ElasticSearch-学习笔记
文章目录
- 前言
- 1.简介
- 2.Es与MySql的对比
- 3.Es与其他数据存储组件比较
- 4.特点
- 5.倒排索引
- 6.B+Tree
- 7.ElasticSearch中的基本概念
- 8.ElasticSearchRepository和ElasticSearchTemplate的使用
- 9.FSCrawler(ElasticSearch的FS搜寻器。)
- 10.RESTful API
- 11.中文分词
- 12.动态同义词(自定义)
- 13.JavaAPI(实现ES的工具类,采用了高级API)
- 总结
前言
本文分享本菜鸟的ElasticSearch笔记。
内容不是很多,也可能是我接触的不够深。
一起学习,一起进步 ~
本菜鸟QQ:599903582
笨鸟先飞,熟能生巧~
比心心 ~
提示:以下是本篇文章正文内容,下面案例可供参考
1.简介
ES是一个基于RESTful web接口并且构建在Apache Lucence之上的开源分布式搜索引擎。分布式文档数据库,每个字段均可被索引,每个字符的数据均可被搜索,能够横向拓展至数以百计的服务器存储以及处理PB级的数据。
高可用 可拓展。
不支持事务。
文档是可以被索引的基本单位。
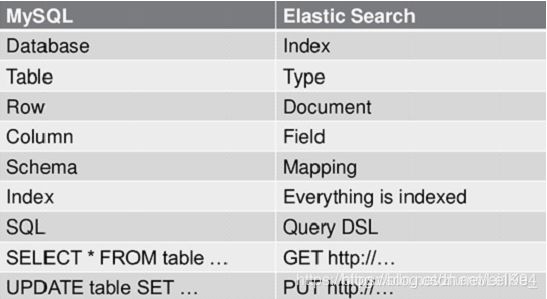
2.Es与MySql的对比

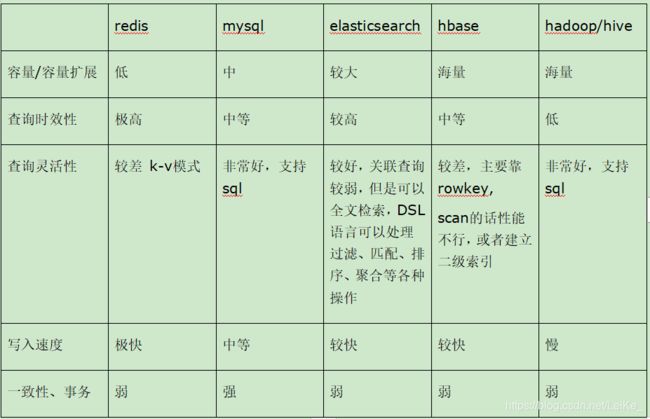
3.Es与其他数据存储组件比较
4.特点
-
天然分片,天然集群
es 把数据分成多个shard,多个shard可以组成一份完整的数据,这些shard可以分布在集群中的各个机器节点中es 把数据分成多个shard。多个shard可以组成一份完整的数据,这些shard可以分布在集群中的各个机器节点中。
在实际运算过程中,每个查询任务提交到某一个节点,该节点必须负责将数据进行整理汇聚,再返回给客户端,也就是一个简单的节点上进行Map计算,在一个固定的节点上进行Reduces得到最终结果向客户端返回。 -
天然索引
ES 所有数据都是默认进行索引的,这点和mysql正好相反,mysql是默认不加索引,要加索引必须特别说明,ES只有不加索引才需要说明。而ES使用的是倒排索引和Mysql的B+Tree索引不同。
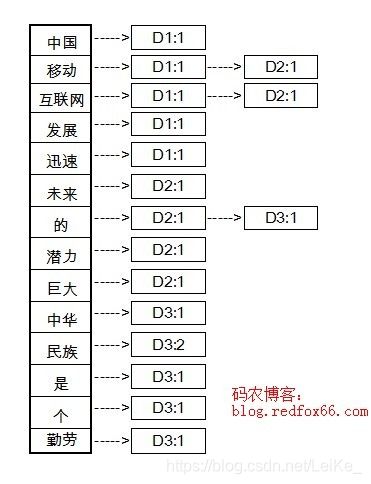
5.倒排索引
索引:倒排索引 前面是字段,后面是字段对应的位置信息
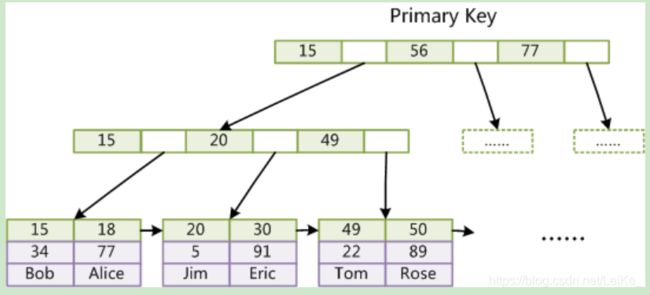
6.B+Tree
7.ElasticSearch中的基本概念
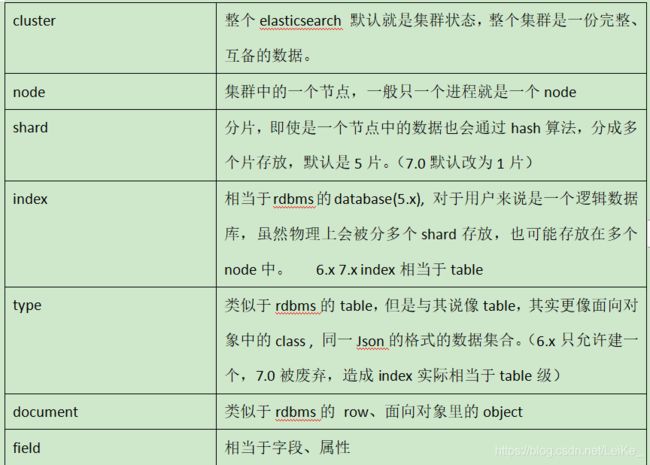
8.ElasticSearchRepository和ElasticSearchTemplate的使用
(极大的简化开发)
https://blog.csdn.net/tianyaleixiaowu/article/details/76149547
9.FSCrawler(ElasticSearch的FS搜寻器。)
https://fscrawler.readthedocs.io/en/latest/index.html
10.RESTful API
(ES7中类型_type已经均为_doc, 这里的是之前版本的指令)
PUT test01 // 建立mapping,然后可以往里传数据 ,如果开始的时候没有指定则根据第一条数据进行推测
{
"mappings": {
"person":{
"properties":{
"id":{
"type":"keyword"
},
"name":{
"type":"text"
},
"age":{
"type":"integer"
}
}
}
}
}
PUT /test01/person/1 //往索引test01传数据,person为_type, 1 为 _id
{
"id":1,
"name":"xuchenglei",
"age":23
}
GET /test01/person/_search //查询 索引 test01 下 person类型的, 满足match匹配的数据
{
"query": {
"match": {
"name": "guomengyao"
}
}
}
GET /test01/person/_search
{
"query": {
"match": {
"_type": "person"
}
}
}
GET /test01/person/_search //得到索引test01下的person类型的所有数据
GET /_cat/nodes?v 查询各个节点状态
GET /_cat/indices?v 查询各个索引状态
GET /_cat/shard/xxxx 查询某个索引的分片情况
GET /_cat/indices?v //查询es中存在那些索引
PUT /movie_index 创建一个索引
DELETE /movie_index 删除一个索引,其实ES是不删除和修改任何数据的,只能其增加版本号
PUT /index/type/id // 插入式各字段的意思
GET movie_index/movie/1 直接用_id进行查询
修改-全部字段值替换 , 格式和新增一样,需要将字段全部写出赋值
修改-某一字段值替换:如下
POST movie_index/movie/3/_update
{
"doc": {
"doubanScore":"7.0"
}
}
DELETE movie_index/movie/3 删除一个document
按条件查询:如下
GET movie_index/movie/_search
{
"query":{
"match_all": {}
}
}
按分词查询:如下
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red"}
}
}
按分词子属性查询:
GET movie_index/movie/_search
{
"query":{
"match": {"actorList.name":"zhang"}
}
}
按短语查询,不再利用分词技术,直接用短语在原始数据中匹配
GET movie_index/movie/_search
{
"query":{
"match_phrase": {"name":"operation red"}
}
}
fuzzy查询,无情精确匹配时,查询出非常接近的词
GET movie_index/movie/_search
