信息抽取实战:命名实体识别NER【ALBERT+Bi-LSTM模型 vs. ALBERT+Bi-LSTM+CRF模型】(附代码)
实战:命名实体识别NER
目录
- 实战:命名实体识别NER
-
- 一、命名实体识别(NER)
- 二、BERT的应用
-
- NLP基本任务
- 查找相似词语
- 提取文本中的实体
- 问答中的实体对齐
- 三、ALBERT
-
- ALBERT 的三大改造
- ALBERT 效果如何
- 总结
- 四、ALBERT+Bi-LSTM模型
- 五、ALBERT+Bi-LSTM+CRF模型
-
- 思考
一、命名实体识别(NER)
本项目将会简单介绍自然语言处理(NLP)中的命名实体识别(NER)。
命名实体识别(Named Entity Recognition,简称NER)是信息抽取、问答系统、句法分析、机器翻译等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要地位。一般来说,命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
举个简单的例子,在句子“小明早上8点去学校上课。”中,对其进行命名实体识别,应该能提取信息
人名:小明,时间:早上8点,地点:学校。
二、BERT的应用
BERT是谷歌公司于2018年11月发布的一款新模型,它一种预训练语言表示的方法,在大量文本语料(维基百科)上训练了一个通用的“语言理解”模型,然后用这个模型去执行想做的NLP任务。一经公布,它便引爆了整个NLP界,其在11个主流NLP任务中都取得优异的结果,因此成为NLP领域最吸引人的一个模型。简单来说,BERT就是在训练了大量的文本语料(无监督)之后,能够在对英语中的单词(或中文的汉字)给出一个向量表示,使得该单词(或汉字)具有一定的语义表示能力,因此,BERT具有一定的先验知识,在NLP任务中表现十分抢眼。
给出BERT的几个可能的应用,如下:
- NLP基本任务
- 查找相似词语
- 提取文本中的实体
- 问答中的实体对齐
NLP基本任务
BERT公布已经半年多了,现在已经成为NLP中的深度学习模型中必不可少的工具,一般会加载在模型中的Embedding层。由于篇幅原因,笔者不再介绍自己的BERT项目,而是介绍几个BERT在基本任务中的Github项目:
- 英语文本分类: BERT-Classification-Tutorial
- 中文情感分类: BERT_Chinese_Classification
- 中文命名实体识别(NER): bertNER
可以看到,BERT已经广泛应用于NLP基本任务中,在开源项目中导出可以见到它的身影,并且这些项目的作者也写了非常细致的代码工程,便于上手。
查找相似词语
利用词向量可以查找文章中与指定词语最相近的几个词语。具体的做法为:现将文章分词,对分词后的每个词,查询其与指定词语的相似度,最后按相似度输出词语即可。
提取文本中的实体
在事件抽取中,我们往往需要抽取一些指定的元素,比如在下面的句子中,
巴基斯坦当地时间2014年12月16日早晨,巴基斯坦塔利班运动武装分子袭击了西北部白沙瓦市一所军人子弟学校,打死141人,其中132人为12岁至16岁的学生。
我们需要抽取袭击者,也就是恐怖组织这个元素。
直接从句法分析,也许可以得到一定的效果,但由于事件描述方式多变,句法分析会显得比较复杂且效果不一定能保证。这时候,我们尝试BERT词向量,它在一定程度上可以作为补充策略,帮助我们定位到事件的元素。具体的想法如下:
- 指定事件元素模板
- 句子分词,对词语做n-gram
- 查询每个n-gram与模板的相似度
- 按相似度对n-gram排序,取相似度最高的n-gram
问答中的实体对齐
在智能问答中,我们往往会采用知识图谱或者数据库存储实体,其中一个难点就是实体对齐。举个例子,我们在数据库中储存的实体如下:
(entities.txt)
094型/晋级
052C型(旅洋Ⅱ级)
辽宁舰/瓦良格/Varyag
杰拉尔德·R·福特号航空母舰
052D型(旅洋III级)
054A型
CVN-72/林肯号/Lincoln
这样的实体名字很复杂,如果用户想查询实体“辽宁舰”,就会碰到困难,但是由于实体以储存在数据库或知识图谱中,实体不好直接修改。一种办法是通过关键字匹配定位实体,在这里,我们可以借助BERT词向量来实现。
三、ALBERT
ALBERT 通过两个参数削减技术克服了扩展预训练模型面临的主要障碍。第一个技术是对嵌入参数化进行因式分解。研究者将大的词汇嵌入矩阵分解为两个小的矩阵,从而将隐藏层的大小与词汇嵌入的大小分离开来。这种分离使得隐藏层的增加更加容易,同时不显著增加词汇嵌入的参数量。
第二种技术是跨层参数共享。这一技术可以避免参数量随着网络深度的增加而增加。两种技术都显著降低了 BERT 的参数量,同时不对其性能造成明显影响,从而提升了参数效率。ALBERT 的配置类似于 BERT-large,但参数量仅为后者的 1/18,训练速度却是后者的 1.7 倍。这些参数削减技术还可以充当某种形式的正则化,可以使训练更加稳定,而且有利于泛化。
