ElasticSearch之IK中文分词
1.中文分词背景
中文分词的难点是,不能简单的按照一个个的字分隔,需要根据不一样的上下文,切分,不像英文有空格做分隔。
例如:中华人民共和国国歌
先只有默认的分词器看下效果
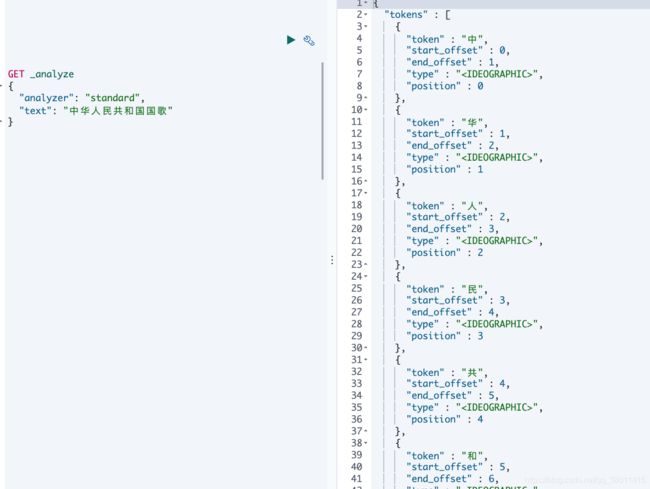
GET _analyze
{
"analyzer": "standard",
"text": "中华人民共和国国歌"
}
从下图中可以看出,完全是按照一个汉字,一个个的分词的,效果差强人意
2.安装IK中文分词器
ik分词是一款流行的elasticsearch 中文分词器,安装ik分词器版本一定要与所安装es版本一致。
官方Github地址:传送门
如果自己下载源码的话,还需要编译,可以直接下载Release版本。
分词器插件下载地址
- IK分词器Release版本
- IK分词器7.2.0
- IK分词器7.4.0
**
**注意:这里下载的时候要对照好ES的版本。
下载分词器
#在ES插件存储目录下创建 analysis-ik文件夹
mkdir -p /usr/local/elasticsearch-7.4.0/plugins/analysis-ik
#切换到插件目录下
cd /usr/local/elasticsearch-7.4.0/plugins/analysis-ik
#下载分词器
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.0/elasticsearch-analysis-ik-7.4.0.zip
unzip elasticsearch-analysis-ik-7.4.0.zip
#删除压缩包
rm -rf elasticsearch-analysis-ik-7.4.0.zip
然后重启elasticsearch
执行如下命令可以查看按照好的
GET _cat/plugins

安装步骤总结:
- 解压ik分词器安装包到plugin目录下,并删除压缩包。
- 重启elasticsearch进程即可。
注意:es集群的话,每台es都需要安装ik分词器。
3.3.使用IK中文分词器
IK中文分词器,有ik_smart 和 ik_max_word
ik_max_word 和 ik_smart 什么区别?
ik_max_word: 将文本做最细粒度的拆分,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,适合 Phrase 查询。
3.3.1ik_max_word
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
分词结果
[ 中华人民共和国,中华人民,中华,华人,人民共和国,人民,共和国,共和,国,国歌 ]

3.3.2ik_smart
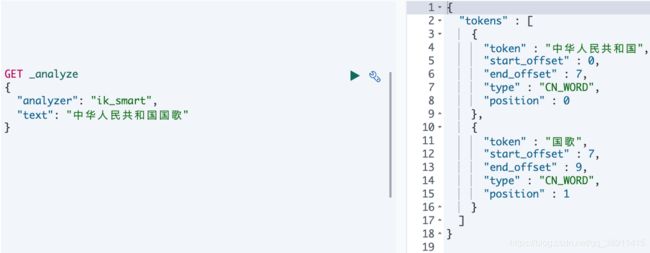
GET _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
分词结果
[ 中华人民共和国,国歌 ]
3.4.自定义字典
(1)切换到分词器插件目录下
cd /usr/local/elasticsearch-7.2.0/plugins/analysis-ik/config
(2)创建自定义文件存储目录
mkdir custom
(3)创建自定义字典文件
vi custom/custom_word.dic
比如填入自定义的字典词语
我是张三
我是李四
注:请确保扩展词典的文本格式为 UTF8 编码
(3)配置自定义字典读取路径
打开配置
vi IKAnalyzer.cfg.xml
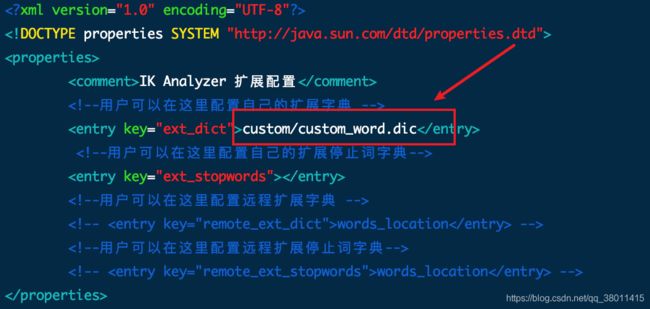
- ext_dict:对应的扩展热词词典的位置
- ext_stopwords:对应扩展停用词词典位置
- remote_ext_dict:远程扩展热词位置 如:https://xxx.xxx.xxx/remote_ext_dict.txt
- remote_ext_stopwords:远程扩展停用词位置 如:https://xxx.xxx.xxx/remote_ext_stopwords.txt
注:多个配置,可以使用";"分号间隔

