一、资料
参考原文:
TensorFlow全新的数据读取方式:Dataset API入门教程
API接口简介:
TensorFlow的数据集
二、背景
注意,在TensorFlow 1.3中,Dataset API是放在contrib包中的:
tf.contrib.data.Dataset
而在TensorFlow 1.4中,Dataset API已经从contrib包中移除,变成了核心API的一员:
tf.data.Dataset
此前,在TensorFlow中读取数据一般有两种方法:
- 使用placeholder读内存中的数据
- 使用queue读硬盘中的数据(这种方式,可以参考原作者之前的一篇文章:十图详解TensorFlow数据读取机制)
Dataset API同时支持从内存和硬盘的读取,相比之前的两种方法在语法上更加简洁易懂。此外,如果想要用到TensorFlow新出的Eager模式,就必须要使用Dataset API来读取数据。
三、基本使用
1、一维数据集示范基本使用
Google官方给出的Dataset API中的类图:
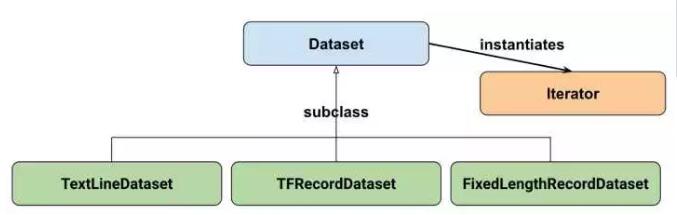
在初学时,我们只需要关注两个最重要的基础类:Dataset和Iterator。
Dataset可以看作是相同类型“元素”的有序列表。在实际使用时,单个“元素”可以是向量,也可以是字符串、图片,甚至是tuple或者dict。
数据集对象实例化:
dataset = tf.data.Dataset.from_tensor_slices(数据)
迭代器对象实例化(非Eager模式下):
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
综合起来效果如下,
import tensorflow as tf
import numpy as np
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0]))
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
for i in range(5):
print(sess.run(one_element))
输出:1.0 2.0 3.0 4.0 5.0
读取结束异常:
如果一个dataset中元素被读取完了,再尝试sess.run(one_element)的话,就会抛出tf.errors.OutOfRangeError异常,这个行为与使用队列方式读取数据的行为是一致的。
在实际程序中,可以在外界捕捉这个异常以判断数据是否读取完,综合以上三点请参考下面的代码:
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0]))
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session(config=config) as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
输出:1.0 2.0 3.0 4.0 5.0 end!
2、高维数据集使用
tf.data.Dataset.from_tensor_slices真正作用是切分传入Tensor的第一个维度,生成相应的dataset,即第一维表明数据集中数据的数量,之后切分batch等操作都以第一维为基础。
dataset = tf.data.Dataset.from_tensor_slices(np.random.uniform(size=(5, 2)))
传入的数值是一个矩阵,它的形状为(5, 2),tf.data.Dataset.from_tensor_slices就会切分它形状上的第一个维度,最后生成的dataset中一个含有5个元素,每个元素的形状是(2, ),即每个元素是矩阵的一行。
dataset = tf.data.Dataset.from_tensor_slices(np.random.uniform(size=(5, 2)))
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session(config=config) as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
[0.09787406 0.71672957] [0.25681324 0.81974072] [0.35186046 0.39362398] [0.75228199 0.6534702 ] [0.39695169 0.9341708 ] end!
3、字典使用
在实际使用中,我们可能还希望Dataset中的每个元素具有更复杂的形式,如每个元素是一个Python中的元组,或是Python中的词典。例如,在图像识别问题中,一个元素可以是{“image”: image_tensor, “label”: label_tensor}的形式,这样处理起来更方便,
注意,image_tensor、label_tensor和上面的高维向量一致,第一维表示数据集中数据的数量。相较之下,字典中每一个key值可以看做数据的一个属性,value则存储了所有数据的该属性值。
dataset = tf.data.Dataset.from_tensor_slices(
{
"a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]),
"b": np.random.uniform(size=(5, 2))
})
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session(config=config) as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
4、复杂的tuple组合数据
类似的,可以使用组合的特征进行拼接,
dataset = tf.data.Dataset.from_tensor_slices(
(np.array([1.0, 2.0, 3.0, 4.0, 5.0]), np.random.uniform(size=(5, 2)))
)
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session(config=config) as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
四、数据集处理方法
Dataset支持一类特殊的操作:Transformation。一个Dataset通过Transformation变成一个新的Dataset。通常我们可以通过Transformation完成数据变换,打乱,组成batch,生成epoch等一系列操作。
常用的Transformation有:
- map
- batch
- shuffle
- repeat
map
和python中的map类似,map接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset,
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0]))
dataset = dataset.map(lambda x: x + 1) # <-----
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session(config=config) as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
输出:2.0 3.0 4.0 5.0 6.0 end!