为了进一步提升 ALBERT 的性能,研究者还引入了一个自监督损失函数,用于句子级别的预测(SOP)。SOP 主要聚焦于句间连贯,用于解决原版 BERT 中下一句预测(NSP)损失低效的问题。
基于这些设计,ALBERT 能够扩展为更大的版本,参数量仍然小于 BERT-large,但性能可以显著提升。研究者在知名的 GLUE、SQuAD 和 RACE 自然语言理解基准测试上都得到了新的 SOTA 结果:在 RACE 上的准确率为 89.4%,在 GLUE 上的得分为 89.4,在 SQuAD 2.0 上的 F1 得分为 92.2。
ALBERT 的三大改造
前面已经展示了小模型的优势,以及 ALBERT 的核心思想,那么 ALBERT 具体结构又是怎么样的。在这一部分中,我们将简要介绍 ALBERT 的三大模块,并提供与标准 BERT 的量化对比。
ALBERT 架构的骨干网络与 BERT 是相似的,即使用 Transformer 编码器和 GELU 非线性激活函数。现在先约定一下 BERT 的表示方式,即指定词嵌入大小为 E、编码器层数为 L、隐藏层大小为 H。与 Devlin 等人的研究一样,这篇论文将前馈网络/滤波器大小设置为 4H,将注意力 Head 的数量设置为 H/64。
如下将介绍 ALBERT 最为独特的三大结果。
(1)嵌入向量参数化的因式分解
在 BERT 以及后续的 XLNet 和 RoBERTa 中,WordPiece 词嵌入大小 E 和隐藏层大小 H 是相等的,即 E ≡ H。由于建模和实际使用的原因,这个决策看起来可能并不是最优的。
从建模的角度来说,WordPiece 词嵌入的目标是学习上下文无关的表示,而隐藏层嵌入的目标是学习上下文相关的表示。通过上下文相关的实验,BERT 的表征能力很大一部分来自于使用上下文为学习过程提供上下文相关的表征信号。因此,将 WordPiece 词嵌入大小 E 从隐藏层大小 H 分离出来,可以更高效地利用总体的模型参数,其中 H 要远远大于 E。
从实践的角度,自然语言处理使用的词典大小 V 非常庞大,如果 E 恒等于 H,那么增加 H 将直接加大嵌入矩阵的大小,这种增加还会通过 V 进行放大。
因此,对于 ALBERT 而言,研究者对词嵌入参数进行了因式分解,将它们分解为两个小矩阵。研究者不再将 one-hot 向量直接映射到大小为 H 的隐藏空间,而是先将它们映射到一个低维词嵌入空间 E,然后再映射到隐藏空间。通过这种分解,研究者可以将词嵌入参数从 O(V × H) 降低到 O(V × E + E × H),这在 H 远远大于 E 的时候,参数量减少得非常明显。
(2)跨层参数共享
对于 ALBERT,研究者提出了另一种跨层参数共享机制来进一步提升参数效率。其实目前有很多方式来共享参数,例如只贡献前馈网络不同层之间的参数,或者只贡献注意力机制的参数,而 ALBERT 采用的是贡献所有层的所有参数。
这种机制之前也是有的,但研究者的度量发现词嵌入的 L2 距离和余弦相似性是震荡而不是收敛。
研究者发现 ALBERT 从一层到另一层的转换要比 BERT 平滑得多,结果表明,权重共享有效地提升了神经网络参数的鲁棒性。即使相比于 BERT 这两个指标都有所下降,但在 24 层以后,它们也不会收敛到 0。
(3)句间连贯性损失
除了自编码语言建模损失外,BERT 还是用了额外的下一句预测损失。下一句预测损失本来是为了提升下游任务的性能,但是后来很多研究者发现这种机制并不是很高效,因此决定去除它。
研究者猜测,下一句预测任务低效的原因,主要是它的难度太小。因为下一句预测将主题预测和连贯性预测结合到单个任务中,然而主题预测比连贯性预测简单得多,因此它与语言建模损失函数学到的内容是有重合的。
研究者表示,句间建模在语言理解中是非常重要的,因此他们提出了一种基于语言连贯性的损失函数。对于 ALBERT,研究者使用了一个句子顺序预测(SOP)损失函数,它会避免预测主题,而只关注建模句子之间的连贯性。
具体的损失函数表达式读者可以查阅原论文,但研究者表示,在使用了该损失函数后,ALBERT 能显著提升下游多句子编码任务的性能。
ALBERT 效果如何
为了进行更公平的对比,研究者在原始 BERT 的配置下训练试验模型效果。研究者使用了 BOOKCORPUS 和 English Wikipedia 共计 16GB 的纯文本作为预训练任务的数据。它们在 Cloud TPU V3 上训练所有的模型,TPU 数量从 64 到 1024 会根据模型大小进行选择。
总结
在初闻ALBERT时,以为其减少了总的运算量,但实际上是通过参数共享的方式降低了内存,预测阶段还是需要和BERT一样的时间,如果采用了xxlarge版本的ALBERT,那实际上预测速度会更慢。
ALBERT解决的是训练时候的速度提升,如果要真的做到总体运算量的减少,的确是一个复杂且艰巨的任务,毕竟鱼与熊掌不可兼得。不过话说回来,ALBERT也更加适合采用feature base或者模型蒸馏等方式来提升最终效果。
ALBERT作者最后也简单提了下后续可能的优化方案,例如采用sparse attention或者block attention,这些方案的确是能真正降低运算量。其次,作者认为还有更多维度的特征需要去采用其他的自监督任务来捕获。