{
"query":{
"fuzzy": {"name":"rad"}
}
}
filter过滤查询:查询后过滤
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red"}
},
"post_filter":{
"term": {
"actorList.id": 3
}
}
}
filter : 查询前过滤
GET movie_index/movie/_search
{
"query":{
"bool":{
"filter":[ {"term": { "actorList.id": "1" }},
{"term": { "actorList.id": "3" }}
],
"must":{"match":{"name":"red"}}
}
}
}
filter 按照范围过滤:
GET movie_index/movie/_search
{
"query": {
"bool": {
"filter": {
"range": {
"doubanScore": {"gte": 8} // gt 大于 lt 小于 gte 大于等于 lte 小于等于
}
}
}
}
}
排序:
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
}
, "sort": [
{
"doubanScore": {
"order": "desc"
}
}
]
}
分页查询:
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
指定查询字段:
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"_source": ["name", "doubanScore"]
}
高亮显示:
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
},
"highlight": {
"fields": {"name":{} }
}
}
聚合:
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor": {
"terms": {
"field": "actorList.name.keyword" // .keyword 使其不分词
}
}
}
}
字符串匹配查询
GET pv/_search
{
"query": {
"query_string": {
"default_field": "name",
"query": "076-97c8-24ca6147"
}
}
}
将会搜索name字段包含076-97c8-24ca6147的数据记录
es索引重建:
https://www.cnblogs.com/juncaoit/p/12815582.html
https://www.cnblogs.com/Ace-suiyuan008/p/9985249.html
11.中文分词
https://github.com/medcl/elasticsearch-analysis-ik
12.动态同义词(自定义)
https://github.com/bells/elasticsearch-analysis-dynamic-synonym/tree/master
13.JavaAPI(实现ES的工具类,采用了高级API)
(推荐下载下来看,有点多)
链接:https://github.com/MrXuSS/EsUtils
pom.xml
com.alibaba
fastjson
1.2.74
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.9.2
org.junit.jupiter
junit-jupiter
RELEASE
test
接口:
public interface EsClient {
/**
* 向es中创建文档索引, 若es中已存在改index,则插入失败。
*
* @param indexName 索引名称
* @param document id
* @param jsonStr json字符串, 要存入的数据
*/
public Boolean insertIndexWithJsonStr(String indexName, String document, String jsonStr);
/**
* 查询指定id下索引数据
*
* @param indexName 索引名称
* @param document id
* @return 返回得到的字符串, 没有返回null
* {"age":18,"id":1,"name":"xuchenglei"}
*/
public String queryIndex(String indexName, String document);
/**
* 查询索引下的所有数据
* @param indexName 索引名称
* @param startNum 开始的位置
* @param pageSize 分页的大小
* @return 数据的字符串, json格式; 没有返回null
* [{"name":"xuchenglei","id":1,"age":18},{"name":"xuchenglei","id":2,"age":18}]
*/
public String queryIndex(String indexName, Integer startNum, Integer pageSize);
/**
* 根据索引名称和id删除数据
* @param indexName 索引名称
* @param document id
* @return 是否删除成功; 索引不存在返货false
*/
public Boolean deleteIndex(String indexName, String document);
/**
* 删除indexName下的所有索引数据
* @param indexName 索引名称
* @return 删除是否成功。
*/
public Boolean deleteIndex(String indexName);
/**
* 判断索引是否存在
* @param indexName 索引名称
* @param document id
* @return true or false
*/
public Boolean isIndexExists(String indexName, String document);
