springcloud 和 springalibabaCloud组件详细解析
springcloud 和 springalibabaCloud
AEROFUGIA
一、分布式架构演进(单机—> 微服务)
单机架构:
优点:便于测试,对小项目友好
缺点:开发速度慢,启动时间长,依赖庞大
分布式架构:
SOA:面向服务的架构 其中包含多个服务,服务之间通过相互依赖提供一系类功能,一个服务通常以独立的形式存在于操作系统中
微服务:将一个大的【单体项目】拆分成多个子项目和服务,每个拆分出来的服务各自独立打包部署
优点:便于理解、开发、部署
缺点:存在分布式事务、服务治理
Spring Alibaba Cloud
- 全家桶+阿里生态多个组件组合+SpringCloud支持
- 官网 https://spring.io/projects/spring-cloud-alibaba
- 服务注册发现:Nacos
- 服务限流降级:Sentinel
- 分布配置中心:Nacos
- 服务网关:SpringCloud Gateway
- 服务之间调用:Feign、Ribbon
- 链路追踪:Sleuth+Zipkin
- 网关:gateway
- 通信方式:http restful
二、聚合工程
module子模块
xdclass-common
xdclass-video-service
xdclass-user-service
xdclass-order-service
xdclass-api-gateway
4.0.0
cn.mesmile
xdclass-cloud
1.0-SNAPSHOT
xdclass-common
xdclass-video-service
xdclass-user-service
xdclass-order-service
xdclass-api-gateway
pom
1.8
1.8
1.8
org.projectlombok
lombok
1.18.8
provided
cn.hutool
hutool-all
5.4.0
org.springframework.boot
spring-boot-dependencies
2.3.3.RELEASE
pom
import
org.springframework.cloud
spring-cloud-dependencies
Hoxton.SR8
pom
import
com.alibaba.cloud
spring-cloud-alibaba-dependencies
2.2.1.RELEASE
pom
import
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.1.2
pom
import
org.springframework.boot
spring-boot-maven-plugin
true
true
子项目依赖:
org.springframework.boot
spring-boot-starter-web
cn.mesmile
xdclass-common
1.0-SNAPSHOT
org.mybatis.spring.boot
mybatis-spring-boot-starter
mysql
mysql-connector-java
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-config
org.springframework.cloud
spring-cloud-starter-openfeign
com.alibaba.cloud
spring-cloud-starter-alibaba-sentinel
org.springframework.cloud
spring-cloud-starter-sleuth
org.springframework.cloud
spring-cloud-starter-zipkin
三、服务之间调用
1.RestTemplate 的方式调用
服务之间ip写死了
服务之间服务提供负载均衡
多个服务之间调用复杂
四、注册中心
服务注册 与 服务发现
主流的注册中心:zookeeper、Eureka、consul、etcd、Nacos
这里使用nacos作为注册中心:
nacos官方文档:https://nacos.io/zh-cn/docs/quick-start.html
注意nacos在window中安装的坑:
1.需要修改配置文件中 MySQL 的设置
2.需要修改配置文件中 将 集群模式 改为 单机模式
1.第一个问题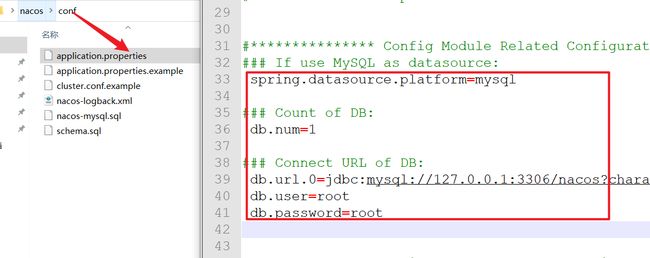
2.第二个问题

nacos注册中心使用:
nacos默认的地址:http://127.0.0.1:8848/nacos
nacos默认的账号和密码:nacos/nacos
五、通过注册中心进行服务之间调用
配置文件:
# application 的名字
spring:
application:
name: xdclass-video-service
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
在启动类加上注解:
@EnableDiscoveryClient
// 可以服务之间调用
private final DiscoveryClient discoveryClient;
// 这里的参数默认为,配置文件中的 application.name = xdclass-video-service
List<ServiceInstance> instances = discoveryClient.getInstances("xdclass-video-service");
ServiceInstance serviceInstance = instances.get(0);
String host = serviceInstance.getHost();
int port = serviceInstance.getPort();
六、负载均衡
Load Balance
常见的负载均衡策略(看组件的支持情况)
- 节点轮询
- 简介:每个请求按顺序分配到不同的后端服务器
- weight 权重配置
- 简介:weight和访问比率成正比,数字越大,分配得到的流量越高
- 固定分发
- 简介:根据请求按访问ip的hash结果分配,这样每个用户就可以固定访问一个后端服务器
