Ray----Tune(2):Tune的用户指南
Tune概述
本篇主要介绍Tune的使用向导,首先是Tune的运行框架(如下图),然后具体介绍实验配置信息(Training API、启动和自定义的trial)、Trailing特征(Tune的搜索空间、多次采样、GPU的使用、Trial的检测点和实验的恢复)、大数据的处理、输出结果的自动填充、日志和结果的可视化(自定义日志和自定义同步和上传命令)、Tune客户机API和Tune命令行。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GN1p39fS-1572334107360)(https://ray.readthedocs.io/en/releases-0.7.3/_images/tune-api.svg)]
Tune调度集群中进行多次实验。 每个trial都运行一个用户定义的Python函数或类,并通过Tune的Variant Generator的配置变量或用户指定的搜索算法进行参数化。 trial由实验调度员安排和管理。
关于实验调度和搜索算法请参考官网。
导包和初始化Ray
import ray
import ray.tune as tune
# 启动Ray
ray.init()
实验配置
本节将介绍修改代码以运行Tune所需的主要步骤:使用Training API并执行Tune实验。如需看实例源码,点击。
Training API
可以使用基于函数的API( the function-based API)或Trainable API进行训练。
Python函数需要具有以下签名:
def trainable(config, reporter):
"""
Args:
config (dict):搜索算法或者 variant generation.
reporter (Reporter): 报告器,Handle to report intermediate metrics to Tune.
"""
while True:
# ...
reporter(**kwargs)
上边的trainable(config, reporter)函数是一个基于函数的API,这个函数名字可以任意命令,其中参数config主要是用来训练时参数的传递,参数reporter主要是把训练标准传递给tune进行优化,报告用于调度,搜索或提前停止的指标。
Tune将在Ray actor进程中的单独线程上运行此函数。 请注意,此API不是可检查的,因为该线程永远不会将控制权返回给其调用者。
注意:如果你有一个想要训练的lambda函数,你需要先注册函数:tune.register_trainable(“lambda_id”,lambda x:...)。 然后,您可以使用lambda_id代替my_trainable。更多请参考例子tune_mnist_keras 中的train_mnist函数或者hyperopt_example.py中的easy_objective函数。
传递给Tune的Python类需要子类ray.tune.Trainable,Trainable接口链接。除报告的指标外,Trainable和基于函数的API都具有自动填充指标。
基于类的calss-based API
class MyClass(Trainable):
def _setup(self):
self.saver = tf.train.Saver()
self.sess = ...
self.iteration = 0
def _train(self):
self.sess.run(...)
self.iteration += 1
def _save(self, checkpoint_dir):
return self.saver.save(
self.sess, checkpoint_dir + "/save",
global_step=self.iteration)
def _restore(self, path):
return self.saver.restore(self.sess, path)
Training的类MyClass(Trainable)是基于类的Training API,类名可以任意的取,其中参数Trainable是ray.tune封装好的类,其中有函数_setup(),_train(),_save(checkpoint_dir),_restore(path)是封装好的接口,在用的时候只需实现即可,Trainable还封装了其他函数如_log_result(result),_stop(),_export_model(export_formats, export_dir)等方法,更多信息看tune的API。
其中
_setup()是初始化函数,在调用类时直接初始化,一般用作数据初始化等。
对一个可训练对象调用_train()将执行一个训练的逻辑迭代。根据经验,一次训练(trial)调用执行时间应该足够长,以避免开销(即超过几秒),但要也足够短,以便定期报告进度(即最多几分钟)。
调用_save()应该将可训练对象的训练状态保存到磁盘,而_restore(path)应该将可训练对象恢复到给定的状态。
通常,当子类化Trainable时,只需要在这里实现_setup()、_train、_save和_restore。
注意 ,如果您不需要检查点/恢复功能,那么您也可以只向配置提供一个my_train(config, reporter)函数,而不是实现这个类。该函数将自动转换为该接口(没有检查点功能)。
启动实验
Tune提供了一个generates(生成器)和运行试验的run函数。
ray.tune.run(run_or_experiment, name=None, stop=None, config=None,
resources_per_trial=None, num_samples=1, local_dir=None, upload_dir=None,