/**
* 判断索引是否存在
* @param indexName 索引名称
* @return true or false
*/
public Boolean isIndexExists(String indexName);
/**
* 查询出所有的index
* @return 查询出所有的索引 Set
*/
public Set queryAllIndex();
/**
* 根据 index 和 id 更新 索引数据
* @param indexName 索引名称
* @param document id
* @param jsonStr 要更新的json
* @return 是否更新成功
*/
public Boolean updateIndex(String indexName, String document, String jsonStr);
/**
* index下的搜索
* @param field 属性
* @param text 值
* @param indexName 索引名称
* @param startNum 开始的位置
* @param pageSize 分页的大小
* @return 返回符合条件的值
*/
public String search(String field, String text, String indexName, Integer startNum, Integer pageSize);
/**
* 模糊查询, 并实现高亮
* @param field 属性名
* @param text value
* @param indexName 索引名
* @param startNum 开始的位置
* @param pageSize 分页大小
* @return json
*/
public String searchFuzzy(String field, String text, String indexName, Integer startNum, Integer pageSize);
/**
* 获取当前索引下的数据量
* @param indexName 索引名称
* @return 数据量条数
*/
public Long searchTotalHitsNum(String indexName);
/**
* 向es中创建文档索引, 若es中已存在改index,则插入失败。(异步)
*
* @param indexName 索引名称
* @param document id
*/
public void insertIndexWithJsonStrAsync(String indexName, String document, String jsonStr);
/**
* 根据索引名称和id删除数据,(异步)
* @param indexName 索引名称
* @param document id
*/
public void deleteIndexAsync(String indexName, String document);
/**
* 删除indexName下的所有索引数据,(异步)
* @param indexName 索引名称
*/
public void deleteIndexAsync(String indexName);
/**
* 根据 index 和 id 更新 索引数据 (异步)
* @param indexName 索引名称
* @param document id
* @param jsonStr 要更新的json
*/
public void updateIndexAsync(String indexName, String document, String jsonStr);
/**
* 索引重建(同步)。 注意:目标索引需要提前创建好
* @param fromIndex 重新索引的索引名
* @param destIndex 重新索引后的索引名
* @return 新创建的文档数
*/
public Long reIndex(String fromIndex, String destIndex);
/**
* 索引重建(异步)。注意:目标索引需要提前创建好
* @param fromIndex 重新索引的索引名
* @param destIndex 重新索引后的索引名
*/
public void reIndexAsync(String fromIndex, String destIndex);
}
实现单例模式:
/**
* 以单例模式提供EsClient实例
*/
public class EsServerManager {
private static EsServerManager instance;
private static RestHighLevelClient client;
private EsServerManager(){
HttpHost host = new HttpHost("192.168.2.201", 9200, "http");
client = new RestHighLevelClient(RestClient.builder(host));
}
public static synchronized EsServerManager getInstance(){
if(instance == null){
instance = new EsServerManager();
}
return instance;
}
public RestHighLevelClient getClient(){
return client;
}
}
API:
public class EsClientImpl implements EsClient{
private static Log log = LogFactory.getLog(EsClientImpl.class);
/**
* 向es中创建文档索引, 若es中已存在改index,则插入失败。
*
* @param indexName 索引名称
* @param document id
* @param jsonStr json字符串, 要存入的数据
*/
public Boolean insertIndexWithJsonStr(String indexName, String document, String jsonStr) {
Boolean indexExists = isIndexExists(indexName, document);
