于创建一族产品的方法,每一个方法对应一种产品。
- ConcreteFactory(具体工厂):它实现了在抽象工厂中声明的创建产品的方法,生成一组具体产品,这些产品构成了一个产品族,每一个产品都位于某个产品等级结构中。
- AbstractProduct(抽象产品):它为每种产品声明接口,在抽象产品中声明了产品所具有的业务方法。
- ConcreteProduct(具体产品):它定义具体工厂生产的具体产品对象,实现抽象产品接口中声明的业务方法。
4)代码
这家公司的技术不断进步,不仅可以生产单核处理器,也能生产多核处理器。因此,抽象工厂模式登场了。它的定义为提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。具体这样应用,这家公司还是开设两个工厂,一个专门用来生产A型号的单核多核处理器,而另一个工厂专门用来生产B型号的单核多核处理器,下面给出实现的代码。
//单核
class SingleCore
{
public:
virtual void Show() = 0;
};
class SingleCoreA: public SingleCore
{
public:
void Show() {
cout<<"Single Core A"<<endl; }
};
class SingleCoreB :public SingleCore
{
public:
void Show() {
cout<<"Single Core B"<<endl; }
};
//多核
class MultiCore
{
public:
virtual void Show() = 0;
};
class MultiCoreA : public MultiCore
{
public:
void Show() {
cout<<"Multi Core A"<<endl; }
};
class MultiCoreB : public MultiCore
{
public:
void Show() {
cout<<"Multi Core B"<<endl; }
};
//工厂
class CoreFactory
{
public:
virtual SingleCore* CreateSingleCore() = 0;
virtual MultiCore* CreateMultiCore() = 0;
};
//工厂A,专门用来生产A型号的处理器
class FactoryA :public CoreFactory
{
public:
SingleCore* CreateSingleCore() {
return new SingleCoreA(); }
MultiCore* CreateMultiCore() {
return new MultiCoreA(); }
};
//工厂B,专门用来生产B型号的处理器
class FactoryB : public CoreFactory
{
public:
SingleCore* CreateSingleCore() {
return new SingleCoreB(); }
MultiCore* CreateMultiCore() {
return new MultiCoreB(); }
};
int main() {
CoreFactory * fac =new FactoryA;
SingleCore* singleCore = fac->CreateSingleCore();
MultiCore* multiCore = fac->CreateMultiCore();
}
5)“开闭原则”的倾斜性
在抽象工厂模式中,增加新的产品族很方便,但是增加新的产品等级结构很麻烦,抽象工厂模式的这种性质称为 "开闭原则"的倾斜性 。“开闭原则”要求系统对扩展开放,对修改封闭,通过扩展达到增强其功能的目的,对于涉及到多个产品族与多个产品等级结构的系统,其功能增强包括两方面:
- 增加产品族:对于增加新的产品族,抽象工厂模式很好地支持了“开闭原则”,只需要增加具体产品并对应增加一个新的具体工厂,对已有代码无须做任何修改。
- 增加新的产品等级结构:对于增加新的产品等级结构,需要修改所有的工厂角色,包括抽象工厂类,在所有的工厂类中都需要增加生产新产品的方法,违背了“开闭原则”。
正因为抽象工厂模式存在“开闭原则”的倾斜性,它以一种倾斜的方式来满足“开闭原则”,为增加新产品族提供方便,但不能为增加新产品结构提供这样的方便,因此要求设计人员在设计之初就能够全面考虑,不会在设计完成之后向系统中增加新的产品等级结构,也不会删除已有的产品等级结构,否则将会导致系统出现较大的修改,为后续维护工作带来诸多麻烦。
6)总结
抽象工厂模式是工厂方法模式的进一步延伸,由于它提供了功能更为强大的工厂类并且具备较好的可扩展性,在软件开发中得以广泛应用,尤其是在一些框架和API类库的设计中,例如在Java语言的AWT(抽象窗口工具包)中就使用了抽象工厂模式,它使用抽象工厂模式来实现在不同的操作系统中应用程序呈现与所在操作系统一致的外观界面。抽象工厂模式也是在软件开发中最常用的设计模式之一。
1. 主要优点
抽象工厂模式的主要优点如下:
- 抽象工厂模式隔离了具体类的生成,使得客户并不需要知道什么被创建。由于这种隔离,更换一个具体工厂就变得相对容易,所有的具体工厂都实现了抽象工厂中定义的那些公共接口,因此只需改变具体工厂的实例,就可以在某种程度上改变整个软件系统的行为。
- 当一个产品族中的多个对象被设计成一起工作时,它能够保证客户端始终只使用同一个产品族中的对象。
- 增加新的产品族很方便,无须修改已有系统,符合“开闭原则”。
2. 主要缺点
抽象工厂模式的主要缺点如下:
增加新的产品等级结构麻烦,需要对原有系统进行较大的修改,甚至需要修改抽象层代码,这显然会带来较大的不便,违背了“开闭原则”。
3. 适用场景
在以下情况下可以考虑使用抽象工厂模式:
- 一个系统不应当依赖于产品类实例如何被创建、组合和表达的细节,这对于所有类型的工厂模式都是很重要的,用户无须关心对象的创建过程,将对象的创建和使用解耦。
- 系统中有多于一个的产品族,而每次只使用其中某一产品族。可以通过配置文件等方式来使得用户可以动态改变产品族,也可以很方便地增加新的产品族。
- 属于同一个产品族的产品将在一起使用,这一约束必须在系统的设计中体现出来。同一个产品族中的产品可以是没有任何关系的对象,但是它们都具有一些共同的约束,如同一操作系统下的按钮和文本框,按钮与文本框之间没有直接关系,但它们都是属于某一操作系统的,此时具有一个共同的约束条件:操作系统的类型。
- 产品等级结构稳定,设计完成之后,不会向系统中增加新的产品等级结构或者删除已有的产品等级结构。
4、单例模式-Singleton Pattern——确保对象的唯一性
1)动机
对于一个软件系统的某些类而言,我们无须创建多个实例。比如Windows的任务管理器,通常情况下,无论我们启动任务管理多少次,Windows系统始终只能弹出一个任务管理器窗口,也就是说在一个Windows系统中,任务管理器存在唯一性。这样设计的原因:1.重复对象会造成资源浪费,根本没有必要显示多个内容完全相同的窗口;2.如果弹出的多个窗口内容不一致,问题就更加严重了。
为了节约系统资源,有时需要确保系统中某个类只有唯一一个实例,当这个唯一实例创建成功之后,我们无法再创建一个同类型的其他对象,所有的操作都只能基于这个唯一实例。为了确保对象的唯一性,我们可以通过单例模式来实现。
2)概述
单例模式(Singleton Pattern)定义:确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,它提供全局访问的方法。单例模式是一种对象创建型模式。
单例模式有三个要点:
- 某个类只能有一个实例;
- 它必须自行创建这个实例;
- 它必须自行向整个系统提供这个实例。
3)结构
单例模式是结构最简单的设计模式一,在它的核心结构中只包含一个被称为单例类的特殊类。单例模式UML图如下所示:

单例模式结构图中只包含一个单例角色:
- Singleton(单例):在单例类的内部实现只生成一个实例,同时它提供一个静态的getInstance()工厂方法,让客户可以访问它的唯一实例;为了防止在外部对其实例化,将其构造函数设计为私有;在单例类内部定义了一个Singleton类型的静态对象,作为外部共享的唯一实例。
4)代码
//Singleton.h
class Singleton
{
public:
static Singleton* getInstance();
private:
Singleton() {
}
//static函数只能访问静态成员变量或函数,所以必须为static
static Singleton *singleton;
};
//Singleton.cpp
//静态非const整型成员变量必须在类外定义
Singleton* Singleton::singleton = NULL;
Singleton* Singleton::getInstance()
{
if(singleton == NULL)
singleton = new Singleton();
return singleton;
}
5)饿汉式和懒汉式单例模式
(1)问题引出
上述代码不符合线程安全,竞态条件:当第一个getInstance()函数的new未结束时singleton仍为NULL,此时第二次使用getInstance()会导致多次new对象,不符合单例要求。
因此引出饿汉式和懒汉式单例模式:
(2)饿汉式(一开始就初始化单例对象)
//写法一
class EagerSingleton
{
public:
static EagerSingleton* getInstance(){
return instance;
}
~EagerSingleton() {
cout<<"销毁"<<endl;}
private:
EagerSingleton() {
cout<<"创建"<<endl;}
static EagerSingleton *instance;
};
EagerSingleton * EagerSingleton::instance = new EagerSingleton();
//写法二
class EagerSingleton
{
public:
static EagerSingleton* getInstance(){
return &instance;
}
~EagerSingleton() {
cout<<"销毁"<<endl;}
private:
EagerSingleton() {
cout<<"创建"<<endl;}
static EagerSingleton instance;
};
EagerSingleton EagerSingleton::instance;
写法一需要手动delete。
由于在定义静态变量的时候实例化单例类,因此在类加载的时候就已经创建了单例对象,可确保单例对象的唯一性。
缺点:无论系统运行时是否需要使用该单例对象,都会在类加载时创建对象,资源利用效率不高。
(3)懒汉式单例模式(需要时再实例化单例对象)
class Singleton
{
public:
static Singleton* GetInstance()
{
if (p_singleton_ == nullptr)//第一次检查:实例化单例对象后,就不会再进入加锁逻辑
{
std::lock_guard<std::mutex> lock(mux_);
if (p_singleton_ == nullptr)//第二次检查:可能两个线程同时通过第一次检查,一个线程获得锁时,可能另外一个线程已经实例化单体
{
p_singleton_ = new Singleton();
}
}
return p_singleton_;
}
private:
Singleton() {
}
static Singleton * p_singleton_ ;
static std::mutex mux_;
};
std::mutex Singleton::mux_;
Singleton * Singleton::p_singleton_ = nullptr;
int main()
{
auto p1 = Singleton::GetInstance();
auto p2 = Singleton::GetInstance();
bool result=( p1 == p2);
std::cout << result << std::endl;
return 0;
}
需要双重检查锁定,原因:
- 如果只是锁定+一次检查,则每次调用都要加锁,大大降低了性能;
- 如果只是一次检查+锁定,则会出现竞态条件。
但是,C++11自带两段检查锁机制来确保static变量实例化一次,因此:
6)最终版本
class Singleton
{
public:
static Singleton* GetInstance()
{
static Singleton singleton;//此变量存在静态区,C++11自带两段检查锁机制来确保static变量实例化一次
return &singleton;
}
private:
Singleton() {
}
};
7) 总结
单例模式作为一种目标明确、结构简单、理解容易的设计模式,在软件开发中使用频率相当高,在很多应用软件和框架中都得以广泛应用。
1.主要优点
单例模式的主要优点如下:
- 单例模式提供了对唯一实例的受控访问。因为单例类封装了它的唯一实例,所以它可以严格控制客户怎样以及何时访问它。
- 由于在系统内存中只存在一个对象,因此可以节约系统资源,对于一些需要频繁创建和销毁的对象单例模式无疑可以提高系统的性能。
- 允许可变数目的实例。基于单例模式我们可以进行扩展,使用与单例控制相似的方法来获得指定个数的对象实例,既节省系统资源,又解决了单例单例对象共享过多有损性能的问题。
2.主要缺点
单例模式的主要缺点如下:
- 由于单例模式中没有抽象层,因此单例类的扩展有很大的困难。
- 单例类的职责过重,在一定程度上违背了“单一职责原则”。因为单例类既充当了工厂角色,提供了工厂方法,同时又充当了产品角色,包含一些业务方法,将产品的创建和产品的本身的功能融合到一起。
- 现在很多面向对象语言(如Java、C#)的运行环境都提供了自动垃圾回收的技术,因此,如果实例化的共享对象长时间不被利用,系统会认为它是垃圾,会自动销毁并回收资源,下次利用时又将重新实例化,这将导致共享的单例对象状态的丢失。
3.适用场景
在以下情况下可以考虑使用单例模式:
- 系统只需要一个实例对象,如系统要求提供一个唯一的序列号生成器或资源管理器,或者需要考虑资源消耗太大而只允许创建一个对象。
- 客户调用类的单个实例只允许使用一个公共访问点,除了该公共访问点,不能通过其他途径访问该实例。
5、原型模式-Prototype Pattern——对象的克隆
如何在一个面向对象系统中实现对象的复制与粘贴?原型模式正为解决这类问题诞生。
与拷贝构造函数的区别在于:拷贝构造函数无法实现多态,因为构造函数必须在编译时指定构造大小,无法为虚函数。
也就是说原型模式能够通过基类指针来复制派生类对象,拷贝构造函数完不成这样的任务。拷贝构造函数是原型模式的一种实现方法。
1)概述
在使用原型模式时,我们需要首先创建一个原型对象,再通过复制这个原型对象来创建更多同类型的对象。原型模式的定义如下:
原型模式(Prototype Pattern):使用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。原型模式是一种对象创建型模式。
原型模式的工作原理很简单:将一个原型对象传给那个要发动创建的对象,这个要发动创建的对象通过请求原型对象拷贝自己来实现创建过程。由于在软件系统中我们经常会遇到需要创建多个相同或者相似对象的情况,因此原型模式在真实开发中的使用频率还是非常高的。原型模式是一种“另类”的创建型模式,创建克隆对象的工厂就是原型类自身,工厂方法由克隆方法来实现。
需要注意的是通过克隆方法所创建的对象是全新的对象,它们在内存中拥有新的地址,通常对克隆所产生的对象进行修改对原型对象不会造成任何影响,每一个克隆对象都是相互独立的。通过不同的方式修改可以得到一系列相似但不完全相同的对象。
2)结构
原型模式的结构如图7-2所示:
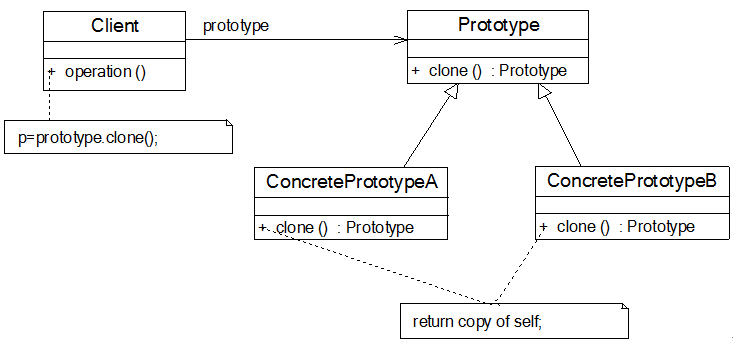
图7-2 原型模式结构图
在原型模式结构图中包含如下几个角色:
- Prototype(抽象原型类):它是声明克隆方法的接口,是所有具体原型类的公共父类,可以是抽象类也可以是接口,甚至还可以是具体实现类。
- ConcretePrototype(具体原型类):它实现在抽象原型类中声明的克隆方法,在克隆方法中返回自己的一个克隆对象。
- Client(客户类):让一个原型对象克隆自身从而创建一个新的对象,在客户类中只需要直接实例化或通过工厂方法等方式创建一个原型对象,再通过调用该对象的克隆方法即可得到多个相同的对象。由于客户类针对抽象原型类Prototype编程,因此用户可以根据需要选择具体原型类,系统具有较好的可扩展性,增加或更换具体原型类都很方便。
3)代码
class base
{
public :
base();
base(base &obj);
virtual ~base();
virtual base *clone() {
return new base(*this) ; };
};
class derived : public base
{
public :
derived();
derived(derived &);
virtual base *clone(){
return new derived (*this); }
//....
};
int main(){
base *obj1 = new base ;
base *obj2 = new derived ;
base *obj3 = obj1->clone();
//考虑到可能内存泄漏,使用智能指针
shared_ptr<base> obj3(obj1->clone());
shared_ptr<base> obj4(obj2->clone());
//不使用原型模式的克隆
shared_ptr<base> obk5(new derived(*dynamic_cast<derived*>(obj2)));
}
4)浅克隆和深克隆
当被拷贝的对象成员变量包含指针或引用时,就要考虑到浅拷贝和深拷贝:
- 浅拷贝:只拷贝指针和引用,共享 指针和引用指向的对象;
- 深拷贝:对指针和引用指向的对象进行拷贝,使每个对象拥有独立的资源。
缺省拷贝构造函数在拷贝过程中是按字节复制的,对于指针型成员变量只复制指针本身,而不复制指针所指向的目标——浅拷贝。
通过修改拷贝构造函数可以选择浅拷贝或深拷贝。
使用浅拷贝的克隆方法叫浅克隆,使用深拷贝的克隆方法叫深克隆。
5)总结
原型模式作为一种快速创建大量相同或相似对象的方式,在软件开发中应用较为广泛,很多软件提供的复制(Ctrl + C)和粘贴(Ctrl + V)操作就是原型模式的典型应用,下面对该模式的使用效果和适用情况进行简单的总结。
1.主要优点
原型模式的主要优点如下:
- 当创建新的对象实例较为复杂时,使用原型模式可以简化对象的创建过程,通过复制一个已有实例可以提高新实例的创建效率。
- 扩展性较好,由于在原型模式中提供了抽象原型类,在客户端可以针对抽象原型类进行编程,而将具体原型类写在配置文件中,增加或减少产品类对原有系统都没有任何影响。
- 原型模式提供了简化的创建结构,工厂方法模式常常需要有一个与产品类等级结构相同的工厂等级结构,而原型模式就不需要这样,原型模式中产品的复制是通过封装在原型类中的克隆方法实现的,无须专门的工厂类来创建产品。
- 可以使用深克隆的方式保存对象的状态,使用原型模式将对象复制一份并将其状态保存起来,以便在需要的时候使用(如恢复到某一历史状态),可辅助实现撤销操作。
2.主要缺点
原型模式的主要缺点如下:
- 需要为每一个类配备一个克隆方法,而且该克隆方法位于一个类的内部,当对已有的类进行改造时,需要修改源代码,违背了“开闭原则”。
- 在实现深克隆时需要编写较为复杂的代码,而且当对象之间存在多重的嵌套引用时,为了实现深克隆,每一层对象对应的类都必须支持深克隆,实现起来可能会比较麻烦。
3.适用场景
在以下情况下可以考虑使用原型模式:
- 创建新对象成本较大(如初始化需要占用较长的时间,占用太多的CPU资源或网络资源),新的对象可以通过原型模式对已有对象进行复制来获得,如果是相似对象,则可以对其成员变量稍作修改。
- 如果系统要保存对象的状态,而对象的状态变化很小,或者对象本身占用内存较少时,可以使用原型模式配合备忘录模式来实现。
- 需要避免使用分层次的工厂类来创建分层次的对象,并且类的实例对象只有一个或很少的几个组合状态,通过复制原型对象得到新实例可能比使用构造函数创建一个新实例更加方便。
6、建造者模式-Builder Pattern——复杂对象的组装与创建
1)概述
建造者模式是较为复杂的创建型模式,它将客户端与包含多个组成部分(或部件)的复杂对象的创建过程分离,客户端无须知道复杂对象的内部组成部分与装配方式,只需要知道所需建造者的类型即可。它关注如何一步一步创建一个的复杂对象,不同的具体建造者定义了不同的创建过程,且具体建造者相互独立,增加新的建造者非常方便,无须修改已有代码,系统具有较好的扩展性。
建造者模式定义: 将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。建造者模式是一种对象创建型模式。
2)结构
建造者模式一步一步创建一个复杂的对象,它允许用户只通过指定复杂对象的类型和内容就可以构建它们,用户不需要知道内部的具体构建细节。建造者模式结构如图所示:
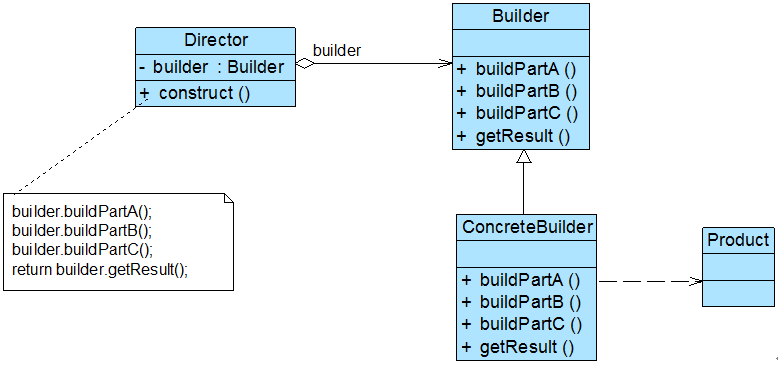
在建造者模式结构图中包含如下几个角色:
- Builder(抽象建造者):它为创建一个产品Product对象的各个部件指定抽象接口,在该接口中一般声明两类方法,一类方法是buildPartX(),它们用于创建复杂对象的各个部件;另一类方法是getResult(),它们用于返回复杂对象。Builder既可以是抽象类,也可以是接口。
- ConcreteBuilder(具体建造者):它实现了Builder接口,实现各个部件的具体构造和装配方法,定义并明确它所创建的复杂对象,也可以提供一个方法返回创建好的复杂产品对象。
- Product(产品角色):它是被构建的复杂对象,包含多个组成部件,具体建造者创建该产品的内部表示并定义它的装配过程。
- Director(指挥者):指挥者又称为导演类,它负责安排复杂对象的建造次序,指挥者与抽象建造者之间存在关联关系,可以在其construct()建造方法中调用建造者对象的部件构造与装配方法,完成复杂对象的建造。客户端一般只需要与指挥者进行交互,在客户端确定具体建造者的类型,并实例化具体建造者对象(也可以通过配置文件和反射机制),然后通过指挥者类的构造函数或者Setter方法将该对象传入指挥者类中。
在建造者模式的定义中提到了复杂对象,那么什么是复杂对象?简单来说,复杂对象是指那些包含多个成员属性的对象,这些成员属性也称为部件或零件,如汽车包括方向盘、发动机、轮胎等部件,电子邮件包括发件人、收件人、主题、内容、附件等部件。
3)代码
// Product:电脑
class Computer
{
public:
void SetmCpu(string cpu) {
m_strCpu = cpu;}
void SetmMainboard(string mainboard) {
m_strMainboard = mainboard; }
void SetmRam(string ram) {
m_strRam = ram; }
void SetVideoCard(string videoCard) {
m_strVideoCard = videoCard; }
string getCPU() {
return m_strCpu; }
string getMainboard() {
return m_strMainboard; }
string getRam() {
return m_strRam; }
string getVideoCard() {
return m_strVideoCard; }
private:
string m_strCpu; // CPU
string m_strMainboard; // 主板
string m_strRam; // 内存
string m_strVideoCard; // 显卡
};
// 建造者接口,组装流程
class IBuilder
{
public:
virtual void buildCPU() = 0; // 创建 CPU
virtual void buildMainboard() = 0; // 创建主板
virtual void buildRam() = 0; // 创建内存
virtual void buildVideoCard() = 0; // 创建显卡
shared_ptr<Computer> getResult() {
return m_pComputer; }; // 获取建造后的产品
protected:
shared_ptr<Computer> m_pComputer = make_shared<Computer>();
};
// ThinkPad 系列
class ThinkPadBuilder : public IBuilder
{
public:
void buildCPU() {
m_pComputer->SetmCpu("i5-6200U"); }