四、ALBERT+Bi-LSTM模型
本项目将会介绍如何利用ALBERT来实现命名实体识别。
本项目的项目结构如下:

其中,albert_zh为ALBERT提取文本特征模块,这方面的代码已经由别人开源,我们只需要拿来使用即可。data目录下为我们本次讲解所需要的数据,图中只有example开头的数据集,这是人民日报的标注语料,实体为人名(PER)、地名(LOC)和组织机构名(ORG)。数据集一行一个字符以及标注符号,标注系统采用BIO系统,我们以example.train的第一句为例,标注信息如下:
海 O
钓 O
比 O
赛 O
地 O
点 O
在 O
厦 B-LOC
门 I-LOC
与 O
金 B-LOC
门 I-LOC
之 O
间O
的 O
海 O
域 O
。 O
在utils.py文件中,配置了一些关于文件路径和模型参数方面的信息,其中规定了输入的文本长度最大为128,代码如下:
# -*- coding: utf-8 -*-
# 数据相关的配置
event_type = "example"
train_file_path = "./data/%s.train" % event_type
dev_file_path = "./data/%s.dev" % event_type
test_file_path = "./data/%s.test" % event_type
# 模型相关的配置
MAX_SEQ_LEN = 128 # 输入的文本最大长度
在load_data.py文件中,我们将处理训练集、验证集和测试集数据,并将标签转换为id,形成label2id.json文件,代码如下:
# -*- coding: utf-8 -*-
import json
from utils import train_file_path, event_type
# 读取数据集
def read_data(file_path):
# 读取数据集
with open(file_path, "r", encoding="utf-8") as f:
content = [_.strip() for _ in f.readlines()]
# 添加原文句子以及该句子的标签
# 读取空行所在的行号
index = [-1]
index.extend([i for i, _ in enumerate(content) if ' ' not in _])
index.append(len(content))
# 按空行分割,读取原文句子及标注序列
sentences, tags = [], []
for j in range(len(index)-1):
sent, tag = [], []
segment = content[index[j]+1: index[j+1]]
for line in segment:
sent.append(line.split()[0])
tag.append(line.split()[-1])
sentences.append(''.join(sent))
tags.append(tag)
# 去除空的句子及标注序列,一般放在末尾
sentences = [_ for _ in sentences if _]
tags = [_ for _ in tags if _]
return sentences, tags
# 读取训练集数据
# 将标签转换成id
def label2id():
train_sents, train_tags = read_data(train_file_path)
# 标签转换成id,并保存成文件
unique_tags = []
for seq in train_tags:
for _ in seq:
if _ not in unique_tags:
unique_tags.append(_)
label_id_dict = dict(zip(unique_tags, range(1, len(unique_tags) + 1)))
with open("%s_label2id.json" % event_type, "w", encoding="utf-8") as g:
g.write(json.dumps(label_id_dict, ensure_ascii=False, indent=2))
if __name__ == '__main__':
label2id()
运行代码,生成的example_label2id.json文件如下:
{
“O”: 1,
“B-LOC”: 2,
“I-LOC”: 3,
“B-PER”: 4,
“I-PER”: 5,
“B-ORG”: 6,
“I-ORG”: 7
}
生成该文件是为了方便我们后边的模型训练和预测的时候调用。
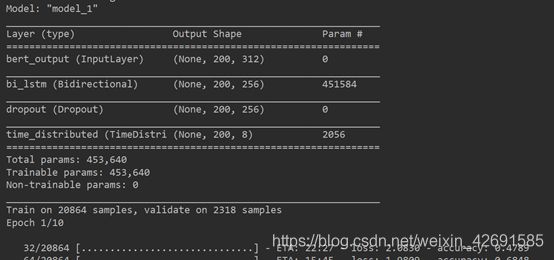
接着就是最重要的模型训练部分了,模型的结构图如下:

我们采用ALBERT作为文本特征提取,后接经典的序列标注算法——Bi-LSTM算法。albert_model_train.py的完整代码如下:
# -*- coding: utf-8 -*-
import json
