Apache顶级项目ShardingSphere — SQL Parser的设计与实现
导语:SQL作为现代计算机行业的数据处理事实标准,是目前最重要的数据处理接口之一,从传统的DBMS(如MySQL、Oracle),到主流的计算框架(如spark,flink)都提供了SQL的解析引擎,因此想对sql进行精细化的操作,一定离不开SQL Parser。Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,需要对SQL进行精细化的操作,如改写,加密等,因此也实现了SQL Parser,并提供独立的Parser引擎。
先来认识一下传统数据库中一条SQL处理流程是怎样的,接受网络包-》数据库协议解析网络包的到sql-》SQL语法解析为抽象语法树-》把语法树转换成关系代数表达式树(逻辑执行计划)-》再转换成物理算子树(物理执行计划)-》遍历物理算子树执行相应算子的实现获取数据并返回。
一、工作原理
SQL Parser 的功能是把一条SQL解析为抽象语法树(AST),SQL Parser需要编译原理相关的知识,简单介绍一下。
SQL Parser 包含词法解析(Lexer)和语法解析(Parser),词法解析的作用是把一个sql 分割成一个一个不可分割的单元,例子:
原始sql: select id,name from table1 where name=“xxx”;
词法解析器输入是原始sql,并且暴露一个接口nextToken(),每次调用nextToken()都会返回一个Token(表示上面所说的不可分割的元素),伪代码如下:
String originSql = "select id,name from table1 where name='xxx'";
Lexer lexer = new Lexer(originSql);
while(!lexer._hitEOF){
// 判断是否结束
System.out.printLn(lexer.nextToken())
}
// 输出如下:
select
id
,
name
from
table1
where
name
=
'xxx'
语法分析器的作用是使用Lexer的输出(调用nextToken()),构造出AST,以上面的sql为例,解析器得出的语法树如下:
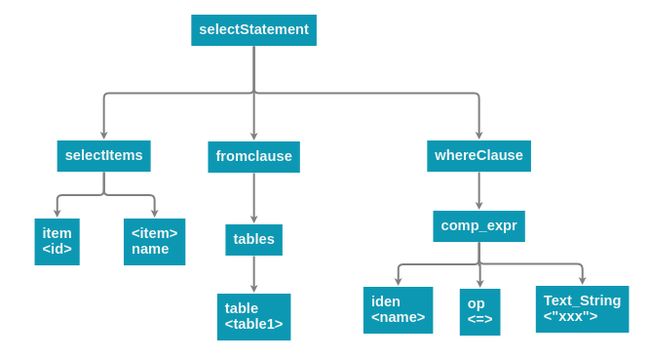
1、Lexer(词法分析)原理
Lexer 也称为分词,从左向右扫描SQL,将其分割成一个个的toke(不可分割的,具有独立意义的单元,类似英语中的单词)。
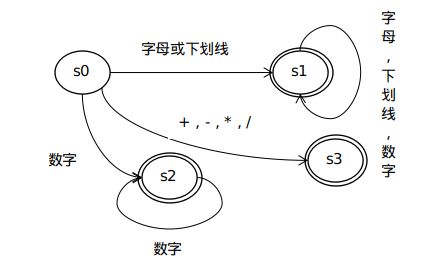
Lexer的实现一般都是构造DFA(确定性有限状态自动机)来实现的,以一个例子说明。
状态转移图如下,这是一个能够识别标识符,数字和一般运算符的词法解析器。
代码实现可以使用传统的while case的模板实现,伪代码如下:
Class Token{
...}
Enum State {
BEGIN,OPERATER,IDENTIFIER,NUMBER
}
Class Lexer{
String input = "...";
State state = BEGIN;
int index = 0;
Token nextToken() {
while(index < input.length) {
Char char = input.charAt(index);
switch (state) {
case BEGIN:
switch (char){
case a-zA-Z_ :
index++;
state = IDENTIFIER;
case +-*/ :
state = BEGIN
return Token(OPERATER)
case 0-9:
state = NUMBER;
index++;
default:
return null;
}
case IDENTIFIER:
switch (char){
case a-zA-Z_0-9 :
index++;
state = IDENTIFIER;
default :
state = BEGIN;
index--;
return Token(IDENTIFIER)
}