void buildMainboard() {
m_pComputer->SetmMainboard("Intel DH57DD"); }
void buildRam() {
m_pComputer->SetmRam("DDR4"); }
void buildVideoCard() {
m_pComputer->SetVideoCard("NVIDIA Geforce 920MX"); }
};
// Yoga 系列
class YogaBuilder : public IBuilder
{
public:
void buildCPU() {
m_pComputer->SetmCpu("i7-7500U"); }
void buildMainboard() {
m_pComputer->SetmMainboard("Intel DP55KG"); }
void buildRam() {
m_pComputer->SetmRam("DDR5"); }
void buildVideoCard() {
m_pComputer->SetVideoCard("NVIDIA GeForce 940MX"); }
shared_ptr<Computer> getResult() {
return m_pComputer; }
};
// 指挥者
class Director
{
public:
shared_ptr<Computer> construct(IBuilder *builder) {
builder->buildCPU();
builder->buildMainboard();
builder->buildRam();
builder->buildVideoCard();
return builder->getResult();
}
};
int main()
{
Director pDirector;
ThinkPadBuilder pTPBuilder ;
YogaBuilder pYogaBuilder;
// 组装 ThinkPad、Yoga,获取组装后的电脑
auto pThinkPadComputer = pDirector.construct(&pTPBuilder);
auto pYogaComputer = pDirector.construct(&pYogaBuilder);
// 测试输出
cout << "-----ThinkPad-----" << endl;
cout << "CPU: " << pThinkPadComputer->getCPU() << endl;
cout << "Mainboard: " << pThinkPadComputer->getMainboard() << endl;
cout << "Ram: " << pThinkPadComputer->getRam() << endl;
cout << "VideoCard: " << pThinkPadComputer->getVideoCard() << endl;
cout << "-----Yoga-----" << endl;
cout << "CPU: " << pYogaComputer->getCPU() << endl;
cout << "Mainboard: " << pYogaComputer->getMainboard() << endl;
cout << "Ram: " << pYogaComputer->getRam() << endl;
cout << "VideoCard: " << pYogaComputer->getVideoCard() << endl;
}
4)关于Director的进一步讨论
1.省略Director
在有些情况下,为了简化系统结构,可以将Director和抽象建造者Builder进行合并,在Builder中提供逐步构建复杂产品对象的construct()方法。
class IBuilder
{
public:
virtual void buildCPU() = 0; // 创建 CPU
virtual void buildMainboard() = 0; // 创建主板
virtual void buildRam() = 0; // 创建内存
virtual void buildVideoCard() = 0; // 创建显卡
shared_ptr<Computer> construct() {
this->buildCPU();
this->buildMainboard();
this->buildRam();
this->buildVideoCard();
return m_pComputer;
}
protected:
shared_ptr<Computer> m_pComputer = make_shared<Computer>();
};
客户端代码代码片段如下所示:
ThinkPadBuilder pTPBuilder ;
YogaBuilder pYogaBuilder;
// 组装 ThinkPad、Yoga,获取组装后的电脑
auto pThinkPadComputer = pTPBuilder.construct();
auto pYogaComputer = pYogaBuilder.construct();
以上对Director类的省略方式不影响系统的灵活性和可扩展性,同时还简化了系统结构,但加重了抽象建造者类的职责,如果construct()方法较为复杂,待构建产品的组成部分较多,建议还是将construct()方法单独封装在Director中,这样做更符合“单一职责原则”。
2.钩子方法的引入
建造者模式除了逐步构建一个复杂产品对象外,还可以通过Director类来更加精细地控制产品的创建过程,例如增加一类称之为钩子方法(HookMethod)的特殊方法来控制是否对某个buildPartX()的调用。
钩子方法的返回类型通常为boolean类型,方法名一般为isXXX(),钩子方法定义在抽象建造者类中,默认返回true或false。Builder实现类根据具体情况选择是否覆盖该方法,之后Director的construct方法可以根据该isXXX()的返回值来选择不同的操作。
通过引入钩子方法,我们可以在Director中对复杂产品的构建进行精细的控制,不仅指定buildPartX()方法的执行顺序,还可以控制是否需要执行某个buildPartX()方法。
例子:https://blog.csdn.net/lovelion/article/details/7426855
5)总结
建造者模式的核心在于如何一步步构建一个包含多个组成部件的完整对象,使用相同的构建过程构建不同的产品,在软件开发中,如果我们需要创建复杂对象并希望系统具备很好的灵活性和可扩展性可以考虑使用建造者模式。
1.主要优点
建造者模式的主要优点如下:
- 在建造者模式中,客户端不必知道产品内部组成的细节,将产品本身与产品的创建过程解耦,使得相同的创建过程可以创建不同的产品对象。
- 每一个具体建造者都相对独立,而与其他的具体建造者无关,因此可以很方便地替换具体建造者或增加新的具体建造者,用户使用不同的具体建造者即可得到不同的产品对象。由于指挥者类针对抽象建造者编程,增加新的具体建造者无须修改原有类库的代码,系统扩展方便,符合“开闭原则”。
- 可以更加精细地控制产品的创建过程。将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰,也更方便使用程序来控制创建过程。
2.主要缺点
建造者模式的主要缺点如下:
- 建造者模式所创建的产品一般具有较多的共同点,其组成部分相似,如果产品之间的差异性很大,例如很多组成部分都不相同,不适合使用建造者模式,因此其使用范围受到一定的限制。
- 如果产品的内部变化复杂,可能会导致需要定义很多具体建造者类来实现这种变化,导致系统变得很庞大,增加系统的理解难度和运行成本。
3.适用场景
在以下情况下可以考虑使用建造者模式:
- 需要生成的产品对象有复杂的内部结构,这些产品对象通常包含多个成员属性。
- 需要生成的产品对象的属性相互依赖,需要指定其生成顺序。
- 对象的创建过程独立于创建该对象的类。在建造者模式中通过引入了指挥者类,将创建过程封装在指挥者类中,而不在建造者类和客户类中。
- 隔离复杂对象的创建和使用,并使得相同的创建过程可以创建不同的产品。
三、七个结构型模式
在面向对象软件系统中,每个类/对象都承担着一定的职责,它们相互协作,可以实现一些复杂的功能。结构型模式(Structural Pattern)关注如何将现有类或对象组织在一起形成更加强大的结构。不同的结构型模式从不同的角度来组合类或对象,在尽可能满足各种面向对象设计原则的同时,为类或对象的组合提供一系列巧妙的解决方案。
1、适配器模式-Adapter Pattern——不兼容结构的协调
我的笔记本电脑的工作电压是20V,而我国的家庭用电是220V,如何让20V的笔记本电脑能够在220V的电压下工作?答案是引入一个电源适配器(AC Adapter),俗称充电器或变压器,有了这个电源适配器,生活用电和笔记本电脑即可兼容。
在软件开发中,有时也存在类似这种不兼容的情况,我们也可以像引入一个电源适配器一样引入一个称之为适配器的角色来协调这些存在不兼容的结构,这种设计方案即为适配器模式。
1)概述
与电源适配器相似,在适配器模式中引入了一个被称为适配器(Adapter)的包装类,而它所包装的对象称为适配者(Adaptee),即被适配的类。适配器的实现就是把客户类的请求转化为对适配者的相应接口的调用。也就是说:当客户类调用适配器的方法时,在适配器类的内部将调用适配者类的方法,而这个过程对客户类是透明的,客户类并不直接访问适配者类。因此,适配器让那些由于接口不兼容而不能交互的类可以一起工作。
适配器模式可以将一个类的接口和另一个类的接口匹配起来,而无须修改原来的适配者接口和抽象目标类接口。适配器模式定义如下:
适配器模式(Adapter Pattern):将一个接口转换成客户希望的另一个接口,使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper)。适配器模式既可以作为类结构型模式,也可以作为对象结构型模式。
【注:在适配器模式定义中所提及的接口是指广义的接口,它可以表示一个方法或者方法的集合。】
在适配器模式中,我们通过增加一个新的适配器类来解决接口不兼容的问题,使得原本没有任何关系的类可以协同工作。根据适配器类与适配者类的关系不同,适配器模式可分为对象适配器和类适配器两种,在对象适配器模式中,适配器与适配者之间是关联关系;在类适配器模式中,适配器与适配者之间是继承(或实现)关系。
2)对象适配器
在实际开发中,对象适配器的使用频率更高,对象适配器模式结构如下图所示:
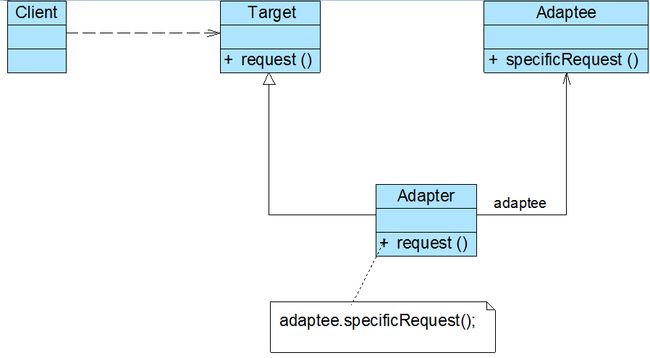 在对象适配器模式结构图中包含如下几个角色:
在对象适配器模式结构图中包含如下几个角色:
- Target(目标抽象类):目标抽象类定义客户所需接口,可以是一个抽象类或接口,也可以是具体类。
- Adapter(适配器类):适配器可以调用另一个接口,作为一个转换器,对Adaptee和Target进行适配,适配器类是适配器模式的核心,在对象适配器中,它通过继承Target并关联一个Adaptee对象使二者产生联系。
- Adaptee(适配者类):适配者即被适配的角色,它定义了一个已经存在的接口,这个接口需要适配,适配者类一般是一个具体类,包含了客户希望使用的业务方法,在某些情况下可能没有适配者类的源代码。
根据对象适配器模式结构图,在对象适配器中,客户端需要调用request()方法,而适配者类Adaptee没有该方法,但是它所提供的specificRequest()方法却是客户端所需要的。为了使客户端能够使用适配者类,需要提供一个包装类Adapter,即适配器类。这个包装类包装了一个适配者的实例,从而将客户端与适配者衔接起来,在适配器的request()方法中调用适配者的specificRequest()方法。因为适配器类与适配者类是关联关系(也可称之为委派关系),所以这种适配器模式称为对象适配器模式。典型的对象适配器代码如下所示:
class Adapter1:public Target
{
public:
Adapter1(Adaptee* adaptee) {
this->_adaptee = _adaptee; }
virtual void Request()//实现Target定义的Request接口
{
this->_adaptee->SpecificRequest();
}
private:
Adaptee* _adaptee;
};
3)类适配器模式
除了对象适配器模式之外,适配器模式还有一种形式,那就是类适配器模式,类适配器模式和对象适配器模式最大的区别在于适配器和适配者之间的关系不同,对象适配器模式中适配器和适配者之间是关联关系,而类适配器模式中适配器和适配者是继承关系,类适配器模式结构如图所示:
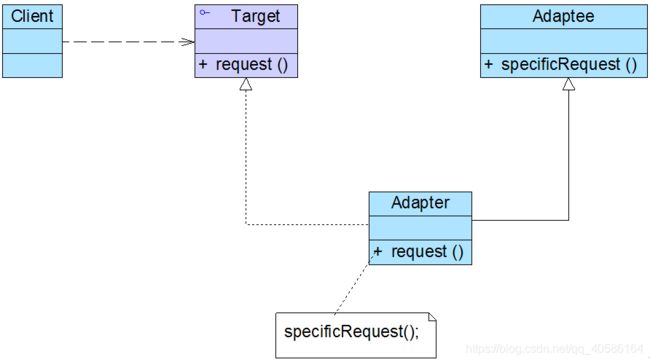 典型的类适配器代码如下所示:
典型的类适配器代码如下所示:
class Adapter:public Target,private Adaptee
{
public:
void Request() {
SpecificRequest();
}
};
由于Java、C#等语言不支持多重类继承,因此类适配器的使用受到很多限制,例如如果目标抽象类Target不是接口,而是一个类,就无法使用类适配器;此外,如果适配者Adapter为最终(Final)类,也无法使用类适配器。在Java等面向对象编程语言中,大部分情况下我们使用的是对象适配器,类适配器较少使用。
4)双向适配器
在对象适配器的使用过程中,如果在适配器中同时包含对目标类和适配者类的引用,适配者可以通过它调用目标类中的方法,目标类也可以通过它调用适配者类中的方法,那么该适配器就是一个双向适配器,其结构示意图如图所示:
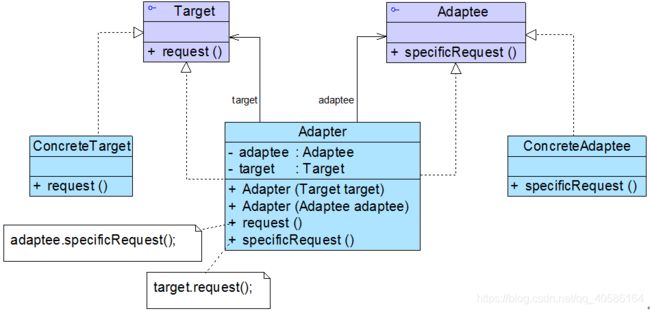 双向适配器的实现较为复杂,其典型代码如下所示:
双向适配器的实现较为复杂,其典型代码如下所示:
class Adapter:public Target, public Adaptee
{
public:
Adapter(Target* _target, Adaptee* _adaptee): target(_target), adaptee(_adaptee) {
}
void Request() {
adaptee->SpecificRequest(); }
void SpecificRequest() {
target->Request(); }
private:
Target* target;
Adaptee* adaptee;
};
5)缺省适配器
缺省适配器模式是适配器模式的一种变体,其应用也较为广泛。缺省适配器模式的定义如下:
缺省适配器模式(Default Adapter Pattern):当不需要实现一个接口所提供的所有方法时,可先设计一个抽象类实现该接口,并为接口中每个方法提供一个默认实现(空方法),那么该抽象类的子类可以选择性地覆盖父类的某些方法来实现需求,它适用于不想使用一个接口中的所有方法的情况,又称为单接口适配器模式。
缺省适配器模式结构如图所示:
 在缺省适配器模式中,包含如下三个角色:
在缺省适配器模式中,包含如下三个角色:
- ServiceInterface(适配者接口):它是一个接口,通常在该接口中声明了大量的方法。
- AbstractServiceClass(缺省适配器类):它是缺省适配器模式的核心类,使用空方法的形式实现了在ServiceInterface接口中声明的方法。通常将它定义为抽象类,因为对它进行实例化没有任何意义。
- ConcreteServiceClass(具体业务类):它是缺省适配器类的子类,在没有引入适配器之前,它需要实现适配者接口,因此需要实现在适配者接口中定义的所有方法,而对于一些无须使用的方法也不得不提供空实现。在有了缺省适配器之后,可以直接继承该适配器类,根据需要有选择性地覆盖在适配器类中定义的方法。
在JDK类库的事件处理包java.awt.event中广泛使用了缺省适配器模式,如WindowAdapter、KeyAdapter、MouseAdapter等。下面我们以处理窗口事件为例来进行说明:在Java语言中,一般我们可以使用两种方式来实现窗口事件处理类,一种是通过实现WindowListener接口,另一种是通过继承WindowAdapter适配器类。如果是使用第一种方式,直接实现WindowListener接口,事件处理类需要实现在该接口中定义的七个方法,而对于大部分需求可能只需要实现一两个方法,其他方法都无须实现,但由于语言特性我们不得不为其他方法也提供一个简单的实现(通常是空实现),这给使用带来了麻烦。而使用缺省适配器模式就可以很好地解决这一问题,在JDK中提供了一个适配器类WindowAdapter来实现WindowListener接口,该适配器类为接口中的每一个方法都提供了一个空实现,此时事件处理类可以继承WindowAdapter类,而无须再为接口中的每个方法都提供实现。如图所示:

6)代码
//目标接口类,客户需要的接口
class Target
{
public:
Target() {
}
virtual ~Target() {
}
virtual void Request()//定义标准接口
{
cout << "Target::Request()" << endl;
}
};
//需要适配的类
class Adaptee
{
public:
Adaptee() {
}
~Adaptee() {
}
void SpecificRequest()
{
cout << "Adaptee::SpecificRequest()" << endl;
}
};
//类模式,适配器类,通过public继承获得接口继承的效果,通过private继承获得实现继承的效果
class Adapter:public Target,private Adaptee
{
public:
Adapter() {
}
~Adapter() {
}
virtual void Request()//实现Target定义的Request接口
{
cout << "Adapter::Request()" << endl;
this->SpecificRequest();
cout << "----------------------------" <<endl;
}
};
//对象模式,适配器类,继承Target类,采用组合的方式实现Adaptee的复用
class Adapter1:public Target
{
public:
Adapter1(Adaptee* adaptee) {
this->_adaptee = _adaptee; }
~Adapter1() {
}
virtual void Request()//实现Target定义的Request接口
{
cout << "Adapter1::Request()" << endl;
this->_adaptee->SpecificRequest();
cout << "----------------------------" <<endl;
}
private:
Adaptee* _adaptee;
};
int main()
{
//类模式Adapter
Target* pTarget = new Adapter();
pTarget->Request();
//对象模式Adapter1
Adaptee* ade = new Adaptee();
Target* pTarget1= new Adapter1(ade);
pTarget1->Request();
return 0;
}
7) 总结
适配器模式将现有接口转化为客户类所期望的接口,实现了对现有类的复用,它是一种使用频率非常高的设计模式,在软件开发中得以广泛应用,在Spring等开源框架、驱动程序设计(如JDBC中的数据库驱动程序)中也使用了适配器模式。
1. 主要优点
无论是对象适配器模式还是类适配器模式都具有如下优点:
- 将目标类和适配者类解耦,通过引入一个适配器类来重用现有的适配者类,无须修改原有结构。
- 增加了类的透明性和复用性,将具体的业务实现过程封装在适配者类中,对于客户端类而言是透明的,而且提高了适配者的复用性,同一个适配者类可以在多个不同的系统中复用。
- 灵活性和扩展性都非常好,通过使用配置文件,可以很方便地更换适配器,也可以在不修改原有代码的基础上增加新的适配器类,完全符合“开闭原则”。
具体来说,类适配器模式还有如下优点:
由于适配器类是适配者类的子类,因此可以在适配器类中置换一些适配者的方法,使得适配器的灵活性更强。
对象适配器模式还有如下优点:
- 一个对象适配器可以把多个不同的适配者适配到同一个目标;
- 可以适配一个适配者的子类,由于适配器和适配者之间是关联关系,根据“里氏代换原则”,适配者的子类也可通过该适配器进行适配。
2. 主要缺点
类适配器模式的缺点如下:
- 对于Java、C#等不支持多重类继承的语言,一次最多只能适配一个适配者类,不能同时适配多个适配者;
- 适配者类不能为最终类,如在Java中不能为final类,C#中不能为sealed类;
- 在Java、C#等语言中,类适配器模式中的目标抽象类只能为接口,不能为类,其使用有一定的局限性。
对象适配器模式的缺点如下:
与类适配器模式相比,要在适配器中置换适配者类的某些方法比较麻烦。如果一定要置换掉适配者类的一个或多个方法,可以先做一个适配者类的子类,将适配者类的方法置换掉,然后再把适配者类的子类当做真正的适配者进行适配,实现过程较为复杂。
3. 适用场景
在以下情况下可以考虑使用适配器模式:
- 系统需要使用一些现有的类,而这些类的接口(如方法名)不符合系统的需要,甚至没有这些类的源代码。
- 想创建一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作。
2、桥接模式-Bridge Pattern——处理多维度变化
1)概述
桥接模式是一种很实用的结构型设计模式,如果软件系统中某个类存在两个独立变化的维度,通过该模式可以将这两个维度分离出来,使两者可以独立扩展,让系统更加符合“单一职责原则”。与多层继承方案不同,它将两个独立变化的维度设计为两个独立的继承等级结构,并且在抽象层建立一个抽象关联,该关联关系类似一条连接两个独立继承结构的桥,故名桥接模式。
桥接模式用一种巧妙的方式处理多层继承存在的问题,用 抽象关联 取代了传统的多层继承,将类之间的静态继承关系转换为动态的对象组合关系,使得系统更加灵活,并易于扩展,同时有效控制了系统中类的个数。桥接定义如下:
桥接模式(Bridge Pattern):将抽象部分与它的实现部分分离,使它们都可以独立地变化。它是一种对象结构型模式,又称为柄体(Handle and Body)模式或接口(Interface)模式。
桥接模式的结构与其名称一样,存在一条连接两个继承等级结构的桥,桥接模式结构如图所示:
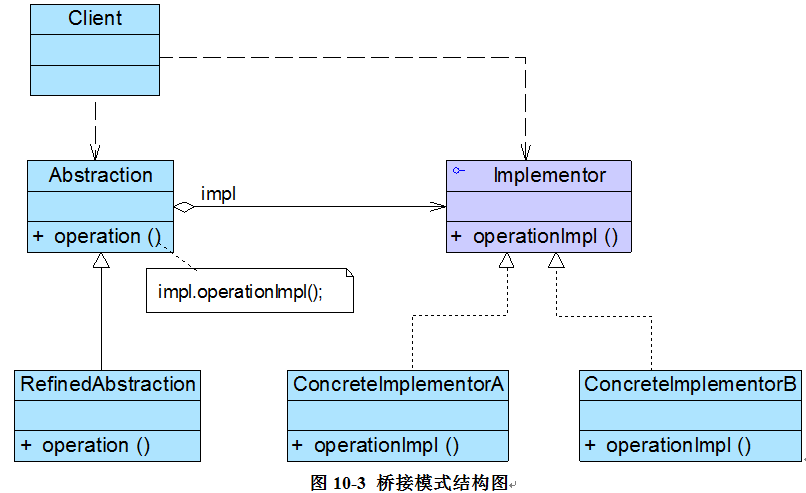 在桥接模式结构图中包含如下几个角色:
在桥接模式结构图中包含如下几个角色:
- Abstraction(抽象类):用于定义抽象类的接口,它一般是抽象类而不是接口,其中定义了一个Implementor(实现类接口)类型的对象并可以维护该对象,它与Implementor之间具有关联关系,它既可以包含抽象业务方法,也可以包含具体业务方法。
- RefinedAbstraction(扩充抽象类):扩充由Abstraction定义的接口,通常情况下它不再是抽象类而是具体类,它实现了在Abstraction中声明的抽象业务方法,在RefinedAbstraction中可以调用在Implementor中定义的业务方法。
- Implementor(实现类接口):定义实现类的接口,这个接口不一定要与Abstraction的接口完全一致,事实上这两个接口可以完全不同,一般而言,Implementor接口仅提供基本操作,而Abstraction定义的接口可能会做更多更复杂的操作。Implementor接口对这些基本操作进行了声明,而具体实现交给其子类。通过关联关系,在Abstraction中不仅拥有自己的方法,还可以调用到Implementor中定义的方法,使用关联关系来替代继承关系。
- ConcreteImplementor(具体实现类):具体实现Implementor接口,在不同的ConcreteImplementor中提供基本操作的不同实现,在程序运行时,ConcreteImplementor对象将替换其父类对象,提供给抽象类具体的业务操作方法。
2)示例
手机品牌和软件是两个概念,不同的软件可以在不同的手机上,不同的手机可以有相同的软件,两者都具有很大的变动性。如果我们单独以手机品牌或手机软件为基类来进行继承扩展的话,无疑会使类的数目剧增并且耦合性很高,(如果更改品牌或增加软件都会增加很多的变动)两种方式的结构如下:
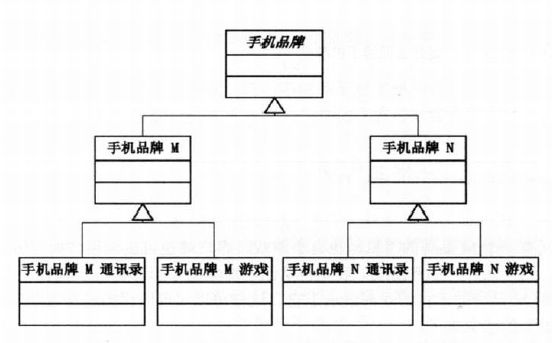
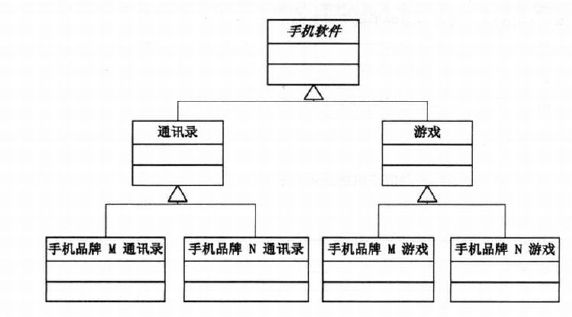
所以将两者抽象出来两个基类分别是PhoneBrand和PhoneSoft,那么在品牌类中聚合一个软件对象的基类将解决软件和手机扩展混乱的问题,这样两者的扩展就相对灵活,剪短了两者的必要联系,结构图如下:
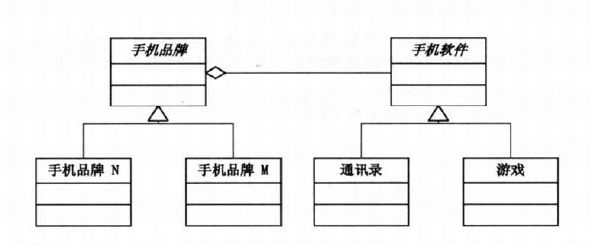
这样扩展品牌和软件就相对灵活独立,达到解耦的目的!
