PyTorch可视化模型结构
1、torchviz
代码:
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torchviz
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.dropout = nn.Dropout2d(p=0.1)
self.adaptive_pool = nn.AdaptiveMaxPool2d((1, 1))
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(64, 32)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.dropout(x)
x = self.adaptive_pool(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
y = self.sigmoid(x)
return y
net = Net()
x = torch.rand(1, 3, 32, 32)
y = net(x)
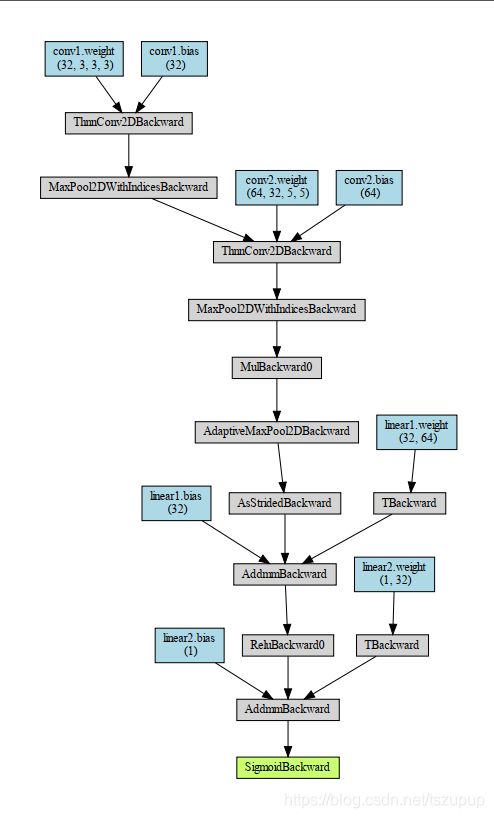
g = torchviz.make_dot(y, params=dict(net.named_parameters()))
g.view()效果:
2、torchsummary
代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # PyTorch v0.4.0
model = Net().to(device)
summary(model, (1, 28, 28))效果:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 10, 24, 24] 260
Conv2d-2 [-1, 20, 8, 8] 5,020
Dropout2d-3 [-1, 20, 8, 8] 0
Linear-4 [-1, 50] 16,050
Linear-5 [-1, 10] 510
================================================================
Total params: 21,840
Trainable params: 21,840
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.06
Params size (MB): 0.08
Estimated Total Size (MB): 0.15
----------------------------------------------------------------3、torchkeras
代码:
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torchkeras import Model,summary
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5)
self.dropout = nn.Dropout2d(p=0.1)
self.adaptive_pool = nn.AdaptiveMaxPool2d((1, 1))
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(64, 32)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
x = self.pool(x)
x = self.dropout(x)
x = self.adaptive_pool(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
y = self.sigmoid(x)
return y
net = Net()
print(net)
summary(net,input_shape= (3,32,32))效果:
Net(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(adaptive_pool): AdaptiveMaxPool2d(output_size=(1, 1))
(flatten): Flatten()
(linear1): Linear(in_features=64, out_features=32, bias=True)
(relu): ReLU()
(linear2): Linear(in_features=32, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 30, 30] 896
MaxPool2d-2 [-1, 32, 15, 15] 0
Conv2d-3 [-1, 64, 11, 11] 51,264
MaxPool2d-4 [-1, 64, 5, 5] 0
Dropout2d-5 [-1, 64, 5, 5] 0
AdaptiveMaxPool2d-6 [-1, 64, 1, 1] 0
Flatten-7 [-1, 64] 0
Linear-8 [-1, 32] 2,080
ReLU-9 [-1, 32] 0
Linear-10 [-1, 1] 33
Sigmoid-11 [-1, 1] 0
================================================================
Total params: 54,273
Trainable params: 54,273
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.011719
Forward/backward pass size (MB): 0.359634
Params size (MB): 0.207035
Estimated Total Size (MB): 0.578388
----------------------------------------------------------------