注意map函数可以使用num_parallel_calls参数加速(第五部分有介绍)。
batch
batch就是将多个元素组合成batch,如上所说,按照输入元素第一个维度,
dataset = tf.data.Dataset.from_tensor_slices(
{
"a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]),
"b": np.random.uniform(size=(5, 2))
})
dataset = dataset.batch(2) # <-----
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session(config=config) as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
{'a': array([1., 2.]), 'b': array([[0.87466134, 0.21519021], [0.6123372 , 0.95722733]])}
{'a': array([3., 4.]), 'b': array([[0.76964374, 0.22445015], [0.08313089, 0.60531841]])}
{'a': array([5.]), 'b': array([[0.37901654, 0.3955096 ]])}
end!
shuffle
shuffle的功能为打乱dataset中的元素,它有一个参数buffersize,表示打乱时使用的buffer的大小,建议舍的不要太小,一般是1000:
dataset = tf.data.Dataset.from_tensor_slices(
{
"a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]),
"b": np.random.uniform(size=(5, 2))
})
dataset = dataset.shuffle(buffer_size=5) # <-----
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session(config=config) as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
repeat
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(2)就可以将之变成2个epoch:
dataset = tf.data.Dataset.from_tensor_slices(
{
"a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]),
"b": np.random.uniform(size=(5, 2))
})
dataset = dataset.repeat(2) # <-----
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session(config=config) as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
{'a': 1.0, 'b': array([0.85180201, 0.1703507 ])}
{'a': 2.0, 'b': array([0.37874819, 0.81303628])}
{'a': 3.0, 'b': array([0.99560094, 0.56446562])}
{'a': 4.0, 'b': array([0.86341794, 0.69984075])}
{'a': 5.0, 'b': array([0.85026424, 0.74761098])}
{'a': 1.0, 'b': array([0.85180201, 0.1703507 ])}
{'a': 2.0, 'b': array([0.37874819, 0.81303628])}
{'a': 3.0, 'b': array([0.99560094, 0.56446562])}
{'a': 4.0, 'b': array([0.86341794, 0.69984075])}
{'a': 5.0, 'b': array([0.85026424, 0.74761098])}
end!
注意,如果直接调用repeat()的话,生成的序列就会无限重复下去,没有结束,因此也不会抛出tf.errors.OutOfRangeError异常。
五、模拟读入磁盘图片与对应label
考虑一个简单,但同时也非常常用的例子:读入磁盘中的图片和图片相应的label,并将其打乱,组成batch_size=32的训练样本,在训练时重复10个epoch
# 函数的功能时将filename对应的图片文件读进来,并缩放到统一的大小
def _parse_function(filename, label):
image_string = tf.read_file(filename)
image_decoded = tf.image.decode_image(image_string)
image_resized = tf.image.resize_images(image_decoded, [28, 28])
return image_resized, label
# 图片文件的列表
filenames = tf.constant(["/var/data/image1.jpg", "/var/data/image2.jpg", ...])
# label[i]就是图片filenames[i]的label
labels = tf.constant([0, 37, ...])
