BIGO技术 | 万亿模型参数的训练
*本文转载自 BIGO技术 公众号,对BIGO技术感兴趣的同学可以关注了解更多内容~
一、推荐场景特征稀疏性
推荐场景通常由于引入了大量的ID类特征从而导致存在海量稀疏参数,例如下图经典YouTube DNN模型中,使用用户观看过的视频以及用户历史search tokens作为主要Embedded特征。根据论文中论述,YouTube DNN中candidate video以及search tokens均有百万之巨。在此基础上如果再使用交叉特征,就会使参数爆炸问题进一步加剧。
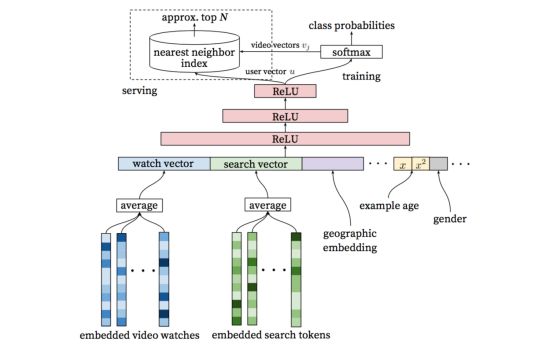
图1 YouTube DNN
在BIGO推荐场景主模型的稀疏参数也已经近万亿,即使按照FP16存储也要消耗近1T的内存空间。BIGO机器学习平台团队针对推荐场景建设了大规模稀疏参数的训练系统,通过参数服务器的深度优化,双图训练,精细化的特征准入和退出策略,自动统计特征,异构硬件平台下的在线预估性能调优,在模型训练,模型交付,在线预估缓解下完整的解决了参数维度爆炸问题,本文主要介绍我们的一些实践和技术思考。
二、参数服务器
万亿级参数的模型训练首先要解决参数通信问题,Ring-AllReduce和独立参数服务器是业界两种主流的参数通信模式。
Ring-AllReduce方式将Parameter Server和Worker合为一个实例。训练过程中,每个实例直接利用本地完整参数副本进行Forward和Backprop计算,有以下特点:
1、单个实例可存储完整参数;
2、要求采用参数同步更新机制,适合对训练速度要求不高但每次Mini-Batch梯度需高精度更新的场景;
3、在N个设备,数据总量K情况下。每个设备在Scatter Reduce阶段,接收N-1次数据,在All Gather 阶段,接收N-1次数据。每个设备每次发送 K/N 大小数据块。故总数据传输量=2(N−1)*K/N,随着设备数量 N 增加,总传输量为恒定。
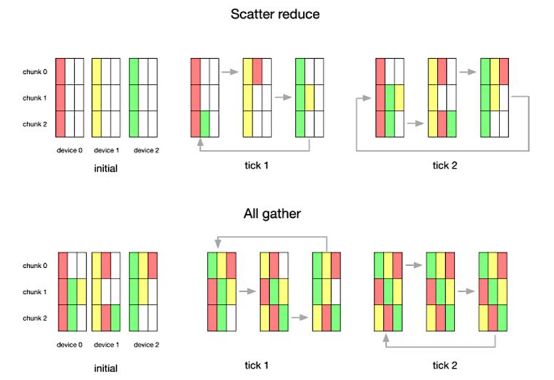
图2 Ring-AllReduce过程示意图
参数服务器(Parameter Server)将参数的存储和更新上升为一个独立的角色,即在分布式调度时Parameter Server与Worker角色分别对应为不同的实例,与Ring-AllReduce相对应有如下特点:
1、支持海量稀疏参数。整体参数经过Sharding后分别存储在不同Parameter Server实例上;
2、支持同步和异步两种参数更新方式;
3、每次Mini-Batch开始时,各个Worker从Parameter Server拉取本次迭代所需参数片段做Forward计算。Backprop时把相应参数梯度推送到Parameter Server上。
在推荐场景存在海量稀疏参数,单个实例不足以存储完整参数,同时推荐场景每天可以产出高达几十T的训练样本,对模型时效性有较高要求,但对每次Mini-Batch梯度更新精度容忍度高,因此参数异步更新方式更为适用。另外由于其参数稀疏性,每次迭代只会涉及极少量参数的梯度更新,采用Ring-AllReduce参数整体更新方式性价比低。综合考虑BIGO采用了独立参数服务器的架构。
在确定使用参数服务器并行计算模式后,我们调研发现现有的TensorFlow,MXNet以及PyTorch等框架都是面对图像、语音等领域,针对稠密数据特征设计的,对广告、推荐等高度稀疏数据的计算实现考虑并不完备。