- 随机选择、最短响应时间等等
restTemplate增加 **@LoadBalanced ** 注解
/**
* @LoadBalanced ribbon 负载均衡 默认是 轮训的策略
*/
@Bean
@LoadBalanced
public RestTemplate getRestTemplate () {
return new RestTemplate();
}
这样通过 restTemplate 的方式调用的话,就可以实现负载均衡 : 默认策略是【 **节点轮询 **】
1.Ribbon 负载均衡策略
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qHAwo33a-1606960678010)(C:\Users\AOSSCI\AppData\Roaming\Typora\typora-user-images\image-20201026110008372.png)]
配置文件:
# video 服务 IRule 规则; 【改变负载均衡策略】 默认为轮训策略
xdclass-video-service:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
2.openFeign调用
Feign默认集成了Ribbon
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
dependency>
启动类配置注解:
@EnableFeignClients
增加一个接口:
@FeignClient(value = "xdclass-video-service", fallback = VideoServiceFallback.class)
public interface VideoService {
// 这里的方法是 video 视频服务中的方法
@GetMapping("/api/v1/video/getVideoById")
Video getVideoById (@RequestParam("videoId")Integer videoId);
}
// value 是application.name fallback 的参数是指定的一个 托底的类,当这个接口中的方法失效的时候,会进入 回调类中调用托底方法
@FeignClient(value = "xdclass-video-service", fallback = VideoServiceFallback.class)
托底类:
@Service
public class VideoServiceFallback implements VideoService {
// 正常接口调用失败,就会进入托底类中调用此方法
@Override
public Video getVideoById(Integer videoId) {
Video video = new Video();
video.setTitle("这是一个兜底 fallback 数据");
video.setId(3);
video.setCoverImg("images");
video.setSummary("描述");
return video;
}
}
3.Ribbon 和 openFeign 的区别
ribbon和feign两个的区别和选择:
选择feign,feign默认集成了ribbon
写起来更加思路清晰和方便,feign面向接口编程
采用注解方式进行配置,配置熔断等方式方便
七、CAP理论
1.CAP基础理论
-
CAP定理: 指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可同时获得
- 一致性(C):所有节点都可以访问到最新的数据
- 可用性(A):每个请求都是可以得到响应的,不管请求是成功还是失败
- 分区容错性(P):除了全部整体网络故障,其他故障都不能导致整个系统不可用
-
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡
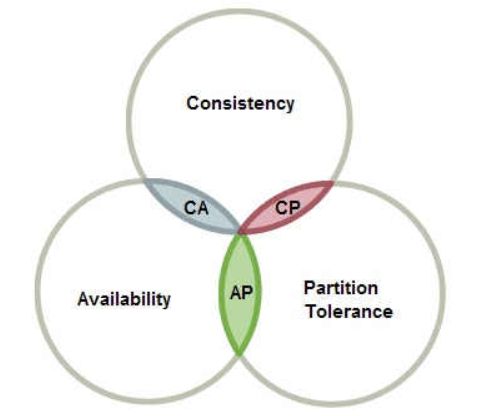
CA: 如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的
CP: 如果不要求A(可用),每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统
AP:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。
2.CAP注册中心的选择
- 常见注册中心:zk、eureka、nacos
- 那你应该怎么选择
| Nacos | Eureka | Consul | Zookeeper | |
|---|---|---|---|---|
| 一致性协议 | CP+AP | AP | CP | CP |
| 健康检查 | TCP/HTTP/MYSQL/Client Beat | 心跳 | TCP/HTTP/gRPC/Cmd | Keep Alive |
| 雪崩保护 | 有 | 有 | 无 | 无 |
| 访问协议 | HTTP/DNS | HTTP | HTTP/DNS | TCP |
| SpringCloud集成 | 支持 | 支持 | 支持 | 支持 |
-
Zookeeper:CP设计,保证了一致性,集群搭建的时候,某个节点失效,则会进行选举行的leader,或者半数以上节点不可用,则无法提供服务,因此可用性没法满足
-
Eureka:AP原则,无主从节点,一个节点挂了,自动切换其他节点可以使用,去中心化
-
结论:
- 分布式系统中P,肯定要满足,所以只能在CA中二选一
- 没有最好的选择,最好的选择是根据业务场景来进行架构设计
- 如果要求一致性,则选择zookeeper/Nacos,如金融行业 CP
- 如果要求可用性,则Eureka/Nacos,如电商系统 AP
- CP : 适合支付、交易类,要求数据强一致性,宁可业务不可用,也不能出现脏数据
- AP: 互联网业务,比如信息流架构,不要求数据强一致,更想要服务可用
3.CAP权衡结果 Base理论
- 什么是Base理论
CAP 中的一致性和可用性进行一个权衡的结果,核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性, 来自 ebay 的架构师提出
