Python进阶三:python好用到哭的几个高阶内置函数以及迭代器和Collections的两个常用类
1. 写在前面
今天整理python里面5个常用的高阶函数(filter, map, reduce, reversed, sorted)和三个迭代器函数(iter, next, enumerate), 然后是辨析迭代器, 生成器, 可迭代对象三个概念名词, 最后整理python的几个好用迭代器(accumulate, compress, dropwhile, takewhile, tee, repeat, product, zip_longest) , 经过这次的学习, 可以在以后的编程中写出比较高效和优雅的代码。 比如给定m, 计算res = 1! + 2! + 3!...+m!, 我们之前可能是先写一个求阶乘的函数,并且可能求阶乘还写的比较复杂, 然后再进行从1-m遍历相加, 而有了reduce和map之后,就可以这样写:
# 输入一个数m, 求1! + 2! + ....m-1! + m!的结果
# 写一个求阶乘函数
def jiecheng(n):
return reduce(lambda x, y: x*y, range(1, n+1))
#def res(m):
def res(m):
return sum(list(map(lambda x:jiecheng(x),list(range(1, m+1)))))
res(10)
所以有时候还是非常方便的, 并且如果再知道累积迭代器的话,上面的代码就会更加简单:
from itertools import *
def res(m):
return sum(list(accumulate([i for i in range(1, m+1)], lambda x, y: x*y)))
res(10)
这次依然是从使用的角度出发, 先用起来, 然后再去追求所以然吧。
大纲如下:
- 5个常用的高阶函数
- 3个迭代器函数
- 8个常用的迭代器、
- 2个Collections里面的常用类
Ok, let’s go!
2. 5个常用的高阶函数
主要包括filter, map, reduce, reversed, sorted和iter, next, enumerate等。这些函数在python幕后的不为人知(二)中也有介绍:
-
filter(function, iterable)
过滤器, 过滤掉不满足函数function的元素, 重新返回一个新的迭代器。 大概等价于下面的自定义函数:def filter_self(function,iterable): return iter([ item for item in iterable if function(item)])filter_self 函数接收一个 function 作为参数,满足条件的元素才得以保留。比如下面的这个例子:
# 筛选出满足指定身高的学生。其条件是,男生身高超过 1.75,女生身高超过 1.65。 class Student(): def __init__(self, name, sex, height): self.name = name self.sex = sex self.height = height def height_condition(stu): if stu.sex == 'male': return stu.height > 1.75 else: return stu.height > 1.65 students = [Student('xiaomng', 'male', 1.74), Student('xiaohong', 'female', 1.68), Student('xiaoli', 'male', 1.8)] students_satisfy = filter(height_condition, students) for stu in students_satisfy: print(stu.name)如果这个例子比较遥远, 可以看一个筛选回文数字的例子, 这个在算法题中可是非常容易见到:
def is_palindrome(n): return str(n) == str(n)[::-1] output = filter(is_palindrome, range(1, 1000)) print('1~1000:', list(output)) -
map(function, iterable, …)
它将 function 映射于 iterable 中的每一项,并返回一个新的迭代器。mylst = [1, 3, 2, 4, 1] result = map(lambda x: x+1, mylst) list(result) # [2, 4, 3, 5, 2]上面代码就实现了列表的每个元素加1, 如果再天真的想为啥这么麻烦? 我直接
mylst+1实现每个元素加1不就行了? please这里是列表, 不是numpy数组, 列表和1是不能直接运算的。下面这个例子可能更加看到numpy的优势:# 借助map函数, 还能实现向量之间的运算 lst1 = [1, 2, 3, 4, 5, 6] lst2 = [3, 4, 5, 6, 3, 2] def vector_add(x, y): return list(map(lambda i, j: i+j, x, y)) vector_add(lst1, lst2) # 这个可以实现两个列表对应元素相加 ## 而如果是 lst1 + lst2 # [1, 2, 3, 4, 5, 6, 3, 4, 5, 6, 3, 2] 会是列表的元素发生改变 lst1 = [1, 2, 3, 4, 5, 6] lst3 = [1, 2] vector_add(lst1, lst3) # [2, 4]同时注意到,map 函数支持传入多个可迭代对象。当传入多个可迭代对象时,输出元素个数等于较短序列长度。也能够发现, python列表之间是不能够直接进行数字之间的运算的, 所以后来才有了numpy, 实现各种向量, 矩阵之间的运算等。