Boolean result = false;
if (!indexExists) {
IndexRequest indexRequest = new IndexRequest(indexName)
.id(document)
.source(jsonStr, XContentType.JSON);
IndexResponse indexResponse = null;
try {
indexResponse = EsServerManager.getInstance().getClient().index(indexRequest, RequestOptions.DEFAULT);
if(indexResponse.getResult() == DocWriteResponse.Result.CREATED){
result = true;
}
log.info(indexResponse.getIndex() + "--" + indexResponse.getId() + "--" + "插入成功");
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
/**
* 查询指定id下索引数据
*
* @param indexName 索引名称
* @param document id
* @return 返回得到的字符串, 没有返回null
* {"age":18,"id":1,"name":"xuchenglei"}
*/
public String queryIndex(String indexName, String document) {
Boolean indexExists = isIndexExists(indexName, document);
if (indexExists) {
GetResponse getResponse = null;
GetRequest getRequest = new GetRequest(indexName, document);
try {
getResponse = EsServerManager.getInstance().getClient().get(getRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
return getResponse == null ? null : getResponse.getSourceAsString().toString();
} else {
return null;
}
}
/**
* 查询索引下的所有数据
* @param indexName 索引名称
* @return 数据的字符串, json格式; 没有返回null
* [{"name":"xuchenglei","id":1,"age":18},{"name":"xuchenglei","id":2,"age":18}]
*/
public String queryIndex(String indexName, Integer startNum, Integer pageSize){
Boolean indexExists = isIndexExists(indexName);
if (indexExists) {
SearchResponse searchResponse = null;
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(indexName);
searchSourceBuilder.from(startNum);
searchSourceBuilder.size(pageSize);
searchRequest.source(searchSourceBuilder);
try {
searchResponse = EsServerManager.getInstance().getClient().search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
if(searchResponse != null){
SearchHit[] searchHits = searchResponse.getHits().getHits();
List> arrayListMap = new ArrayList>();
for (SearchHit searchHit : searchHits) {
Map sourceAsMap = searchHit.getSourceAsMap();
arrayListMap.add(sourceAsMap);
}
return JSON.toJSONString(arrayListMap);
}
return null;
} else {
return null;
}
}
/**
* 根据索引名称和id删除数据
* @param indexName 索引名称
* @param document id
* @return 是否删除成功; 索引不存在返货false
*/
public Boolean deleteIndex(String indexName, String document){
Boolean indexExists = isIndexExists(indexName, document);
Boolean result = false;
if(indexExists) {
DeleteRequest deleteRequest = new DeleteRequest(indexName, document);
DeleteResponse deleteResponse = null;
try {
deleteResponse = EsServerManager.getInstance().getClient().delete(deleteRequest, RequestOptions.DEFAULT);
if(deleteResponse.getResult() == DocWriteResponse.Result.DELETED){
result = true;
}
log.info(deleteResponse.getIndex()+"--"+deleteResponse.getId()+":已删除");
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
/**
* 删除indexName下的所有索引数据
