卷积神经网络,卷积和池化
卷积神经网络是一种多层神经网络,擅长处理图像特别是大图像的相关机器学习问题。
卷积网络通过一系列方法,成功将数据量庞大的图像识别问题不断降维,最终使其能够被训练。CNN最早由Yann LeCun提出并应用在手写字体识别上(MINST)。LeCun提出的网络称为LeNet,其网络结构如下:
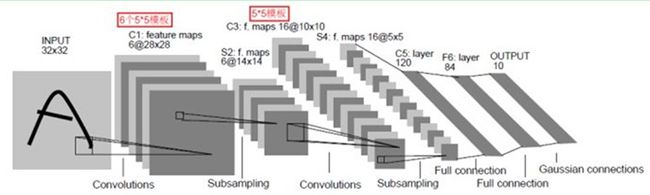
这是一个最典型的卷积网络,由卷积层、池化层、全连接层组成。其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。
卷积层完成的操作,可以认为是受局部感受野概念的启发,而池化层,主要是为了降低数据维度。
综合起来说,CNN通过卷积来模拟特征区分,并且通过卷积的权值共享及池化,来降低网络参数的数量级,最后通过传统神经网络完成分类等任务。
降低参数量级
为什么要降低参数量级?从下面的例子就可以很容易理解了。
如果我们使用传统神经网络方式,对一张图片进行分类,那么,我们把图片的每个像素都连接到隐藏层节点上,那么对于一张1000x1000像素的图片,如果我们有1M隐藏层单元,那么一共有10^12个参数,这显然是不能接受的。(如下图所示)
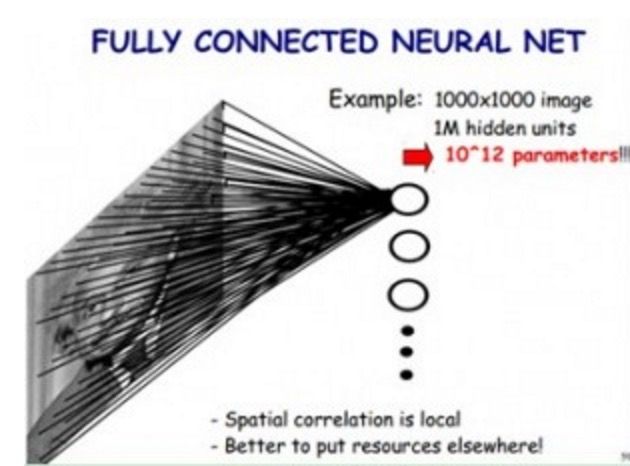
但是我们在CNN里,可以大大减少参数个数,我们基于以下两个假设:
1)最底层特征都是局部性的,也就是说,我们用10x10这样大小的过滤器就能表示边缘等底层特征
