kafka简单理解
1.Kafka是什么:
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
KAFKA + STORM +REDIS
Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高吞吐量、低等待的平台。
Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性
2.kafka的核心组件
Topic :消息根据Topic进行归类
Producer:发送消息者
Consumer:消息接受者
broker:每个kafka实例(server)
Zookeeper:依赖集群保存meta信息。
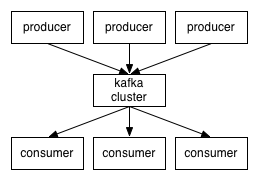
2-3.X-Consumer与topic的关系
本质上kafka只支持Topic;
每个group中可以有多个consumer,每个consumer属于一个consumer group;
通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高”故障容错”性,如果group中的某个consumer失效那么其消费的partitions将会有其他consumer自动接管。
对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer;
那么一个group中所有的consumer将会交错的消费整个Topic,每个group中consumer消息消费互相独立,我们可以认为一个group是一个”订阅”者。
在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);
一个Topic中的每个partions,只会被一个”订阅者”中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
kafka只能保证一个partition中的消息被某个consumer消费时是顺序的;事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的。
消息的分发 和Consumer的负载均衡,先记下,稍后总结。
网上有总结的很好的,就不重复造轮子了,传送门
3:Kafka集群部署
wget http://mirrors.hust.edu.cn/apache/kafka/1.1.0/kafka_2.11-1.1.0.tgz.tgz
废掉防火墙
解压 修改用户所有者 解压,修改配置文件
常用操作
查看当前服务器中的所有topic
bin/kafka-topics.sh --list --zookeeper spark01:2181
创建topic
bin/kafka-topics.sh --create --zookeeper spark01:2181 --replication-factor 1 --partitions 1 --topic test
删除topic
bin/kafka-topics.sh --delete --zookeeper spark01:2181 --topic test
需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
通过shell命令发送消息
bin/kafka-console-producer.sh --broker-list spark01:9092 --topic test1
通过shell消费消息
bin/kafka-console-consumer.sh --zookeeper spark01:2181 --from-beginning --topic test1
查看消费位置
bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper spark01:2181 --group testGroup
查看某个Topic的详情
bin/kafka-topics.sh --topic test --describe --zookeeper spark01:2181
对分区数进行修改
bin/kafka-topics.sh --zookeeper spark01--alter --partitions 15 --topic utopic
4.Kafka中的名词快速入门
Topic(主题)
kafka系统通过主题来区分不同业务类型的消息记录
例如,用户登录数据存储在主题A,用户充值记录存储在主题B中,则如果应用程序只订阅了主题A,而没有订阅订阅主题B,那该引用只能读取主题A中的数据
Broker(代理)
在Kafka集群中一个Kafka进程(Kafka进程又称为Kafka实例)被称为一个代理(broker)节点。代理节点是消息队列中的一个常用概念。通常在部署Kafka集群时,一台服务器上部署一个Kafka实例。
Producer(生产者)
生产者负责将数据传入Kafka,比如flume,Java后台服务,logstash
生产者可以有多个,并且可以同时往一个人topic中写数据,也可以同时往同一个partition中写数据
每一个生产者都是一个独立的进程,而且单个生产者就具有分发数据的能力
一个生产者可以同时往多个topic中分发数据
####计算主题索引的索引值
分区索引值 = 键的哈希值取绝对值 % 分区数
# 计算公式
def partition(key: Any, numPartitions: Int): Int = {
Utils.abs(key.hashCode) % numPartitions
}
Consumer(消费者)
消费者(Consumer)从Kafka集群指定的主题(Topic)中读取消息记录
在读取主题数据时,需要设置消费组名(GroupId),如果不设置,则Kafka消费者或默认生成一个消费者组名
Consumer Group(消费者组)
消费者负责拉取数据,比如steaming、storm、java服务
消费者组中可以存在多个consumer,在steaming中一个consumer作为一个线程
新增或减少consumer数量会触发负载均衡,目的是减少部分的broker的压力,提高Kafka的吞吐量
分区(Partition)
每一个主题(Topic)可以有一个或多个分区(Partition).在Kafka系统的设计思想中,分区是基于物理层面的,不同的分区对应着不同的数据文件。
Kafka通过分区(Partition)来支持物理层面上的并发读写,以提高Kafka居群的吞吐量。
每个分区内部的消息记录是有序的,每个消息都是有一个连续的偏移量序号(Offset)
一个分区只对应一个代理节点,一个代理节点可以管理多个分区。
副本(Replication)
在Kafka系统中,每个主题(Topic)在创建的时候要求指定他的副本数,默认是1.通过副本(Replication)机制来保证Kafka分布式集群数据的高可用性。
###提示
在创建主题时,主题的副本系数值应如以下设置:
(1):若集群的数量大于3,则主题的副本系数可以设置为3;
(2):若集群的数量小于3,则主题的数量可以设置为小于等于集群数量值。
例如,集群数量为2,则副本系数可以设置为1或者2;集群数量为1,则副本系数只能设置为1.
