Pandas 初级操作指南
文章目录
-
- 数据结构
- pandas对象创建
- 导入导出
- 查看
- 切片操作
- 缺失值处理
-
- 合并操作
- 分组
首先,导入pandas相关的包
In [1]: import pandas as pd
import numpy as np
数据结构
pandas的数据类型包括 pd.DataFrame 和 pd.Series。
下图是一个典型的DataFrame结构,其主要由三部分组成:列名(列索引)、行索引、值,如下图所示。从 DataFrame 对象中任取一列(如flag列),就是一个 pd.Series 对象。
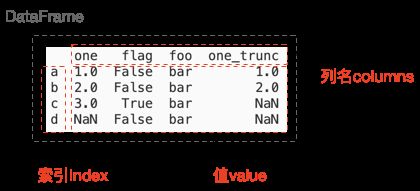
其支持的数据类型包括:
字符型(str)、整型(int)、浮点型(float)、时间类型(datetime64)、布尔型(bool)
注意: NaN默认是float类型
pandas对象创建
pandas支持显式的创建 pd.DataFrame 对象和 pd.Series 对象。值可以是list、nd.array、dict对象,列名和索引通过 columns 和 index 指定。
创建pd.DataFrame 对象:
In [2]: df = pd.DataFrame({
'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'flag': pd.Series([False, False, True, False], index=['a', 'b', 'c', 'd']),
'foo': pd.Series(['bar', 'bar', 'bar', 'bar'], index=['a', 'b', 'c', 'd']),
'one_trunc': pd.Series([1., 2.], index=['a', 'b']),
})
Out[2]:
one flag foo one_trunc
a 1.0 False bar 1.0
b 2.0 False bar 2.0
c 3.0 True bar NaN
d NaN False bar NaN
创建pd.Series 对象,不指定index参数的话,默认为数字索引:
In [3]: pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
Out [3]:
a 0.469112
b -0.282863
c -1.509059
d -1.135632
e 1.212112
dtype: float64
In [4]: df['flag']
Out [4]:
a False
b False
c True
d False
Name: flag, dtype: bool
导入导出
pandas支持的文件格式有很多种,如csv、xlsx、json、html、pickle等…
导入:pd.read_csv、pd.read_excel、pd.read_table、pd.read_html
导出:df.to_csv、df.to_excel、df.to_json、df.to_pickle(path)
查看
可以通过 index 和 columns 属性访问该对象的行列索引。
In [5]: df.index
Out[5]: Index(['a', 'b', 'c', 'd'], dtype='object')
In [6]: df.columns
Out[6]: Index(['one', 'flag', 'foo', 'one_trunc'], dtype='object')
通过 head 和 tail 属性访问pandas对象的头部和尾部,默认展示五行。
In [7]: df.head()
Out[7]:
one flag foo one_trunc
a 1.0 False bar 1.0
b 2.0 False bar 2.0
c 3.0 True bar NaN
d NaN False bar NaN
In [8]: df.tail(3)
Out[8]:
one flag foo one_trunc
b 2.0 False bar 2.0
c 3.0 True bar NaN
d NaN False bar NaN
通过 pandas 内置的函数判断某列的类型,也可以使用 dtypes 属性查看所有列的类型。
In [9]: df.dtypes
Out [9]:
one float64
flag bool
foo object
one_trunc float64
dtype: object
In [10]: from pandas.core.dtypes.common import is_numeric_dtype, is_string_like_dtype, is_bool_dtype, is_datetime_or_timedelta_dtype
In [11]: is_numeric_dtype(df['flag'])
Out[11]: True
通过内置的describe函数可以查看数据的分布情况,默认展示连续列。通过设置include参数,可以查看所有列的详情。
In [12]: df.describe()
Out [12]:
one one_trunc
count 3.0 2.000000
mean 2.0 1.500000
std 1.0 0.707107
min 1.0 1.000000
25% 1.5 1.250000
50% 2.0 1.500000
75% 2.5 1.750000
max 3.0 2.000000
In [13]: df.describe(include='all')
Out [13]:
one flag foo one_trunc
count 3.0 4 4 2.000000
unique NaN 2 1 NaN
top NaN False bar NaN
freq NaN 3 4 NaN
mean 2.0 NaN NaN 1.500000
std 1.0 NaN NaN 0.707107
min 1.0 NaN NaN 1.000000
25% 1.5 NaN NaN 1.250000
50% 2.0 NaN NaN 1.500000
75% 2.5 NaN NaN 1.750000
max 3.0 NaN NaN 2.000000
转置数据:
In [14]: df.T
Out [14]:
a b c d
one 1 2 3 NaN
flag False False True False
foo bar bar bar bar
one_trunc 1 2 NaN NaN
按索引排序:
In [15]: df.sort_index(axis=1, ascending=False)
Out [15]:
one_trunc one foo flag
a 1.0 1.0 bar False
b 2.0 2.0 bar False
c NaN 3.0 bar True
d NaN NaN bar False
按值排序:
In [16]: df.sort_values(by='flag')
Out [16]:
one flag foo one_trunc
a 1.0 False bar 1.0
b 2.0 False bar 2.0
d NaN False bar NaN
c 3.0 True bar NaN
切片操作
切片操作主要用于访问pandas对象中的指定部分,如某列、某行或者某个子范围。
可以采用类似 C语言、matlab 之类的索引访问方式。由于 pandas 支持的索引可以是编号索引,也可以是用户指定的字符索引。所以