trial_name_creator=None, loggers=None, sync_function=None, checkpoint_freq=0,
checkpoint_at_end=False, export_formats=None, max_failures=3, restore=None,
search_alg=None, scheduler=None, with_server=False, server_port=4321,
verbose=2, resume=False, queue_trials=False, reuse_actors=False,
trial_executor=None, raise_on_failed_trial=True)
执行训练。
参数:
run_or_experiment (function|class|str|Experiment) -如果是function | class | str,
那么这就是要训练的算法或模型。 这可以指内置算法的名称(例如RLLib的DQN或PPO),
用户定义的Trainable函数或类,或者在tune注册表中注册的Trainable函数或类的字符串标
识符。 如果是Experiment,那么Tune将根据Experiment.spec执行训练。
name (str) – 实验名称。
stop (dict) – 停止条件。键可以是' train() '返回结果中的任何字段,以先到达的字段为准。
默认为空dict。
config (dict) – 特定算法的Tune variant generation (变量生成器)的配置信息。
默认为空字典。自定义搜索算法可能会忽略这一点。
resources_per_trial (dict) -每次试验分配的机器资源,如{“cpu”:64,“gpu”:8}。注意,
除非在这里指定gpu,否则不会分配GPU资源。Trainable.default_resource_request()中默认
为1个CPU和0个gpu。
num_samples (int) –从超参数空间采样的次数。默认为1。如果grid_search作为参数提供,
则网格将多次重复使用num_samples。
local_dir (str) –保存训练结果到本地路径。默认是~/ray_results。
upload_dir (str) –可选URI将训练结果同步到(例如s3://bucket)。
trial_name_creator (func) –用于生成训练字符串表示形式的可选函数。
loggers (list) – 每次试验都要使用的日志记录器创建者列表。如果没有,
默认为ray.tune.logger.DEFAULT_LOGGERS. 见ray/tune/logger.py.
sync_function (func|str) –函数的作用是:将local_dir同步到upload_dir。如果是字符串,那么它
必须是一个字符串模板,以便syncer运行。如果没有提供,
sync命令默认为标准S3或gsutil sync comamnds。
checkpoint_freq (int) – 检查点之间的训练迭代次数。值0(默认值)禁用检查点。
checkpoint_at_end (bool) – 是否在实验结束时进行检查点检查,而不考虑checkpoint t_freq。
默认是假的。
export_formats (list) – 实验结束时导出的格式列表。默认是没有的。
max_failures (int) –至少多次尝试从最后一个检查点恢复试验。仅当启用检查点时才适用。
设置为-1将导致无限的恢复重试。默认为3。
restore (str) – 路径监测点。只有在运行1次试验时设置才有意义。默认为没有。
search_alg (SearchAlgorithm) – 搜索算法。默认为BasicVariantGenerator。
scheduler (TrialScheduler) –用于执行实验的调度程序。选择FIFO(默认值)、medianstop、
AsyncHyperBand和HyperBand。
with_server (bool) –启动后台Tune服务器。需要使用客户端API。
server_port (int) –启动TuneServer的端口号。
verbose (int) –0,1或 2冗长的模式。0 =静音,1 =只更新状态,2 =状态和试验结果。
resume (bool|"prompt") –如果检查点存在,实验将从那里继续进行。
如果resume是“prompt”,那么如果检测到检查点,Tune将会提示。
queue_trials (bool) – 当集群当前没有足够的资源来启动一个测试时,是否对测试进行排队。
在自动缩放集群上运行时,应将此设置为True,以启用自动缩放。
reuse_actors (bool) –如果可能,是否在不同的试验之间重用actor。这可以极大地加快经常启动
和停止参与者的实验(例如,在时间复用模式下的PBT)。这要求试验具有相同的资源需求。
trial_executor (TrialExecutor) –管理训练的执行。
raise_on_failed_trial (bool) –当实验完成时,如果存在失败的试验(错误状态),
则提出TuneError。
返回:
训练对象列表。
例子
>>> tune.run(mytrainable, scheduler=PopulationBasedTraining())
>>> tune.run(mytrainable, num_samples=5, reuse_actors=True)
>>> tune.run(
"PG",
num_samples=5,
config={
"env": "CartPole-v0",
"lr": tune.sample_from(lambda _: np.random.rand())
}
)
此功能将报告状态打印在控制台上,直到所有试验停止,如下:
== Status ==
Using FIFO scheduling algorithm.