import numpy as np
from keras.models import Model, Input
from keras.layers import Dense, Bidirectional, Dropout, LSTM, TimeDistributed, Masking
from keras.utils import to_categorical, plot_model
from seqeval.metrics import classification_report
import matplotlib.pyplot as plt
from utils import event_type
from utils import MAX_SEQ_LEN, train_file_path, test_file_path, dev_file_path
from load_data import read_data
from albert_zh.extract_feature import BertVector
# 利用ALBERT提取文本特征
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=MAX_SEQ_LEN)
f = lambda text: bert_model.encode([text])["encodes"][0]
# 读取label2id字典
with open("%s_label2id.json" % event_type, "r", encoding="utf-8") as h:
label_id_dict = json.loads(h.read())
id_label_dict = {
v:k for k,v in label_id_dict.items()}
# 载入数据
def input_data(file_path):
sentences, tags = read_data(file_path)
print("sentences length: %s " % len(sentences))
print("last sentence: ", sentences[-1])
# ALBERT ERCODING
print("start ALBERT encding")
x = np.array([f(sent) for sent in sentences])
print("end ALBERT encoding")
# 对y值统一长度为MAX_SEQ_LEN
new_y = []
for seq in tags:
num_tag = [label_id_dict[_] for _ in seq]
if len(seq) < MAX_SEQ_LEN:
num_tag = num_tag + [0] * (MAX_SEQ_LEN-len(seq))
else:
num_tag = num_tag[: MAX_SEQ_LEN]
new_y.append(num_tag)
# 将y中的元素编码成ont-hot encoding
y = np.empty(shape=(len(tags), MAX_SEQ_LEN, len(label_id_dict.keys())+1))
for i, seq in enumerate(new_y):
y[i, :, :] = to_categorical(seq, num_classes=len(label_id_dict.keys())+1)
return x, y
# Build model
def build_model(max_para_length, n_tags):
# Bert Embeddings
bert_output = Input(shape=(max_para_length, 312, ), name="bert_output")
# LSTM model
lstm = Bidirectional(LSTM(units=128, return_sequences=True), name="bi_lstm")(bert_output)
drop = Dropout(0.1, name="dropout")(lstm)
out = TimeDistributed(Dense(n_tags, activation="softmax"), name="time_distributed")(drop)
model = Model(inputs=bert_output, outputs=out)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 模型结构总结
model.summary()
plot_model(model, to_file="albert_bi_lstm.png", show_shapes=True)
return model
# 模型训练
def train_model():
# 读取训练集,验证集和测试集数据
train_x, train_y = input_data(train_file_path)
dev_x, dev_y = input_data(dev_file_path)