2)图像上不同小片段,以及不同图像上的小片段的特征是类似的,也就是说,我们能用同样的一组分类器来描述各种各样不同的图像
基于以上两个,假设,我们就能把第一层网络结构简化如下:
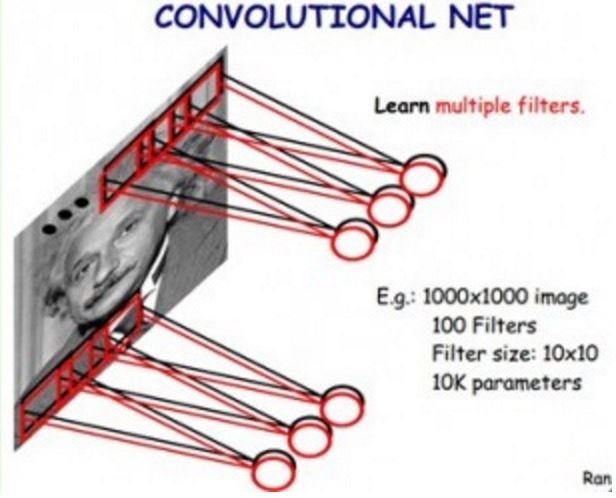
我们用100个10x10的小过滤器,就能够描述整幅图片上的底层特征。
卷积(Convolution)
卷积运算的定义如下图所示:
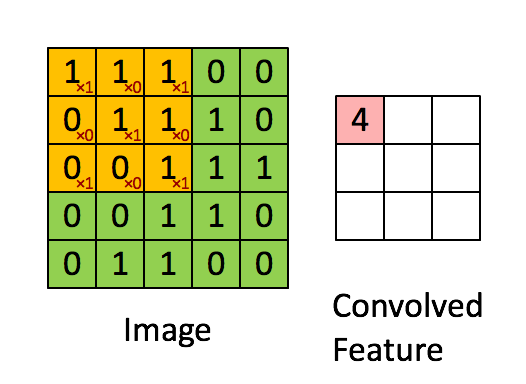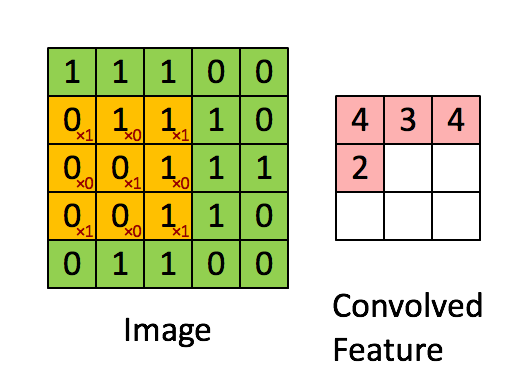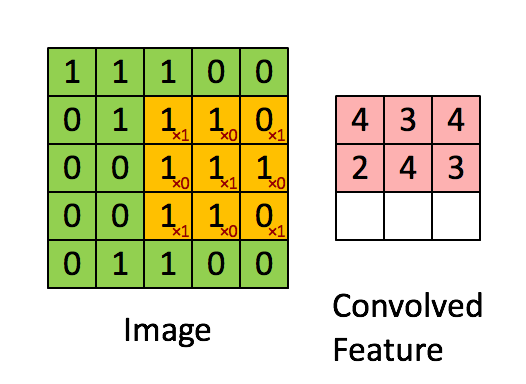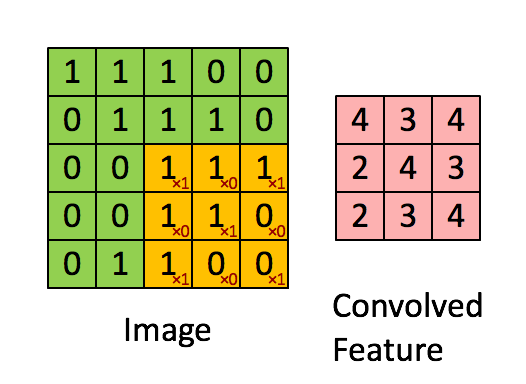
如图所示,我们有一个5x5的图像,我们用一个3x3的卷积核:
1 0 1
0 1 0
1 0 1
来对图像进行卷积操作(可以理解为有一个滑动窗口,把卷积核与对应的图像像素做乘积然后求和),得到了3x3的卷积结果。
这个过程我们可以理解为我们使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
在实际训练过程中,卷积核的值是在学习过程中学到的。
在具体应用中,往往有多个卷积核,可以认为,每个卷积核代表了一种图像模式,如果某个图像块与此卷积核卷积出的值大,则认为此图像块十分接近于此卷积核。如果我们设计了6个卷积核,可以理解:我们认为这个图像上有6种底层纹理模式,也就是我们用6中基础模式就能描绘出一副图像。以下就是24种不同的卷积核的示例:

