JVM-G1垃圾回收器:从入门到-到搬砖系列一:简介跟基础介绍(内存模型)
JVM-G1垃圾回收器:从入门到-到搬砖系列一:简介跟基础介绍
- (一) G1(Garbage First Collection):简介
-
- 1.这是一个什么类型的文章?
- 2.阅读文章后达到的效果
- 3.G1是什么?
- 4.为什么学习G1
- 5.how?怎么去学G1?
- (二)G1脉络介绍(内存模型)
-
- 1.内存模型:
-
- 名词概念普及
- 内存模型不一致原因:
- 垃圾在内存中的流转
- 内存对象的逃逸分析
- 小结一下
(一) G1(Garbage First Collection):简介
进入正题之前,我们首先聊聊这是一个什么类型的博客。阅读这一系列博客的作用,跟跟达到的实际效果是什么。
1.这是一个什么类型的文章?
本人最近一直在研究JVM,说实话,这东西内容多,知识资料也挺杂。如果作为一个刚刚入门,或者是只是有一点点工作经验的人来说,看那些知识断章的文章,或者是去看周志明老师的:《深入理解JVM》,说实话:是真的看完就忘记系列。当然也不是不推荐大家去看,而是说,作为一个小白同学,一下就去理解这么庞大的内容,并且从中扣细节,属实比较困难。到最后就变成了背概念,然后过不久就成了忘记牛逼知识系列了。
所以这篇文章的针对人群呢,就是有一点点java基础,然后又想开始深入理解底层jvm知识的人群。
2.阅读文章后达到的效果
1.首先为咱们理清G1垃圾回收器的整体脉络。
2.为我们工作中的jvm调优,提供理论基础,并且提供一些调优知识以及经验。
3.为我们面试中的jvm问答提供一个基本知识架构基础。做到问到不慌,心中有丘壑。
3.G1是什么?
G1全称:Garbage First Collection,翻译一下就是垃圾优先收集器。当然还有各种各样的一个七七八八的历史简介,大家百度一下五花八门的都有,我们就不在这详细的赘述了。
稍稍要谈一下G1的话,必然绕不开的就是CMS,所以我们就稍微拿两者来对比一下,来聊聊G1是什么。
1.G1 在我看来是继承CMS这个垃圾回收器的基础之上研发出来的。同样的并发垃圾收集器,大大减少了STW(Stop The World)时间。
2.他们两个的垃圾回收算法的核心思想都是空间换时间,但是G1相对于CMS来说做的更加优秀。
3.G1作为更先进的垃圾回收器,相对于CMS来说简化了更多的参数,让更多的工作交由G1本身动态设置,简化了开发人员的工作量跟学习成本。设置基本的简单的参数就能达到非常好的运行效果。
4.为什么学习G1
非常简单的一个原因,因为工作中用到了。JDK8作为现在所有互联网各大厂商大面积使用的版本,其中能用的的垃圾回收器无外乎三种:Parallel Scavenger、CMS、G1。其中以CMS跟G1 为最主要的两个类型,像我待过的几家公司,所有的都是这两个垃圾回收器。所以作为日常工作,还是面试,都必须了解甚至是熟练掌握这两个垃圾回收器的原理。
5.how?怎么去学G1?
在我看来,学习一门知识,首先观其脉络,知道其总体的架构思路。然后再细细掰其中的细节。这样能更快更好的理解细节的内容,以及为什么这样处理的原因。所以,接下来,我就会首先把G1所涉及到的部分基础知识,一一介绍。然后,讲G1的整个流程,最后再详细的掰开回收流程之中每个阶段的详细内容。
(二)G1脉络介绍(内存模型)
1.内存模型:
首先一图胜过前言万语,上一张G1内存模型图。

名词概念普及
Region: G1把堆内存分成一块块的小内存分区, 每块分区的大小为1~32M之间。如果你不设置分区大小(+XX:G1HeapRegionSize = N),默认大小:X=Head(堆内存大小)/ 2048,但是X大小,只能在2的幂次方中取(1,2,4,8,16,32),所以最终大小就是X靠近那个2的幂次方,就为最终的值。
Humongous: 大对象区,存放超过阀值的大对象。(阀值 = G1HeadRegionSize / 2) 如果一个Object 超过了一个Region大小,那么就如上图所示,一个对象会放在几个连续的Region里面。所以这里就有一个思考:如果说一个超大的对象,没有连续的区域可以存放会发生什么?(接下来会详细解释)
Eden,Survivor: 年轻代分区
Old: 老年代分区
解释完名词,我们来详细的探讨一下G1的内存模型。从上图,我们可以很明显的看到G1的内存模型跟之前的一些垃圾回收器比如:CMS \ Parallel Scavange 等垃圾器有一个明显的区别,就是青年代,老年代之间的不是连续的了,G1变成了一小块一小块的。为什么会这样呢?
为了加深印象,我们先看看CMS的内存模型图:

对比上面两个图,可以明显的看到CMS的内存物理结构实际上是连续的,老年代的就一整块老年代的,新生代就一整块是新生的,但是G1并非如此。为什么会造成G1做出如此大的改变呢?