case NUMBER:
switch (char){
case 0-9 :
index++;
state = NUMBER;
default :
state = BEGIN;
index--;
return Token(NUMBER)
}
default:
return null;
}
}
}
}
2、Parser(语法解析) 原理
Parser阶段有两种类型方法来实现,一种是自顶向下分析法,另一种是自底向上分析法,简单介绍一下两种类型分析法的处理思路。
首先给出上下文无关语法和相关术语的定义:
- 终结符集合 T (terminal set)
一个有限集合,其元素称为 终结符(terminal) - 非终结符集合 N (non-terminal set)
一个有限集合,与 T 无公共元素,其元素称为 非终结符(non-terminal) - 符号集合 V (alphabet)
T 和 N 的并集,其元素称为符号(symbol) 。因此终结符和非终结符都是符号。符号可用字母:A, B, C, X, Y, Z, a, b, c 等表示。 - 符号串(a string of symbols)
一串符号,如 X1 X2 … Xn 。只有终结符的符号串称为 句子(sentence)。空串 (不含任何符号)也是一个符号串,用 ε 表示。符号串一般用小写字母 u, v, w 表示。 - 产生式(production)
一个描述符号串如何转换的规则。对于上下文本无关语法,其固定形式为:A -> u ,其中 A 为非终结符, u 为一个符号串。 - 产生式集合 P (production set)
一个由有限个产生式组成的集合 - 展开(expand)
一个动作:将一个产生式 A -> u 应用到一个含有 A 的符号串 vAw 上,用 u 代替该符号串中的 A ,得到一个新的符号串 vuw。 - 折叠(reduce)
一个动作:将一个产生式 A -> u 应用到一个含有 u 的符号串 vuw 上,用 A 代替该符号串中的 u ,得到一个新的符号串 vAw。 - 起始符号 S (start symbol)
N 中的一个特定的元素 - 推导(derivate)
一个过程:从一个符号串 u 开始,应用一系列的产生式,展开到另一个的符号串 v。若 v 可以由 u 推导得到,则可写成:u => v 。 - 上下文本无关语法 G (context-free grammar, CFG)
一个 4 元组:(T, N, P, S) ,其中 T 为终结符集合, N 为非终结符集合, P 为产生式集合, S 为起始符号。一个句子如果能从语法 G 的 S 推导得到,可以直接称此句子由语法 G 推导得到,也可称此句子符合这个语法,或者说此句子属于 G 语言。G 语言( G language) 就是语法 G 推导出来的所有句子的集合,有时也用 G 代表这个集合。 - 解析(parse)
也称为分析,是一个过程:给定一个句子 s 和语法 G ,判断 s 是否属于 G ,如果是,则找出从起始符号推导得到 s 的全过程。推导过程中的任何符号串(包括起始符号和最终的句子)都称为 中间句子(working string)。
2.1 自顶向下分析法 LL(1)
LL(1) 是自顶向下分析法的一种,第一个L代表从左向右扫描待解析文本,第二个L代表从左向右展开,(1)代表每次读取一个Token。
以简单表达式为例子:
// 语法规则, 整个是一个产生式,左边expr为非终结符,NUM是一
//个Token,为终结符
expr: NUM | NUM expr
// 待解析文本
1 2 23 45
解析过程如下:

我们的目标是将起始符号expr展开成句子 1 2 23 45
- 对比expr和NUM(1),只能选择expr -> NUM expr,才可以和NUM(1)匹配,展开后得NUM expr
- 忽略已匹配的NUM(1), 再次读入NUM(2),只能选择expr -> NUM expr,展开后得NUM expr
- 忽略已匹配的NUM(2),再次读入NUM(23),只能选择expr -> NUM expr,展开后得NUM expr
- 忽略已匹配的NUM(23),再次读入NUM(45),只能选择expr -> NUM,展开后得NUM