//抽象实现类,定义了实现的接口
class AbstractionImplement
{
public:
virtual void Operation()=0;//定义操作接口
AbstractionImplement() {
}
virtual ~AbstractionImplement() {
}
};
//抽象类
class Abstraction
{
public:
virtual void Operation()=0;//定义接口,表示该类所支持的操作
void setImp(AbstractionImplement* imp)
{
_imp = imp;
}
virtual ~Abstraction() {
}
protected :
AbstractionImplement* _imp;
};
//扩充抽象类
class RefinedAbstractionA:public Abstraction
{
public:
RefinedAbstractionA(AbstractionImplement* imp) {
setImp(imp); }//构造函数
virtual void Operation()//实现接口
{
cout << "RefinedAbstractionA::Operation" << endl;
this->_imp->Operation();
}
virtual ~RefinedAbstractionA() {
}//析构函数
};
//扩充抽象类
class RefinedAbstractionB:public Abstraction
{
public:
RefinedAbstractionB(AbstractionImplement* imp) {
setImp(imp); }//构造函数
virtual void Operation()//实现接口
{
cout << "RefinedAbstractionB::Operation" << endl;
this->_imp->Operation();
}
virtual ~RefinedAbstractionB() {
}//析构函数
};
//具体实现类
class ConcreteAbstractionImplementA:public AbstractionImplement
{
public:
ConcreteAbstractionImplementA() {
}
void Operation()//实现操作
{
cout << "ConcreteAbstractionImplementA Operation" << endl;
}
~ConcreteAbstractionImplementA() {
}
};
//具体实现类
class ConcreteAbstractionImplementB:public AbstractionImplement
{
public:
ConcreteAbstractionImplementB() {
}
void Operation()//实现操作
{
cout << "ConcreteAbstractionImplementB Operation" << endl;
}
~ConcreteAbstractionImplementB() {
}
};
int main()
{
AbstractionImplement* imp = new ConcreteAbstractionImplementA(); //实现部分ConcreteAbstractionImplementA
Abstraction* abs = new RefinedAbstractionA(imp); //抽象部分RefinedAbstractionA
abs->Operation();
cout << "-----------------------------------------" << endl;
AbstractionImplement* imp1 = new ConcreteAbstractionImplementB(); //实现部分ConcreteAbstractionImplementB
Abstraction* abs1 = new RefinedAbstractionA(imp1); //抽象部分RefinedAbstractionA
abs1->Operation();
cout << "-----------------------------------------" << endl;
AbstractionImplement* imp2 = new ConcreteAbstractionImplementA(); //实现部分ConcreteAbstractionImplementA
Abstraction* abs2 = new RefinedAbstractionB(imp2); //抽象部分RefinedAbstractionB
abs2->Operation();
cout << "-----------------------------------------" << endl;
AbstractionImplement* imp3 = new ConcreteAbstractionImplementB(); //实现部分ConcreteAbstractionImplementB
Abstraction* abs3 = new RefinedAbstractionB(imp3); //抽象部分RefinedAbstractionB
abs3->Operation();
}
3)总结
桥接模式是设计Java虚拟机和实现JDBC等驱动程序的核心模式之一,应用较为广泛。在软件开发中如果一个类或一个系统有多个变化维度时,都可以尝试使用桥接模式对其进行设计。桥接模式为多维度变化的系统提供了一套完整的解决方案,并且降低了系统的复杂度。
1.主要优点
- 分离抽象接口及其实现部分。桥接模式使用“对象间的关联关系”解耦了抽象和实现之间固有的绑定关系,使得抽象和实现可以沿着各自的维度来变化。所谓抽象和实现沿着各自维度的变化,也就是说抽象和实现不再在同一个继承层次结构中,而是“子类化”它们,使它们各自都具有自己的子类,以便任何组合子类,从而获得多维度组合对象。
- 在很多情况下,桥接模式可以取代多层继承方案,多层继承方案违背了“单一职责原则”,复用性较差,且类的个数非常多,桥接模式是比多层继承方案更好的解决方法,它极大减少了子类的个数。
- 桥接模式提高了系统的可扩展性,在两个变化维度中任意扩展一个维度,都不需要修改原有系统,符合“开闭原则”。
2.主要缺点
- 桥接模式的使用会增加系统的理解与设计难度,由于关联关系建立在抽象层,要求开发者一开始就针对抽象层进行设计与编程。
- 桥接模式要求正确识别出系统中两个独立变化的维度,因此其使用范围具有一定的局限性,如何正确识别两个独立维度也需要一定的经验积累。
3.适用场景
在以下情况下可以考虑使用桥接模式:
- 如果一个系统需要在抽象化和具体化之间增加更多的灵活性,避免在两个层次之间建立静态的继承关系,通过桥接模式可以使它们在抽象层建立一个关联关系。
- “抽象部分”和“实现部分”可以以继承的方式独立扩展而互不影响,在程序运行时可以动态将一个抽象化子类的对象和一个实现化子类的对象进行组合,即系统需要对抽象化角色和实现化角色进行动态耦合。
- 一个类存在两个(或多个)独立变化的维度,且这两个(或多个)维度都需要独立进行扩展。
- 对于那些不希望使用继承或因为多层继承导致系统类的个数急剧增加的系统,桥接模式尤为适用。
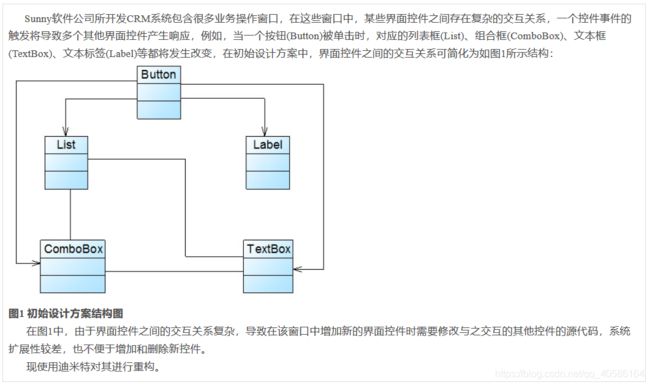
3、组合模式-Composite Pattern——树形结构的处理
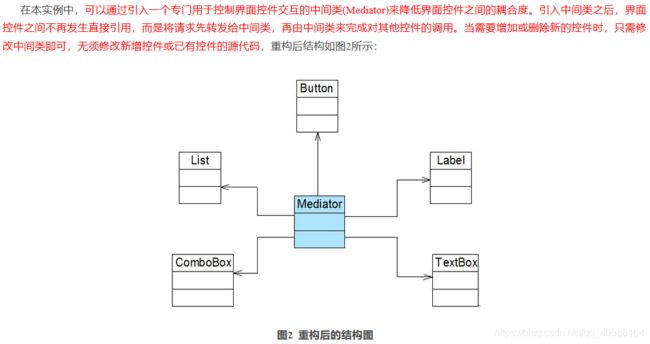
树形结构在软件中随处可见,例如操作系统中的目录结构、应用软件中的菜单、办公系统中的公司组织结构等等,如何运用面向对象的方式来处理这种树形结构是组合模式需要解决的问题,组合模式通过一种巧妙的设计方案使得用户可以一致性地处理整个树形结构或者树形结构的一部分,也可以一致性地处理树形结构中的叶子节点(不包含子节点的节点)和容器节点(包含子节点的节点)。

树形目录结构示意图:
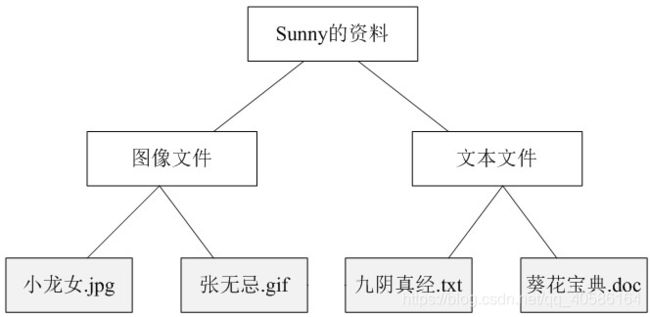
组合模式为处理树形结构提供了一种较为完美的解决方案,它描述了如何将容器和叶子进行递归组合,使得用户在使用时无须对它们进行区分,可以一致地对待容器和叶子。
1)概述
对于树形结构,当容器对象(如文件夹)的某一个方法被调用时,将遍历整个树形结构,寻找也包含这个方法的成员对象(可以是容器对象,也可以是叶子对象)并调用执行,牵一而动百,其中使用了递归调用的机制来对整个结构进行处理。由于容器对象和叶子对象在功能上的区别,在使用这些对象的代码中必须有区别地对待容器对象和叶子对象,而实际上大多数情况下我们希望一致地处理它们,因为对于这些对象的区别对待将会使得程序非常复杂。组合模式为解决此类问题而诞生,它可以让叶子对象和容器对象的使用具有一致性。
组合模式定义如下:
组合模式(Composite Pattern):组合多个对象形成树形结构以表示具有“整体—部分”关系的层次结构。组合模式对单个对象(即叶子对象)和组合对象(即容器对象)的使用具有一致性,组合模式又可以称为“整体—部分”(Part-Whole)模式,它是一种对象结构型模式。
2)结构
在组合模式中引入了抽象构件类Component,它是所有容器类和叶子类的公共父类,客户端针对Component进行编程。组合模式结构如图11-3所示:
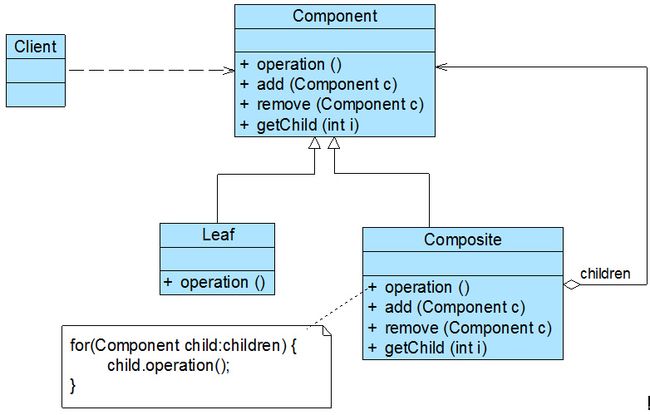
图11-3 组合模式结构图
在组合模式结构图中包含如下几个角色:
- Component(抽象构件):它可以是接口或抽象类,为叶子构件和容器构件对象声明接口,在该角色中可以包含所有子类共有行为的声明和实现。在抽象构件中定义了访问及管理它的子构件的方法,如增加子构件、删除子构件、获取子构件等。
- Leaf(叶子构件):它在组合结构中表示叶子节点对象,叶子节点没有子节点,它实现了在抽象构件中定义的行为。对于那些访问及管理子构件的方法,可以通过异常等方式进行处理。
- Composite(容器构件):它在组合结构中表示容器节点对象,容器节点包含子节点,其子节点可以是叶子节点,也可以是容器节点,它提供一个集合用于存储子节点,实现了在抽象构件中定义的行为,包括那些访问及管理子构件的方法,在其业务方法中可以递归调用其子节点的业务方法。
组合模式的关键是定义了一个抽象构件类,它既可以代表叶子,又可以代表容器,而客户端针对该抽象构件类进行编程,无须知道它到底表示的是叶子还是容器,可以对其进行统一处理。同时容器对象与抽象构件类之间还建立一个聚合关联关系,在容器对象中既可以包含叶子,也可以包含容器,以此实现递归组合,形成一个树形结构。
如果不使用组合模式,客户端代码将过多地依赖于容器对象复杂的内部实现结构,容器对象内部实现结构的变化将引起客户代码的频繁变化,带来了代码维护复杂、可扩展性差等弊端。组合模式的引入将在一定程度上解决这些问题。
下面通过简单的示例代码来分析组合模式的各个角色的用途和实现。对于组合模式中的抽象构件角色,其典型代码如下所示:
abstract class Component {
public abstract void add(Component c); //增加成员
public abstract void remove(Component c); //删除成员
public abstract Component getChild(int i); //获取成员
public abstract void operation(); //业务方法
}
一般将抽象构件类设计为接口或抽象类,将所有子类共有方法的声明和实现放在抽象构件类中。对于客户端而言,将针对抽象构件编程,而无须关心其具体子类是容器构件还是叶子构件。
如果继承抽象构件的是叶子构件,则其典型代码如下所示:
class Leaf extends Component {
public void add(Component c) {
//异常处理或错误提示
}
public void remove(Component c) {
//异常处理或错误提示
}
public Component getChild(int i) {
//异常处理或错误提示
return null;
}
public void operation() {
//叶子构件具体业务方法的实现
}
}
作为抽象构件类的子类,在叶子构件中需要实现在抽象构件类中声明的所有方法,包括业务方法以及管理和访问子构件的方法,但是叶子构件不能再包含子构件,因此在叶子构件中实现子构件管理和访问方法时需要提供异常处理或错误提示。当然,这无疑会给叶子构件的实现带来麻烦。
如果继承抽象构件的是容器构件,则其典型代码如下所示:
class Composite extends Component {
private ArrayList<Component> list = new ArrayList<Component>();
public void add(Component c) {
list.add(c);
}
public void remove(Component c) {
list.remove(c);
}
public Component getChild(int i) {
return (Component)list.get(i);
}
public void operation() {
//容器构件具体业务方法的实现
//递归调用成员构件的业务方法
for(Object obj:list) {
((Component)obj).operation();
}
}
}
在容器构件中实现了在抽象构件中声明的所有方法,既包括业务方法,也包括用于访问和管理成员子构件的方法,如add()、remove()和getChild()等方法。需要注意的是在实现具体业务方法时,由于容器构件充当的是容器角色,包含成员构件,因此它将调用其成员构件的业务方法。在组合模式结构中,由于容器构件中仍然可以包含容器构件,因此在对容器构件进行处理时需要使用递归算法,即在容器构件的operation()方法中递归调用其成员构件的operation()方法。
代码示例:
JAVA:https://blog.csdn.net/lovelion/article/details/7956931
C++:https://www.cnblogs.com/jiese/p/3168844.html
3)透明组合模式与安全组合模式
由于在Component 中声明了大量用于管理和访问成员构件的方法,例如add()、remove()等方法,我们不得不在Leaf类中实现这些方法,提供对应的错误提示和异常处理。为了简化代码,我们有以下两个解决方案:
-
解决方案一:将叶子构件的add()、remove()等方法的实现代码移至主抽象类中,由其提供统一的默认实现,代码如下所示:
abstract class Component { public void add(Component c) //增加成员 { System.out.println("对不起,不支持该方法!"); } public void remove(Component c) //删除成员 { System.out.println("对不起,不支持该方法!"); } publict Component getChild(int i); //获取成员 { System.out.println("对不起,不支持该方法!"); } public abstract void operation(); //业务方法 }在Composite 类中覆盖这些方法。
如果不希望出现任何错误提示,我们可以在客户端定义对象时不使用抽象层,而直接使用具体叶子构件本身,这样就产生了一种不透明的使用方式,即在客户端不能全部针对抽象构件类编程,需要使用具体叶子构件类型来定义叶子对象。 -
解决方法二:除此之外,还有一种解决方法是在抽象构件AbstractFile中不声明任何用于访问和管理成员构件的方法:
abstract class Component { public abstract void operation(); //业务方法 }此时,由于在AbstractFile中没有声明add()、remove()等访问和管理成员的方法,其叶子构件子类无须提供实现;而且无论客户端如何定义叶子构件对象都无法调用到这些方法,不需要做任何错误和异常处理,容器构件再根据需要增加访问和管理成员的方法,但这时候也存在一个问题:客户端不得不使用容器类本身来声明容器构件对象,否则无法访问其中新增的add()、remove()等方法,如果客户端一致性地对待叶子和容器,将会导致容器构件的新增对客户端不可见,客户端代码对于容器构件无法再使用抽象构件来定义。
class Client { public static void main(String args[]) { Component file1,file2,file3,file4,file5; Composite folder1,folder2,folder3,folder4; //不能透明处理容器构件 //其他代码省略 } }
在使用组合模式时,根据抽象构件类的定义形式,我们可将组合模式分为透明组合模式和安全组合模式两种形式:
-
透明组合模式
透明组合模式中,抽象构件Component中声明了所有用于管理成员对象的方法,包括add()、remove()以及getChild()等方法,这样做的好处是确保所有的构件类都有相同的接口。在客户端看来,叶子对象与容器对象所提供的方法是一致的,客户端可以相同地对待所有的对象。透明组合模式也是组合模式的标准形式,虽然上面的解决方案一在客户端可以有不透明的实现方法,但是由于在抽象构件中包含add()、remove()等方法,因此它还是透明组合模式,透明组合模式的完整结构如图11-6所示: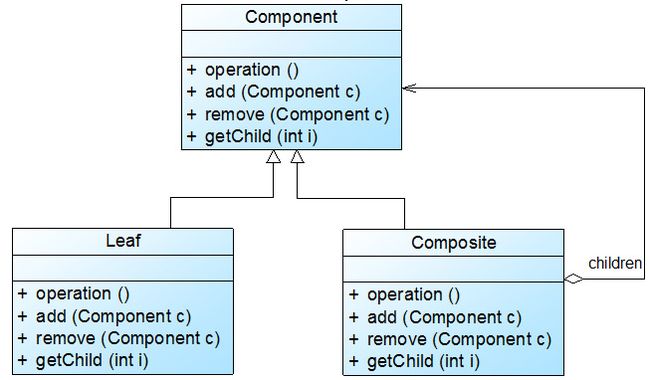
透明组合模式的缺点是不够安全,因为叶子对象和容器对象在本质上是有区别的。叶子对象不可能有下一个层次的对象,即不可能包含成员对象,因此为其提供add()、remove()以及getChild()等方法是没有意义的,这在编译阶段不会出错,但在运行阶段如果调用这些方法可能会出错(如果没有提供相应的错误处理代码)。 -
安全组合模式
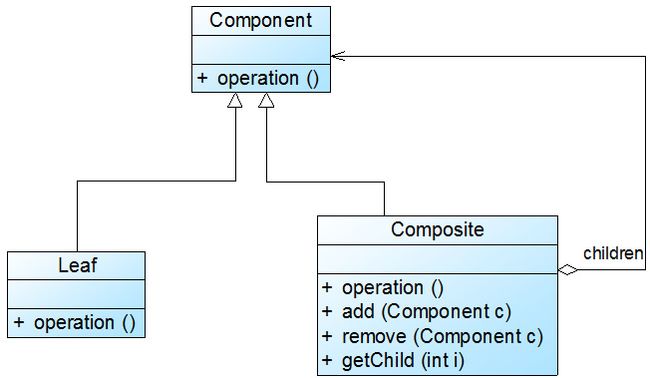
安全组合模式中,在抽象构件Component中没有声明任何用于管理成员对象的方法,而是在Composite类中声明并实现这些方法。这种做法是安全的,因为根本不向叶子对象提供这些管理成员对象的方法,对于叶子对象,客户端不可能调用到这些方法,这就是解决方案二所采用的实现方式。安全组合模式的结构如图所示:
安全组合模式的缺点是不够透明,因为叶子构件和容器构件具有不同的方法,且容器构件中那些用于管理成员对象的方法没有在抽象构件类中定义,因此客户端不能完全针对抽象编程,必须有区别地对待叶子构件和容器构件。在实际应用中,安全组合模式的使用频率也非常高,在Java AWT中使用的组合模式就是安全组合模式。
4)总结
组合模式使用面向对象的思想来实现树形结构的构建与处理,描述了如何将容器对象和叶子对象进行递归组合,实现简单,灵活性好。由于在软件开发中存在大量的树形结构,因此组合模式是一种使用频率较高的结构型设计模式,Java SE中的AWT和Swing包的设计就基于组合模式,在这些界面包中为用户提供了大量的容器构件(如Container)和成员构件(如Checkbox、Button和TextComponent等),其结构如图所示:
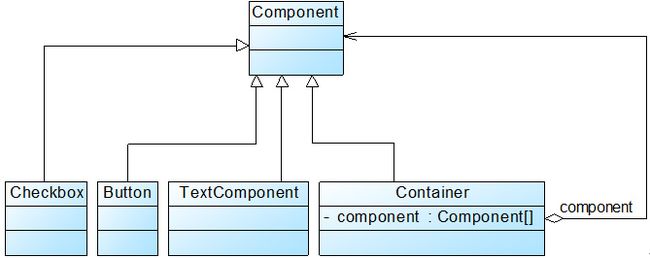
在图中,Component类是抽象构件,Checkbox、Button和TextComponent是叶子构件,而Container是容器构件,在AWT中包含的叶子构件还有很多,因为篇幅限制没有在图中一一列出。在一个容器构件中可以包含叶子构件,也可以继续包含容器构件,这些叶子构件和容器构件一起组成了复杂的GUI界面。
除此以外,在XML解析、组织结构树处理、文件系统设计等领域,组合模式都得到了广泛应用。
1. 主要优点
组合模式的主要优点如下:
- 组合模式可以清楚地定义分层次的复杂对象,表示对象的全部或部分层次,它让客户端忽略了层次的差异,方便对整个层次结构进行控制。
- 客户端可以一致地使用一个组合结构或其中单个对象,不必关心处理的是单个对象还是整个组合结构,简化了客户端代码。
- 在组合模式中增加新的容器构件和叶子构件都很方便,无须对现有类库进行任何修改,符合“开闭原则”。
- 组合模式为树形结构的面向对象实现提供了一种灵活的解决方案,通过叶子对象和容器对象的递归组合,可以形成复杂的树形结构,但对树形结构的控制却非常简单。
2. 主要缺点
组合模式的主要缺点如下:
在增加新构件时很难对容器中的构件类型进行限制。有时候我们希望一个容器中只能有某些特定类型的对象,例如在某个文件夹中只能包含文本文件,使用组合模式时,不能依赖类型系统来施加这些约束,因为它们都来自于相同的抽象层,在这种情况下,必须通过在运行时进行类型检查来实现,这个实现过程较为复杂。
3. 适用场景
在以下情况下可以考虑使用组合模式:
- 在具有整体和部分的层次结构中,希望通过一种方式忽略整体与部分的差异,客户端可以一致地对待它们。
- 在一个使用面向对象语言开发的系统中需要处理一个树形结构。
- 在一个系统中能够分离出叶子对象和容器对象,而且它们的类型不固定,需要增加一些新的类型。
4、装饰模式-Decorator Pattern——扩展系统功能
在软件设计中,我们有一种类似新房装修的技术可以对已有对象(新房)的功能进行扩展(装修),以获得更加符合用户需求的对象,使得对象具有更加强大的功能。这种技术对应于一种被称之为装饰模式的设计模式。
1)概述
装饰模式可以在不改变一个对象本身功能的基础上给对象增加额外的新行为,在现实生活中,这种情况也到处存在,例如一张照片,我们可以不改变照片本身,给它增加一个相框,使得它具有防潮的功能,而且用户可以根据需要给它增加不同类型的相框,甚至可以在一个小相框的外面再套一个大相框。
装饰模式是一种用于替代继承的技术,它通过一种无须定义子类的方式来给对象动态增加职责,使用对象之间的关联关系取代类之间的继承关系。在装饰模式中引入了装饰类,在装饰类中既可以调用待装饰的原有类的方法,还可以增加新的方法,以扩充原有类的功能。
装饰模式定义如下:
装饰模式(Decorator Pattern):动态地给一个对象增加一些额外的职责,就增加对象功能来说,装饰模式比生成子类实现更为灵活。装饰模式是一种对象结构型模式。
2)结构
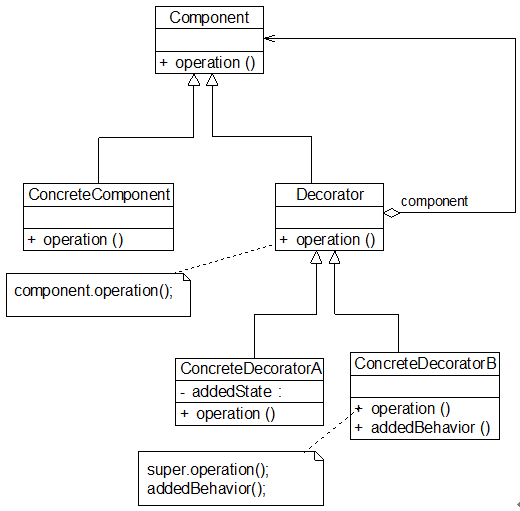
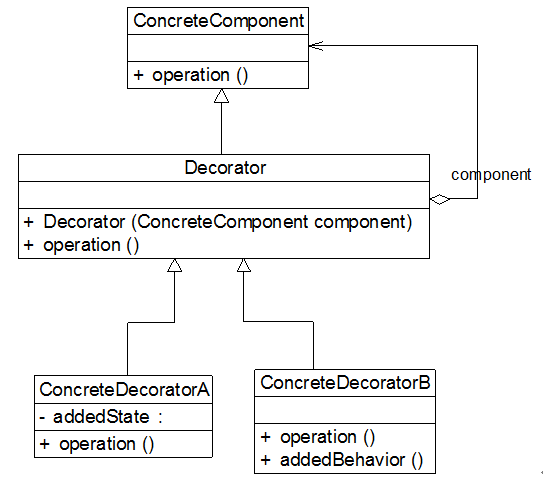
在装饰模式中,为了让系统具有更好的灵活性和可扩展性,我们通常会定义一个抽象装饰类,而将具体的装饰类作为它的子类,装饰模式结构如图所示:
在装饰模式结构图中包含如下几个角色:
- Component(抽象构件):它是具体构件和抽象装饰类的共同父类,声明了在具体构件中实现的业务方法,它的引入可以使客户端以一致的方式处理未被装饰的对象以及装饰之后的对象,实现客户端的透明操作。
- ConcreteComponent(具体构件):它是抽象构件类的子类,用于定义具体的构件对象,实现了在抽象构件中声明的方法,装饰器可以给它增加额外的职责(方法)。
- Decorator(抽象装饰类):它也是抽象构件类的子类,用于给具体构件增加职责,但是具体职责在其子类中实现。它维护一个指向抽象构件对象的引用,通过该引用可以调用装饰之前构件对象的方法,并通过其子类扩展该方法,以达到装饰的目的。
- ConcreteDecorator(具体装饰类):它是抽象装饰类的子类,负责向构件添加新的职责。每一个具体装饰类都定义了一些新的行为,它可以调用在抽象装饰类中定义的方法,并可以增加新的方法用以扩充对象的行为。
由于具体构件类和装饰类都实现了相同的抽象构件接口,因此装饰模式以对客户透明的方式动态地给一个对象附加上更多的责任,换言之,客户端并不会觉得对象在装饰前和装饰后有什么不同。装饰模式可以在不需要创造更多子类的情况下,将对象的功能加以扩展。
装饰模式的核心在于抽象装饰类的设计,其典型代码如下所示:
class Decorator implements Component
{
private Component component; //维持一个对抽象构件对象的引用
public Decorator(Component component) //注入一个抽象构件类型的对象
{
this.component = component;
}
public void operation()
{
component.operation(); //调用原有业务方法
}
}
在抽象装饰类Decorator中定义了一个Component类型的对象component,维持一个对抽象构件对象的引用,并可以通过构造方法或Setter方法将一个Component类型的对象注入进来,同时由于Decorator类实现了抽象构件Component接口,因此需要实现在其中声明的业务方法operation(),需要注意的是在Decorator中并未真正实现operation()方法,而只是调用原有component对象的operation()方法,它没有真正实施装饰,而是提供一个统一的接口,将具体装饰过程交给子类完成。
在Decorator的子类即具体装饰类中将继承operation()方法并根据需要进行扩展,典型的具体装饰类代码如下:
class ConcreteDecorator extends Decorator
{
public ConcreteDecorator(Component component)
{
super(component);//父类构造函数
}
public void operation()
{
super.operation(); //调用原有业务方法
addedBehavior(); //调用新增业务方法
}
//新增业务方法
public void addedBehavior()
{
……
}
}
在具体装饰类中可以调用到抽象装饰类的operation()方法,同时可以定义新的业务方法,如addedBehavior()。
由于在抽象装饰类Decorator中注入的是Component类型的对象,因此我们可以将一个具体构件对象注入其中,再通过具体装饰类来进行装饰;此外,我们还可以将一个已经装饰过的Decorator子类的对象再注入其中进行多次装饰,从而对原有功能的多次扩展。
示例:
JAVA:https://blog.csdn.net/lovelion/article/details/7425861
C++:https://www.cnblogs.com/jiese/p/3167050.html
我们可以将装饰了一次之后的componentSB对象注入另一个装饰类中实现第二次装饰,得到一个经过两次装饰的对象componentBB,再调用componentBB的display()方法即可实现一个被两次装饰过的功能。
3)透明装饰模式与半透明装饰模式
装饰模式虽好,但存在一个问题。如果客户端希望单独调用具体装饰类新增的方法,而不想通过抽象构件中声明的方法来调用新增方法时将遇到一些麻烦,我们通过一个实例来对这种情况加以说明:
在Sunny软件公司开发的Sunny OA系统中,采购单(PurchaseRequest)和请假条(LeaveRequest)等文件(Document)对象都具有显示功能,现在要为其增加审批、删除等功能,使用装饰模式进行设计。
我们使用装饰模式可以得到如图所示结构图:
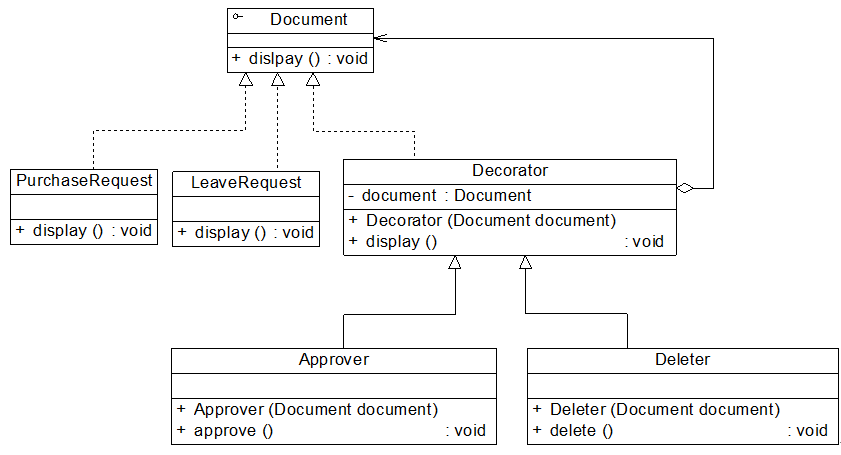
在图中,Document充当抽象构件类,PurchaseRequest和LeaveRequest充当具体构件类,Decorator充当抽象装饰类,Approver和Deleter充当具体装饰类。其中Decorator类和Approver类的示例代码如下所示:
//抽象装饰类
class Decorator implements Document {
private Document document;
