广度优先搜索算法BFS讲解以及python 实现
一.图简介
假设你居住在旧金山,要从双子峰前往金门大桥,你想乘公交车前往。
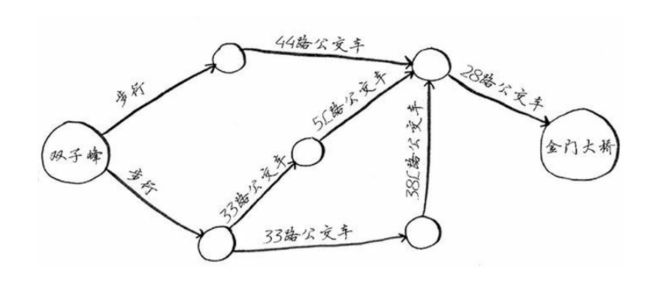
为找出换乘最少的乘车路线,你将使用怎样的算法?

金门大桥未突出,因此一步无法到达那里。两步能吗?

金门大桥未突出,两步步无法到达那里。三步能吗?

金门大桥突出了!因此从双子峰出发,可沿下面的路线三步到达金门大桥。
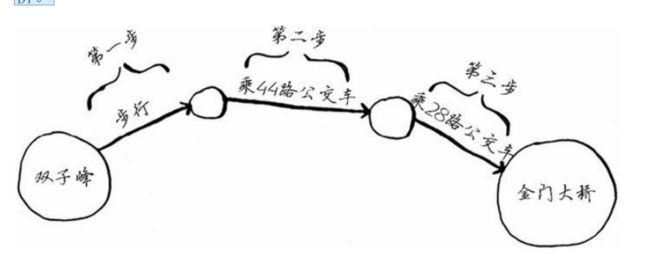
还有其他前往金门大桥的路线,但他们更远(需要四步)。这个算法发现,前往金门大桥的最短路径需要三步,这种问题被称为最短路径问题。
解决最短路径的算法被称为广度优先搜索。
需要两个步骤:
- 使用图来建立问题模型。
- 使用广度优先搜索解决问题。
1图
图模拟一组连接。假设你和你朋友正在玩牌,模拟下谁欠谁钱。
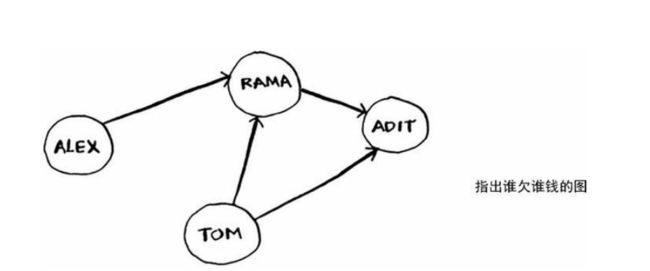
Alex欠Rama钱,Tom欠Adit钱,等等。图由节点(node)和边(edge)组成。
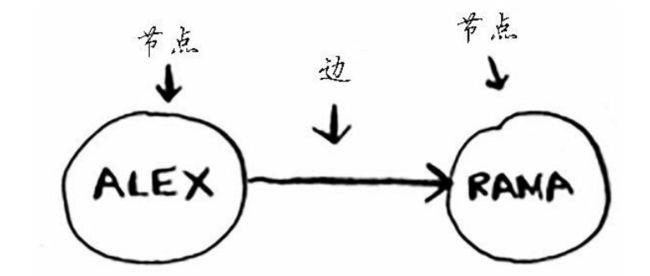
图由节点和边组成。一个节点可以由众多节点直接相连组成。这些节点被称为邻居。在前面的欠钱图中,Rama是Alex的邻居,Adit不是Alex的邻居,因为它们不直接相连,但Adit是Rama的邻居,又是Tom的邻居。
二.广度优先搜索
广度优先搜索通常用来解决两类问题:
- 从A点出发,有前往节点B的路径吗?
- 从A点出发,前往节点B的路径那条最短?
算例
本文通过算法来解决问题1。
假设你经营着一个芒果农场,需要寻找芒果销售商,以便将这些芒果卖给他。为此你可以在你的朋友中查找。
首先创建一个朋友名单,然后依次检查名单中的每一个人,看他是不是芒果销售商。