- 得到最终句子 NUM(1)NUM(2) NUM(23) NUM(45) 可接受,解析完成
注意点:为什么1,2,3只能选择expr -> NUM expr, Lexer中会有接口判断是否得到末尾,ShardingSphere中接口是lexer._hitEOF。
2.1 自底向上分析法 LR(1)
自底向上分析的顺序和自顶向下分析的顺序相反,从给定的句子开始,不断的挑选出合适的产生式,将中间句子中的子串折叠为非终结符,最终折叠到起始符号。
LR(1) 是自底向上分析法的一种,第一个L代表从左向右扫描待解析文本,第二个R代表从右向坐折叠,(1)代表每次读取一个Token。
以简单表达式为例:
// 语法规则, 整个是一个产生式,左边expr为非终结符,NUM是一
//个Token,为终结符
expr: NUM | expr NUM
// 待解析文本
1 2 23 45
解析过程是如下:
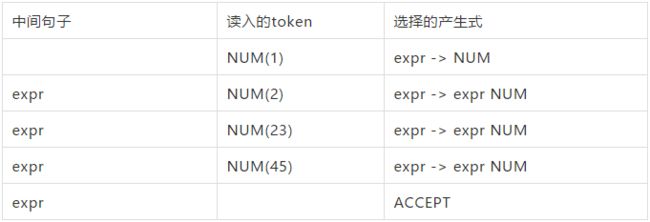
我们的目标是把 1 2 23 45 折叠为expr
- 读入NUM(1),发现只能选择expr -> NUM, 折叠得expr
- 读入NUM(2),只能选择expr -> expr NUM,折叠得expr
- 读入NUM(23),只能选择expr -> expr NUM, 折叠得expr
- 读入NUM(45),只能选择expr-> expr NUM, 折叠得expr 可接受,解析完成
二、ShardingSphere Parser 实现
实现Parser的方式一般分为两种,一种是写代码实现状态机来进行解析,另一种是通过解析器生成器根据定义的语法规则生成解析器,ShardingSphere使用第二种方式,这是由于衡量了性能,扩展性和容易维护因素最终决定的。
以ShardingSphere中的MySQL 解析引擎为例,模块shardingsphere-sql-parser-mysql,语法定义路径src/main/antlr。
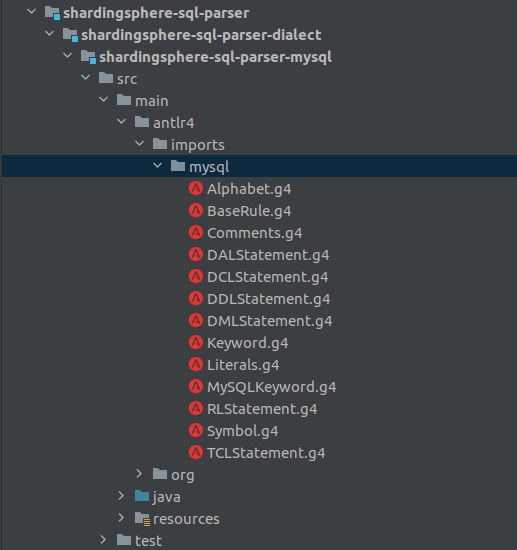
功能点:
- 提供独立的SQL解析引擎
- 可以方便的对语法规则进行扩充和修改
- 提供SQL 变量参数化功能
- 提供SQL 格式化功能
- 支持多种方言
| 数据库 | 支持状态 |
|---|---|
| MySQL | 支持,完善 |
| PostgreSQL | 支持,完善 |
| SQLServer | 支持 |
| Oracle | 支持 |
| SQL92 | 支持 |
使用方法:
//maven 依赖
org.apache.shardingsphere
shardingsphere-sql-parser-engine
${project.version}
// 根据需要引入指定方言的解析模块(以MySQL为例),可以添加所有支持的方言,也可以只添加使用到的
org.apache.shardingsphere
shardingsphere-sql-parser-mysql
${project.version}
//获取语法树
/**
* databaseType type:String 可能值 MySQL,Oracle,PostgreSQL,SQL92,SQLServer
* sql type:String 解析的SQL
* useCache type:boolean 是否使用缓存
* @return parse tree
*/
ParseTree tree = new SQLParserEngine(databaseType).parse(sql, useCache);
// 获取SQLStatement
/**
* databaseType type:String 可能值 MySQL,Oracle,PostgreSQL,SQL92,SQLServer
* useCache type:boolean 是否使用缓存
* @return SQLStatement
*/
ParseTree tree = new SQLParserEngine(databaseType).parse(sql, useCache);
SQLVisitorEngine sqlVisitorEngine = new SQLVisitorEngine(databaseType, "STATEMENT");