内存模型不一致原因:
1回收算法不一致: G1使用的是:Copying(复制) CMS:Mark-Sweep(标记-清除)、Mark-Compact(标记-整理)
首先我们通常讲的CMS回收器,只是老年代的回收器,而青年代回收器通常是ParNew回收器(一个并发回收的年轻代回收器,没听过的同学可以某度一下),但是G1回收器,无论是老年代青年代都是全部由G1回收器管控。
其次,我们都知道垃圾回收的三种总体上的算法(Copying(复制)、Mark-Sweep(标记-清除)、Mark-Compact(标记-整理),各有优缺点。其中copy效率高,不会产生碎片,但是会浪费空间。
G1为了减少空间的浪费,设计成多个小块分区,分区回收,这样就算是我们使用了大部分的空间,但是只要还有剩下空闲空间就能继续使用copying 算法腾出空间让垃圾回收器继续运行。
这样的思想,我们可以在其他青年代回收器上看到。比如ParNew,Serial New,他们回收垃圾的思路就是:Eden->Survivor1,Survivor1(s1)->Survivor2(s2),s2->s1…一直到一个垃圾年龄够了,然后进入老年代,这里面都是使用的Copying算法,为了减少Copying 算法造成的空间浪费所以把 年轻代空间 分割成 Eden:S1:S2 = 8:1:1,当然这是默认情况的比例,你可以通过参数 -XX:SurvivorRatio=N 设置,如果你设置N = 8,那么 Eden:S1:S2 = 8:1:1,如果你设置N =4 ,那么 Eden:S1:S2 = 4:1:1。(至于为什么这样设置,可以看我之后关于CMS垃圾回收器的文章)
所以总结一句话G1 为了尽量减少Copying 垃圾回收算法带来的空间浪费,将内存堆分成了小块分区。
垃圾在内存中的流转
啥也别说,上图为敬!

对象流转流程如下:
1.new一个对象,首先在新生代Eden区分配。设置 :O(0,Eden) = 对象O经历了0次垃圾回收,处于Eden区
2.经历了一次垃圾回收之后 ,对象状态由 O(0,Eden) -> O(1,S1)
3.经历了两次回收之后 O(1,S1)-> O(2,S2)
4.经历了三次回收之后 O(2,S2)-> O(3,S3)
一直重复上述 3,4 逻辑 ,直到对象年龄足够,进入old区
5.O(N,S2/S1) -> O(N+1,Old)
解释一下:
其中 进入老年代时的经历N次回收,在垃圾回收器的术语当中,每经历一次垃圾回收对象的年龄代+1。
N的值在不同的回收器中不相同。在CMS中默认为6,在G1中默认为15,其最大值不能超过15,或者自己设置参数(-XX:MaxTenuringThreshold = N)。(为什么最大年龄不能超过15,稍稍解释一下。就是对象头部信息里面保存对象年龄信息的只有4个bit,2^4-1==15)
这个逻辑不只是G1,其他的任何分代垃圾回收器,对象的流转逻辑都是这样的。
但是,如果我们只是了解这一点点,好像又太普通了,深究其细节,我们需要更深入的探究。
问题1: 是不是所有对象的流转流程都是按照这个逻辑来?
答案:显然不是。
问题2: 有哪些例外呢?
1.大对象显然不是这样的流转流程。(对象多大才能算是大对象,上面有详细描述!这里就不多说了)
2.非逃逸对象可以直接分配在栈上。(what 逃逸对象是什么鬼?大家慢慢看下去。)
那么真正new一个对象,他的分配流程图是怎么样的呢?
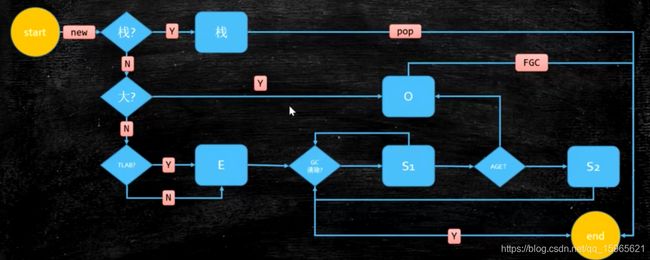
(这张图是借用马士兵老师jvm课程视频中流程图)
首先这个图有个小小的问题,就是 FGC 这个流程,这里其实在G1里面可以是Full GC / Mix GC,在CMS里面也可以是 Full GC / OldGC。在这里要区分一个概念就是 Full GC 不等于 Mix GC 或者 Old GC 或者 Major GC。有很多人在博文中会写FullGC 就是老年代GC 就等于OldGC 其实是错的。
那么Full GC 到底是什么?