Resources used: 4/8 CPUs, 0/0 GPUs
Result logdir: ~/ray_results/my_experiment
- train_func_0_lr=0.2,momentum=1: RUNNING [pid=6778], 209 s, 20604 ts, 7.29 acc
- train_func_1_lr=0.4,momentum=1: RUNNING [pid=6780], 208 s, 20522 ts, 53.1 acc
- train_func_2_lr=0.6,momentum=1: TERMINATED [pid=6789], 21 s, 2190 ts, 100 acc
- train_func_3_lr=0.2,momentum=2: RUNNING [pid=6791], 208 s, 41004 ts, 8.37 acc
- train_func_4_lr=0.4,momentum=2: RUNNING [pid=6800], 209 s, 41204 ts, 70.1 acc
- train_func_5_lr=0.6,momentum=2: TERMINATED [pid=6809], 10 s, 2164 ts, 100 acc
自定义训练(trial)名称
要指定自定义试验名称,可以将trial_name_creator参数传递给tune.run。这需要一个具有以下签名的函数,并确保用tune.function包装它:
# trial_name_string(trial)定义自己想改的训练名称
def trial_name_string(trial):
"""
Args:
trial (Trial): A generated trial object.
Returns:
trial_name (str): String representation of Trial.
"""
return str(trial)
# 此处通过tune.function(trial_name_string)把训练函数MyTrainableClass的名改成trial_name_string(trial)转换的名。
tune.run(
MyTrainableClass,
name="hyperband_test",
num_samples=1,
trial_name_creator=tune.function(trial_name_string)
)
一个例子可以在logging_example.py中找到。
训练特征(Training Features)
Tune的搜索空间(Tune Search Space)(默认)
可以使用tune.grid_search指定网格搜索的轴。默认情况下,Tune还支持从用户指定的lambda函数中抽取采样参数,这些函数可以单独使用,也可以与网格搜索结合使用。
注意: 如果指定了显式搜索算法,则可能无法使用此接口指定lambdas或网格搜索,因为搜索算法可能需要不同的搜索空间声明。
下面显示了对两个嵌套参数的网格搜索,结合来自两个lambda函数的随机抽样,生成了9个不同的试验。注意,beta的值依赖于alpha的值,它通过在lambda函数中引用spec.config.alpha来表示。这允许指定参数的条件分布。
tune.run(
my_trainable,
name="my_trainable",
config={
"alpha": tune.sample_from(lambda spec: np.random.uniform(100)),
"beta": tune.sample_from(lambda spec: spec.config.alpha * np.random.normal()),
"nn_layers": [
tune.grid_search([16, 64, 256]),
tune.grid_search([16, 64, 256]),
],
}
)
注:使用tune.sample_from(…)在训练变量生成期间对函数进行采样。如果需要在配置中传递文字函数,请使用tune.function(…)转义它。
有关变体生成器( variant generation)的更多信息,请看 basic_variant.py.
多次抽样(Sampling Multiple Times)
默认情况下,每个随机变量和网格搜索点采样一次。要获取多个随机样本,请将num_samples: N添加到实验配置中。如果grid_search作为参数提供,则网格将多次重复使用num_samples。
tune.run(
my_trainable,
name="my_trainable",
config={
"alpha": tune.sample_from(lambda spec: np.random.uniform(100)),
"beta": tune.sample_from(lambda spec: spec.config.alpha * np.random.normal()),
"nn_layers": [
tune.grid_search([16, 64, 256]),
tune.grid_search([16, 64, 256]),
],
},
num_samples=10
)
例如,在上面的例子中,num_samples=10重复了10次3x3的网格搜索,总共进行了90次试验,每次试验都有随机采样的alpha和beta值。
使用gpu资源
Tune将为每个单独的试验(trial)分配指定的GPU和CPU resources_per_trial(默认为每个试验分配一个CPU)。在幕后,Tune以Ray actor的身份运行每个试验(trail),使用Ray的资源处理来分配资源和放置参与者(actor)。以防止集群过载,除非集群中的资源数每达到一个trial需要的资源数,安排一个trial进行运行,否则不会安排试验运行,直到有trial运行结束,资源被释放后再运行下一个trial。
资源个数可以是小数(例如,“gpu”: 0.2)。您可以在Keras MNIST example中找到一个这样的例子。
如果不请求GPU资源,CUDA_VISIBLE_DEVICES环境变量将被设置为空,不允许GPU访问。
如果可训练(trainable)函数/类创建了很多的Ray actor或任务,这些任务也消耗CPU / GPU资源,那么您还需要设置extra_cpu或extra_gpu来为将要创建的actor保留额外的资源槽。例如,如果一个可训练(trainable)类本身需要一个GPU,但将使用另一个GPU分别启动4个actor,那么它应该设置“gpu”:1,“extra_gpu”:4。
tune.run(
my_trainable,
name="my_trainable",
# 给试验分配一个cpu,一个gpu ,为将要创建的actor保留额外4个gpu的资源槽
resources_per_trial={
"cpu": 1,
"gpu": 1,
"extra_gpu": 4
}
)
训练检测点(Trial Checkpointing)
检查点主要是为了训练中出错及时进行恢复,提高训练的正确率。
要启用检测点,必须实现一个 Trainable 类(Trainable函数不是检查者,因为它们从不将控制权返回给调用者)。最简单的方法是子类化预定义的Trainable类,并实现它的_train、_save和_restore抽象方法(示例)。在HyperBand和PBT等试用调度程序中,需要实现此接口来支持资源多路复用。
一个TensorFlow 模型训练的例子如下:
class MyClass(Trainable):
def _setup(self, config):
self.saver = tf.train.Saver()
self.sess = ...