public Decorator(Document document) {
this.document = document;
}
public void display() {
document.display();
}
}
//具体装饰类
class Approver extends Decorator {
public Approver(Document document) {
super(document);
System.out.println("增加审批功能!");
}
public void approve() {
System.out.println("审批文件!");
}
}
Approver类继承了抽象装饰类Decorator的display()方法,同时新增了业务方法approve(),但这两个方法是独立的,没有任何调用关系。如果客户端需要分别调用这两个方法,代码片段如下所示:
Document doc; //使用抽象构件类型定义
doc = new PurchaseRequest();
Approver newDoc; //使用具体装饰类型定义
newDoc = new Approver(doc);
newDoc.display();//调用原有业务方法
newDoc.approve();//调用新增业务方法
如果newDoc也使用Document类型来定义,将导致客户端无法调用新增业务方法approve(),因为在抽象构件类Document中没有对approve()方法的声明。也就是说,在客户端无法统一对待装饰之前的具体构件对象和装饰之后的构件对象。
在实际使用过程中,由于新增行为可能需要单独调用,因此这种形式的装饰模式也经常出现,这种装饰模式被称为半透明(Semi-transparent)装饰模式,而前面标准的装饰模式是透明(Transparent)装饰模式。
透明装饰模式可以让客户端透明地使用装饰之前的对象和装饰之后的对象,无须关心它们的区别,此外,还可以对一个已装饰过的对象进行多次装饰,得到更为复杂、功能更为强大的对象。在实现透明装饰模式时,要求具体装饰类的operation()方法覆盖抽象装饰类的operation()方法,除了调用原有对象的operation()外还需要调用新增的addedBehavior()方法来增加新行为。
半透明装饰模式可以给系统带来更多的灵活性,设计相对简单,使用起来也非常方便;但是其最大的缺点在于不能实现对同一个对象的多次装饰,而且客户端需要有区别地对待装饰之前的对象和装饰之后的对象。在实现半透明的装饰模式时,我们只需在具体装饰类中增加一个独立的addedBehavior()方法来封装相应的业务处理,由于客户端使用具体装饰类型来定义装饰后的对象,因此可以单独调用addedBehavior()方法来扩展系统功能。
4)注意事项
在使用装饰模式时,通常我们需要注意以下几个问题:
-
尽量保持装饰类的接口与被装饰类的接口相同,这样,对于客户端而言,无论是装饰之前的对象还是装饰之后的对象都可以一致对待。这也就是说,在可能的情况下,我们应该尽量使用透明装饰模式。
-
尽量保持具体构件类ConcreteComponent是一个“轻”类,也就是说不要把太多的行为放在具体构件类中,我们可以通过装饰类对其进行扩展。
-
如果只有一个具体构件类,那么抽象装饰类可以作为该具体构件类的直接子类。如图所示:
5)总结
装饰模式降低了系统的耦合度,可以动态增加或删除对象的职责,并使得需要装饰的具体构件类和具体装饰类可以独立变化,以便增加新的具体构件类和具体装饰类。在软件开发中,装饰模式应用较为广泛,例如在JavaIO中的输入流和输出流的设计、javax.swing包中一些图形界面构件功能的增强等地方都运用了装饰模式。
主要优点
- 对于扩展一个对象的功能,装饰模式比继承更加灵活性,不会导致类的个数急剧增加。
- 可以通过一种动态的方式来扩展一个对象的功能,通过配置文件可以在运行时选择不同的具体装饰类,从而实现不同的行为。
- 可以对一个对象进行多次装饰,通过使用不同的具体装饰类以及这些装饰类的排列组合,可以创造出很多不同行为的组合,得到功能更为强大的对象。
- 具体构件类与具体装饰类可以独立变化,用户可以根据需要增加新的具体构件类和具体装饰类,原有类库代码无须改变,符合“开闭原则”。
主要缺点
- 使用装饰模式进行系统设计时将产生很多小对象,这些对象的区别在于它们之间相互连接的方式有所不同,而不是它们的类或者属性值有所不同,大量小对象的产生势必会占用更多的系统资源,在一定程序上影响程序的性能。
- 装饰模式提供了一种比继承更加灵活机动的解决方案,但同时也意味着比继承更加易于出错,排错也很困难,对于多次装饰的对象,调试时寻找错误可能需要逐级排查,较为繁琐。
3.适用场景
在以下情况下可以考虑使用装饰模式:
- 在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责。
- 当不能采用继承的方式对系统进行扩展或者采用继承不利于系统扩展和维护时可以使用装饰模式。不能采用继承的情况主要有两类:第一类是系统中存在大量独立的扩展,为支持每一种扩展或者扩展之间的组合将产生大量的子类,使得子类数目呈爆炸性增长;第二类是因为类已定义为不能被继承(如Java语言中的final类)。
5、外观模式-Facade Pattern——减少耦合
外观模式是一种使用频率非常高的结构型设计模式,它通过引入一个外观角色来简化客户端与子系统之间的交互,为复杂的子系统调用提供一个统一的入口,降低子系统与客户端的耦合度,且客户端调用非常方便。
1)概述
在软件开发中,有时候为了完成一项较为复杂的功能,一个客户类需要和多个业务类交互,而这些需要交互的业务类经常会作为一个整体出现,由于涉及到的类比较多,导致使用时代码较为复杂,此时,特别需要一个类似服务员一样的角色,由它来负责和多个业务类进行交互,而客户类只需与该类交互。外观模式通过引入一个新的外观类(Facade)来实现该功能,外观类充当了软件系统中的“服务员”,它为多个业务类的调用提供了一个统一的入口,简化了类与类之间的交互。在外观模式中,那些需要交互的业务类被称为子系统(Subsystem)。如果没有外观类,那么每个客户类需要和多个子系统之间进行复杂的交互,系统的耦合度将很大,如图2(A)所示;而引入外观类之后,客户类只需要直接与外观类交互,客户类与子系统之间原有的复杂引用关系由外观类来实现,从而降低了系统的耦合度,如图2(B)所示。
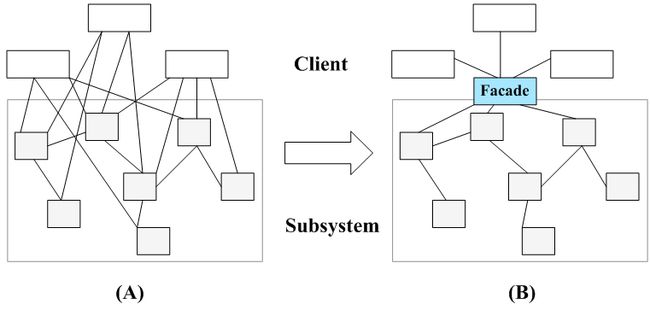
图2 外观模式示意图
外观模式中,一个子系统的外部与其内部的通信通过一个统一的外观类进行,外观类将客户类与子系统的内部复杂性分隔开,使得客户类只需要与外观角色打交道,而不需要与子系统内部的很多对象打交道。
外观模式定义如下:
外观模式:为子系统中的一组接口提供一个统一的入口。外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
外观模式又称为门面模式,它是一种对象结构型模式。外观模式是迪米特法则的一种具体实现,通过引入一个新的外观角色可以降低原有系统的复杂度,同时降低客户类与子系统的耦合度。
2)结构
外观模式没有一个一般化的类图描述,通常使用如图2(B)所示示意图来表示外观模式。图3所示的类图也可以作为描述外观模式的结构图:
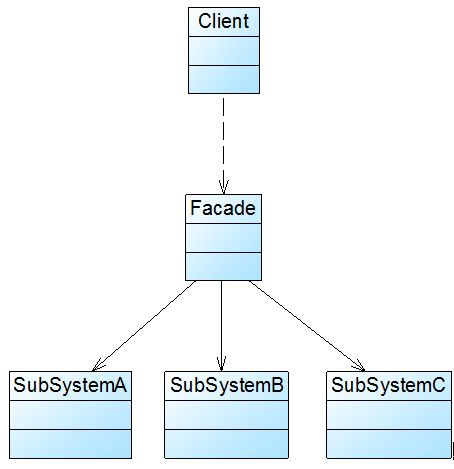
图3 外观模式结构图
外观模式包含如下两个角色:
-
Facade(外观角色):在客户端可以调用它的方法,在外观角色中可以知道相关的(一个或者多个)子系统的功能和责任;在正常情况下,它将所有从客户端发来的请求委派到相应的子系统去,传递给相应的子系统对象处理。
-
SubSystem(子系统角色):在软件系统中可以有一个或者多个子系统角色,每一个子系统可以不是一个单独的类,而是一个类的集合,它实现子系统的功能;每一个子系统都可以被客户端直接调用,或者被外观角色调用,它处理由外观类传过来的请求;子系统并不知道外观的存在,对于子系统而言,外观角色仅仅是另外一个客户端而已。
3)实现
外观模式的主要目的在于降低系统的复杂程度,在面向对象软件系统中,类与类之间的关系越多,不能表示系统设计得越好,反而表示系统中类之间的耦合度太大,这样的系统在维护和修改时都缺乏灵活性,因为一个类的改动会导致多个类发生变化,而外观模式的引入在很大程度上降低了类与类之间的耦合关系。引入外观模式之后,增加新的子系统或者移除子系统都非常方便,客户类无须进行修改(或者极少的修改),只需要在外观类中增加或移除对子系统的引用即可。从这一点来说,外观模式在一定程度上并不符合开闭原则,增加新的子系统需要对原有系统进行一定的修改,虽然这个修改工作量不大。
外观模式中所指的子系统是一个广义的概念,它可以是一个类、一个功能模块、系统的一个组成部分或者一个完整的系统。子系统类通常是一些业务类,实现了一些具体的、独立的业务功能,其典型代码如下:
class SubSystemA
{
public void MethodA()
{
//业务实现代码
}
}
class SubSystemB
{
public void MethodB()
{
//业务实现代码
}
}
class SubSystemC
{
public void MethodC()
{
//业务实现代码
}
}
在引入外观类之后,与子系统业务类之间的交互统一由外观类来完成,在外观类中通常存在如下代码:
class Facade
{
private SubSystemA obj1 = new SubSystemA();
private SubSystemB obj2 = new SubSystemB();
private SubSystemC obj3 = new SubSystemC();
public void Method()
{
obj1.MethodA();
obj2.MethodB();
obj3.MethodC();
}
}
由于在外观类中维持了对子系统对象的引用,客户端可以通过外观类来间接调用子系统对象的业务方法,而无须与子系统对象直接交互。引入外观类后,客户端代码变得非常简单,典型代码如下:
class Program
{
static void Main(string[] args)
{
Facade facade = new Facade();
facade.Method();
}
}
4)抽象外观类
在标准的外观模式结构图中,如果需要增加、删除或更换与外观类交互的子系统类,必须修改外观类或客户端的源代码,这将违背开闭原则,因此可以通过引入抽象外观类来对系统进行改进,在一定程度上可以解决该问题。在引入抽象外观类之后,客户端可以针对抽象外观类进行编程,对于新的业务需求,不需要修改原有外观类,而对应增加一个新的具体外观类,由新的具体外观类来关联新的子系统对象,同时通过修改配置文件来达到不修改任何源代码并更换外观类的目的。
5)外观模式效果与使用场景
外观模式是一种使用频率非常高的设计模式,它通过引入一个外观角色来简化客户端与子系统之间的交互,为复杂的子系统调用提供一个统一的入口,使子系统与客户端的耦合度降低,且客户端调用非常方便。外观模式并不给系统增加任何新功能,它仅仅是简化调用接口。在几乎所有的软件中都能够找到外观模式的应用,如绝大多数B/S系统都有一个首页或者导航页面,大部分C/S系统都提供了菜单或者工具栏,在这里,首页和导航页面就是B/S系统的外观角色,而菜单和工具栏就是C/S系统的外观角色,通过它们用户可以快速访问子系统,降低了系统的复杂程度。所有涉及到与多个业务对象交互的场景都可以考虑使用外观模式进行重构。
6)总结
外观模式的主要优点如下:
- 它对客户端屏蔽了子系统组件,减少了客户端所需处理的对象数目,并使得子系统使用起来更加容易。通过引入外观模式,客户端代码将变得很简单,与之关联的对象也很少。
- 它实现了子系统与客户端之间的松耦合关系,这使得子系统的变化不会影响到调用它的客户端,只需要调整外观类即可。
- 一个子系统的修改对其他子系统没有任何影响,而且子系统内部变化也不会影响到外观对象。
外观模式的主要缺点如下:
- 不能很好地限制客户端直接使用子系统类,如果对客户端访问子系统类做太多的限制则减少了可变性和灵活 性。
- 如果设计不当,增加新的子系统可能需要修改外观类的源代码,违背了开闭原则。
适用场景:
在以下情况下可以考虑使用外观模式:
- 当要为访问一系列复杂的子系统提供一个简单入口时可以使用外观模式。
- 客户端程序与多个子系统之间存在很大的依赖性。引入外观类可以将子系统与客户端解耦,从而提高子系统的独立性和可移植性。
- 在层次化结构中,可以使用外观模式定义系统中每一层的入口,层与层之间不直接产生联系,而通过外观类建立联系,降低层之间的耦合度。
6、享元模式-Flyweight Pattern——实现对象的复用
在软件系统中,有时候也会存在资源浪费的情况,例如在计算机内存中存储了多个完全相同或者非常相似的对象,如果这些对象的数量太多将导致系统运行代价过高,内存属于计算机的“稀缺资源”,不应该用来“随便浪费”,那么是否存在一种技术可以用于节约内存使用空间,实现对这些相同或者相似对象的共享访问呢?享元模式就是这样的技术。
1)概述
当一个软件系统在运行时产生的对象数量太多,将导致运行代价过高,带来系统性能下降等问题。例如在一个文本字符串中存在很多重复的字符,如果每一个字符都用一个单独的对象来表示,将会占用较多的内存空间,那么我们如何去避免系统中出现大量相同或相似的对象,同时又不影响客户端程序通过面向对象的方式对这些对象进行操作?享元模式正为解决这一类问题而诞生。享元模式通过共享技术实现相同或相似对象的重用,在逻辑上每一个出现的字符都有一个对象与之对应,然而在物理上它们却共享同一个享元对象,这个对象可以出现在一个字符串的不同地方,相同的字符对象都指向同一个实例,在享元模式中,存储这些共享实例对象的地方称为享元池(Flyweight Pool)。我们可以针对每一个不同的字符创建一个享元对象,将其放在享元池中,需要时再从享元池取出。如图所示:
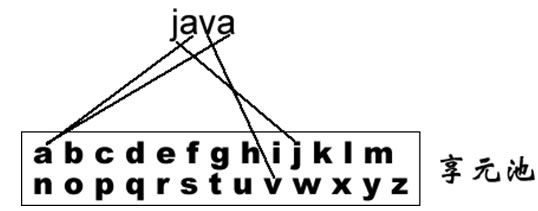
享元模式以共享的方式高效地支持大量细粒度对象的重用,享元对象能做到共享的关键是区分了内部状态(Intrinsic State)和外部状态(Extrinsic State)。下面将对享元的内部状态和外部状态进行简单的介绍:
- 内部状态是存储在享元对象内部并且不会随环境改变而改变的状态,内部状态可以共享。如字符的内容,不会随外部环境的变化而变化,无论在任何环境下字符“a”始终是“a”,都不会变成“b”。
- 外部状态是随环境改变而改变的、不可以共享的状态。享元对象的外部状态通常由客户端保存,并在享元对象被创建之后,需要使用的时候再传入到享元对象内部。一个外部状态与另一个外部状态之间是相互独立的。如字符的颜色,可以在不同的地方有不同的颜色,例如有的“a”是红色的,有的“a”是绿色的,字符的大小也是如此,有的“a”是五号字,有的“a”是四号字。而且字符的颜色和大小是两个独立的外部状态,它们可以独立变化,相互之间没有影响,客户端可以在使用时将外部状态注入享元对象中。
正因为区分了内部状态和外部状态,我们可以将具有相同内部状态的对象存储在享元池中,享元池中的对象是可以实现共享的,需要的时候就将对象从享元池中取出,实现对象的复用。通过向取出的对象注入不同的外部状态,可以得到一系列相似的对象,而这些对象在内存中实际上只存储一份。
享元模式定义如下:
享元模式(Flyweight Pattern):运用共享技术有效地支持大量细粒度对象的复用。系统只使用少量的对象,而这些对象都很相似,状态变化很小,可以实现对象的多次复用。由于享元模式要求能够共享的对象必须是细粒度对象,因此它又称为轻量级模式,它是一种对象结构型模式。
2)结构
享元模式结构较为复杂,一般结合工厂模式一起使用,在它的结构图中包含了一个享元工厂类,其结构图如图所示:

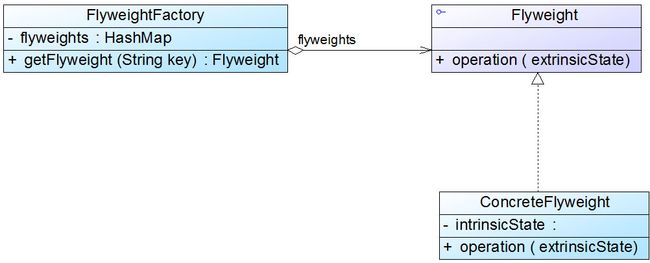
在享元模式结构图中包含如下几个角色:
- Flyweight(抽象享元类):通常是一个接口或抽象类,在抽象享元类中声明了具体享元类公共的方法,这些方法可以向外界提供享元对象的内部数据(内部状态),同时也可以通过这些方法来设置外部数据(外部状态)。
- ConcreteFlyweight(具体享元类):它实现了抽象享元类,其实例称为享元对象;在具体享元类中为内部状态提供了存储空间。通常我们可以结合单例模式来设计具体享元类,为每一个具体享元类提供唯一的享元对象。
- UnsharedConcreteFlyweight(非共享具体享元类):并不是所有的抽象享元类的子类都需要被共享,不能被共享的子类可设计为非共享具体享元类;当需要一个非共享具体享元类的对象时可以直接通过实例化创建。
- FlyweightFactory(享元工厂类):享元工厂类用于创建并管理享元对象,它针对抽象享元类编程,将各种类型的具体享元对象存储在一个享元池中,享元池一般设计为一个存储“键值对”的集合(也可以是其他类型的集合),可以结合工厂模式进行设计;当用户请求一个具体享元对象时,享元工厂提供一个存储在享元池中已创建的实例或者创建一个新的实例(如果不存在的话),返回新创建的实例并将其存储在享元池中。
在享元模式中引入了享元工厂类,享元工厂类的作用在于提供一个用于存储享元对象的享元池,当用户需要对象时,首先从享元池中获取,如果享元池中不存在,则创建一个新的享元对象返回给用户,并在享元池中保存该新增对象。典型的享元工厂类的代码如下:
class FlyweightFactory {
//定义一个HashMap用于存储享元对象,实现享元池
private final HashMap flyweights = newHashMap();
public Flyweight getFlyweight(String key) {
//如果对象存在,则直接从享元池获取
if (flyweights.containsKey(key)) {
return (Flyweight) flyweights.get(key);
}
//如果对象不存在,先创建一个新的对象添加到享元池中,然后返回
else {
Flyweight fw = newConcreteFlyweight();
flyweights.put(key, fw);
return fw;
}
}
}
享元类的设计是享元模式的要点之一,在享元类中要将内部状态和外部状态分开处理,通常将内部状态作为享元类的成员变量,而外部状态通过注入的方式添加到享元类中。典型的享元类代码如下所示:
class Flyweight {
//内部状态intrinsicState作为成员变量,同一个享元对象其内部状态是一致的
private final String intrinsicState;
public Flyweight(String intrinsicState) {
this.intrinsicState = intrinsicState;
}
//外部状态extrinsicState在使用时由外部设置,不保存在享元对象中,即使是同一个对象,在每一次调用时也可以传入不同的外部状态
public void operation(String extrinsicState) {
......
}
}
示例:
JAVA:https://blog.csdn.net/lovelion/article/details/7667839
C++:https://www.cnblogs.com/jiese/p/3171463.html
3)单纯享元模式和复合享元模式
标准的享元模式结构图中既包含可以共享的具体享元类,也包含不可以共享的非共享具体享元类。但是在实际使用过程中,我们有时候会用到两种特殊的享元模式:单纯享元模式和复合享元模式,下面将对这两种特殊的享元模式进行简单的介绍:
1.单纯享元模式
在单纯享元模式中,所有的具体享元类都是可以共享的,不存在非共享具体享元类。单纯享元模式的结构如图所示:
 2.复合享元模式
2.复合享元模式
将一些单纯享元对象使用组合模式加以组合,还可以形成复合享元对象,这样的复合享元对象本身不能共享,但是它们可以分解成单纯享元对象,而后者则可以共享。复合享元模式的结构如图所示:
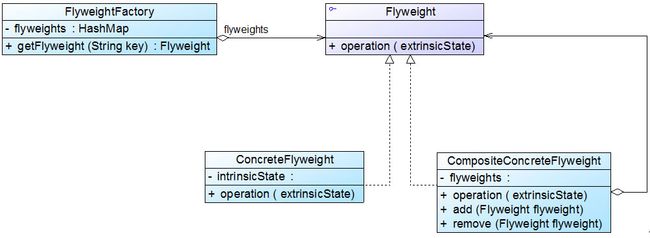 通过复合享元模式,可以确保复合享元类CompositeConcreteFlyweight中所包含的每个单纯享元类ConcreteFlyweight都具有相同的外部状态,而这些单纯享元的内部状态往往可以不同。如果希望为多个内部状态不同的享元对象设置相同的外部状态,可以考虑使用复合享元模式。
通过复合享元模式,可以确保复合享元类CompositeConcreteFlyweight中所包含的每个单纯享元类ConcreteFlyweight都具有相同的外部状态,而这些单纯享元的内部状态往往可以不同。如果希望为多个内部状态不同的享元对象设置相同的外部状态,可以考虑使用复合享元模式。
4)几点补充
1.与其他模式的联用
享元模式通常需要和其他模式一起联用,几种常见的联用方式如下:
- 在享元模式的享元工厂类中通常提供一个静态的工厂方法用于返回享元对象,使用简单工厂模式来生成享元对象。
- 在一个系统中,通常只有唯一一个享元工厂,因此可以使用单例模式进行享元工厂类的设计。
- 享元模式可以结合组合模式形成复合享元模式,统一对多个享元对象设置外部状态。
2.享元模式与String类
JDK类库中的String类使用了享元模式,我们通过如下代码来加以说明:
class Demo {
public static void main(String args[]) {
String str1 = "abcd";
String str2 = "abcd";
String str3 = "ab" + "cd";
String str4 = "ab";
str4 += "cd";
System.out.println(str1 == str2);
System.out.println(str1 == str3);
System.out.println(str1 == str4);
str2 += "e";
System.out.println(str1 == str2);
}
}
在Java语言中,如果每次执行类似String str1=“abcd"的操作时都创建一个新的字符串对象将导致内存开销很大,因此如果第一次创建了内容为"abcd"的字符串对象str1,下一次再创建内容相同的字符串对象str2时会将它的引用指向"abcd”,不会重新分配内存空间,从而实现了"abcd"在内存中的共享。上述代码输出结果如下:
true
true
false
false
可以看出,前两个输出语句均为true,说明str1、str2、str3在内存中引用了相同的对象;如果有一个字符串str4,其初值为"ab",再对它进行操作str4 += “cd”,此时虽然str4的内容与str1相同,但是由于str4的初始值不同,在创建str4时重新分配了内存,所以第三个输出语句结果为false;最后一个输出语句结果也为false,说明当对str2进行修改时将创建一个新的对象,修改工作在新对象上完成,而原来引用的对象并没有发生任何改变,str1仍然引用原有对象,而str2引用新对象,str1与str2引用了两个完全不同的对象。
扩展 关于Java String类这种在修改享元对象时,先将原有对象复制一份,然后在新对象上再实施修改操作的机制称为“Copy On Write”,大家可以自行查询相关资料来进一步了解和学习“Copy On Write”机制,在此不作详细说明。
5)总结
当系统中存在大量相同或者相似的对象时,享元模式是一种较好的解决方案,它通过共享技术实现相同或相似的细粒度对象的复用,从而节约了内存空间,提高了系统性能。相比其他结构型设计模式,享元模式的使用频率并不算太高,但是作为一种以“节约内存,提高性能”为出发点的设计模式,它在软件开发中还是得到了一定程度的应用。
1.主要优点
享元模式的主要优点如下:
- 可以极大减少内存中对象的数量,使得相同或相似对象在内存中只保存一份,从而可以节约系统资源,提高系统性能。
- 享元模式的外部状态相对独立,而且不会影响其内部状态,从而使得享元对象可以在不同的环境中被共享。
2.主要缺点
享元模式的主要缺点如下:
- 享元模式使得系统变得复杂,需要分离出内部状态和外部状态,这使得程序的逻辑复杂化。
- 为了使对象可以共享,享元模式需要将享元对象的部分状态外部化,而读取外部状态将使得运行时间变长。
3.适用场景
在以下情况下可以考虑使用享元模式:
- 一个系统有大量相同或者相似的对象,造成内存的大量耗费。
- 对象的大部分状态都可以外部化,可以将这些外部状态传入对象中。
- 在使用享元模式时需要维护一个存储享元对象的享元池,而这需要耗费一定的系统资源,因此,应当在需要多次重复使用享元对象时才值得使用享元模式。
7、代理模式-Proxy Pattern
代理模式是常用的结构型设计模式之一,当无法直接访问某个对象或访问某个对象存在困难时可以通过一个代理对象来间接访问,为了保证客户端使用的透明性,所访问的真实对象与代理对象需要实现相同的接口。根据代理模式的使用目的不同,代理模式又可以分为多种类型,例如保护代理、远程代理、虚拟代理、缓冲代理等,它们应用于不同的场合,满足用户的不同需求。
1)概述
在软件开发中由于某些原因,客户端不想或不能直接访问一个对象,此时可以通过一个称之为“代理”的第三者来实现间接访问,该方案对应的设计模式被称为代理模式。
代理模式是一种应用很广泛的结构型设计模式,而且变化形式非常多,常见的代理形式包括远程代理、保护代理、虚拟代理、缓冲代理、智能引用代理等,后面将学习这些不同的代理形式。
代理模式定义如下:
代理模式:给某一个对象提供一个代理或占位符,并由代理对象来控制对原对象的访问。
代理模式是一种对象结构型模式。在代理模式中引入了一个新的代理对象,代理对象在客户端对象和目标对象之间起到中介的作用,它去掉客户不能看到的内容和服务或者增添客户需要的额外的新服务。
2)结构与实现
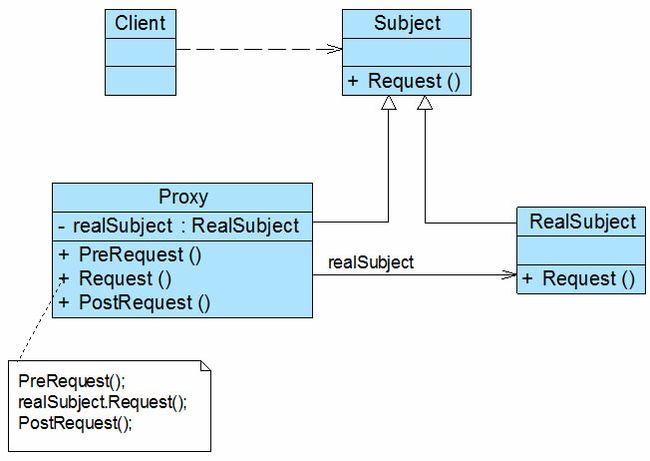
代理模式的结构比较简单,其核心是代理类,为了让客户端能够一致性地对待真实对象和代理对象,在代理模式中引入了抽象层,代理模式结构如图所示:
 代理模式包含如下三个角色:
代理模式包含如下三个角色:
- Subject(抽象主题角色):它声明了真实主题和代理主题的共同接口,这样一来在任何使用真实主题的地方都可以使用代理主题,客户端通常需要针对抽象主题角色进行编程。
- Proxy(代理主题角色):它包含了对真实主题的引用,从而可以在任何时候操作真实主题对象;在代理主题角色中提供一个与真实主题角色相同的接口,以便在任何时候都可以替代真实主题;代理主题角色还可以控制对真实主题的使用,负责在需要的时候创建和删除真实主题对象,并对真实主题对象的使用加以约束。通常,在代理主题角色中,客户端在调用所引用的真实主题操作之前或之后还需要执行其他操作,而不仅仅是单纯调用真实主题对象中的操作。
- RealSubject(真实主题角色):它定义了代理角色所代表的真实对象,在真实主题角色中实现了真实的业务操作,客户端可以通过代理主题角色间接调用真实主题角色中定义的操作。
代理模式的结构图比较简单,但是在真实的使用和实现过程中要复杂很多,特别是代理类的设计和实现。
抽象主题类声明了真实主题类和代理类的公共方法,它可以是接口、抽象类或具体类,客户端针对抽象主题类编程,一致性地对待真实主题和代理主题,典型的抽象主题类代码如下:
abstract class Subject
{
public abstract void Request();
}
真实主题类继承了抽象主题类,提供了业务方法的具体实现,其典型代码如下:
class RealSubject : Subject
{
public override void Request()
{
//业务方法具体实现代码
}
}
代理类也是抽象主题类的子类,它维持一个对真实主题对象的引用,调用在真实主题中实现的业务方法,在调用时可以在原有业务方法的基础上附加一些新的方法来对功能进行扩充或约束,最简单的代理类实现代码如下:
class Proxy : Subject
{
private RealSubject realSubject = new RealSubject(); //维持一个对真实主题对象的引用
public void PreRequest()
{
…...