假设你的朋友没有人是芒果销售商,你必须在朋友的朋友中寻找。

检查名单中的每个人时,你都将其朋友加入名单
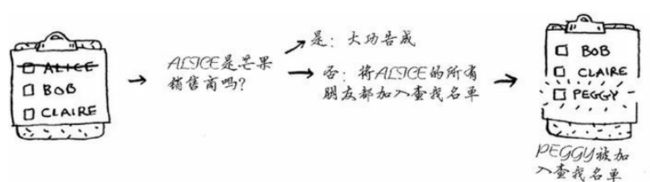
这样一来,你不仅在朋友中查找,还在朋友的朋友中查找。
上文解释了如何解决问题1,下面讲解如何通过算法来解决问题2。
谁是最近的芒果销售商,例如,朋友是一度关系,朋友的朋友是二度关系。
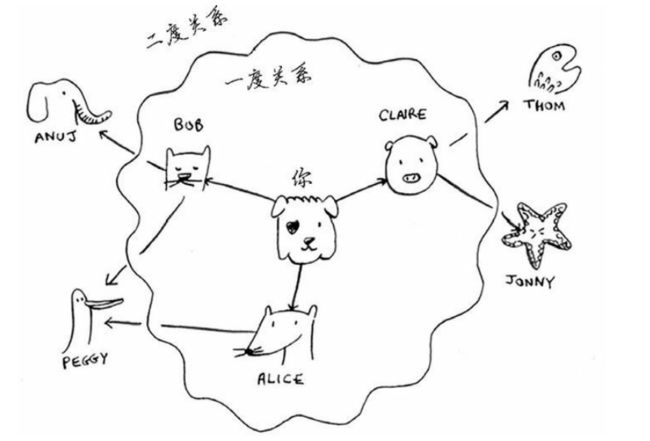
在你看来,一度关系胜过二度关系,首先在一度关系里寻找,如果没有芒果销售商,再在二度关系里寻找,以此类推。
广度优先搜索就是这样干的,首先检查一度关系,再检查二度关系。
在本题中,你可以这样理解,一度关系先于二度关系加入名单。你按顺序检查名单中的每一个人,看他是不是芒果销售商,然后再在二度关系里找。
本题需要运用到一个知识点:队列
队列是一种数据结构,具有先进先出的特点。例如排队上车,排在前面的先上车。
三.代码实现
1. 使用图来建立问题模型。
首先,需要用代码来实现图。图是有节点和邻近节点组成。来表示 [我:余登武] ,[我的邻居:小明,小白] 这种映射关系。这需要用到散列表。
散列表可以将键映射到值,在这里,将你映射到你的朋友。

python中用字典表示散列表。
graph={
}
graph['you']=["alice","bob","claire"]
更大的图

graph={
}
graph['you']=["alice","bob","claire"]
graph['bob']=["anuj","peggy"]
graph['alice']=["peggy"]
graph['claire']=["thom","jonny"]
graph['anuj']=[]
graph['peggy']=[]
graph['thom']=[]
graph['jonny']=[]
2.使用广度优先搜索解决问题
算法流程

流程中用到了队列。队列是一种数据结构,具有先进先出的特点。例如排队上车,排在前面的先上车。python中采用deque来创建一个队列。
代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu(余登武)
# @Date : 2021/1/04
#@email:[email protected]
#定义图
graph={
}
graph['you']=["alice","bob","claire"]
graph['bob']=["anuj","peggy"]
graph['alice']=["peggy"]
graph['claire']=["thom","jonny"]
graph['anuj']=[]
graph['peggy']=[]
graph['thom']=[]
graph['jonny']=[]
#检查是否是芒果销售商。如果名字最后一个字母为m就是芒果销售商
def person_is_seller(name):
return name[-1] =='m'
#
from collections import deque #导入队列
search_deque=deque()#创建一个队列
search_deque+=graph['you']
#print(search_deque) #deque(['alice', 'bob', 'claire'])
#检查部分代码
try:
while search_deque: # 只有队列不为空
find = False # 定义是否找到
person = search_deque.popleft() # 取出队列中的第一个人
if person_is_seller(person):
print(person + "是芒果销售商")
find = True
break
else:
search_deque += graph[person] # 将朋友的朋友添加进队列
finally:
if find==False:
print('没有找到')
运行结果