最终我们确定工作重心是利用具备稠密数据计算能力的开源框架,打造适合推荐/广告场景的工业级稀疏数据训练框架。该训练框架是分布式架构,拥有易用性更好、扩展性更强的参数服务器。同时单Worker内通过适配层,嵌入TensorFlow, MXNet等开源框架稠密计算能力。
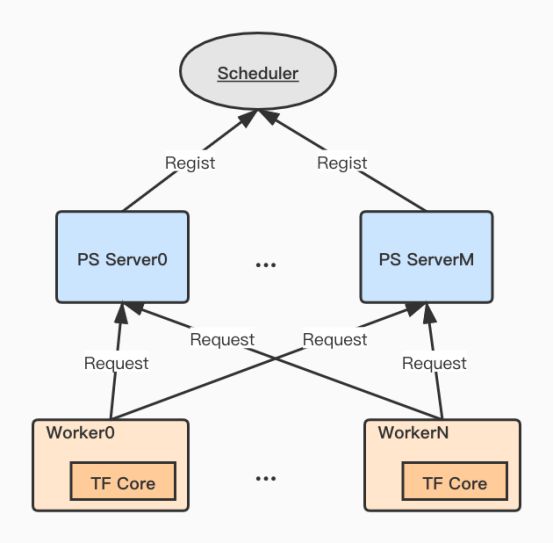
图3 BIGO推荐分布式训练架构
1、参数分配
在训练之前,通常无法对每路Embedding参数未来规模进行预估, 因此基于提前参数规模预估所做参数存储分布优化并不现实。此外在实际训练中,由于受不同时期样本分布的影响, 各个Parameter Server实例负载长期难以保持均衡。参数分布不均匀,会导致计算出现严重倾斜,影响整体任务的运行效率。在参数服务器的早期设计中,我们就重点关注了参数分配的优化。
在Scheduler启动时,会根据本次申请的Parameter Server的个数对Feature ID进行分桶,算出每个Parameter Server负责的ID范围。模型加载以及特征新增时,Feature ID经Hash后按Parameter Server个数取余能够均匀落在各个桶中,保证了各个Parameter Server长期负载均衡。每个Parameter Server的容量可以根据存储参数大小进行动态增长。
2、动态增长
在单个Parameter Server内部,我们使用独立HashTable来存储每路 Embedding的权重分片, 其负责的Feature ID 范围由上节介绍的参数分配环节所确定。首先使用无锁HashMap管理特征ID到存储行号的映射。其次使用无锁Vector来管理真正用于存储Embedding 权重分片的Blocks。整体采用预分配机制,即当存储空间不够时,申请一个新的Block用于新增存储,Block大小通常为1024 * Embedding Dim大小。
3、请求合并
按照上小节介绍的方法把每路Embedding均匀分配到Parameter Server后,每次迭代过程中,单个Worker请求Parameter Server拉取每路Embedding最新权重,都需要向每个Parameter Server发送Pull请求。例如有m路Embedding,n个Parameter Server,则需要发送m*n个RPC请求。当Worker数超过100后训练速度很难提升。针对这种情况,我们做了如下的优化:当Worker请求Parameter Server拉取最新Embedding权重时,自动对计算图中依赖关系进行分析,合并无依赖的请求,把发往每个Parameter Server k个请求进行合并,实现批量拉取Embedding最新权重。请求量由k*n降为n。
4、性能优化
通过分析发现CPU主要有并发同步,数据复制以及系统调用时上下文切换三大类开销。
首先并发编程的难点在于如何处理数据共享。优化并发同步开销,一般思路为减小临界区以及降低锁开销。这样优化下来的代码往往异常复杂,可维护性不高。BIGO Parameter Server内部采用Shared-Nothing并发范式。每个CPU核固定绑定一个线程,不同CPU核之间完全禁止数据共享,只允许通过消息队列进行通信。可以理解为每个CPU核均被抽象为一台单核处理器。同时,用户的请求被拆解为若干个Task,这些Task按照前后依赖关系构成DAG图。CPU按照拓扑顺序执行DAG图中TASK完成宏观用户请求。与此同时,每个CPU核上运行一个轻量调度器,用于Task调度。用户态执行控制流可以有效地降低上下文切换以及数据并发同步的开销。