(4)重启ElasticSearch
(5)测试效果
示例内容:我是张三的老师

3.5.热更新自定义字典
支持热更新 IK 分词。需要在 IKAnalyzer.cfg.xml配置中添加远程字典访问地址。
words_location
words_location
可以将需自动更新的热词放在一个UTF-8 编码的 .txt 文件里.
- 放在 nginx,或其他简易 http server
通过http server的地址替换上述配置中的words_location 参数,
words_location 是一个URL地址。配置如下图。多个地址用分号分隔。
注: 单个文件不要过大,建议不超2M ,可以配置多个。

可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt 文件。
该请求需要满足的条件
- 该 http 请求需要返回两个头部(header),一个是
Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。 - 该 http 请求返回的内容格式是一行一个分词,换行符用
\n即可
综上,满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
热key服务简单实现
/**
* IK自定义分词器,热点字典-存储目录
* /Users/mengqiang/fsdownload
* /home/devjava/ik_custom_dir
*/
private static final String EXT_DICT_PATH_PREFIX = "/home/devjava/ik_custom_dir";
/**
* IK自定义分词器,热点字典读取
*
* @param response
*/
@RequestMapping(value = "/getCustomDict/{fileName}")
public void getCustomDict(@PathVariable("fileName") String fileName, HttpServletResponse response) {
FileInputStream inputStream = null;
OutputStream outputStream = null;
BufferedReader bufferedReader = null;
try {
//文件全路径
String fileFullPath = this.getFileFullPath(fileName);
//读取字典文件
File file = new File(fileFullPath);
StringBuilder content = new StringBuilder();
int time = 0;
if (file.exists()) {
inputStream = new FileInputStream(file);
bufferedReader = new BufferedReader(new InputStreamReader(inputStream, StandardCharsets.UTF_8));
String line = null;
while ((line = bufferedReader.readLine()) != null) {
//需要加换行符
content.append(line).append("\n");
}
bufferedReader.close();
}
//内容字节长度
int contentLength = content.toString().getBytes().length;
// 返回数据
outputStream = response.getOutputStream();
response.setContentLength(contentLength);
response.setHeader("Last-Modified", String.valueOf(contentLength));
response.setHeader("ETag", String.valueOf(contentLength));
response.setContentType("text/plain; charset=utf-8");
outputStream.write(content.toString().getBytes(StandardCharsets.UTF_8));
outputStream.flush();
String requestIp = WebToolUtils.getIpAddress(request);
log.info("[{}] >> [ getCustomDict ] fileFullPath:{}, time:{}, length:{}", requestIp, fileFullPath, time, contentLength);
} catch (Exception e) {
log.error("[ getCustomDict ] exception >> ", e);
} finally {
//关闭资源
this.closeStream(inputStream, outputStream, bufferedReader);
}
}
/**
* 文件全路径
*
* @param fileName
*/
private String getFileFullPath(String fileName) {
if (StringUtils.isEmpty(fileName)) {
return "";
}
if (fileName.contains(".")) {
return EXT_DICT_PATH_PREFIX + "/" + fileName;
}
//若非.txt结尾
if (!fileName.endsWith(".txt")) {
return EXT_DICT_PATH_PREFIX + "/" + fileName.concat(".txt");
}
return EXT_DICT_PATH_PREFIX + "/" + fileName;
}
/**
* 防止异常后未关闭流
*
* @param inputStream
* @param outputStream
* @param bufferedReader
*/
private void closeStream(FileInputStream inputStream, OutputStream outputStream, BufferedReader bufferedReader) {
try {
if (null != inputStream) {
inputStream.close();
}
if (null != outputStream) {
outputStream.close();
}
if (null != bufferedReader) {
bufferedReader.close();
}
} catch (Exception e) {
log.error("[ getCustomDict ] close stream exception >> ", e);
}
}
关注程序员小强公众号更多编程趣事,知识心得与您分享
关注“程序员小强”发送关键字“elasticSearch”到公众号获取相关篇