* @param indexName 索引名称
* @return 删除是否成功。
*/
public Boolean deleteIndex(String indexName){
Boolean indexExists = isIndexExists(indexName);
Boolean result = false;
if(indexExists){
DeleteIndexRequest deleteRequest = new DeleteIndexRequest(indexName);
AcknowledgedResponse acknowledgedResponse = null;
try {
acknowledgedResponse = EsServerManager.getInstance().getClient().indices().delete(deleteRequest, RequestOptions.DEFAULT);
if(acknowledgedResponse.isAcknowledged()){
result = true;
}
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
/**
* 判断索引是否存在
* @param indexName 索引名称
* @param document id
* @return true or false
*/
public Boolean isIndexExists(String indexName, String document){
GetRequest getRequest = new GetRequest(indexName, document);
// 禁用提取源
getRequest.fetchSourceContext(new FetchSourceContext(false));
// 禁用提取存储字段
getRequest.storedFields("_none_");
Boolean exists = false;
try {
exists = EsServerManager.getInstance().getClient().exists(getRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
return exists;
}
/**
* 判断索引是否存在
* @param indexName 索引名称
* @return true or false
*/
public Boolean isIndexExists(String indexName){
GetIndexRequest getIndexRequest = new GetIndexRequest(indexName);
Boolean exists = false;
try {
exists = EsServerManager.getInstance().getClient().indices().exists(getIndexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
return exists;
}
/**
* 查询出所有的index
* @return 查询出所有的索引 Set
*/
public Set queryAllIndex(){
GetAliasesRequest getAliasesRequest = new GetAliasesRequest();
Set indexNameKeySet = new HashSet();
try {
GetAliasesResponse getAliasesResponse = EsServerManager.getInstance().getClient().indices().getAlias(getAliasesRequest, RequestOptions.DEFAULT);
Set keySet = getAliasesResponse.getAliases().keySet();
for (String s : keySet) {
if(!s.startsWith(".")){
indexNameKeySet.add(s);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return indexNameKeySet;
}
/**
* 根据 index 和 id 更新 索引数据
* @param indexName 索引名称
* @param document id
* @return 是否更新成功
*/
public Boolean updateIndex(String indexName, String document, String jsonStr){
Boolean indexExists = isIndexExists(indexName, document);
Boolean result = false;
if(indexExists){
UpdateRequest updateRequest = new UpdateRequest(indexName, document).doc(jsonStr,XContentType.JSON);
UpdateResponse updateResponse = null;
try {
updateResponse = EsServerManager.getInstance().getClient().update(updateRequest, RequestOptions.DEFAULT);
if(updateResponse.getResult() == DocWriteResponse.Result.UPDATED){
result = true;
}
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
/**
* 全量匹配查询
* @param field 属性
* @param text 值
* @param indexName 索引名称
* @param startNum 开始的位置
* @param pageSize 分页的大小
* @return 返回符合条件的值
*/
public String search(String field, String text, String indexName, Integer startNum, Integer pageSize){