test_x, test_y = input_data(test_file_path)
# 模型训练
model = build_model(MAX_SEQ_LEN, len(label_id_dict.keys())+1)
history = model.fit(train_x, train_y, validation_data=(dev_x, dev_y), batch_size=32, epochs=10)
model.save("%s_ner.h5" % event_type)
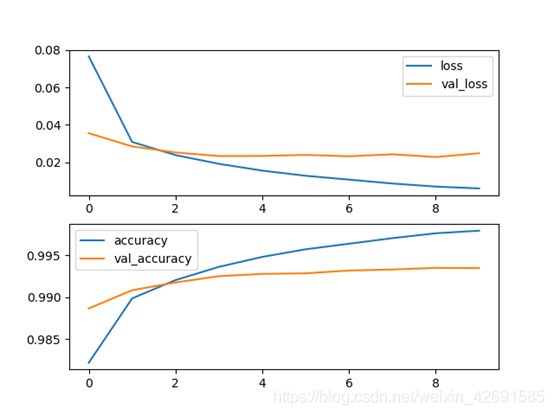
# 绘制loss和acc图像
plt.subplot(2, 1, 1)
epochs = len(history.history['loss'])
plt.plot(range(epochs), history.history['loss'], label='loss')
plt.plot(range(epochs), history.history['val_loss'], label='val_loss')
plt.legend()
plt.subplot(2, 1, 2)
epochs = len(history.history['acc'])
plt.plot(range(epochs), history.history['acc'], label='acc')
plt.plot(range(epochs), history.history['val_acc'], label='val_acc')
plt.legend()
plt.savefig("%s_loss_acc.png" % event_type)
# 模型在测试集上的表现
# 预测标签
y = np.argmax(model.predict(test_x), axis=2)
pred_tags = []
for i in range(y.shape[0]):
pred_tags.append([id_label_dict[_] for _ in y[i] if _])
# 因为存在预测的标签长度与原来的标注长度不一致的情况,因此需要调整预测的标签
test_sents, test_tags = read_data(test_file_path)
final_tags = []
for test_tag, pred_tag in zip(test_tags, pred_tags):
if len(test_tag) == len(pred_tag):
final_tags.append(test_tag)
elif len(test_tag) < len(pred_tag):
final_tags.append(pred_tag[:len(test_tag)])
else:
final_tags.append(pred_tag + ['O'] * (len(test_tag) - len(pred_tag)))
# 利用seqeval对测试集进行验证
print(classification_report(test_tags, final_tags, digits=4))
if __name__ == '__main__':
train_model()
模型训练过程中的输出结果如下(部分输出省略):
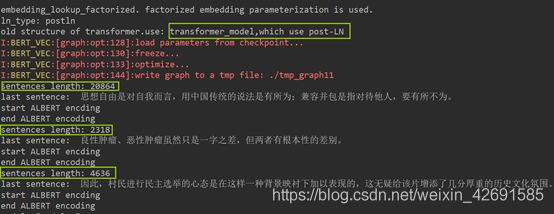
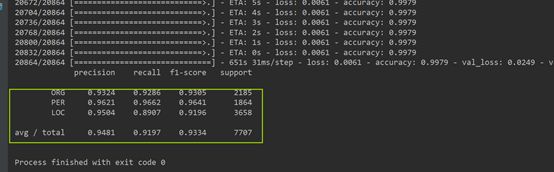
在测试集上的F1值为93.37%。同时,训练过程中的loss和acc曲线如下图:
模型预测部分的代码(脚本为model_predict.py)如下:
# -*- coding: utf-8 -*-
import json
import numpy as np
from albert_zh.extract_feature import BertVector
from keras.models import load_model
from collections import defaultdict
from pprint import pprint
from utils import MAX_SEQ_LEN, event_type
# 读取label2id字典
with open("%s_label2id.json" % event_type, "r", encoding="utf-8") as h:
label_id_dict = json.loads(h.read())
id_label_dict = {
v: k for k, v in label_id_dict.items()}
# 利用ALBERT提取文本特征
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=MAX_SEQ_LEN)
f = lambda text: bert_model.encode([text])["encodes"][0]
# 载入模型
ner_model = load_model("%s_ner.h5" % event_type)