与之对应的是,在Parameter Server启动时,会分配给每个CPU核独有的一段虚拟地址空间。每个CPU 核在自己内存块中进行内存分配与释放,进一步避免数据并发同步。
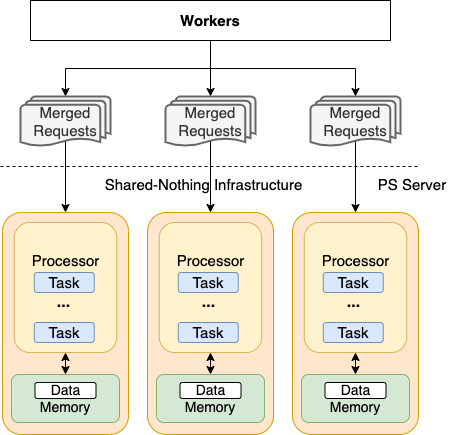
图4 Shared-Nothing框架
另一方面,后两类属于操作系统内核抽象带来的固有开销,不能完全避免,只能尽量减少对内核操作的依赖。我们使用用户态TCP/IP栈和DPDK技术,实现了网络操作方面的Zero Copy 以及Zero Switch。
3、参数服务器小结
经过上面改造,简化了用户使用成本,不再需要预估Embedding参数大小, 同时也避免定期做Rebalance。在高达万亿稀疏参数场景下,Parameter Server水平扩容能力得到了保证,600 Worker实例以下可以达到线性提升,保存和加载模型速度也有将近3倍的提升。
三、双图训练
深度学习模型将Embedding层与深度网络层整体训练是理论上的最优选择,其与预训练Embedding的方式相比,反向传播过程贯穿整个模型,可以让Embedding层参数更好的拟合学习目标,然而在实际训练中我们却遇到了网络参数过拟合的问题。
在推荐场景实际分布式训练过程中,要求每次随机梯度下降过程中训练样本是独立同分布(i.i.d.)的。为了保证这点,原始训练样本在进训练之前会进行全局shuffle,从而整体训练样本时间的正序性已被打乱,会存在训练先遇到“未来”样本的现象。与此同时基于记忆的推荐模型会记住“未来”样本信息,造成整体网络参数过拟合。
1、双图训练
我们针对此问题实现了基于双图的训练方案:
1、图0和图1并行迭代训练样本;
2、图0固定Embedding层,训练深度神经网络参数;
3、图1网络整体参与梯度下降更新;
4、图0和图1网络参数和Embedding层均隔离,可以认为是另一副本;
5、最终模型由图0中深度网络参数部分以及图1中Embedding层权重部分构成。
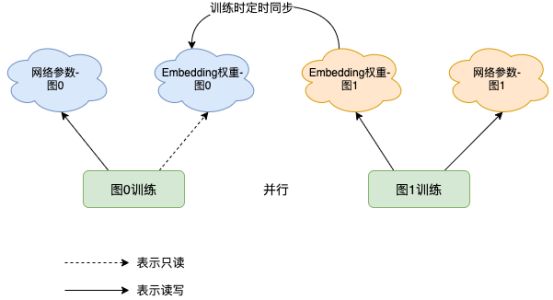
图5 双图训练
每次训练任务开始,加载上次训练任务的模型产出:网络参数部分各自加载对应图的产出, Embedding层权重部分均加载图1的产出。在图0训练中,Embedding层参数不参与梯度反向传播,即使训练样本是乱序的,Embedding层并不会记住未来的信息。整个网络训练过程中受乱序样本影响可忽略,能够有效避免过拟合现象。在图1训练中,整个网络一起参与梯度反向传播,Embedding层权重得到更新。
双图训练方案能够保证Embedding层和深度学习网络结构天然契合。同时避免了乱序样本带来统计特征过拟合问题。采用双图训练方案后,推荐模型普遍能有线上预测AUC +0.5%的收益。
四、特征准入&退出
推荐场景低频的ID类特征同样会给系统带来过拟合的风险,针对这个问题,我们设计了特征准入/退出机制策略,方便根据具体模型预设的表达能力,调整低频稀疏参数对模型的影响。
1、特征准入
训练框架会对新特征设置特征准入的“门槛”来防止低频特征频繁的出入。我们提供了两种机制来限定新增特征准入:
-
概率新增,每次遇到新增特征时,根据预设分布生成概率,控制特征准入;
-
使用Counting Bloom Filter对新增特征出现次数进行统计,当次数超过阈值时,准入。
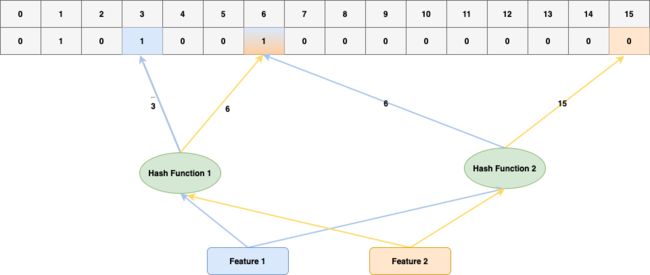
图6 基于Counting Bloom Filter统计特征频率