self.iteration = 0
def _train(self):
self.sess.run(...)
self.iteration += 1
def _save(self, checkpoint_dir):
return self.saver.save(
self.sess, checkpoint_dir + "/save",
global_step=self.iteration)
def _restore(self, path):
return self.saver.restore(self.sess, path)
此外,检测点还可以为实验提供容错能力。这可以通过设置checkpoint_freq=N和max_failure =M来启用检查点试验,每次迭代N次,每次试验从最多M次崩溃中恢复,例如:
tune.run(
my_trainable,
checkpoint_freq=10,
max_failures=5,
)
checkpoint_freq可能与实验的确切结束时间不一致。如果希望在试验结束时创建检查点,还可以将checkpoint_at_end设置为True(在实验结束是进行检查点检测,如果出错,恢复到上次失败的地方重新训练,在结束时再进行检查点检测,直至训练正确的结束)。例子如下:
tune.run(
my_trainable,
checkpoint_freq=10,
checkpoint_at_end=True,
max_failures=5,
)
故障恢复(实验)
Tune会自动保存实验的进程,因此,如果一个实验崩溃或被取消,可以使用resume=True恢复它。resume=False的默认设置将创建一个新实验,resume=“prompt”将导致Tune提示您是否要恢复。可以通过更改实验名称强制创建一个新的实验。
注意,训练将恢复到最后一个检查点。如果没有启用试验检查点,未完成的试验将从头开始。
例如:
tune.run(
my_trainable,
checkpoint_freq=10,
local_dir="~/path/to/results",
resume=True
)
在第二次运行时,这将从~/path/to/results/my_experiment_name恢复整个实验状态。重要的是,对实验说明书的任何修改将被忽略(就是会忽略没有保存的实验修改)。
该特性仍处于试验阶段,因此不会保留任何提供的试验调度程序或搜索算法。只支持FIFOschscheduler和BasicVariantGenerator。
处理大型数据集
想要在驱动程序上计算一个大数据对象(例如,训练数据、模型权重),并在每次试验中使用该对象。Tune提供了一个pin_in_object_store实用函数,可用于广播这样的大数据对象。在驱动程序进程运行时,以这种方式固定的对象永远不会从Ray对象存储中被删除,并且可以通过get_pinned_object从任何任务中有效地检索。
import ray
from ray import tune
from ray.tune.util import pin_in_object_store, get_pinned_object
import numpy as np
ray.init()
# X_id can be referenced in closures
X_id = pin_in_object_store(np.random.random(size=100000000))
def f(config, reporter):
X = get_pinned_object(X_id)
# use X
tune.run(f)
自动填充结果(Auto-Filled Results)
在训练期间,Tune会自动填充没有被提供的字段(打印在控制台上的日志信息)。所有这些都可以用作停止条件或在调度程序/搜索算法规范中使用。下面列出来的只是主要打印信息,其中带有Auto-filled是每次必须打印出来的,其它选项是可选的(即不在运行是声明是不会打印出的)。
# (Optional/Auto-filled) training is terminated. Filled only if not provided.
DONE = "done"
# (Auto-filled) The hostname of the machine hosting the training process.
HOSTNAME = "hostname"
# (Auto-filled) The node ip of the machine hosting the training process.
NODE_IP = "node_ip"
# (Auto-filled) The pid of the training process.
PID = "pid"
# (Optional) Mean reward for current training iteration
EPISODE_REWARD_MEAN = "episode_reward_mean"
# (Optional) Mean loss for training iteration
MEAN_LOSS = "mean_loss"
# (Optional) Mean accuracy for training iteration
MEAN_ACCURACY = "mean_accuracy"