# 从预测的标签列表中获取实体
def get_entity(sent, tags_list):
entity_dict = defaultdict(list)
i = 0
for char, tag in zip(sent, tags_list):
if 'B-' in tag:
entity = char
j = i+1
entity_type = tag.split('-')[-1]
while j < min(len(sent), len(tags_list)) and 'I-%s' % entity_type in tags_list[j]:
entity += sent[j]
j += 1
entity_dict[entity_type].append(entity)
i += 1
return dict(entity_dict)
# 输入句子,进行预测
while 1:
# 输入句子
text = input("Please enter an sentence: ").replace(' ', '')
# 利用训练好的模型进行预测
train_x = np.array([f(text)])
y = np.argmax(ner_model.predict(train_x), axis=2)
y = [id_label_dict[_] for _ in y[0] if _]
# 输出预测结果
pprint(get_entity(text, y)
随机在网上找几条新闻测试,结果如下:

本项目已经开源,Github网址为:https://github.com/chenlian-zhou/ALBERT_NER 。
五、ALBERT+Bi-LSTM+CRF模型
在本项目中,将介绍如何实现ALBERT+Bi-LSTM+CRF模型,以及在人民日报NER数据集和CLUENER数据集上的表现。
Bi-LSTM可以预测出每一个字属于不同标签的概率,然后使用 Softmax 得到概率最大的标签,作为该位置的预测值。这样在预测的时候会忽略了标签之间的关联性,即Bi-LSTM没有考虑标签间联系。
Bi-LSTM+CRF在 BiLSTM 的输出层加上一个 CRF,使得模型可以考虑类标之间的相关性,标签之间的相关性就是 CRF 中的转移矩阵,表示从一个状态转移到另一个状态的概率。
模型为ALBERT+Bi-LSTM+CRF,结构图如下:

模型训练的代码(albert_crf_model_train.py)中新增导入keras-contrib模块中的CRF层:
from keras_contrib.layers import CRF
from keras_contrib.losses import crf_loss
from keras_contrib.metrics import crf_accuracy, crf_viterbi_accuracy
模型方面的代码如下:
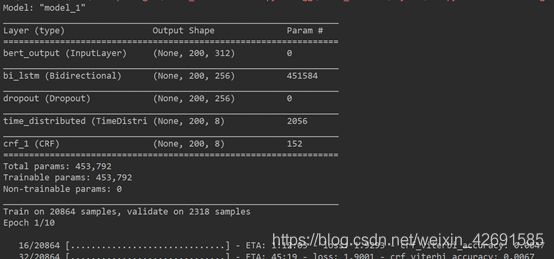
# Build model
def build_model(max_para_length, n_tags):
# Bert Embeddings
bert_output = Input(shape=(max_para_length, 312, ), name="bert_output")
# LSTM model
lstm = Bidirectional(LSTM(units=128, return_sequences=True), name="bi_lstm")(bert_output)
drop = Dropout(0.1, name="dropout")(lstm)
dense = TimeDistributed(Dense(n_tags, activation="softmax"), name="time_distributed")(drop)
crf = CRF(n_tags)
out = crf(dense)
model = Model(inputs=bert_output, outputs=out)
# model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.compile(loss=crf.loss_function, optimizer='adam', metrics=[crf.accuracy])
# 模型结构总结
model.summary()
plot_model(model, to_file="albert_bi_lstm.png", show_shapes=True)
return model
设置文本的最大长度MAX_SEQ_LEN = 128,训练10个epoch,在测试集上的F1值(利用seqeval模块评估)输出如下:
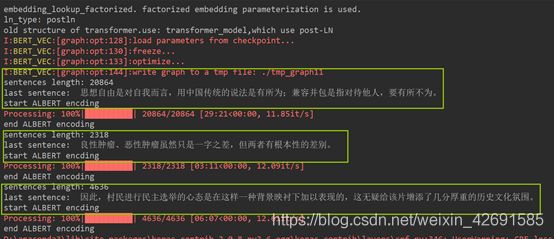

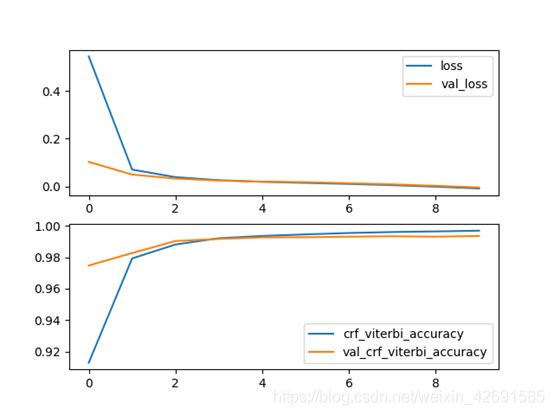
之前用ALBERT+Bi-LSTM模型得到的F1值为93.37%,而ALBERT+Bi-LSTM+CRF模型能达到72.26%,效果???