通常情况下,当集群数量大于等于3时,为了保证集群数据不丢失,会将副本系数值设置为3.当然,集群数量大于等于3时,副本系数值可以设置为1或2,但是会存在数据丢失的风险。
记录(Record)
被实际记录到Kafka集群并且可以被消费者应用程序的取得数据,被称为记录(Record)。每条记录包含一个键(Key)、值(Value)和时间戳(Timestamp)
部分来自书籍-
Kafka并不难学!入门、进阶、商业实战–邓杰-编著
4.Kafka中元数据的存储分布
在Kafka中,核心组件的元数据信息均存储在Zookeeper系统中。这些元数据信息具体包含:控制器选举次数、代理节点和主题、配置、管理员操作、控制器。他们在zookeeper中的分不吐如下
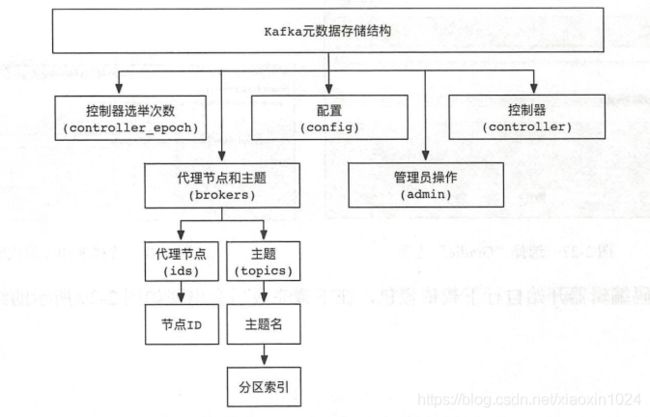
1.控制器选举次数
在Kafka系统中,控制器进行每一次选举,都会在Zookeeper系统/controller_epoch节点下进行记录,该值为一个数字。在Kafka集群中,第一个代理节点(Broker)启动时,该值为1
.
在Kafka集群中,如果遇到代理节点宕机或者变更,则卡夫卡集群会重新选举新的控制器。每次控制器发生变化时Zookeeper系统/controller_epoch节点中的值就会加1.
2.代理节点和主题
1.在Zookeeper系统/brokers节点中,存储着Kafka代理接待你和主题的元数据信息
2.在Zookeeper系统/brokers/ids节点中,存储着代理节点的ID值
2.在Zookeeper系统/brokers/topics节点中,存储着主题和分区的元数据信息
问题:
1.Kafka数据的存储机制
1.broker先接收到producer传过来的数据,将数据写入到操作系统(Linux)的缓存里面(pagecache),pagecache会用尽可能多的空闲内存来存储数据
2.使用sendfile技术尽可能的减少操作系统和应用程序的重复缓存 写数据时是顺序写入(顺序写入的速度可以达到600m/s)
2.consumer是怎么解决负载均衡的
1.获取consumer消费的起始分区号
2.计算出consumer消费的分区数量
3.用起始分区号的哈希值%分区数
3.segment是什么?segment的概念
一个分区被分为多个大小相同的segment,默认是1G
每个segment是由多个index和logs文件组成,index存储数据对应的索引,实际数据是存储在log文件中
segment是有生命周期的,生命周期默认是168小时(7天)。
4.数据是怎么分发的(数据的分发策略)
Kafka接受到数据后会根据创建的topic指定topic指定的副本来存储的,多副本之间会有选举的过程,既有leader,follower
Kafka会调用分区器进行分发数据,默认分区器是DafaultPartitioner(分区的逻辑是key的哈希值%分区数),也可以自定义分区器,需要实现partition特质,实现partition方法。
5.Kafka数据能做到全局有序吗
不能
只能做到分区内有序
如果要做到topic的全局有序,只声明一个分区,但会影响吞吐量
6.Kafka的lsr源码实现
待解答
7.Kafka api操作
// 生产者
import java.util.Properties
import kafka.javaapi.producer.Producer
import kafka.producer.{KeyedMessage, ProducerConfig}
/**
* 实现一个生产者
* 模拟一些数据并不断发送到Kafka的topic中
* 实现自定义分区器
*/
object HomeWorkProducer {
def main(args: Array[String]): Unit = {
// 配置Kafka的信息
val props = new Properties()
// 配置序列化类型
props.put("serializer.class", "kafka.serializer.StringEncoder")
// 指定Kafka列表 --注意value不能有空格 不用写全
props.put("metadata.broker.list", "hadoop01:9092,hadoop02:9090")
// 设置消息发送数据的响应方式 0 1 -1
props.put("request.required.acks", "1")
// 声明分区器
props.put("partition.class", "com.qf.gp15.day08.MyPartitioner")
// 指定topic
val topic = "test"
// 创建Producer配置对象
val config = new ProducerConfig(props)
// 创建Producer对象
val producer: Producer[String, String] = new Producer(config)