# Number of episodes in this iteration.
EPISODES_THIS_ITER = "episodes_this_iter"
# (Optional/Auto-filled) Accumulated number of episodes for this experiment.
EPISODES_TOTAL = "episodes_total"
# Number of timesteps in this iteration.
TIMESTEPS_THIS_ITER = "timesteps_this_iter"
# (Auto-filled) Accumulated number of timesteps for this entire experiment.
TIMESTEPS_TOTAL = "timesteps_total"
# (Auto-filled) Time in seconds this iteration took to run.
# This may be overriden to override the system-computed time difference.
TIME_THIS_ITER_S = "time_this_iter_s"
# (Auto-filled) Accumulated time in seconds for this entire experiment.
TIME_TOTAL_S = "time_total_s"
# (Auto-filled) The index of this training iteration.
TRAINING_ITERATION = "training_iteration"
如果提供以下字段将自动显示在控制台输出(即:不提供不会输出):
episode_reward_meanmean_lossmean_accuracytimesteps_this_iter(总和为timesteps_total)
例如:
Example_0: TERMINATED [pid=68248], 179 s, 2 iter, 60000 ts, 94 rew
记录和可视化结果
每个实验中,trainable报告的所有结果都将被本地记录到一个惟一的目录中,如上面例子中的~/ray_results/my_experiment。在集群上,新增结果将同步到head节点上的本地磁盘。日志记录与许多可视化工具兼容:
可视化学习工具tensorboard,需要安装TensorFlow:
$ pip install tensorflow
然后,在您运行一个实验之后,您可以通过指定结果的输出目录,使用TensorBoard可视化您的实验。注意,如果在远程集群上运行Ray,可以使用ssh -L 6006:localhost:6006 :
$ tensorboard --logdir=~/ray_results/my_experiment
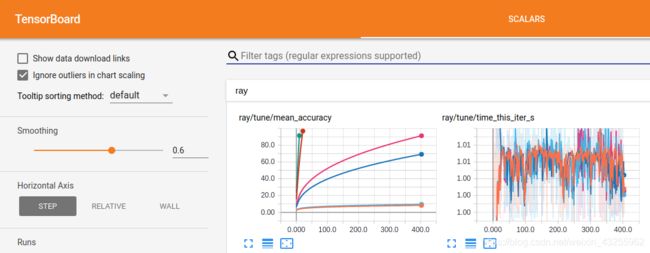
要使用rllab的VisKit(可能需要安装一些依赖项),请运行:
$ git clone https://github.com/rll/rllab.git
$ python rllab/rllab/viskit/frontend.py ~/ray_results/my_experiment

最后,要使用并行坐标可视化查看结果,请打开ParallelCoordinatesVisualization。ipynb如下,并运行其组件:
$ cd $RAY_HOME/python/ray/tune
$ jupyter-notebook ParallelCoordinatesVisualization.ipynb

自定义日志(Custom Loggers)
你可以通过你自己的日志机制来输出自定义格式的日志,如下:
from ray.tune.logger import DEFAULT_LOGGERS
tune.run(
MyTrainableClass
name="experiment_name",
loggers=DEFAULT_LOGGERS + (CustomLogger1, CustomLogger2)
)
这些日志记录器将与默认的Tune日志记录器一起调用。所有记录器都必须继承记录器接口。
Tune为Tensorboard、CSV和JSON格式提供了默认的日志记录器。
还可以查看logger.py以了解实现细节。一个日志相关的例子 logging_example.py.