卷积神经网络(CNN)由输入层、卷积层、激活函数、池化层、全连接层组成,即INPUT-CONV-RELU-POOL-FC
(1)卷积层:用它来进行特征提取,如下:
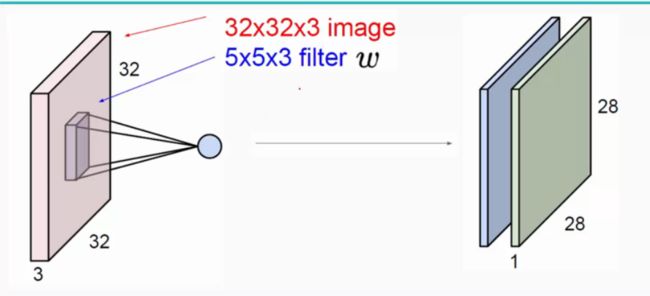
输入图像是32*32*3,3是它的深度(即R、G、B),卷积层是一个5*5*3的filter(感受野),这里注意:感受野的深度必须和输入图像的深度相同。通过一个filter与输入图像的卷积可以得到一个28*28*1的特征图,上图是用了两个filter得到了两个特征图;
我们通常会使用多层卷积层来得到更深层次的特征图。如下:


关于卷积的过程图解如下:
:
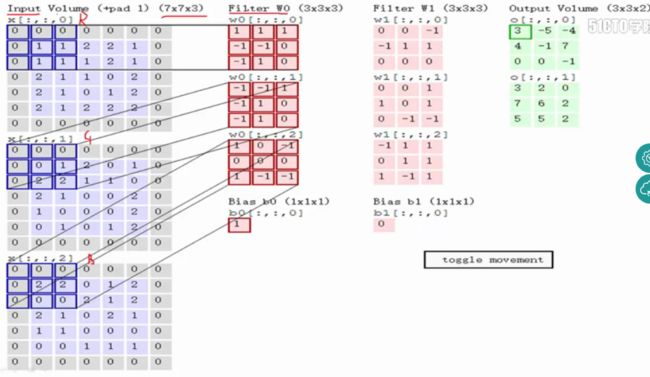
输入图像和filter的对应位置元素相乘再求和,最后再加上b,得到特征图。如图中所示,filter w0的第一层深度和输入图像的蓝色方框中对应元素相乘再求和得到0,其他两个深度得到2,0,则有0+2+0+1=3即图中右边特征图的第一个元素3.,卷积过后输入图像的蓝色方框再滑动,stride=2,如下:
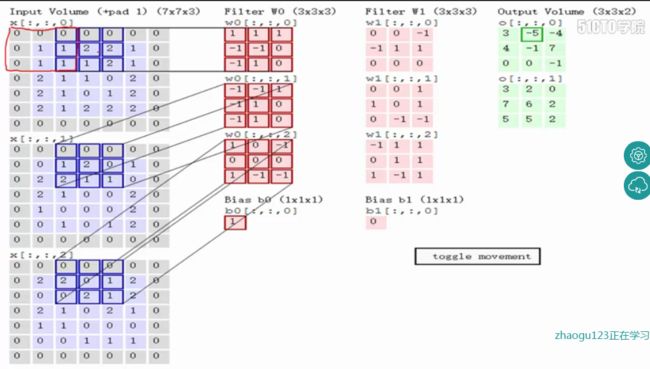
如上图,完成卷积,得到一个3*3*1的特征图;