下面的一个实例是给定两个列表, 找出第一个列表的元素为奇数, 第二个列表对应位置为偶数的那些位置。# 找出同时满足第一个列表的元素为奇数, 第二个列表对应位置的元素为偶数的位置 xy = map(lambda x, y: x%2==1 and y%2==0, [1, 3, 2, 4, 1], [3, 2, 1, 2]) list(xy) # [False, True, False, False] -
reduce(function, iterable[, initializer])
提到 map,就会想起 reduce,前者生成映射关系,后者实现归约。reduce 函数位于functools模块中,使用前需要先导入。reduce 函数中第一个参数是函数 function。function 函数,参数个数必须为 2,是可迭代对象 iterable 内的连续两项。计算过程,从左侧到右侧,依次归约,直到最终为单个值并返回。 这个函数求阶乘, 累加啥的就特别方便。from functools import reduce reduce(lambda x, y: x*y, list(range(1, 6))) # 这样直接可以求阶乘 reduce(lambda x, y: x+y, list(range(1, 101))) # 这样可以直接实现累加 -
reversed(seq)
重新生成一个反向迭代器,对输入的序列实现反转。这个比较简单。rev = reversed([1, 4, 2, 3, 1]) list(rev) # 列表的逆序 -
sorted(iterable,
*, key=None, reverse=False)
实现对序列化对象的排序, key 参数和 reverse 参数必须为关键字参数,都可省略。a = [1, 4, 2, 3, 1] sorted(a, reverse=True) # [4, 3, 2, 1, 1] # 如果可迭代对象的元素也是一个复合对象,如下为字典。依据依据为字典键的值,sorted 的 key 函数就会被用到。 a = [{ 'name': 'xiaoming', 'age': 20, 'gender': 'male'}, { 'name': 'xiaohong', 'age':18, 'gender':'female'}, { 'name':'xiaoli', 'age': 19, 'gender': 'male'}] b = sorted(a, key=lambda x: x['age'], reverse=True) b ## 结果: [{ 'name': 'xiaoming', 'age': 20, 'gender': 'male'}, { 'name': 'xiaoli', 'age': 19, 'gender': 'male'}, { 'name': 'xiaohong', 'age': 18, 'gender': 'female'}]
3. 3个迭代器函数
-
iter(object, [sentinel])
返回一个严格意义上的迭代器,关于迭代器和可迭代对象, 还是有区别的, 后面会具体说, 这里iter的作用是可以把一个可迭代对象变成迭代器, 其中,参数 sentinel 可有可无。lst = [1, 3, 5] it = iter(lst) it.__next__() # 1 it.__next__() # 3只要 iterable 对象支持可迭代协议,即自定义了
iter函数,便都能配合for依次迭代输出其元素。class TestIter(object): def __init__(self): self._lst = [1, 3, 2, 3, 4, 5] # 支持迭代协议(即定义有__iter__()函数) def __iter__(self): print('__iter__ is called!!') return iter(self._lst) # 所以, 对象t能结合for, 迭代输出元素 t = TestIter() for e in t: print(e) -
next(iterator, [, default])
返回迭代器对象的下一个元素it = iter([5, 3, 4, 1]) next(it) # 5下面可以下一个递减迭代器, 通过循环语句, 对某个正整数, 依次递减1, 直到为0
from collections.abc import Iterator class Decrease(Iterator): def __init__(self, init): self.init = init def __iter__(self): return self def __next__(self): while 0 < self.init: self.init -= 1 return self.init raise StopIteration descend_iter = Decrease(6) for i in descend_iter: print(i) -
enumerate(iterable, start=0)