SQLStatement sqlStatement = sqlVisitorEngine.visit(tree);
三、常见解析器
1、MySQL Parser
词法解析通过手写代码的方式实现,语法解析通过定义语法规则,使用bison生成语法解析代码。
2、PostgreSQL Parser
通过定义语法规则,使用flex/bison生成词法,语法解析代码。
3、TIDB Parser(能够单独使用, golang)
词法解析通过手写代码的方式实现,语法解析通过定义语法规则,使用goyacc生成语法解析代码。
4、ShardingSphere Parser(能够单独使用, 多种目标语言c,c++,java, golang,python)
- 通过定义语法规则,使用ANTLR生成词法,语法解析代码
- 可以方便自定义语法
- 提供缓存机制
- SQL 格式化,SQL参数化
- 支持多种DB: Mysql, PostgreSQL, SQLServer, Oracle, SQL92
- 支持自定义visitor
5、alibaba druid(能够单独使用,java)
- 通过代码的方式实现词法解析器和语法解析器
- 支持多种DB: Mysql, PostgreSQL, SQLServer, Oracle, odps, db2, hive, SQL92
- SQL 格式化,SQL参数化
- 支持自定义visitor
6、Jsqlparser(能够单独使用, java)
- 通过javacc定义语法解析规则实现
- 不局限于某一个DB
注意:
- 基本都是通过定义语法来实现的,词法解析都是通过定义正则语言,构造有限状态自动机实现,区别是LL(自顶向下)语法和LR(自底向上)语法。
- antlr使用的是LL(自顶向下)的语法规则 改进的LL(*)算法,Bison和goyacc使用LR(自底向上)的语法规则,LALR算法,Jsqlparser是LL(k), druid目测类似LL(k)。
- LR相比LL表达能力更强,典型的例子是antlr不支持相互左递归,bison支持。
四、AST(语法树)应用
- 转化为逻辑执行计划,逻辑执行计划再转换为物理执行计划,物理执行计划用于存储引擎具体执行。
eg: select * from table1, table2 where table1.id=1 转化为逻辑执行计划为:
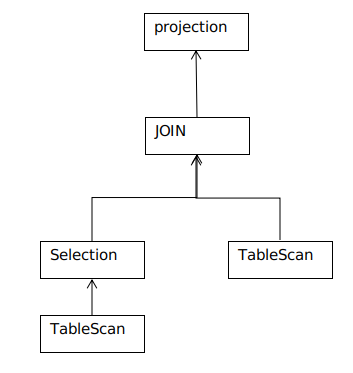
- 通过遍历语法树,对SQL进行格式化,参数化等
参考文献
[1] LL(*):https://www.antlr.org/papers/LL-star-PLDI11.pdf
[2] LALR:https://suif.stanford.edu/dragonbook/lecture-notes/Stanford-CS143/11-LALR-Parsing.pdf;http://www.cs.ecu.edu/karl/5220/spr16/Notes/Bottom-up/lalr.html
[3] TiDB优化器设计:https://pingcap.com/blog-cn/tidb-cascades-planner
[4] MySQL优化器设计:https://dev.mysql.com/doc/refman/8.0/en/cost-model.html
本文作者
陆敬尚,京东数科软件工程师,Apache ShardingSphere Committer,热爱开源,现专注于ShardingSphere 的开源建设和开发工作。
招聘信息
京东数科长期招聘Apache ShardingSphere的开源工程师(点击阅读原文可查询岗位详情),欢迎优秀的开源人才加入我们,共同打造出色的Apache顶级项目!简历投递邮箱:[email protected]。
往期好文推荐:
2020 ICDM 知识图谱竞赛获奖技术方案
一文读懂联邦学习的前世今生(建议收藏)
突破DevOps瓶颈:京东数科自动化测试平台建设实践
京东数科七层负载 | HTTPS硬件加速 (Freescale加速卡篇)
京东数科mPaaS:深度解读京东金融App(Android)的秒开优化实践
