攻防世界 Misc base64stego wp python脚本分析 新手
压缩包打开是加密的,题目没有给其他提示,那么有可能是伪加密
ZIP伪加密
一个ZIP文件由三个部分组成:压缩源文件数据区+压缩源文件目录区+压缩源文件目录结束标志。
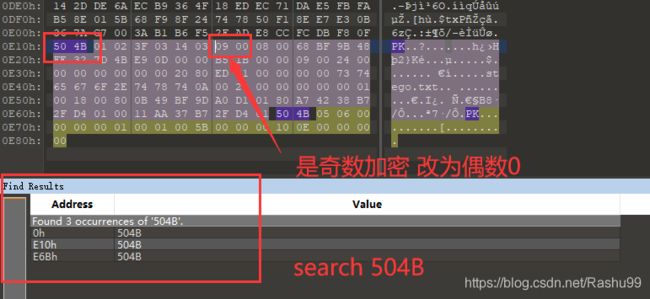
伪加密原理:zip伪加密是在文件头的加密标志位做修改,进而再打开文件时识被别为加密压缩包。 一般来说,文件各个区域开头就是50 4B,然后后面两个字节是版本,再后面两个就是判断是否有加密的关键了。
压缩源文件数据区:
50 4B 03 04:这是头文件标记(0x04034b50)
00 00:全局方式位标记(判断有无加密的重要标志)
压缩源文件目录区:
50 4B 01 02:目录中文件文件头标记(0x02014b50)
00 00:全局方式位标记(有无加密的重要标志,这个更改这里进行伪加密,改为09 00打开就会提示有密码了)
压缩源文件目录结束标志:
50 4B 05 06:目录结束标记
识别真假加密
1.无加密
压缩源文件数据区的全局加密应当为00 00
且压缩源文件目录区的全局方式位标记应当为00 00
2.假加密
压缩源文件数据区的全局加密应当为00 00
且压缩源文件目录区的全局方式位标记应当为09 00
3.真加密
压缩源文件数据区的全局加密应当为09 00
且压缩源文件目录区的全局方式位标记应当为09 00
成功打开以后
有很多=,有可能是
base64隐写
得知base64
6bit编为1字符, 1字节=8bit
因此base64可能会出现3种情况
1、刚刚好,比如3个字节的字符串 3x8=24bit base64加密后有 24/6=4个字符
2、差2bit,比如2x8=16/6 余 4 bit 已经编码了 但还差2bit 才能编成字符 所以得用=补充 默认填0
3、差4bit,比如1x8=8/6 余2bit 还差4bit,所以用 = = 补充
隐写得数据藏在=中,1个= 等于2 bit

代码每行具体分析如下:
import base64
bin_str=''
b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('D://stego.txt','r') as f:
for line in f.readlines():
stegb64="".join(line.split())
rowb64="".join(str(base64.b64encode(base64.b64decode(stegb64)),'utf-8').split())
offset=abs(b64chars.index(stegb64.replace('=','')[-1])-b64chars.index(rowb64.replace('=', '')[-1]))
equalnum=line.count('=')
if equalnum:
bin_str += bin(offset)[2:].zfill(equalnum * 2)
print(''.join([chr(int(bin_str[i:i + 8], 2)) for i in range(0,len(bin_str),8)]))
用with open(…) as … 打开 stego.txt ‘r’ 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
readlines()可以一次读取所有内容并按行返回list , line 每次读取一行内容
join()函数是用来连接字符串,而split()函数是用来拆分字符串
大佬得代码有点看不懂,,为什么[-1] 也可以? 为什么row64 解码完还要再编码一次?
base64的编码解码
python2 :
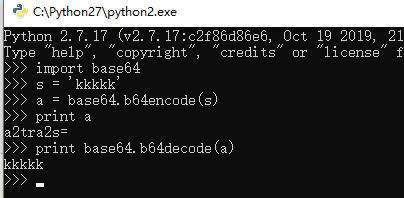
>>> import base64
>>> s = 'kkkkk'
>>> a = base64.b64encode(s)
>>> print a
a2tra2s=
>>> print base64.b64decode(a)
kkkkk
python 3 :
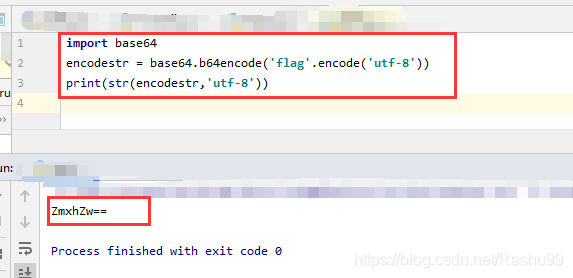
import base64
encodestr = base64.b64encode('flag'.encode('utf-8'))
print(str(encodestr,'utf-8'))
因为3.x中字符都为unicode编码,而b64encode函数的参数为byte类型,所以必须先转码。
合在一起写
print(str(base64.b64encode('flag'.encode('utf-8')),'utf-8'))
a[i:i+1]: = a[i]
a='abcdefghijk'
a[:-1]=k a[:-2]=jk
a.replace('ab',xx) xxcdefghijk
a.replace('jk','') abcdefghi
import base64
a=''
mode=("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/") #mode码表
c=''
f = open("D://stego.txt","r") #读取文件
line = f.readline()
while line:
if("=" in line):
a=line.replace('=','')[-2:] #去掉‘=’留下最后一个字符
# print(a,end="") #这里用来检测是否出错了
num=(line.count('='))*2
c=c+(bin(mode.index(a[0])).replace("0b",'')[-(num):].zfill(num)) #这里是关键,对其进行查表对号,再进行二进制转换筛选
line = f.readline()
else:
line = f.readline()
continue
f.close()
for i in range (0,len(c),8):
print(chr(int(c[i:i+8],2)),end='') #输出
a=line.replace('=','')[-2:] #去掉‘=’
-2是V -3 则是mV -4 则是bmV
a.index('e') 4 将某值的下标打出来 abcde
a.count('e') 1 查询'e'的数量
a.zfill(2) 00abcdefghijk 字符串右对齐,前面填充0
num=(line.count('='))*2 查=的数量 1个= 等于2bit
bin(mode.index(a[0])) 将**数值**转换为二进制输出一个**str**为:0b######
本题中的a[0]=V 对应的下标是21 转换成0b00010101
a[1]=U 20 0b00010100
replace("0b",'')[-(num):] 再去掉0b 取 -2 即01
zfill(num) 右对齐 即0001 = c 循环累加得c
for i in range (0,len(c),8):
print(chr(int(c[i:i+8],2)),end='') 8个一组 二进制转成十进制 输出
Base_sixty_four_point_five chr(66)=B
参考链接
参考链接2
参考链接3