}
public override void Request()
{
PreRequest();
realSubject.Request(); //调用真实主题对象的方法
PostRequest();
}
public void PostRequest()
{
……
}
}
示例:
C#:https://blog.csdn.net/lovelion/article/details/8228042
C++:https://www.cnblogs.com/jiese/p/3177491.html
在实际开发过程中,代理类的实现比上述代码要复杂很多,代理模式根据其目的和实现方式不同可分为很多种类,其中常用的几种代理模式简要说明如下:
- 远程代理(Remote Proxy):为一个位于不同的地址空间的对象提供一个本地的代理对象,这个不同的地址空间可以是在同一台主机中,也可是在另一台主机中,远程代理又称为大使(Ambassador)。
- 虚拟代理(Virtual Proxy):如果需要创建一个资源消耗较大的对象,先创建一个消耗相对较小的对象来表示,真实对象只在需要时才会被真正创建。
- 保护代理(Protect Proxy):控制对一个对象的访问,可以给不同的用户提供不同级别的使用权限。
- 缓冲代理(Cache Proxy):为某一个目标操作的结果提供临时的存储空间,以便多个客户端可以共享这些结果。
- 智能引用代理(Smart Reference Proxy):当一个对象被引用时,提供一些额外的操作,例如将对象被调用的次数记录下来等。
在这些常用的代理模式中,有些代理类的设计非常复杂,例如远程代理类,它封装了底层网络通信和对远程对象的调用,其实现较为复杂。
1. 远程代理
远程代理(Remote Proxy) 是一种常用的代理模式,它使得客户端程序可以访问在远程主机上的对象,远程主机可能具有更好的计算性能与处理速度,可以快速响应并处理客户端的请求。远程代理可以将网络的细节隐藏起来,使得客户端不必考虑网络的存在。客户端完全可以认为被代理的远程业务对象是在本地而不是在远程,而远程代理对象承担了大部分的网络通信工作,并负责对远程业务方法的调用。
远程代理示意图如图15-5所示,客户端对象不能直接访问远程主机中的业务对象,只能采取间接访问的方式。远程业务对象在本地主机中有一个代理对象,该代理对象负责对远程业务对象的访问和网络通信,它对于客户端对象而言是透明的。客户端无须关心实现具体业务的是谁,只需要按照服务接口所定义的方式直接与本地主机中的代理对象交互即可。
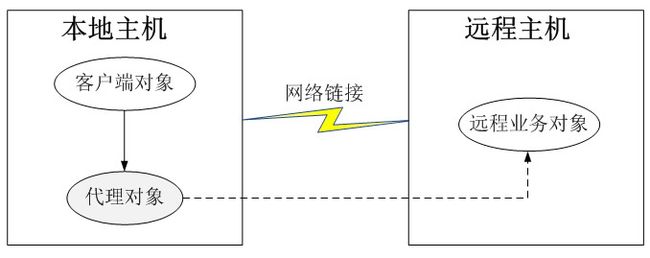
2.虚拟代理
虚拟代理(Virtual Proxy) 也是一种常用的代理模式,对于一些占用系统资源较多或者加载时间较长的对象,可以给这些对象提供一个虚拟代理。在真实对象创建成功之前虚拟代理扮演真实对象的替身,而当真实对象创建之后,虚拟代理将用户的请求转发给真实对象。
通常,在以下两种情况下可以考虑使用虚拟代理:
- 由于对象本身的复杂性或者网络等原因导致一个对象需要较长的加载时间,此时可以用一个加载时间相对较短的代理对象来代表真实对象。通常在实现时可以结合多线程技术,一个线程用于显示代理对象,其他线程用于加载真实对象。这种虚拟代理模式可以应用在程序启动的时候,由于创建代理对象在时间和处理复杂度上要少于创建真实对象,因此,在程序启动时,可以用代理对象代替真实对象初始化,大大加速了系统的启动时间。当需要使用真实对象时,再通过代理对象来引用,而此时真实对象可能已经成功加载完毕,可以缩短用户的等待时间。
- 当一个对象的加载十分耗费系统资源的时候,也非常适合使用虚拟代理。虚拟代理可以让那些占用大量内存或处理起来非常复杂的对象推迟到使用它们的时候才创建,而在此之前用一个相对来说占用资源较少的代理对象来代表真实对象,再通过代理对象来引用真实对象。为了节省内存,在第一次引用真实对象时再创建对象,并且该对象可被多次重用,在以后每次访问时需要检测所需对象是否已经被创建,因此在访问该对象时需要进行存在性检测,这需要消耗一定的系统时间,但是可以节省内存空间,这是一种用时间换取空间的做法。
无论是以上哪种情况,虚拟代理都是用一个“虚假”的代理对象来代表真实对象,通过代理对象来间接引用真实对象,可以在一定程度上提高系统的性能。
3.缓冲代理
缓冲代理(Cache Proxy) 也是一种较为常用的代理模式,它为某一个操作的结果提供临时的缓存存储空间,以便在后续使用中能够共享这些结果,从而可以避免某些方法的重复执行,优化系统性能。
在微软示例项目PetShop 4.0的业务逻辑层(Business Logic Layer, BLL)中定义了Product、Category、Item等类,它们封装了相关的业务方法,用于调用数据访问层(Data Access Layer, DAL)对象访问数据库,以获取相关数据。为了改进系统性能,PetShop 4.0为这些实现方法增加缓存机制,引入一个新的对象去控制原来的BLL业务逻辑对象,这些新的对象对应于代理模式中的代理对象。在引入代理模式后,实现了在缓存级别上对业务对象的封装,增强了对业务对象的控制,如果需要访问的数据在缓存中已经存在,则无须再重复执行获取数据的方法,直接返回存储在缓存中的数据即可。由于原有业务对象(真实对象)和新增代理对象暴露在外的方法是一致的,因而对于调用方即客户端而言,调用代理对象与真实对象并没有实质的区别。
3)总结
1.代理模式的共同优点如下:
- 能够协调调用者和被调用者,在一定程度上降低了系统的耦合度。
- 客户端可以针对抽象主题角色进行编程,增加和更换代理类无须修改源代码,符合开闭原则,系统具有较好的灵活性和可扩展性。
此外,不同类型的代理模式也具有独特的优点,例如:
- 远程代理为位于两个不同地址空间对象的访问提供了一种实现机制,可以将一些消耗资源较多的对象和操作移至性能更好的计算机上,提高系统的整体运行效率。
- 虚拟代理通过一个消耗资源较少的对象来代表一个消耗资源较多的对象,可以在一定程度上节省系统的运行开销。
- 缓冲代理为某一个操作的结果提供临时的缓存存储空间,以便在后续使用中能够共享这些结果,优化系统性能,缩短执行时间。
- 保护代理可以控制对一个对象的访问权限,为不同用户提供不同级别的使用权限。
2.代理模式的主要缺点如下:
- 由于在客户端和真实主题之间增加了代理对象,因此有些类型的代理模式可能会造成请求的处理速度变慢,例如保护代理。
- 实现代理模式需要额外的工作,而且有些代理模式的实现过程较为复杂,例如远程代理。
3.适用场景:
代理模式的类型较多,不同类型的代理模式有不同的优缺点,它们应用于不同的场合:
- 当客户端对象需要访问远程主机中的对象时可以使用远程代理。
- 当需要用一个消耗资源较少的对象来代表一个消耗资源较多的对象,从而降低系统开销、缩短运行时间时可以使用虚拟代理,例如一个对象需要很长时间才能完成加载时。
- 当需要为某一个被频繁访问的操作结果提供一个临时存储空间,以供多个客户端共享访问这些结果时可以使用缓冲代理。通过使用缓冲代理,系统无须在客户端每一次访问时都重新执行操作,只需直接从临时缓冲区获取操作结果即可。
- 当需要控制对一个对象的访问,为不同用户提供不同级别的访问权限时可以使用保护代理。
- 当需要为一个对象的访问(引用)提供一些额外的操作时可以使用智能引用代理。
四、十一个行为型模式
1、职责链模式-Chain of Responsibility Pattern——请求的链式处理
采购单的分级审批:
1)概述
很多情况下,在一个软件系统中可以处理某个请求的对象不止一个,例如SCM系统中的采购单审批,主任、副董事长、董事长和董事会都可以处理采购单,他们可以构成一条处理采购单的链式结构,采购单沿着这条链进行传递,这条链就称为职责链。职责链可以是一条直线、一个环或者一个树形结构,最常见的职责链是直线型,即沿着一条单向的链来传递请求。链上的每一个对象都是请求处理者,职责链模式可以将请求的处理者组织成一条链,并让请求沿着链传递,由链上的处理者对请求进行相应的处理,客户端无须关心请求的处理细节以及请求的传递,只需将请求发送到链上即可,实现请求发送者和请求处理者解耦。
职责链模式定义如下:
职责链模式(Chain of Responsibility Pattern):避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。职责链模式是一种对象行为型模式。
2)结构与实现
职责链模式结构的核心在于引入了一个抽象处理者。职责链模式结构如图所示:
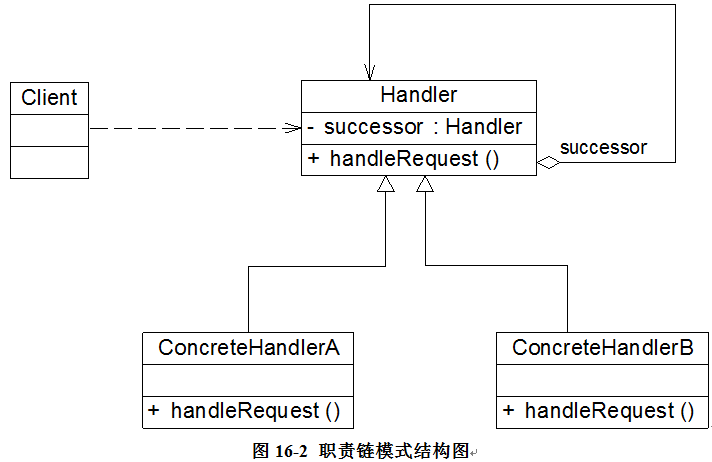 在职责链模式结构图中包含如下几个角色:
在职责链模式结构图中包含如下几个角色:
- Handler(抽象处理者):它定义了一个处理请求的接口,一般设计为抽象类,由于不同的具体处理者处理请求的方式不同,因此在其中定义了抽象请求处理方法。因为每一个处理者的下家还是一个处理者,因此在抽象处理者中定义了一个抽象处理者类型的对象(如结构图中的successor),作为其对下家的引用。通过该引用,处理者可以连成一条链。
- ConcreteHandler(具体处理者):它是抽象处理者的子类,可以处理用户请求,在具体处理者类中实现了抽象处理者中定义的抽象请求处理方法,在处理请求之前需要进行判断,看是否有相应的处理权限,如果可以处理请求就处理它,否则将请求转发给后继者;在具体处理者中可以访问链中下一个对象,以便请求的转发。
在职责链模式里,很多对象由每一个对象对其下家的引用而连接起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。发出这个请求的客户端并不知道链上的哪一个对象最终处理这个请求,这使得系统可以在不影响客户端的情况下动态地重新组织链和分配责任。
职责链模式的核心在于抽象处理者类的设计,抽象处理者的典型代码如下所示:
abstract class Handler {
//维持对下家的引用
protected Handler successor;
public void setSuccessor(Handler successor) {
this.successor=successor;
}
public abstract void handleRequest(String request);
}
上述代码中,抽象处理者类定义了对下家的引用对象,以便将请求转发给下家,该对象的访问符可设为protected,在其子类中可以使用。在抽象处理者类中声明了抽象的请求处理方法,具体实现交由子类完成。
具体处理者是抽象处理者的子类,它具有两大作用:
- 第一是处理请求,不同的具体处理者以不同的形式实现抽象请求处理方法handleRequest();
- 第二是转发请求,如果该请求超出了当前处理者类的权限,可以将该请求转发给下家。具体处理者类的典型代码如下:
class ConcreteHandler extends Handler {
public void handleRequest(String request) {
if (请求满足条件) {
//处理请求
}
else {
this.successor.handleRequest(request); //转发请求
}
}
}
在具体处理类中通过对请求进行判断可以做出相应的处理。
需要注意的是,职责链模式并不创建职责链,职责链的创建工作必须由系统的其他部分来完成,一般是在使用该职责链的客户端中创建职责链。职责链模式降低了请求的发送端和接收端之间的耦合,使多个对象都有机会处理这个请求。
3)解决方案
为了让采购单的审批流程更加灵活,并实现采购单的链式传递和处理,Sunny公司开发人员使用职责链模式来实现采购单的分级审批,其基本结构如图16-3所示:

在图中,抽象类Approver充当抽象处理者(抽象传递者),Director、VicePresident、President和Congress充当具体处理者(具体传递者),PurchaseRequest充当请求类。完整代码如下所示:
//采购单:请求类
class PurchaseRequest {
private double amount; //采购金额
private int number; //采购单编号
private String purpose; //采购目的
public PurchaseRequest(double amount, int number, String purpose) {
this.amount = amount;
this.number = number;
this.purpose = purpose;
}
public void setAmount(double amount) {
this.amount = amount;
}
public double getAmount() {
return this.amount;
}
public void setNumber(int number) {
this.number = number;
}
public int getNumber() {
return this.number;
}
public void setPurpose(String purpose) {
this.purpose = purpose;
}
public String getPurpose() {
return this.purpose;
}
}
//审批者类:抽象处理者
abstract class Approver {
protected Approver successor; //定义后继对象
protected String name; //审批者姓名
public Approver(String name) {
this.name = name;
}
//设置后继者
public void setSuccessor(Approver successor) {
this.successor = successor;
}
//抽象请求处理方法
public abstract void processRequest(PurchaseRequest request);
}
//主任类:具体处理者
class Director extends Approver {
public Director(String name) {
super(name);
}
//具体请求处理方法
public void processRequest(PurchaseRequest request) {
if (request.getAmount() < 50000) {
System.out.println("主任" + this.name + "审批采购单:" + request.getNumber() + ",金额:" + request.getAmount() + "元,采购目的:" + request.getPurpose() + "。"); //处理请求
}
else {
this.successor.processRequest(request); //转发请求
}
}
}
//副董事长类:具体处理者
class VicePresident extends Approver {
public VicePresident(String name) {
super(name);
}
//具体请求处理方法
public void processRequest(PurchaseRequest request) {
if (request.getAmount() < 100000) {
System.out.println("副董事长" + this.name + "审批采购单:" + request.getNumber() + ",金额:" + request.getAmount() + "元,采购目的:" + request.getPurpose() + "。"); //处理请求
}
else {
this.successor.processRequest(request); //转发请求
}
}
}
//董事长类:具体处理者
class President extends Approver {
public President(String name) {
super(name);
}
//具体请求处理方法
public void processRequest(PurchaseRequest request) {
if (request.getAmount() < 500000) {
System.out.println("董事长" + this.name + "审批采购单:" + request.getNumber() + ",金额:" + request.getAmount() + "元,采购目的:" + request.getPurpose() + "。"); //处理请求
}
else {
this.successor.processRequest(request); //转发请求
}
}
}
//董事会类:具体处理者
class Congress extends Approver {
public Congress(String name) {
super(name);
}
//具体请求处理方法
public void processRequest(PurchaseRequest request) {
System.out.println("召开董事会审批采购单:" + request.getNumber() + ",金额:" + request.getAmount() + "元,采购目的:" + request.getPurpose() + "。"); //处理请求
}
}
编写如下客户端测试代码:
class Client {
public static void main(String[] args) {
Approver wjzhang,gyang,jguo,meeting;
wjzhang = new Director("张无忌");
gyang = new VicePresident("杨过");
jguo = new President("郭靖");
meeting = new Congress("董事会");
//创建职责链
wjzhang.setSuccessor(gyang);
gyang.setSuccessor(jguo);
jguo.setSuccessor(meeting);
//创建采购单
PurchaseRequest pr1 = new PurchaseRequest(45000,10001,"购买倚天剑");
wjzhang.processRequest(pr1);
PurchaseRequest pr2 = new PurchaseRequest(60000,10002,"购买《葵花宝典》");
wjzhang.processRequest(pr2);
PurchaseRequest pr3 = new PurchaseRequest(160000,10003,"购买《金刚经》");
wjzhang.processRequest(pr3);
PurchaseRequest pr4 = new PurchaseRequest(800000,10004,"购买桃花岛");
wjzhang.processRequest(pr4);
}
}
编译并运行程序,输出结果如下:
主任张无忌审批采购单:10001,金额:45000.0元,采购目的:购买倚天剑。
副董事长杨过审批采购单:10002,金额:60000.0元,采购目的:购买《葵花宝典》。
董事长郭靖审批采购单:10003,金额:160000.0元,采购目的:购买《金刚经》。
召开董事会审批采购单:10004,金额:800000.0元,采购目的:购买桃花岛。
如果需要在系统增加一个新的具体处理者,如增加一个经理(Manager)角色可以审批5万元至8万元(不包括8万元)的采购单,需要编写一个新的具体处理者类Manager,作为抽象处理者类Approver的子类,实现在Approver类中定义的抽象处理方法,如果采购金额大于等于8万元,则将请求转发给下家,代码如下所示:
//经理类:具体处理者
class Manager extends Approver {
public Manager(String name) {
super(name);
}
//具体请求处理方法
public void processRequest(PurchaseRequest request) {
if (request.getAmount() < 80000) {
System.out.println("经理" + this.name + "审批采购单:" + request.getNumber() + ",金额:" + request.getAmount() + "元,采购目的:" + request.getPurpose() + "。"); //处理请求
}
else {
this.successor.processRequest(request); //转发请求
}
}
}
由于链的创建过程由客户端负责,因此增加新的具体处理者类对原有类库无任何影响,无须修改已有类的源代码,符合“开闭原则”。
在客户端代码中,如果要将新的具体请求处理者应用在系统中,需要创建新的具体处理者对象,然后将该对象加入职责链中。如在客户端测试代码中增加如下代码:
Approver rhuang;
rhuang = new Manager("黄蓉");
将职责链代码改为:
//创建职责链
wjzhang.setSuccessor(rhuang); //将“黄蓉”作为“张无忌”的下家
rhuang.setSuccessor(gyang); //将“杨过”作为“黄蓉”的下家
gyang.setSuccessor(jguo);
jguo.setSuccessor(meeting);
由客户端来创建职责链,则不需要在修改职责链时修改源码。
4)纯与不纯的职责链模式
职责链模式可分为纯的职责链模式和不纯的职责链模式两种:
- 纯的职责链模式
一个纯的职责链模式要求一个具体处理者对象只能在两个行为中选择一个:要么承担全部责任,要么将责任推给下家,不允许出现某一个具体处理者对象在承担了一部分或全部责任后又将责任向下传递的情况。而且在纯的职责链模式中,要求一个请求必须被某一个处理者对象所接收,不能出现某个请求未被任何一个处理者对象处理的情况。在前面的采购单审批实例中应用的是纯的职责链模式。 - 不纯的职责链模式
在一个不纯的职责链模式中允许某个请求被一个具体处理者部分处理后再向下传递,或者一个具体处理者处理完某请求后其后继处理者可以继续处理该请求,而且一个请求可以最终不被任何处理者对象所接收。Java AWT 1.0中的事件处理模型应用的是不纯的职责链模式,其基本原理如下:由于窗口组件(如按钮、文本框等)一般都位于容器组件中,因此当事件发生在某一个组件上时,先通过组件对象的handleEvent()方法将事件传递给相应的事件处理方法,该事件处理方法将处理此事件,然后决定是否将该事件向上一级容器组件传播;上级容器组件在接到事件之后可以继续处理此事件并决定是否继续向上级容器组件传播,如此反复,直到事件到达顶层容器组件为止;如果一直传到最顶层容器仍没有处理方法,则该事件不予处理。每一级组件在接收到事件时,都可以处理此事件,而不论此事件是否在上一级已得到处理,还存在事件未被处理的情况。显然,这就是不纯的职责链模式,早期的Java AWT事件模型(JDK 1.0及更早)中的这种事件处理机制又叫事件浮升(Event Bubbling)机制。从Java.1.1以后,JDK使用观察者模式代替职责链模式来处理事件。目前,在JavaScript中仍然可以使用这种事件浮升机制来进行事件处理。
5)总结
职责链模式通过建立一条链来组织请求的处理者,请求将沿着链进行传递,请求发送者无须知道请求在何时、何处以及如何被处理,实现了请求发送者与处理者的解耦。在软件开发中,如果遇到有多个对象可以处理同一请求时可以应用职责链模式,例如在Web应用开发中创建一个过滤器(Filter)链来对请求数据进行过滤,在工作流系统中实现公文的分级审批等等,使用职责链模式可以较好地解决此类问题。
1.主要优点
职责链模式的主要优点如下:
- 职责链模式使得一个对象无须知道是其他哪一个对象处理其请求,对象仅需知道该请求会被处理即可,接收者和发送者都没有对方的明确信息,且链中的对象不需要知道链的结构,由客户端负责链的创建,降低了系统的耦合度。
- 请求处理对象仅需维持一个指向其后继者的引用,而不需要维持它对所有的候选处理者的引用,可简化对象的相互连接。
- 在给对象分派职责时,职责链可以给我们更多的灵活性,可以通过在运行时对该链进行动态的增加或修改来增加或改变处理一个请求的职责。
- 在系统中增加一个新的具体请求处理者时无须修改原有系统的代码,只需要在客户端重新建链即可,从这一点来看是符合“开闭原则”的。
2.主要缺点
职责链模式的主要缺点如下:
- 由于一个请求没有明确的接收者,那么就不能保证它一定会被处理,该请求可能一直到链的末端都得不到处理;一个请求也可能因职责链没有被正确配置而得不到处理。
- 对于比较长的职责链,请求的处理可能涉及到多个处理对象,系统性能将受到一定影响,而且在进行代码调试时不太方便。
- 如果建链不当,可能会造成循环调用,将导致系统陷入死循环。
3.适用场景
在以下情况下可以考虑使用职责链模式:
- 有多个对象可以处理同一个请求,具体哪个对象处理该请求待运行时刻再确定,客户端只需将请求提交到链上,而无须关心请求的处理对象是谁以及它是如何处理的。
- 在不明确指定接收者的情况下,向多个对象中的一个提交一个请求。
- 可动态指定一组对象处理请求,客户端可以动态创建职责链来处理请求,还可以改变链中处理者之间的先后次序。
2、命令模式-Command Pattern——请求发送者与接收者解耦
在软件开发中,我们经常需要向某些对象发送请求(调用其中的某个或某些方法),但是并不知道请求的接收者是谁,也不知道被请求的操作是哪个,此时,我们特别希望能够以一种松耦合的方式来设计软件,使得请求发送者与请求接收者能够消除彼此之间的耦合,让对象之间的调用关系更加灵活,可以灵活地指定请求接收者以及被请求的操作。命令模式为此类问题提供了一个较为完美的解决方案。
1)概述
命令模式可以将请求发送者和接收者完全解耦,发送者与接收者之间没有直接引用关系,发送请求的对象只需要知道如何发送请求,而不必知道如何完成请求。
命令模式定义如下:
命令模式(Command Pattern):将一个请求封装为一个对象,从而让我们可用不同的请求对客户进行参数化;对请求排队或者记录请求日志,以及支持可撤销的操作。命令模式是一种对象行为型模式,其别名为动作(Action)模式或事务(Transaction)模式。
命令模式的定义比较复杂,提到了很多术语,例如“用不同的请求对客户进行参数化”、“对请求排队”,“记录请求日志”、“支持可撤销操作”等,在后面我们将对这些术语进行一一讲解。
2)结构与实现
命令模式的核心在于引入了命令类,通过命令类来降低发送者和接收者的耦合度,请求发送者只需指定一个命令对象,再通过命令对象来调用请求接收者的处理方法,其结构如图3所示:
图3 命令模式结构图
在命令模式结构图中包含如下几个角色:
- Command(抽象命令类):抽象命令类一般是一个抽象类或接口,在其中声明了用于执行请求的execute()等方法,通过这些方法可以调用请求接收者的相关操作。
- ConcreteCommand(具体命令类):具体命令类是抽象命令类的子类,实现了在抽象命令类中声明的方法,它对应具体的接收者对象,将接收者对象的动作绑定其中。在实现execute()方法时,将调用接收者对象的相关操作(Action)。
- Invoker(调用者):调用者即请求发送者,它通过命令对象来执行请求。一个调用者并不需要在设计时确定其接收者,因此它只与抽象命令类之间存在关联关系。在程序运行时可以将一个具体命令对象注入其中,再调用具体命令对象的execute()方法,从而实现间接调用请求接收者的相关操作。
- Receiver(接收者):接收者执行与请求相关的操作,它具体实现对请求的业务处理。
命令模式的本质是对请求进行封装,一个请求对应于一个命令,将发出命令的责任和执行命令的责任分割开。每一个命令都是一个操作:请求的一方发出请求要求执行一个操作;接收的一方收到请求,并执行相应的操作。命令模式允许请求的一方和接收的一方独立开来,使得请求的一方不必知道接收请求的一方的接口,更不必知道请求如何被接收、操作是否被执行、何时被执行,以及是怎么被执行的。
命令模式的关键在于引入了抽象命令类,请求发送者针对抽象命令类编程,只有实现了抽象命令类的具体命令才与请求接收者相关联。在最简单的抽象命令类中只包含了一个抽象的execute()方法,每个具体命令类将一个Receiver类型的对象作为一个实例变量进行存储,从而具体指定一个请求的接收者,不同的具体命令类提供了execute()方法的不同实现,并调用不同接收者的请求处理方法。
典型的抽象命令类代码如下所示:
abstract class Command {
public abstract void execute();
}
对于请求发送者即调用者而言,将针对抽象命令类进行编程,可以通过构造注入或者设值注入的方式在运行时传入具体命令类对象,并在业务方法中调用命令对象的execute()方法,其典型代码如下所示:
class Invoker {
private Command command;
//构造注入
public Invoker(Command command) {
this.command = command;
}
//设值注入
public void setCommand(Command command) {