Full GC在CMS或者G1垃圾回收过程中,比如在 并发标记过程 过程中用户线程产生了新的垃圾,但是又没有多余的空闲空间,垃圾回收器将自动的STW,并且将垃圾回收器降级为单线程的Serial 垃圾回收器,对堆进行回收的一次降级垃圾回收。所以无论是在CMS 或者 G1 发生Full GC 之后,就代表着你的服务停止服务,并且要长时间的进行速度很慢的垃圾回收了。虽然作为一个垃圾回收的兜底手段,但是在商业开发之中是必须要避免发生的。
回到正题:
这张图,上面解释了new一个对象到这个对象被回收详细的流程,其中大对象我们可以看到如果对象被认定为大对象会直接进入old区,但是在G1中,会直接进入Humourgous区中。Humourgous占用的比例,对于G1垃圾回收器来说,其实是算老年代比例的一部分。(注意:这里所说的是占用老年代的比例,而不是属于Old Region)
然后我们我们看上图,我们可以看到一个非常疑惑的点,就是对象竟然会分配到栈上?(惊不惊喜意不意外) why? 为什么?
内存对象的逃逸分析
这里就要谈到一个叫:内存对象的逃逸分析 (Escape Analysis)。
首先我们来说说什么叫内存对象的逃逸分析:
简单来讲就是,Java Hotspot 虚拟机可以分析新创建对象的使用范围,并决定是否在 Java 堆上分配内存的一项技术(百度得到)。稍微说人话一点就是:一个对象在线程执行方法的时候创建,在执行完之后就成为垃圾的对象。这样的对象会直接分配在线程栈上,当方法执行完毕,对象跟着栈帧销毁而销毁。
逃逸分析的 JVM 参数如下:
- 开启逃逸分析:-XX:+DoEscapeAnalysis
- 关闭逃逸分析:-XX:-DoEscapeAnalysis
- 显示分析结果:-XX:+PrintEscapeAnalysis
其实他的主要作用就是快速结束小对象垃圾的生命,不让这样可以直接判定就能结束生命的对象进入堆区,减轻垃圾回收器的压力。
然后可能有的小伙伴不信,那么来点真的东西:(java 版本需要在以上Java SE 6u23+以上,java8默认支持)执行以下代码,观察GC日志。
jvm参数: -server -Xmx10m -Xms10m -XX:+DoEscapeAnalysis -XX:+PrintGC
public class Main {
public static void main(String[] args) {
System.gc();
System.out.println("============start============");
for (int i = 0; i <100000 ; i++) {
alloc();
}
System.out.println("============end============");
}
private static void alloc(){
new User();
}
private static class User{}
}
打印的日志如下:
[GC (System.gc()) 1670K->724K(9728K), 0.0015446 secs]
[Full GC (System.gc()) 724K->603K(9728K), 0.0047578 secs]
============start============
[GC (Allocation Failure) 2651K->931K(9728K), 0.0005124 secs]
============end============
Process finished with exit code 0
我们再来看看关闭逃逸分析的代码以及日志情况:
jvm参数: -server -Xmx10m -Xms10m -XX:-DoEscapeAnalysis -XX:+PrintGC
public class Main {
private static User u;
public static void main(String[] args) {
System.gc();
System.out.println("============start============");
for (int i = 0; i <100000000 ; i++) {
u = alloc();
}
System.out.println("============end============");
}
private static User alloc(){
return new User();
}
private static class User{}
}
日志:
[GC (System.gc()) 1661K->828K(9728K), 0.0021497 secs]
[Full GC (System.gc()) 828K->603K(9728K), 0.0061200 secs]
============start============
[GC (Allocation Failure) 2651K->931K(9728K), 0.0018375 secs]
[GC (Allocation Failure) 2979K->835K(9728K), 0.0003087 secs]
[GC (Allocation Failure) 2883K->803K(9728K), 0.0002589 secs]
[GC (Allocation Failure) 2851K->803K(9728K), 0.0002862 secs]
[GC (Allocation Failure) 2851K->835K(8704K), 0.0002739 secs]
[GC (Allocation Failure) 1859K->803K(9216K), 0.0002803 secs]
[GC (Allocation Failure) 1827K->747K(9216K), 0.0003166 secs]
[GC (Allocation Failure) 1771K->747K(9216K), 0.0002341 secs]
[GC (Allocation Failure) 1771K->747K(9216K), 0.0002428 secs]
[GC (Allocation Failure) 1771K->747K(9216K), 0.0002404 secs]
[GC (Allocation Failure) 1771K->747K(9216K), 0.0002747 secs]
[GC (Allocation Failure) 1771K->747K(9216K), 0.0002021 secs]
.....
[GC (Allocation Failure) 2795K->747K(9728K), 0.0002799 secs]
============end============
Process finished with exit code 0
通过对比,我们很明显的看出。内存逃逸分析技术对于垃圾回收器压力的减轻。
到这里,我们对G1垃圾回收器的内存模型,就有个一个初步大体上的了解。当然其中还有非常多的细节,比如说Region里面是不是只是存对象?RSet是没是?CSet是什么?Rset的三个状态等等一系列的内容,都会在接下来的博客中一一为大家解答。
小结一下
G1垃圾回收机制的内存模型,以及通过内存模型讲解了一个对象的流转过程。最后通过流转过程,为我们讲解了对象栈上分配的原因,以及内存逃逸技术的测试。接下来,我的下一遍博客会大体的讲解G1垃圾回收器的回收流程。
JVM-G1垃圾回收器:从入门到-到搬砖系列二:G1回收流程