List> resultMapList = new ArrayList>();
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchRequest.source(searchSourceBuilder);
searchSourceBuilder.query(QueryBuilders.termQuery(field, text));
searchSourceBuilder.from(startNum);
searchSourceBuilder.size(pageSize);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
searchResponse = EsServerManager.getInstance().getClient().search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] searchHits = searchResponse.getHits().getHits();
for (SearchHit hit : searchHits) {
Map sourceAsMap = hit.getSourceAsMap();
resultMapList.add(sourceAsMap);
}
} catch (IOException e) {
e.printStackTrace();
}
return JSON.toJSONString(resultMapList);
}
/**
* 模糊查询, 并实现高亮
* @param field 属性名
* @param text value
* @param indexName 索引名称
* @return json
*/
public String searchFuzzy(String field, String text, String indexName, Integer startNum, Integer pageSize) {
List> resultMapList = new ArrayList>();
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.wildcardQuery(field, "*"+text+"*"));
searchSourceBuilder.from(startNum);
searchSourceBuilder.size(pageSize);
searchRequest.source(searchSourceBuilder);
// 高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field(field);
highlightTitle.highlighterType("unified");
highlightBuilder.field(highlightTitle);
highlightBuilder.preTags("");
highlightBuilder.postTags("");
searchSourceBuilder.highlighter(highlightBuilder);
SearchResponse searchResponse = null;
try {
searchResponse = EsServerManager.getInstance().getClient().search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] searchHits = searchResponse.getHits().getHits();
for (SearchHit hit : searchHits) {
Map highlightFields = hit.getHighlightFields();
HighlightField highlightField = highlightFields.get(field);
Text[] fragments = highlightField.fragments();
Map sourceAsMap = hit.getSourceAsMap();
sourceAsMap.put(field, fragments[0].string());
resultMapList.add(sourceAsMap);
}
} catch (IOException e) {
e.printStackTrace();
}
return JSON.toJSONString(resultMapList);
}
/**
* 获取当前索引下的数据量
* @param indexName 索引名称
* @return 数据量条数
*/
public Long searchTotalHitsNum(String indexName) {
Boolean indexExists = isIndexExists(indexName);
Long result = -1L;
if(indexExists){
SearchRequest searchRequest = new SearchRequest(indexName);
SearchResponse searchResponse = null;
try {
searchResponse = EsServerManager.getInstance().getClient().search(searchRequest, RequestOptions.DEFAULT);
result = searchResponse.getHits().getTotalHits().value;
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
/**
* 向es中创建文档索引, 若es中已存在改index,则插入失败。(异步)
*
* @param indexName 索引名称
* @param document id
* @param jsonStr json字符串, 要存入的数据
*/
public void insertIndexWithJsonStrAsync(String indexName, String document, String jsonStr) {
Boolean indexExists = isIndexExists(indexName, document);