- Basically Available(基本可用)
- 假设系统,出现了不可预知的故障,但还是能用, 可能会有性能或者功能上的影响
- Soft state(软状态)
- 允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时
- Eventually consistent(最终一致性)
- 系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问最终都能够获取到最新的值
八、高并发下微服务架构存在的问题和解决方案
存在问题: 微服务拆分多个系统,服务之间相互依赖,可能由于 负载过高、流量突发或者网络异常等情况导致服务不可用
解决思路:
- 不要外界影响
- 不被请求拖垮
- 上游服务
- 下游服务
1.限流
采用漏洞算法
2.熔断
服务之间调用出现异常,熔断停止调用,避免拖垮整个业务
保险丝,熔断服务,为了防止整个系统故障,包含当前和下游服务 下单服务 -》商品服务-》用户服务 -》(出现异常-》熔断风控服务
3.降级
服务之间,空余资源降级给紧张资源使用
抛弃一些非核心对的接口和数据,返回兜底数据
4.隔离
限制服务的调用,将其隔离在外
熔断和降级互相交集
-
相同点:
- 从可用性和可靠性触发,为了防止系统崩溃
- 最终让用户体验到的是某些功能暂时不能用
-
不同点
- 服务熔断一般是下游服务故障导致的,而服务降级一般是从整体系统负荷考虑,由调用方控制
5.解决方案:流量防卫兵-Sentinel
官网地址:https://github.com/alibaba/Sentinel/wiki/%E6%8E%A7%E5%88%B6%E5%8F%B0
下载好jar包后的启动命令:
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.0.jar
导入jar包:
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-sentinelartifactId>
dependency>
配置文件:
# sentinel 限流 dashboard: 8080 控制台端口
# port: 9998 本地启的端口,随机选个不能被占用的,与dashboard进行数据交互,会在应用对应的机器上启动一个 Http Server,该 Server 会与 Sentinel 控制台做交互, 若被占用,则开始+1一次扫描
spring:
cloud:
sentinel:
transport:
dashboard: 127.0.0.1:8080
port: 9998
6.Sentinel自定义异常-整合Open-Feign
自定义 sentinel 异常返回结果:
@Component
public class MySentinelBlockHandler implements BlockExceptionHandler {
/*
FlowException //限流异常
DegradeException //降级异常
ParamFlowException //参数限流异常
SystemBlockException //系统负载异常
AuthorityException //授权异常
*/
/**
* V2.1.0 到 V2.2.0后,sentinel 里面依赖进行改动,且不向下兼容
* @param request
* @param response
* @param e
* @throws Exception
*/
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
System.out.println("request.getRequestURI() = " + request.getRequestURI());
System.out.println("request.getRemoteUser() = " + request.getRemoteUser());
System.out.println("request.getContextPath() = " + request.getContextPath());
System.out.println("request.getMethod() = " + request.getMethod());
// 降级业务
Map<String,Object> backMap=new HashMap<>();
if (e instanceof FlowException){
backMap.put("code",-1);
backMap.put("msg","限流-异常啦");
}else if (e instanceof DegradeException){
backMap.put("code",-2);
backMap.put("msg","降级-异常啦");
}else if (e instanceof ParamFlowException){
backMap.put("code",-3);
backMap.put("msg","热点-异常啦");
}else if (e instanceof SystemBlockException){
backMap.put("code",-4);
backMap.put("msg","系统规则-异常啦");
}else if (e instanceof AuthorityException){
backMap.put("code",-5);
backMap.put("msg","认证-异常啦");
}
// 设置返回json数据
response.setStatus(200);
response.setHeader("content-Type","application/json;charset=UTF-8");
response.getWriter().write(JSON.toJSONString(backMap));
}
}
7.新版Sentinel整合OpenFeign配置实战
配置文件:
# 开启 feign 对 Sentinel 的支持
feign:
sentinel:
enabled: true
九、JDK相关
简介:讲解JDK⼀些基础知识科普
- OpenJDK和OracleJDK版本区别
- OpenJDK是JDK的开放源码版本,以GPL协议的形式发布(General Public License)
- Oracle JDK采⽤了商业实现
- LTS 是啥意思?