# 此时dataset中的一个元素是(filename, label)
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
# 此时dataset中的一个元素是(image_resized, label)
dataset = dataset.map(_parse_function)
# 此时dataset中的一个元素是(image_resized_batch, label_batch)
dataset = dataset.shuffle(buffersize=1000).batch(32).repeat(10)
在这个过程中,dataset经历三次转变:
- 运行dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))后,dataset的一个元素是(filename, label)。filename是图片的文件名,label是图片对应的标签。
- 之后通过map,将filename对应的图片读入,并缩放为28x28的大小。此时dataset中的一个元素是(image_resized, label)
-
最后,dataset.shuffle(buffersize=1000).batch(32).repeat(10)的功能是:在每个epoch内将图片打乱组成大小为32的batch,并重复10次。最终,dataset中的一个元素是(image_resized_batch, label_batch),image_resized_batch的形状为(32, 28, 28, 3),而label_batch的形状为(32, ),接下来我们就可以用这两个Tensor来建立模型了。
help(tf.data.Dataset.map)
可见:
Help on function map in module tensorflow.python.data.ops.dataset_ops:
map(self, map_func, num_parallel_calls=None)
Maps `map_func` across this datset.
Args:
map_func: A function mapping a nested structure of tensors (having
shapes and types defined by `self.output_shapes` and
`self.output_types`) to another nested structure of tensors.
num_parallel_calls: (Optional.) A `tf.int32` scalar `tf.Tensor`,
representing the number elements to process in parallel. If not
specified, elements will be processed sequentially.
Returns:
A `Dataset`.
由此可见map作为读取处理的关键步骤,是可以多线程加速的。
六、更多的Dataset创建方法
除了tf.data.Dataset.from_tensor_slices外,目前Dataset API还提供了另外三种创建Dataset的方式:
- tf.data.TextLineDataset():这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件。
- tf.data.FixedLengthRecordDataset():这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。
- tf.data.TFRecordDataset():顾名思义,这个函数是用来读TFRecord文件的,dataset中的每一个元素就是一个TFExample。
它们的详细使用方法可以参阅文档:Module: tf.data
七、更多的Iterator创建方法
在非Eager模式下,最简单的创建Iterator的方法就是通过dataset.make_one_shot_iterator()来创建一个one shot iterator。
除了这种one shot iterator外,还有三个更复杂的Iterator,即:
- initializable iterator
- reinitializable iterator
- feedable iterator
initializable iterator方法要在使用前通过sess.run()来初始化,使用initializable iterator,可以将placeholder代入Iterator中,实现更为灵活的数据载入,实际上占位符引入了dataset对象创建中,我们可以通过feed来控制数据集合的实际情况。
limit = tf.placeholder(dtype=tf.int32, shape=[])
dataset = tf.data.Dataset.from_tensor_slices(tf.range(start=0, limit=limit))
iterator = dataset.make_initializable_iterator()
next_element = iterator.get_next()
with tf.Session() as sess:
sess.run(iterator.initializer, feed_dict={limit: 10})
for i in range(10):
value = sess.run(next_element)
print(value)
assert i == value
输出:0 1 2 3 4 5 6 7 8 9
initializable iterator还有一个功能:读入较大的数组。
在使用tf.data.Dataset.from_tensor_slices(array)时,实际上发生的事情是将array作为一个tf.constants保存到了计算图中。当array很大时,会导致计算图变得很大,给传输、保存带来不便。这时,我们可以用一个placeholder取代这里的array,并使用initializable iterator,只在需要时将array传进去,这样就可以避免把大数组保存在图里,示例代码为(来自官方例程):
# 从硬盘中读入两个Numpy数组
with np.load("/var/data/training_data.npy") as data:
features = data["features"]
labels = data["labels"]
features_placeholder = tf.placeholder(features.dtype, features.shape)
labels_placeholder = tf.placeholder(labels.dtype, labels.shape)
dataset = tf.data.Dataset.from_tensor_slices((features_placeholder, labels_placeholder))
iterator = dataset.make_initializable_iterator()
sess.run(iterator.initializer, feed_dict={features_placeholder: features,
labels_placeholder: labels})
可见,在上面程序中,feed也遵循着类似字典一样的规则,创建两个占位符(keys),给data_holder去feed数据文件,给label_holder去feed标签文件。
reinitializable iterator和feedable iterator相比initializable iterator更复杂,也更加少用,如果想要了解它们的功能,可以参阅官方介绍,这里就不再赘述了。
八、总结
在非Eager模式下,Dataset中读出的一个元素一般对应一个batch的Tensor,我们可以使用这个Tensor在计算图中构建模型。
在Eager模式下,Dataset建立Iterator的方式有所不同,此时通过读出的数据就是含有值的Tensor,方便调试。