上图简要描述了CBF的原理,假设容量是16,两个hash函数用作Feature ID到Index的映射。查询特征频率时,Feature1经过Hash Function1和 Hash Function2分别得到Slot 3和 Slot 6,两个Slot值均为1,Feature出现次数可以认为是1。Feature2经过Hash Function1和 Hash Function2分别得到Slot 6和 Slot 15。两个Slot值分别为1和0,Feature2出现次数可以认为是0。即映射到所有Slot中 Value最小值。
2、特征退出
对于已经准入的特征,提供以下三种方式判断是否处于低频状态:
1、更新时间。如果一个特征长时间没有被更新,认为已经处于低频状态;
2、L2范数。如果一个特征L2范数计算结果过小,认为已经处于低频状态;
3、统计值综合得分。支持用户提供自定义函数,通过特征统计值(曝光数,点击数,点赞数,评论数等)来计算特征综合分数,分数小于阈值认为处于低频状态。
被判定处于低频状态的特征会被淘汰屏蔽,下次再次出现时会被当做新特征对待。
使用特征准入&退出后,推荐模型普遍能够减少到未使用时四分之一大小,线上预测AUC在千分位保持持平。
五、自动统计特征
在上篇Likee深度推荐模型的特征工程优化中,曾经介绍过将统计信息从流式任务移到模型中的优点:支持灵活对交叉特征进行统计,提供了模型细粒度建模能力。再者BIGO推荐从早期XGB时代沿袭下来大量的统计类特征需求,流式系统需要记录大量的统计状态。一旦事件打点延迟或者流式集群出现抖动,不精确的统计数据会直接干扰模型,导致线上模型效果坍塌。
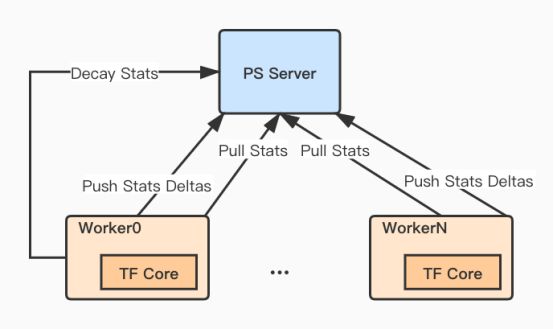
图7 统计特征更新和衰减
与普通Embedding相同,自动统计特征也是以Feature ID作为统计对象实体。在每次mini-batch训练之前,Worker向PS发送请求获取当前统计特征值(初始值为0),根据当前mini-batch中每条样本的UserActions计算相应统计特征值Delta。UserActions为具体标识样本(Label1, Label2, Label3... )元组。Worker0会在固定时间间隔向PS发送统计值衰减的请求,达到弱化统计历史积累影响。
Embedding特征在每次Backprop中基于梯度进行小幅度更新,随着特征曝光次数的增加能够学到更加精细全面的信息。与之相对,自动统计特征是对特征Label频率统计,在特征曝光次数较少情况下,也能做到快速收敛。交叉特征往往曝光次数极低,使用自动统计特征能够更好地弥补Embedding在此方面捕捉信息能力不足的问题。
1、衰减
推荐场景需要获取滑动变长时间窗口统计特征值。例如统计Video分别在最近一小时,最近一天,最近三天,最近7天等的评论数。我们支持多时间衰减率来近似模拟不同时间窗口的聚合效果。计算统计值衰减率公式为:
其中time_window为统计时间窗口(例如一天),decay_interval标明Worker0每经过多长时间间隔通知PS进行衰减。
六、总结
BIGO推荐场景模型的稀疏参数规模从百亿上升到万亿级别,这对分布式训练和预估平台提出相当大的挑战,经过一年多的技术建设,BIGO终于获得了万亿参数规模的模型训练,交付和在线预估的完整技术能力。本文中主要从参数服务器设计和优化,双图训练,特征准入和退出,自动统计特征的五个技术点对BIGO推荐场景分布式训练平台做了简要的介绍,后续还将分享万亿模型参数的在线预估,敬请期待。
版权声明
转载本网站原创文章需要注明来源出处。因互联网客观情况,原创文章中可能会存在不当使用的情况,如文章部分图片或者部分引用内容未能及时与相关权利人取得联系,非恶意侵犯相关权利人的权益,敬请相关权利人谅解并联系我们及时处理。