如果现在特征图由10个32*32*1的特征图组成,即每个特征图上有1024个神经元,每个神经元对应输入图像上一块5*5*3的区域,即一个神经元和输入图像的这块区域有75个连接,即75个权值参数,则共有75*1024*10=768000个权值参数,这是非常复杂的,因此卷积神经网络引入“权值”共享原则,即一个特征图上每个神经元对应的75个权值参数被每个神经元共享,这样则只需75*10=750个权值参数,而每个特征图的阈值也共享,即需要10个阈值,则总共需要750+10=760个参数。
池化(Pooling)
池化听起来很高深,其实简单的说就是下采样。池化的过程如下图所示:
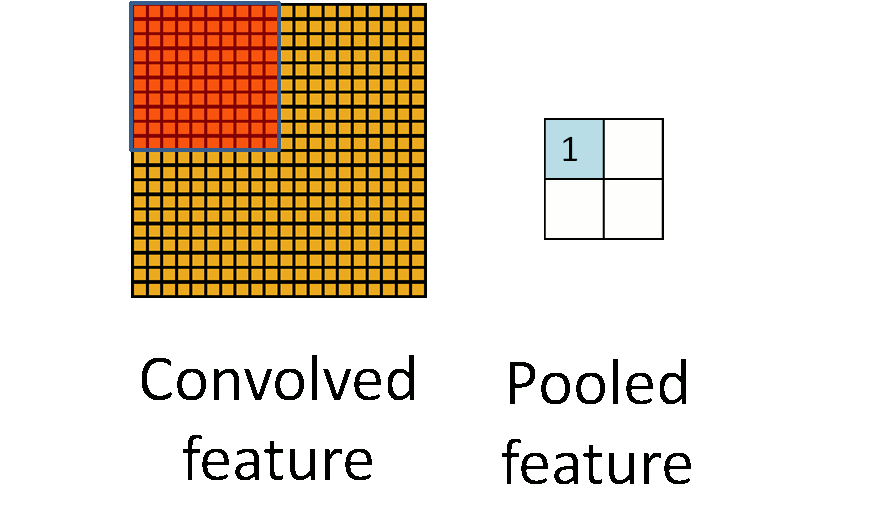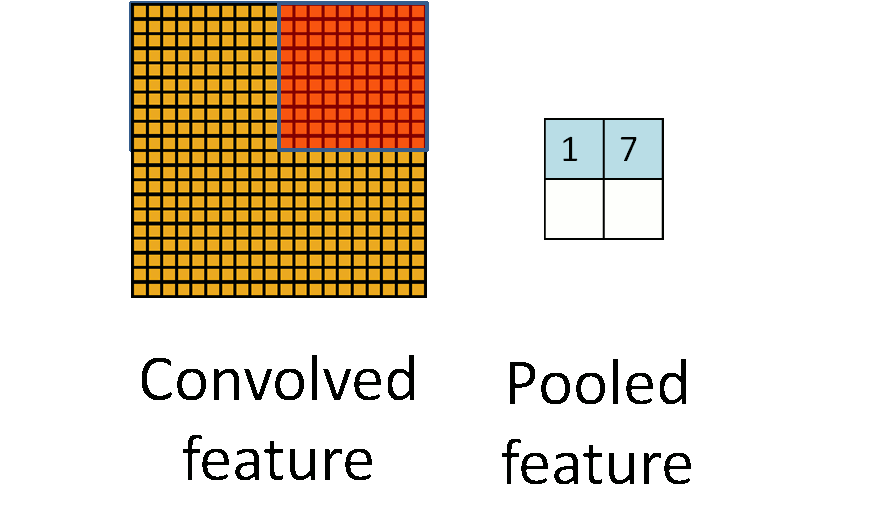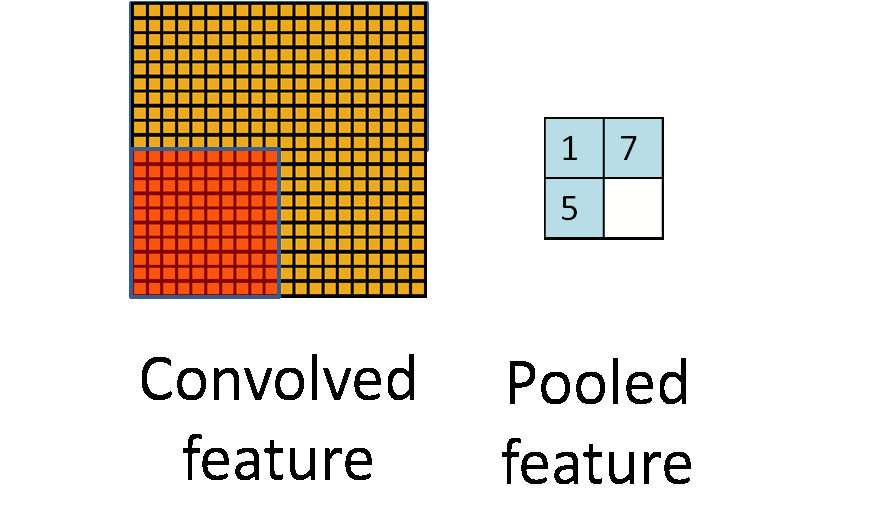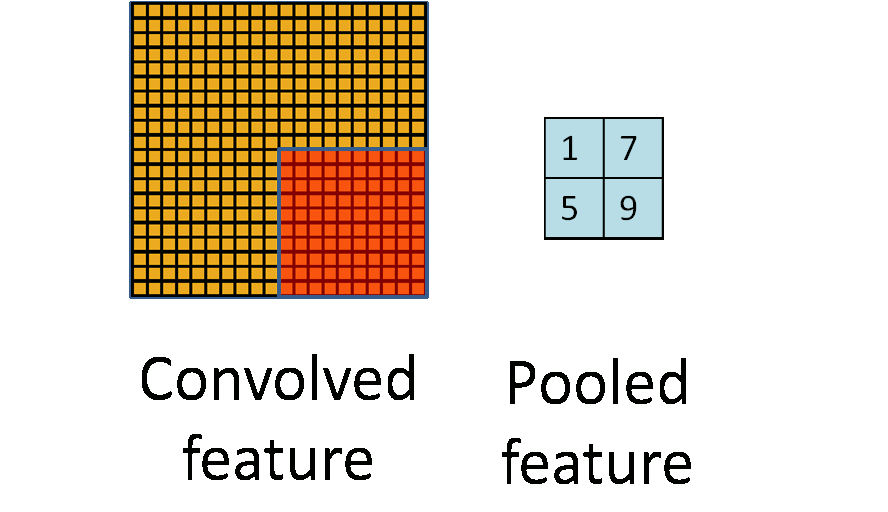
上图中,我们可以看到,原始图片是20x20的,我们对其进行下采样,采样窗口为10x10,最终将其下采样成为一个2x2大小的特征图。
之所以这么做的原因,是因为即使做完了卷积,图像仍然很大(因为卷积核比较小),所以为了降低数据维度,就进行下采样。
之所以能这么做,是因为即使减少了许多数据,特征的统计属性仍能够描述图像,而且由于降低了数据维度,有效地避免了过拟合。
在实际应用中,池化根据下采样的方法,分为最大值下采样(Max-Pooling)与平均值下采样(Mean-Pooling)。