if (!indexExists) {
IndexRequest indexRequest = new IndexRequest(indexName)
.id(document)
.source(jsonStr, XContentType.JSON);
ActionListener listener = new ActionListener() {
public void onResponse(IndexResponse indexResponse) {
log.info("索引"+indexResponse.getIndex()+"--"+indexResponse.getId()+"插入成功");
}
public void onFailure(Exception e) {
e.printStackTrace();
}
};
EsServerManager.getInstance().getClient().indexAsync(indexRequest, RequestOptions.DEFAULT, listener);
}else{
log.info("插入失败"+"索引"+indexName+"--"+document+"--"+"已存在");
}
}
/**
* 根据索引名称和id删除数据,(异步)
* @param indexName 索引名称
* @param document id
* @return 是否删除成功; 索引不存在返货false
*/
public void deleteIndexAsync(String indexName, String document) {
Boolean indexExists = isIndexExists(indexName, document);
if(indexExists) {
final DeleteRequest deleteRequest = new DeleteRequest(indexName, document);
ActionListener listener = new ActionListener() {
public void onResponse(DeleteResponse deleteResponse) {
log.info(deleteResponse.getIndex() + "--" + deleteResponse.getId() + "已删除");
}
public void onFailure(Exception e) {
e.printStackTrace();
}
};
EsServerManager.getInstance().getClient().deleteAsync(deleteRequest, RequestOptions.DEFAULT, listener);
}else {
log.info("索引"+indexName+"--"+document+"不存在");
}
}
/**
* 删除indexName下的所有索引数据,(异步)
* @param indexName 索引名称
* @return 删除是否成功。
*/
public void deleteIndexAsync(String indexName) {
Boolean indexExists = isIndexExists(indexName);
if(indexExists){
final DeleteIndexRequest deleteRequest = new DeleteIndexRequest(indexName);
ActionListener listener = new ActionListener() {
public void onResponse(AcknowledgedResponse AcknowledgedResponse) {
log.info(AcknowledgedResponse.toString());
}
public void onFailure(Exception e) {
e.printStackTrace();
}
};
EsServerManager.getInstance().getClient().indices().deleteAsync(deleteRequest, RequestOptions.DEFAULT, listener);
}else {
log.info("索引"+indexName+"不存在");
}
}
/**
* 根据 index 和 id 更新 索引数据 (异步)
* @param indexName 索引名称
* @param document id
* @param jsonStr 要更新的json
* @return 是否更新成功
*/
public void updateIndexAsync(String indexName, String document, String jsonStr) {
Boolean indexExists = isIndexExists(indexName, document);
if(indexExists) {
final UpdateRequest updateRequest = new UpdateRequest(indexName, document).doc(jsonStr, XContentType.JSON);
ActionListener listener = new ActionListener() {
public void onResponse(UpdateResponse updateResponse) {
log.info("索引" + updateResponse.getIndex() + "--" + updateResponse.getId() + "更新成功");
}
public void onFailure(Exception e) {
e.printStackTrace();
}
};
EsServerManager.getInstance().getClient().updateAsync(updateRequest, RequestOptions.DEFAULT, listener);
}else {
log.info("索引"+indexName+"--"+document+"不存在");
}
}
/**
* 索引重建(同步)。 注意:目标索引需要提前创建好
* @param fromIndex 重新索引的索引名
* @param destIndex 重新索引后的索引名