- Long Term Support ⻓期⽀持的版本,如JDK8、JDK11都是属于LTS
- JDK9 和 JDK10 这两个被称为“功能性的版本”不同, 两者均只提供半年的技术⽀持
- 甲⻣⽂释出Java的政策,每6个⽉会有⼀个版本的释出,⻓期⽀持版本每三年发布⼀次,根据 后续的发布计划,下⼀个⻓期⽀持版 Java 17 将于2021年发布
- 8u20、11u20是啥意思?
- 就是Java的补丁,⽐如JDK8的 8u20版本、8u60版本; java11的 11u20、11u40版本
十、网关 springcloud gateway
简介:介绍什么是微服务的网关和应用场景
- 什么是网关
- API Gateway,是系统的唯一对外的入口,介于客户端和服务器端之间的中间层,处理非业务功能 提供路由请求、鉴权、监控、缓存、限流等功能
- 统一接入
- 智能路由
- AB测试、灰度测试
- 负载均衡、容灾处理
- 日志埋点(类似Nignx日志)
- 流量监控
- 限流处理
- 服务降级
- 安全防护
- 鉴权处理
- 监控
- 机器网络隔离
- 主流的网关
- zuul:是Netflix开源的微服务网关,和Eureka,Ribbon,Hystrix等组件配合使用,依赖组件比较多,性能教差
- kong: 由Mashape公司开源的,基于Nginx的API gateway
- nginx+lua:是一个高性能的HTTP和反向代理服务器,lua是脚本语言,让Nginx执行Lua脚本,并且高并发、非阻塞的处理各种请求
- springcloud gateway: Spring公司专门开发的网关,替代zuul
1.网关实战:
导入 jar 包:
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-gatewayartifactId>
dependency>
配置文件:
# 端口号
server:
port: 8888
# application 的名字 不能有下划线 _
spring:
application:
name: xdclass-api-gateway
cloud:
# nacos 注册与发现
nacos:
discovery:
server-addr: 127.0.0.1:8848
# sentinel 限流 dashboard: 8080 控制台端口
# port: 9999 本地启的端口,随机选个不能被占用的,与dashboard进行数据交互,会在应用对应的机器上启动一个 Http Server,该 Server 会与 Sentinel 控制台做交互, 若被占用,则开始+1一次扫描
sentinel:
transport:
dashboard: 127.0.0.1:8080
port: 9993
gateway:
routes: #数组形式
- id: order-service #路由唯一标识
# uri: http://127.0.0.1:8000 #想要转发到的地址
uri: lb://xdclass-order-service # 从nacos 进行转发 lb 是负载均衡的意思
order: 1 #优先级,数字越小优先级越高
predicates: #断言过滤器 配置哪个路径才转发 【RoutePredicateFactory】 支持多个predicates请求转发,如果配置多个必须满足多个才能转发
- Path=/order-server/**
# - Before=2020-10-30T18:59:00.000+08:00[Asia/Shanghai]
# - Query=source
# 这个时间【之前可以访问】2020-10-25T14:10:07.049+08:00[Asia/Shanghai] ZonedDateTime
# Query=source 每个接口必须携带一个字段过来 source
filters: #过滤器,请求在传递过程中通过过滤器修改
- StripPrefix=1 #去掉第一层前缀
discovery:
locator:
enabled: true # 开启网关拉取 nacos 服务
#访问路径 http://localhost:8888/order-server/api/v1/video_order/list
#转发路径 http://localhost:8000/api/v1/video_order/list
#需要过滤器去掉前面第一层
2.网关自定义全局过滤
自定义全局过滤:
//@Component
public class UserGlobalFilter implements GlobalFilter, Ordered {
/**
* 【网关不要加入太多业务逻辑,否则会影响性能】
*/
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 写业务逻辑
String token = exchange.getRequest().getHeaders().getFirst("Authorization");
// 根据业务鉴权
if (StrUtil.isEmpty(token)) {
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
Mono<Void> voidMono = exchange.getResponse().setComplete();
return voidMono;
}
Mono<Void> filter = chain.filter(exchange);
return filter;
}
// 数字越小,优先级越高
@Override
public int getOrder() {
return 0;
}
}
十一、albabaCloud下实现链路追踪功能
1.快速排查问题所在
2.快速排查调用慢的情况
1.链路追踪系统Sleuth
简介:讲解什么Sleuth链路追踪系统
- 什么是Sleuth
- 一个组件,专门用于记录链路数据的开源组件
- 文档:https://spring.io/projects/spring-cloud-sleuth
- 案例
[order-service,96f95a0dd81fe3ab,852ef4cfcdecabf3,false]
第一个值,spring.application.name的值
第二个值,96f95a0dd81fe3ab ,sleuth生成的一个ID,叫Trace ID,用来标识一条请求链路,一条请求链路中包含一个Trace ID,多个Span ID