this.command = command;
}
//业务方法,用于调用命令类的execute()方法
public void call() {
command.execute();
}
}
具体命令类继承了抽象命令类,它与请求接收者相关联,实现了在抽象命令类中声明的execute()方法,并在实现时调用接收者的请求响应方法action(),其典型代码如下所示:
class ConcreteCommand extends Command {
private Receiver receiver; //维持一个对请求接收者对象的引用
public void execute() {
receiver.action(); //调用请求接收者的业务处理方法action()
}
}
请求接收者Receiver类具体实现对请求的业务处理,它提供了action()方法,用于执行与请求相关的操作,其典型代码如下所示:
class Receiver {
public void action() {
//具体操作
}
}
示例:
JAVA:https://blog.csdn.net/lovelion/article/details/8806049
C++:https://www.cnblogs.com/jiese/p/3190414.html
3)命令队列
有时候我们需要将多个请求排队,当一个请求发送者发送一个请求时,将不止一个请求接收者产生响应,这些请求接收者将逐个执行业务方法,完成对请求的处理。此时,我们可以通过命令队列来实现。
命令队列的实现方法有多种形式,其中最常用、灵活性最好的一种方式是增加一个CommandQueue类,由该类来负责存储多个命令对象,而不同的命令对象可以对应不同的请求接收者,CommandQueue类的典型代码如下所示:
import java.util.*;
class CommandQueue {
//定义一个ArrayList来存储命令队列
private ArrayList<Command> commands = new ArrayList<Command>();
public void addCommand(Command command) {
commands.add(command);
}
public void removeCommand(Command command) {
commands.remove(command);
}
//循环调用每一个命令对象的execute()方法
public void execute() {
for (Object command : commands) {
((Command)command).execute();
}
}
}
在增加了命令队列类CommandQueue以后,请求发送者类Invoker将针对CommandQueue编程,代码修改如下:
class Invoker {
private CommandQueue commandQueue; //维持一个CommandQueue对象的引用
//构造注入
public Invoker(CommandQueue commandQueue) {
this. commandQueue = commandQueue;
}
//设值注入
public void setCommandQueue(CommandQueue commandQueue) {
this.commandQueue = commandQueue;
}
//调用CommandQueue类的execute()方法
public void call() {
commandQueue.execute();
}
}
命令队列与我们常说的“批处理”有点类似。批处理,顾名思义,可以对一组对象(命令)进行批量处理,当一个发送者发送请求后,将有一系列接收者对请求作出响应,命令队列可以用于设计批处理应用程序,如果请求接收者的接收次序没有严格的先后次序,我们还可以使用多线程技术来并发调用命令对象的execute()方法,从而提高程序的执行效率。
4)撤销操作
在命令模式中,我们可以通过调用一个命令对象的execute()方法来实现对请求的处理,如果需要撤销(Undo)请求,可通过在命令类中增加一个逆向操作来实现。
扩展
除了通过一个逆向操作来实现撤销(Undo)外,还可以通过保存对象的历史状态来实现撤销,后者可使用备忘录模式(Memento Pattern)来实现。
撤销操作示例:
https://blog.csdn.net/lovelion/article/details/8806509
5)请求日志
请求日志就是将请求的历史记录保存下来,通常以**日志文件(Log File)**的形式永久存储在计算机中。很多系统都提供了日志文件,例如Windows日志文件、Oracle日志文件等,日志文件可以记录用户对系统的一些操作(例如对数据的更改)。请求日志文件可以实现很多功能,常用功能如下:
- “天有不测风云”,一旦系统发生故障,日志文件可以为系统提供一种恢复机制,在请求日志文件中可以记录用户对系统的每一步操作,从而让系统能够顺利恢复到某一个特定的状态;
- 请求日志也可以用于实现批处理,在一个请求日志文件中可以存储一系列命令对象,例如一个命令队列;
- 可以将命令队列中的所有命令对象都存储在一个日志文件中,每执行一个命令则从日志文件中删除一个对应的命令对象,防止因为断电或者系统重启等原因造成请求丢失,而且可以避免重新发送全部请求时造成某些命令的重复执行,只需读取请求日志文件,再继续执行文件中剩余的命令即可。
在实现请求日志时,我们可以将命令对象通过序列化写到日志文件中,此时命令类必须实现java.io.Serializable接口。
具体实现:https://blog.csdn.net/lovelion/article/details/8806643
6)宏命令
宏命令(Macro Command)又称为组合命令,它是组合模式和命令模式联用的产物。宏命令是一个具体命令类,它拥有一个集合属性,在该集合中包含了对其他命令对象的引用。通常宏命令不直接与请求接收者交互,而是通过它的成员来调用接收者的方法。当调用宏命令的execute()方法时,将递归调用它所包含的每个成员命令的execute()方法,一个宏命令的成员可以是简单命令,还可以继续是宏命令。执行一个宏命令将触发多个具体命令的执行,从而实现对命令的批处理,其结构如图所示:
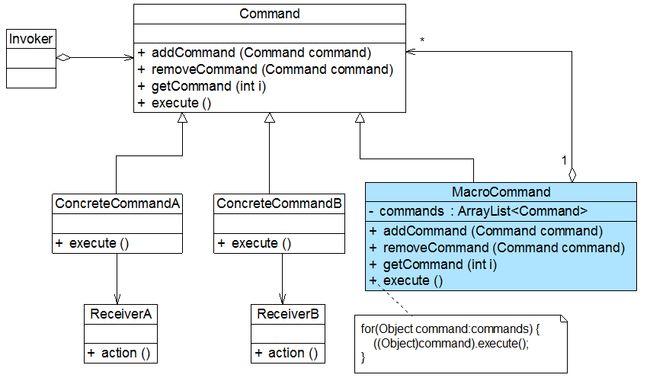
7)总结
命令模式是一种使用频率非常高的设计模式,它可以将请求发送者与接收者解耦,请求发送者通过命令对象来间接引用请求接收者,使得系统具有更好的灵活性和可扩展性。在基于GUI的软件开发,无论是在电脑桌面应用还是在移动应用中,命令模式都得到了广泛的应用。
1. 主要优点
- 降低系统的耦合度。由于请求者与接收者之间不存在直接引用,因此请求者与接收者之间实现完全解耦,相同的请求者可以对应不同的接收者,同样,相同的接收者也可以供不同的请求者使用,两者之间具有良好的独立性。
- 新的命令可以很容易地加入到系统中。由于增加新的具体命令类不会影响到其他类,因此增加新的具体命令类很容易,无须修改原有系统源代码,甚至客户类代码,满足“开闭原则”的要求。
- 可以比较容易地设计一个命令队列或宏命令(组合命令)。
- 为请求的撤销(Undo)和恢复(Redo)操作提供了一种设计和实现方案。
2. 主要缺点
使用命令模式可能会导致某些系统有过多的具体命令类。因为针对每一个对请求接收者的调用操作都需要设计一个具体命令类,因此在某些系统中可能需要提供大量的具体命令类,这将影响命令模式的使用。
3. 适用场景
在以下情况下可以考虑使用命令模式:
- 系统需要将请求调用者和请求接收者解耦,使得调用者和接收者不直接交互。请求调用者无须知道接收者的存在,也无须知道接收者是谁,接收者也无须关心何时被调用。
- 系统需要在不同的时间指定请求、将请求排队和执行请求。一个命令对象和请求的初始调用者可以有不同的生命期,换言之,最初的请求发出者可能已经不在了,而命令对象本身仍然是活动的,可以通过该命令对象去调用请求接收者,而无须关心请求调用者的存在性,可以通过请求日志文件等机制来具体实现。
- 系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作。
- 系统需要将一组操作组合在一起形成宏命令。
3、解释器模式-Interpreter Pattern——自定义语言的实现
虽然目前计算机编程语言有好几百种,但有时候我们还是希望能用一些简单的语言来实现一些特定的操作,我们只要向计算机输入一个句子或文件,它就能够按照预先定义的文法规则来对句子或文件进行解释,从而实现相应的功能。例如提供一个简单的加法/减法解释器,只要输入一个加法/减法表达式,它就能够计算出表达式结果,当输入字符串表达式为“1 + 2 + 3 – 4 + 1”时,将输出计算结果为3。
1)概述
解释器模式是一种使用频率相对较低但学习难度较大的设计模式,它用于描述如何使用面向对象语言构成一个简单的语言解释器。在某些情况下,为了更好地描述某一些特定类型的问题,我们可以创建一种新的语言,这种语言拥有自己的表达式和结构,即文法规则,这些问题的实例将对应为该语言中的句子。此时,可以使用解释器模式来设计这种新的语言。对解释器模式的学习能够加深我们对面向对象思想的理解,并且掌握编程语言中文法规则的解释过程。
解释器模式定义如下:
解释器模式(Interpreter Pattern):定义一个语言的文法,并且建立一个解释器来解释该语言中的句子,这里的“语言”是指使用规定格式和语法的代码。解释器模式是一种类行为型模式。
2)结构与实现
由于表达式可分为终结符表达式和非终结符表达式,因此解释器模式的结构与组合模式的结构有些类似,但在解释器模式中包含更多的组成元素,它的结构如图所示:
 在解释器模式结构图中包含如下几个角色:
在解释器模式结构图中包含如下几个角色:
- AbstractExpression(抽象表达式):在抽象表达式中声明了抽象的解释操作,它是所有终结符表达式和非终结符表达式的公共父类。
- TerminalExpression(终结符表达式):终结符表达式是抽象表达式的子类,它实现了与文法中的终结符相关联的解释操作,在句子中的每一个终结符都是该类的一个实例。通常在一个解释器模式中只有少数几个终结符表达式类,它们的实例可以通过非终结符表达式组成较为复杂的句子。
- NonterminalExpression(非终结符表达式):非终结符表达式也是抽象表达式的子类,它实现了文法中非终结符的解释操作,由于在非终结符表达式中可以包含终结符表达式,也可以继续包含非终结符表达式,因此其解释操作一般通过递归的方式来完成。
- Context(环境类):环境类又称为上下文类,它用于存储解释器之外的一些全局信息,通常它临时存储了需要解释的语句。
在解释器模式中,每一种终结符和非终结符都有一个具体类与之对应,正因为使用类来表示每一条文法规则,所以系统将具有较好的灵活性和可扩展性。对于所有的终结符和非终结符,我们首先需要抽象出一个公共父类,即抽象表达式类,其典型代码如下所示:
abstract class AbstractExpression {
public abstract void interpret(Context ctx);
}
终结符表达式和非终结符表达式类都是抽象表达式类的子类,对于终结符表达式,其代码很简单,主要是对终结符元素的处理,其典型代码如下所示:
class TerminalExpression extends AbstractExpression {
public void interpret(Context ctx) {
//终结符表达式的解释操作
}
}
对于非终结符表达式,其代码相对比较复杂,因为可以通过非终结符将表达式组合成更加复杂的结构,对于包含两个操作元素的非终结符表达式类,其典型代码如下:
class NonterminalExpression extends AbstractExpression {
private AbstractExpression left;
private AbstractExpression right;
public NonterminalExpression(AbstractExpression left, AbstractExpression right) {
this.left = left;
this.right = right;
}
public void interpret(Context ctx) {
//递归调用每一个组成部分的interpret()方法
//在递归调用时指定组成部分的连接方式,即非终结符的功能
}
}
除了上述用于表示表达式的类以外,通常在解释器模式中还提供了一个环境类Context,用于存储一些全局信息,通常在Context中包含了一个HashMap或ArrayList等类型的集合对象(也可以直接由HashMap等集合类充当环境类),存储一系列公共信息,如变量名与值的映射关系(key/value)等,用于在进行具体的解释操作时从中获取相关信息。其典型代码片段如下:
class Context {
private HashMap map = new HashMap();
public void assign(String key, String value) {
//往环境类中设值
}
public String lookup(String key) {
//获取存储在环境类中的值
}
}
当系统无须提供全局公共信息时可以省略环境类,可根据实际情况决定是否需要环境类。
示例:
JAVA:https://blog.csdn.net/lovelion/article/details/7713593
https://blog.csdn.net/lovelion/article/details/7713602
3)总结
解释器模式为自定义语言的设计和实现提供了一种解决方案,它用于定义一组文法规则并通过这组文法规则来解释语言中的句子。虽然解释器模式的使用频率不是特别高,但是它在正则表达式、XML文档解释等领域还是得到了广泛使用。与解释器模式类似,目前还诞生了很多基于抽象语法树的源代码处理工具,例如Eclipse中的Eclipse AST,它可以用于表示Java语言的语法结构,用户可以通过扩展其功能,创建自己的文法规则。
1. 主要优点
- 易于改变和扩展文法。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。
- 每一条文法规则都可以表示为一个类,因此可以方便地实现一个简单的语言。
- 实现文法较为容易。在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂,还可以通过一些工具自动生成节点类代码。
- 增加新的解释表达式较为方便。如果用户需要增加新的解释表达式只需要对应增加一个新的终结符表达式或非终结符表达式类,原有表达式类代码无须修改,符合“开闭原则”。
2. 主要缺点
-
对于复杂文法难以维护。在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护,此时可以考虑使用语法分析程序等方式来取代解释器模式。
-
执行效率较低。由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦。
3. 适用场景
在以下情况下可以考虑使用解释器模式:
-
可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。
-
一些重复出现的问题可以用一种简单的语言来进行表达。
-
一个语言的文法较为简单。
-
执行效率不是关键问题。【注:高效的解释器通常不是通过直接解释抽象语法树来实现的,而是需要将它们转换成其他形式,使用解释器模式的执行效率并不高。】
4、迭代器模式-Iterator Pattern——遍历聚合对象中的元素
1)概述
在软件开发中,我们经常需要使用聚合对象来存储一系列数据。聚合对象拥有两个职责:一是存储数据;二是遍历数据。从依赖性来看,前者是聚合对象的基本职责;而后者既是可变化的,又是可分离的。因此,可以将遍历数据的行为从聚合对象中分离出来,封装在一个被称之为“迭代器”的对象中,由迭代器来提供遍历聚合对象内部数据的行为,这将简化聚合对象的设计,更符合“单一职责原则”的要求。
迭代器模式定义如下:
迭代器模式(Iterator Pattern):提供一种方法来访问聚合对象,而不用暴露这个对象的内部表示,其别名为游标(Cursor)。迭代器模式是一种对象行为型模式。
2)结构与实现
在迭代器模式结构中包含聚合和迭代器两个层次结构,考虑到系统的灵活性和可扩展性,在迭代器模式中应用了工厂方法模式,其模式结构如图所示:
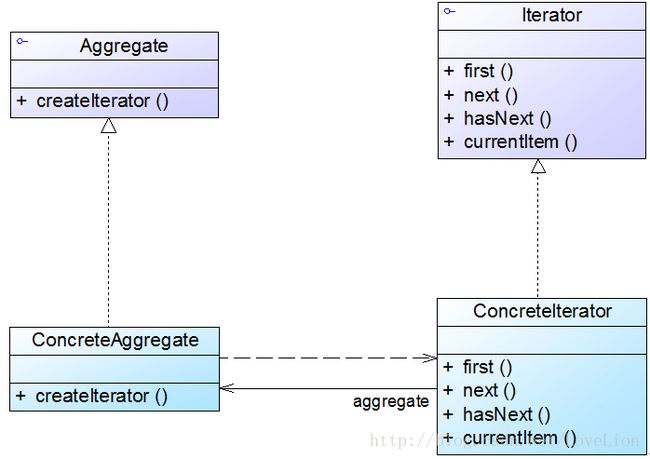
在迭代器模式结构图中包含如下几个角色:
- Iterator(抽象迭代器):它定义了访问和遍历元素的接口,声明了用于遍历数据元素的方法,例如:用于获取第一个元素的first()方法,用于访问下一个元素的next()方法,用于判断是否还有下一个元素的hasNext()方法,用于获取当前元素的currentItem()方法等,在具体迭代器中将实现这些方法。
- ConcreteIterator(具体迭代器):它实现了抽象迭代器接口,完成对聚合对象的遍历,同时在具体迭代器中通过游标来记录在聚合对象中所处的当前位置,在具体实现时,游标通常是一个表示位置的非负整数。
- Aggregate(抽象聚合类):它用于存储和管理元素对象,声明一个createIterator()方法用于创建一个迭代器对象,充当抽象迭代器工厂角色。
- ConcreteAggregate(具体聚合类):它实现了在抽象聚合类中声明的createIterator()方法,该方法返回一个与该具体聚合类对应的具体迭代器ConcreteIterator实例。
在迭代器模式中,提供了一个外部的迭代器来对聚合对象进行访问和遍历,迭代器定义了一个访问该聚合元素的接口,并且可以跟踪当前遍历的元素,了解哪些元素已经遍历过而哪些没有。迭代器的引入,将使得对一个复杂聚合对象的操作变得简单。
下面我们结合代码来对迭代器模式的结构进行进一步分析。在迭代器模式中应用了工厂方法模式,抽象迭代器对应于抽象产品角色,具体迭代器对应于具体产品角色,抽象聚合类对应于抽象工厂角色,具体聚合类对应于具体工厂角色。
在抽象迭代器中声明了用于遍历聚合对象中所存储元素的方法,典型代码如下所示:
interface Iterator {
public void first(); //将游标指向第一个元素
public void next(); //将游标指向下一个元素
public boolean hasNext(); //判断是否存在下一个元素
public Object currentItem(); //获取游标指向的当前元素
}
在具体迭代器中将实现抽象迭代器声明的遍历数据的方法,如下代码所示:
class ConcreteIterator implements Iterator {
private ConcreteAggregate objects; //维持一个对具体聚合对象的引用,以便于访问存储在聚合对象中的数据
private int cursor; //定义一个游标,用于记录当前访问位置
public ConcreteIterator(ConcreteAggregate objects) {
this.objects=objects;
}
public void first() {
...... }
public void next() {
...... }
public boolean hasNext() {
...... }
public Object currentItem() {
...... }
}
需要注意的是抽象迭代器接口的设计非常重要,一方面需要充分满足各种遍历操作的要求,尽量为各种遍历方法都提供声明,另一方面又不能包含太多方法,接口中方法太多将给子类的实现带来麻烦。因此,可以考虑使用抽象类来设计抽象迭代器,在抽象类中为每一个方法提供一个空的默认实现。如果需要在具体迭代器中为聚合对象增加全新的遍历操作,则必须修改抽象迭代器和具体迭代器的源代码,这将违反“开闭原则”,因此在设计时要考虑全面,避免之后修改接口。
聚合类用于存储数据并负责创建迭代器对象,最简单的抽象聚合类代码如下所示:
interface Aggregate {
Iterator createIterator();
}
具体聚合类作为抽象聚合类的子类,一方面负责存储数据,另一方面实现了在抽象聚合类中声明的工厂方法createIterator(),用于返回一个与该具体聚合类对应的具体迭代器对象,代码如下所示:
class ConcreteAggregate implements Aggregate {
......
public Iterator createIterator() {
return new ConcreteIterator(this);
}
......
}
示例:
JAVA:https://blog.csdn.net/lovelion/article/details/9992679
3)总结
迭代器模式是一种使用频率非常高的设计模式,通过引入迭代器可以将数据的遍历功能从聚合对象中分离出来,聚合对象只负责存储数据,而遍历数据由迭代器来完成。由于很多编程语言的类库都已经实现了迭代器模式,因此在实际开发中,我们只需要直接使用Java、C#等语言已定义好的迭代器即可,迭代器已经成为我们操作聚合对象的基本工具之一。
1. 主要优点
迭代器模式的主要优点如下:
- 它支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多种遍历方式。在迭代器模式中只需要用一个不同的迭代器来替换原有迭代器即可改变遍历算法,我们也可以自己定义迭代器的子类以支持新的遍历方式。
- 迭代器简化了聚合类。由于引入了迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法,这样可以简化聚合类的设计。
- 在迭代器模式中,由于引入了抽象层,增加新的聚合类和迭代器类都很方便,无须修改原有代码,满足“开闭原则”的要求。
2. 主要缺点
迭代器模式的主要缺点如下:
- 由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
- 抽象迭代器的设计难度较大,需要充分考虑到系统将来的扩展,例如JDK内置迭代器Iterator就无法实现逆向遍历,如果需要实现逆向遍历,只能通过其子类ListIterator等来实现,而ListIterator迭代器无法用于操作Set类型的聚合对象。在自定义迭代器时,创建一个考虑全面的抽象迭代器并不是件很容易的事情。
3. 适用场景
在以下情况下可以考虑使用迭代器模式:
- 访问一个聚合对象的内容而无须暴露它的内部表示。将聚合对象的访问与内部数据的存储分离,使得访问聚合对象时无须了解其内部实现细节。
- 需要为一个聚合对象提供多种遍历方式。
- 为遍历不同的聚合结构提供一个统一的接口,在该接口的实现类中为不同的聚合结构提供不同的遍历方式,而客户端可以一致性地操作该接口。
5、中介者模式-Mediator Pattern——协调多个对象之间的交互
1)概述
如果在一个系统中对象之间的联系呈现为网状结构,如下图所示。对象之间存在大量的多对多联系,将导致系统非常复杂,这些对象既会影响别的对象,也会被别的对象所影响,这些对象称为同事对象,它们之间通过彼此的相互作用实现系统的行为。在网状结构中,几乎每个对象都需要与其他对象发生相互作用,而这种相互作用表现为一个对象与另外一个对象的直接耦合,这将导致一个过度耦合的系统。
 中介者模式可以使对象之间的关系数量急剧减少,通过引入中介者对象,可以将系统的网状结构变成以中介者为中心的星形结构,如下图所示。在这个星形结构中,同事对象不再直接与另一个对象联系,它通过中介者对象与另一个对象发生相互作用。中介者对象的存在保证了对象结构上的稳定,也就是说,系统的结构不会因为新对象的引入带来大量的修改工作。
中介者模式可以使对象之间的关系数量急剧减少,通过引入中介者对象,可以将系统的网状结构变成以中介者为中心的星形结构,如下图所示。在这个星形结构中,同事对象不再直接与另一个对象联系,它通过中介者对象与另一个对象发生相互作用。中介者对象的存在保证了对象结构上的稳定,也就是说,系统的结构不会因为新对象的引入带来大量的修改工作。
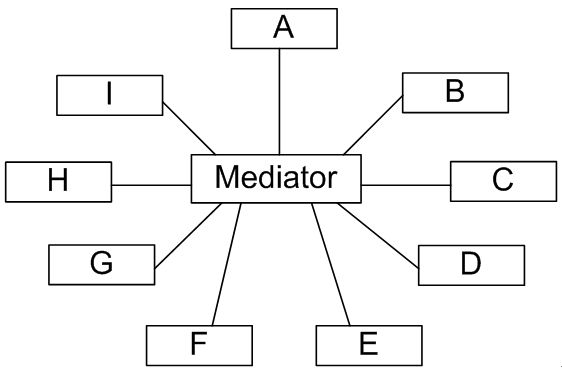 如果在一个系统中对象之间存在多对多的相互关系,我们可以将对象之间的一些交互行为从各个对象中分离出来,并集中封装在一个中介者对象中,并由该中介者进行统一协调,这样对象之间多对多的复杂关系就转化为相对简单的一对多关系。通过引入中介者来简化对象之间的复杂交互,中介者模式是“迪米特法则”的一个典型应用。
如果在一个系统中对象之间存在多对多的相互关系,我们可以将对象之间的一些交互行为从各个对象中分离出来,并集中封装在一个中介者对象中,并由该中介者进行统一协调,这样对象之间多对多的复杂关系就转化为相对简单的一对多关系。通过引入中介者来简化对象之间的复杂交互,中介者模式是“迪米特法则”的一个典型应用。
中介者模式定义如下:
中介者模式(Mediator Pattern):用一个中介对象(中介者)来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。中介者模式又称为调停者模式,它是一种对象行为型模式。
2)结构与实现
在中介者模式中,我们引入了用于协调其他对象/类之间相互调用的中介者类,为了让系统具有更好的灵活性和可扩展性,通常还提供了抽象中介者,其结构图如图所示:
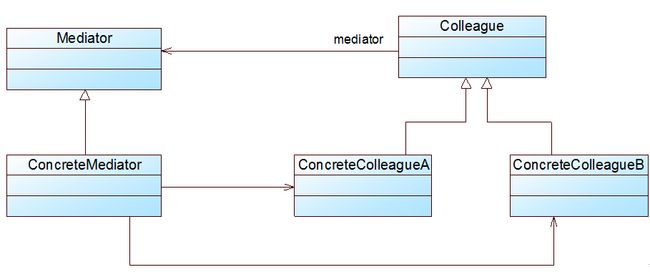
在中介者模式结构图中包含如下几个角色:
- Mediator(抽象中介者):它定义一个接口,该接口用于与各同事对象之间进行通信。
- ConcreteMediator(具体中介者):它是抽象中介者的子类,通过协调各个同事对象来实现协作行为,它维持了对各个同事对象的引用。
- Colleague(抽象同事类):它定义各个同事类公有的方法,并声明了一些抽象方法来供子类实现,同时它维持了一个对抽象中介者类的引用,其子类可以通过该引用来与中介者通信。
- ConcreteColleague(具体同事类):它是抽象同事类的子类;每一个同事对象在需要和其他同事对象通信时,先与中介者通信,通过中介者来间接完成与其他同事类的通信;在具体同事类中实现了在抽象同事类中声明的抽象方法。
中介者模式的核心在于中介者类的引入,在中介者模式中,中介者类承担了两方面的职责:
- 中转作用(结构性):通过中介者提供的中转作用,各个同事对象就不再需要显式引用其他同事,当需要和其他同事进行通信时,可通过中介者来实现间接调用。该中转作用属于中介者在结构上的支持。
- 协调作用(行为性):中介者可以更进一步的对同事之间的关系进行封装,同事可以一致的和中介者进行交互,而不需要指明中介者需要具体怎么做,中介者根据封装在自身内部的协调逻辑,对同事的请求进行进一步处理,将同事成员之间的关系行为进行分离和封装。该协调作用属于中介者在行为上的支持。
在中介者模式中,典型的抽象中介者类代码如下所示:
abstract class Mediator {
protected ArrayList<Colleague> colleagues; //用于存储同事对象
//注册方法,用于增加同事对象
public void register(Colleague colleague) {
colleagues.add(colleague);
}
//声明抽象的业务方法
public abstract void operation();
}
在抽象中介者中可以定义一个同事类的集合,用于存储同事对象并提供注册方法,同时声明了具体中介者类所具有的方法。在具体中介者类中将实现这些抽象方法,典型的具体中介者类代码如下所示:
class ConcreteMediator extends Mediator {
//实现业务方法,封装同事之间的调用
public void operation() {
......
((Colleague)(colleagues.get(0))).method1(); //通过中介者调用同事类的方法
......
}
}
在具体中介者类中将调用同事类的方法,调用时可以增加一些自己的业务代码对调用进行控制。
在抽象同事类中维持了一个抽象中介者的引用,用于调用中介者的方法,典型的抽象同事类代码如下所示:
abstract class Colleague {
protected Mediator mediator; //维持一个抽象中介者的引用
public Colleague(Mediator mediator) {
this.mediator=mediator;
}
public abstract void method1(); //声明自身方法,处理自己的行为
//定义依赖方法,与中介者进行通信
public void method2() {
mediator.operation();
}
}
在抽象同事类中声明了同事类的抽象方法,而在具体同事类中将实现这些方法,典型的具体同事类代码如下所示:
class ConcreteColleague extends Colleague {
public ConcreteColleague(Mediator mediator) {
super(mediator);
}
//实现自身方法
public void method1() {
......