* @return 新创建的文档数
*/
public Long reIndex(String fromIndex, String destIndex) {
Boolean fromIndexExists = isIndexExists(fromIndex);
Boolean destIndexExists = isIndexExists(destIndex);
Long result = 0L;
if(fromIndexExists && destIndexExists){
ReindexRequest reindexRequest = new ReindexRequest();
reindexRequest.setSourceIndices(fromIndex);
reindexRequest.setDestIndex(destIndex);
reindexRequest.setSourceBatchSize(5000);
reindexRequest.setSlices(5);
BulkByScrollResponse reindexResponse = null;
try {
reindexResponse = EsServerManager.getInstance().getClient().reindex(reindexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
if(reindexResponse != null) {
result = reindexResponse.getCreated();
log.info("时间:"+reindexResponse.getTook());
}
}else {
if(!fromIndexExists){
log.info("fromIndex不存在");
}
if(!destIndexExists){
log.info("destIndex不存在");
}
}
return result;
}
/**
* 索引重建(异步)。 注意:目标索引需要提前创建好
* @param fromIndex 重新索引的索引名
* @param destIndex 重新索引后的索引名
*/
public void reIndexAsync(String fromIndex, String destIndex) {
Boolean fromIndexExists = isIndexExists(fromIndex);
Boolean destIndexExists = isIndexExists(destIndex);
if(fromIndexExists && destIndexExists){
ReindexRequest reindexRequest = new ReindexRequest();
reindexRequest.setSourceIndices(fromIndex);
reindexRequest.setDestIndex(destIndex);
reindexRequest.setSourceBatchSize(1000);
ActionListener actionListener = new ActionListener() {
public void onResponse(BulkByScrollResponse bulkByScrollResponse) {
log.info("新创建的索引数" + bulkByScrollResponse.getCreated());
log.info("更新的索引数"+ bulkByScrollResponse.getUpdated());
log.info("时间:"+bulkByScrollResponse.getTook());
}
public void onFailure(Exception e) {
e.printStackTrace();
}
};
EsServerManager.getInstance().getClient().reindexAsync(reindexRequest, RequestOptions.DEFAULT, actionListener);
}else {
if(!fromIndexExists){
log.info("fromIndex不存在");
}
if(!destIndexExists){
log.info("destIndex不存在");
}
}
}
}
项目中也可以使用JestClient,支持这种JSON格式的查询方式:
在官方的RestClient 基础上,进行了简单包装的Jest客户端,而且该客户端也与springboot完美集成。
application.properties中加入
spring.elasticsearch.jest.uris=http://192.168.67.163:9200
org.springframework.boot
spring-boot-starter-data-elasticsearch
io.searchbox
jest
5.3.3
net.java.dev.jna
jna
4.5.1
@Autowired
JestClient jestClient;
@Test
public void testEs() throws IOException {
String query="{\n" +
" \"query\": {\n" +
" \"match\": {\n" +
" \"actorList.name\": \"张译\"\n" +
" }\n" +
" }\n" +
"}";
Search search = new Search.Builder(query).addIndex("movie_chn").addType("movie").build();
SearchResult result = jestClient.execute(search);
List> hits = result.getHits(HashMap.class);
for (SearchResult.Hit hit : hits) {
HashMap source = hit.source;
System.err.println("source = " + source);
}
}
总结
ElasticSearch作为搜索引擎,在很多的搜索场景下应用的比较广泛。内容相对来说比较简单,但是有点杂,参考目录来看吧。
笨鸟先飞,熟能生巧 ~
本菜鸟QQ:599903582
比心心~