第三个值,852ef4cfcdecabf3、spanid 基本的工作单元,获取元数据,如发送一个http
第四个值:false,是否要将该信息输出到zipkin服务中来收集和展示。
导入jar:
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
dependency>
2.链路追踪系统ZipKin 部署实战
-
什么是zipkin
- 官网
- https://zipkin.io/
- https://zipkin.io/pages/quickstart.html
- 大规模分布式系统的APM工具(Application Performance Management),基于Google Dapper的基础实现,和sleuth结合可以提供可视化web界面分析调用链路耗时情况
- 官网
-
同类产品
- 鹰眼(EagleEye)
- CAT
- twitter开源zipkin,结合sleuth
- Pinpoint,运用JavaAgent字节码增强技术
-
StackDriver Trace (Google)
-
开始使用
- 安装包在资料里面,启动服务
java -jar zipkin-server-2.12.9-exec.jar- 访问入口:http://127.0.0.1:9411/zipkin/
- zipkin组成:Collector、Storage、Restful API、Web UI组成
3.链路追踪组件Zipkin+Sleuth整合实战
简介:使用Zipkin+Sleuth业务分析调用链路分析实战
- sleuth收集跟踪信息通过http请求发送给zipkin server
- zipkin server进行跟踪信息的存储以及提供Rest API即可
- Zipkin UI调用其API接口进行数据展示默认存储是内存,可也用mysql 或者elasticsearch等存储
- 微服务加入依赖
org.springframework.cloud
spring-cloud-starter-zipkin
- 配置地址和采样百分比配置
spring:
application:
name: api-gateway
zipkin:
base-url: http://127.0.0.1:9411/ #zipkin地址
discovery-client-enabled: false #不用开启服务发现
sleuth:
sampler:
probability: 1.0 #采样百分比
默认为0.1,即10%,这里配置1,是记录全部的sleuth信息,是为了收集到更多的数据(仅供测试用)。
在分布式系统中,过于频繁的采样会影响系统性能,所以这里配置需要采用一个合适的值。
4.Zipkin持久化配置
持久化的数据库sql脚本:
/*
Navicat MySQL Data Transfer
Source Server : mydata
Source Server Version : 50726
Source Host : localhost:3306
Source Database : zipkin_log
Target Server Type : MYSQL
Target Server Version : 50726
File Encoding : 65001
Date: 2020-10-26 17:17:01
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for zipkin_annotations
-- ----------------------------
DROP TABLE IF EXISTS `zipkin_annotations`;
CREATE TABLE `zipkin_annotations` (
`trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` varchar(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` blob COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` int(11) NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` bigint(20) DEFAULT NULL COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` int(11) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` binary(16) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` smallint(6) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` varchar(255) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null',
UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`span_id`,`a_key`,`a_timestamp`) COMMENT 'Ignore insert on duplicate',
KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`span_id`) COMMENT 'for joining with zipkin_spans',
KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTraces/ByIds',
KEY `endpoint_service_name` (`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames',
KEY `a_type` (`a_type`) COMMENT 'for getTraces and autocomplete values',
KEY `a_key` (`a_key`) COMMENT 'for getTraces and autocomplete values',