enumerate 是很有用的一个内置函数,尤其要用到列表索引时。它返回可枚举对象,也是一个迭代器。s = ['a', 'b', 'c'] for i, v in enumerate(s): print(i, v)
4. 8个常用的迭代器
再介绍这个之前, 先理一理可迭代对象, 迭代器和生成器之间的关系, 可迭代对象是Iterable, 表示可以直接通过for循环进行遍历的数据类型, 像列表, 字典, 集合,字符串, 迭代器等, 这些都是Iterable, 所以这个范围是更大的, 而迭代器是Iterator, 是Iterable的其中一种, 和列表这些处于并列, 但是又有些不同, 迭代器类似于一个容器一样的, 不能像列表那样直接print出来, 而是必须得一个元素一个元素的去拿,并且无法通过len看到迭代器的长度。 而生成器又是迭代器里面的一个分支, 带有yield的函数我们叫做生成器。 具体的分析在python幕后的不为人知(二), 这里放个图:
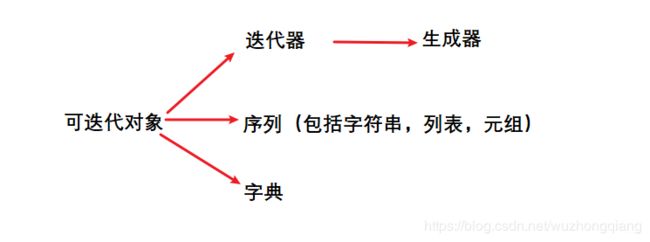
下面具体看看迭代器和列表的区别:
from collections.abc import Iterable, Iterator
a = [1, 3, 5, 7] # 这是一个列表
isinstance(a, Iterable) # True
isinstance(a, Iterator) # False
# 可以看到a是一个可迭代对象, 但是并不是一个迭代器, 那么如何把a变成迭代器呢
a_iter = iter(a)
isinstance(a_iter, Iterator) # True 就是iter函数
# 这时候, 我们可以进行for循环遍历
for i in a:
print(i)
for j in a_iter:
print(j)
## 结果如下:
1
3
5
7
1
3
5
7
会发现, 这俩的结果是一样的, 但是如果再来一遍:
for i in a:
print(i)
for j in a_iter:
print(j) # 就会发现这个输出不出东西了
## 结果:
1
3
5
7
就会发现, 迭代器这个输出不出东西了, 这是因为迭代器这个到头了。 这就是列表 a 和迭代器 a_iter 的区别:
- 列表不论遍历多少次,表头位置始终是第一个元素;
- 迭代器遍历结束后,不再指向原来的表头位置,而是为最后元素的下一个位置。
只有迭代器对象才能与内置函数 next 结合使用,next 一次,迭代器就前进一次,指向一个新的元素。所以,要想迭代器 a_iter 重新指向 a 的表头,需要重新创建一个新的迭代 a_iter_copy:调用 next,输出迭代器指向 a 的第一个元素, 这时候就会发现后面的tee克隆迭代器的作用。
a_iter_copy = iter(a)
next(a_iter_copy) # 1
next(a) # 'list' object is not an iterator
值得注意,我们无法通过调用 len 获得迭代器的长度,只能迭代到最后一个末尾元素时,才知道其长度。到了末尾, 会发生迭代器结束异常, 所以可以通过捕获此异常来获得迭代器的长度。
a = [1, 3, 5, 7]
a_iter_copy2 = iter(a)
iter_len = 0
try:
while True:
i = next(a_iter_copy2)
print(i)
iter_len += 1
except StopIteration:
print('iterator stops')
print('length of iterator is %d' % (iter_len))
## 结果如下:
1
3
5
7
iterator stops
length of iterator is 4
以上总结:遍历列表,表头位置始终不变;遍历迭代器,表头位置相应改变;next 函数执行一次,迭代对象指向就前进一次;StopIteration 触发时,意味着已到迭代器尾部。
带 yield 的函数是生成器,而生成器也是一种迭代器。所以,生成器也有上面那些迭代器的特点。 那么生成器的一个好处就是可以节省内存, 下面依然是开头给出的那个例子, 给定m, 求出res = 1!+2!+…m!。
def accumulate_mul(a):
if a is None or len(a) == 0:
return []
rtn = [a[0]]
for i in a[1:]:
rtn.append(i*rtn[-1])
return rtn
rtn = accumulate_mul([i for i in range(1, m+1)])
sum(rtn)
这个的内存消耗是O(m), 而如果换成生成器, 会是O(1)的空间复杂度。
def accumulate_mul1(a):
if s is None or len(a) == 0:
return []
it = iter(a)
total = next(it)
yield total
for i in it:
total *= i
yield total
sum(list(accumulate_mul1([i for i in range(1, m+1)])))
所以以后能用生成器的时候, 尽量尝试使用生成器,这时候的代码才更加高效。
好了, 铺垫结束, 下面整理来自itertools包里面的几个好用的迭代器, 可是好用到哭,并且他们内部都是采用了生成器的写法,比较高效。
-
拼接迭代器(chain)