}
}
在具体同事类ConcreteColleague中实现了在抽象同事类中声明的方法,其中方法method1()是同事类的自身方法(Self-Method),用于处理自己的行为,而方法method2()是依赖方法(Depend-Method),用于调用在中介者中定义的方法,依赖中介者来完成相应的行为,例如调用另一个同事类的相关方法。
示例:
C++:https://www.cnblogs.com/jiese/p/3184151.html
JAVA:https://blog.csdn.net/lovelion/article/details/8483031
3)中介者与同事类的扩展
使用了中介者模式,在原有系统中增加新的同事类将变得很容易,我们至少有如下两种解决方案:
-
解决方案一:增加一个ConcreteColleagueC类,修改原有的具体中介者类ConcreteMediator,增加一个对ConcreteColleagueC对象的引用,然后修改operation方法中其他同事类对象的业务处理代码,原有组件类无须任何修改,客户端代码也需针对新增对象进行适当修改。
-
解决方案二:与方案一相同,首先增加一个ConcreteColleagueC类,但不修改原有具体中介者类ConcreteMediator的代码,而是增加一个ConcreteMediator的子类SubConcreteMediator来实现对ConcreteColleagueC对象的引用,然后在新增的中介者类SubConcreteMediator中通过覆盖operation方法来实现所有组件(包括新增对象)之间的交互,同样,原有同事类无须做任何修改,客户端代码需少许修改。
在中介者模式的实际使用过程中,如果需要引入新的具体同事类,只需要继承抽象同事类并实现其中的方法即可,由于具体同事类之间并无直接的引用关系,因此原有所有同事类无须进行任何修改,它们与新增同事对象之间的交互可以通过修改或者增加具体中介者类来实现;如果需要在原有系统中增加新的具体中介者类,只需要继承抽象中介者类(或已有的具体中介者类)并覆盖其中定义的方法即可,在新的具体中介者中可以通过不同的方式来处理对象之间的交互,也可以增加对新增同事的引用和调用。在客户端中只需要修改少许代码(如果引入配置文件的话有时可以不修改任何代码)就可以实现中介者的更换。
4)总结
中介者模式将一个网状的系统结构变成一个以中介者对象为中心的星形结构,在这个星型结构中,使用中介者对象与其他对象的一对多关系来取代原有对象之间的多对多关系。中介者模式在事件驱动类软件中应用较为广泛,特别是基于GUI(Graphical User Interface,图形用户界面)的应用软件,此外,在类与类之间存在错综复杂的关联关系的系统中,中介者模式都能得到较好的应用。
1. 主要优点
中介者模式的主要优点如下:
- 中介者模式简化了对象之间的交互,它用中介者和同事的一对多交互代替了原来同事之间的多对多交互,一对多关系更容易理解、维护和扩展,将原本难以理解的网状结构转换成相对简单的星型结构。
- 中介者模式可将各同事对象解耦。中介者有利于各同事之间的松耦合,我们可以独立的改变和复用每一个同事和中介者,增加新的中介者和新的同事类都比较方便,更好地符合“开闭原则”。
- 可以减少子类生成,中介者将原本分布于多个对象间的行为集中在一起,改变这些行为只需生成新的中介者子类即可,这使各个同事类可被重用,无须对同事类进行扩展。
2. 主要缺点
中介者模式的主要缺点如下:
在具体中介者类中包含了大量同事之间的交互细节,可能会导致具体中介者类非常复杂,使得系统难以维护。
3. 适用场景
在以下情况下可以考虑使用中介者模式:
- 系统中对象之间存在复杂的引用关系,系统结构混乱且难以理解。
- 一个对象由于引用了其他很多对象并且直接和这些对象通信,导致难以复用该对象。
- 想通过一个中间类来封装多个类中的行为,而又不想生成太多的子类。可以通过引入中介者类来实现,在中介者中定义对象交互的公共行为,如果需要改变行为则可以增加新的具体中介者类。
6、备忘录模式-Memento Pattern——撤销功能的实现
1)概述
备忘录模式提供了一种状态恢复的实现机制,使得用户可以方便地回到一个特定的历史步骤,当新的状态无效或者存在问题时,可以使用暂时存储起来的备忘录将状态复原,当前很多软件都提供了撤销(Undo)操作,其中就使用了备忘录模式。
备忘录模式定义如下:
备忘录模式(Memento Pattern):在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样可以在以后将对象恢复到原先保存的状态。它是一种对象行为型模式,其别名为Token。
2)结构与实现
备忘录模式的核心是备忘录类以及用于管理备忘录的负责人类的设计,其结构如图所示:
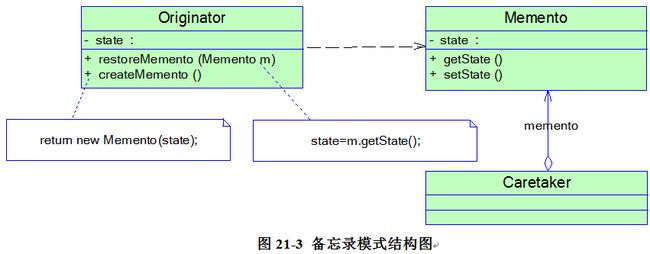 在备忘录模式结构图中包含如下几个角色:
在备忘录模式结构图中包含如下几个角色:
-
Originator(原发器):它是一个普通类,可以创建一个备忘录,并存储它的当前内部状态,也可以使用备忘录来恢复其内部状态,一般将需要保存内部状态的类设计为原发器。
-
Memento(备忘录):存储原发器的内部状态,根据原发器来决定保存哪些内部状态。备忘录的设计一般可以参考原发器的设计,根据实际需要确定备忘录类中的属性。需要注意的是,除了原发器本身与负责人类之外,备忘录对象不能直接供其他类使用,原发器的设计在不同的编程语言中实现机制会有所不同。
-
Caretaker(负责人):负责人又称为管理者,它负责保存备忘录,但是不能对备忘录的内容进行操作或检查。在负责人类中可以存储一个或多个备忘录对象,它只负责存储对象,而不能修改对象,也无须知道对象的实现细节。
理解备忘录模式并不难,但关键在于如何设计备忘录类和负责人类。由于在备忘录中存储的是原发器的中间状态,因此需要防止原发器以外的其他对象访问备忘录,特别是不允许其他对象来修改备忘录。
在C++中可以通过 使Originator类称为Memento类的友元类,Memento类所有成员为private来 实现。
下面我们通过简单的示例代码来说明如何使用Java语言实现备忘录模式:
在使用备忘录模式时,首先应该存在一个原发器类Originator,在真实业务中,原发器类是一个具体的业务类,它包含一些用于存储成员数据的属性,典型代码如下所示:
package dp.memento;
public class Originator {
private String state;
public Originator(){
}
// 创建一个备忘录对象
public Memento createMemento() {
return new Memento(this);
}
// 根据备忘录对象恢复原发器状态
public void restoreMemento(Memento m) {
state = m.state;
}
public void setState(String state) {
this.state=state;
}
public String getState() {
return this.state;
}
}
对于备忘录类Memento而言,它通常提供了与原发器相对应的属性(可以是全部,也可以是部分)用于存储原发器的状态,典型的备忘录类设计代码如下:
package dp.memento;
//备忘录类,默认可见性,包内可见
class Memento {
private String state;
public Memento(Originator o) {
state = o.getState();
}
public void setState(String state) {
this.state=state;
}
public String getState() {
return this.state;
}
}
在设计备忘录类时需要考虑其封装性,除了Originator类,不允许其他类来调用备忘录类Memento的构造函数与相关方法,如果不考虑封装性,允许其他类调用setState()等方法,将导致在备忘录中保存的历史状态发生改变,通过撤销操作所恢复的状态就不再是真实的历史状态,备忘录模式也就失去了本身的意义。
在使用Java语言实现备忘录模式时,一般通过将Memento类与Originator类定义在同一个包(package)中来实现封装,在Java语言中可使用默认访问标识符来定义Memento类,即保证其包内可见。只有Originator类可以对Memento进行访问,而限制了其他类对Memento的访问。在 Memento中保存了Originator的state值,如果Originator中的state值改变之后需撤销,可以通过调用它的restoreMemento()方法进行恢复。
对于负责人类Caretaker,它用于保存备忘录对象,并提供getMemento()方法用于向客户端返回一个备忘录对象,原发器通过使用这个备忘录对象可以回到某个历史状态。典型的负责人类的实现代码如下:
package dp.memento;
public class Caretaker {
private Memento memento;
public Memento getMemento() {
return memento;
}
public void setMemento(Memento memento) {
this.memento=memento;
}
}
在Caretaker类中不应该直接调用Memento中的状态改变方法,它的作用仅仅用于存储备忘录对象。将原发器备份生成的备忘录对象存储在其中,当用户需要对原发器进行恢复时再将存储在其中的备忘录对象取出。
C++完整实现:添加链接描述
JAVA示例:https://blog.csdn.net/lovelion/article/details/7526755
3)实现多次撤销
方法:在负责人类中定义一个集合来存储多个备忘录,每个备忘录负责保存一个历史状态,在撤销时可以对备忘录集合进行逆向遍历,回到一个指定的历史状态,而且还可以对备忘录集合进行正向遍历,实现重做(Redo)操作,即取消撤销,让对象状态得到恢复。
详细:https://blog.csdn.net/lovelion/article/details/7526756
在实际开发中,可以使用链表或者堆栈来处理有分支的对象状态改变。
4)总结
备忘录模式在很多软件的使用过程中普遍存在,但是在应用软件开发中,它的使用频率并不太高,因为现在很多基于窗体和浏览器的应用软件并没有提供撤销操作。如果需要为软件提供撤销功能,备忘录模式无疑是一种很好的解决方案。在一些字处理软件、图像编辑软件、数据库管理系统等软件中备忘录模式都得到了很好的应用。
1.主要优点
- 它提供了一种状态恢复的实现机制,使得用户可以方便地回到一个特定的历史步骤,当新的状态无效或者存在问题时,可以使用暂时存储起来的备忘录将状态复原。
- 备忘录实现了对信息的封装,一个备忘录对象是一种原发器对象状态的表示,不会被其他代码所改动。备忘录保存了原发器的状态,采用列表、堆栈等集合来存储备忘录对象可以实现多次撤销操作。
2.主要缺点
资源消耗过大,如果需要保存的原发器类的成员变量太多,就不可避免需要占用大量的存储空间,每保存一次对象的状态都需要消耗一定的系统资源。
3.适用场景
- 保存一个对象在某一个时刻的全部状态或部分状态,这样以后需要时它能够恢复到先前的状态,实现撤销操作。
- 防止外界对象破坏一个对象历史状态的封装性,避免将对象历史状态的实现细节暴露给外界对象。
7、观察者模式-Observer Pattern——对象间的联动
1)概述
观察者模式是使用频率最高的设计模式之一,它用于建立一种对象与对象之间的依赖关系,一个对象发生改变时将自动通知其他对象,其他对象将相应作出反应。在观察者模式中,发生改变的对象称为观察目标,而被通知的对象称为观察者,一个观察目标可以对应多个观察者,而且这些观察者之间可以没有任何相互联系,可以根据需要增加和删除观察者,使得系统更易于扩展。
观察者模式定义如下:
观察者模式(Observer Pattern):定义对象之间的一种一对多依赖关系,使得每当一个对象状态发生改变时,其相关依赖对象皆得到通知并被自动更新。观察者模式的别名包括发布-订阅(Publish/Subscribe)模式、模型-视图(Model/View)模式、源-监听器(Source/Listener)模式或从属者(Dependents)模式。观察者模式是一种对象行为型模式。
2)结构与实现
观察者模式结构中通常包括观察目标和观察者两个继承层次结构,其结构如图所示:
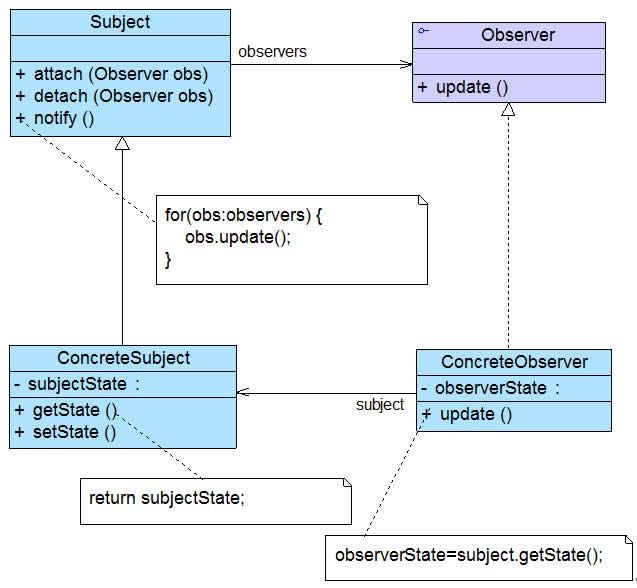
在观察者模式结构图中包含如下几个角色:
- Subject(目标):目标又称为主题,它是指被观察的对象。在目标中定义了一个观察者集合,一个观察目标可以接受任意数量的观察者来观察,它提供一系列方法来增加和删除观察者对象,同时它定义了通知方法notify()。目标类可以是接口,也可以是抽象类或具体类。
- ConcreteSubject(具体目标):具体目标是目标类的子类,通常它包含有经常发生改变的数据,当它的状态发生改变时,向它的各个观察者发出通知;同时它还实现了在目标类中定义的抽象业务逻辑方法(如果有的话)。如果无须扩展目标类,则具体目标类可以省略。
- Observer(观察者):观察者将对观察目标的改变做出反应,观察者一般定义为接口,该接口声明了更新数据的方法update(),因此又称为抽象观察者。
- ConcreteObserver(具体观察者):在具体观察者中维护一个指向具体目标对象的引用,它存储具体观察者的有关状态,这些状态需要和具体目标的状态保持一致;它实现了在抽象观察者Observer中定义的update()方法。通常在实现时,可以调用具体目标类的attach()方法将自己添加到目标类的集合中或通过detach()方法将自己从目标类的集合中删除。
观察者模式描述了如何建立对象与对象之间的依赖关系,以及如何构造满足这种需求的系统。观察者模式包含观察目标和观察者两类对象,一个目标可以有任意数目的与之相依赖的观察者,一旦观察目标的状态发生改变,所有的观察者都将得到通知。作为对这个通知的响应,每个观察者都将监视观察目标的状态以使其状态与目标状态同步,这种交互也称为发布-订阅(Publish-Subscribe)。观察目标是通知的发布者,它发出通知时并不需要知道谁是它的观察者,可以有任意数目的观察者订阅它并接收通知。
下面通过示意代码来对该模式进行进一步分析。首先我们定义一个抽象目标Subject,典型代码如下所示:
import java.util.*;
abstract class Subject {
//定义一个观察者集合用于存储所有观察者对象
protected ArrayList observers<Observer> = new ArrayList();
//注册方法,用于向观察者集合中增加一个观察者
public void attach(Observer observer) {
observers.add(observer);
}
//注销方法,用于在观察者集合中删除一个观察者
public void detach(Observer observer) {
observers.remove(observer);
}
//声明抽象通知方法
public abstract void notify();
}
具体目标类ConcreteSubject是实现了抽象目标类Subject的一个具体子类,其典型代码如下所示:
class ConcreteSubject extends Subject {
//实现通知方法
public void notify() {
//遍历观察者集合,调用每一个观察者的响应方法
for(Object obs:observers) {
((Observer)obs).update();
}
}
}
抽象观察者角色一般定义为一个接口,通常只声明一个update()方法,为不同观察者的更新(响应)行为定义相同的接口,这个方法在其子类中实现,不同的观察者具有不同的响应方法。抽象观察者Observer典型代码如下所示:
interface Observer {
//声明响应方法
public void update();
}
在具体观察者ConcreteObserver中实现了update()方法,其典型代码如下所示:
class ConcreteObserver implements Observer {
//实现响应方法
public void update() {
//具体响应代码
}
}
在有些更加复杂的情况下,具体观察者类ConcreteObserver的update()方法在执行时需要使用到具体目标类ConcreteSubject中的状态(属性),因此在ConcreteObserver与ConcreteSubject之间有时候还存在关联或依赖关系,在ConcreteObserver中定义一个ConcreteSubject实例,通过该实例获取存储在ConcreteSubject中的状态。如果ConcreteObserver的update()方法不需要使用到ConcreteSubject中的状态属性,则可以对观察者模式的标准结构进行简化,在具体观察者ConcreteObserver和具体目标ConcreteSubject之间无须维持对象引用。如果在具体层具有关联关系,系统的扩展性将受到一定的影响,增加新的具体目标类有时候需要修改原有观察者的代码,在一定程度上违反了“开闭原则”,但是如果原有观察者类无须关联新增的具体目标,则系统扩展性不受影响。
示例:
JAVA:https://blog.csdn.net/lovelion/article/details/7720490
C++:https://www.cnblogs.com/jiese/p/3183635.html
3)总结
观察者模式是一种使用频率非常高的设计模式,无论是移动应用、Web应用或者桌面应用,观察者模式几乎无处不在,它为实现对象之间的联动提供了一套完整的解决方案,凡是涉及到一对一或者一对多的对象交互场景都可以使用观察者模式。观察者模式广泛应用于各种编程语言的GUI事件处理的实现,在基于事件的XML解析技术(如SAX2)以及Web事件处理中也都使用了观察者模式。
1.主要优点
- 观察者模式可以实现表示层和数据逻辑层的分离,定义了稳定的消息更新传递机制,并抽象了更新接口,使得可以有各种各样不同的表示层充当具体观察者角色。
- 观察者模式在观察目标和观察者之间建立一个抽象的耦合。观察目标只需要维持一个抽象观察者的集合,无须了解其具体观察者。由于观察目标和观察者没有紧密地耦合在一起,因此它们可以属于不同的抽象化层次。
- 观察者模式支持广播通信,观察目标会向所有已注册的观察者对象发送通知,简化了一对多系统设计的难度。
- 观察者模式满足“开闭原则”的要求,增加新的具体观察者无须修改原有系统代码,在具体观察者与观察目标之间不存在关联关系的情况下,增加新的观察目标也很方便。
2.主要缺点
- 如果一个观察目标对象有很多直接和间接观察者,将所有的观察者都通知到会花费很多时间。
- 如果在观察者和观察目标之间存在循环依赖,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。
- 观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
3.适用场景
- 一个抽象模型有两个方面,其中一个方面依赖于另一个方面,将这两个方面封装在独立的对象中使它们可以各自独立地改变和复用。
- 一个对象的改变将导致一个或多个其他对象也发生改变,而并不知道具体有多少对象将发生改变,也不知道这些对象是谁。
- 需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,可以使用观察者模式创建一种链式触发机制。
8、状态模式-State Pattern——处理对象的多种状态及其相互转换
1)概述
状态模式用于解决系统中复杂对象的状态转换以及不同状态下行为的封装问题。当系统中某个对象存在多个状态,这些状态之间可以进行转换,而且对象在不同状态下行为不相同时可以使用状态模式。状态模式将一个对象的状态从该对象中分离出来,封装到专门的状态类中,使得对象状态可以灵活变化,对于客户端而言,无须关心对象状态的转换以及对象所处的当前状态,无论对于何种状态的对象,客户端都可以一致处理。
状态模式定义如下:
状态模式(State Pattern):允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类。其别名为状态对象(Objects for States),状态模式是一种对象行为型模式。
2)结构与实现
在状态模式中引入了抽象状态类和具体状态类,它们是状态模式的核心,其结构如图所示:
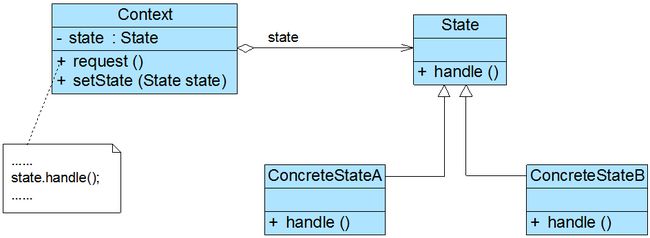
在状态模式结构图中包含如下几个角色:
- Context(环境类):环境类又称为上下文类,它是拥有多种状态的对象。由于环境类的状态存在多样性且在不同状态下对象的行为有所不同,因此将状态独立出去形成单独的状态类。在环境类中维护一个抽象状态类State的实例,这个实例定义当前状态,在具体实现时,它是一个State子类的对象。
- State(抽象状态类):它用于定义一个接口以封装与环境类的一个特定状态相关的行为,在抽象状态类中声明了各种不同状态对应的方法,而在其子类中实现类这些方法,由于不同状态下对象的行为可能不同,因此在不同子类中方法的实现可能存在不同,相同的方法可以写在抽象状态类中。
- ConcreteState(具体状态类):它是抽象状态类的子类,每一个子类实现一个与环境类的一个状态相关的行为,每一个具体状态类对应环境的一个具体状态,不同的具体状态类其行为有所不同。
在状态模式中,我们将对象在不同状态下的行为封装到不同的状态类中,为了让系统具有更好的灵活性和可扩展性,同时对各状态下的共有行为进行封装,我们需要对状态进行抽象,引入了抽象状态类角色,其典型代码如下所示:
abstract class State {
//声明抽象业务方法,不同的具体状态类可以不同的实现
public abstract void handle();
}
在抽象状态类的子类即具体状态类中实现了在抽象状态类中声明的业务方法,不同的具体状态类可以提供完全不同的方法实现,在实际使用时,在一个状态类中可能包含多个业务方法,如果在具体状态类中某些业务方法的实现完全相同,可以将这些方法移至抽象状态类,实现代码的复用,典型的具体状态类代码如下所示:
class ConcreteState extends State {
public void handle() {
//方法具体实现代码
}
}
环境类维持一个对抽象状态类的引用,通过setState()方法可以向环境类注入不同的状态对象,再在环境类的业务方法中调用状态对象的方法,典型代码如下所示:
class Context {
private State state; //维持一个对抽象状态对象的引用
private int value; //其他属性值,该属性值的变化可能会导致对象状态发生变化
//设置状态对象
public void setState(State state) {
this.state = state;
}
public void request() {
//其他代码
state.handle(); //调用状态对象的业务方法
//其他代码
}
}
环境类实际上是真正拥有状态的对象,我们只是将环境类中与状态有关的代码提取出来封装到专门的状态类中。在状态模式结构图中,环境类Context与抽象状态类State之间存在单向关联关系,在Context中定义了一个State对象。在实际使用时,它们之间可能存在更为复杂的关系,State与Context之间可能也存在依赖或者关联关系。
在状态模式的使用过程中,一个对象的状态之间还可以进行相互转换,通常有两种实现状态转换的方式:
-
统一由环境类来负责状态之间的转换,此时,环境类还充当了状态管理器(State Manager)角色,在环境类的业务方法中通过对某些属性值的判断实现状态转换,还可以提供一个专门的方法用于实现属性判断和状态转换,如下代码片段所示:
…… public void changeState() { //判断属性值,根据属性值进行状态转换 if (value == 0) { this.setState(new ConcreteStateA()); } else if (value == 1) { this.setState(new ConcreteStateB()); } ...... } …… -
由具体状态类来负责状态之间的转换,可以在具体状态类的业务方法中判断环境类的某些属性值再根据情况为环境类设置新的状态对象,实现状态转换,同样,也可以提供一个专门的方法来负责属性值的判断和状态转换。此时,状态类与环境类之间就将存在依赖或关联关系,因为状态类需要访问环境类中的属性值,如下代码片段所示:
…… public void changeState(Context ctx) { //根据环境对象中的属性值进行状态转换 if (ctx.getValue() == 1) { ctx.setState(new ConcreteStateB()); } else if (ctx.getValue() == 2) { ctx.setState(new ConcreteStateC()); } ...... } ……
示例:
JAVA:https://blog.csdn.net/lovelion/article/details/8523083
3)共享状态
在有些情况下,多个环境对象可能需要共享同一个状态,如果希望在系统中实现多个环境对象共享一个或多个状态对象,那么需要将这些状态对象定义为环境类的静态成员对象。
下面通过一个简单实例来说明如何实现共享状态:
如果某系统要求两个开关对象要么都处于开的状态,要么都处于关的状态,在使用时它们的状态必须保持一致,开关可以由开转换到关,也可以由关转换到开。
可以使用状态模式来实现开关的设计,其结构如图所示:
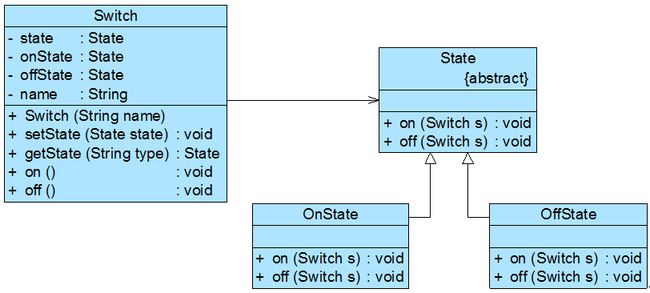
开关类Switch代码如下所示:
class Switch {
private static State state,onState,offState; //定义三个静态的状态对象
private String name;
public Switch(String name) {
this.name = name;
onState = new OnState();
offState = new OffState();
this.state = onState;
}
public void setState(State state) {
this.state = state;
}
public static State getState(String type) {
if (type.equalsIgnoreCase("on")) {
return onState;
}
else {
return offState;
}
}
//打开开关
public void on() {
System.out.print(name);
state.on(this);
}
//关闭开关
public void off() {
System.out.print(name);
state.off(this);
}
}
抽象状态类如下代码所示:
abstract class State {
public abstract void on(Switch s);
public abstract void off(Switch s);
}
两个具体状态类如下代码所示:
//打开状态
class OnState extends State {
public void on(Switch s) {
System.out.println("已经打开!");
}
public void off(Switch s) {
System.out.println("关闭!");
s.setState(Switch.getState("off"));
}
}
//关闭状态
class OffState extends State {
public void on(Switch s) {
System.out.println("打开!");
s.setState(Switch.getState("on"));
}
public void off(Switch s) {
System.out.println("已经关闭!");
}
}
编写如下客户端代码进行测试:
class Client {
public static void main(String args[]) {
Switch s1,s2;
s1=new Switch("开关1");
s2=new Switch("开关2");
s1.on();
s2.on();
s1.off();
s2.off();
s2.on();
s1.on();
}
}
输出结果如下:

从输出结果可以得知两个开关共享相同的状态,如果第一个开关关闭,则第二个开关也将关闭,再次关闭时将输出“已经关闭”;打开时也将得到类似结果。
4)总结
状态模式将一个对象在不同状态下的不同行为封装在一个个状态类中,通过设置不同的状态对象可以让环境对象拥有不同的行为,而状态转换的细节对于客户端而言是透明的,方便了客户端的使用。在实际开发中,状态模式具有较高的使用频率,在工作流和游戏开发中状态模式都得到了广泛的应用,例如公文状态的转换、游戏中角色的升级等。
1. 主要优点
状态模式的主要优点如下:
- 封装了状态的转换规则,在状态模式中可以将状态的转换代码封装在环境类或者具体状态类中,可以对状态转换代码进行集中管理,而不是分散在一个个业务方法中。
- 将所有与某个状态有关的行为放到一个类中,只需要注入一个不同的状态对象即可使环境对象拥有不同的行为。
- 允许状态转换逻辑与状态对象合成一体,而不是提供一个巨大的条件语句块,状态模式可以让我们避免使用庞大的条件语句来将业务方法和状态转换代码交织在一起。
- 可以让多个环境对象共享一个状态对象,从而减少系统中对象的个数。
2. 主要缺点
状态模式的主要缺点如下:
- 状态模式的使用必然会增加系统中类和对象的个数,导致系统运行开销增大。
- 状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱,增加系统设计的难度。
- 状态模式对“开闭原则”的支持并不太好,增加新的状态类需要修改那些负责状态转换的源代码,否则无法转换到新增状态;而且修改某个状态类的行为也需修改对应类的源代码。
3. 适用场景
在以下情况下可以考虑使用状态模式:
- 对象的行为依赖于它的状态(如某些属性值),状态的改变将导致行为的变化。
- 在代码中包含大量与对象状态有关的条件语句,这些条件语句的出现,会导致代码的可维护性和灵活性变差,不能方便地增加和删除状态,并且导致客户类与类库之间的耦合增强。
9、策略模式-Strategy Pattern——算法的封装与切换
1)概述
在策略模式中,我们可以定义一些独立的类来封装不同的算法,每一个类封装一种具体的算法,在这里,每一个封装算法的类我们都可以称之为一种策略(Strategy),为了保证这些策略在使用时具有一致性,一般会提供一个抽象的策略类来做规则的定义,而每种算法则对应于一个具体策略类。
策略模式的主要目的是将算法的定义与使用分开,也就是将算法的行为和环境分开,将算法的定义放在专门的策略类中,每一个策略类封装了一种实现算法,使用算法的环境类针对抽象策略类进行编程,符合“依赖倒转原则”。在出现新的算法时,只需要增加一个新的实现了抽象策略类的具体策略类即可。策略模式定义如下:
策略模式(Strategy Pattern):定义一系列算法类,将每一个算法封装起来,并让它们可以相互替换,策略模式让算法独立于使用它的客户而变化,也称为政策模式(Policy)。策略模式是一种对象行为型模式。
2)结构与实现
策略模式结构并不复杂,但我们需要理解其中环境类Context的作用,其结构如图所示:
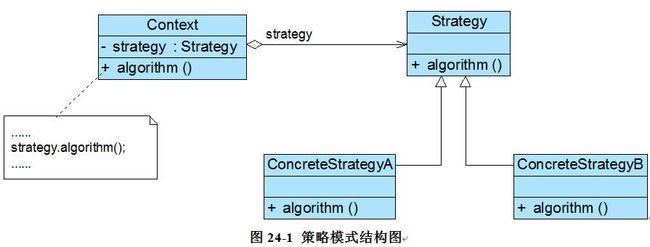
在策略模式结构图中包含如下几个角色:
- Context(环境类):环境类是使用算法的角色,它在解决某个问题(即实现某个方法)时可以采用多种策略。在环境类中维持一个对抽象策略类的引用实例,用于定义所采用的策略。
- Strategy(抽象策略类):它为所支持的算法声明了抽象方法,是所有策略类的父类,它可以是抽象类或具体类,也可以是接口。环境类通过抽象策略类中声明的方法在运行时调用具体策略类中实现的算法。
- ConcreteStrategy(具体策略类):它实现了在抽象策略类中声明的算法,在运行时,具体策略类将覆盖在环境类中定义的抽象策略类对象,使用一种具体的算法实现某个业务处理。
策略模式是一个比较容易理解和使用的设计模式,策略模式是对算法的封装,它把算法的责任和算法本身分割开,委派给不同的对象管理。策略模式通常把一个系列的算法封装到一系列具体策略类里面,作为抽象策略类的子类。在策略模式中,对环境类和抽象策略类的理解非常重要,环境类是需要使用算法的类。在一个系统中可以存在多个环境类,它们可能需要重用一些相同的算法。
在使用策略模式时,我们需要将算法从Context类中提取出来,首先应该创建一个抽象策略类,其典型代码如下所示:
abstract class AbstractStrategy {
public abstract void algorithm(); //声明抽象算法
}
然后再将封装每一种具体算法的类作为该抽象策略类的子类,如下代码所示:
class ConcreteStrategyA extends AbstractStrategy {
//算法的具体实现
public void algorithm() {
//算法A
}
}
其他具体策略类与之类似,对于Context类而言,在它与抽象策略类之间建立一个关联关系,其典型代码如下所示:
class Context {
private AbstractStrategy strategy; //维持一个对抽象策略类的引用
public void setStrategy(AbstractStrategy strategy) {
this.strategy= strategy;
}
//调用策略类中的算法
public void algorithm() {
strategy.algorithm();
}
}
在Context类中定义一个AbstractStrategy类型的对象strategy,通过注入的方式在客户端传入一个具体策略对象,客户端代码片段如下所示:
……
Context context = new Context();
AbstractStrategy strategy;
strategy = new ConcreteStrategyA(); //可在运行时指定类型
context.setStrategy(strategy);
context.algorithm();
……
在客户端代码中只需注入一个具体策略对象,可以将具体策略类类名存储在配置文件中,通过反射来动态创建具体策略对象,从而使得用户可以灵活地更换具体策略类,增加新的具体策略类也很方便。策略模式提供了一种可插入式(Pluggable)算法的实现方案。
示例:
JAVA:https://blog.csdn.net/lovelion/article/details/7819216
C++:https://www.cnblogs.com/jiese/p/3181099.html
3)总结
策略模式用于算法的自由切换和扩展,它是应用较为广泛的设计模式之一。策略模式对应于解决某一问题的一个算法族,允许用户从该算法族中任选一个算法来解决某一问题,同时可以方便地更换算法或者增加新的算法。只要涉及到算法的封装、复用和切换都可以考虑使用策略模式。
1. 主要优点
策略模式的主要优点如下:
- 策略模式提供了对“开闭原则”的完美支持,用户可以在不修改原有系统的基础上选择算法或行为,也可以灵活地增加新的算法或行为。
- 策略模式提供了管理相关的算法族的办法。策略类的等级结构定义了一个算法或行为族,恰当使用继承可以把公共的代码移到抽象策略类中,从而避免重复的代码。
- 策略模式提供了一种可以替换继承关系的办法。如果不使用策略模式,那么使用算法的环境类就可能会有一些子类,每一个子类提供一种不同的算法。但是,这样一来算法的使用就和算法本身混在一起,不符合“单一职责原则”,决定使用哪一种算法的逻辑和该算法本身混合在一起,从而不可能再独立演化;而且使用继承无法实现算法或行为在程序运行时的动态切换。
- 使用策略模式可以避免多重条件选择语句。多重条件选择语句不易维护,它把采取哪一种算法或行为的逻辑与算法或行为本身的实现逻辑混合在一起,将它们全部硬编码(Hard Coding)在一个庞大的多重条件选择语句中,比直接继承环境类的办法还要原始和落后。
- 策略模式提供了一种算法的复用机制,由于将算法单独提取出来封装在策略类中,因此不同的环境类可以方便地复用这些策略类。
2. 主要缺点
策略模式的主要缺点如下:
- 客户端必须知道所有的策略类,并自行决定使用哪一个策略类。这就意味着客户端必须理解这些算法的区别,以便适时选择恰当的算法。换言之,策略模式只适用于客户端知道所有的算法或行为的情况。
- 策略模式将造成系统产生很多具体策略类,任何细小的变化都将导致系统要增加一个新的具体策略类。
- 无法同时在客户端使用多个策略类,也就是说,在使用策略模式时,客户端每次只能使用一个策略类,不支持使用一个策略类完成部分功能后再使用另一个策略类来完成剩余功能的情况。
3. 适用场景
在以下情况下可以考虑使用策略模式:
- 一个系统需要动态地在几种算法中选择一种,那么可以将这些算法封装到一个个的具体算法类中,而这些具体算法类都是一个抽象算法类的子类。换言之,这些具体算法类均有统一的接口,根据“里氏代换原则”和面向对象的多态性,客户端可以选择使用任何一个具体算法类,并只需要维持一个数据类型是抽象算法类的对象。
- 一个对象有很多的行为,如果不用恰当的模式,这些行为就只好使用多重条件选择语句来实现。此时,使用策略模式,把这些行为转移到相应的具体策略类里面,就可以避免使用难以维护的多重条件选择语句。
- 不希望客户端知道复杂的、与算法相关的数据结构,在具体策略类中封装算法与相关的数据结构,可以提高算法的保密性与安全性。
10、模板方法模式-Template Method Pattern——基于继承的代码复用
1)概述
在软件开发中,有时也会遇到:某个方法的实现需要多个步骤,其中有些步骤是固定的,而有些步骤并不固定,存在可变性。为了提高代码的复用性和系统的灵活性,可以使用一种称之为模板方法模式的设计模式来对这类情况进行设计,在模板方法模式中,将实现功能的每一个步骤所对应的方法称为基本方法,而调用这些基本方法同时定义基本方法的执行次序的方法称为模板方法。在模板方法模式中,可以将相同的代码放在父类中;而对于基本方法,在父类中只做一个声明,将其不同的具体实现放在不同的子类中。
模板方法模式定义如下:
模板方法模式:定义一个操作中算法的框架,而将一些步骤延迟到子类中。模板方法模式使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。 Template Method Pattern: Define the skeleton of an algorithm in an operation, deferring some steps to subclasses. Template Method lets subclasses redefine certain steps of an algorithm without changing the algorithm’s structure.