KEY `trace_id` (`trace_id`,`span_id`,`a_key`) COMMENT 'for dependencies job'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;
-- ----------------------------
-- Table structure for zipkin_dependencies
-- ----------------------------
DROP TABLE IF EXISTS `zipkin_dependencies`;
CREATE TABLE `zipkin_dependencies` (
`day` date NOT NULL,
`parent` varchar(255) NOT NULL,
`child` varchar(255) NOT NULL,
`call_count` bigint(20) DEFAULT NULL,
`error_count` bigint(20) DEFAULT NULL,
PRIMARY KEY (`day`,`parent`,`child`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;
-- ----------------------------
-- Table structure for zipkin_spans
-- ----------------------------
DROP TABLE IF EXISTS `zipkin_spans`;
CREATE TABLE `zipkin_spans` (
`trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` bigint(20) NOT NULL,
`id` bigint(20) NOT NULL,
`name` varchar(255) NOT NULL,
`remote_service_name` varchar(255) DEFAULT NULL,
`parent_id` bigint(20) DEFAULT NULL,
`debug` bit(1) DEFAULT NULL,
`start_ts` bigint(20) DEFAULT NULL COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` bigint(20) DEFAULT NULL COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',
PRIMARY KEY (`trace_id_high`,`trace_id`,`id`),
KEY `trace_id_high` (`trace_id_high`,`trace_id`) COMMENT 'for getTracesByIds',
KEY `name` (`name`) COMMENT 'for getTraces and getSpanNames',
KEY `remote_service_name` (`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames',
KEY `start_ts` (`start_ts`) COMMENT 'for getTraces ordering and range'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED;
运行指令:
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin_log --MYSQL_USER=root --MYSQL_PASS=xdclass.net
十二、配置中心nacos
1.注释原来的 application.yml 文件
新建一个 bootstrap.yml 文件
spring:
application:
name: xdclass-api-gateway
cloud:
nacos:
config:
server-addr: 127.0.0.1:8848 #Nacos配置中心地址
file-extension: yaml #文件拓展格式
profiles:
active: dev
若不可用则重新编译项目:
重新构建下项目
mvn clean package -U
然后重启IDEA
在nacos中配置:
- dataId组成,在 Nacos Spring Cloud 中,dataId 的完整格式如下
${prefix}-${spring.profiles.active}.${file-extension}
prefix 默认为 spring.application.name 的值
spring.profiles.active 即为当前环境对应的 profile
当 spring.profiles.active 为空时,对应的连接符 - 也将不存在,dataId 的拼接格式变成 ${prefix}.${file-extension}
file-exetension 为配置内容的数据格式,可以通过配置项 spring.cloud.nacos.config.file-extension 来配置。目前只支持 properties 和 yaml 类型。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DiHWkiOC-1606960678014)(C:\Users\AOSSCI\AppData\Roaming\Typora\typora-user-images\image-20201026172918849.png)]
2.配置中心下面动态的获取配置属性
- 什么是动态刷新配置
- 我们修改了配置,程序不能自动更新
- 动态刷新就可以解决这个问题
- 配置实战
- 增加Nacos增加测试配置
- 编写代码
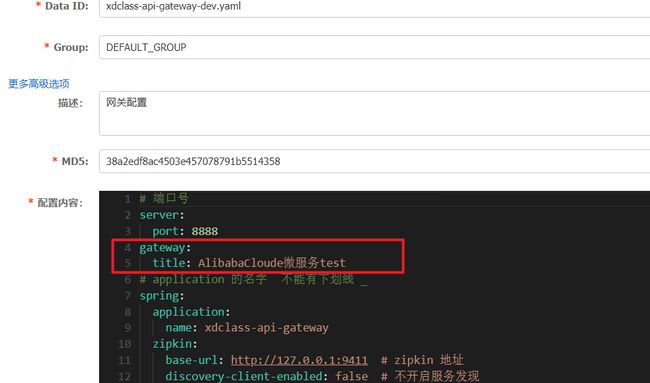
编写代码动态获取文件:
@RequestMapping("/api/v1/get")
@RestController
@RefreshScope
public class GatewayConfigRefresh {
@Value("${gateway.title}")
private String gatewayTitle;
@GetMapping("/test")
public Object test(){
return gatewayTitle;
}
}