这个实现元素的拼接。from itertools import * # 拼接迭代器 chain(*iterables): 实现元素拼接 chain_iterator = chain(['I', 'love'], ['python'], ['very', 'much']) list(chain_iterator) # ['I', 'love', 'python', 'very', 'much']内部实现:
def chain(*iterables): for it in iterables: for element in it: yield element # chain 是一个生成器函数,在迭代时,每次吐出一个元素,所以做到最高效的节省内存。 -
累积迭代器(accumulate)
accumulate(iterable[, func, *, initial=None]):默认是求累积和accu_iterator = accumulate([1, 2, 3, 4, 5, 6]) list(accu_iterator) # [1, 3, 6, 10, 15, 21] # 累积乘 accu_iterator1 = accumulate([1, 2, 3, 4, 5, 6], lambda x, y: x*y) list(accu_iterator1) # [1, 2, 6, 24, 120, 720]内部实现:
def accumulate(iterable, func=operator.add, *, initial=None): it = iter(iterable) total = initial if initial is None: try: total = next(it) except StopIteration: return yield total for element in it: total = func(total, element) yield total -
漏斗迭代器(compress)
compress 函数,功能类似于漏斗功能,所以称它为漏斗迭代器,原型:compress(data, selectior), 经过 selectors 过滤后,返回一个更小的迭代器。compress_iter = compress('abcdefg', [1, 1, 0, 1, 0, 1]) list(compress_iter) # ['a', 'b', 'd', 'f']内部实现:
def compress(data, selectors): return (d for d, s in zip(data, selectors) if s) -
drop迭代器
扫描可迭代对象 iterable,从不满足条件处往后全部保留,返回一个更小的迭代器。dropwhile(predicate, iterable)drop_iterator = dropwhile(lambda x: x<3, [1, 0, 2, 4, 1, 1, 3, 5]) list(drop_iterator) # [4, 1, 1, 3, 5]内部实现:
def dropwhile(predicate, iterable): iterable = iter(iterable) for x in iterable: if not predicate(x): yield x break for x in iterable: yield x -
take迭代器
扫描列表,只要满足条件就从可迭代对象中返回元素,直到不满足条件为止,原型如下:takewhile(predicate, iterable)take_iterator = takewhile(lambda x: x<5, [1, 4, 5, 4, 1]) list(take_iterator) # [1, 4]内部实现:
def takewhile(predicate, iterable): for x in iterable: if predicate(x): yield x else: break #立即返回 -
克隆迭代器(tee)
tee 实现对原迭代器的复制,原型如下:tee(iterable, n=2)a = tee([1, 4, 6, 4, 1], 2) print(a[0], a[1]) #内部实现:
from collections import deque def tee(iterable, n=2): it = iter(iterable) deques = [deque() for i in range(n)] def gen(mydeque): while True: if not mydeque: try: newval = next(it) except StopIteration: return for d in deques: d.append(newval) yield mydeque.popleft() return tuple(gen(d) for d in deques) -
复制元素
repeat 实现复制元素 n 次,原型如下:repeat(object[, times])list(repeat(6, 3)) list(repeat([1, 2, 3], 2)) # [[1, 2, 3], [1, 2, 3]]内部实现:
def repeat(object, times=None): if times is None: while True: yield object else: for i in range(times): yield object -
笛卡尔积