模型预测代码(model_predict.py)如下:
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-03-11 13:16
import json
import numpy as np
from keras_contrib.layers import CRF
from keras_contrib.losses import crf_loss
from keras_contrib.metrics import crf_accuracy, crf_viterbi_accuracy
from keras.models import load_model
from collections import defaultdict
from pprint import pprint
from utils import MAX_SEQ_LEN, event_type
from albert_zh.extract_feature import BertVector
# 读取label2id字典
with open("%s_label2id.json" % event_type, "r", encoding="utf-8") as h:
label_id_dict = json.loads(h.read())
id_label_dict = {
v: k for k, v in label_id_dict.items()}
# 利用ALBERT提取文本特征
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=MAX_SEQ_LEN)
f = lambda text: bert_model.encode([text])["encodes"][0]
# 载入模型
custom_objects = {
'CRF': CRF, 'crf_loss': crf_loss, 'crf_viterbi_accuracy': crf_viterbi_accuracy}
ner_model = load_model("%s_ner.h5" % event_type, custom_objects=custom_objects)
# 从预测的标签列表中获取实体
def get_entity(sent, tags_list):
entity_dict = defaultdict(list)
i = 0
for char, tag in zip(sent, tags_list):
if 'B-' in tag:
entity = char
j = i+1
entity_type = tag.split('-')[-1]
while j < min(len(sent), len(tags_list)) and 'I-%s' % entity_type in tags_list[j]:
entity += sent[j]
j += 1
entity_dict[entity_type].append(entity)
i += 1
return dict(entity_dict)
# 输入句子,进行预测
while 1:
# 输入句子
text = input("Please enter an sentence: ").replace(' ', '')
# 利用训练好的模型进行预测
train_x = np.array([f(text)])
y = np.argmax(ner_model.predict(train_x), axis=2)
y = [id_label_dict[_] for _ in y[0] if _]
# 输出预测结果
pprint(get_entity(text, y))
在网上找几条新闻,预测结果如下:

接下来我们看看该模型在CLUENER数据集上的表现。CLUENER数据集是在清华大学开源的文本分类数据集THUCTC基础上,选出部分数据进行细粒度命名实体标注,原数据来源于Sina News RSS,实体有:地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene),该数据集的介绍网站为:https://www.cluebenchmarks.com/introduce.html 。
下载数据集,用脚本将其处理成模型支持的数据格式,因为缺少test数据集,故模型评测的时候用dev数据集代替。设置模型的文本最大长度MAX_SEQ_LEN = 128,训练10个epoch,在测试集上的F1值(利用seqeval模块评估)输出如下:
sentences length: 10748
last sentence: 艺术家也讨厌画廊的老板,内心恨他们,这样的话,你是在这样的状态下,两年都是一次性合作,甚至两年、
start ALBERT encding
end ALBERT encoding
sentences length: 1343
last sentence: 另外意大利的PlayGeneration杂志也刚刚给出了92%的高分。
start ALBERT encding
end ALBERT encoding
sentences length: 1343
last sentence: 另外意大利的PlayGeneration杂志也刚刚给出了92%的高分。
start ALBERT encding
end ALBERT encoding
......
.......
precision recall f1-score support
book 0.9343 0.8421 0.8858 152
position 0.9549 0.8965 0.9248 425
government 0.9372 0.9180 0.9275 244
game 0.6968 0.6725 0.6844 287
organization 0.8836 0.8605 0.8719 344
company 0.8659 0.7760 0.8184 366
address 0.8394 0.8187 0.8289 364
movie 0.9217 0.7067 0.8000 150
name 0.8771 0.8071 0.8406 451
scene 0.9939 0.8191 0.8981 199
micro avg 0.8817 0.8172 0.8482 2982
macro avg 0.8835 0.8172 0.8482 2982
在网上找几条新闻,预测结果如下:
Please enter an sentence: 据中山外侨局消息,近日,秘鲁国会议员、祖籍中山市开发区的玛利亚·洪大女士在秘鲁国会大厦亲切会见了中山市人民政府副市长冯煜荣一行,对中山市友好代表团的来访表示热烈的欢迎。
{
'address': ['中山市开发区', '秘鲁国会大厦'],
'government': ['中山外侨局', '秘鲁国会', '中山市人民政府'],
'name': ['玛利亚·洪大', '冯煜荣'],
'position': ['议员', '副市长']}
Please enter an sentence: “隔离结束回来,发现公司不见了”,网上的段子,真发生在了昆山达鑫电子有限公司员工身上。
{
'company': ['昆山达鑫电子有限公司']}
Please enter an sentence: 由黄子韬、易烊千玺、胡冰卿、王子腾等一众青年演员主演的热血励志剧《热血同行》正在热播中。
{
'game': ['《热血同行》'], 'name': ['黄子韬', '易烊千玺', '胡冰卿', '王子腾'], 'position': ['演员']}
Please enter an sentence: 近日,由作家出版社主办的韩作荣《天生我才——李白传》新书发布会在京举行
{
'book': ['《天生我才——李白传》'], 'name': ['韩作荣'], 'organization': ['作家出版社']}
本项目已经开源,Github网址为:https://github.com/chenlian-zhou/ALBERT_NER 。
思考
之前用ALBERT+Bi-LSTM模型得到的F1值为93.37%,而ALBERT+Bi-LSTM+CRF模型能达到72.26%,效果???