模板方法模式是一种基于继承的代码复用技术,它是一种类行为型模式。
模板方法模式是结构最简单的行为型设计模式,在其结构中只存在父类与子类之间的继承关系。通过使用模板方法模式,可以将一些复杂流程的实现步骤封装在一系列基本方法中,在抽象父类中提供一个称之为模板方法的方法来定义这些基本方法的执行次序,而通过其子类来覆盖某些步骤,从而使得相同的算法框架可以有不同的执行结果。模板方法模式提供了一个模板方法来定义算法框架,而某些具体步骤的实现可以在其子类中完成。
2)结构与实现
模板方法模式结构比较简单,其核心是抽象类和其中的模板方法的设计,其结构如图所示:
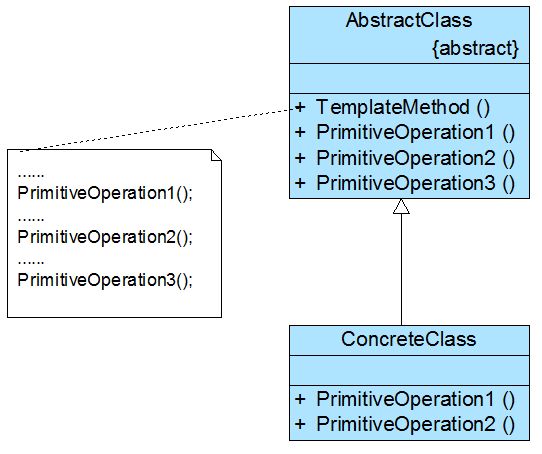
模板方法模式包含如下两个角色:
- AbstractClass(抽象类):在抽象类中定义了一系列基本操作(PrimitiveOperations),这些基本操作可以是具体的,也可以是抽象的,每一个基本操作对应算法的一个步骤,在其子类中可以重定义或实现这些步骤。同时,在抽象类中实现了一个模板方法(Template Method),用于定义一个算法的框架,模板方法不仅可以调用在抽象类中实现的基本方法,也可以调用在抽象类的子类中实现的基本方法,还可以调用其他对象中的方法。
- ConcreteClass(具体子类):它是抽象类的子类,用于实现在父类中声明的抽象基本操作以完成子类特定算法的步骤,也可以覆盖在父类中已经实现的具体基本操作。
在实现模板方法模式时,开发抽象类的软件设计师和开发具体子类的软件设计师之间可以进行协作。一个设计师负责给出一个算法的轮廓和框架,另一些设计师则负责给出这个算法的各个逻辑步骤。实现这些具体逻辑步骤的方法即为基本方法,而将这些基本方法汇总起来的方法即为模板方法,模板方法模式的名字也因此而来。下面将详细介绍模板方法和基本方法:
1. 模板方法
一个模板方法是定义在抽象类中的、把基本操作方法组合在一起形成一个总算法或一个总行为的方法。这个模板方法定义在抽象类中,并由子类不加以修改地完全继承下来。模板方法是一个具体方法,它给出了一个顶层逻辑框架,而逻辑的组成步骤在抽象类中可以是具体方法,也可以是抽象方法。由于模板方法是具体方法,因此模板方法模式中的抽象层只能是抽象类,而不是接口。
2. 基本方法
基本方法是实现算法各个步骤的方法,是模板方法的组成部分。基本方法又可以分为三种:抽象方法(Abstract Method)、具体方法(Concrete Method)和钩子方法(Hook Method)。
- 抽象方法:一个抽象方法由抽象类声明、由其具体子类实现。在C#语言里一个抽象方法以abstract关键字标识。
- 具体方法:一个具体方法由一个抽象类或具体类声明并实现,其子类可以进行覆盖也可以直接继承。
- 钩子方法:一个钩子方法由一个抽象类或具体类声明并实现,而其子类可能会加以扩展。通常在父类中给出的实现是一个空实现(可使用virtual关键字将其定义为虚函数),并以该空实现作为方法的默认实现,当然钩子方法也可以提供一个非空的默认实现。
在模板方法模式中,钩子方法有两类:第一类钩子方法可以与一些具体步骤“挂钩”,以实现在不同条件下执行模板方法中的不同步骤,这类钩子方法的返回类型通常是bool类型的,这类方法名一般为IsXXX(),用于对某个条件进行判断,如果条件满足则执行某一步骤,否则将不执行,如下C#代码片段所示:
……
//模板方法
public void TemplateMethod()
{
Open();
Display();
//通过钩子方法来确定某步骤是否执行
if (IsPrint())
{
Print();
}
}
//钩子方法
public bool IsPrint()
{
return true;
}
……
在代码中IsPrint()方法即是钩子方法,它可以决定Print()方法是否执行,一般情况下,钩子方法的返回值为true,如果不希望某方法执行,可以在其子类中覆盖钩子方法,将其返回值改为false即可,这种类型的钩子方法可以控制方法的执行,对一个算法进行约束。
还有一类钩子方法就是实现体为空的具体方法,子类可以根据需要覆盖或者继承这些钩子方法,与抽象方法相比,这类钩子方法的好处在于子类如果没有覆盖父类中定义的钩子方法,编译可以正常通过,但是如果没有覆盖父类中声明的抽象方法,编译将报错。
在模板方法模式中,抽象类的典型代码如下:
abstract class AbstractClass
{
//模板方法
public void TemplateMethod()
{
PrimitiveOperation1();
PrimitiveOperation2();
PrimitiveOperation3();
}
//基本方法—具体方法
public void PrimitiveOperation1()
{
//实现代码
}
//基本方法—抽象方法
public abstract void PrimitiveOperation2();
//基本方法—钩子方法
public virtual void PrimitiveOperation3()
{
}
}
在抽象类中,模板方法TemplateMethod()定义了算法的框架,在模板方法中调用基本方法以实现完整的算法,每一个基本方法如PrimitiveOperation1()、PrimitiveOperation2()等均实现了算法的一部分,对于所有子类都相同的基本方法可在父类提供具体实现,例如PrimitiveOperation1(),否则在父类声明为抽象方法或钩子方法,由不同的子类提供不同的实现,例如PrimitiveOperation2()和PrimitiveOperation3()。
可在抽象类的子类中提供抽象步骤的实现,也可覆盖父类中已经实现的具体方法,具体子类的典型代码如下:
class ConcreteClass : AbstractClass
{
public override void PrimitiveOperation2()
{
//实现代码
}
public override void PrimitiveOperation3()
{
//实现代码
}
}
在模板方法模式中,由于面向对象的多态性,子类对象在运行时将覆盖父类对象,子类中定义的方法也将覆盖父类中定义的方法,因此程序在运行时,具体子类的基本方法将覆盖父类中定义的基本方法,子类的钩子方法也将覆盖父类的钩子方法,从而可以通过在子类中实现的钩子方法对父类方法的执行进行约束,实现子类对父类行为的反向控制。
示例:
C#:https://blog.csdn.net/lovelion/article/details/8299863
C++:https://www.cnblogs.com/jiese/p/3180477.html
3)钩子方法的使用
模板方法模式中,在父类中提供了一个定义算法框架的模板方法,还提供了一系列抽象方法、具体方法和钩子方法,其中钩子方法的引入使得子类可以控制父类的行为。最简单的钩子方法就是空方法。当然也可以在钩子方法中定义一个默认的实现,如果子类不覆盖钩子方法,则执行父类的默认实现代码。
另一种钩子方法可以实现对其他方法进行约束,这种钩子方法通常返回一个bool类型,即返回true或false,用来判断是否执行某一个基本方法,子类通过覆盖该方法来控制父类的行为。
示例:https://blog.csdn.net/lovelion/article/details/8299927
4)总结
模板方法模式是基于继承的代码复用技术,它体现了面向对象的诸多重要思想,是一种使用较为频繁的模式。模板方法模式广泛应用于框架设计中,以确保通过父类来控制处理流程的逻辑顺序(如框架的初始化,测试流程的设置等)。
1. 主要优点
模板方法模式的主要优点如下:
- 在父类中形式化地定义一个算法,而由它的子类来实现细节的处理,在子类实现详细的处理算法时并不会改变算法中步骤的执行次序。
- 模板方法模式是一种代码复用技术,它在类库设计中尤为重要,它提取了类库中的公共行为,将公共行为放在父类中,而通过其子类来实现不同的行为,它鼓励我们恰当使用继承来实现代码复用。
- 可实现一种反向控制结构,通过子类覆盖父类的钩子方法来决定某一特定步骤是否需要执行。
- 在模板方法模式中可以通过子类来覆盖父类的基本方法,不同的子类可以提供基本方法的不同实现,更换和增加新的子类很方便,符合单一职责原则和开闭原则。
2. 主要缺点
需要为每一个基本方法的不同实现提供一个子类,如果父类中可变的基本方法太多,将会导致类的个数增加,系统更加庞大,设计也更加抽象,此时,可结合桥接模式来进行设计。
3. 适用场景
在以下情况下可以考虑使用模板方法模式:
- 对一些复杂的算法进行分割,将其算法中固定不变的部分设计为模板方法和父类具体方法,而一些可以改变的细节由其子类来实现。即:一次性实现一个算法的不变部分,并将可变的行为留给子类来实现。
- 各子类中公共的行为应被提取出来并集中到一个公共父类中以避免代码重复。
- 需要通过子类来决定父类算法中某个步骤是否执行,实现子类对父类的反向控制。
11、访问者模式-Visitor Pattern——操作复杂对象结构
就医时,在医生开具处方单(药单)后,很多医院都存在如下处理流程:划价人员拿到处方单之后根据药品名称和数量计算总价并收费,药房工作人员根据药品名称和数量准备药品。
我们可以将处方单看成一个药品信息的集合,里面包含了一种或多种不同类型的药品信息,不同类型的工作人员(如划价人员和药房工作人员)在操作同一个药品信息集合时将提供不同的处理方式,而且可能还会增加新类型的工作人员来操作处方单。
在软件开发中,有时候我们也需要处理像处方单这样的集合对象结构,在该对象结构中存储了多个不同类型的对象信息,而且对同一对象结构中的元素的操作方式并不唯一,可能需要提供多种不同的处理方式,还有可能增加新的处理方式。在设计模式中,访问者模式可以满足上述要求,其模式动机就是以不同的方式操作复杂对象结构。
1)概述
访问者模式是一种较为复杂的行为型设计模式,它包含访问者和被访问元素两个主要组成部分,这些被访问的元素通常具有不同的类型,且不同的访问者可以对它们进行不同的访问操作。例如处方单中的各种药品信息就是被访问的元素,而划价人员和药房工作人员就是访问者。访问者模式使得用户可以在不修改现有系统的情况下扩展系统的功能,为这些不同类型的元素增加新的操作。
在使用访问者模式时,被访问元素通常不是单独存在的,它们存储在一个集合中,这个集合被称为“对象结构”,访问者通过遍历对象结构实现对其中存储的元素的逐个操作。
访问者模式定义如下:
访问者模式(Visitor Pattern):提供一个作用于某对象结构中的各元素的操作表示,它使我们可以在不改变各元素的类的前提下定义作用于这些元素的新操作。访问者模式是一种对象行为型模式。
2)结构与实现
访问者模式的结构较为复杂,其结构如图所示:
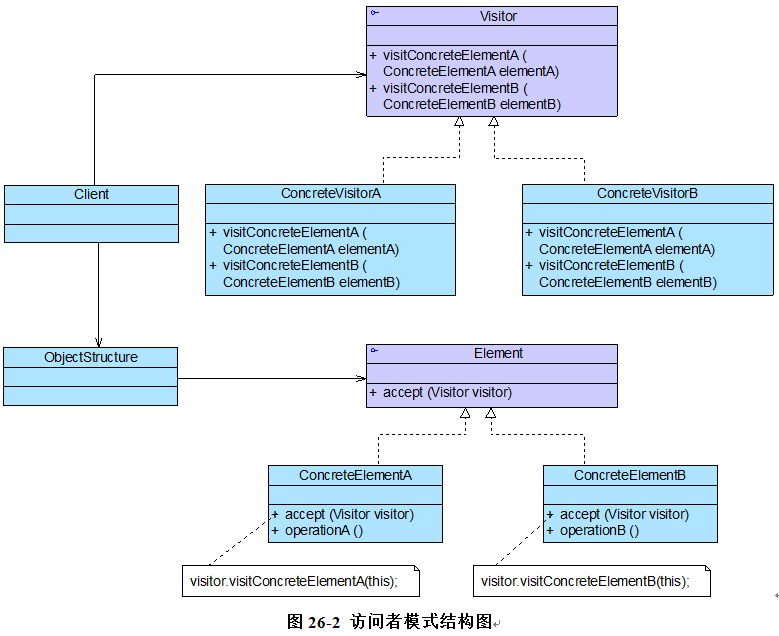
在访问者模式结构图中包含如下几个角色:
- Vistor(抽象访问者):抽象访问者为对象结构中每一个具体元素类ConcreteElement声明一个访问操作,从这个操作的名称或参数类型可以清楚知道需要访问的具体元素的类型,具体访问者需要实现这些操作方法,定义对这些元素的访问操作。
- ConcreteVisitor(具体访问者):具体访问者实现了每个由抽象访问者声明的操作,每一个操作用于访问对象结构中一种类型的元素。
- Element(抽象元素):抽象元素一般是抽象类或者接口,它定义一个accept()方法,该方法通常以一个抽象访问者作为参数。
- ConcreteElement(具体元素):具体元素实现了accept()方法,在accept()方法中调用访问者的访问方法以便完成对一个元素的操作。
- ObjectStructure(对象结构):对象结构是一个元素的集合,它用于存放元素对象,并且提供了遍历其内部元素的方法。它可以结合组合模式来实现,也可以是一个简单的集合对象,如一个List对象或一个Set对象。
访问者模式中对象结构存储了不同类型的元素对象,以供不同访问者访问。访问者模式包括两个层次结构,一个是访问者层次结构,提供了抽象访问者和具体访问者,一个是元素层次结构,提供了抽象元素和具体元素。相同的访问者可以以不同的方式访问不同的元素,相同的元素可以接受不同访问者以不同访问方式访问。在访问者模式中,增加新的访问者无须修改原有系统,系统具有较好的可扩展性。
在访问者模式中,抽象访问者定义了访问元素对象的方法,通常为每一种类型的元素对象都提供一个访问方法,而具体访问者可以实现这些访问方法。这些访问方法的命名一般有两种方式:一种是直接在方法名中标明待访问元素对象的具体类型,如visitElementA(ElementA elementA),还有一种是统一取名为visit(),通过参数类型的不同来定义一系列重载的visit()方法。当然,如果所有的访问者对某一类型的元素的访问操作都相同,则可以将操作代码移到抽象访问者类中,其典型代码如下所示:
abstract class Visitor
{
public abstract void visit(ConcreteElementA elementA);
public abstract void visit(ConcreteElementB elementB);
public void visit(ConcreteElementC elementC)
{
//元素ConcreteElementC操作代码
}
}
在这里使用了重载visit()方法的方式来定义多个方法用于操作不同类型的元素对象。在抽象访问者Visitor类的子类ConcreteVisitor中实现了抽象的访问方法,用于定义对不同类型元素对象的操作,具体访问者类典型代码如下所示:
class ConcreteVisitor extends Visitor
{
public void visit(ConcreteElementA elementA)
{
//元素ConcreteElementA操作代码
}
public void visit(ConcreteElementB elementB)
{
//元素ConcreteElementB操作代码
}
}
对于元素类而言,在其中一般都定义了一个accept()方法,用于接受访问者的访问,典型的抽象元素类代码如下所示:
interface Element
{
public void accept(Visitor visitor);
}
需要注意的是该方法传入了一个抽象访问者Visitor类型的参数,即针对抽象访问者进行编程,而不是具体访问者,在程序运行时再确定具体访问者的类型,并调用具体访问者对象的visit()方法实现对元素对象的操作。在抽象元素类Element的子类中实现了accept()方法,用于接受访问者的访问,在具体元素类中还可以定义不同类型的元素所特有的业务方法,其典型代码如下所示:
class ConcreteElementA implements Element
{
public void accept(Visitor visitor)
{
visitor.visit(this);
}
public void operationA()
{
//业务方法
}
}
在具体元素类ConcreteElementA的accept()方法中,通过调用Visitor类的visit()方法实现对元素的访问,并以当前对象作为visit()方法的参数。其具体执行过程如下:
- 调用具体元素类的accept(Visitor visitor)方法,并将Visitor子类对象作为其参数;
- 在具体元素类accept(Visitor visitor)方法内部调用传入的Visitor对象的visit()方法,如visit(ConcreteElementA elementA),将当前具体元素类对象(this)作为参数,如visitor.visit(this);
- 执行Visitor对象的visit()方法,在其中还可以调用具体元素对象的业务方法。
这种调用机制也称为“双重分派”,正因为使用了双重分派机制,使得增加新的访问者无须修改现有类库代码,只需将新的访问者对象作为参数传入具体元素对象的accept()方法,程序运行时将回调在新增Visitor类中定义的visit()方法,从而增加新的元素访问方式。
在访问者模式中,对象结构是一个集合,它用于存储元素对象并接受访问者的访问,其典型代码如下所示:
class ObjectStructure
{
private ArrayList<Element> list = new ArrayList<Element>(); //定义一个集合用于存储元素对象
public void accept(Visitor visitor)
{
Iterator i=list.iterator();
while(i.hasNext())
{
((Element)i.next()).accept(visitor); //遍历访问集合中的每一个元素
}
}
public void addElement(Element element)
{
list.add(element);
}
public void removeElement(Element element)
{
list.remove(element);
}
}
在对象结构中可以使用迭代器对存储在集合中的元素对象进行遍历,并逐个调用每一个对象的accept()方法,实现对元素对象的访问操作。
示例:
https://blog.csdn.net/lovelion/article/details/7433576
3)访问者模式与组合模式联用
在访问者模式中,包含一个用于存储元素对象集合的对象结构,我们通常可以使用迭代器来遍历对象结构,同时具体元素之间可以存在整体与部分关系,有些元素作为容器对象,有些元素作为成员对象,可以使用组合模式来组织元素。引入组合模式后的访问者模式结构图如图所示:
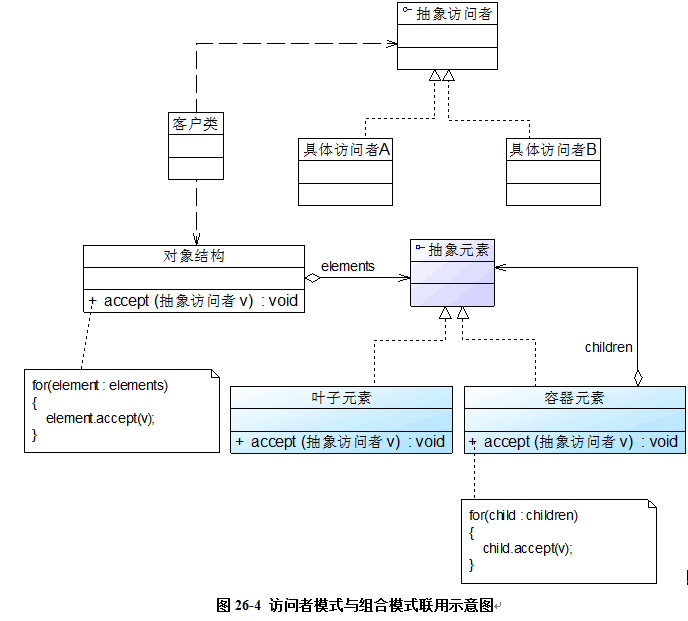
需要注意的是,在图所示结构中,由于叶子元素的遍历操作已经在容器元素中完成,因此要防止单独将已增加到容器元素中的叶子元素再次加入对象结构中,对象结构中只保存容器元素和孤立的叶子元素。
4)总结
由于访问者模式的使用条件较为苛刻,本身结构也较为复杂,因此在实际应用中使用频率不是特别高。当系统中存在一个较为复杂的对象结构,且不同访问者对其所采取的操作也不相同时,可以考虑使用访问者模式进行设计。在XML文档解析、编译器的设计、复杂集合对象的处理等领域访问者模式得到了一定的应用。
1.主要优点
访问者模式的主要优点如下:
- 增加新的访问操作很方便。使用访问者模式,增加新的访问操作就意味着增加一个新的具体访问者类,实现简单,无须修改源代码,符合“开闭原则”。
- 将有关元素对象的访问行为集中到一个访问者对象中,而不是分散在一个个的元素类中。类的职责更加清晰,有利于对象结构中元素对象的复用,相同的对象结构可以供多个不同的访问者访问。
- 让用户能够在不修改现有元素类层次结构的情况下,定义作用于该层次结构的操作。
2.主要缺点
访问者模式的主要缺点如下:
- 增加新的元素类很困难。在访问者模式中,每增加一个新的元素类都意味着要在抽象访问者角色中增加一个新的抽象操作,并在每一个具体访问者类中增加相应的具体操作,这违背了“开闭原则”的要求。
- 破坏封装。访问者模式要求访问者对象访问并调用每一个元素对象的操作,这意味着元素对象有时候必须暴露一些自己的内部操作和内部状态,否则无法供访问者访问。
3.适用场景
在以下情况下可以考虑使用访问者模式:
- 一个对象结构包含多个类型的对象,希望对这些对象实施一些依赖其具体类型的操作。在访问者中针对每一种具体的类型都提供了一个访问操作,不同类型的对象可以有不同的访问操作。
- 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作“污染”这些对象的类,也不希望在增加新操作时修改这些类。访问者模式使得我们可以将相关的访问操作集中起来定义在访问者类中,对象结构可以被多个不同的访问者类所使用,将对象本身与对象的访问操作分离。
- 对象结构中对象对应的类很少改变,但经常需要在此对象结构上定义新的操作。
参考:
《设计模式的艺术》
https://blog.csdn.net/LoveLion/article/details/17517213
https://www.cnblogs.com/jiese/tag/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/