// 模拟数据 利用netcat模拟 nc -lk 9999
for (i <- 1 to 10000) {
val msg = s"$i:Producer send data"
producer.send(new KeyedMessage[String, String](topic, msg))
Thread.sleep(500)
}
}
}
// 消费者
import java.util.Properties
import java.util.concurrent.Executors
import kafka.consumer.{Consumer, ConsumerConfig, KafkaStream}
import scala.collection.mutable
class HomeWorkConsumer(val consumer: String, val stream: KafkaStream[Array[Byte], Array[Byte]]) extends Runnable {
override def run() = {
val it = stream.iterator()
while (it.hasNext()) {
val data = it.next()
val topic = data.topic
val offset = data.offset
val partition = data.partition
val msgByte: Array[Byte] = data.message()
val msg: String = new String(msgByte)
println(s"consumer:$consumer,topic:$topic,offset:$offset,partition:$partition,msg:$msg")
}
}
}
object HomeWorkConsumer {
def main(args: Array[String]): Unit = {
// 定义topic
val topic = "test"
// 定义map,用于多个topic的信息,key=topic value=获取topic数据的线程数
val topics = new mutable.HashMap[String, Int]()
topics.put(topic, 1)
// 配置
val props = new Properties()
// 定义group
props.put("group.id", "group02")
// 指定zk列表
props.put("zookeeper.connect", "hadoop01:2181,hadoop02:2181,hadoop03:2181")
// 指定offset
// 如果zookeeper没有offset值 或者offset值超出范围。那么给个初始的offset
props.put("auto.offset.reset", "smallest")
// 创建配置类,封装配置信息
val config = new ConsumerConfig(props)
// 创建Consumer对象
val consumer = Consumer.create(config)
// 开始消费数据
val streams: collection.Map[String, List[KafkaStream[Array[Byte], Array[Byte]]]] = consumer.createMessageStreams(topics)
// 将topic中的数据拿出来,KafkaStream中,key=offset value=data
val topicStreams: Option[List[KafkaStream[Array[Byte], Array[Byte]]]] = streams.get(topic)
// 创建固定线程池
val pool = Executors.newFixedThreadPool(3)
for (i <- 0 until topicStreams.size) {
pool.execute(new HomeWorkConsumer(s"consumer:$i", topicStreams.get(0)))
}
}
}
// 自定义分区器
import kafka.producer.Partitioner
import kafka.utils.Utils
class MyPartitioner(props: kafka.utils.VerifiableProperties = null) extends Partitioner {
override def partition(key: Any, numPartitions: Int) = {
Utils.abs(key.hashCode) % numPartitions
}
}
// 配置文件梳理
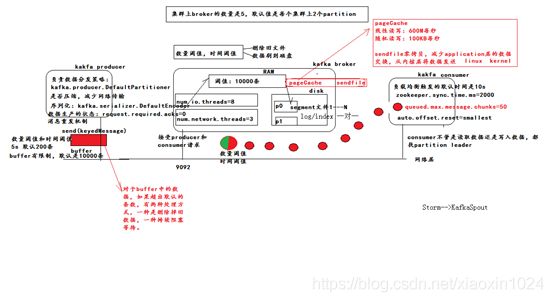
//图片来自网络,侵联删
未完待续…