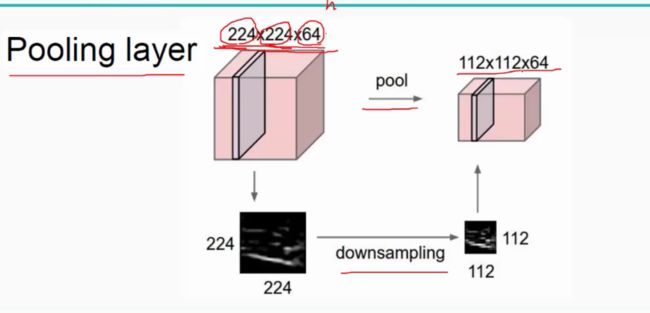
池化层:对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征,如下:
池化操作一般有两种,一种是Avy Pooling,一种是max Pooling,如下:
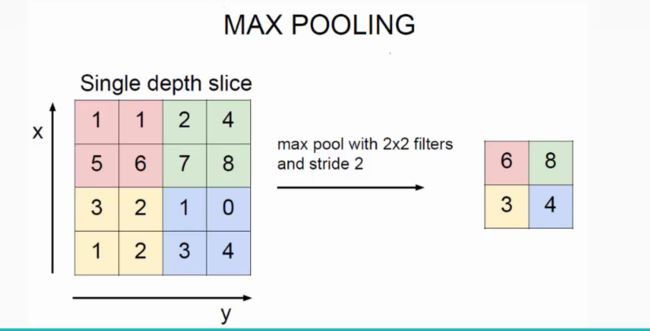
同样地采用一个2*2的filter,max pooling是在每一个区域中寻找最大值,这里的stride=2,最终在原特征图中提取主要特征得到右图。
(Avy pooling现在不怎么用了(其实就是平均池化层),方法是对每一个2*2的区域元素求和,再除以4,得到主要特征),而一般的filter取2*2,最大取3*3,stride取2,压缩为原来的1/4.
注意:这里的pooling操作是特征图缩小,有可能影响网络的准确度,因此可以通过增加特征图的深度来弥补(这里的深度变为原来的2倍)。
全连接层:连接所有的特征,将输出值送给分类器(如softmax分类器)。
总的一个结构大致如下:
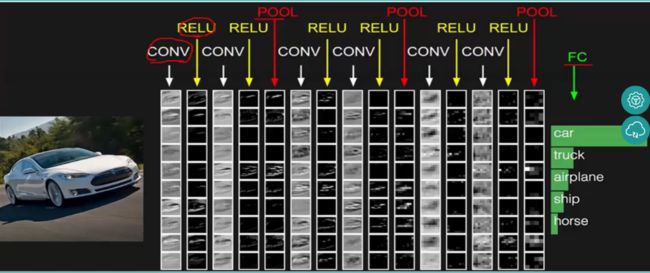
另外:CNN网络中前几层的卷积层参数量占比小,计算量占比大;而后面的全连接层正好相反,大部分CNN网络都具有这个特点。因此我们在进行计算加速优化时,重点放在卷积层;进行参数优化、权值裁剪时,重点放在全连接层。