- df.loc 通过行/列 编号索引 获取指定行/列的数据
- df.iloc通过行/列 字符索引 获取指定行/列的数据 iloc --> index location
访问单列:
In [17]: df['one']
Out [17]:
a 1.0
b 2.0
c 3.0
d NaN
Name: one, dtype: float64
访问行:
In [18]: df[0:3]
Out [18]:
one flag foo one_trunc
a 1.0 False bar 1.0
b 2.0 False bar 2.0
c 3.0 True bar NaN
In [19]: df['a':'b']
Out [19]:
one flag foo one_trunc
a 1.0 False bar 1.0
b 2.0 False bar 2.0
访问名称访问:
In [20]: df.loc[:, ['one', 'foo']]
Out [20]:
one foo
a 1.0 bar
b 2.0 bar
c 3.0 bar
d NaN bar
In [21]: df.loc['b':'d', ['one', 'foo']]
Out [21]:
one foo
b 2.0 bar
c 3.0 bar
d NaN bar
访问位置访问:
In [22]: df.iloc[3] # 取第三行的数据:
Out [22]:
one NaN
flag False
foo bar
one_trunc NaN
Name: d, dtype: object
In [23]: df.iloc[2:3, 0:2]
Out [23]:
one flag
c 3.0 True
In [24]: df.iloc[[0, 2, 3], [0, 2]]
Out [24]:
one foo
a 1.0 bar
c 3.0 bar
d NaN bar
bool型索引:
In [25]: df[df['one'] > 2]
Out [25]:
one flag foo one_trunc
c 3.0 True bar NaN
缺失值处理
pandas一般采用 np.nan 代表缺失值。
删除包含缺失值的列:
In [26]: df.dropna(how='any')
Out [26]:
one flag foo one_trunc
a 1.0 False bar 1.0
b 2.0 False bar 2.0
填充缺失值
In [27]: df.fillna(value=5)
Out [27]:
one flag foo one_trunc
a 1.0 False bar 1.0
b 2.0 False bar 2.0
c 3.0 True bar 5.0
d 5.0 False bar 5.0
获取缺失值所处位置的二值掩模:
In [28]: pd.isna(df)
Out [28]:
one flag foo one_trunc
a False False False False
b False False False False
c False False False True
d True False False True
合并操作
pandas提供多种方式合并 series 和 dataframe 对象。
串联两个pandas对象:concat
df = pd.DataFrame(np.random.randn(10, 4))
In [29]: df
Out[29]:
0 1 2 3
0 -0.548702 1.467327 -1.015962 -0.483075
1 1.637550 -1.217659 -0.291519 -1.745505
2 -0.263952 0.991460 -0.919069 0.266046
3 -0.709661 1.669052 1.037882 -1.705775
4 -0.919854 -0.042379 1.247642 -0.009920
5 0.290213 0.495767 0.362949 1.548106
6 -1.131345 -0.089329 0.337863 -0.945867
7 -0.932132 1.956030 0.017587 -0.016692
8 -0.575247 0.254161 -1.143704 0.215897
9 1.193555 -0.077118 -0.408530 -0.862495
In [30]: pd.concat([df[:3], df[3:7], df[7:]])
Out[30]:
0 1 2 3
0 -0.548702 1.467327 -1.015962 -0.483075
1 1.637550 -1.217659 -0.291519 -1.745505
2 -0.263952 0.991460 -0.919069 0.266046
3 -0.709661 1.669052 1.037882 -1.705775
4 -0.919854 -0.042379 1.247642 -0.009920
5 0.290213 0.495767 0.362949 1.548106
6 -1.131345 -0.089329 0.337863 -0.945867
7 -0.932132 1.956030 0.017587 -0.016692
8 -0.575247 0.254161 -1.143704 0.215897
9 1.193555 -0.077118 -0.408530 -0.862495
以 sql 风格合并:merge
In [82]: left = pd.DataFrame({
"key": ["foo", "bar"], "lval": [1, 2]})
In [83]: right = pd.DataFrame({
"key": ["foo", "bar"], "rval": [4, 5]})
In [84]: left
Out[84]:
key lval
0 foo 1
1 bar 2
In [85]: right
Out[85]:
key rval
0 foo 4
1 bar 5
In [86]: pd.merge(left, right, on="key")
Out[86]:
key lval rval
0 foo 1 4
1 bar 2 5
另一个例子如下:
In [31]: left = pd.DataFrame({
"key": ["foo", "foo"], "val": [1, 2]})
In [32]: right = pd.DataFrame({
"key": ["foo", "foo"], "val": [4, 5]})
In [33]: left
Out[33]:
key val
0 foo 1
1 foo 2
In [34]: right
Out[34]:
key val
0 foo 4
1 foo 5
In [35]: pd.merge(left, right, on="key")
Out[35]:
key lval1_x lval1_y
0 foo 1 4
1 foo 1 5
2 foo 2 4
3 foo 2 5
分组
按某些列进行分组并统计:
In [30]: df.groupby('flag').sum()
Out [30]:
one one_trunc
flag
False 3.0 3.0
True 3.0 0.0
In [31]: df.groupby(['flag', 'one']).sum()
Out [31]:
one_trunc
flag one
False 1.0 1.0
2.0 2.0
True 3.0 0.0