自定义同步/上传的命令
如果提供了上传目录,那么Tune将使用标准的S3/gsutil命令自动将结果同步到给定目录。您可以通过提供函数或字符串自定义upload命令。
如果提供了一个字符串,那么它必须包含替换字段{local_dir}和{remote_dir},比如“aws s3 sync {local_dir} {remote_dir}”。然后,函数可以提供以下签名(并且必须用tune.function包装):
def custom_sync_func(local_dir, remote_dir):
sync_cmd = "aws s3 sync {local_dir} {remote_dir}".format(
local_dir=local_dir,
remote_dir=remote_dir)
# subprocess.Popen()创建函数
sync_process = subprocess.Popen(sync_cmd, shell=True)
sync_process.wait()
tune.run(
MyTrainableClass,
name="experiment_name",
sync_function=tune.function(custom_sync_func)
)
Tune 客户端的 API
您可以使用Tune客户机API与正在进行的实验进行交互。Tune客户机API是围绕REST组织的,其中包括面向资源的url、接受表单编码的请求、返回json编码的响应并使用标准HTTP协议。
要允许Tune接收和响应客户机API的调用,您必须使用with_server=True开始您的实验:
# 此例子中通过with_server=True开启客户端服务,server_port=4321
tune.run(..., with_server=True, server_port=4321)
使用Tune客户机API的最简单方法是使用内置的TuneClient。要使用TuneClient,请验证是否安装了requests库:
$ pip install requests
然后,在客户端,您可以使用以下类。如果在集群中,您可能希望转发这个端口(例如ssh -L
),以便您可以在本地机器上使用客户机。
| class ray.tune.web_server.TuneClient(tune_address, port_forward) |
|---|
与正在运行的Tune实验进行交互。请求TuneServer 开始运行。
tune_address :(str)正在运行的TuneServer地址
port_forward:(int)正在运行的TuneServer端口号
get_all_trials():返回所有训练(trial)信息的列表。
get_trial(trial_id):通过trial_id返回训练信息。
add_trial(name, specification):添加按名称和规范(dict)进行的trial。
stop_trial(trial_id):请求停止trial通过trial_id。
该API还支持curl。下面是获得trial的例子(GET /trials/[:id]):
curl http://:/trials
curl http://:/trials/
终止trial(PUT /trials/:id):
curl -X PUT http://:/trials/
Tune CLI
tune有一个易于使用的命令行界面(CLI)来管理和监控您在Ray上的实验。要做到这一点,请确认已经安装了 tabulate库:
$ pip install tabulate
下面是一些命令行调用的例子。
-
tune list-trials:列出实验中训练(trial)的列表信息。默认情况下将删除空列。添加
--sort标志,按特定列对输出进行排序。
添加--filter标志,以“格式对输出进行过滤。”
添加--output标志,将试验信息写入特定的文件(CSV或Pickle)。
添加--columns和--result-columns标志,以选择要显示的特定列。
$ tune list-trials [EXPERIMENT_DIR] --output note.csv
+------------------+-----------------------+------------+
| trainable_name | experiment_tag | trial_id |
|------------------+-----------------------+------------|
| MyTrainableClass | 0_height=40,width=37 | 87b54a1d |
| MyTrainableClass | 1_height=21,width=70 | 23b89036 |
| MyTrainableClass | 2_height=99,width=90 | 518dbe95 |
| MyTrainableClass | 3_height=54,width=21 | 7b99a28a |
| MyTrainableClass | 4_height=90,width=69 | ae4e02fb |
+------------------+-----------------------+------------+
Dropped columns: ['status', 'last_update_time']
Please increase your terminal size to view remaining columns.
Output saved at: note.csv
$ tune list-trials [EXPERIMENT_DIR] --filter "trial_id == 7b99a28a"
+------------------+-----------------------+------------+
| trainable_name | experiment_tag | trial_id |
|------------------+-----------------------+------------|
| MyTrainableClass | 3_height=54,width=21 | 7b99a28a |
+------------------+-----------------------+------------+
Dropped columns: ['status', 'last_update_time']
Please increase your terminal size to view remaining columns.
-
tune list-experiments:列出项目中实验的列表信息。默认情况下将删除空列。添加
--sort标志,按特定列对输出进行排序。
添加--filter标志,以“格式对输出进行过滤。”
添加--output标志,将试验信息写入特定的文件(CSV或Pickle)。
添加--columns标志以选择要显示的特定列。
$ tune list-experiments [PROJECT_DIR] --output note.csv
+----------------------+----------------+------------------+---------------------+
| name | total_trials | running_trials | terminated_trials |
|----------------------+----------------+------------------+---------------------|
| pbt_test | 10 | 0 | 0 |
| test | 1 | 0 | 0 |
| hyperband_test | 1 | 0 | 1 |
+----------------------+----------------+------------------+---------------------+
Dropped columns: ['error_trials', 'last_updated']
Please increase your terminal size to view remaining columns.
Output saved at: note.csv
$ tune list-experiments [PROJECT_DIR] --filter "total_trials <= 1" --sort name
+----------------------+----------------+------------------+---------------------+
| name | total_trials | running_trials | terminated_trials |
|----------------------+----------------+------------------+---------------------|
| hyperband_test | 1 | 0 | 1 |
| test | 1 | 0 | 0 |
+----------------------+----------------+------------------+---------------------+
Dropped columns: ['error_trials', 'last_updated']
Please increase your terminal size to view remaining columns.
此篇主要参考Ray官网,如有错误,请阅读者提出指正,谢谢!
原英文链接:https://ray.readthedocs.io/en/latest/tune-usage.html