BERT+BiLSTM +CRF比BiLSTM+CRF以及BERT+CRF效果好。
原因如下:
1.BERT+BiLSTM+CRF>BiLSTM+CRF
多了一层BERT初始化word embedding,比随机初始化肯定要好。
2.BERT+BiLSTM+CRF>BERT+CRF
首先BERT使用的是transformer,而transformer是基于self-attention的,也就是在计算的过程当中是弱化了位置信息的(仅靠position
embedding来告诉模型输入token的位置信息),而在序列标注任务当中位置信息是很有必要的,甚至方向信息也很有必要,所以我们需要用LSTM习得观测序列上的依赖关系,最后再用CRF习得状态序列的关系并得到答案,如果直接用CRF的话,模型在观测序列上学习力就会下降,从而导致效果不好。
15年的论文《Bidirectional LSTM-CRF Models for Sequence Tagging》。
该论文基于双向的LSTM与CRF(条件随机场)的结合,提出了一种序列标注模型Bi-LSTM-CRF。该模型在多项的序列标注任务中取得了SOA的成绩。即使如今Bert满天下的时代,在序列标注类任务中,该模型仍然存在使用的空间,并且由于双向LSTM的处理,使得对于序列标注时特征工程,词向量的依赖大大降低,模型的鲁棒性较高。以下将分三部分来介绍:1)本论文所涉及的知识点介绍;2)作者是如何提出Bi-LSTM-CRF模型的,以及该模型在各项序列标注任务上的测试成绩;3)对此论文的结论进行小结并谈谈自己的看法。
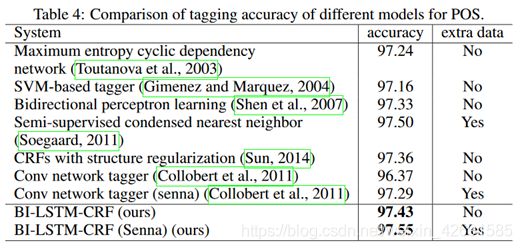
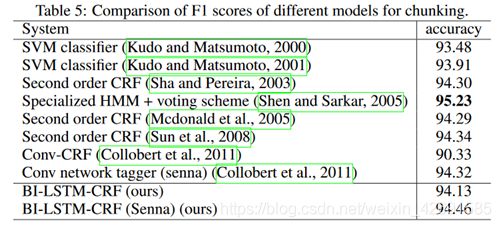
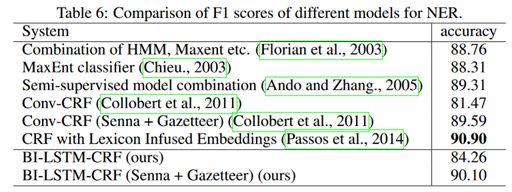
可以看到Bi-LSTM-CRF在POS中取得了SOA,Chunking和NER任务非常接近SOA的成绩。
1. 对该模型的认识
RNN和LSTM都是单向的序列模型,它假设句子当前的状态仅依赖其之前的特征。这可能会不符合实际句子语义的结构。即有些句子不仅依赖其前面的词,还依赖其后面的词(比如倒装句等)。
而在本论文作者介绍了双向LSTM和CRF。双向LSTM对句子从前往后,和从后往前进行扫描,将两个方向的扫描结果“拼接”在一起。这就记录了句子两个方向的特征信息。
CRF的情况也类似。因为CRF是一种无向图概率模型,能过记录句子中“相邻”词之间的上下文关系,并根据执行设计的score函数构建概率模型。因此CRF也能“捕获”这种句子间的上下文关系。但是CRF的这种上下文关系完全依赖于自行设计的score函数和特征工程。所以实际性能偏差会很大。
LSTM-CRF的结合就是依赖LSTM的深度神经网络处理句子的"特征工程",然后LSTM的处理结果映射到一个CRF的状态的向量空间内,而CRF通过其参数的“转移矩阵”和Viterbi算法解码,求出最合适的标注序列。整个过程结合
Bi-LSTM-CRF在15年提出以后在Bert出现之前基本是在序列标注任务中长期处于顶尖的位置。而目前来说在工业界也有非常广泛的应用。其模型相比Bert更间简单高效,性能也相不错。如果考虑模型的执行效率和性能,BI-LSTM-CRF还是有很大的使用空间。
2. 缺点
可以看到Bi-LSTM-CRF 通过其双向LSTM的结构捕获了句子中两个方向的上下文信息,但是有些句子会依赖句子间的上下文关系。而BERT能够很好的处理这种关系,因此在更加复杂的基于语义的序列标注模型任务中,Bert相比Bi-LSTM-CRF具有更好的适用性。