该段代码终止条件:
- 找到一位芒果商
- 队列变为空的,意味着你的朋友圈里没有芒果商。
代码优化
代码优化
peggy既是Alice的朋友又是Bob的朋友,因此她将被加入队列两次:一次是在添加Alice的朋友时,一次是在添加Bob的朋友时。因此搜索队列里包含了两个peggy。
我们可以只检查peggy一次,检查完一个人后,标记这个人为已检查。且不再检查他。如果不这样做,很快可能陷入死循环,如果你的朋友关系如图。

最后代码
#定义图,图中每个人的朋友关系都要写
graph={
}
graph['you']=["alice","bob","claire"]
graph['bob']=["anuj","peggy"]
graph['alice']=["peggy"]
graph['claire']=["thom","jonny"]
graph['anuj']=[]
graph['peggy']=[]
graph['thom']=[]
graph['jonny']=[]
#检查是否是芒果销售商。如果名字最后一个字母为m就是芒果销售商
def person_is_seller(name):
return name[-1] =='m'
#检查是否是芒果商代码
from collections import deque #导入队列
search_deque=deque()#创建一个队列
def search(name):
search_deque = deque() # 创建一个队列
search_deque += graph[name]#将一级关系添加进队列,即自己的朋友
searched=[]#定义是否检查
try:
while search_deque: # 只有队列不为空
find = False # 定义是否找到
person = search_deque.popleft() # 取出队列中的第一个人
if person not in searched:#如果这个人没有被检查
if person_is_seller(person):#如果这个人是芒果商
print(person + "是芒果销售商")
find = True
break
else: #如果不是芒果商
search_deque += graph[person] # 将朋友的朋友添加进队列
searched.append(person)#将这个人标记为已检查
finally:
if find == False:
print('没有找到')
search('you')
运行结果
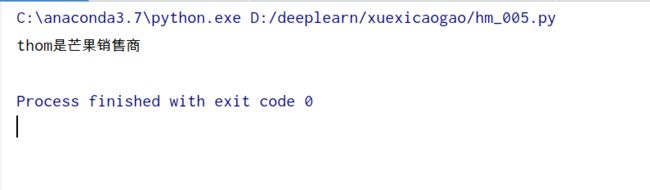
打印最短路径
在上文中,我们找到了芒果供应商是thom,我们现在需要把you到thom的关系打印出来。
我这里采用倒排表的知识来实现
假设
原始字典为
{‘问题IID’:[关键词1,关键词2…],‘问题2ID’:[关键词2,关键词3…]…}
处理后的倒排表为
{‘关键词1’:[问题1ID],‘关键词2’:[问题1ID,问题2ID…}
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu(余登武)
# @Date : 2021/1/04
#@email:[email protected]
#定义图
graph={
}
graph['you']=["alice","bob","claire"]
graph['bob']=["anuj","peggy"]
graph['alice']=["peggy"]
graph['claire']=["thom","jonny"]
graph['anuj']=[]
graph['peggy']=[]
graph['thom']=[]
graph['jonny']=[]
#所有问题组合起来的倒排表 result
result = {
}
for i in graph.keys():
left,rights=i,graph[i]
for right in rights:
if right in result.keys():
result[right].append(left)
else:
result[right] = [left]
#print(result)
#得到的结果{'alice': ['you'], 'bob': ['you'], 'claire': ['you'], 'anuj': ['bob'], 'peggy': ['bob', 'alice'], 'thom': ['claire'], 'jonny': ['claire']}
def print_searchname(name1,name2):#name1为芒果商的名字即终点,name2为起点
parent=result[name1] #终点的上一级.格式['claire']
parent=''.join(parent)#去除中括号 得到格式 claire
print('终点是{0}'.format(name1))
while True:
if parent !=name2:
print("上一级是{0}".format(parent) )
parent=result[parent]
parent = ''.join(parent)
if parent ==name2:
print('{0}的上一级是终点{1}'.format(parent,name2))
break
print_searchname('thom','you')


本文有借鉴书籍《算法图解》
作者:电气-余登武