list(product('ABCD', 'xy')) [('A', 'x'), ('A', 'y'), ('B', 'x'), ('B', 'y'), ('C', 'x'), ('C', 'y'), ('D', 'x'), ('D', 'y')] -
加强版zip
若可迭代对象的长度未对齐,将根据 fillvalue 填充缺失值,返回结果的长度等于更长的序列长度。list(zip_longest('ABCD', 'xy', fillvalue='-')) [('A', 'x'), ('B', 'y'), ('C', '-'), ('D', '-')]内部实现:
def zip_longest(*args, fillvalue=None): iterators = [iter(it) for it in args] num_active = len(iterators) if not num_active: return while True: values = [] for i, it in enumerate(iterators): try: value = next(it) except StopIteration: num_active -= 1 if not num_active: return iterators[i] = repeat(fillvalue) value = fillvalue values.append(value) yield tuple(values)
5. 2个Colections里面的常用类
下面介绍两个collections里面的常用类Counter和defaultdict, 前者主要的功能就是计数, 而我们分析数据的时候, 基本都会与计数相遇, 所以这个真的是家常便饭了。 而至于defaultdict, 能自动创建一个初始化的字典, 有时候也非常好用。
-
Counter
假设我们有这样一个任务, 给定一个列表, 让我们统计列表里面每个元素出现的次数, 并且按照频率由高到低对其元素进行排序, 我们可能用这样的方式:sku_purchase = [3, 8, 8, 10, 3, 3, 1, 3, 7, 6, 1, 2, 7, 0, 7, 9, 1, 5, 1, 0] d = { } for i in sku_purchase: if d.get(i) is None: d[i] = 1 else: d[i] += 1 d_most = dict(sorted(d.items(), key=lambda item: item[1], reverse=True)) print(d_most)而有了Counter, 我们就可以一句话进行搞定:
Counter(sku_purchase).most_common(3) # 频率高的前3个 [(3, 4), (1, 4), (7, 3)]Counter还能快速统计字符串中每个字符出现的次数, 这个在NLP创建词典的时候经常会用到:
# Counter能快速统计单词出现次数 Counter('i love python so much').most_common() -
DefaultDict
DefaultDict 能自动创建一个被初始化的字典,也就是每个键都已经被访问过一次。 比如我们有下面一个任务, 给定一个字符串, 要求返回每个字符出现的位置, 就可以用这个字典进行搞定:d = defaultdict(list) s = 'from collections import defaultdict' for index, i in enumerate(s): d[i].append(index) print(d) ## 结果: defaultdict(<class 'list'>, { 'f': [0, 26], 'r': [1, 21], 'o': [2, 6, 13, 20], 'm': [3, 18], ' ': [4, 16, 23], 'c': [5, 10, 33], 'l': [7, 8, 29], 'e': [9, 25], 't': [11, 22, 30, 34], 'i': [12, 17, 32], 'n': [14], 's': [15], 'p': [19], 'd': [24, 31], 'a': [27], 'u': [28]})这个还能完成一个经典的案例: 查找排序词, 所谓排序词是两个字符串含有相同的字符, 但是字符顺序不同
def is_permutation(str1, str2): if str1 is None or str2 is None: return False if len(str1) != len(str2): return False unq_s1 = defaultdict(int) unq_s2 = defaultdict(int) for c1 in str1: unq_s1[c1] += 1 for c2 in str2: unq_s2[c2] += 1 #print(unq_s1, unq_s2) return unq_s1 == unq_s2 r = is_permutation('work', 'woom') # False r = is_permutation('work', 'kowr') # True
5. 小总一下
今天整理了几个高阶的内置函数和迭代器, 这些东西都是比较好用的, 在日常写代码中也会经常遇到, 如果能正确使用, 就可以写出高效且整洁的代码, 但是也不能太简洁, 那样会失去一些可读性。 比如一句话求累积累乘的那个, 可能第一眼不太好看出啥意思。